平衡二叉搜索树
平衡二叉搜索树(Balanced Binary Search Tree)的每个节点的左右子树高度差不超过 1,它可以在 O(logn) 时间复杂度内完成插入、查找和删除操作,最早被提出的自平衡二叉搜索树是 AVL 树。
AVL 树在执行插入或删除操作后,会根据节点的平衡因子来判断是否平衡,若非平衡则执行旋转操作来维持树的平衡,本文主要是对红黑树相关的讲解,如果大家感兴趣可以去了解一下 AVL 树相关的知识,在这里不做赘述。
2-3 搜索树
标准二叉树中的节点称为 2-节点(含有一个键和两个指针),为了保证二叉搜索树的平衡性,需要增加一些灵活性,增加 3-节点(含有两个键和三个指针)。2-节点的指针和 3-节点的指针对应的区间大小关系如下:
我们先来看一下一棵2-3搜索树的样例:
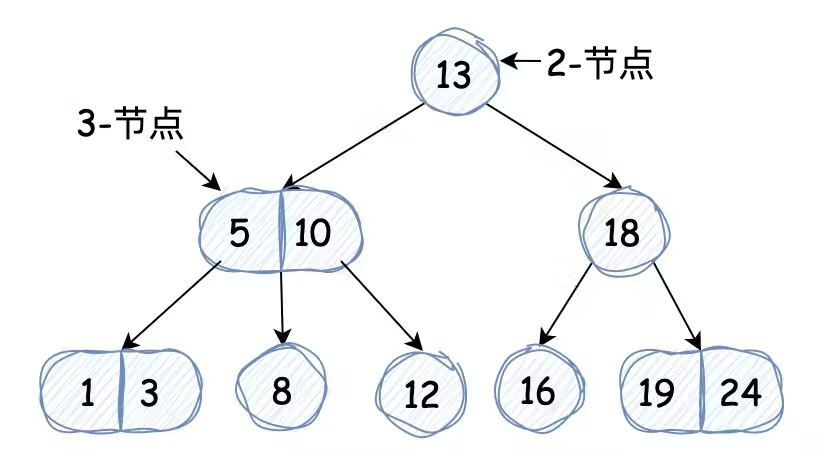
这里需要注意:2-3搜索树无论如何增删节点,它
始终都能维持完美的平衡性
,看下文时要牢记这一点。
3-节点的引入是如何保证树平衡的?
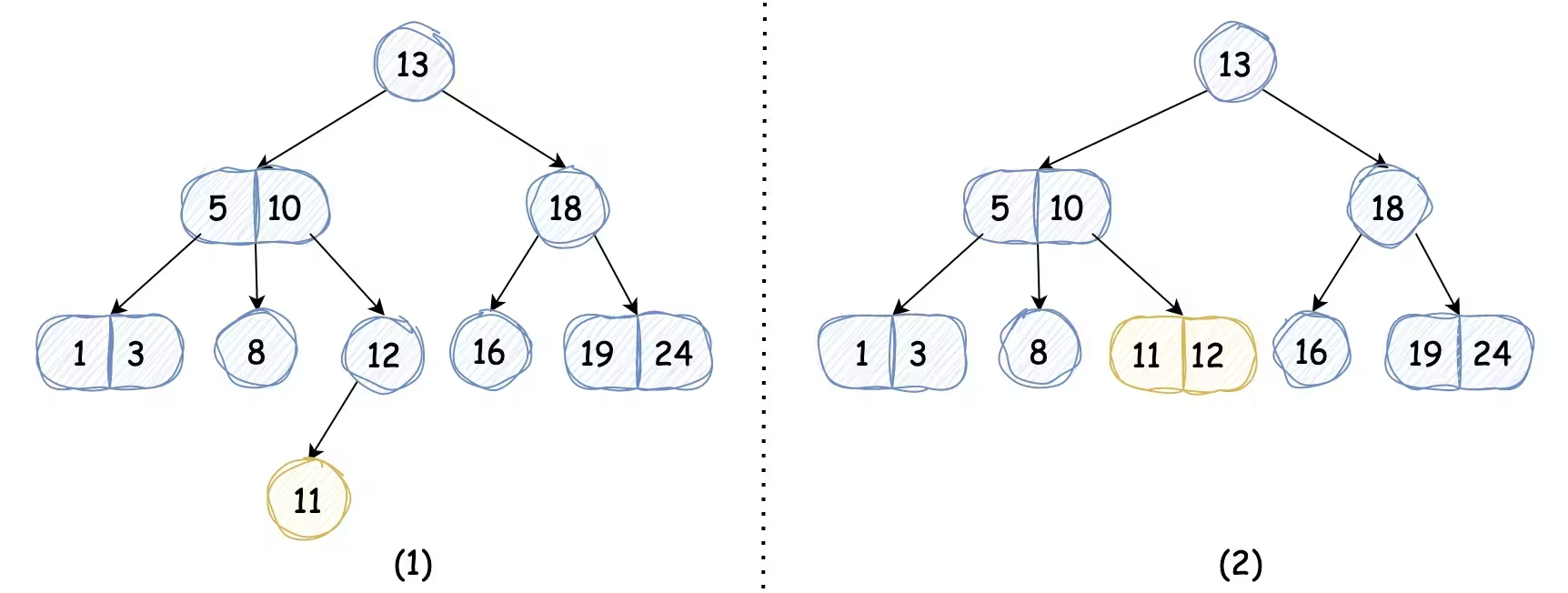
我们以插入键值 11 的节点为例,它会查找到该键对应的位置为 12 节点的左子树,如果我们未引入3-节点,那么树高会增加,如下图中(1)所示,而我们引入3-节点后,我们只需将2-节点替换为3-节点,而不会导致树高的增加,2-3搜索树依然完美平衡,如下图中(2)所示:
我们接着看,如果我们插入的键值为 26,它会查找到该键的位置为 19 和 24 这个3-节点,因为这个节点中已经没有多余的键的位置了,所以26键只能放在右子树的位置,使得树高加一。不过我们可以通过巧妙的方法,先将该节点转换为4-节点,一个4-节点又能转换成 3 个 2-节点, 我们将这 3 个2-节点的根节点(4-节点的中键值)插入到原来的父节点中,那么树高仍能保持不变(完美平衡),如下图所示:
