人脸识别技术演进:从几何算法到深度学习的深度剖析
本文全面探讨了人脸识别技术的发展历程、关键方法及其应用任务目标,深入分析了从几何特征到深度学习的技术演进。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

一、人脸识别技术的发展历程
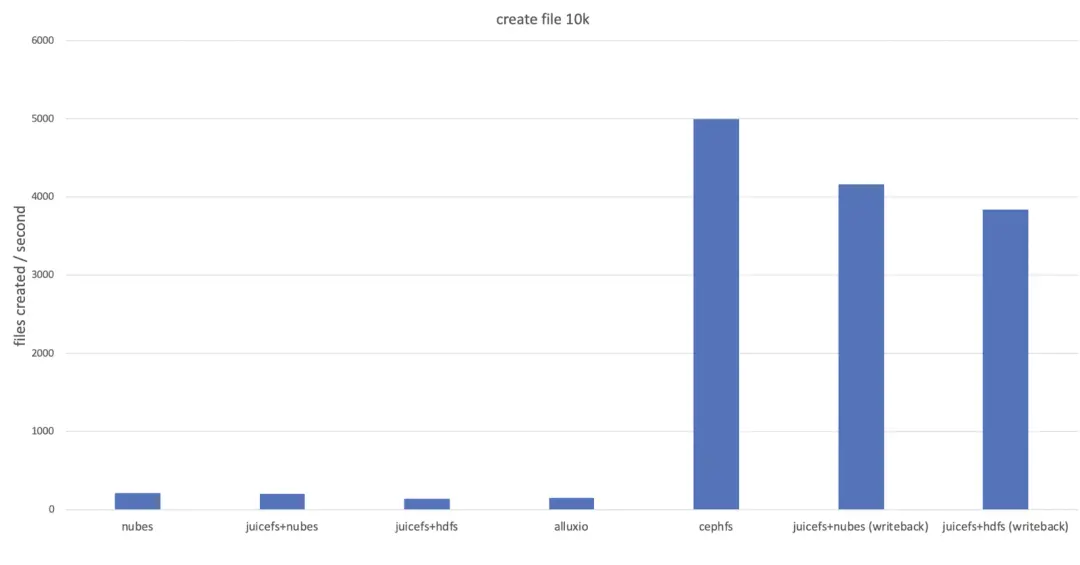
人脸识别技术作为一种生物识别技术,在过去几十年中经历了显著的发展。其发展可以分为几个主要阶段,每个阶段都对应着特定的技术进步和应用模式的变化。
早期探索:20世纪60至80年代
在这个阶段,人脸识别技术的研究还处于起步阶段。最初的方法侧重于几何特征的手动测量和比较,如眼睛、鼻子和嘴的相对位置。这些方法的精度受限于图像质量和手动测量的不准确性。
技术价值点:
- 几何特征方法
:标志着对人脸识别的第一步尝试,奠定了后续自动化和算法化发展的基础。
自动化与算法化:20世纪90年代
随着计算机视觉和图像处理技术的进步,人脸识别开始转向更自动化的方法。这一时期,特征匹配和模板匹配技术开始流行。例如,基于特征的识别方法(如Eigenfaces)通过提取和比较面部的主要特征,实现了更高的识别准确率。
技术价值点:
- Eigenfaces方法
:利用主成分分析(PCA),这是第一次使用统计方法对面部图像进行编码和识别。 - 模板匹配技术
:这为后续更复杂的人脸识别算法奠定了基础。
深度学习的革命:21世纪初至今
深度学习的兴起彻底改变了人脸识别领域。卷积神经网络(CNN)的应用大幅提高了识别的准确度和效率,尤其是在大规模人脸数据库中。现代人脸识别系统能够处理更复杂的变化,如不同的光照条件、表情变化和姿态变化。
技术价值点:
- 卷积神经网络(CNN)
:CNN能够自动学习和提取高层次的面部特征,大大提高了识别的准确性。 - 大数据和GPU加速
:海量数据的训练和GPU的加速计算为深度学习模型的训练提供了可能。 - 跨领域应用
:深度学习使得人脸识别技术在安全、金融、零售等多个领域得到应用。
二、几何特征方法详解与实战
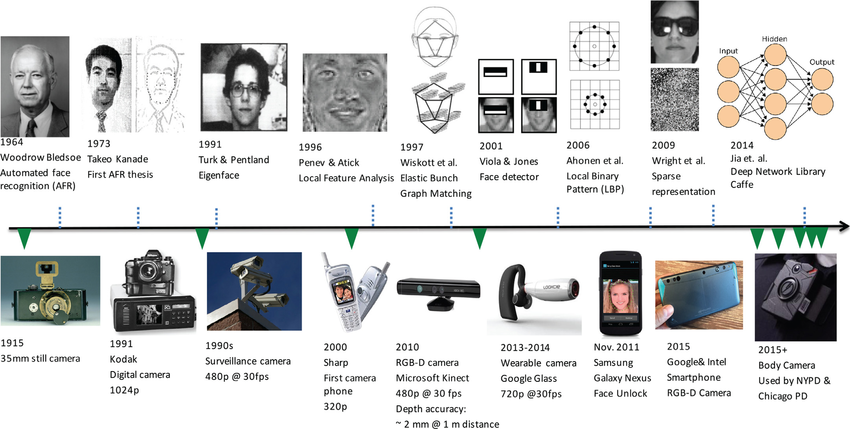
几何特征方法是人脸识别领域的一种传统技术。它依赖于面部的特定几何标记,如眼睛、鼻子和嘴的位置,以及这些标记之间的距离和角度。
几何特征方法的原理
这种方法的基本思想是,每个人的面部几何结构都是独特的。通过测量这些结构之间的相对位置和大小,可以生成一个独特的面部“指纹”。这种方法通常包括以下步骤:
- 面部检测
:首先确定图像中面部的位置。 - 特征点定位
:识别面部的关键特征点,如眼角、鼻尖、嘴角等。 - 特征提取
:计算这些特征点之间的距离和角度。 - 面部比对
:将提取的特征与数据库中的特征进行比对,以识别个体。
几何特征方法的局限性
尽管这种方法在早期人脸识别系统中被广泛使用,但它有一些局限性:
- 对图像质量敏感
:几何特征方法对图像的大小、分辨率和光照条件非常敏感。 - 缺乏灵活性
:它难以处理面部表情变化、姿态变化或部分遮挡的情况。 - 手动特征点标定的挑战
:早期的方法需要手动标记特征点,这既费时又不精确。
实战案例:简单的几何特征人脸识别
为了展示几何特征方法的基本原理,我们将使用Python编写一个简单的人脸识别脚本。
环境配置
首先,需要安装必要的库,例如
OpenCV
,它是一个开源的计算机视觉和机器学习软件库。
!pip install opencv-python
代码实现
