1.概述
人工智能(AI)的能力持续在全球范围内引起轰动,并对我们日常生活和职业生涯带来重大变革。随着像ChatGPT这样的先进生成型AI模型以及从GPT-3到GPT-4的加速,我们在高级推理、理解更长上下文和输入设置方面看到了重大改进。像ChatGPT这样的工具要求用户编写Prompt,以获得所需的输出。然而,一种更先进且更强大的AI工具已经进入游戏,只需用户解释需要的目标,之后工具会为您完成一切。本篇博客笔者将给大家介绍AutoGPT的一些使用实战心得。
2.内容
开发人员现在正在研究自主AI代理,这是对人工通用智能(AGI)的初步展望,这是一种能够通过其自身的过程、智力和推理执行人类水平智力任务的AI类型。
2.1 什么是AutoGPT
Auto-GPT的强大文本生成能力使其在用户中迅速赢得口碑。相比于之前的版本,GPT-4在高级推理、对更长上下文的理解以及输入设置方面都实现了显著的改进。这使得Auto-GPT成为撰写文章、创作故事,甚至解决复杂问题的理想选择。
更令人印象深刻的是,Auto-GPT相较于传统的ChatGPT等工具更为智能化。不再需要繁琐的提示草稿,只需简单解释您的目标,Auto-GPT即可为您完成所有繁重的工作。这标志着人工智能领域向着实现人工通用智能(AGI)迈出了更为重要的一步。
2.2 AutoGPT如何工作
Auto-GPT基于自主AI机制工作,将任务分解为多个子任务,并创建不同的AI代理来满足和完成这些任务。
这些人工智能代理包括:
- 任务创建代理
:当您向 Auto-GPT 提供目标时,第一个与您交互以启动处理任务的过程的代理是任务创建代理。该代理根据您的最终目标创建任务列表以及实现这些目标的步骤,并将其发送给优先级代理。
- 任务优先级代理
:一旦优先级代理收到任务列表,它会确保其正确的顺序具有逻辑意义并将其发送到执行代理。
- 任务执行代理
:一旦设置了子任务优先级,执行代理就开始一一完成这些任务,利用互联网、GPT-4 和完成任务所需的其他工具。
如果任务未完成,这三个代理还会相互通信。
例如,一旦执行代理完成了步骤,但结果不符合预期,它就会与任务创建代理进行通信,任务创建代理可以创建一个新的任务列表来满足最终目标。此过程在所有三个代理之间创建交互循环,直到它们可以生成用户定义的输出。
当这些人工智能代理执行任务时,他们的操作会显示在用户界面上,分为四个类别,即:
- 想法:人工智能代理在完成每项任务后分享他们的想法。
- 推理:人工智能代理解释其行为背后的推理,回答执行每个步骤背后的原因。
- 计划:系统然后提供完成给定任务的战略计划。
- 批评:然后系统会提供批评,允许人工智能代理克服错误并纠正错误(如果有)。
因此,这种计算流程使 Auto-GPT 能够深入了解解决特定问题的步骤并纠正错误,而无需人工干预。
2.3 安装AutoGPT的依赖环境
以下是在计算机上安装Auto-GPT的关键要求:
➡️ 适用计算机:
您不需要一台先进或功能强大的计算机,但一台具备基本性能的计算机即可安装Auto-GPT,因为大多数繁重的工作由云上的OpenAI API执行。
➡️ Python版本:
安装Auto-GPT需要Python 3.8或更高版本。
➡️ GPT-4 API访问:
为了获得更出色的性能、推理能力,并降低生成虚假信息的风险,您需要访问GPT-4 API。
➡️ Git:
安装过程中需要Git,确保已安装并配置。
➡️ Visual Studio Code:
推荐使用Visual Studio Code作为集成开发环境,以便更便捷地进行代码编辑和管理。
➡️ OpenAI API密钥:
为了使用Auto-GPT,您需要获得OpenAI API密钥。确保您的密钥有效并按照安装过程中的指导进行正确配置。
这些要求将确保您能够顺利安装和使用Auto-GPT,充分发挥其强大的文本生成能力。
2.4 如何安装AutoGPT
与ChatGPT等只需简单登录即可访问和使用的工具不同,使用Auto-GPT需要进行本地设备上的多个软件安装,以满足其运行的要求。
因此,如果您希望充分利用Auto-GPT的功能,请按照以下步骤在本地设备上安装该工具。
2.4.1 安装必备软件
Auto-GPT的安装涉及到三个主要软件:Python、Git和Visual Studio Code。
2.4.2 下载AutoGPT源代码
前往最新的
GitHub Auto-GPT 发布页面
,向下滚动并单击“源代码 (zip)”链接以下载 zip 文件。
现在解压缩此 zip 文件并复制 Auto-GPT 文件夹,将其粘贴到您所需的位置或硬盘驱动器上。 同时,您可以从 GitHub Auto-GPT 发布页面复制项目的链接。为此,请单击窗口左侧的“代码” ,然后再次单击绿色的“代码”按钮。然后,复制屏幕上提示的 HTTPS URL。
2.4.3 安装Python
打开 Visual Code Studio 并在 VCS 编辑器中打开 Auto-GPT 文件。单击“打开文件夹”链接并在编辑器中打开 Auto-GPT 文件夹。

为了尽可能轻松地使用存储库提供的所有工具,存储库的根目录中包含一个 CLI:
$ ./run
Usage: cli.py [OPTIONS] COMMAND [ARGS]...