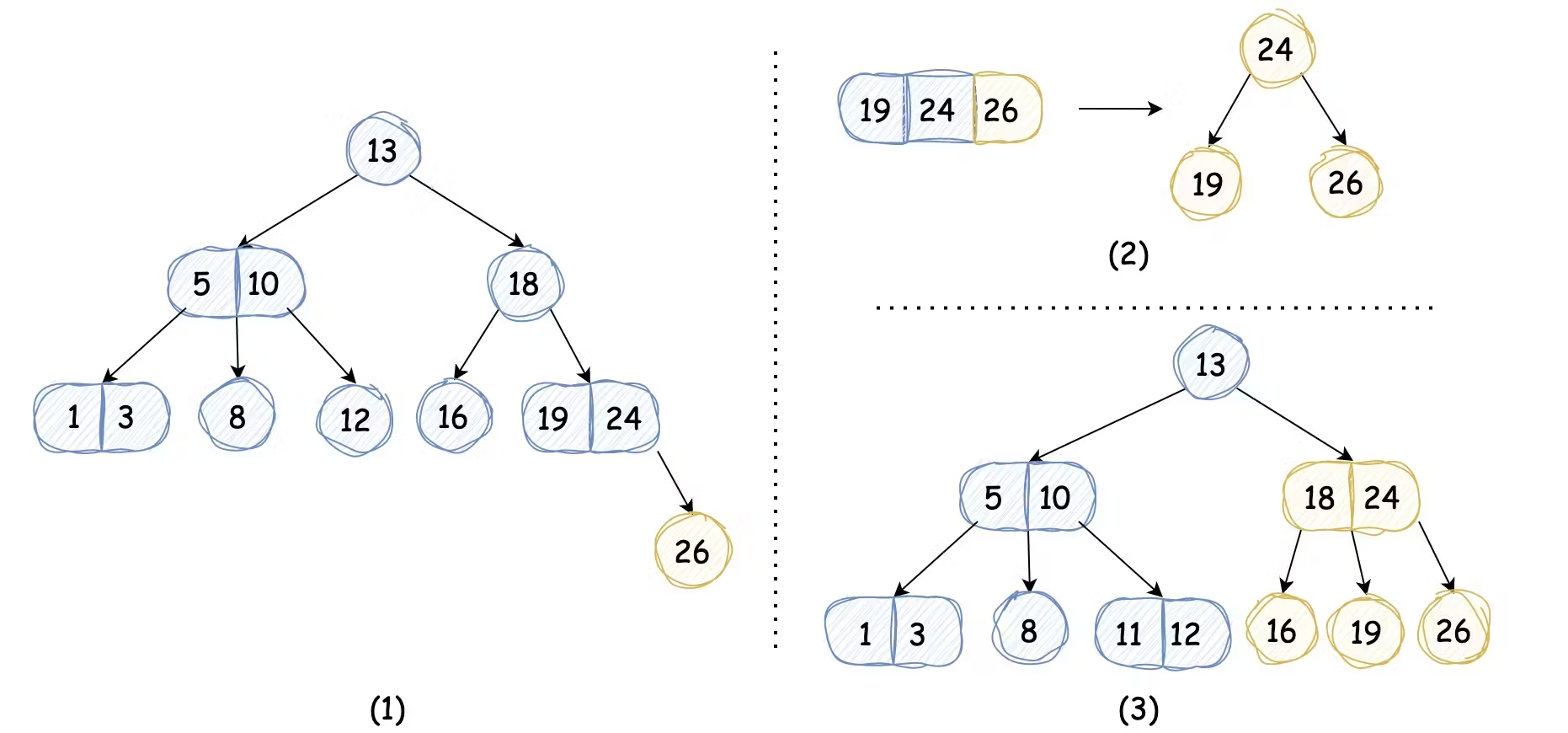
虽然我们临时借助了4-节点,但是最终变换完毕后,整棵树还是依然是由2-节点和3-节点组成的。
我们再插入键值为4的节点会如何呢?它会查找到1和3这个3-节点的位置,还是采用相同的办法,将其转换成4-节点,但是转换完后准备将它插入到原来的父节点时,会发现父节点也是3-节点,这就导致我们不得不再次使用同样的方法,这样推广到一般情况,
需要不断地分解临时的4-节点并将其中键插入到更高的父节点中,直到遇到一个2-节点并将其转换成不需要分解的3-节点或者到达为2-节点的根节点
,如下图所示:
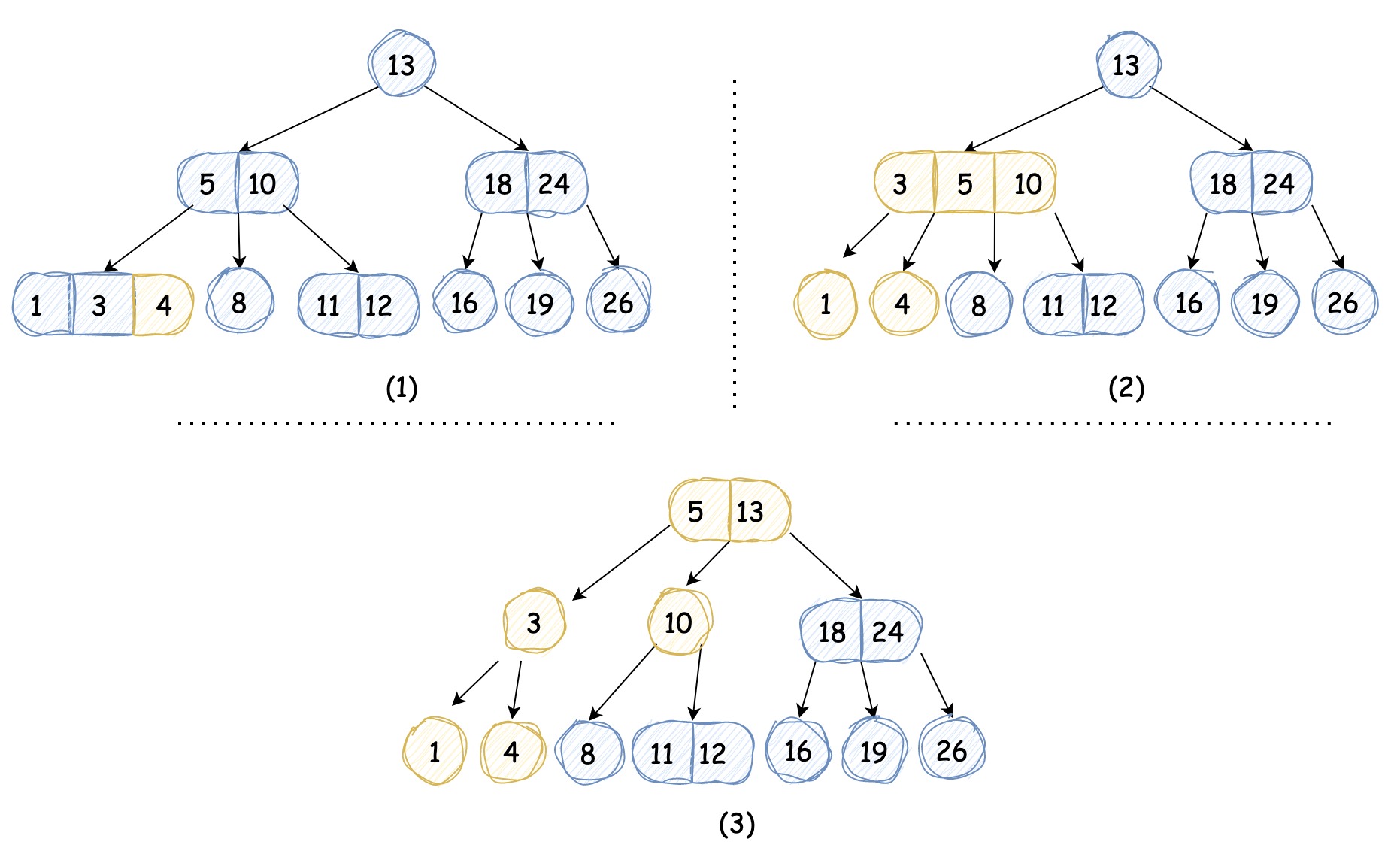
那如果处理到根节点时,根节点仍然为3-节点呢?其实原理是一样的,只不过根节点没有父节点,不需要再将4-节点的中键向上合并,转换成3个2-节点即可,相应地树高会加一。
在以上所述的情况中,2-3树的插入算法使树本身结构发生的改变是
局部
的,除了相关的节点和引用之外,不必修改和检查树的其他部分,这些局部变换不会影响到树的全局有序性和平衡性,在插入的过程中,
2-3树始终是完美平衡二叉树
。
左倾红黑树(LLRBT)
学会了 2-3 树我们先来学习一种简单的红黑树,
左倾红黑树
,它是经典红黑树的变体,相对更容易实现。它的基本思想是用标准的二叉搜索树和“颜色信息”来表示2-3树:其中的链接分为两种,红链接将两个2-节点连接起来构成一个3-节点,黑链接是2-3树中的普通链接,如下图所示:
