《HelloGitHub》第 93 期
兴趣是最好的老师,
HelloGitHub
让你对编程感兴趣!

简介
HelloGitHub
分享 GitHub 上有趣、入门级的开源项目。
这里有实战项目、入门教程、黑科技、开源书籍、大厂开源项目等,涵盖多种编程语言 Python、Java、Go、C/C++、Swift...让你在短时间内感受到开源的魅力,对编程产生兴趣!
以下为本期内容|每个月
28
号更新
C 项目
1、
rsync
:Linux 远程同步文件的工具。该项目提供了一种快速、增量的文件传输方式,即仅传输有变动的部分,可用于远程同步和备份文件。
C# 项目
2、
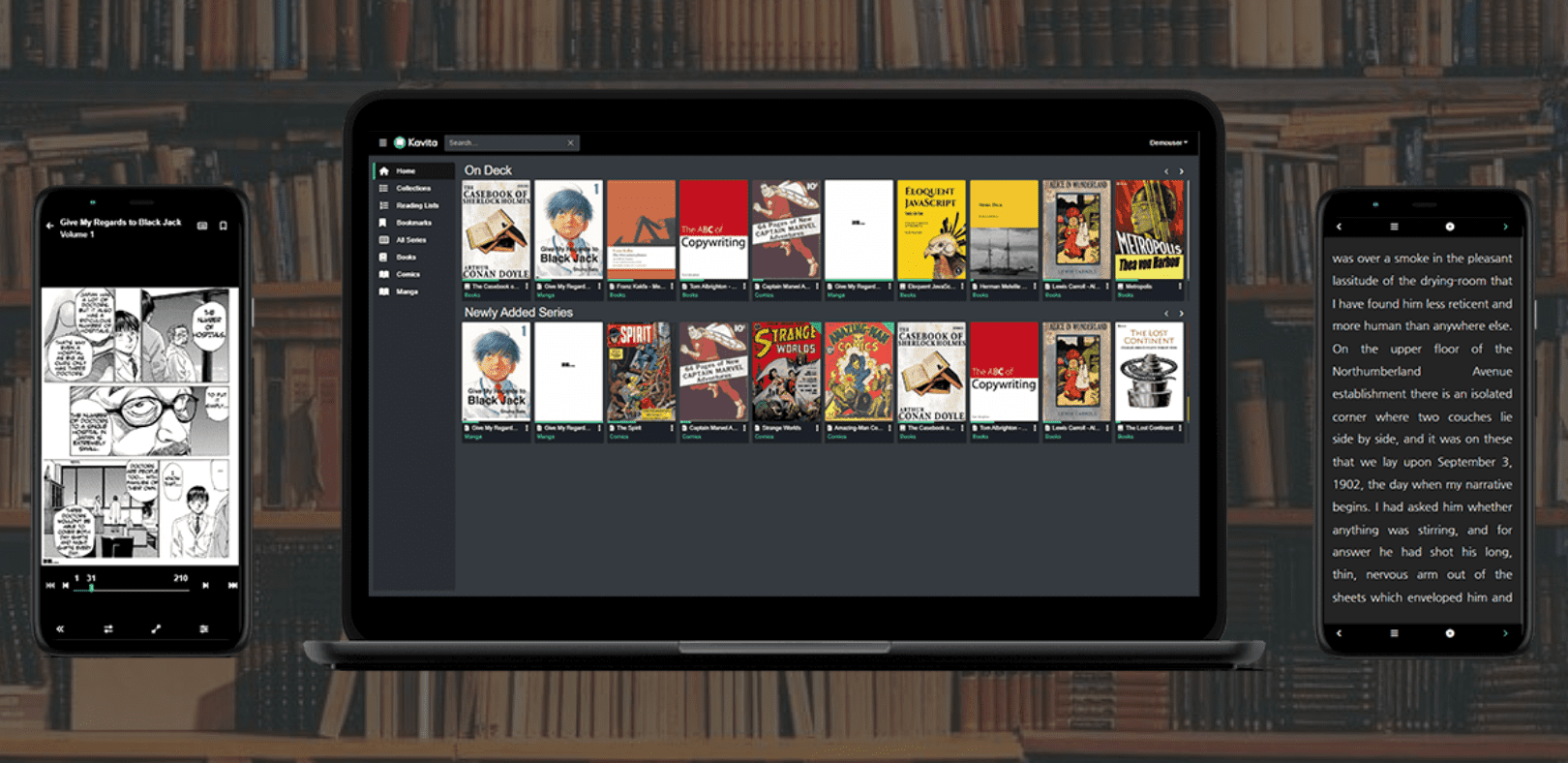
Kavita
:一款功能丰富的在线阅读平台。该项目可以在本地架设一个阅读漫画和电子书的 Web 平台,在手机、平板、台式机等设备上都有着出色的访问体验。
3、
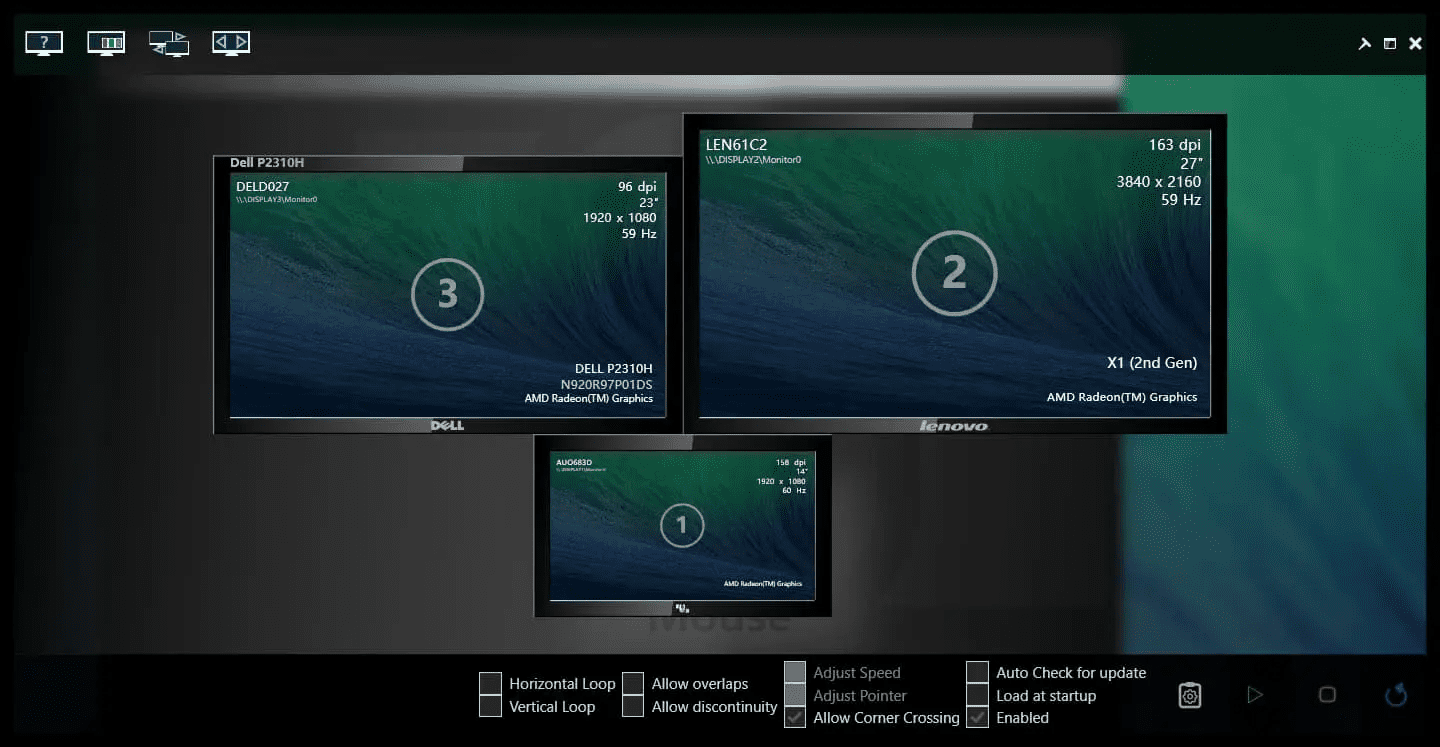
LittleBigMouse
:Windows 多显示器鼠标平滑移动的工具。在 Windows 多显示器、分辨率不一致的情况下,鼠标在屏幕间移动会出现跳跃,比如外接了一台 4k 屏幕的和一台 2k 的屏幕,从 4k 屏幕中间挪到 2k 屏幕,鼠标就出现在底部了。该项目可以完美解决这个鼠标跳跃的问题,实现 Windows 多显示器鼠标平滑移动。来自
@Wu Zheng
的分享
C++ 项目
4、
Modern-CPP-Programming
:现代 C++ 编程课程。该教程面向有一定编程基础的人,内容涵盖 C++ 编程的基础知识、高级 C++ 语义和概念。
5、
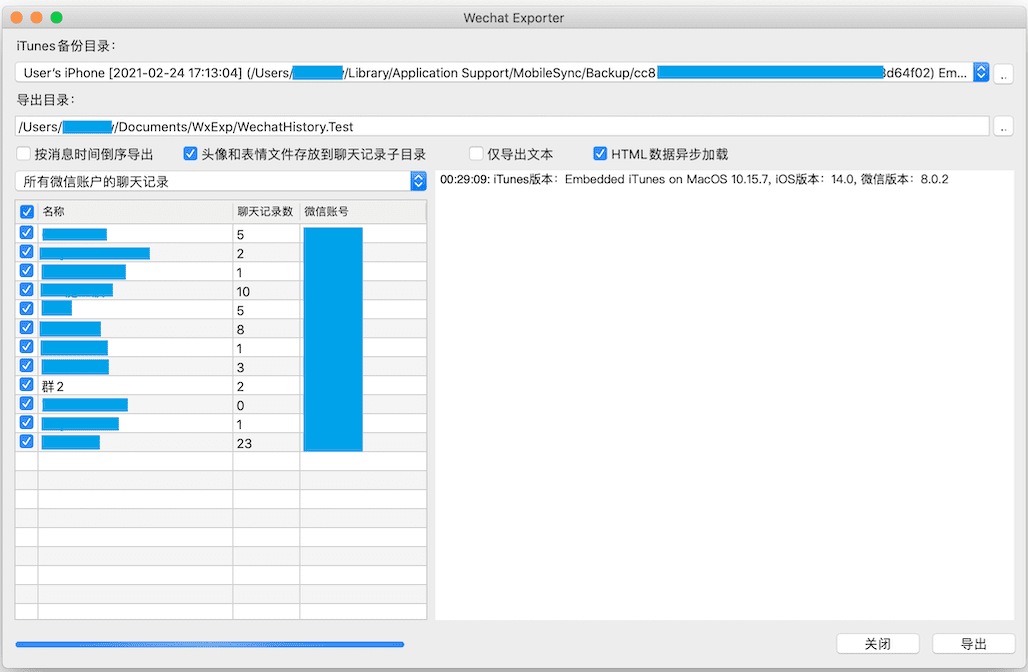
WechatExporter
:微信聊天记录迁移和备份工具。这是一个用于导出微信聊天记录的工具,支持以 HTML、PDF 或文本格式保存聊天内容,适用于 Windows 和 macOS 系统。
Go 项目
6、
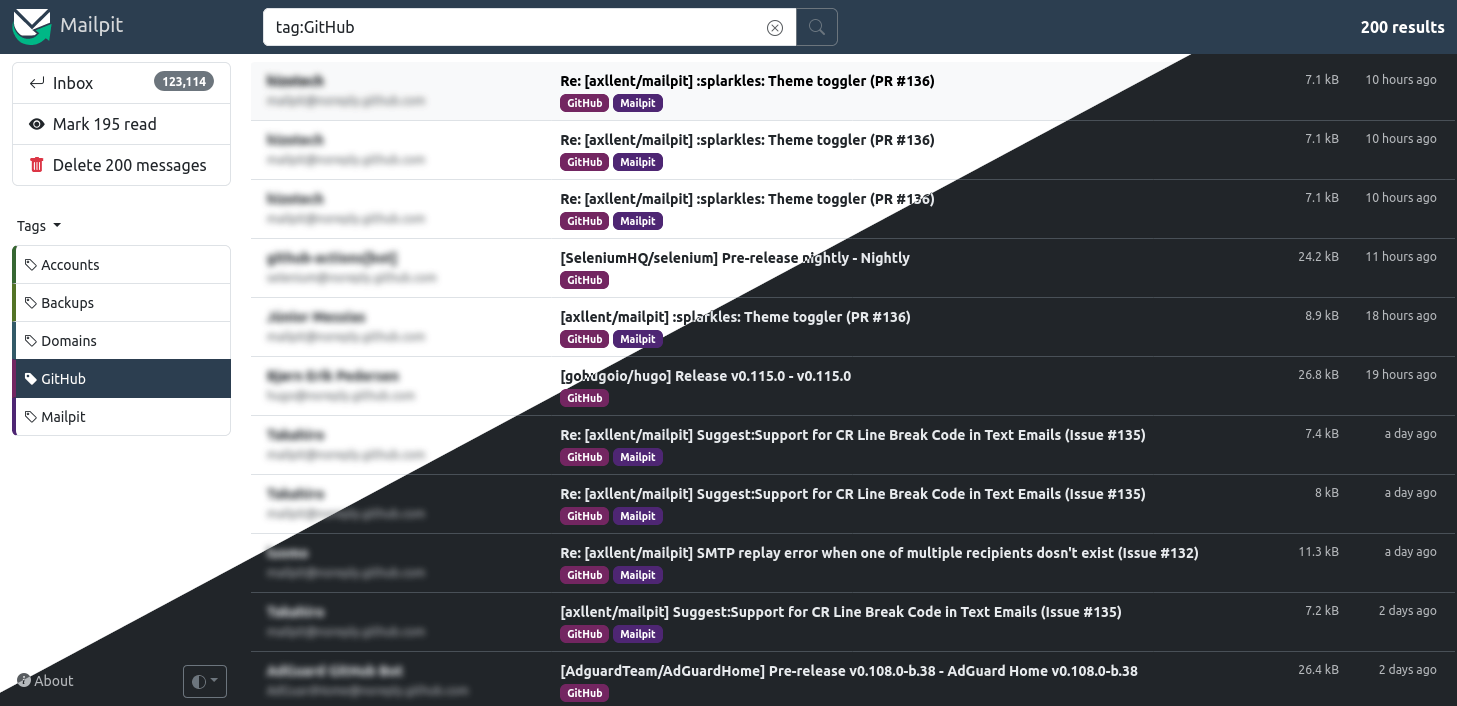
