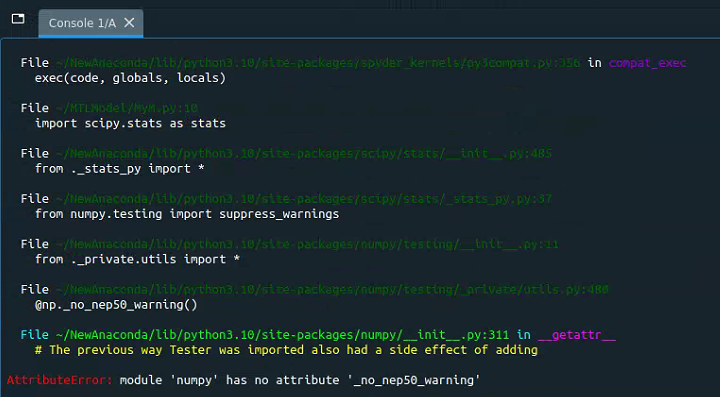
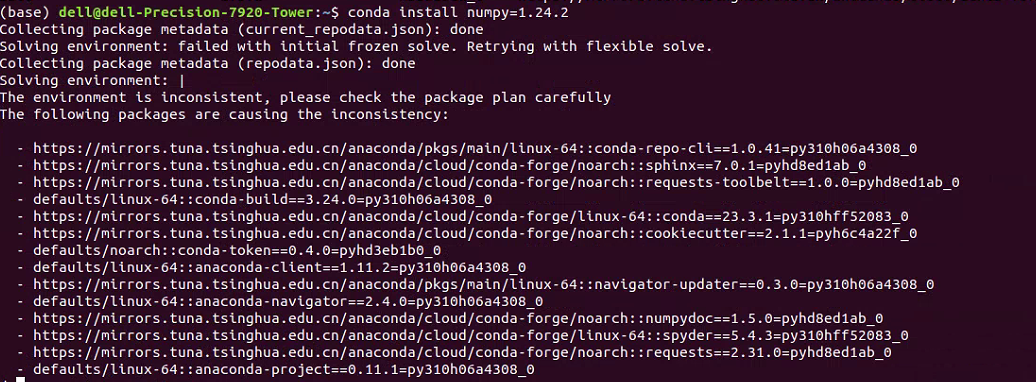
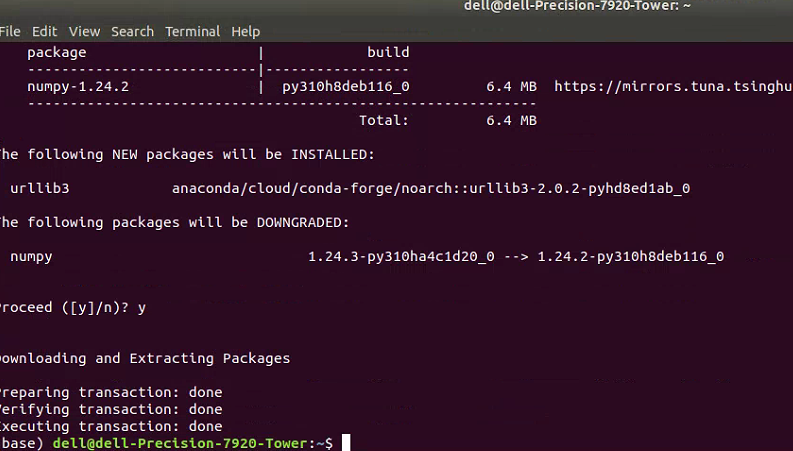
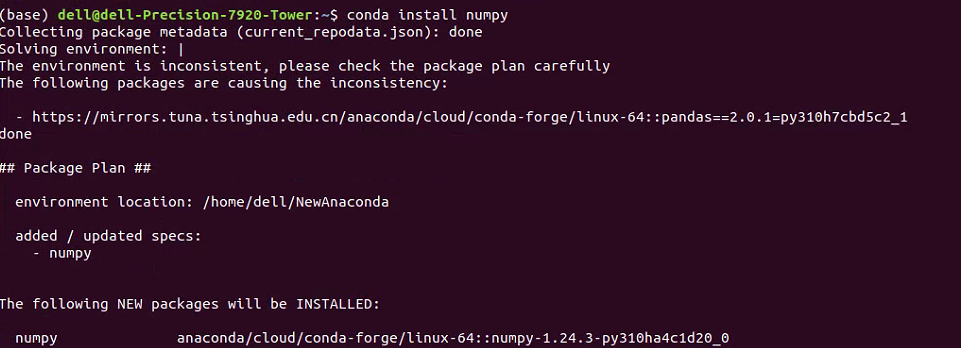
jQuery.i18n.properties 是 jQuery 老项目的国际化框架,其实国际化方案本质上都大同小异,都是需要用翻译函数包裹词条,然后根据词条文件来进行翻译
就是使用上与其他框架不太一样而已
但由于我们已经基于 vue 框架实现了一个国际化自动处理脚本,脚本会自动用全局函数包裹词条,自动提取到 json 文件中
因此,为了让这个老项目也能够用脚本来进行维护,又考虑到最小的改造成本和最小的影响,我们决定扩展 jQuery.i18n.properties 的能力,让它的国际化行为跟 vue-i18n 一致,也就能够用脚本来进行维护了
而且对于团队内的其他新人而言,也没必要去了解 jQuery.i18n.properties,毕竟扩展后的使用方式跟 vue-i18n 基本一样
那么扩展之前,先来看下 jQuery.i18n.properties 这个框架:
全局函数
$.i18n.properties(settings)
国际化初始化函数,用来设置当前语言,资源文件路径
$.i18n.prop(key, ...args)
国际化全局函数,根据 key 值去资源文件里找翻译,后续参数支持占位符替换
当根据 key 值找不到翻译时,会直接返回 key 值
类似 vue-i18n 的
$t
词条文件
.properties 格式文件
也是个键值对的配置文件,只是格式与 json 不一样
【en.properties】
string_login=Login
string_username=username
string_password=password
【zh.properties】
string_login=登录
string_username=账号
string_password=密码
扩展
增加支持 .json 格式的词条文件
重写 $.i18n 的全局函数,内部增加支持 json 词条的挂载,以及在原本翻译行为结束后,如果没翻译成功,则走入 json 词条里进行匹配,查看是否能翻译成功
这样能保证不改动原本项目里已有的国际化代码和行为,保持原样
新增或新改动到的代码就可以用新的方式去进行维护
所以才叫做扩展,而不是改造,毕竟扩展是以不影响原样为前提,不然谁知道老项目的屎山会由于什么修改而突然崩塌
// i18n.expand.js
/**
* 劫持 jQuery.i18n.properties 的 api,扩展国际化能力:
* 1. 支持 .json 格式的资源文件
*/
function init(i18n) {
// 注意,初始化需要在 jQuery.i18n.properties.js 文件加载后才能正常劫持到 i18n 的 api
if (!i18n) return;
wrapFnProperties(i18n);
wrapFnProp(i18n);
wrapMap(i18n);
}
/**
* 挂载新的 map 对象来存储从 .json 资源文件里读取的国际化翻译信息
*/
function wrapMap(i18n) {
i18n.mapFromJson = i18n.mapFromJson || {};
}
/**
* 劫持原 prop,如果原 prop 翻译失败,则再去 mapFromJson 里尝试翻译
*/
function wrapFnProp(i18n) {
let oldFn = i18n.prop;
i18n.prop = function (key, ...args) {
let value = oldFn.call(i18n, key, ...args);
// 如果原翻译行为未翻译成功,则尝试从 json 词条里去寻找翻译
if (value === key) {
// 这里把原 jquery.i18n.properties#prop 代码拷贝过来就行,然后把词条来源改成从json词条里寻找翻译
