非工程师指南: 训练 LLaMA 2 聊天机器人
引言
本教程将向你展示在不编写一行代码的情况下,如何构建自己的开源 ChatGPT,这样人人都能构建自己的聊天模型。我们将以 LLaMA 2 基础模型为例,在开源指令数据集上针对聊天场景对其进行微调,并将微调后的模型部署到一个可分享的聊天应用中。全程只需点击鼠标,即可轻松通往荣耀之路!
本教程将向你展示在不编写一行代码的情况下,如何构建自己的开源 ChatGPT,这样人人都能构建自己的聊天模型。我们将以 LLaMA 2 基础模型为例,在开源指令数据集上针对聊天场景对其进行微调,并将微调后的模型部署到一个可分享的聊天应用中。全程只需点击鼠标,即可轻松通往荣耀之路!
这一年可以说是这么多年来,我第一次花时间去细细回顾过往,这是被裁员意外带来的机会,过去的我好像过得总是那么的漫不经心,偶尔去思考一些事,也是想想就过去了,没有去深究过什么。比如说,过去失败的面试经历,我总是死磕在技术方面,总觉得说自己要在技术方面多精进一点,当然这也没什么错,只是说我忽视了其他一些同样值得重视的问题,比如说面试时太社恐,不够自信,表达能力不足,以前在复盘的时候自己在潜意识中会有意无意的忽略、逃避这些问题,然后有时虽然说是面试复盘,但也没像其他人一样,会把答的不好的或者答不上的问题去查找答案、整理什么的,总而言之就是有点乱糟糟的,没什么章程。这一段日子闲下来了,偶尔我也开始思考这些真实存在的问题,不过想的也只是,不说完全解决问题、也不说改变自己的性格,只是说做一些适应和自我的调整。
这一年闲赋在家的总结,下面就是理一理吧,主要经历的几件事:
今年是毕业工作以来第一次参加编制考试,倒不是说想要个铁饭碗,存粹只是因为没什么事做,也到考编的擦边年龄了,算是最后的体验吧,从二月的人社厅专属到十二月的浙江省考,参加了大概七八场。
从学校毕业后,我就没想着要再去考什么证,属于一整个自我放飞,某天有个前同事跟我说他准备参加软考,正好我也没啥事,就心生一计,也去考个信息系统项目管理师,谁知刚好赶上教材改版,又赶上笔考改机考,谁能不说这是一场该死的缘分呢,论文也没怎么准备,五月和十一月两场的成绩都没过及格线,只剩下“到此一游”。
这是今年最大的意外,说实话待业的压力真的有点大,有一段时间我的精神状态十分糟糕,并且我也没有把待业的事跟家里说,所以家里同时又在催着相亲,现在去回忆那段时间,整个人的状态是飘忽的,就这样被骗子钻了空子,曾经我也很自信觉得自己不会被骗,但是在那样一种状态下,稀里糊涂着了骗子的道,事后也曾在网上发帖分享自己的经历,其中也不乏有个别嘲讽我的人,我祝他们永远不会被骗。
说说事后吧,虽然知道没啥用,但是报警了,仍然有好多天特别崩溃,一度觉得自己快活不下去了,本来就没了收入,一下子又雪上加霜,真的感觉人生灰暗,到现在还背负着债务。
感谢很多人的安慰和鼓励,感谢自己活过来了。
待业之后,对于前途也和很多人一样,有点模糊不清,就主要用学习来填充生活了,固定工作日上图书馆,在准备考试的阶段周末也会去,其实我也没什么学习的重心,主要起一个缓解焦虑的作用,去年好像是因为双十一的原因,往极客时间上充了点钱,所以今年就在上面买了些课程,完成了极客时间上vue3课程的学习、wasm入门课程的学习,中间穿插着复习整理一些前端的面试题、学习软考的教材、看一些考编资料,目前正在学习可视化的课程。
仰卧起坐,稳定学习。
以前是博客注册了一堆,但是都没怎么写过,现在觉得说,学习了一些东西、整理了一些东西,如果不留下点什么,好像就没有学过的痕迹,有一种,学习了,但是不知道学了啥的感觉,就跟自己的人生一样,也有那么点漫不经心在里面,所以开始写一些博客,当做给自己的一种交代,如果恰巧帮助到需要的伙伴,也算日行一善了,给自己积点德。
比起写博客,录视频存粹是对自己的一种锻炼了,总是害怕表达,不敢表达,就从读自己的文章做起吧,以前总觉得,听自己念自己写的东西、表达自己的想法会有一种羞耻感,会有一种觉得自己不够好的感觉。我心里知道自己有很多不足,也听闻过别人夸我身上的一些优点,也许人总是不那么完美的,所以我应该学着欣赏自己、接纳自己身上不足的地方,其实有时候一个人身上的缺点才更显得人的真实和鲜活吧。