mailpit
:带 API 的电子邮件测试工具。这是一个小型、快速、多平台的电子邮件测试工具,它可以充当一个 SMTP 服务器,自带 Web 界面,支持模拟电子邮件接收、切换不同设备查看邮件等功能,还提供了可用于自动集成测试的接口。
7、
muffet
:Go 写的网站链接检查工具。该项目通过多线程和递归的方式,检查目标网站中所有页面的链接。它使用简单、速度快,支持 a、img、link、script 等多种标签。

8、
one-api
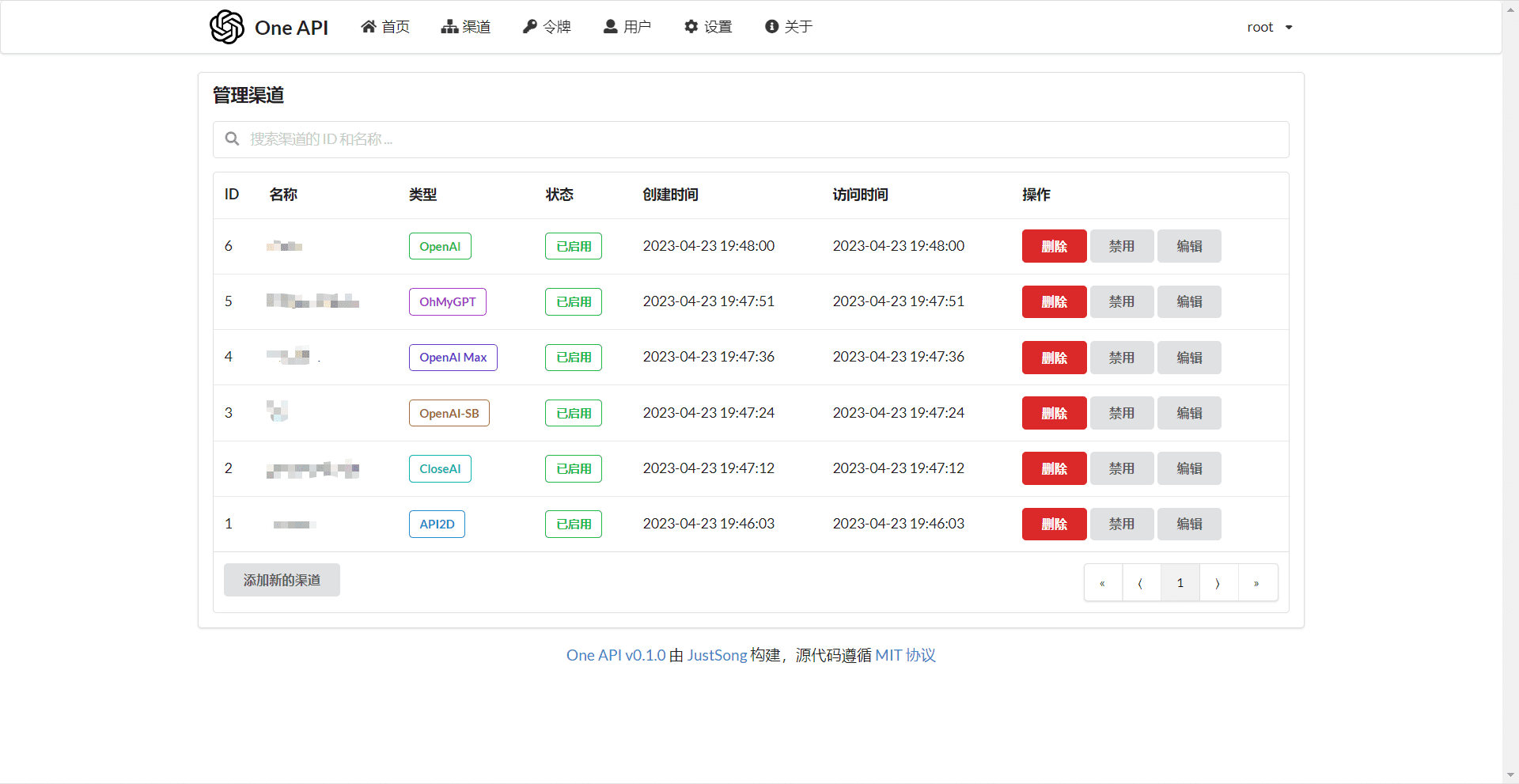
:OpenAI 接口管理和分发系统。该项目集成了各种大模型,并统一转化成了类似 OpenAI 接口的服务。它开箱即用、单文件,支持负载均衡、令牌管理、兑换码、用户分组、查看额度、邀请奖励等功能,可用于自建 ChatGPT 服务。
9、
zen
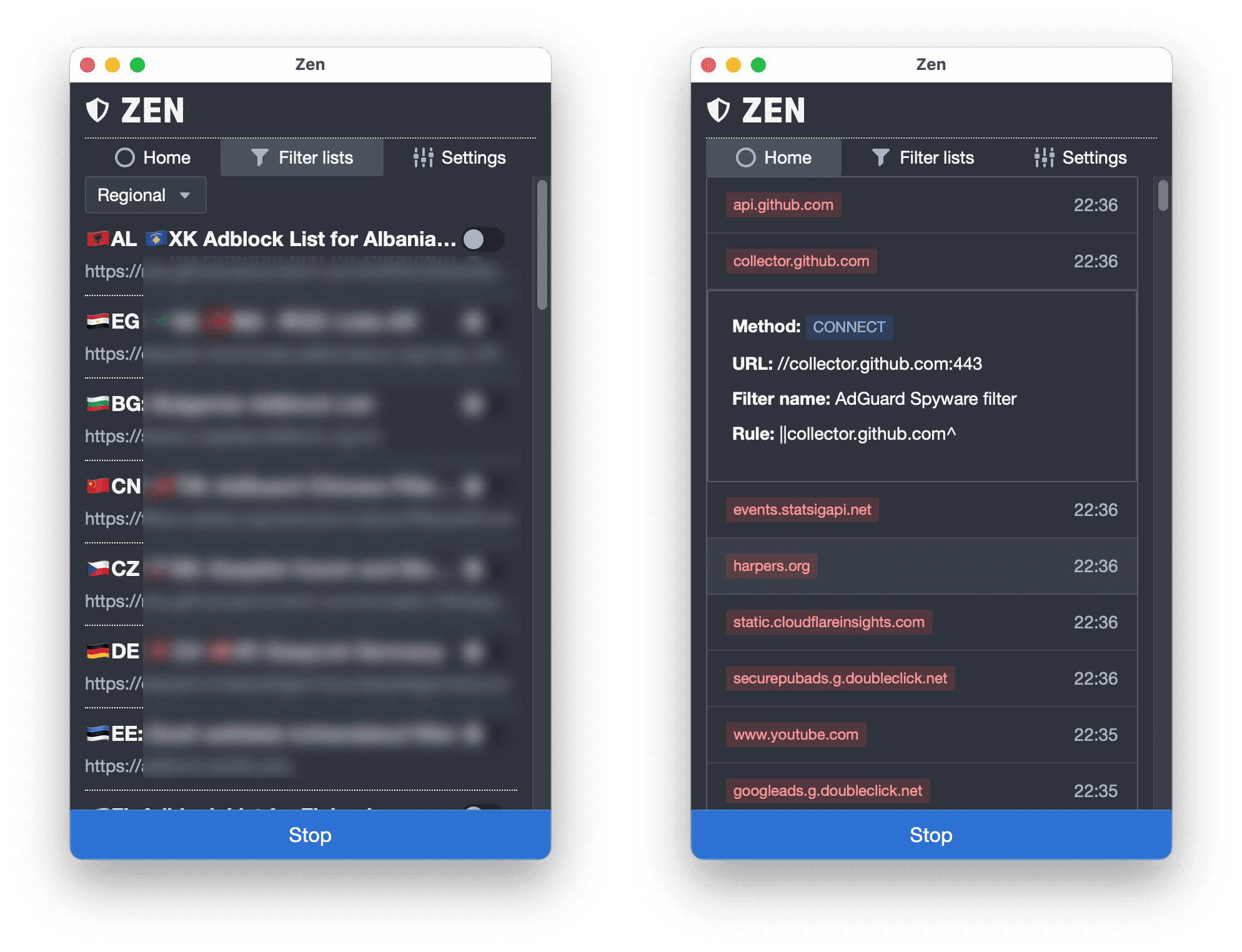
:一款适用于 PC 的广告拦截器。该项目是采用 Go 语言 Wails 框架写的能够屏蔽各种广告的桌面工具。它的工作原理是设置一个代理,拦截所有应用的 HTTP 请求,从而阻止广告和跟踪行为的请求,支持 Windows、macOS 和 Linux 操作系统。
Java 项目
10、
sensitive-word
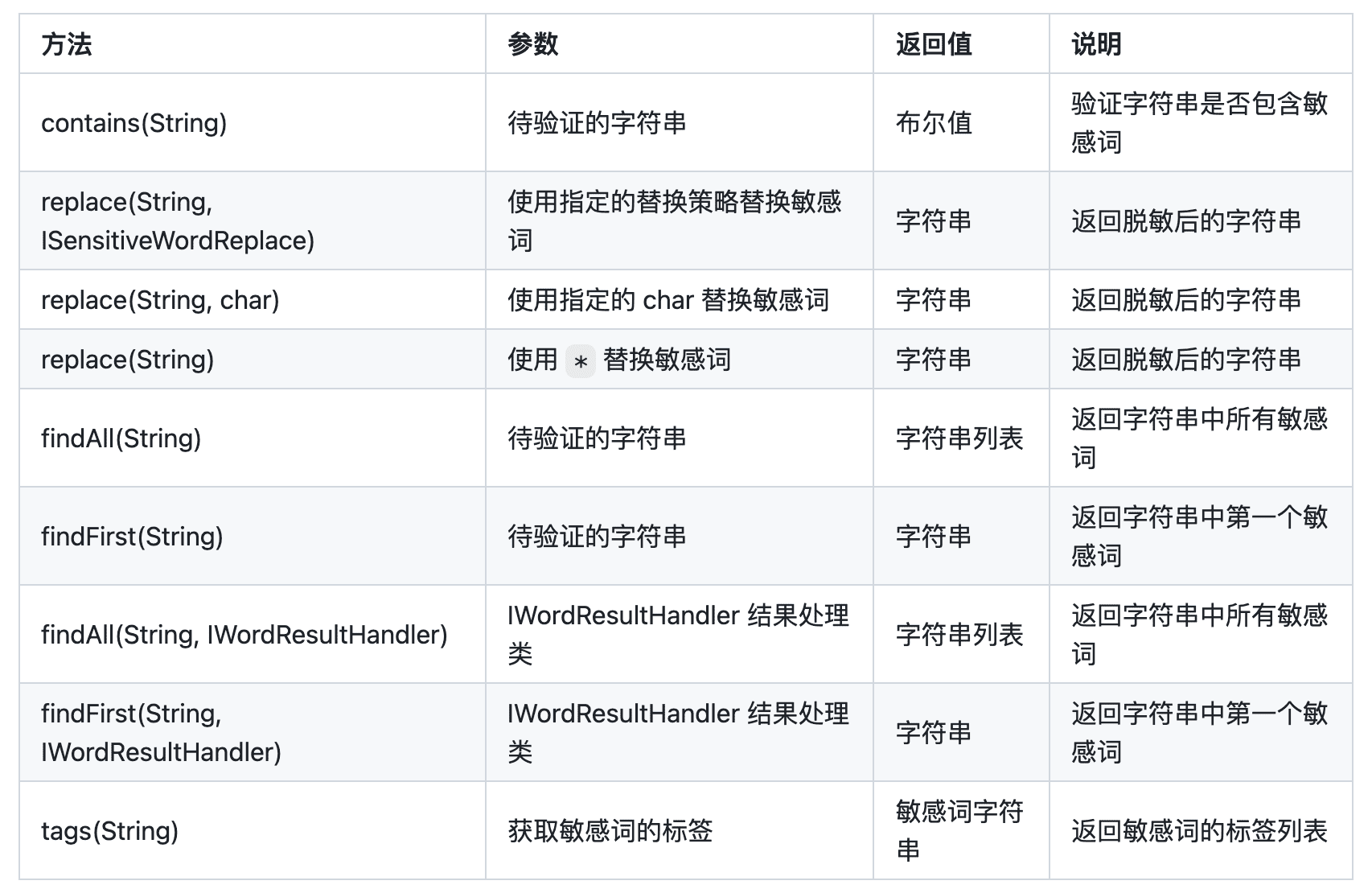
:用于过滤敏感词的 Java 库。该项目是基于 DFA 算法实现的高性能敏感词过滤工具,词库收录了 6w+ 内容,支持自定义敏感词、白名单、替换策略、数字常见形式的互换、忽略重复词等功能。
11、
SMS4J
:Java 的短信服务聚合框架。该项目集成了国内众多第三方短信服务,简化了接入多个短信 SDK 的流程,仅通过修改配置文件,就能轻松实现发送短信的功能。来自
@ヽ米 饭
的分享
@RestController
@RequestMapping("/test/")
public class DemoController {
// 测试发送固定模板短信