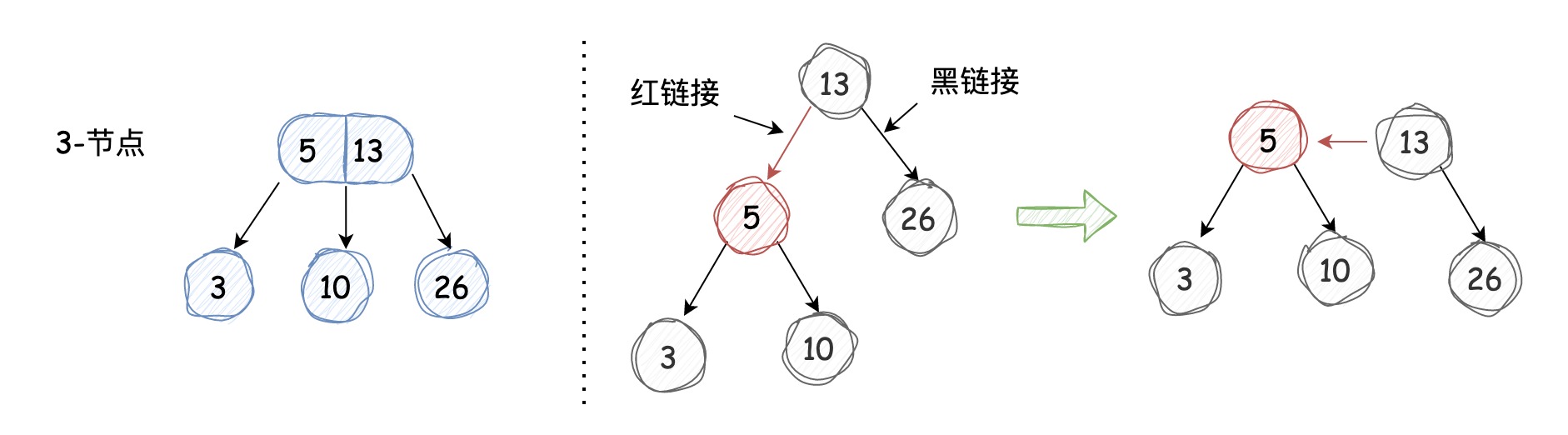
我们规定被红色链接指向的节点为红色节点,被黑色链接指向的节点为黑色节点,从上图中我们也能够发现:如果我们将红链接“横过来”,它和3-节点的表示是一样的,这就是在左倾红黑树中用颜色信息表示3-节点的方式,确切地说,3-节点是由两个2-节点组成,并且其中一个2-节点被另一个2-节点用
红链接左引用
。
可以说左倾红黑树就是一棵2-3搜索树,它满足如下条件:
2-3搜索树始终能保持完美平衡,那么任意叶子节点到根节点的距离是相等的。左倾红黑树又是一棵2-3搜索树,其中的黑链接是2-3搜索树中的普通链接,那么左倾红黑树中被黑色链接引用的黑色节点也必然是完美平衡的,所以任意叶子节点到根节点路径上的黑色节点数量必然相同。
性质我们已经理解了,接下来我们看看左倾红黑树的代码实现:
节点定义
上文我们已经规定,被红链接引用的节点为红色,被黑色链接引用的节点为黑色,我们在节点中添加
color
字段来标记颜色:
True
表示红色,
False
表示黑色,定义如下:
public class LeftLeaningRedBlackTree {
private static final boolean RED = true;
private static final boolean BLACK = false;
static class Node {
int key;
int value;
boolean color;
Node left;
Node right;
public Node(int key, int value, boolean color) {
this.key = key;
this.value = value;
this.color = color;