import cv2
import math
# 加载面部和眼睛检测器
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_eye.xml')
def calculate_distance(p1, p2):
"""计算两点之间的距离"""
return math.sqrt((p1[0] - p2[0])**2 + (p1[1] - p2[1])**2)
def geometric_features(image_path):
"""处理图像并提取几何特征"""
# 读取图像
img = cv2.imread(image_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 检测面部
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
roi_gray = gray[y:y+h, x:x+w]
# 检测眼睛
eyes = eye_cascade.detectMultiScale(roi_gray)
if len(eyes) >= 2:
# 选取两个主要的眼睛
eye1 = (eyes[0][0], eyes[0][1])
eye2 = (eyes[1][0], eyes[1][1])
# 计算眼睛间距
eye_distance = calculate_distance(eye1, eye2)
return eye_distance
return None
# 示例:处理图像并提取几何特征
eye_distance = geometric_features('path_to_image.jpg')
print(f"Eye Distance: {eye_distance}")
代码说明
在这个简单的例子中,我们使用OpenCV库来检测面部和眼睛。然后,我们计算两只眼睛之间的距离作为一个基本的几何特征。尽管这个例子相对简单,但它展示了几何特征方法的基本思路。
三、自动化与算法化详解与实战
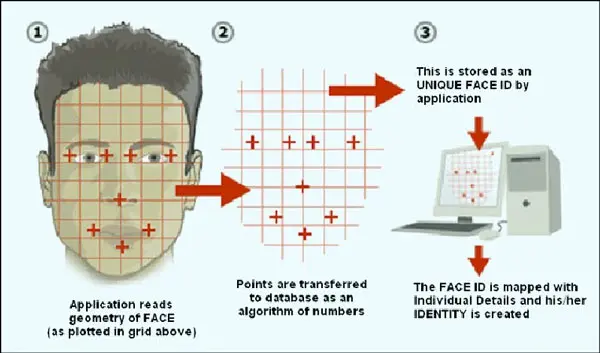
自动化与算法化标志着人脸识别技术的一个重要转折点。在这个阶段,人工干预逐渐减少,计算机视觉和模式识别算法开始在人脸识别过程中扮演核心角色。
自动化与算法化的进展
这一阶段的主要进展体现在以下几个方面:
- 特征自动提取
:通过算法自动识别和提取面部特征,减少了对人工干预的依赖。 - 模板匹配技术
:使用一系列标准化的面部模板来识别个体。 - 特征融合方法
:结合多种类型的特征,如几何特征、纹理特征等,以提高识别的准确性和鲁棒性。
技术创新点:
- 特征自动提取
:引入更先进的图像处理技术,如边缘检测、纹理分析等。 - 模板匹配
:这种方法简化了识别过程,适用于较小规模的人脸识别应用。
实战案例:基于特征匹配的人脸识别
在本实战案例中,我们将使用Python和OpenCV库来实现一个基于特征匹配的简单人脸识别系统。
环境配置
首先,需要安装必要的库,例如
OpenCV
。
!pip install opencv-python
代码实现
import cv2
import numpy as np
# 加载人脸检测器
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
def feature_matching(image_path, template_path):
"""使用特征匹配进行人脸识别"""