@RequestMapping("/")
public void doLogin(String username, String password) {
//阿里云向此手机号发送短信
SmsFactory.createSmsBlend(SupplierType.ALIBABA).sendMessage("18888888888","123456");
//华为短信向此手机号发送短信
SmsFactory.createSmsBlend(SupplierType.HUAWEI).sendMessage("16666666666","000000");
}
}
JavaScript 项目
12、
daedalOS
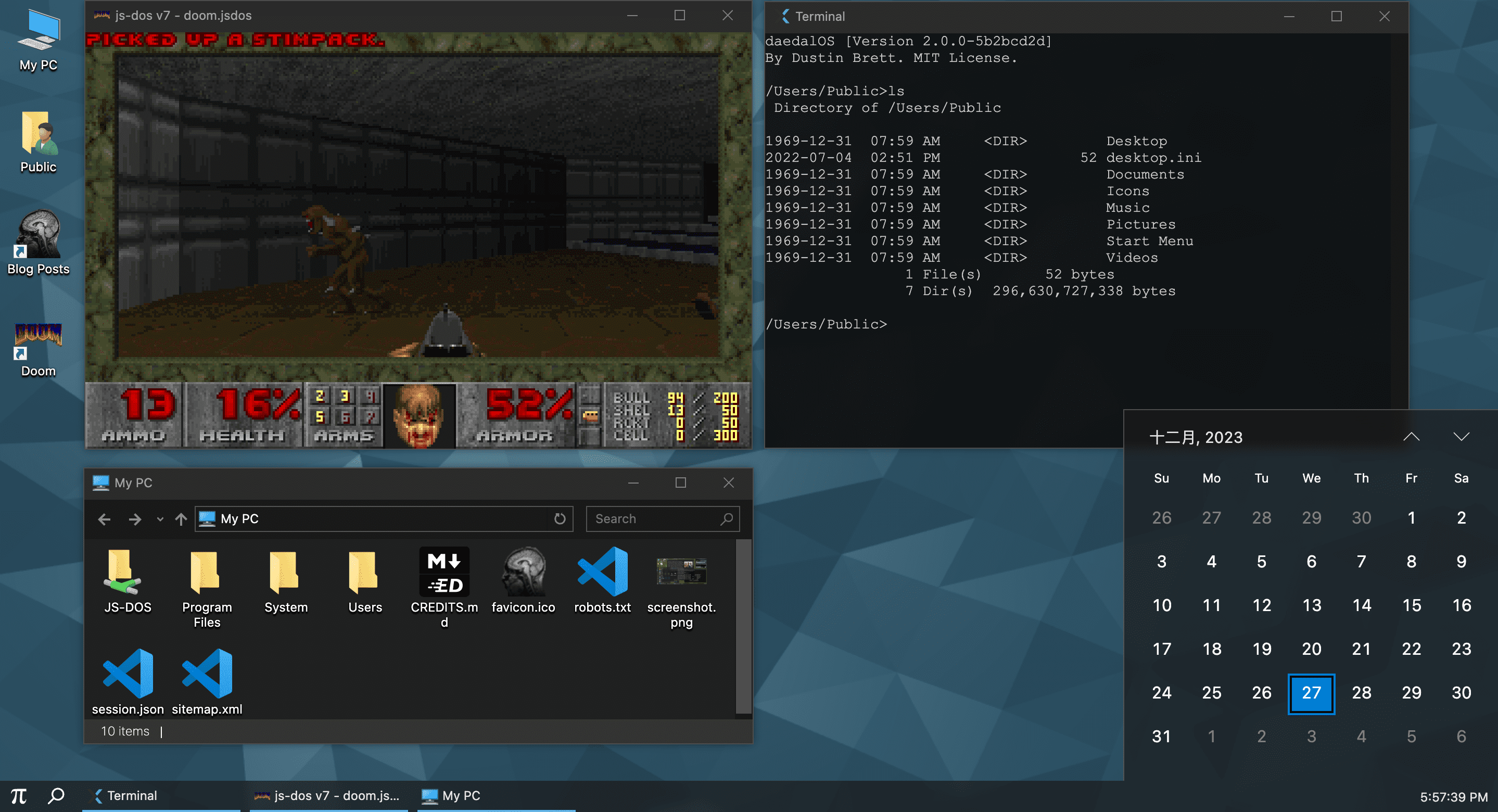
:跑在浏览器里的桌面环境。该项目是用 JavaScript 写的运行在浏览器中的仿 Windows 桌面操作系统,支持开始菜单、动态壁纸、命令行终端、视频播放器、3D 弹球、Markdown 查看器、浏览器等功能。
13、
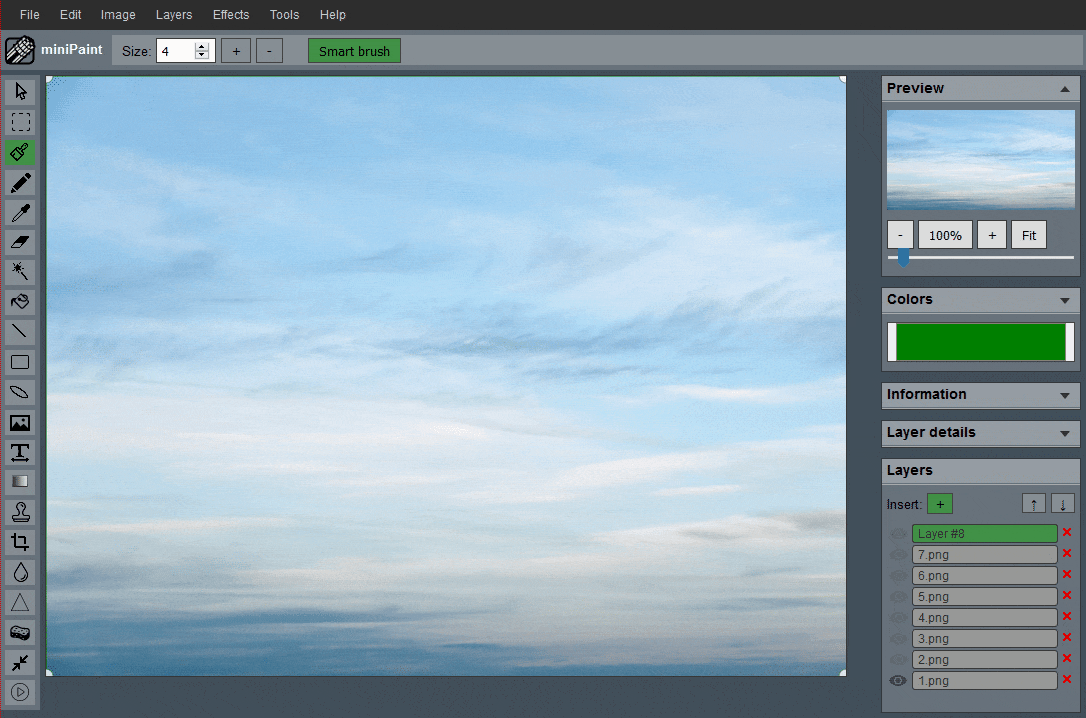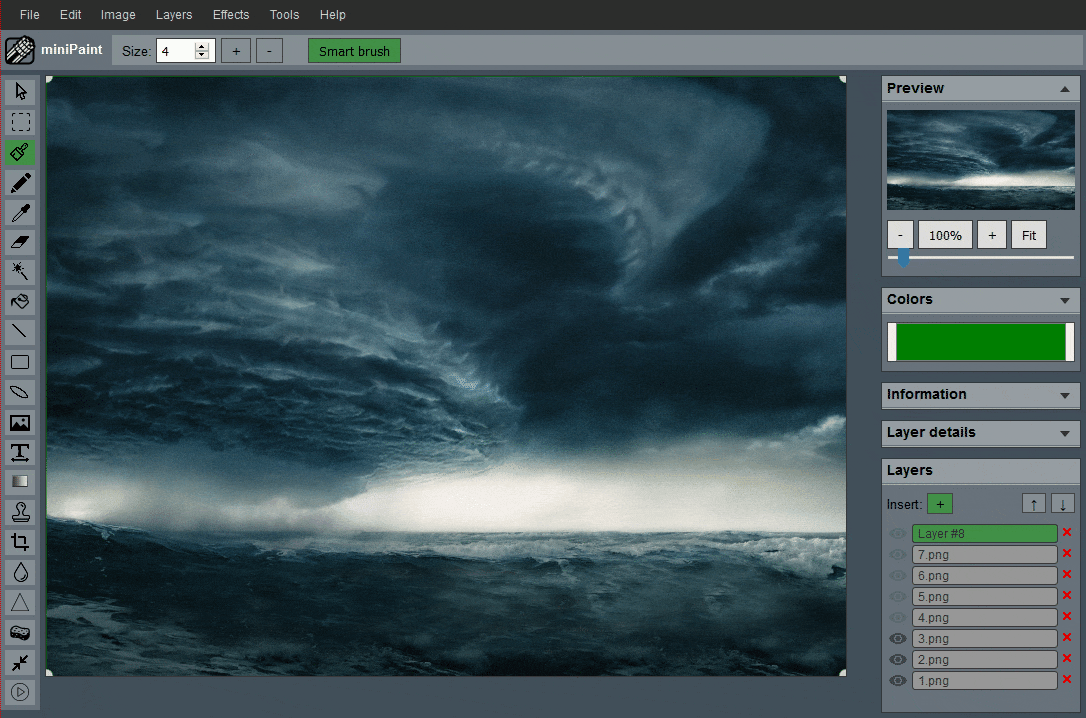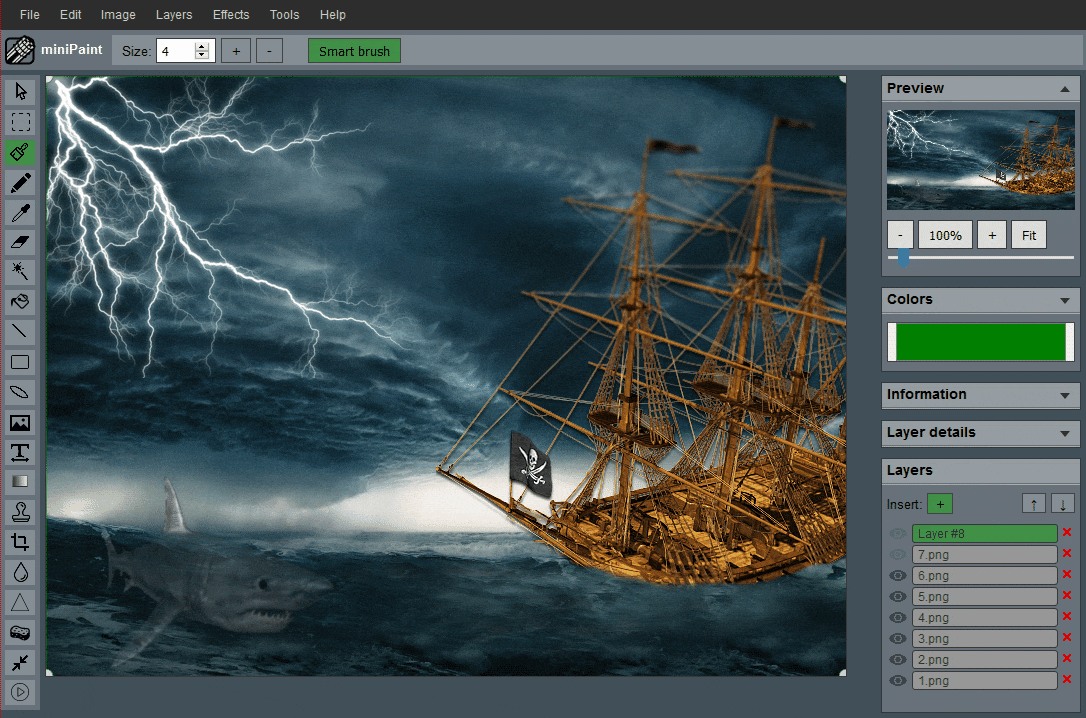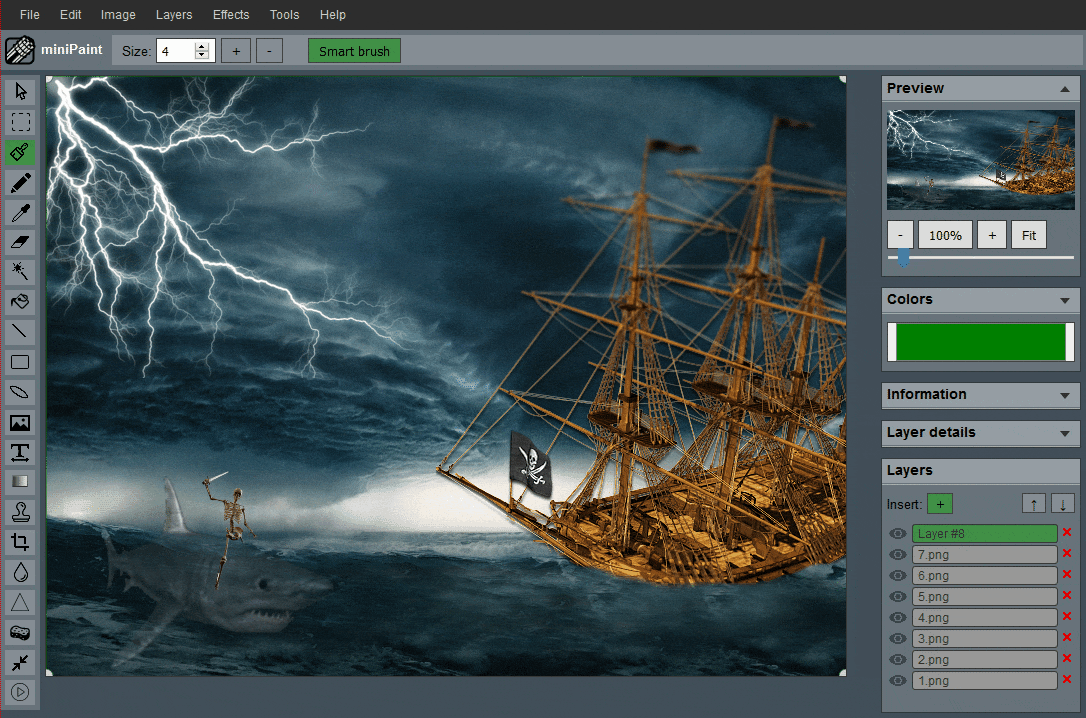
miniPaint
:免费的在线图片编辑器。该项目无需安装、可直接在浏览器中运行,支持创建/编辑图像、图层、滤镜、马赛克、绘图工具等功能。
14、
multipleWindow3dScene
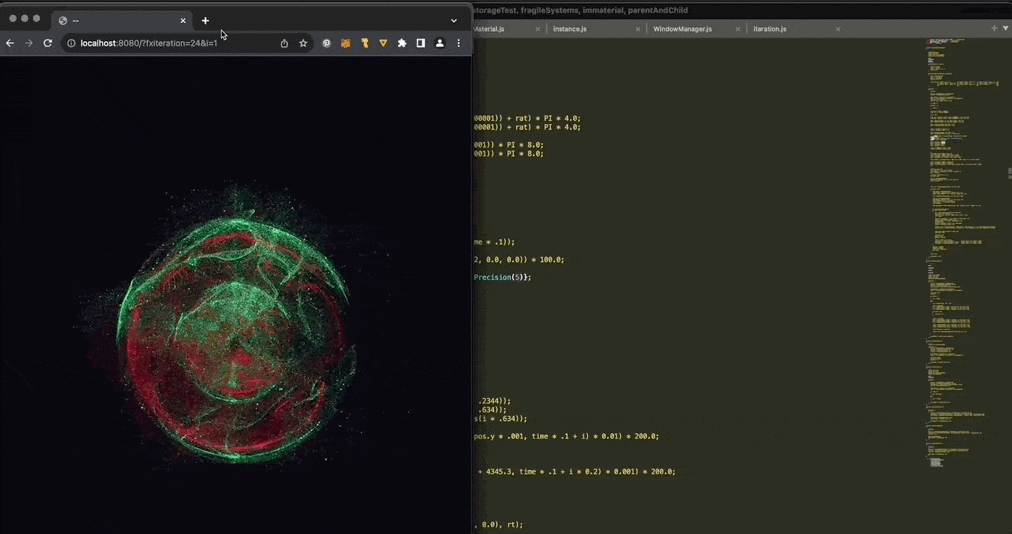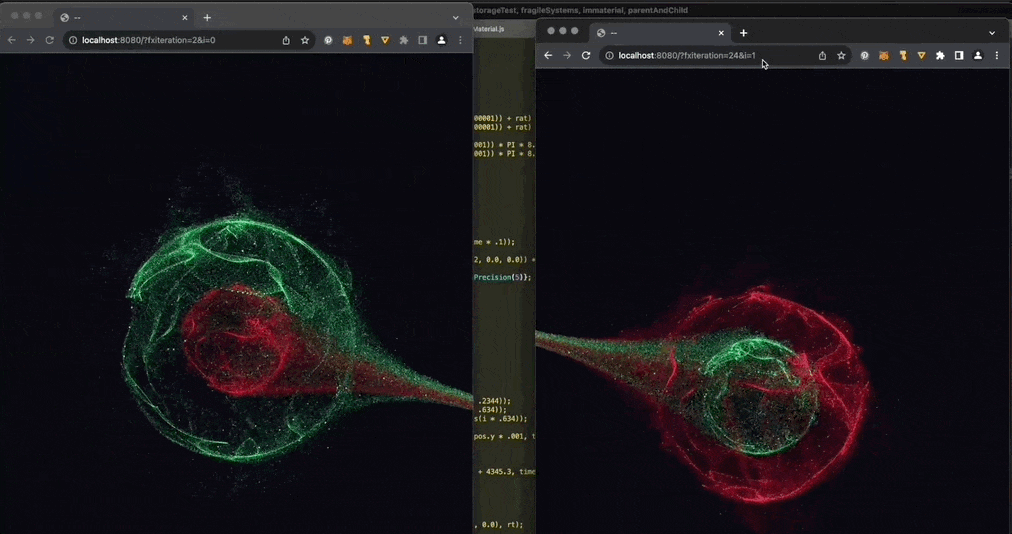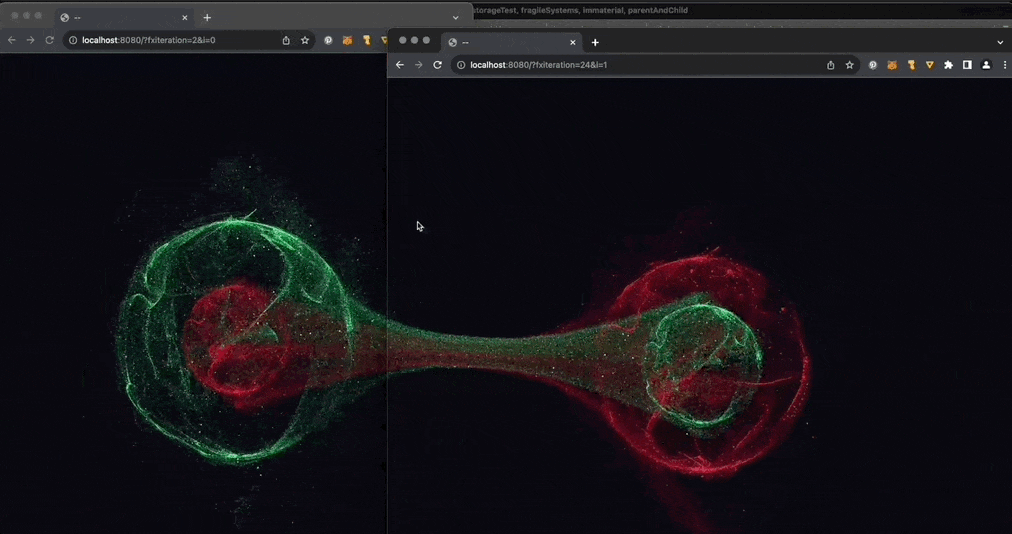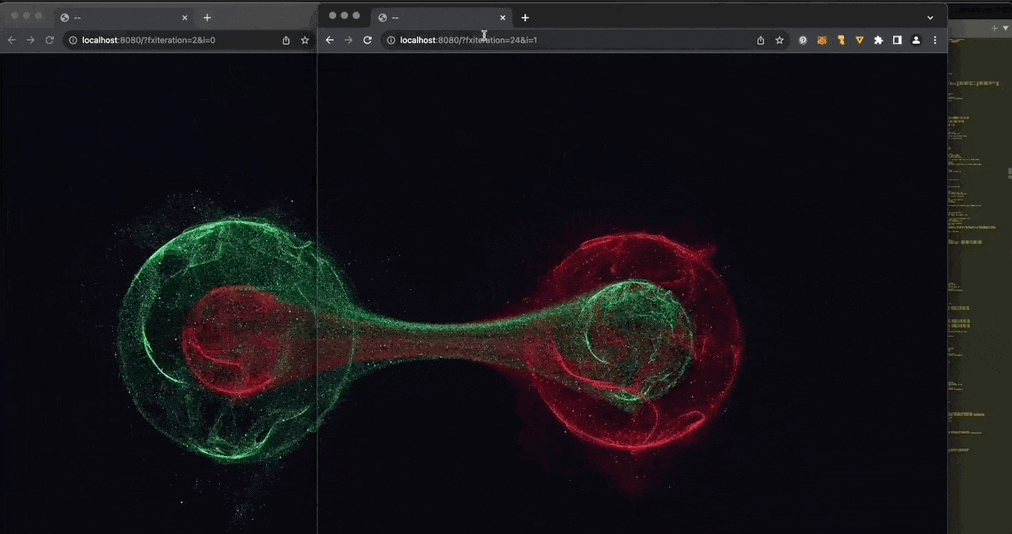