}
}
/**
* 判断节点是否为红色
*/
private boolean isRed(Node node) {
if (node == null) {
return false;
} else {
return node.color == RED;
}
}
}
旋转
插入和删除操作可能会使左倾红黑树出现红链接右引用或者左右引用都是红链接的情况,造成黑色不平衡,为了始终满足左倾红黑树的性质,我们需要通过旋转操作进行修复。
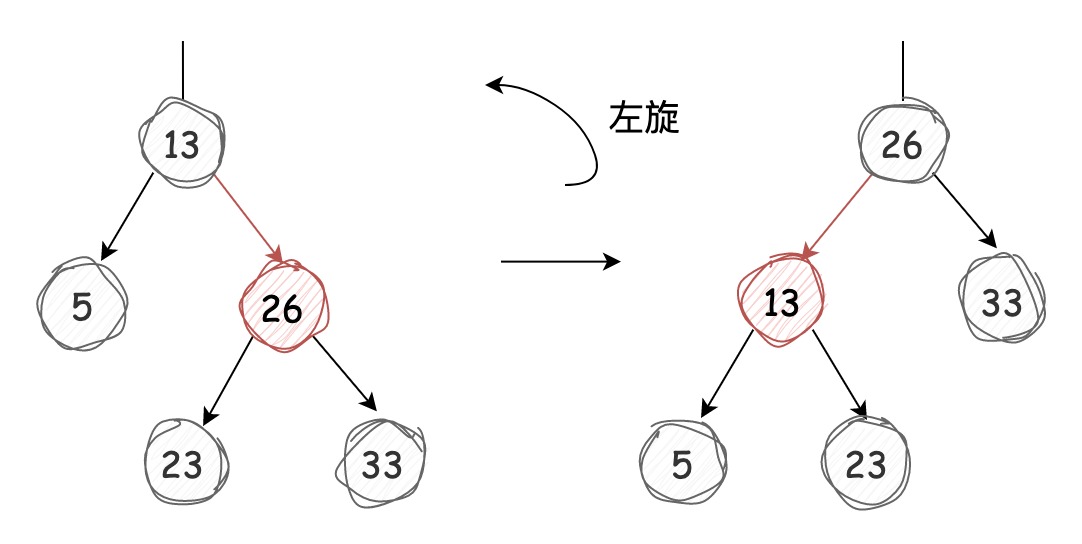
左旋
如果有红链接右引用,我们可以通过
左旋
操作将其调整为红链接左引用,过程如下图所示:
代码如下:
/**
* 左旋
*/
private Node rotateLeft(Node node) {
Node newRoot = node.right;
node.right = newRoot.left;
newRoot.left = node;
newRoot.color = node.color;
node.color = RED;
return newRoot;
}
旋转完成后可以发现,左旋是将两个键中较小的作为根节点转变为较大的作为根节点。
右旋
右旋是和左旋完全相反的动作,它能将红链接左引用旋转成红链接右引用,过程如下图所示:
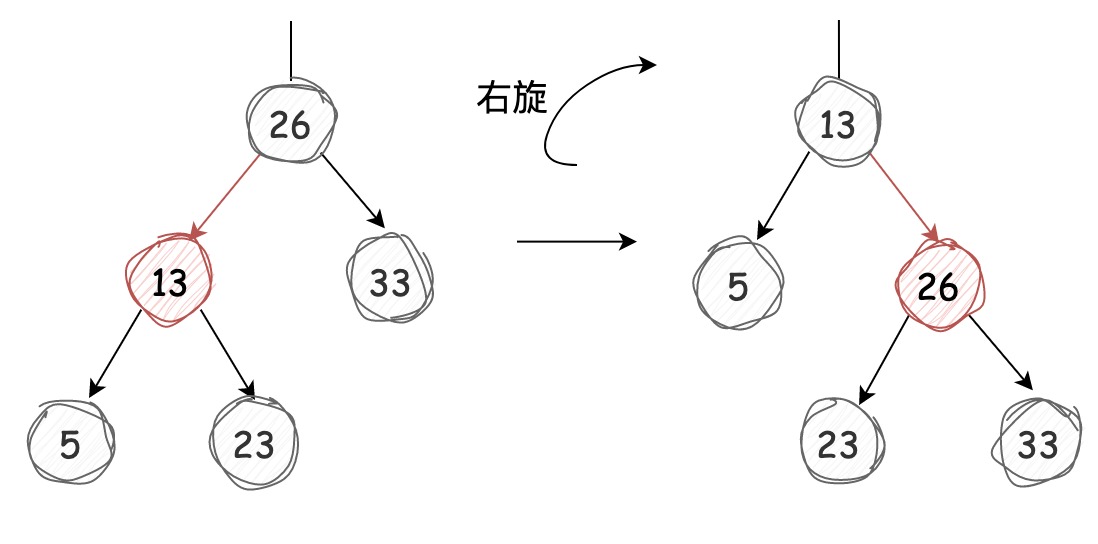
代码如下:
/**
* 右旋
*/
private Node rotateRight(Node node) {
Node newRoot = node.left;
node.left = newRoot.right;
newRoot.right = node;
