uni-app+vue3+ts项目搭建完整流程
项目代码同步更新至码云
uni-vue3-ts-template
开发前准备
利用
uni-app
开发,有两种方法:
- 通过
HBuilderX
创建(需安装
HBuilderX
编辑器) - 通过命令行创建(需安装
NodeJS
环境),推荐使用
vscode
编辑器
这里我们使用第2种方法,这两种方法官方都有详细介绍
点击查看官方文档
vscode
安装插件
- 安装 Vue3 插件,
点击查看官方文档
- 安装
Vue Language Features (Volar)
:Vue3 语法提示插件 - 安装
TypeScript Vue Plugin (Volar)
:Vue3+TS 插件 - 工作区禁用
Vue2 的 Vetur 插件(Vue3 插件和 Vue2 冲突) - 工作区禁用
@builtin typescript 插件(禁用后开启 Vue3 的 TS 托管模式)
- 安装 uni-app 开发插件
uni-create-view
:快速创建 uni-app 页面uni-helper
(插件套装,安装一个后会有多个插件) :代码提示uniapp小程序扩展
:鼠标悬停查文档
uni-create-view
插件使用
uni-create-view
安装后,需要修改配置,进入
文件
->
首选项
->
设置
,按以下选项修改即可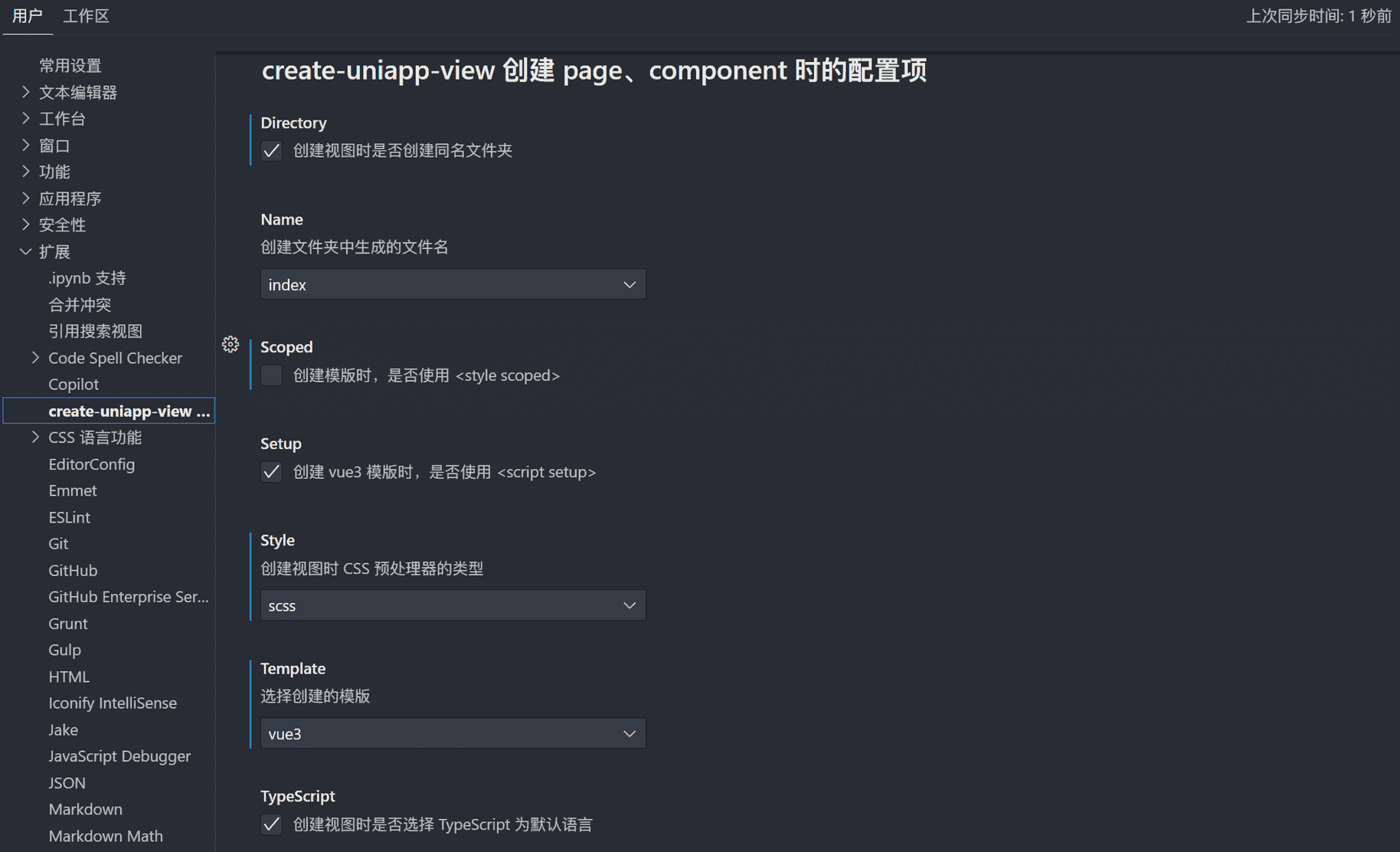
uni-create-view
使用方法:
在
src/pages
下右键,选择
新建uni-app页面
,弹出输入框,输入
文件夹名称 页面名称
,然后回车
生成如下目录文件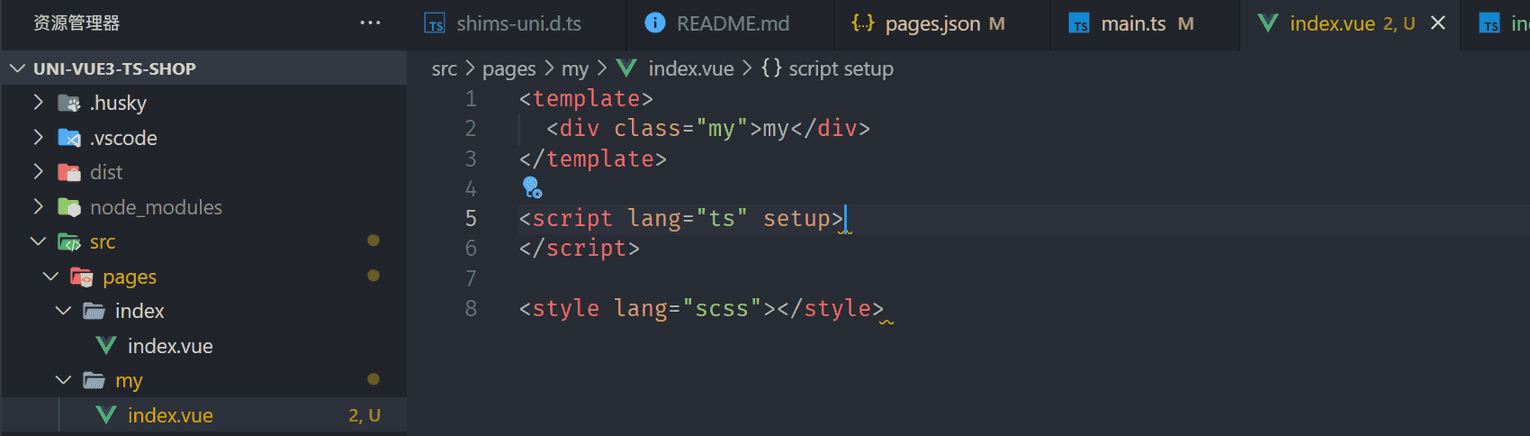
并且在
src/pages.json
目录下,已将新界面配置进去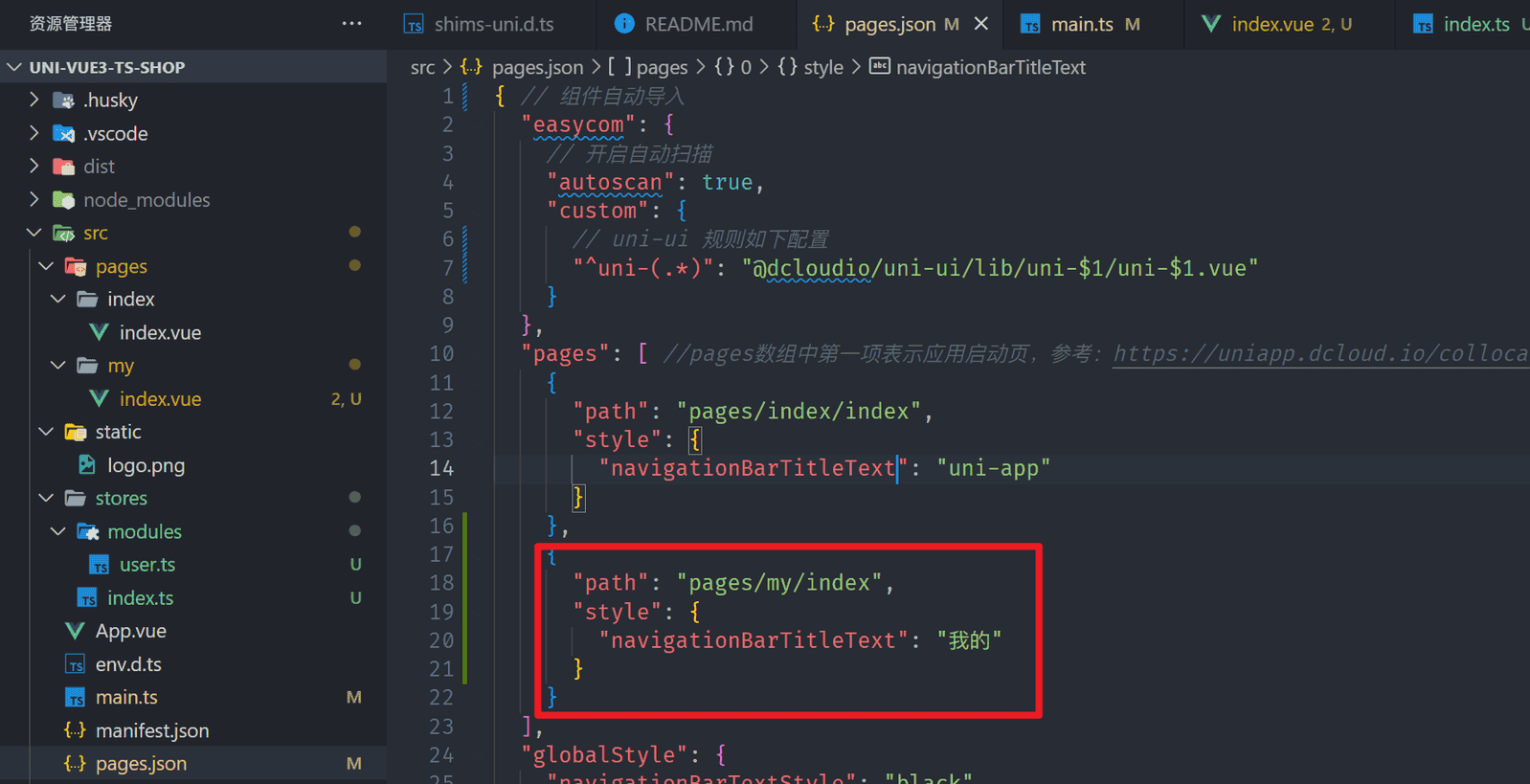
vscode
项目配置
项目生成后,在项目的根目录进行
新建
.vscode
文件夹,并创建
settings.json
文件:
{
// 在保存时格式化文件
"editor.formatOnSave": true,
// 文件格式化配置
"[vue]": {
"editor.defaultFormatter": "esbenp.prettier-vscode"
},
"[json]": {
"editor.defaultFormatter": "esbenp.prettier-vscode"
},