Options:--help Show this message andexit.
Commands:
agent Commands to create, startandstop agents
arena Commands to enter the arena
benchmark Commands to start the benchmarkand list tests andcategories
setup Installs dependencies neededfor your system.
只需克隆存储库,使用 安装依赖项./run setup,就可以开始了!
2.4.4 重命名配置文件
当您在 VCS 编辑器中向上滚动文件列表时,您将看到 .env.template 文件。右键单击该文件,然后单击“重命名”选项。通过删除“.template”来重命名该文件。
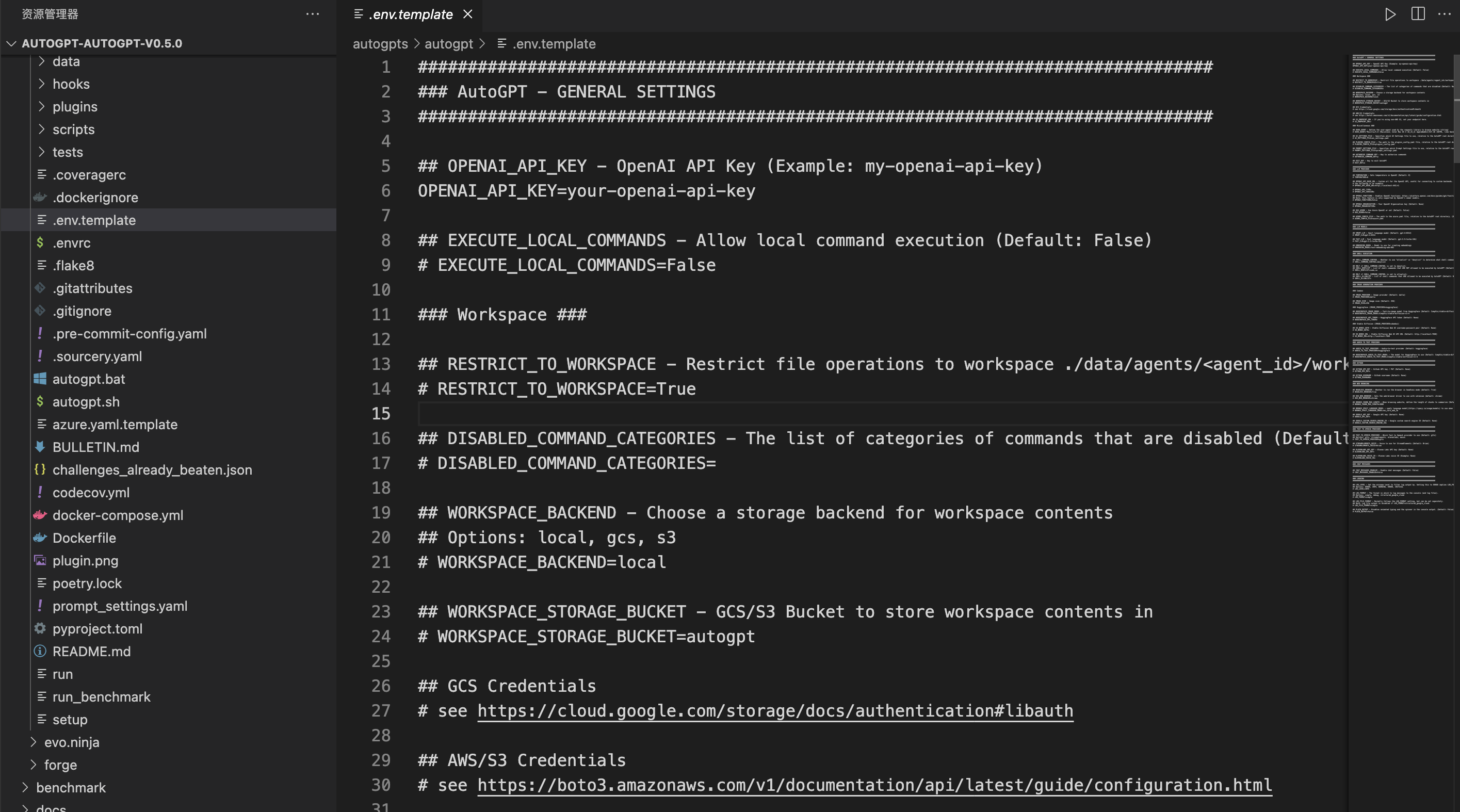
最后,配置好OPENAI_API_KEY就可以启动AutoGPT了。
3.AutoGPT与ChatGPT
尽管ChatGPT和Auto-GPT都是由OpenAI训练的大型语言模型(LLM),但它们在服务不同目的的同时也存在一些区别。这两种工具分别在不同的数据集上训练,并针对执行不同任务进行了优化。
以下是Auto-GPT与ChatGPT的几个区别:
1.训练数据
ChatGPT 主要基于从网络、社交媒体帖子、书籍、博客和文章检索的大量文本进行训练。因此,它在理解人类语言方面更有能力、更通用。
另一方面,Auto-GPT 是在来自 StackOverflow、GitHub 和类似代码存储库的大量代码集合上进行训练的。该训练数据集使 Auto-GPT 专门用于理解编程语言、结构和语法。
因此,由于 Auto-GPT 对特定代码的编写方式有更深入的了解,因此它可以生成准确且高效的代码,从而加快组织的代码开发过程并降低软件错误的风险。
2.实时洞察
ChatGPT 最新的 GPT-4 模型是在相同的 GPT-3.5 数据上训练的;然而,它只到2021年9月。因此,ChatGPT无法提供最新信息和实时见解,因为它不允许您访问在线平台或网站来提取信息。
相反,Auto-GPT提供访问互联网、联网搜索、验证数据源是否合法的功能。此外,Auto-GPT 可以访问任何网站或在线平台来执行给定任务。例如,根据您向 Auto-GPT 提供的目标,它可以进入星巴克网站并订购您的饮料,还可以根据指示起草电子邮件并将其发送给潜在客户。
3.文字转语音
