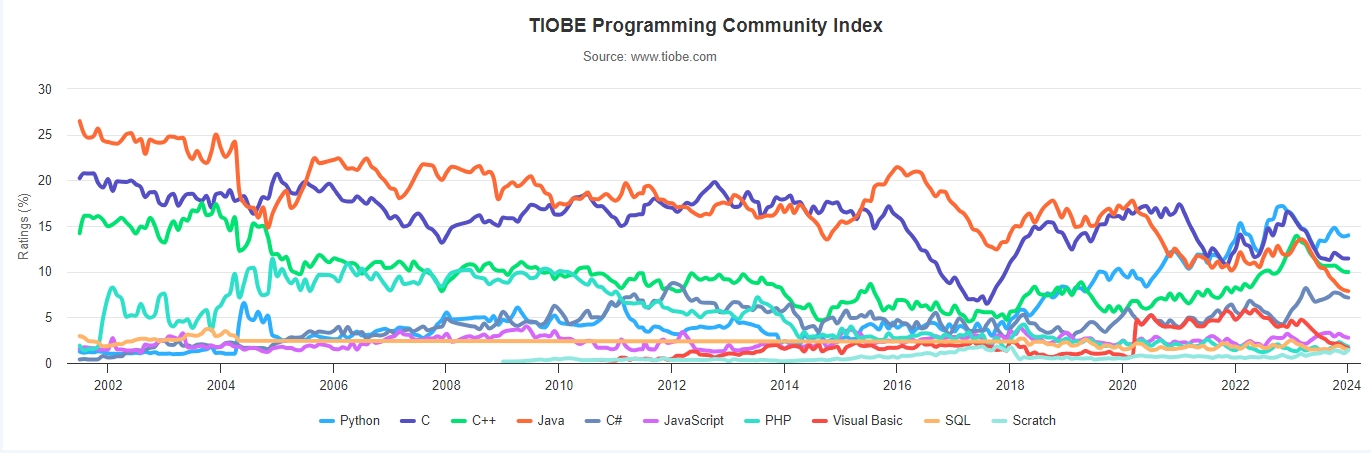
前言
路由(routers)是应用的重要组成部分。所谓路由,有多种定义,对于应用层的单页应用程序而言,路由是一个决定 URL 如何呈现的库,在服务层实现 API 时,路由是解析请求并将请求定向到处理程序的组件。简单的来说,在 Next.js 中,路由决定了一个页面如何渲染或者一个请求该如何返回。
Next.js 目前有两套路由解决方案,之前的方案称之为“Pages Router”,目前的方案称之为“App Router”,两套方案是兼容的,都可以在 Next.js 中使用。本篇我们会重点讲解 App Router,并学习 App Router 下路由的定义方式和常见的文件约定,学习完本篇,你将学会如何创建一个页面。
1. 文件系统(file-system)
Next.js 的路由基于的是文件系统,也就是说,一个文件就可以是一个路由。举个例子,你在
app/pages
目录下创建一个
index.js
文件,它会直接映射到
/
路由地址:
在
app/pages
目录下创建一个
about.js
文件,它会直接映射到
/about
路由地址:
2. 从 Pages Router 到 App Router
现在你打开使用
create-next-app
创建的项目,你会发现默认并没有
pages
这个目录。查看
packages.json
中的 Next.js 版本,如果版本号大于
13.4
,那就对了!
Next.js 从 v13 起就使用了新的路由模式 —— App Router。之前的路由模式我们称之为“Pages Router”,为保持渐进式更新,依然存在。从 v13.4 起,App Router 正式进入稳定化阶段,App Router 功能更强、性能更好、代码组织更灵活,以后就让我们使用新的路由模式吧!
可是这俩到底有啥区别呢?Next.js 又为什么升级到 App Router 呢?知其然知其所以然,让我们简单追溯一下。以前我们声明一个路由,只用在
pages
目录下创建一个文件就可以了,以前的目录结构类似于:
└── pages
├── index.js
├── about.js
└── more.js
这种方式有一个弊端,那就是
pages
目录的所有 js 文件都会被当成路由文件,这就导致比如组件不能写在
pages
目录下,这就不符合开发者的使用习惯。(当然 Pages Router 还有很多其他的问题,只不过目前我们介绍的内容还太少,为了不增加大家的理解成本,就不多说了)
升级为新的 App Router 后,现在的目录结构类似于:
src/
└── app
├── page.js
├── layout.js
├── template.js
├── loading.js
├── error.js
└── not-found.js
├── about
│ └── page.js
└── more
└── page.js
使用新的模式后,你会发现
app
下多了很多文件。这些文件的名字并不是我乱起的,而是 Next.js 约定的一些特殊文件。从这些文件的名称中你也可以了解文件实现的功能,比如布局(layout.js)、模板(template.js)、加载状态(loading.js)、错误处理(error.js)、404(not-found.js)等。
简单的来说,App Router 制定了更加完善的规范,使代码更好被组织和管理。至于这些文件具体的功能和介绍,不要着急,本篇我们会慢慢展开。
3. 使用 Pages Router
当然你也可以继续使用 Pages Router,如果你想使用 Pages Router,只需要在
src
目录下创建一个
pages
文件夹或者在根目录下创建一个
pages
文件夹。其中的 JS 文件会被视为 Pages Router 进行处理。