value = $.i18n.mapFromJson[key];
// ... 省略拷贝过来的代码
}
return value;
};
}
/**
* 劫持原 properties,获取国际化相关配置信息
* 如:当前语言 language,【新增】json的国际化翻译信息
*/
function wrapFnProperties(i18n) {
let oldFn = i18n.properties;
i18n.properties = function (settings, ...args) {
if (settings.jsonResource) {
i18n.mapFromJson = settings.jsonResource;
}
return oldFn.call(i18n, settings, ...args);
};
}
// 如果当前已经加载完jquery.i18n.properties.js文件,就直接扩展它的能力
if ($.i18n) {
// 扩展 jquery.i18n.properties 的能力
init($.i18n);
}
export default {
init: init,
};
然后在引入 jquery.i18n.properties.js 的 html 下面增加:
<script type="text/javascript" src="/lib/jquery.i18n.properties.js"></script>
<script type="text/javascript" src="/lib/i18n.expand.js"></script>
如果你们多页应用没有基类 html 文件的话,那如果有基类 js 的话,也可以在基类 js 里去初始化
尽量只在一个地方去初始化,省得需要每个 html 里去加代码
import i18nExpand from "./i18n.expand";
if ($.i18n) {
// 扩展 jquery.i18n.properties 的能力
i18nExpand.init($.i18n);
}
给 Vue 挂载个全局函数 $t 指向 $.i18n.prop
我们老项目里有引入 Vue 框架,但也仅仅引入 Vue,没有引入其他全家桶系列,只用来在有新改动时,可以局部性使用 Vue 的响应式编程
而这里老项目里没必要再引入个 Vue-i18n 框架了,直接给挂载个全局函数 $t 指向原本的国际化方案的翻译函数即可
if (Vue) {
// 给 Vue 挂载全局函数
Vue.prototype.$t = $.i18n.prop;
}
properties 转 json 的脚本
如果嫌弃 properties 格式的文件不好维护词条,可以写个脚本来转换:
/**
* 将 properties 文件的国际化资源文件转成 json 格式文件
* 脚本命令挂在 package.json 文件里
* 注:由于 properties 文件的中文经过编码,该脚本会进行解码处理,以便中文可正常显示
*/
const vfs = require("vinyl-fs");
const map = require("map-stream");
const path = require("path");
const fs = require("fs");
const ROOT_DIR = path.resolve(__dirname, "./");
const fileRules = ["**/*.+(properties)"];
const jsonFile = "properties2json.json";
function ascii2native(value) {
var character = value.split("\\u");
var native1 = character[0];
for (var i = 1; i < character.length; i++) {
var code = character[i];
native1 += String.fromCharCode(parseInt("0x" + code.substring(0, 4)));