// 配置语言的文件关联
"files.associations": {
"pages.json": "jsonc", // pages.json 可以写注释
"manifest.json": "jsonc" // manifest.json 可以写注释
}
}
同样,在
.vscode
文件夹内,创建 vue3 模板文件,命名为
vue3-uniapp.code-snippets
:
{
"vue3+uniapp快速生成模板": {
"scope": "vue",
"prefix": "Vue3",
"body": [
"<script setup lang=\"ts\">",
"$2",
"</script>\n",
"<template>",
"\t<view class=\"\">test</view>",
"</template>\n",
"<style lang=\"scss\"></style>",
"$2"
],
"description": "vue3+uniapp快速生成模板"
}
}
然后,在空白vue文件中,输入vue3,选择此模板,即可快速生成代码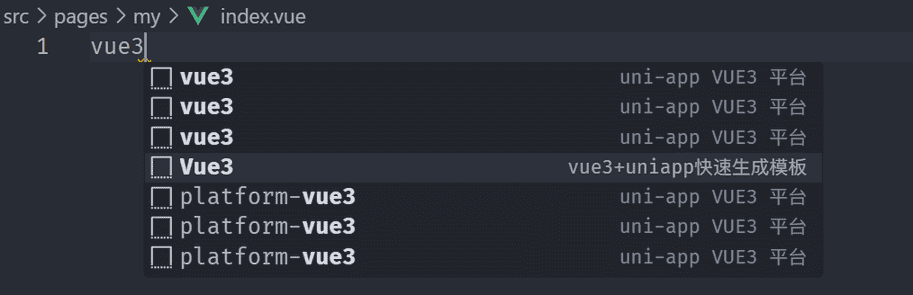
项目初始化
项目创建
拉取
uni-app
官方项目基础架构代码
https://uniapp.dcloud.net.cn/quickstart-cli.html
npx degit dcloudio/uni-preset-vue#vite-ts uni-vue3-ts-shop
cd uni-vue3-ts-shop
或者直接直接克隆国内 gitee 地址,然后修改项目名称,并进入项目根目标
git clone -b vite-ts https://gitee.com/dcloud/uni-preset-vue.git
安装ts扩展
主要是为了增加
uni-app
、
微信小程序
、
nodejs
对ts的支持
npm i -D @uni-helper/uni-app-types miniprogram-api-typings @types/node
修改
tsconfig.json
{
"compilerOptions": {
"ignoreDeprecations": "5.0",
"allowJs": true,
},
"types": ["@dcloudio/types", "miniprogram-api-typings", "@uni-helper/uni-app-types"]
},
"vueCompilerOptions": {