但是要注意,虽然两者可以共存,但 App Router 的优先级要高于 Pages Router。而且如果两者解析为同一个 URL,会导致构建错误。
你在 Next.js 官方文档进行搜索的时候,左上角会有 App 和 Pages 选项,这对应的就是 App Router 和 Pages Router:

因为两种路由模式的使用方式有很大不同,所以搜索的时候注意选择正确的的路由模式。
4. 使用 App Router
4.1. 定义路由
现在让我们开始正式的学习 App Router 吧。
首先是定义路由,文件夹被用来定义路由。每个文件夹都代表一个对应到 URL 片段的路由片段。创建嵌套的路由,只需要创建嵌套的文件夹。举个例子,下图的
app/dashboard/settings
目录对应的路由地址就是
/dashboard/settings
:

4.2. 定义页面(Pages)
那如何保证这个路由可以被访问呢?你需要创建一个特殊的名为
page.js
的文件。至于为什么叫
page.js
呢?除了
page
有“页面”这个含义之外,你可以理解为这是一种约定或者规范。(如果你是 Next.js 的开发者,你也可以约定为
index.js
甚至
yayu.js
!)

在上图这个例子中:
app/page.js
对应路由
/
app/dashboard/page.js
对应路由
/dashboard
app/dashboard/settings/page.js
对应路由
/dashboard/settings
analytics
目录下因为没有
page.js
文件,所以没有对应的路由。这个文件可以被用于存放组件、样式表、图片或者其他文件。
当然不止
.js
文件,Next.js 默认是支持 React、TypeScript 的,所以
.js
、
.jsx
、
.tsx
都是可以的。
那这个
page.js
代码如何写呢?最常见的是展示 UI,比如:
访问
http://localhost:3000/
,效果如下:

4.3. 定义布局(Layouts)
布局是指多个页面共享的 UI。在导航的时候,布局会保留状态,保持可交互性并且不会重新渲染,比如用来实现后台管理系统的侧边导航栏。
定义一个布局,你需要新建一个名为
layout.js
的文件,该文件默认导出一个 React 组件,该组件应接收一个
children
prop,
chidren
表示子布局(如果有的话)或者子页面。
举个例子,我们新建目录和文件如下图所示:

相关代码如下:
当访问
/dashboard
的时候,效果如下:

其中,
nav
来自于
app/dashboard/layout.js
,
Hello, Dashboard!
来自于
app/dashboard/page.js
你可以发现:同一文件夹下如果有 layout.js 和 page.js,page 会作为 children 参数传入 layout。换句话说,layout 会包裹同层级的 page。
app/dashboard/settings/page.js
代码如下:
当访问
/dashboard/settings
的时候,效果如下:

其中,
nav
来自于
app/dashboard/layout.js
,
Hello, Settings!
来自于
app/dashboard/settings/page.js
你可以发现:布局是支持嵌套的
,
app/dashboard/settings/page.js
会使用
app/layout.js
和
app/dashboard/layout.js
两个布局中的内容,不过因为我们没有在
app/layout.js
写入可以展示的内容,所以图中没有体现出来。
根布局(Root Layout)
布局支持嵌套,最顶层的布局我们称之为根布局(Root Layout),也就是
app/layout.js
。它会应用于所有的路由。除此之外,这个布局还有点特殊。
使用
create-next-app
默认创建的
layout.js
代码如下:
其中:
app
目录必须包含根布局,也就是
app/layout.js
这个文件是必需的。- 根布局必须包含
html
和
body
标签,其他布局不能包含这些标签。但如果你要更改这些标签,不推荐直接修改,Next.js 提供
内置工具
帮助你管理诸如
<title />
这样的 HTML 元素。
- 你可以使用
路由组
创建多个根布局。
- 默认根布局是
服务端组件
,且不能设置为客户端组件。
4.4. 定义模板(Templates)
模板类似于布局,它也会传入每个子布局或者页面。但不会像布局那样维持状态。
模板在路由切换时会为每一个 children 创建一个实例。这就意味着当用户在共享一个模板的路由间跳转的时候,将会重新挂载组件实例,重新创建 DOM 元素,不保留状态。这听起来有点抽象,没有关系,我们先看看模板的写法,再写个 demo 你就明白了。
定义一个模板,你需要新建一个名为
template.js
的文件,该文件默认导出一个 React 组件,该组件接收一个
children
prop。我们写个示例代码。在
app
目录下新建一个
template.js
文件。