if (code.length > 4) {
native1 += code.substring(4, code.length);
}
}
return native1;
}
function run() {
console.log("================================>start");
let zhProperties = {};
let enProperties = {};
let curProperties = {};
let res = {};
const exist = fs.existsSync(path.resolve(ROOT_DIR, jsonFile));
if (exist) {
res = fs.readFileSync(path.resolve(ROOT_DIR, jsonFile), "utf-8");
res = JSON.parse(res);
}
vfs
.src(fileRules.map((item) => path.resolve(ROOT_DIR, item)))
.pipe(
map((file, cb) => {
console.log("开始解析 =========================>", file.path);
let count = 0;
if (file.path.indexOf("_zh") > -1) {
curProperties = zhProperties;
} else {
curProperties = enProperties;
}
let fileContent = file.contents.toString();
fileContent.split("\n").map((line) => {
if (line.indexOf("=") > -1) {
count++;
line = ascii2native(line);
const [key, ...value] = line.split("=");
// console.log(key, value);
curProperties[key.trim()] = value.join("=").trim();
}
});
console.log("词条数量:", count);
console.log("解析结束 =========================>", file.path);
cb();
})
)
.on("end", () => {
console.log("================================>end");
// console.log(zhProperties);
// console.log(enProperties);
let unTranslate = {};
Object.keys(zhProperties).map((key) => {
if (enProperties[key]) {
res[zhProperties[key]] = enProperties[key];
} else {
unTranslate[key] = zhProperties[key].trim();
console.log("==>翻译丢失", key, zhProperties[key].trim());
}
});
fs.writeFileSync(
path.resolve(ROOT_DIR, jsonFile),
JSON.stringify(res, " ", 2)
);
// fs.writeFileSync(
// path.resolve(ROOT_DIR, "unTranslate.json"),
// JSON.stringify(unTranslate, " ", 2)
// );
});
}
run();
总之,老项目的国际化原则就是控制影响面,降低维护成本,包括需要考虑交给新人去维护的情况
因此,能不改动到原方案就不改动,保持原方案不变的情况下,扩展支持跟 vue 项目一致的使用方式,以便国际化自动处理脚本也能够直接用来维护老项目