// experimentalRuntimeMode 已废弃,现调整为 nativeTags,请升级 Volar 插件至最新版本
"nativeTags": ["block", "component", "template", "slot"]
}
}
配置环境变量
新增env文件
根目录下新建
.env
文件
VITE_HTTP = https://mock.mengxuegu.com/mock/6598258423a3c638568501db/uniapp_template
使用
获取环境变量
process.env.NODE_ENV // 应用运行的模式,比如vite.config.ts里
import.meta.env.VITE_HTTP // src下的vue文件或其他ts文件里
开启
sourcemap
点我查看官方文档
修改
vite.config.ts
文件:
export default defineConfig({
build: {
// 开发阶段启用源码映射:https://uniapp.dcloud.net.cn/tutorial/migration-to-vue3.html#需主动开启-sourcemap
sourcemap: process.env.NODE_ENV === 'development',
},
plugins: [uni()],
})
统一代码规范
安装
prettier
npm i -D prettier
根目录下新建
.prettierrc.json
{
"singleQuote": true,
"semi": false,
"printWidth": 120,
"trailingComma": "all",
"endOfLine": "auto"
}
安装
eslint
npm i -D eslint eslint-plugin-vue @rushstack/eslint-patch @vue/eslint-config-typescript @vue/eslint-config-prettier
根目录下新建
.eslintrc.js
/* eslint-env node */
require('@rushstack/eslint-patch/modern-module-resolution')
module.exports = {
root: true,
extends: [
'plugin:vue/vue3-essential',
'eslint:recommended',
'@vue/eslint-config-typescript',