template.js
代码如下:
你会发现,这用法跟布局一模一样。它们最大的区别就是状态的保持。如果同一目录下既有
template.js
也有
layout.js
,最后的输出效果如下:
<Layout>
{
也就是说
layout
会包裹
template
,
template
又会包裹
page
。
某些情况下,模板会比布局更适合:
布局 VS 模板
为了帮助大家更好的理解布局和模板,我们写一个 demo,展示下两者的特性。
项目目录如下:
app
└─ dashboard
├─ layout.js
├─ page.js
├─ template.js
├─ about
│ └─ page.js
└─ settings
└─ page.js
其中
dashboard/layout.js
代码如下:
'use client'
import { useState } from 'react'
import Link from 'next/link'
export default function Layout({ children }) {
const [count, setCount] = useState(0)
return (
<>
<div>
<Link href="/dashboard/about">About</Link>
<br/>
<Link href="/dashboard/settings">Settings</Link>
</div>
<h1>Layout {count}</h1>
<button onClick={() => setCount(count + 1)}>
Increment
</button>
{children}
</>
)
}
dashboard/template.js
代码如下:
'use client'
import { useState } from 'react'
export default function Template({ children }) {
const [count, setCount] = useState(0)
return (
<>
<h1>Template {count}</h1>
<button onClick={() => setCount(count + 1)}>
Increment
</button>
{children}
</>
)
}
dashboard/page.js
代码如下:
export default function Page() {
return <h1>Hello, Dashboard!</h1>
}
dashboard/about/page.js
代码如下:
export default function Page() {
return <h1>Hello, About!</h1>
}
dashboard/settings/page.js
代码如下:
export default function Page() {
return <h1>Hello, Settings!</h1>
}
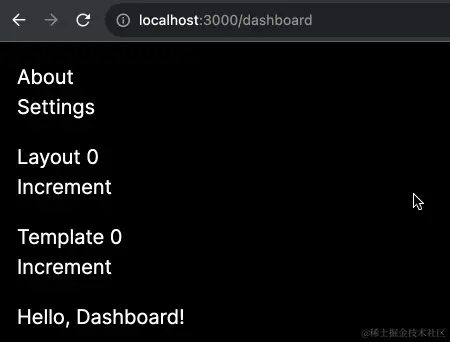
最终展示效果如下(为了方便区分,做了部分样式处理):

现在点击两个
Increment
按钮,会开始计数。随便点击下数字,然后再点击
About
或者
Settings
切换路由,你会发现,Layout 后的数字没有发生变化,Template 后的数字重置为 0。这就是所谓的状态保持。
注:当然如果刷新页面,Layout 和 Template 后的数字肯定都重置为 0。
4.5. 定义加载界面(Loading UI)
现在我们已经了解了
page.js
、
layout.js
、
template.js
的功能,然而特殊文件还不止这些。App Router 提供了用于展示加载界面的
loading.js
。
这个功能的实现借助了 React 的
Suspense
API。关于 Suspense 的用法,可以查看
《React 之 Suspense》
。它实现的效果就是当发生路由变化的时候,立刻展示 fallback UI,等加载完成后,展示数据。
初次接触 Suspense 这个概念的时候,往往会有一个疑惑,那就是——“在哪里控制关闭 fallback UI 的呢?”
哪怕在 React 官网中,对背后的实现逻辑并无过多提及。但其实实现的逻辑很简单,简单的来说,ProfilePage 会 throw 一个数据加载的 promise,Suspense 会捕获这个 promise,追加一个 then 函数,then 函数中实现替换 fallback UI 。当数据加载完毕,promise 进入 resolve 状态,then 函数执行,于是更新替换 fallback UI。
了解了原理,那我们来看看如何写这个
loading.js
吧。
dashboard
目录下我们新建一个
loading.js
。

loading.js
的代码如下:
同级的
page.js
代码如下:
不再需要其他的代码,loading 的效果就实现了:
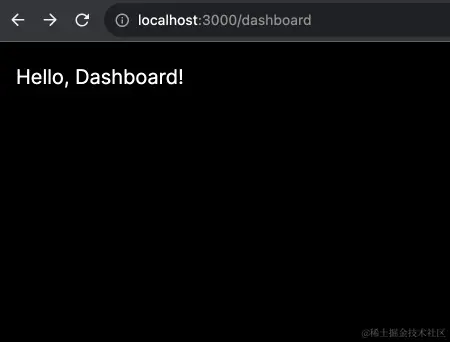
就是这么简单。其关键在于
page.js
导出了一个 async 函数。
loading.js
的实现原理是将
page.js
和下面的 children 用
<Suspense>
包裹。因为
page.js
导出一个 async 函数,Suspense 得以捕获数据加载的 promise,借此实现了 loading 组件的关闭。