:炫酷的前端量子纠缠效果。量子纠缠是一种量子力学现象,即两个或多个量子不论相距多远都存在一种关联。该项目通过使用 Three.js 和 localStorage 跨多个浏览器窗口,展示了这一量子力学现象。来自
@YJLTF
的分享
15、
omnivore
:一款免费、多端的稍后阅读工具。该项目采用 TypeScript + Next.js 构建而成,支持保存文章、电子邮件、文档和同步 Obsidian 等个人知识管理系统的内容,以便日后阅读。而且还提供了 iOS、Android 客户端和浏览器插件,方便随时随地阅读。
16、
vue-naive-admin
:一款极简风格的 Vue 管理后台。这是一个开源、免费、可商用的后台管理模板,基于 Vue3、Vite4、Pinia、Unocss 和 Naive UI 等前端最新技术栈。它简洁、轻量、风格清新,上手成本低,适合中小型项目或者个人项目。来自
@Ronnie Zhang
的分享

Kotlin 项目
17、
Calendar
:适用于 Android 的高度可定制的日历库。这是一个用于开发 Android 日历应用的库,内含示例应用。提供了周或月模式显示、边界日期、水平或垂直滚动等功能,可以随心所欲地设计日历。
PHP 项目
18、
BookStack
:一个简单、开箱即用的 wiki 平台。该项目是基于 PHP 和 Laravel 的 wiki 平台,拥有搜索、Markdown 编辑器、绘图、多语言、身份验证等功能。

Python 项目
19、
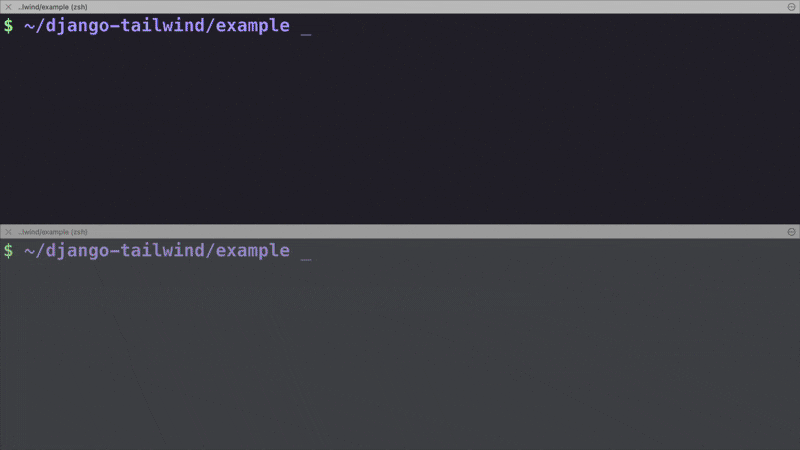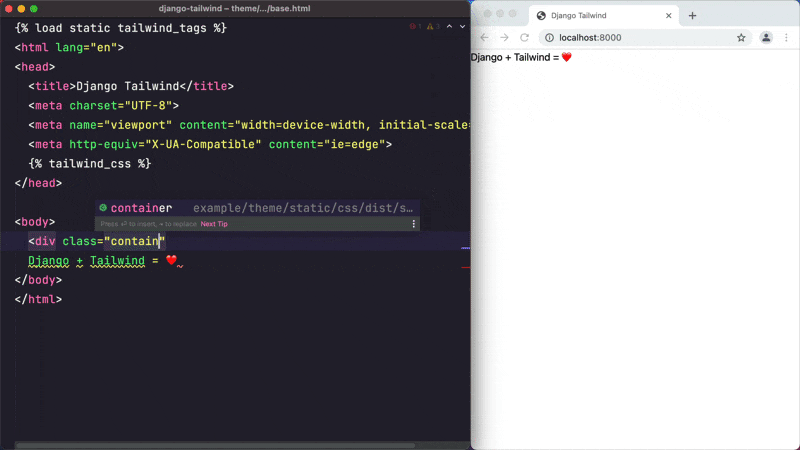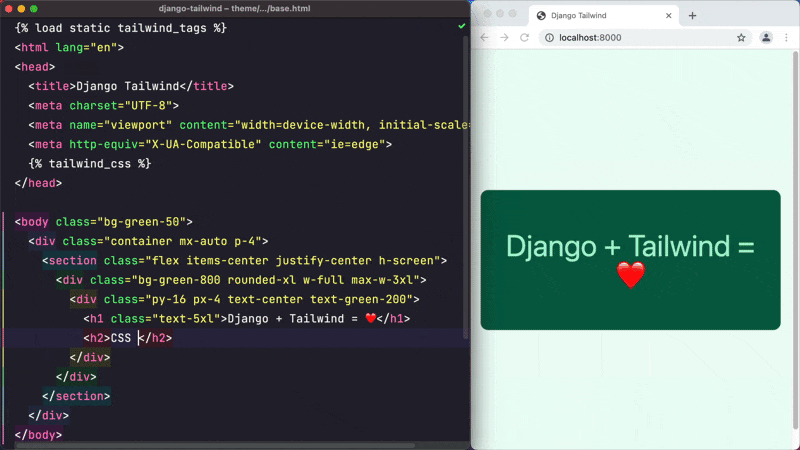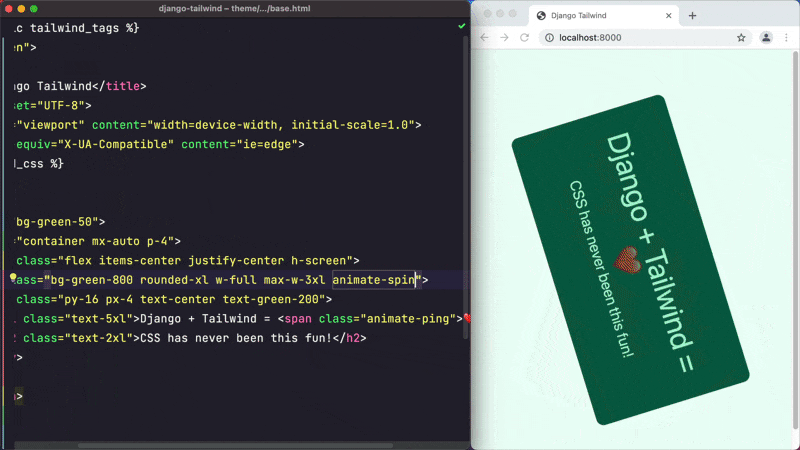
django-tailwind
:Django 集成 Tailwind CSS 的库。该项目可以让你在 Django 项目中轻松地使用 Tailwind CSS 框架,内含 Tailwind CSS 官方的排版、表单、line-clamp 等插件。
20、
frigate