阅读一贯是对自己的要求,但是我自知看书比较慢,过程中还容易发散思维,现在又喜欢摘抄做笔记,写写字能让自己的心定一定,所以对自己没有速度上的要求,今年主要在看的有三本,《置身事内》、《毛选1》,和《一读就懂的18堂中医入门课》,同时也听了一点喜马拉雅上蒙曼对红楼梦的解读。
今年确实比过去有了更多反思自己过去所作所为的时间,有时候会想,自己发展到现状是有迹可循的吗?其实就跟所有的历史发展是类似的,其中有一定的偶然性、也有一定的必然性,假如我早早听从了家里的建议,考进老家的体制内,也不会有在外面的种种,假如在毕业时选择条件更好的另一家公司,假如我没有因为一时冲动做出的决定....可是一切都没有假如,一切都已经发生,过去的无法改变。
唯一能做的,就是再去仔细想想,是否还有遗漏的点,是否还能从中得到什么经验和教训。
总体而言,除去被诈骗这件糟心事,今年整体过得其实还算挺充实的,虽然跟家里也起过一些争执,回过头看,也让彼此加深了了解,可以说是有得有失的一年。
说到24年的规划,作为infp实在不擅长做规划和执行规划,只有唯一的一点展望:每天进步一点点。
在软件开发的世界里,虽然技术日新月异,但有些原则是经久不衰的。就像建房子需要坚实的地基,软件开发也有其基础原则。它们像是指南针,帮助开发者在变化莫测的技术海洋中保持方向。接下来,我们就来聊聊这三个基本原则:DRY、KISS和YAGNI。
想象一下,你你在家自己做土豆丝夹饼,如果你家有三口人需要做三个,你不会每次都重新和面、烤饼、切土豆丝,调配同样的调料吧?这不仅效率低下,而且很难保证味道一致。你会一次性准备好所有的面饼,然后一次性切好所有的土豆丝,预先调制好所有的调料,这样更高效。这就是DRY原则的精髓——不要做重复的事情。

通过将重复的逻辑提取出来,形成独立的模块或函数,我们的代码变得更加整洁、易于管理。这就像我们制作每一个土豆丝夹饼时,因为已经提前做好了准备,只需要从烤箱中把饼拿出来,从菜盆中夹出土豆丝,从调料盒中挖出调料,而不是每次从和面烤饼开始。这样的组织让做饭过程更加高效和一致。
public class Calculator {
// DRY - 将加法逻辑提取到一个方法中,避免在多处重复
public int add(int a, int b) {
return a + b;
}
// 其他操作也应该遵循DRY原则
public int subtract(int a, int b) {
return a - b;
}
}让我们继续用美食做比喻。如果你的土豆丝夹饼食谱需要30种配料,而实际上只需要3种就能做出美味的饼,那这个食谱显然过于复杂了。KISS原则告诉我们,保持简单直接非常重要。

一个简单的设计意味着更少的错误,更容易的维护,就像简单的食谱更容易掌握,结果也更加可靠。
public class SimpleTask {
// KISS - 使用简单直接的方法来计算两个整数的和
public int add(int a, int b) {
return a + b;
}
// 这个方法违反了KISS原则,因为它过于复杂
public int add(int a, int b) {
// 使用一个数组来存储参数
int[] numbers = new int[2];
numbers[0] = a;
numbers[1] = b;
// 使用流来计算和,这在这种情况下是不必要的复杂性
return Arrays.stream(numbers).reduce(0, (subtotal, element) -> subtotal + element);
}
}如果你只是做几个土豆丝夹饼,你不会去买一个和面机吧?除非你打算经常自制烧饼,否则这显然是不必要的。这就是YAGNI原则的核心——不要添加当前不需要的功能。

YAGNI原则鼓励我们专注于当前的需求,而不是过度设计未来可能也可能不会用到的功能。这就像是在购物时,只买你当天晚餐需要的材料,而不是囤积一大堆可能永远不会用到的食材。
public class UserService {
// 当前只需一个方法来添加用户
public int add(String userName,int age) {
...