当然实现 loading 效果,不一定非导出一个 async 函数。也可以借助 React 的
use
函数。现在我们在
dashboard
下新建一个
about
目录,在其中新建
page.js
文件。
/dashboard/about/page.js
代码如下:
同样实现了 loading 效果:
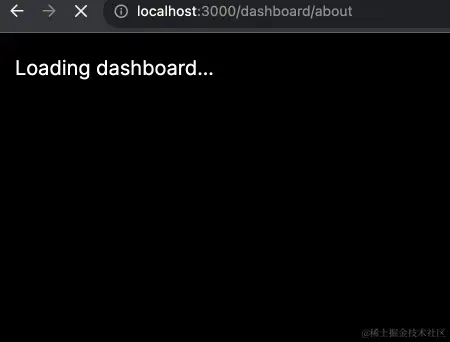
如果你想针对
/dashboard/about
单独实现一个 loading 效果,那就在
about
目录下再写一个
loading.js
即可。
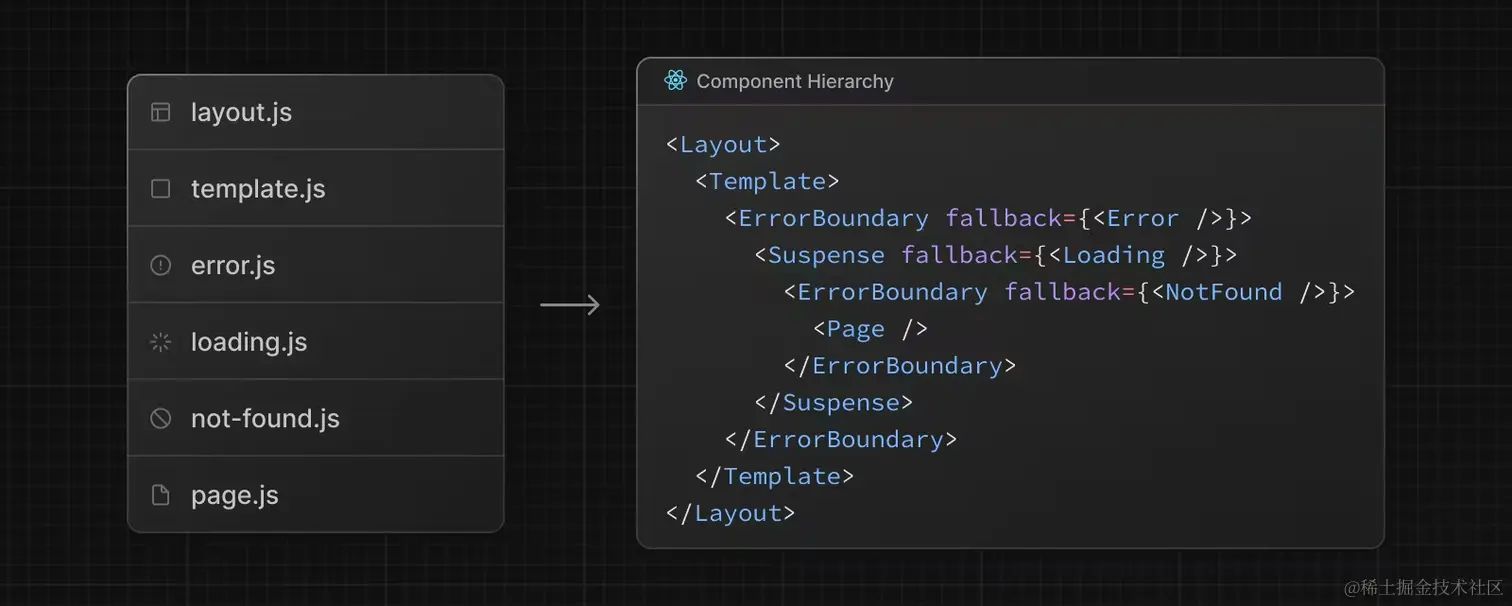
如果同一文件夹既有
layout.js
又有
template.js
又有
loading.js
,那它们的层级关系是怎样呢?
对于这些特殊文件的层级问题,直接一张图搞定:
4.6. 定义错误处理(Error Handling)
再讲讲特殊文件
error.js
。顾名思义,用来创建发生错误时的展示 UI。
其实现借助了 React 的
Error Boundary