Auto-GPT 允许您通过在命令行中键入命令python -m autogpt -speak来启用文本转语音。但是,每次您希望通过语音与 Auto-GPT 交互时,它都要求您输入此命令。
4.图像生成
与 ChatGPT 等 AI 模型不同,Auto-GPT 可以生成图像,因为该工具使用 DALL-E。您必须提供对 DALL-E 的 API 访问权限,才能为您的 AI 代理启用图像生成功能。
5.优化
OpenAI 优化了 ChatGPT,以实现生成类似人类的文本输出的连贯性和自然性,而 Auto-GPT 则针对代码生成的速度和准确性进行了优化,从而减少了时间以及软件中的错误和漏洞。
6.应用领域
您可以使用 Auto-GPT 执行代码优化、自动代码完成和代码摘要等任务。另一方面,ChatGPT 广泛用于完成文本生成、语言翻译和聊天机器人等任务。因此,ChatGPT 的应用程序专注于提高机器与人类之间的效率和通信,而 Auto-GPT 的应用程序专注于提高代码开发过程的准确性和效率。
4.自动 GPT 的优点
Auto-GPT 是一种以最少的人力输入生成高质量输出的工具,与传统人工智能聊天机器人相比,具有多种优势,包括:
- 无缝定制:您可以根据您的特定业务或行业需求轻松定制 Auto-GPT。开发人员可以轻松修改源代码以改进现有功能,或将新功能添加到相关的产品内容中,并根据目标受众和项目的需求进行定制。
- 自主性: Auto-GPT 的自主性是其最独特的功能之一,使其与其他传统人工智能机器人区分开来。由于它可以自行识别完成目标所需的提示以提供高质量的输出,因此 Auto-GPT 成为高度可靠且高效的人工智能工具。
- 速度: Auto-GPT 可以轻松分析大量数据并比人类更快地生成准确的结果。
- 灵活性: Auto-GPT可以学习新技能并执行广泛的任务;因此,它不仅仅局限于特定的任务或领域,使其成为一个高度通用的工具。
- 一致性: Auto-GPT 可以在多个内容片段中保持风格、语气和语音的一致性。此功能使 Auto-GPT 成为企业和机构定期生成大量内容的出色工具。
5.总结
Auto-GPT是一种多功能的创新工具,极大地改变了我们与人工智能模型的互动方式。其引入了多样化的用例,使我们能够以更迅速的速度执行任务,并且具备更高的准确性和效率。
这一特性使得Auto-GPT在希望生成准确、迅速代码的人工智能爱好者和代码开发人员中成为理想的工具。其优越的文本生成能力不仅简化了创作过程,还提高了任务执行的效率,为用户提供了一种更智能、更便捷的体验。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。