}
// 不要预先添加额外的方法,例如删除用户,除非有明确的当前需求
// public double delete(int userId) {
// ...
// }
}软件开发就像是编织一张网,DRY、KISS和YAGNI这三个原则就是那些帮助我们编织出强韧而灵活网格的工具。它们指导我们避免重复,保持简单,不做无用功。当我们遵循这些原则时,我们能够创造出更加可靠、易于维护且满足用户需求的软件产品。
就像做饭时,遵循一些基本原则,我们才能做出既美味又健康的土豆丝夹饼。
在Kotlin中,委托属性(Delegated Properties)是一种强大的语言特性,允许你将属性的 getter 和 setter 方法的实现委托给其他对象。这使得你能够通过委托来重用代码、将属性的行为解耦,并实现一些通用的模式。下面是一些关键概念和用法:
classExample {varproperty: String by Delegate()
}classDelegate {operator fun getValue(thisRef: Any?, property: KProperty<*>): String {//获取属性值的实际实现 return "Delegated value"}operator fun setValue(thisRef: Any?, property: KProperty<*>, value: String) {//设置属性值的实际实现 println("Setting value to: $value")
}
}
在上面的代码中,Example类中的property属性的访问,比如,访问example.property,就会委托到Delegate.getValue; 属性值的设置example.property = "str",就会委托到
Delegae.setValue。
实际例子:
fun saveCookie(url: String?, domain: String?, cookies: String) {
url?: return varspUrl: String by Preference(url, cookies)
@Suppress("UNUSED_VALUE")
spUrl=cookies
domain?: return varspDomain: String by Preference(domain, cookies)
@Suppress("UNUSED_VALUE")
spDomain=cookies
}
var spUrl: String by Preference(url, cookies),定义一个委托属性spUrl,Preference委托,执行spUrl = cookies,会将这个setValue的动作委托到Preference类中的setValue。
operator fun setValue(thisRef: Any?, property: KProperty<*>, value: T) {
putSharedPreferences(name, value)
}
其中value的值是cookies.如果要访问spUrl,那么,对应的getValue方法,会被委托到Preference中的getValue方法中去。