newRoot.color = node.color;
node.color = RED;
return newRoot;
}
右旋是将两个键中较大的作为根节点转变为较小的作为根节点。
左旋和右旋的方法返回值都是
Node
,旋转完成后父节点对旋转节点的引用会发生改变,在插入节点时旋转操作可以保持左倾红黑树的
有序性
和
完美平衡性
,也就是说我们在红黑树中进行旋转时无需为它的有序性和完美平衡性担心。
插入节点
插入的每个节点默认红色,之后根据插入后节点颜色情况,使用旋转操作进行修复,我们分情况讨论:
向2-节点中插入
向2-节点中插入节点很简单:如果新键值比老键小,那么将该节点被老节点红链接左引用即可;如果新键值比老键大,那么该节点需要被老节点红链接右引用,因为左倾红黑树中红链接不能左引用,所以我们需要左旋进行调节,过程图示如下:
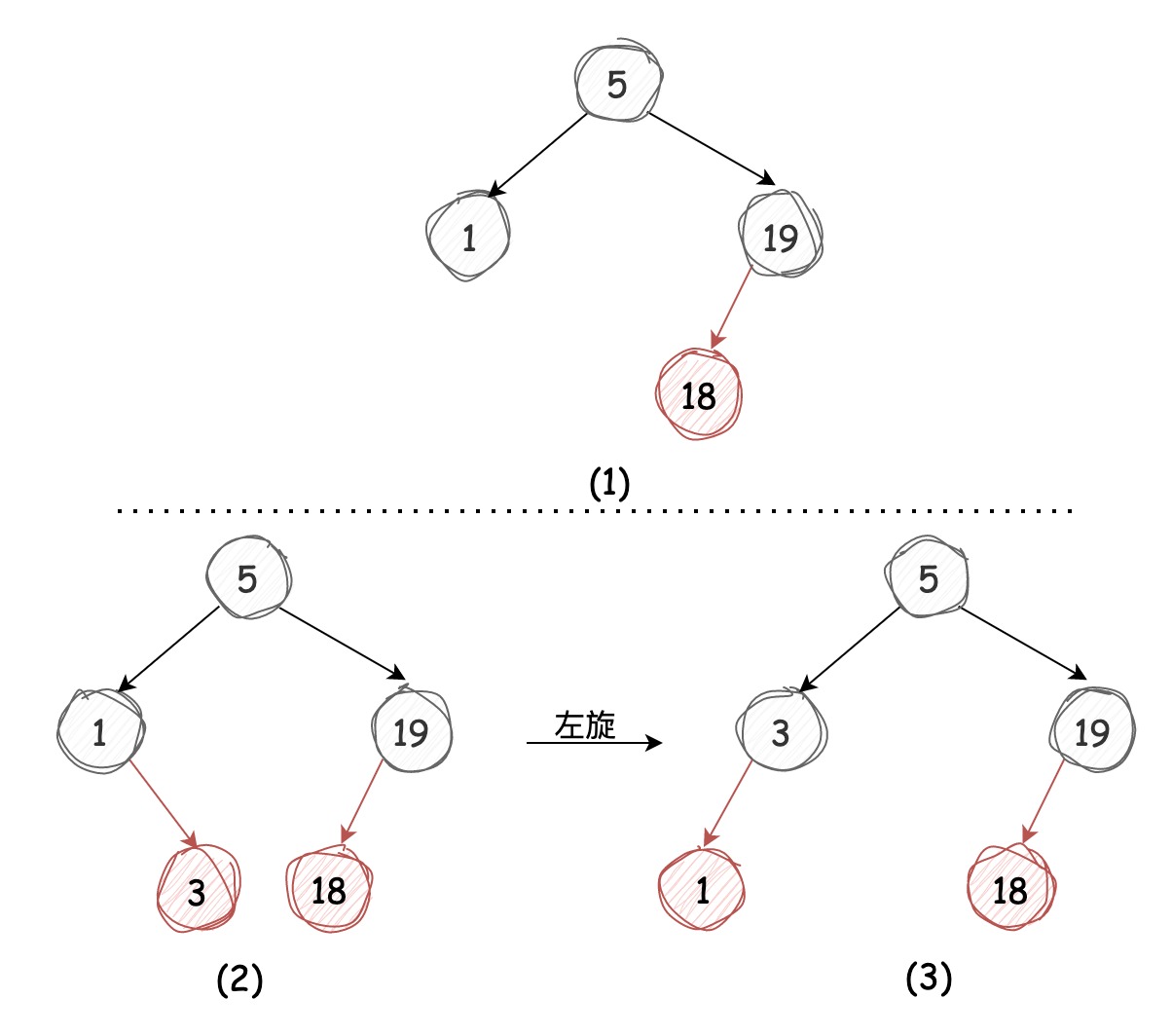
向3-节点中插入
向3-节点中插入分三种情况,我们分别进行讨论:
这种情况该节点被3-节点右引用,前文中我们说过,在3-节点中插入新节点可以临时转化成4-节点进行处理,4-节点又能转换成3个2-节点,那么我们得到的就是一颗树高为 2 的平衡树,此时根节点的左右引用均为红链接,我们可以将它们全部转换成黑链接(反色处理),如下图所示:
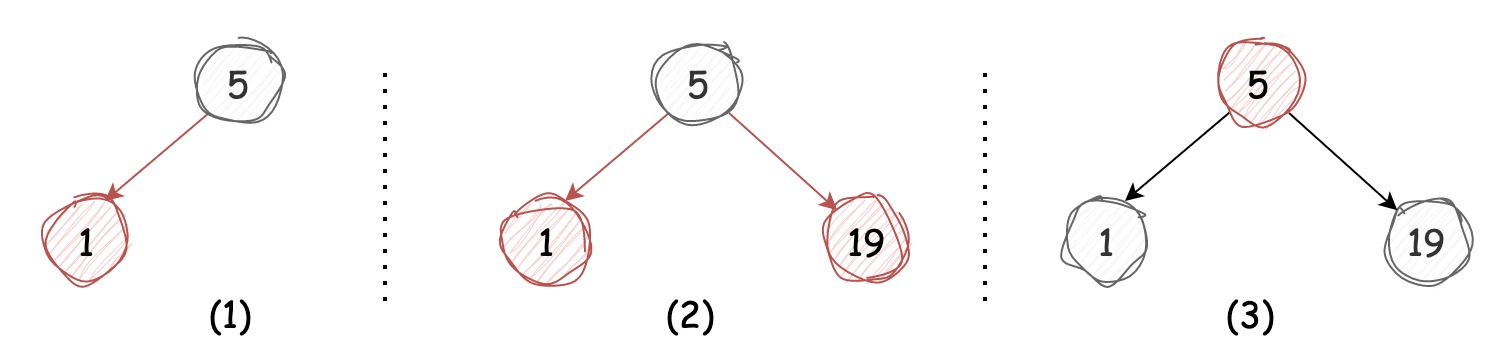
这种情况该节点被3-节点左引用,这样会出现两条红链接连续的情况,我们只需将上层的红链接右旋,这样便转换成了我们上述的第一种情况,过程如下图所示:
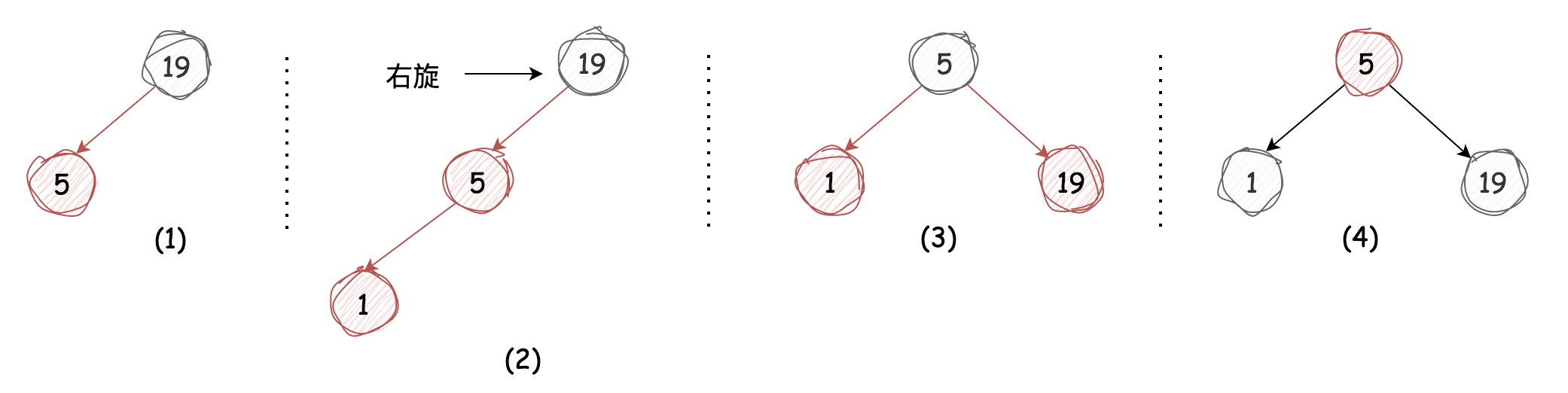