功能。简单来说,就是给 page.js 和 children 包了一层
ErrorBoundary
。
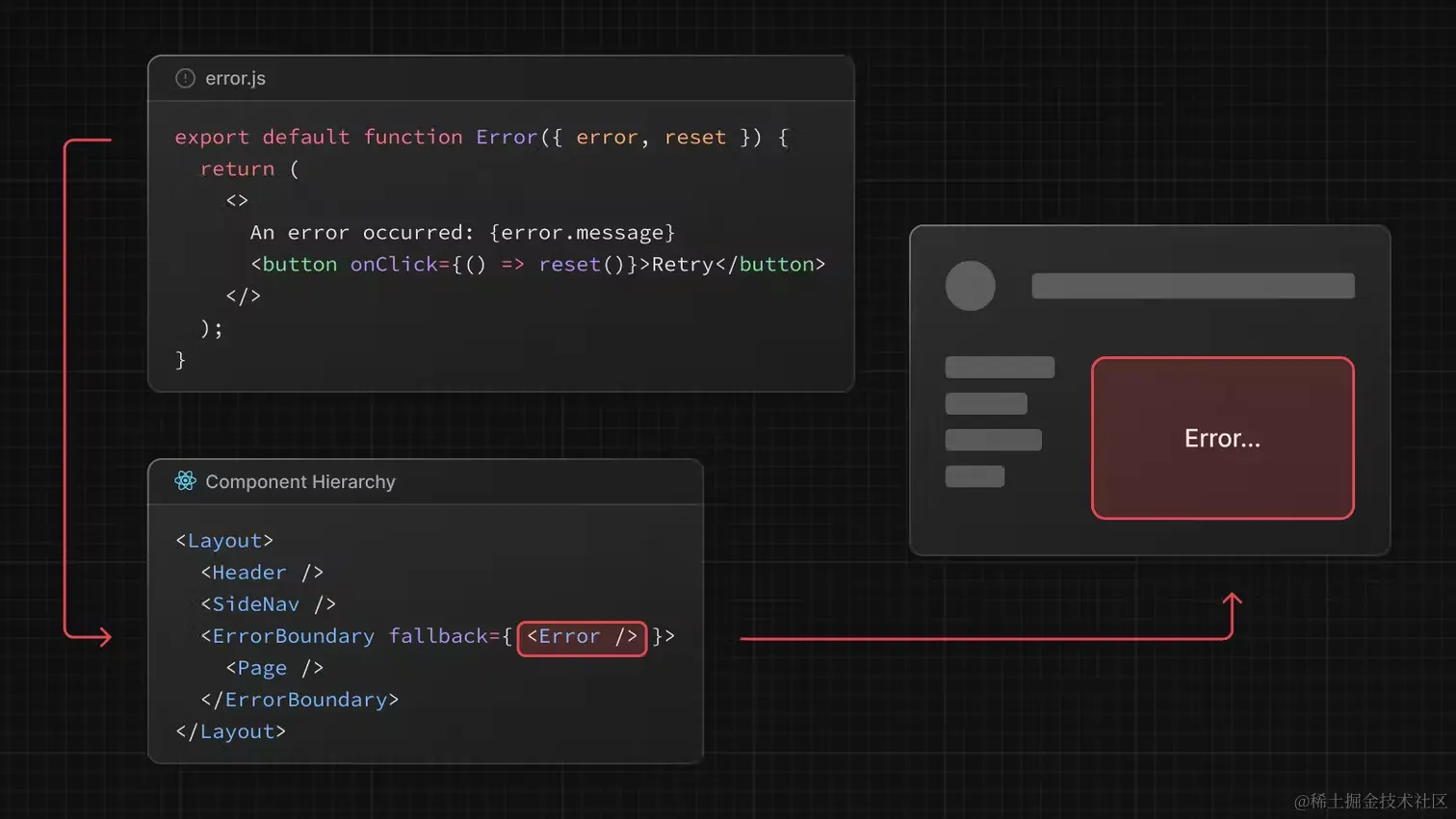
我们写一个 demo 演示一下
error.js
的效果。
dashboard
目录下新建一个
error.js
,目录效果如下:
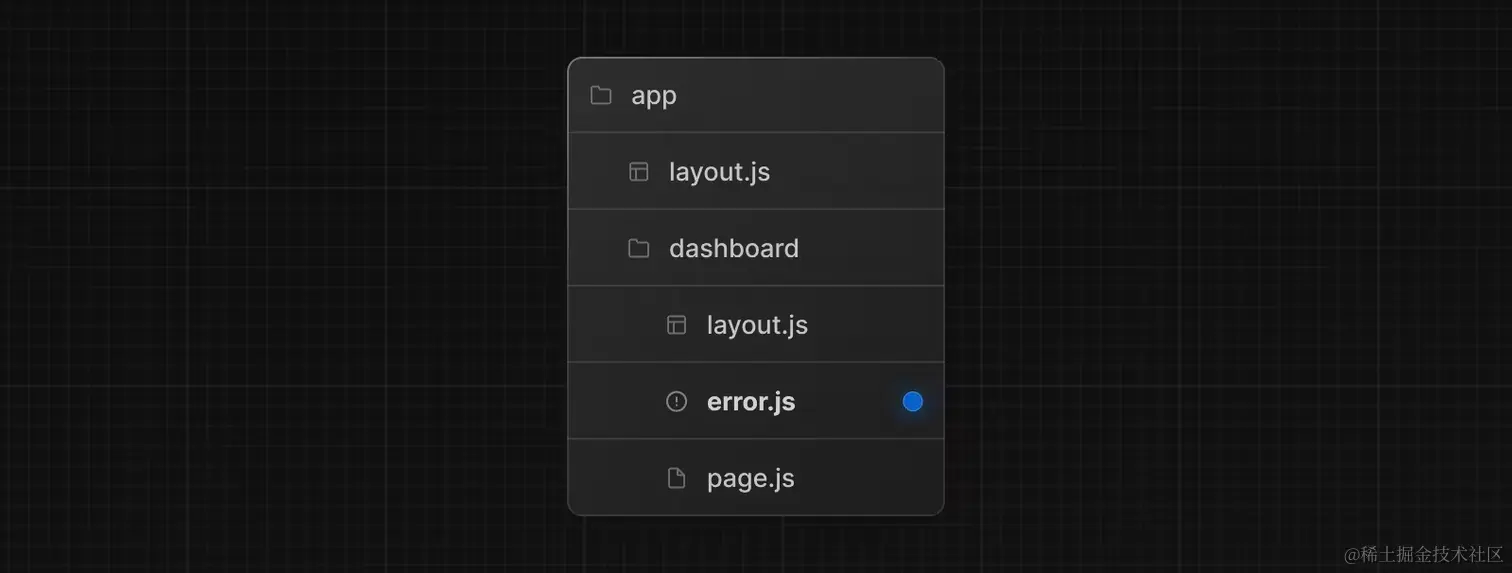
dashboard/error.js
代码如下:
'use client'
为触发 Error 错误,同级
page.js
的代码如下:
"use client";
效果如下:
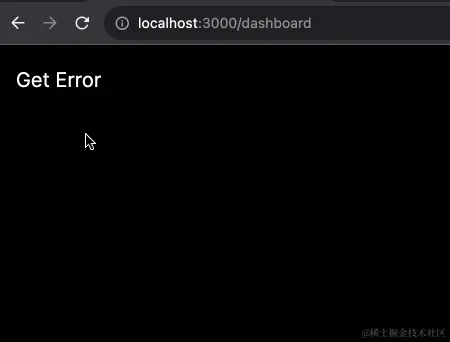
有时错误是暂时的,只需要重试就可以解决问题。所以 Next.js 会在
error.js
导出的组件中,传入
reset
函数,帮助尝试从错误中恢复。该函数会触发重新渲染错误边界里的内容。如果成功,会替换展示重新渲染的内容。
还记得上节讲过的层级问题吗?让我们回顾一下:
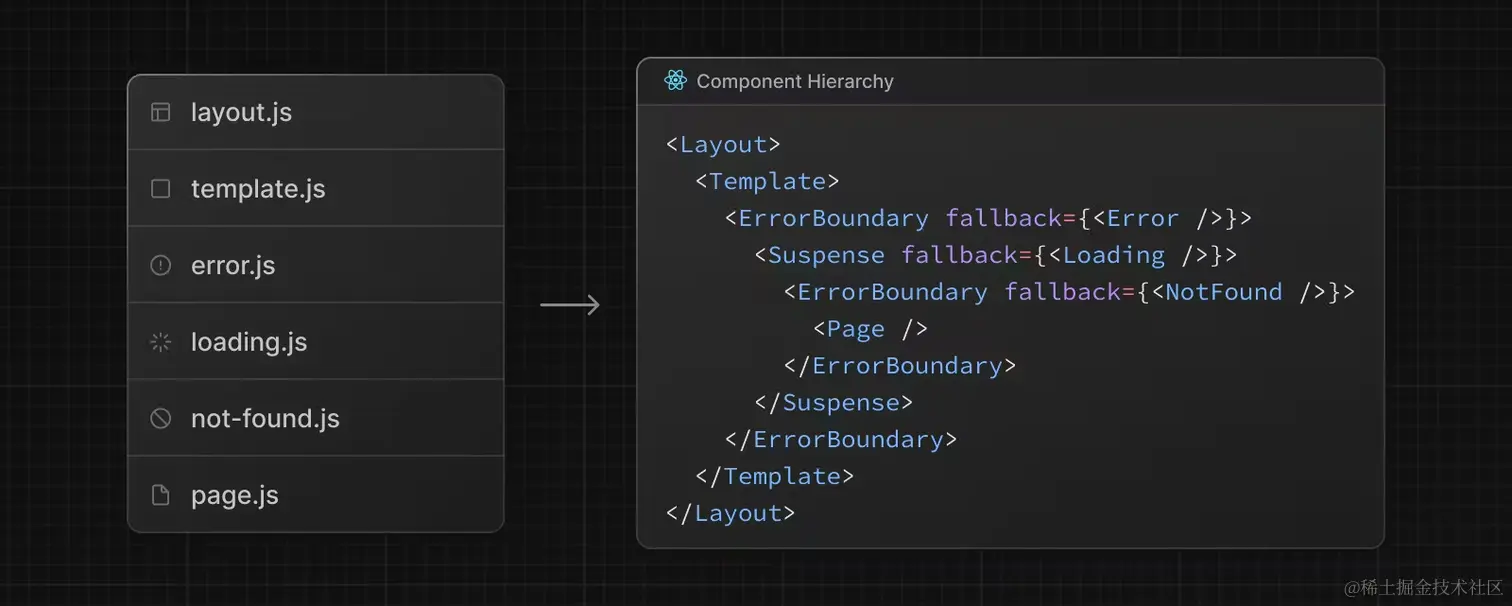
从这张图里你会发现一个问题,因为
Layout
和
Template
在
ErrorBoundary
外面,这说明错误边界不能捕获同级的
layout.js
或者
template.js
中的错误。如果你想捕获特定布局或者模板中的错误,那就在父级的
error.js
里进行捕获。
那问题来了,如果已经到了顶层,就比如根布局中的错误如何捕获呢?为了解决这个问题,Next.js 提供了
global-error.js
文件,使用它时,将其放在
app
目录下。
global-error.js
会包裹整个应用,而且当它触发的时候,它会替换掉根布局的内容。所以,
global-error.js
中也要定义
<html>
和
<body>
标签。
global-error.js
示例代码如下:
'use client'
注:
global-error.js
用来处理根布局和根模板中的错误,
app/error.js
建议还是要写的
4.7. 定义 404 页面
最后再讲一个特殊文件 ——
not-found.js
。顾名思义,当该路由不存在的时候展示的内容。
Next.js 项目默认的 not-found 效果如下:

如果你要替换这个效果,只需要在
app
目录下新建一个
not-found.js
,代码示例如下:
import Link from 'next/link'
export default function NotFound() {
return (
<div>
<h2>Not Found</h2>
<p>Could not find requested resource</p>
<Link href="/">Return Home</Link>
</div>
)
}
not-found 的效果就会更改为:

考虑到
layout.js
和
template.js
的使用效果,如果我把
not-found.js
添加到一个子目录里,比如
/dashboard/blog
下:
dashboard
└─ blog
├─ page.js
└─ not-found.js
当访问
/dashboard/blog/yayu
(该路由没有声明)时,它的 not-found 效果会是自定义的吗?
答案是不会。访问
/dashboard/blog/yayu
依然会走到默认 not-found 路由效果。这是因为
not-found.js
被用于当
notFound
函数被抛出的时候。(
notFound
函数是
next/navigation
这个包提供的一个方法)
写个示例代码:
/dashboard/blog
下新建一个
page.js
和
not-found.js
。
page.js
代码如下:
not-found.js
代码则直接复制上面的
not-found.js
。
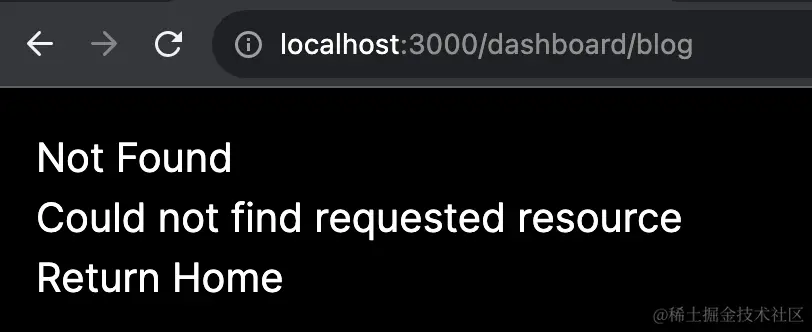
当访问
/dashboard/blog
时,因为
page.js
丢出了
notFound
函数,所以会触发
not-found.js
的执行。
但当访问
/dashboard/blog/yayu
时,因为没有对应的路由处理程序,依然是默认的 not-found 效果