总结来说:
委托属性,就是将一个属性的getValue方法和setValue方法委托到另外一个代理类来实现。将属性的获取和设置隔离开来。
class Preference<T>(val name: String, private val default: T) {
companionobject{private val file_name = "wan_android_file" privateval prefs: SharedPreferences by lazy {
App.context.getSharedPreferences(file_name, Context.MODE_PRIVATE)
}/**
* 删除全部数据*/fun clearPreference() {
prefs.edit().clear().apply()
}/**
* 根据key删除存储数据*/fun clearPreference(key: String) {
prefs.edit().remove(key).apply()
}/**
* 查询某个key是否已经存在
*
* @param key
* @return*/fun contains(key: String): Boolean {returnprefs.contains(key)
}/**
* 返回所有的键值对
*
* @param context
* @return*/fun getAll(): Map<String, *>{returnprefs.all
}
}operator fun getValue(thisRef: Any?, property: KProperty<*>): T {return getSharedPreferences(name, default)
}operator fun setValue(thisRef: Any?, property: KProperty<*>, value: T) {
putSharedPreferences(name, value)
}
@SuppressLint("CommitPrefEdits")private fun putSharedPreferences(name: String, value: T) =with(prefs.edit()) {
when (value) {is Long ->putLong(name, value)is String ->putString(name, value)is Int ->putInt(name, value)is Boolean ->putBoolean(name, value)is Float ->putFloat(name, value)else ->putString(name, serialize(value))
}.apply()
}
@Suppress("UNCHECKED_CAST")private fun getSharedPreferences(name: String, default: T): T =with(prefs) {