# 读取图像和模板
img = cv2.imread(image_path)
template = cv2.imread(template_path, 0)
w, h = template.shape[::-1]
# 转换为灰度图
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 人脸检测
faces = face_cascade.detectMultiScale(gray_img, 1.1, 5)
for (x, y, w, h) in faces:
roi_gray = gray_img[y:y+h, x:x+w]
# 模板匹配
res = cv2.matchTemplate(roi_gray, template, cv2.TM_CCOEFF_NORMED)
threshold = 0.8
loc = np.where(res >= threshold)
for pt in zip(*loc[::-1]):
cv2.rectangle(img, pt, (pt[0] + w, pt[1] + h), (0, 255, 0), 2)
cv2.imshow('Detected Faces', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 示例:使用特征匹配进行人脸识别
feature_matching('path_to_image.jpg', 'path_to_template.jpg')
代码说明
这个脚本首先读取一张图片和一个人脸模板。然后,使用OpenCV的模板匹配功能在图片中查找与模板相似的区域。如果找到匹配度高的区域,脚本将在这些区域周围绘制矩形框。
四、深度学习方法
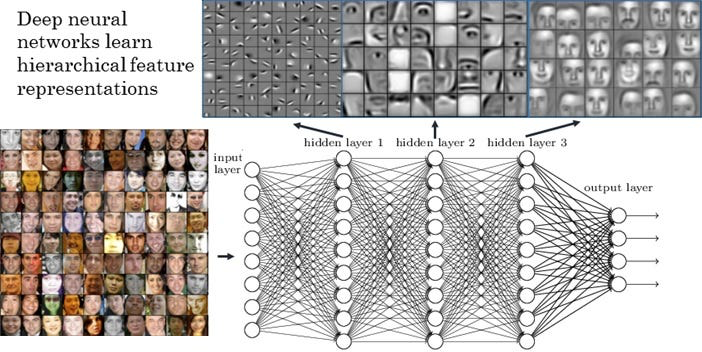
深度学习方法在人脸识别领域引起了一场革命。通过利用大数据和强大的计算能力,深度学习算法能够学习复杂的面部模式,大幅提升识别的准确性和效率。
深度学习方法的核心概念
- 卷积神经网络(CNN)
:CNN是深度学习中最常用于图像识别的模型之一。它通过多个卷积层自动提取图像的特征。 - 数据和训练
:深度学习模型需要大量的数据进行训练。数据的质量和多样性对模型的性能有重要影响。 - 优化和调整
:模型的结构和训练过程需要细致地调整,以提高准确率和处理复杂场景的能力。
技术创新点
- 自动特征提取
:深度学习模型能够自动学习面部的复杂特征,无需手动设计。 - 大规模数据处理
:深度学习能够有效处理和学习海量的图像数据。
实战案例:使用深度学习进行人脸识别
在这个实战案例中,我们将使用Python和PyTorch框架来实现一个基于深度学习的人脸识别系统。
环境配置
首先,需要安装必要的库,包括
PyTorch
和
OpenCV
。
!pip install torch torchvision
!pip install opencv-python
代码实现
import torch
import torchvision
import cv2
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
# 定义一个简单的CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=5)
self.conv2 = nn.Conv2d(32, 64, kernel_size=5)