:一款围绕实时 AI 对象检测构建的开源 NVR。该项目基于 OpenCV 和 Tensorflow 实现在本地为 IP Camera 提供实时目标检测和安全报警等功能,还支持根据设定的规则,保留检测到物体的视频。

21、
sqlglot
:一个非常全面的 SQL 解析器。该项目是用 Python 写的 SQL 解析器、转译器和优化器,它可以格式化 SQL 以及支持在 20 种不同方言和 SQL 之间进行转化,可用来自定义解析器、分析查询,用编程方式构建 SQL。
import sqlglot
# SQL 转 Spark
sql = """WITH baz AS (SELECT a, c FROM foo WHERE a = 1) SELECT f.a, b.b, baz.c, CAST("b"."a" AS REAL) d FROM foo f JOIN bar b ON f.a = b.a LEFT JOIN baz ON f.a = baz.a"""
print(transpile(sql, write="spark", identify=True, pretty=True)[0])
22、
tablib
:轻松处理表格数据集的 Python 库。该项目能够将不同格式的表格数据集,转化成统一的 Dataset 对象。它提供了动态列、标签、过滤等功能,支持 csv、df、json、yaml、xls 等格式的数据。
import tablib
data = tablib.Dataset(headers=['First Name', 'Last Name', 'Age'])
for i in [('Kenneth', 'Reitz', 22), ('Bessie', 'Monke', 21)]:
data.append(i)
# 将数据输出成 json 格式
print(data.export('json'))
# [{"Last Name": "Reitz", "First Name": "Kenneth", "Age": 22}, {"Last Name": "Monke", "First Name": "Bessie", "Age": 21}]
# df 对象
data.export('df')