val res: Any= when (default) {is Long -> getLong(name, default)is String -> getString(name, default) ?: "" is Int -> getInt(name, default)is Boolean -> getBoolean(name, default)is Float -> getFloat(name, default)else -> deSerialization(getString(name, serialize(default)) ?: "")
}return res asT
}/**
* 序列化对象
* @param person
* *
* @return
* *
* @throws IOException*/@Throws(IOException::class)private fun <A>serialize(obj: A): String {
val byteArrayOutputStream=ByteArrayOutputStream()
val objectOutputStream=ObjectOutputStream(
byteArrayOutputStream
)
objectOutputStream.writeObject(obj)var serStr = byteArrayOutputStream.toString("ISO-8859-1")
serStr= java.net.URLEncoder.encode(serStr, "UTF-8")
objectOutputStream.close()
byteArrayOutputStream.close()returnserStr
}/**
* 反序列化对象
* @param str
* *
* @return
* *
* @throws IOException
* *
* @throws ClassNotFoundException*/@Suppress("UNCHECKED_CAST")
@Throws(IOException::class, ClassNotFoundException::class)private fun <A>deSerialization(str: String): A {
val redStr= java.net.URLDecoder.decode(str, "UTF-8")
val byteArrayInputStream=ByteArrayInputStream(
redStr.toByteArray(charset("ISO-8859-1"))
)
val objectInputStream=ObjectInputStream(
byteArrayInputStream
)
val obj= objectInputStream.readObject() asA
objectInputStream.close()
byteArrayInputStream.close()returnobj
}
}
公众号「架构成长指南」,专注于生产实践、云原生、分布式系统、大数据技术分享