'@vue/eslint-config-prettier',
],
// 小程序全局变量
globals: {
uni: true,
wx: true,
WechatMiniprogram: true,
getCurrentPages: true,
getApp: true,
UniApp: true,
UniHelper: true,
App: true,
Page: true,
Component: true,
AnyObject: true,
},
parserOptions: {
ecmaVersion: 'latest',
},
rules: {
'prettier/prettier': [
'warn',
{
singleQuote: true,
semi: false,
printWidth: 120,
trailingComma: 'all',
endOfLine: 'auto',
},
],
'vue/multi-word-component-names': ['off'],
'vue/no-setup-props-destructure': ['off'],
'vue/no-deprecated-html-element-is': ['off'],
'@typescript-eslint/no-unused-vars': ['off'],
},
}
package.json
中新增命令
lint
{
"scripts": {
"lint": "eslint . --ext .vue,.js,.jsx,.cjs,.mjs,.ts,.tsx,.cts,.mts --fix --ignore-path .gitignore"
}
}
然后运行
npm run lint
,将项目内的文件格式化为
eslint
规定的格式(这个命令可随时运行,以便有新页面/插件加入时,解决代码风格的问题)
规范git提交
非必需,适合多人开发
安装
husky
安装并初始化
husky
npx husky-init
如果是首次安装,会有以下提示,输入
y
回车即可
Need to install the following packages:
husky-init@8.0.0
Ok to proceed? (y)
安装完成后,会多出
.husky
文件夹和
pre-commit
文件
安装
lint-staged
npm i -D lint-staged
安装完成后配置
package.json
{
"script": {
// ... 省略 ...