# First Name Last Name Age
# 0 Kenneth Reitz 22
# 1 Bessie Monke 21
23、
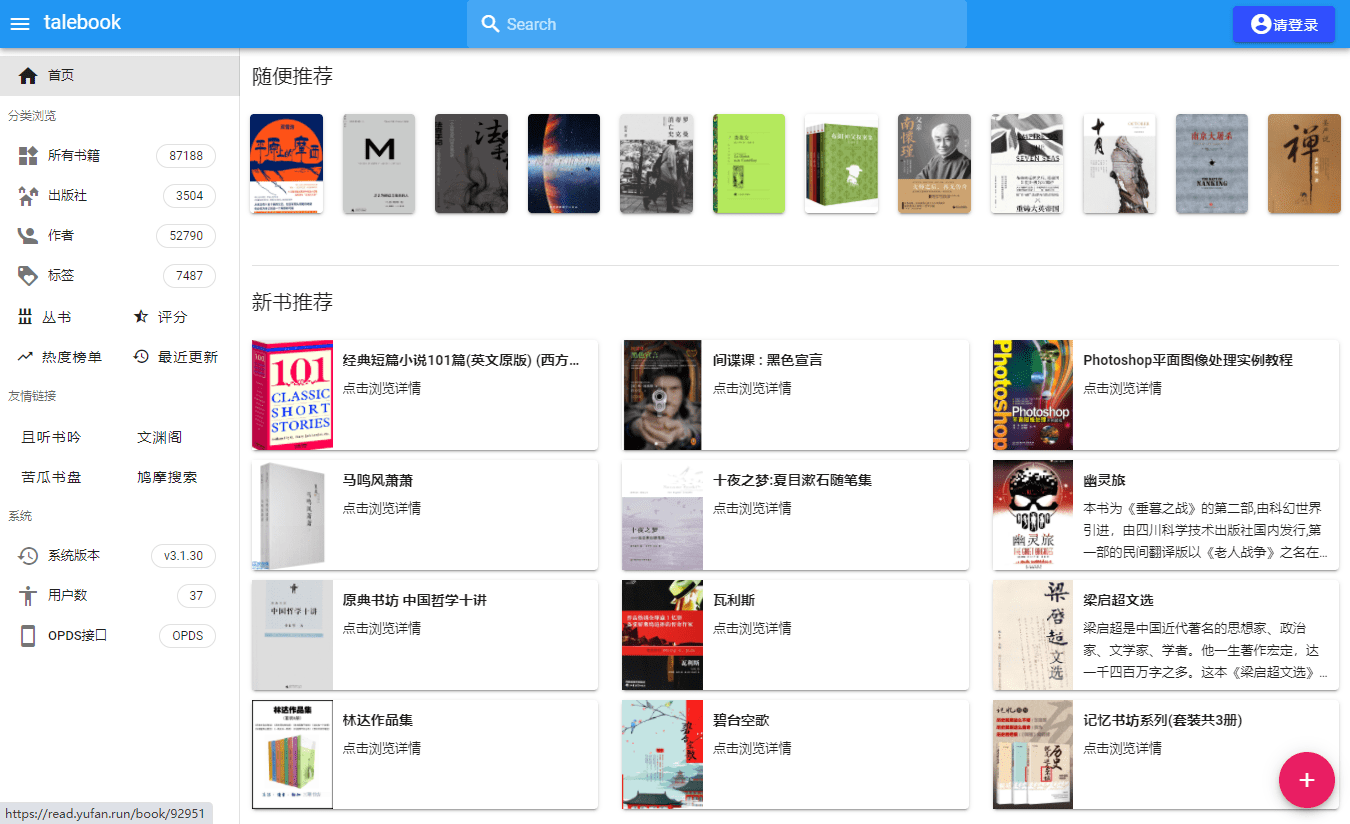
talebook
:一款简单好用的在线个人书库。该项目是基于 Calibre 的个人图书管理系统,后端是 Python 的 Tornado Web 框架,前端采用 Vue.js 构建。它不仅拥有美观的界面而且安装简单,支持在线阅读、导入书籍、推送到 Kindle、私人模式等功能。
Rust 项目
24、
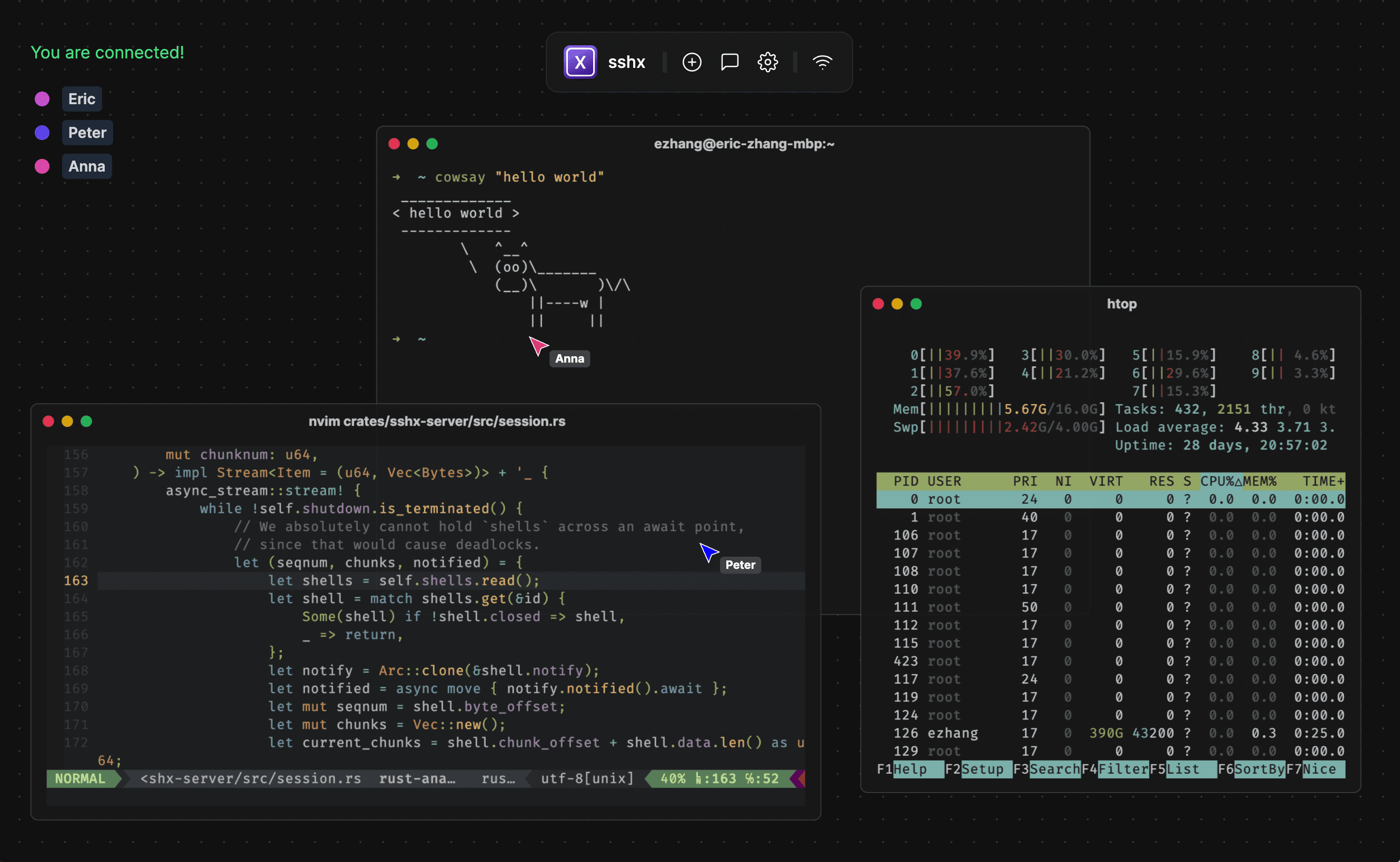
sshx
:基于 Web 的安全终端协作工具。该项目只需一条命令,即可与多人共享终端。支持实时多人协作、多窗口、远程光标、在线聊天、自动重连等功能,可用于教学和远程调试。来自
@猎隼丶止戈reNo7
的分享
25、
tailspin
:一款实用的日志高亮命令行工具。该项目是 Rust 写的命令行查看日志的工具,它无需配置开箱即用,通过高亮的形式,突出显示数字、日期、IP、URL 等内容,让重要的信息一目了然。
26、
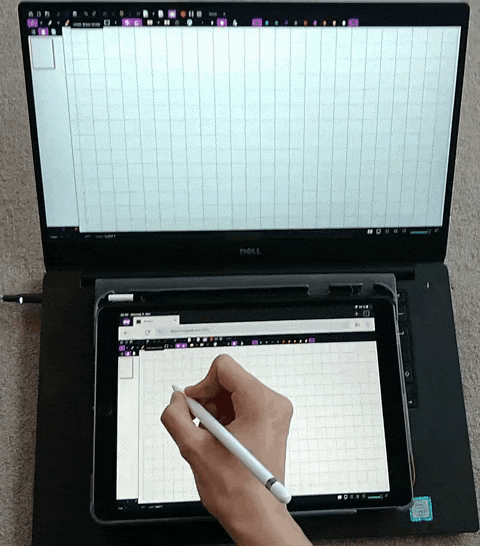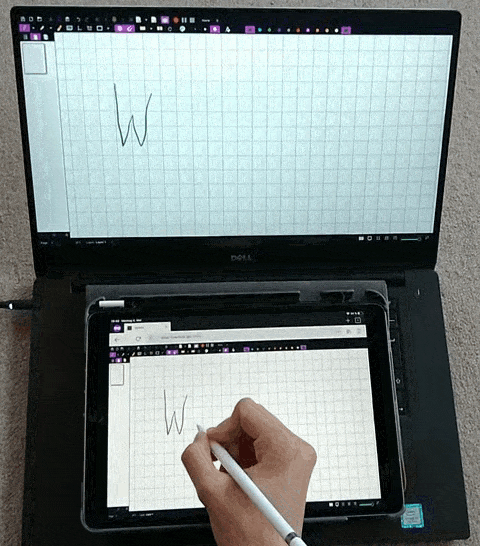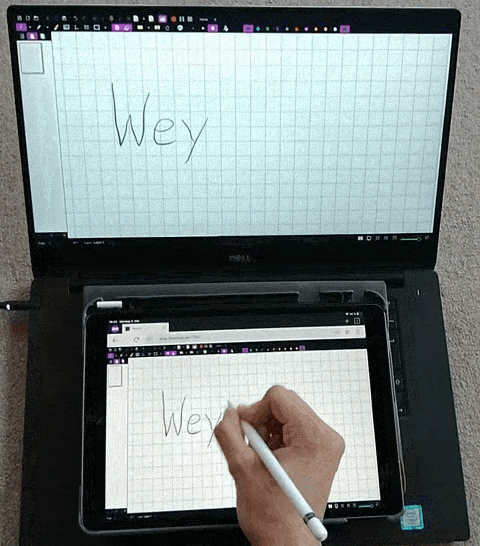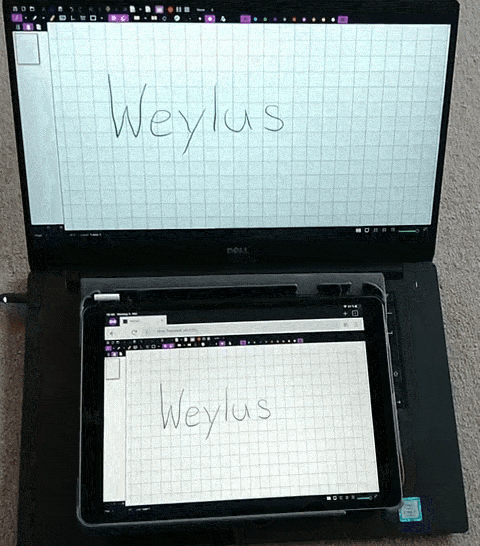
Weylus
:将平板用作计算机上的输入板/触摸屏。通过该项目可以将平板设备,作为电脑的外接屏幕、触控板、键盘,适用于 Windows、Linux 和 macOS 系统。
Swift 项目
27、
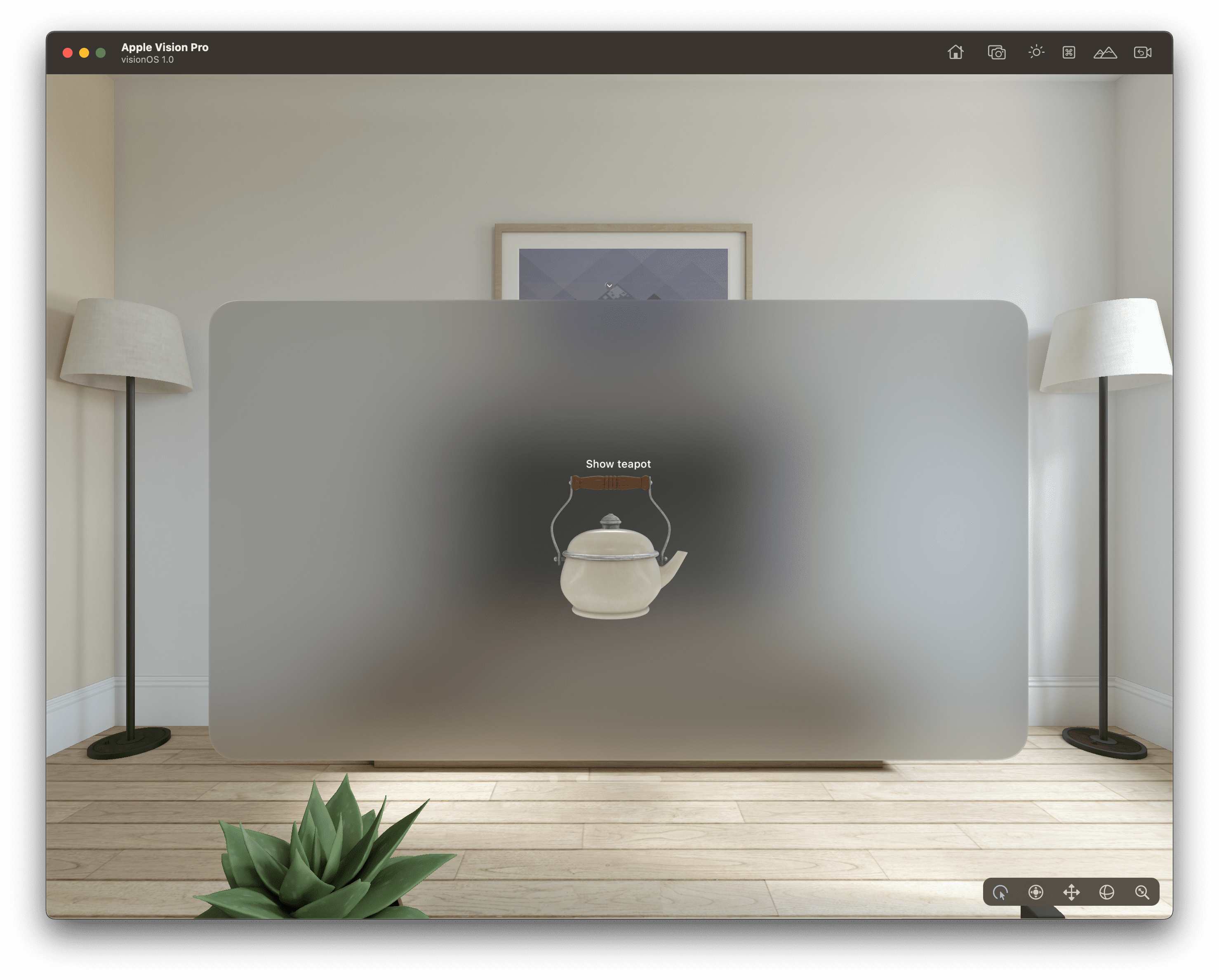
visionOS_30Days