时序数据库有很多,比如Prometheus、M3DB、TimescaleDB、OpenTSDB、InfluxDB等等。Prometheus和VictoriaMetrics是开源的时间序列数据库,在复杂的环境中提供了强大的监控和警报解决方案。然而,它们的设计不同,并提供了独特的功能,这些功能可能会影响它们在监视工作负载方面的性能、可扩展性和易用性。本文分析Prometheus和VictoriaMetrics之间的差异,以为特定需求的用户提供最合适的解决方案。
Prometheus
最初是 SoundCloud 中的一个项目,是一个功能强大的监控和警报工具包,专门用于处理多维环境中的时间序列数据。由于其对多维数据收集、查询和警报生成的本机支持,它在 SRE 和 DevOps 社区中变得非常受欢迎。
Prometheus 是在云原生计算基金会 (CNCF) 下开发的。Prometheus 服务器、客户端库、Alertmanager 和其他相关组件可以在 Prometheus GitHub 组织中找到。主要存储库是:
https://github.com/prometheus/prometheus
VictoriaMetrics
则是一个高性能、高性价比、可扩展的时间序列数据库,可以作为Prometheus的长期远程存储。它拥有超强的数据压缩和高速数据摄取能力,使其成为大规模监控任务的有吸引力的替代方案。VictoriaMetrics源代码可以在以下位置找到:
https://github.com/VictoriaMetrics/VictoriaMetrics
VictoriaMetrics 与 Prometheus 之间的数据摄取和查询率性能基于使用指标的基准node_exporter`测试。内存和磁盘空间使用情况数据适用于单个 Prometheus 或 VictoriaMetrics 服务器。
| 比较 | Prometheus | VictoriaMetrics |
|---|---|---|
| 数据采集 | 基于拉动 | 基于拉式和推式 |
| 数据摄取 | 每秒高达 240,000 个样本 | 每秒高达 360,000 个样本 |
| 数据查询 | 每秒高达 80,000 次查询 | 每秒高达 100,000 次查询 |
| 内存使用情况 | 高达 14GB RAM | 高达 4.3GB 的 RAM |
| 数据压缩 | 使用LZF压缩 | 使用 Snappy 压缩 |
| 磁盘写入频率 | 更频繁地将数据写入磁盘 | 减少将数据写入磁盘的频率 |
| 磁盘空间使用情况 | 需要更多磁盘空间 | 需要更少的磁盘空间 |
| 查询语言 | PromQL | MetricsQL(向后兼容 PromQL) |
Prometheus
使用基于PUll模型来收集指标,可以处理多达数百万个活动时间序列。该架构虽然简化了监控服务方的操作。但是也有一定的弊端,比如多个实例抓取的是相同的监控指标,不能保证采集的数据值为一致的,并且在实际的使用中可能遇到网络延迟问题,所以会产生数据不一致的问题,不过对于监控报警这个场景来说,一般不会要求数据的强一致性,所以从业务上来说是可以接受,因为这种数据不一致性影响基本上没什么影响。这种场景适合监控规模不大,只需要保存短周期监控数据的场景。
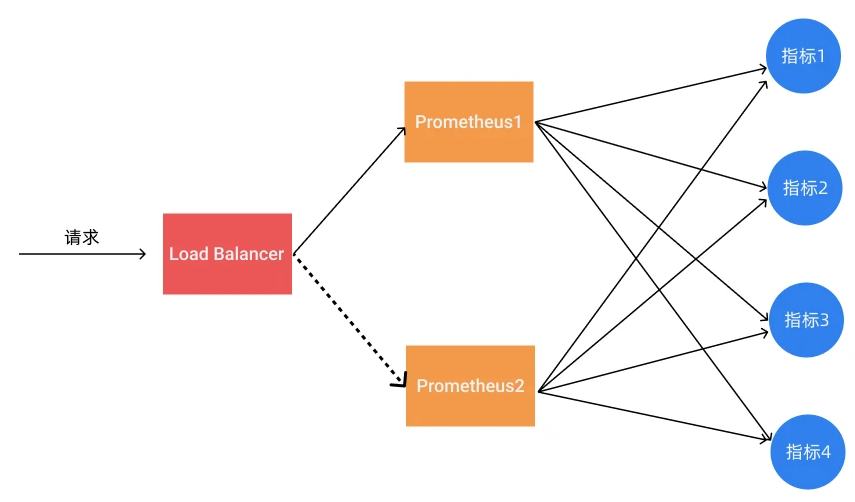
而 VictoriaMetrics