"lint-staged": "lint-staged"
},
"lint-staged": {
"*.{vue,ts,js}": ["eslint --fix"]
}
}
修改
pre-commit
文件
- npm test
+ npm run lint-staged
提交规范
至此,已完成
husky
+
lint-staged
的配置。之后,每次提交代码,在提交信息前都要加入以下提交类型之一,譬如:
feat: 首页新增轮播图
| 提交字段 | 说明 |
|---|---|
| feat: | 增加新功能 |
| fix: | 修复问题/BUG |
| style: | 代码风格相关无影响运行结果的 |
| perf: | 优化/性能提升 |
| refactor: | 重构 |
| revert: | 撤销修改 |
| test: | 测试相关 |
| docs: | 文档/注释 |
| chore: | 依赖更新/脚手架配置修改等 |
| workflow: | 工作流改进 |
| ci: | 持续集成 |
| types: | 类型定义文件更改 |
| wip: | 开发中 |
安装
uni-ui
组件库
非必需,也可使用其他组件库
uni-ui
是DCloud提供的一个跨端ui库,它是基于vue组件的、flex布局的、无dom的跨全端ui框架。
查看官方文档
安装
uni-ui
及相关插件
sass sass-loader
是
uni-ui
的依赖库,
@uni-helper/uni-ui-types
是类型声明文件
npm i -D sass sass-loader
npm i @dcloudio/uni-ui
npm i -D @uni-helper/uni-ui-types
修改配置
修改
tsconfig.json
,配置类型声明文件
{
"compilerOptions": {
"types": ["@dcloudio/types", "miniprogram-api-typings", "@uni-helper/uni-app-types", "@uni-helper/uni-ui-types"]
}
}
修改
src/pages.json
,配置自动导入组件
{
"easycom": {
"autoscan": true,
"custom": {
// uni-ui 规则如下配置
"^uni-(.*)": "@dcloudio/uni-ui/lib/uni-$1/uni-$1.vue"
}
},
"pages": [
// ……
]
}
安装配置
pina
安装
pinia-plugin-persistedstate
是持久化
pina
插件
npm i pinia pinia-plugin-persistedstate
使用
在
src
下新增以下目录和文件
src
├─stores
│ ├─modules
│ │ └─user.ts
| └─index.ts
user.ts
import { defineStore } from 'pinia'
import { ref } from 'vue'
// 定义 Store
export const useMemberStore = defineStore(
'user',
() => {
// 用户信息
const userInfo = ref<any>()
// 保存用户信息,登录时使用
const setUserInfo = (val: any) => {
userInfo.value = val
}
// 清理用户信息,退出时使用
const clearUserInfo = () => {
userInfo.value = undefined
}
return {
userInfo,
setUserInfo,
clearUserInfo,
}
},
// TODO: 持久化
{
persist: true,
},
)
index.ts
import { createPinia } from 'pinia'
import persist from 'pinia-plugin-persistedstate'
// 创建 pinia 实例
const pinia = createPinia()
// 使用持久化存储插件