:挑战 30 天上手苹果 visionOS 开发。visionOS 是运行在苹果的混合实境头戴式设备 Apple Vision Pro 上的操作系统,该项目提供了 30 个 visionOS 开发的示例代码。
其它
28、
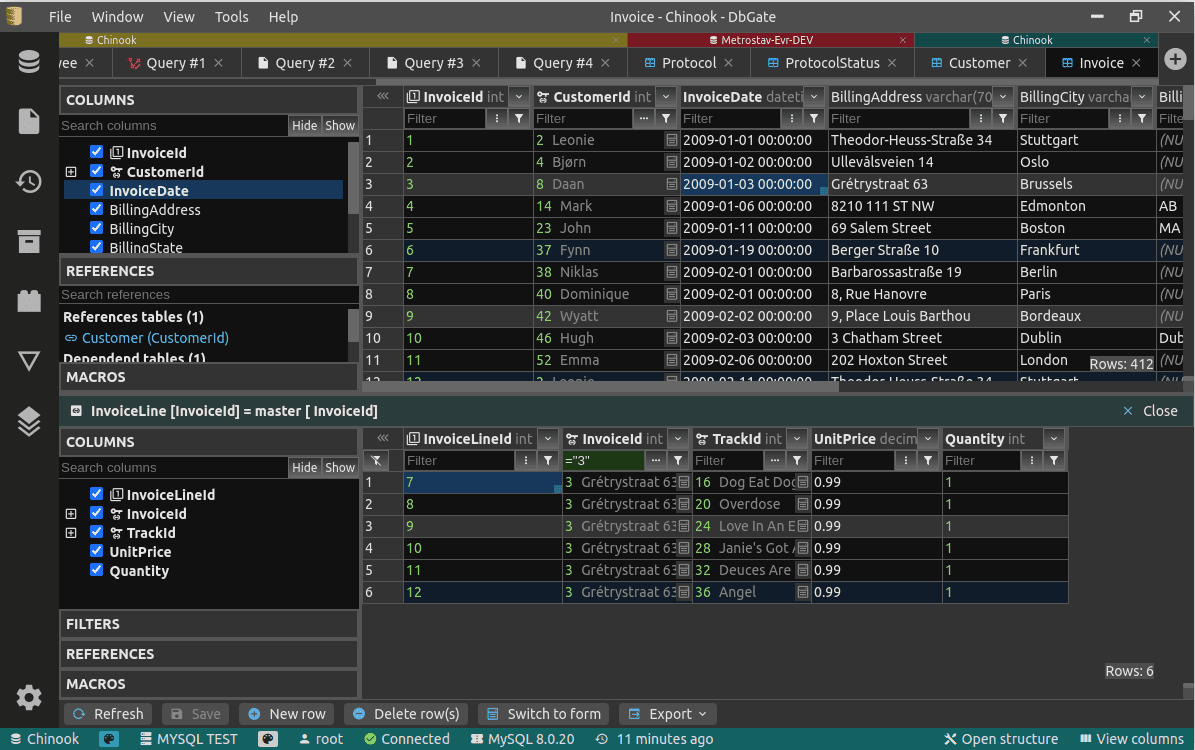
dbgate
:(no)SQL 数据库桌面管理工具。该项目支持包括 MySQL、PostgreSQL、SQL Server、MongoDB、SQLite、Redis 等多种数据库,适用于 Windows、Linux、macOS 系统。
29、
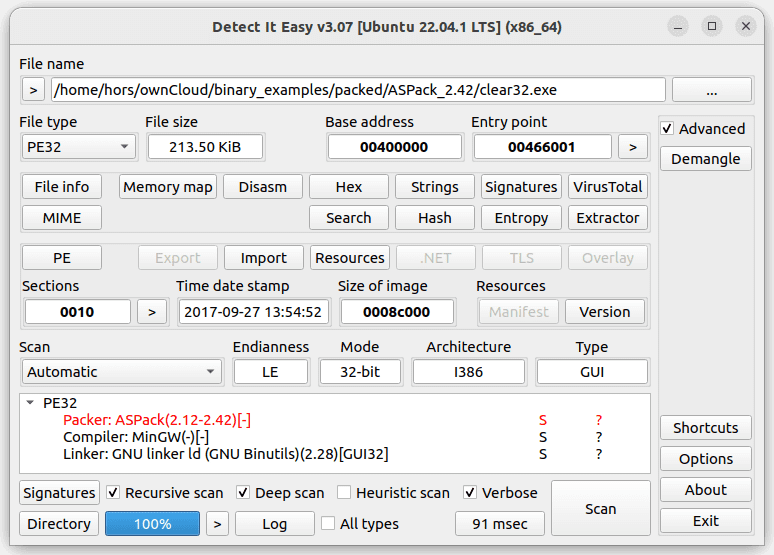
Detect-It-Easy
:用于查看文件类型的工具。该项目可以快速检测二进制文件的文件类型、体系结构和编译器信息,支持识别多种文件格式,有助于进行逆向工程和安全分析,适用于 Windows、Linux、macOS 系统。
30、
github-chinese
:GitHub 网站汉化插件。该项目可以将 GitHub 网站的菜单栏、标题、按钮等公共组件,自动翻译成中文,适合刚接触 GitHub 的小白使用。来自
@wuyuncheng-26
的分享
31、
HumanSystemOptimization
:人体系统调优不完全指南。这是一份帮助改善人体健康状态的指南,篇幅较长。尽量做到保持睡眠时长与质量、不要吸烟、每天做点运动、减少糖分的摄入,就能拥有不错的健康状态。
32、
wondershaper
:Linux 限制网络带宽的工具。该项目通过使用 iproute 的 tc 命令,实现了对 Linux 网络带宽限速的功能,支持多网卡、限制最大上传/下载速率。
开源书籍
33、
Node.js-Troubleshooting-Guide
:Node.js 应用故障排查手册。该手册主要是帮助 Node.js 开发者,应对开发和线上部署中遇到的问题,比如定位故障、压测和性能调优等。
34、
pml-book
:《概率机器学习》。该项目包含凯文·墨菲的三本书籍,分别为《机器学习:概率视角》、《概率机器学习:简介》、《概率机器学习:高级》,内容涵盖了基础理论和前沿研究,图文并茂并配有示例和练习。来自