支持pull模型和Push模型。它能够处理大量数据和更广泛的网络场景(得益于其推送模型支持),使其具有可扩展性和灵活性。
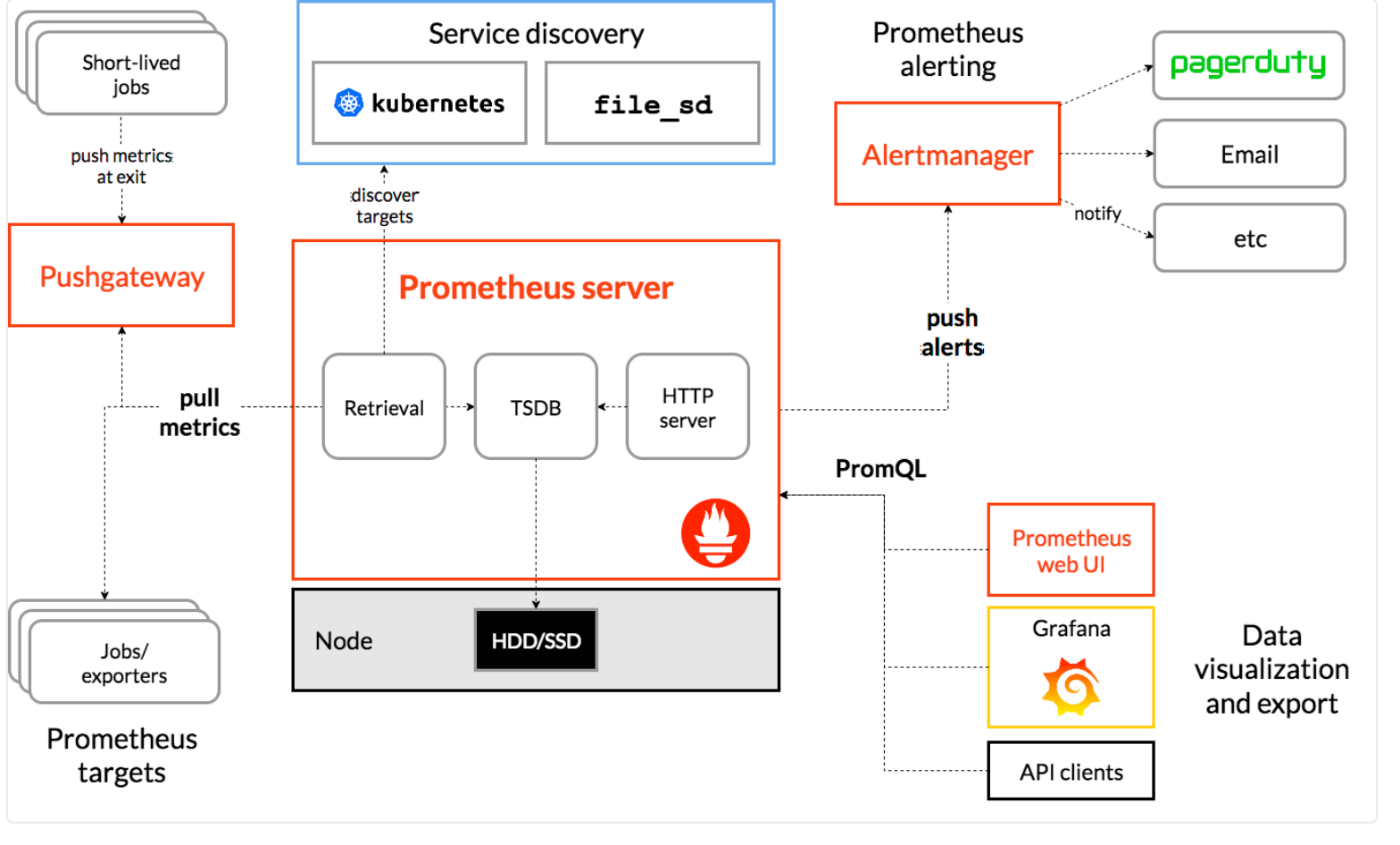
Prometheus的架构由四个主要组件组成:
Prometheus Server
:Prometheus Server是Prometheus的核心组件,主要负责从各个目标(target)中收集指标(metrics)数据,并对这些数据进行存储、聚合和查询。
Client Libraries
:Prometheus提供了多种客户端库,用于在应用程序中嵌入Prometheus的指标收集功能。
Exporters
:Exporters是用于将第三方系统的监控数据导出为Prometheus格式的组件。Prometheus支持多种Exporters,例如Node Exporter、MySQL Exporter、HAProxy Exporter等。
Alertmanager
:Alertmanager是Prometheus的告警组件,用于根据用户定义的规则对监控数据进行告警。
服务发现
:Prometheus 支持各种服务发现机制,帮助它找到应该抓取的目标。
PromQL
:这是 Prometheus 内置的灵活查询语言,用于数据探索和仪表板,与 SQL 不同。
VictoriaMetrics 提供
单机版
和
集群版
。如果您的每秒写入数据点数小于100万(这个数量是个什么概念呢,如果只是做机器设备的监控,每个机器差不多采集200个指标,采集频率是10秒的话每台机器每秒采集20个指标左右,100万/20=5万台机器),VictoriaMetrics 官方默认推荐您使用单机版,单机版可以通过增加服务器的CPU核心数,增加内存,增加IOPS来获得线性的性能提升。且单机版易于配置和运维。
下面这是一个集群版的架构图
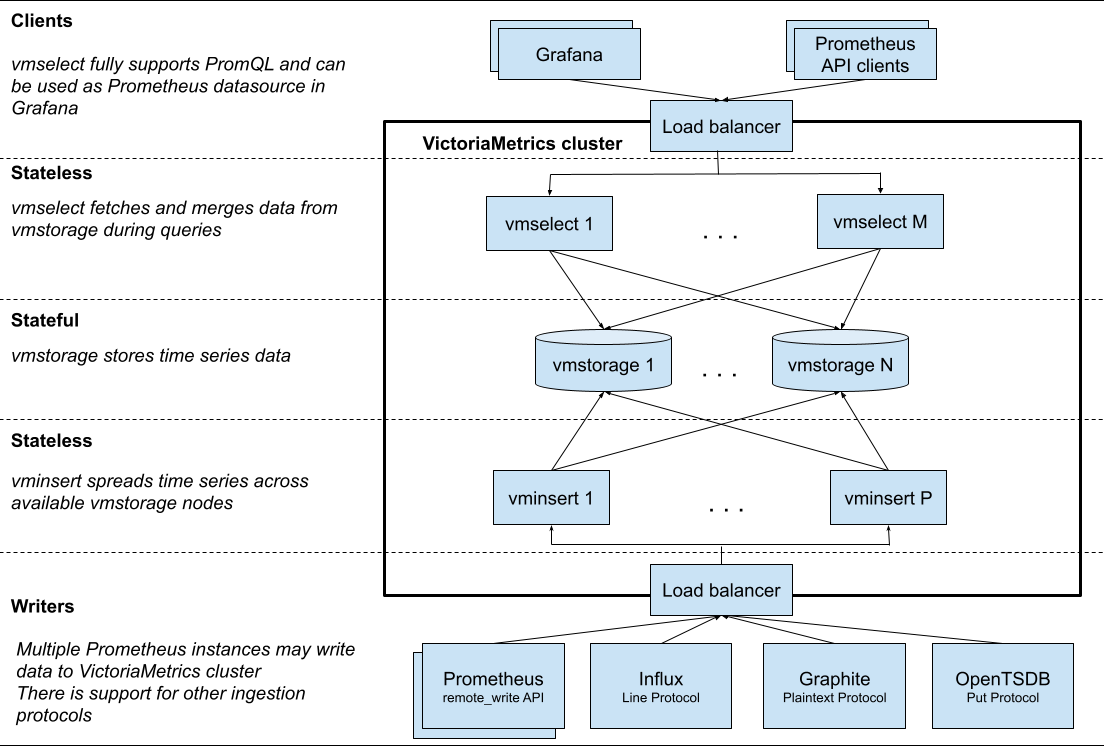
VictoriaMetrics在保持更简单的架构的同时,还包括几个核心组件:
vmstorage
vminsert
vmselect
vmagent
vmalert
Prometheus拥有高效的存储系统,但在长期数据存储后端和检索效率方面不如VictoriaMetrics。
VictoriaMetrics 相对于 Prometheus 的主要优势之一是其数据压缩功能。它的数据压缩算法,可显着降低存储要求。VictoriaMetrics 声称提供比 Prometheus 高出 10 倍的数据压缩,这是长期数据保留和成本优化的关键优势。
head block
checkpointing
1.内存存储:与 Prometheus 类似,VictoriaMetrics 使用内存存储在传入数据写入磁盘之前进行缓冲。这种方法有助于优化写入性能。同事还缓存经常访问的数据以加快检索速度。
2.磁盘存储:VictoriaMetrics 中的大部分数据存储在磁盘上。它使用一种高效的存储格式,可以实现大幅度的进行数据压缩。
Prometheus
使用
PromQL
。PromQL 允许实时选择和聚合时间序列数据。它使我们能够高度灵活地使用指标。通过 PromQL,用户可以过滤和聚合指标,计算比率、比率、平均值和百分位数等指标。