pinia.use(persist)
// 默认导出,给 main.ts 使用
export default pinia
// 模块统一导出
export * from './modules/user'
main.ts
import { createSSRApp } from 'vue'
import pinia from './stores'
import App from './App.vue'
export function createApp() {
const app = createSSRApp(App)
app.use(pinia)
return {
app,
}
}
持久化
插件默认使用
localStorage
实现持久化,小程序端不兼容,需要替换持久化 API。
修改
stores/modules/user.ts
export const useUserStore = defineStore(
'member',
() => {
//…省略
},
{
// 配置持久化
persist: {
// 调整为兼容多端的API
storage: {
setItem(key, value) {
uni.setStorageSync(key, value)
},
getItem(key) {
return uni.getStorageSync(key)
},
},
},
},
)
封装请求
uniapp
拦截器
uni.addInterceptor
的使用参考
官方文档
src
目录下新建
utils
文件夹,并新建
http.ts
文件
import { useUserStore } from '@/stores'
const baseURL = import.meta.env.VITE_HTTP
// 拦截器配置
const httpInterceptor = {
// 拦截前触发
invoke(options: UniApp.RequestOptions) {
// 非 http 开头需拼接地址
if (!options.url.startsWith('http')) {
options.url = baseURL + options.url
}
options.timeout = 10000
// 添加请求头标识
options.header = {
'request-client': 'wechart-app',
...options.header,
}
// 添加 token 请求头标识
const memberStore = useUserStore()
const token = memberStore.userInfo?.token
if (token) {
options.header.Authorization = token
}
},
}
// 拦截 request 请求
uni.addInterceptor('request', httpInterceptor)
// 拦截 uploadFile 文件上传
uni.addInterceptor('uploadFile', httpInterceptor)
由于
uni-app
的响应拦截器对类型支持并不友好,所以我们自行封装响应拦截器,同一个文件,继续
/**
* 请求函数
* @param UniApp.RequestOptions
* @returns Promise
*/
// Data类型根据后台返回数据去定义
type Data<T> = {
code: string
msg: string
result: T
}
export const http = <T>(options: UniApp.RequestOptions) => {
return new Promise<Data<T>>((resolve, reject) => {
uni.request({
...options,
// 响应成功
success(res) {
if (res.statusCode >= 200 && res.statusCode < 300) {
resolve(res.data as Data<T>)
} else if (res.statusCode === 401) {
// 401错误 -> 清理用户信息,跳转到登录页