@Xuefeng Xu
的分享
机器学习
35、
backgroundremover
:一条命令自动移除图像背景。该项目通过 AI 技术,可自动移除图片和视频中的背景。

36、
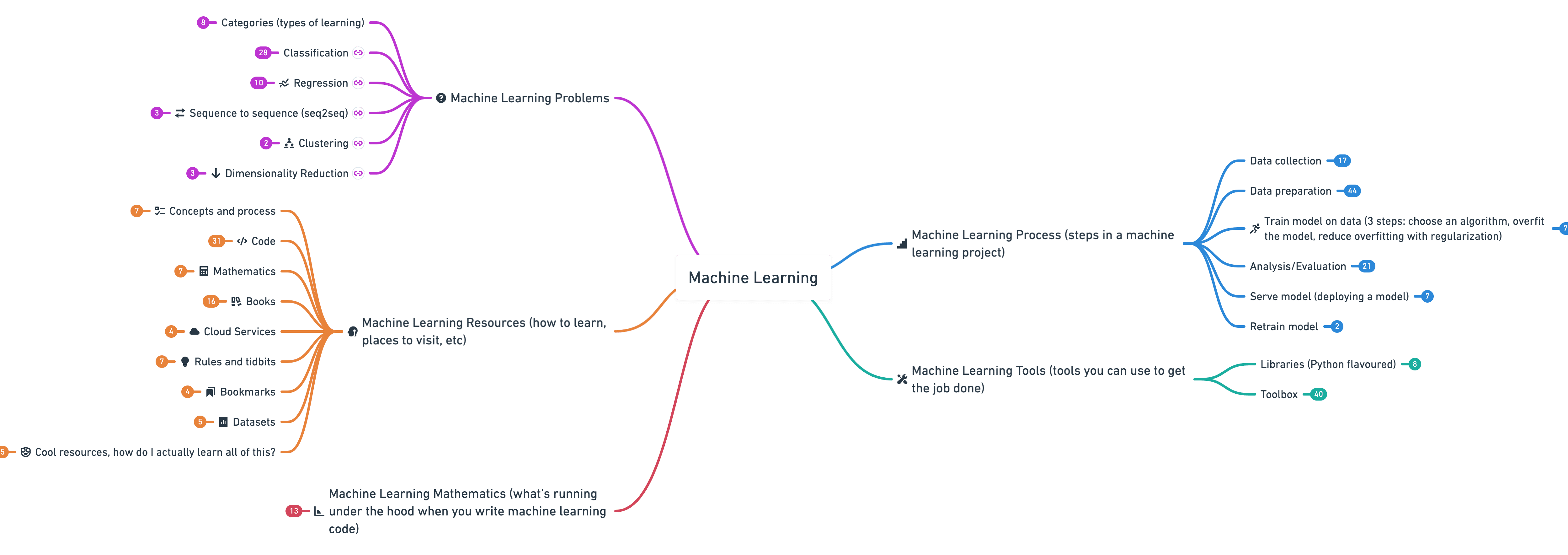
machine-learning-roadmap
:机器学习路线图。这份机器学习思维导图,包含了机器学习相关的问题、学习步骤、工具、底层数学知识、教程资源等,为如何学习机器学习指出方向。
37、
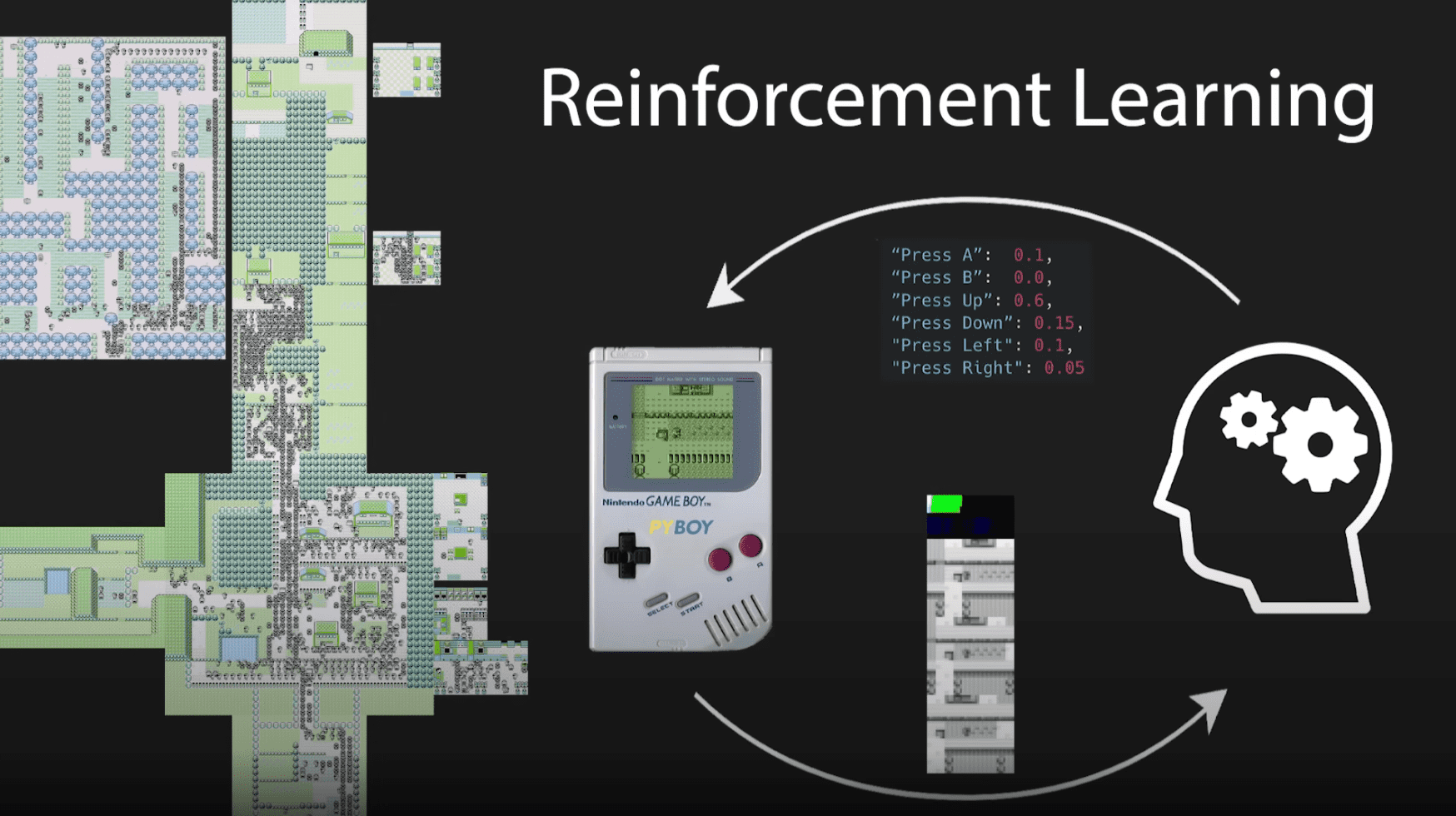
PokemonRedExperiments
:通过强化学习训练 AI 玩 Pokemon。该项目使用 Python + RL 从零训练了一个玩「宝可梦红」的 AI,同时作者还提供了配套的讲解视频,以及如何在本地运行和自定义训练的教程,快来上手试试吧!来自
@老荀
的分享
38、
supervision
:计算机视觉 AI 工具库。该项目简化了对象检测、分类、标注、跟踪等计算机视觉的开发流程。开发者仅需加载数据集和模型,就能轻松实现对图像和视频进行检测、统计某区域的被检测数量等操作。
import cv2
import supervision as sv
from ultralytics import YOLO
image = cv2.imread(...)
model = YOLO('yolov8s.pt')
result = model(image)[0]
detections = sv.Detections.from_ultralytics(result)
print(len(detections))
# 5
最后
感谢参与分享开源项目的小伙伴们,欢迎更多的开源爱好者来 HelloGitHub 自荐/推荐开源项目。如果你发现了 GitHub 上有趣的项目,就
点击这里
分享给大家伙吧!
本期有你感兴趣的开源项目吗?如果有的话就留言告诉我吧~如果还没看过瘾,可以
点击阅读
往期内容。
那么,下个月
28 号
不见不散,完结撒花
