VictoriaMetrics向后兼容 PromQL。我们都可以按照理解的 PromQL 语法来进行查询。但是,它还引入了 PromQL 的扩展,称为
MetricsQL
。MetricsQL 增强了 PromQL 提供的查询功能。它引入了新函数、运算符和语法糖。简化并改善了用户体验,特别是对于复杂的查询和聚合。
Prometheus 本身并不支持集群,这意味着它不提供原生高可用性。高可用性可以通过运行重复实例来实现,或者thanos架构,当然也可以整合VictoriaMetrics。
而VictoriaMetrics 在设计时就考虑到了高可用性。它使用复制和集群来确保在实例发生故障时数据不会丢失,从而成为了很多大厂的选择。
Prometheus和VictoriaMetrics都提供了基于 Http的 API接口,已满足客户端调用需求
VictoriaMetrics提供了一个全面的HTTP API,根据功能分为几个部分:
适用于Prometheus的指标API:此API与Prometheus的HTTP API兼容,这意味着可以将VictoriaMetrics作为Prometheus的替代品。
InfluxDB API:VictoriaMetrics还提供与InfluxDB的写入和查询API兼容的API。这使得从InfluxDB切换到VictoriaMetrics也很容易。
Graphite API:VictoriaMetrics还为Graphite的API提供了一个兼容层。
MetricsQL和PromQL API:这些API用于查询存储在VictoriaMetrics中的指标数据。MetricsQL是VictoriaMetrics特定的
PromQL扩展,提供了PromQL中不可用的额外功能。
由于 VictoriaMetrics兼容Prometheus,所以在 在 Grafana 进行可视化配置时,可以使用“Prometheus”数据源,并将 Url 设置为VictoriaMetrics Server 地址即可。
以上我们总结Prometheus与VictoriaMetrics的各个方面的对比,虽然VictoriaMetrics在某些方面可能比Prometheus更强大,比如在处理大规模数据和高并发负载时的性能表现,完全可以替换Prometheus,但它相对来说是相对较新的项目,尚未达到Prometheus在用户社区和广泛采用方面的水平。此外,Prometheus的发展时间更早,是CNCF第二个毕业的项目,已经得到了大量用户的验证,并且有更多的文档、教程和案例可供参考。
此外,技术的流行和广泛采用并不仅仅取决于技术本身的性能,还受到多个因素的影响,包括市场宣传、社区支持、用户体验和可用性等。Prometheus在这些方面都做得相对较好,因此在监控领域更为流行和广泛采用。
如果本篇文章对您有所帮助,麻烦帮忙一键三连(
点赞、转发、收藏
)~
扫描下面的二维码关注我们的微信公众帐号,在微信公众帐号中回复◉加群◉即可加入到我们的技术讨论群里面共同学习。

参考
https://last9.io/blog/prometheus-vs-victoriametrics/
https://www.qikqiak.com/post/victoriametrics-usage/