const userStore = useUserStore()
userStore.clearUserInfo()
uni.navigateTo({ url: '/pages/login' })
reject(res)
} else {
// 其他错误 -> 根据后端错误信息轻提示
uni.showToast({
icon: 'none',
title: (res.data as Data<T>).msg || '请求错误',
})
reject(res)
}
},
// 响应失败
fail(err) {
uni.showToast({
icon: 'none',
title: '网络错误,换个网络试试',
})
reject(err)
},
})
})
}
使用
为了统一API文件,我们在 src 目录下新建
api
文件夹,并新建
user.ts
import { http } from '@/utils/http'
export const getUserInfoAPI = (data: any) => {
return http({
url: '/user/info',
method: 'POST',
data,
})
}
然后在需要的地方调用,比如在
page/my/index.vue
里调用:
<script setup lang="ts">
import { useUserStore } from '@/stores'
import { getUserInfoAPI } from '@/api/user'
const userStore = useUserStore()
const getUserInfo = async () => {
const res = await getUserInfoAPI({ id: 'weizwz' })
console.log(res)
const { result } = res
userStore.setUserInfo(result)
}
</script>
<template>
<view class="">
<view>用户信息: {{ userStore.userInfo }}</view>
<button
@tap="
userStore.setUserInfo({
userName: 'weizwz',
})
"
size="mini"
plain
type="primary"
>
保存用户信息
</button>
<button @tap="userStore.clearUserInfo()" size="mini" plain type="primary">清理用户信息</button>
<button @tap="getUserInfo()" size="mini" plain type="primary">发送请求</button>
</view>
</template>
<style lang="scss"></style>
效果如下,可以看到已经调用成功: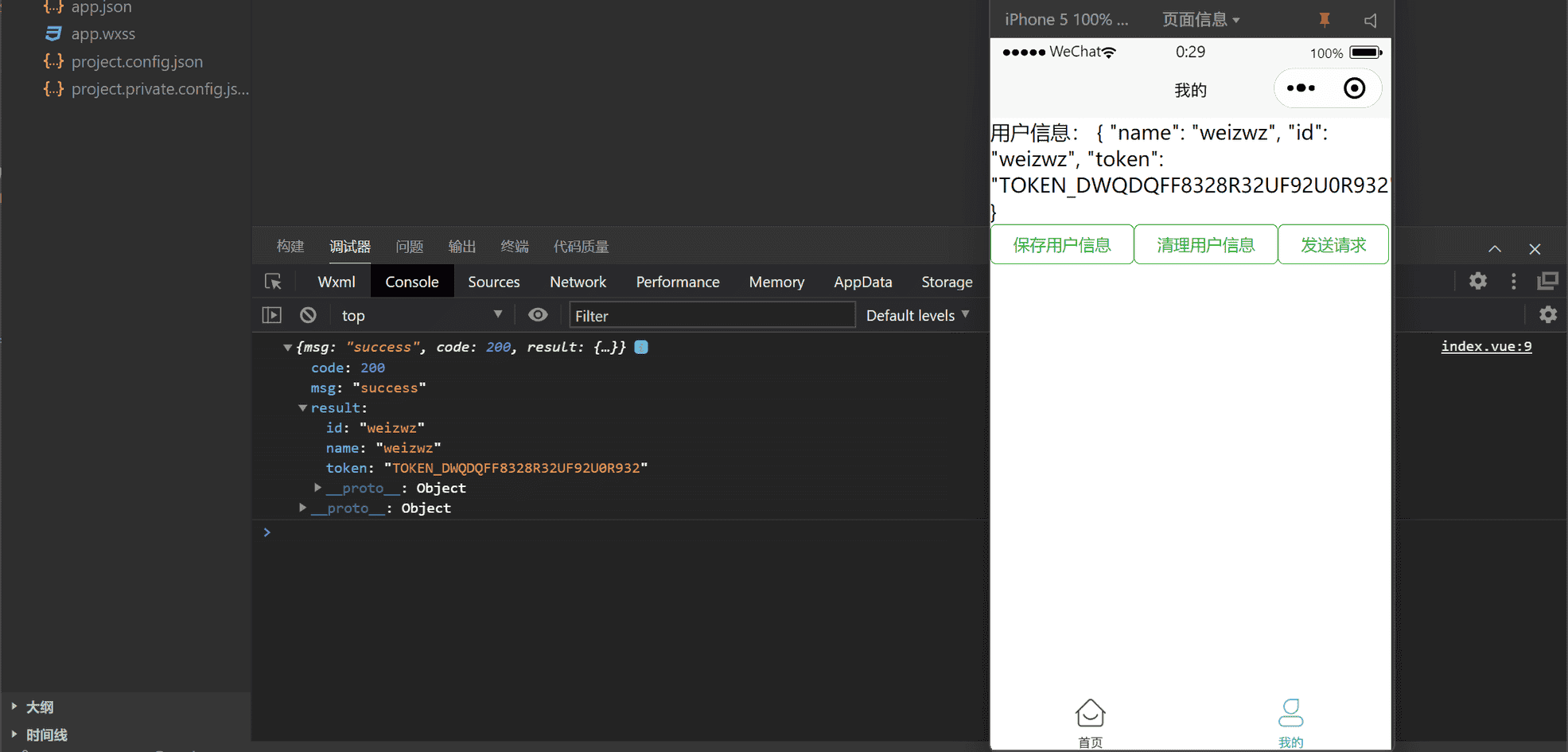
如果调用被拦截的话,请检查微信小程序里的项目设置,然后选中
不检验合法域名、web-view(业务域名)、TLS版本以及HTTPS证书
选项
注意事项
开发区别
uni-app
项目每个页面是一个
.vue
文件,数据绑定及事件处理同
Vue.js
规范:
- vue文件中的
div
标签需替换为
view
标签 - 属性绑定
src="{ { url }}"
升级成
:src="url" - 事件绑定
bindtap="eventName"
升级成
@tap="eventName"
,
支持()传参 - 支持 Vue 常用
指令
v-for
、
v-if
、
v-show
、
v-model
等
其他补充
- 调用接口能力,
建议前缀
wx
替换为
uni
,养成好习惯,
支持多端开发
。 <style>
页面样式不需要写
scoped
,小程序是多页面应用,
页面样式自动隔离
。- 生命周期分三部分
:应用生命周期(小程序),页面生命周期(小程序),组件生命周期(Vue) - 其他参考
uniapp-vue语法 官方文档
文章部分内容来自
小兔鲜儿项目
,本文主要是在此基础上补全了完整创建此项目的流程和所需的依赖