self.fc1 = nn.Linear(1024, 128)
self.fc2 = nn.Linear(128, 2) # 假设有两个类别
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2(x), 2))
x = x.view(x.size(0), -1) # 展平
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 加载模型
model = SimpleCNN()
model.load_state_dict(torch.load('model.pth'))
model.eval()
# 图像预处理
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Grayscale(),
transforms.Resize((32, 32)),
transforms.ToTensor(),
])
def predict_face(image_path):
"""预测图像中的人脸"""
img = cv2.imread(image_path)
img = transform(img)
img = img.unsqueeze(0) # 增加一个批次维度
with torch.no_grad():
outputs = model(img)
_, predicted = torch.max(outputs, 1)
return predicted.item()
# 示例:预测图像中的人脸
result = predict_face('path_to_face_image.jpg')
print(f"Predicted class: {result}")
代码说明
在这个例子中,我们定义了一个简单的卷积神经网络模型,并加载了预先训练好的模型权重。图像通过一系列的预处理操作,然后被输入到模型中进行预测。这个简单的案例展示了如何使用深度学习进行基本的人脸识别。
总结
人脸识别技术的发展历程展示了技术创新的连续性和累积性。从最初的几何特征方法到现代的深度学习方法,每一步技术进步都是建立在前人基础之上的。这种连续的技术进化不仅推动了识别准确率的提高,也促进了人脸识别在更广泛领域的应用。
深度学习时代的到来凸显了大数据在人脸识别技术中的重要性。数据的质量、多样性和规模直接影响到模型的性能。未来,如何有效收集、处理和利用数据,将是技术发展的关键。
随着技术的发展和应用领域的拓展,隐私和伦理问题日益凸显。如何在提升技术性能的同时保护用户隐私,是人脸识别技术未来发展需要着重考虑的问题。未来的技术创新将不仅仅聚焦于提高算法的性能,也将包括如何设计符合伦理标准和隐私保护的应用系统。
未来人脸识别技术可能会与其他技术领域,如人工智能的其他分支、物联网、移动计算等领域进行更深层次的融合。这种跨领域的融合不仅能够提高识别技术的准确性和适用性,也能够创造出全新的应用场景和业务模式。
总的来说,人脸识别技术的未来发展将是一个多维度、跨学科的过程。这一过程不仅涉及技术层面的创新,也包括对社会、法律和伦理方面问题的深入思考。随着技术的不断成熟和社会对隐私权益的日益重视,人脸识别技术的健康和可持续发展将更加受到重视。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
如有帮助,请多关注
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。