如果我们添加对应的处理程序,在
app/dashboard/blog/yayu/page.js
中也执行 notFound 函数,就会渲染
/dashboard/blog/not-found.js
的 UI 内容。
对应到实际开发,当我们请求一个用户的数据时或是请求一篇文章的数据时,如果该数据不存在,就可以直接丢出
notFound
函数,渲染自定义的
not-found
界面。一个示例代码如下:
5. 链接和导航(Linking and Navigating)
知道了如何定义路由,最后我们再讲讲如何在 Next.js 中实现链接和导航。Next.js 提供了两种方式:
- 使用
<Link>
组件
- 使用
useRouter
Hook
5.1.
<Link>
<Link>
是一个拓展了 HTML
<a>
标签的内置组件,用来实现预获取(prefetching) 和客户端路由导航。这是 Next.js 中路由导航的主要方式。
5.1.1. 基础使用
使用示例如下:
import Link from 'next/link'
export default function Page() {
return <Link href="/dashboard">Dashboard</Link>
}
支持 hash 值用于实现跳转到页面的某个位置:
<Link href="/dashboard#settings">Settings</Link>
5.1.2. 动态渲染链接
支持路由链接动态渲染:
import Link from 'next/link'
export default function PostList({ posts }) {
return (
<ul>
{posts.map((post) => (
<li key={post.id}>
<Link href={`/blog/${post.slug}`}>{post.title}</Link>
</li>
))}
</ul>
)
}
5.1.3. 获取当前路径名
如果需要对当前链接进行判断,你可以使用
usePathname()
这个方法,它会读取当前 URL 的路径名(pathname),这是一段示例代码:
'use client'
import { usePathname } from 'next/navigation'
import Link from 'next/link'
export function Navigation({ navLinks }) {
const pathname = usePathname()
return (
<>
{navLinks.map((link) => {
const isActive = pathname === link.href
return (
<Link
className={isActive ? 'text-blue' : 'text-black'}
href={link.href}
key={link.name}
>
{link.name}
</Link>
)
})}
</>
)
}
5.1.4. 跳转行为设置
App Router 的默认行为是滚动到新路由的顶部,或者在前进后退导航时维持之前的滚动距离。
如果你想要禁用这个行为,你可以给
<Link>
组件传递一个
scroll={false}
,或者在使用
router.push
和
router.replace
的时候,设置
scroll: false
。
示例代码如下:
注:关于
<Link>
组件的用法,我们还会在
《组件篇 | Link 和 Script》
中详细介绍。
5.2. useRouter
第二种方式是使用 useRouter。示例代码如下:
'use client'
import { useRouter } from 'next/navigation'
export default function Page() {
const router = useRouter()
return (
<button type="button" onClick={() => router.push('/dashboard')}>
Dashboard
</button>
)
}
注意使用该 hook 需要在客户端组件中。(顶层的
'use client'
就是声明这是客户端组件)
注:关于 useRouter,我们还会在
《API 篇 | 请求相关的常用函数与方法》
篇中详细介绍。
小结
恭喜你,完成了本节内容的学习!
这一节我们重点讲解了 Next.js 基于文件系统的路由解决方案 App Router,介绍了用于定义页面的
page.js
、定义布局的
layout.js
、定义模板的
template.js
、定义加载界面的
loading.js
、定义错误处理的
error.js
、定义 404 页面的
not-found.js
。现在你再看 App Router 的这个目录结构:
src/
└── app
├── page.js
├── layout.js
├── template.js
├── loading.js
├── error.js
└── not-found.js
├── about
│ └── page.js
└── more
└── page.js
简单的来说,App Router 制定了更加完善的规范,使代码更好被组织和管理。
对此是不是有了更加深刻的理解呢?然而这还只有 Next.js 强大的路由功能的一小部分。下篇我们开始介绍 Next.js 的高级路由功能。
知识星球【Next.js开发指南】(已更新至第33章)
- 初始篇 | Next.js CLI
- 路由篇 | App Router
- 路由篇 | 动态路由、路由组、平行路由和拦截路由
- 路由篇 | 路由处理程序和中间件
- 路由篇 | 国际化
- 数据获取篇 | 数据获取、缓存与重新验证
- 数据获取篇 | Server Actions 与表单
- 渲染篇 | 从 CSR、SSR、SSG、ISR 开始说起
- 渲染篇 | 服务端组件和客户端组件
- 渲染篇 | Streaming 和 Edge Runtime
- 缓存篇 | Caching
- 样式篇 | Tailwind CSS、CSS-in-JS 与 Sass
- 组件篇 | Images
- 组件篇 | Font
- 组件篇 | Link 和 Script
- 优化篇 | 懒加载
- 配置篇 | TypeScript 和 ESLint
- 配置篇 | 环境变量、路径别名与 src 目录
- 配置篇 | MDX
- 配置篇 | 草稿模式和内容安全策略
- 配置篇 | 路由段配置项
- 部署篇 | 静态导出
- Metadata 篇 | 基于配置
- Metadata 篇 | 基于文件
- API 篇 | next.config.js(上)
- API 篇 | next.config.js(下)
- API 篇 | 请求相关的常用函数与方法
- API 篇 | 常用函数与方法
- 实战篇 | React Notes | 项目介绍与创建
- 实战篇 | React Notes | 侧边栏笔记列表
- 实战篇 | React Notes | 笔记预览界面
- 实战篇 | React Notes | 笔记编辑界面
- 实战篇 | React Notes | 笔记搜索
- 实战篇 | React Notes | 国际化
- 实战篇 | React Notes | Auth
- 实战篇 | React Notes | 文件上传
- 实战篇 | React Notes | 部署(一)
- 实战篇 | React Notes | 部署(二)
- 实战篇 | 博客 | 项目创建
- 实战篇 | 博客 | 博客后台
- 实战篇 | 博客 | MDX
- 实战篇 | 博客 | Server Actions
- 实战篇 | 博客 | 渲染原理
- 实战篇 | App | 需求分析
- 实战篇 | App | 数据库设计
- 实战篇 | App | 项目创建
- 实战篇 | App | 移动端处理
- 实战篇 | App | 接口开发
- 实战篇 | App | 数据请求
- 实战篇 | App | 构建部署
- 源码篇 | 源码架构
- 源码篇 | 调试代码
- 源码篇 | 路由实现
- 源码篇 | 渲染原理
- 源码篇 | 手写 SSR
- 源码篇 | mini-next
- 源码篇 | mini-next
- 源码篇 | mini-next
- 源码篇 | mini-next
- 面试篇 | 常见面试题及解析
- 面试篇 | 常见面试题及解析
- 面试篇 | 常见面试题及解析