这种情况仍然会出现两条红链接连续的情况,我们只需要将下层的红链接左旋,便转换成了上述的第二种情况,过程如下图所示:
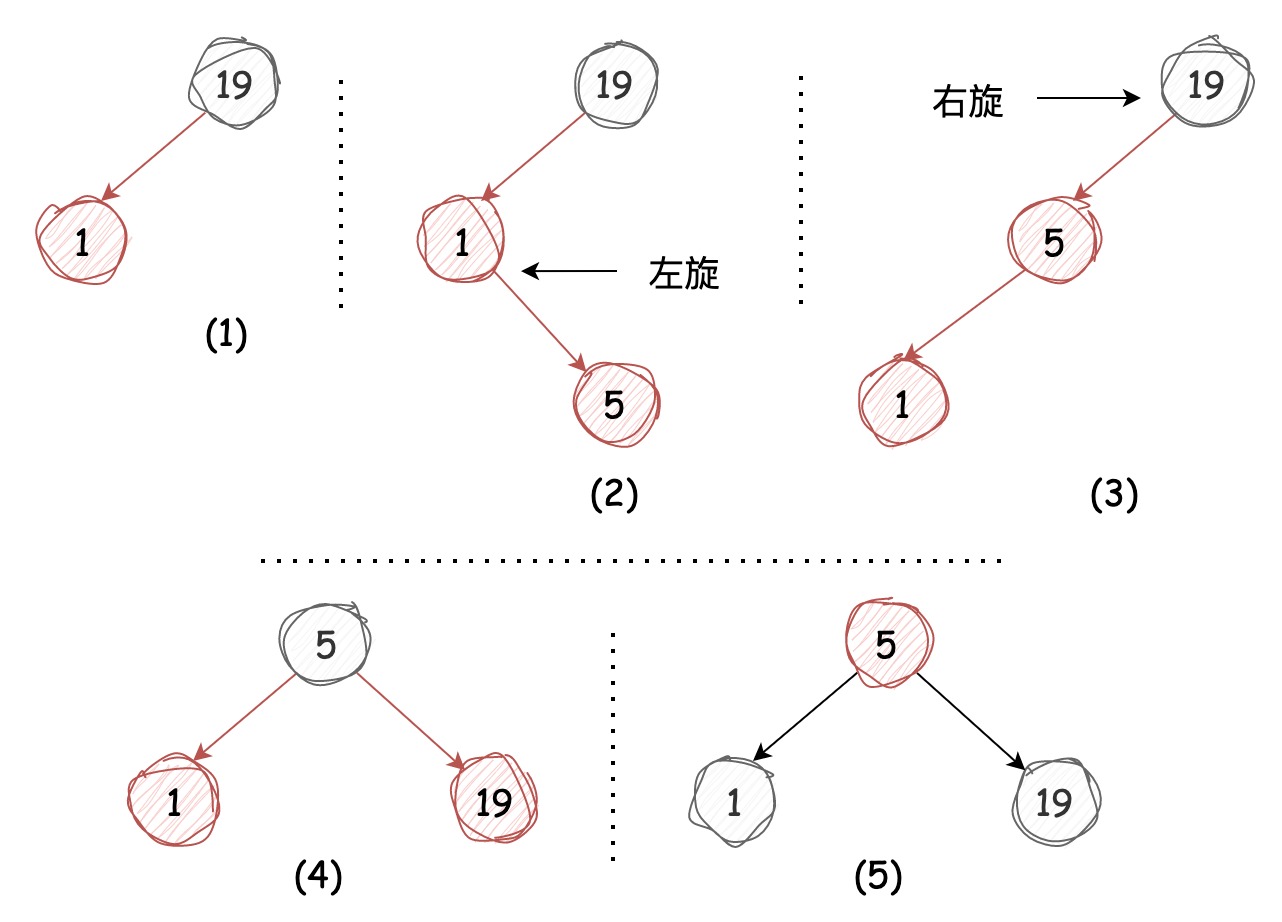
颜色转换
我们需要为上述将某个节点的两条红链接转换成黑链接的动作定义
flipColors
方法,在图示中能够发现除了将左右节点转换成黑色外,
该节点被转换成了红色
,颜色转换在本质上和旋转操作同样都是局部的,并
不会影响整棵树的黑色平衡性
。该节点颜色转换成红色后,
相当于将其送入了它的父节点,意味着在父节点插入了一个新键
,我们需要按照上述插入节点的对应情况进行处理。
/**
* 颜色转换
*/
private void flipColors(Node node) {
node.color = RED;
node.left.color = BLACK;
node.right.color = BLACK;
}
不过,这对于根节点来说,并不能完全按照这种规则进行颜色转换,因为如果根节点是红色的,那么说明根节点为3-节点中较小的节点,但实际上并非如此(根节点始终为其中较大的值)。所以我们
每次插入节点时需要保证根节点是黑色的
,而且
每当根节点由红色转变为黑色时,都意味着树高增加了 1
。
在3-节点中插入节点后,将临时转换成4-节点,并将4-节点的中键作为红色节点插入到它的父节点中(无论是左引用还是右引用),中键作为红色节点插入父节点无异于处理新插入一个红色节点,我们需要不断地重复这个过程,直到遇到根节点或2-节点,这样我们就能始终保持左倾红黑树和2-3搜索树的一一对应关系。
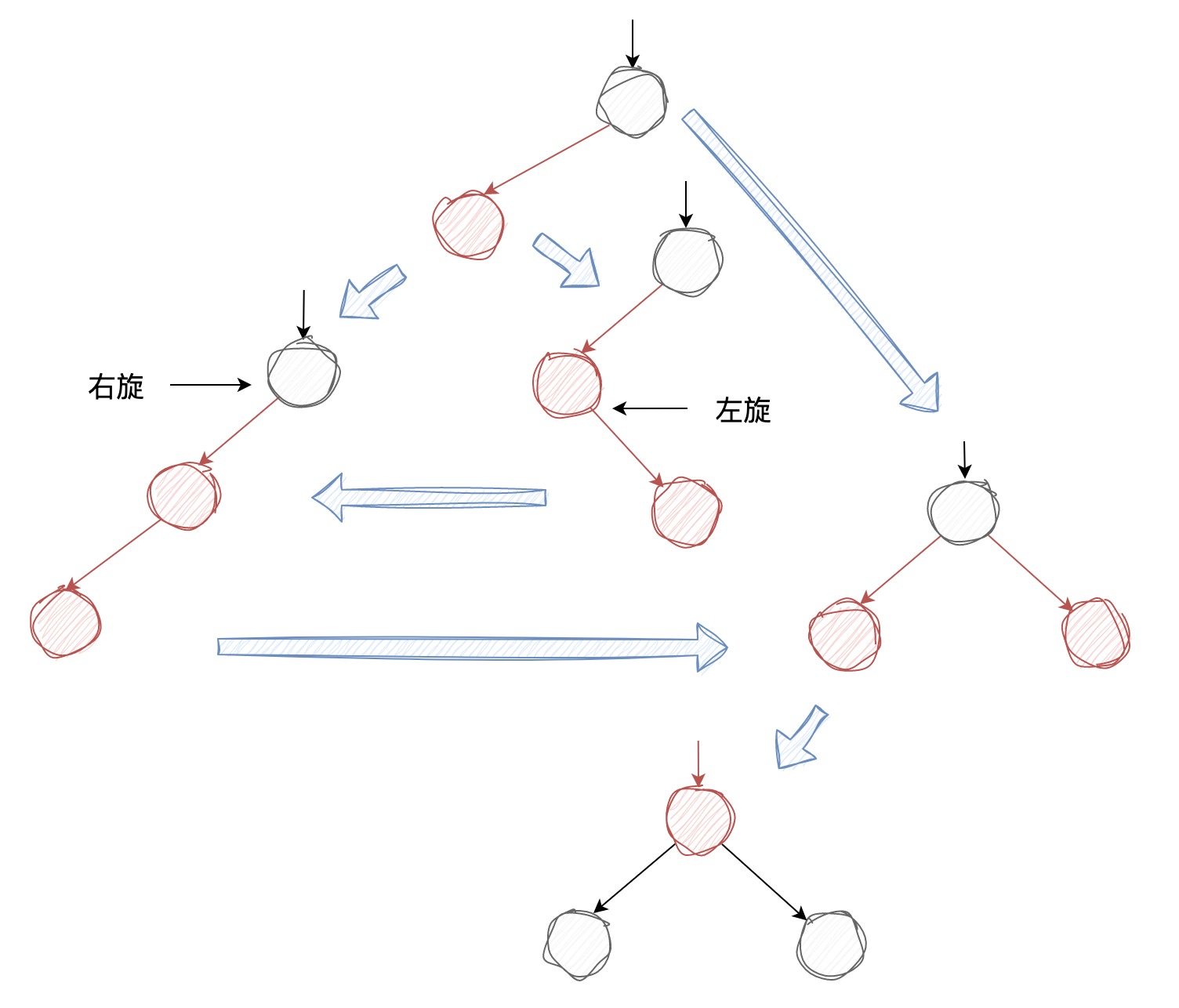
上图对应了节点插入后,执行旋转和颜色转换的所有情况。这些保持树平衡的操作需要在该插入节点到根节点路径上(回溯)的所有节点执行,规则如下:
如果某节点的右节点是红色,左节点为空或为黑色,需要左旋
如果某节点的左节点是红色,该左节点的左节点仍是红色,需要右旋
如果某节点的左节点和右节点均为红色,需要执行颜色转换
现在我们已经讨论了插入节点时所有可能出现的情况,接下来我们要实现左倾红黑树的插入方法。它的实现是在普通二叉搜索树的插入方法上进行了扩展,添加了保持树平衡性的逻辑,而平衡性的保持又是
由下到上
的,所以我们需要将旋转和颜色转换的逻辑放在递归逻辑之后,也就是我们在回溯时修复树的平衡,代码如下:
/**
* 插入节点
*/
public void put(Integer key, Integer value) {
root = put(root, key, value);
// 根节点永远都是黑色
root.color = BLACK;
}
/**
* 插入节点的执行逻辑
*/
private Node put(Node node, Integer key, Integer value) {
if (node == null) {
return new Node(key, value, RED);
}
if (key .key) {
node.right = put(node.right, key, value);
} else if (key .key) {
node.left = put(node.left, key, value);
} else {
node.value = value;
}
// 将3-节点的红链接右引用左旋
if (isRed(node.right) !isRed(node.left)) {
node = rotateLeft(node);
}
// 将4-节点两条连续的红链接左引用左旋
if (isRed(node.left) isRed(node.left.left)) {
node = rotateRight(node);
}
// 进行颜色转换并将红链接在树中向上传递
if (isRed(node.left) isRed(node.right)) {
flipColor(node);
}
return node;
}
删除节点
删除节点方法是左倾红黑树中最复杂的实现,所以接下来的内容可能会让大家觉得有一些困难,但是千万不要灰心,我在学习的时候也是重复了很多遍才理解了这个过程,也请大家多给自己一些耐心。
左倾红黑树在执行删除的过程中,如果直接删除一个2-节点,会留下空链接,这样
会破坏树的完美平衡性
,如下图所示:
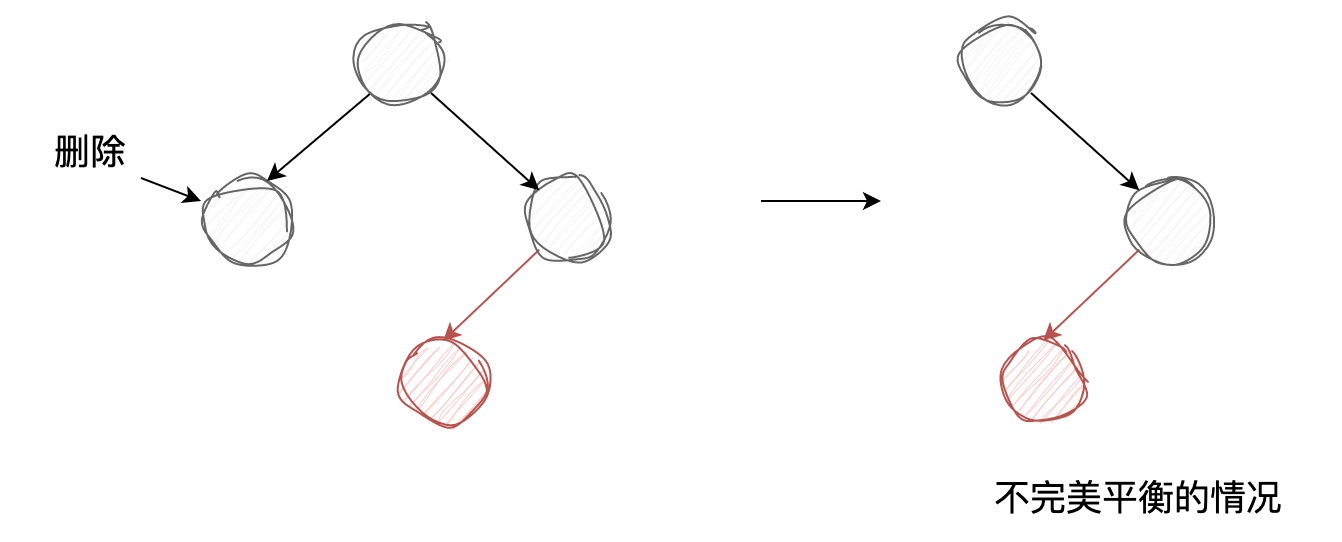
所以,在执行删除之前,需要将被删除节点转换成3-节点或临时的4-节点的一部分,这样才能保证删除节点前后左倾红黑树一直都是完美平衡的,相应地,如果被删除节点为3-节点或4-节点,那么直接移除它是不影响树的完美平衡的。
接下来我们以删除最小节点为例,讲解下节点删除的过程。
删除最小节点
既然我们需要将被删除的2-节点转换成3-或4-节点的一部分,那么我们该如何转换呢?
我们先看第一种情况,要被删除的节点和它的兄弟节点都是2-节点。根据上文中插入节点的逻辑,
两个黑色的左右子节点是由4-节点转换颜色后得到的
,那么我们可以再对其进行颜色转换,使之再成为4-节点,被删除节点也就成了4-节点的一部分,此时将其删除就不会影响树的平衡性了。不过在删除之后,虽然树的平衡性不被影响,但是红链接右引用不符合左倾红黑树的性质,需要左旋操作来修复,过程图示如下:
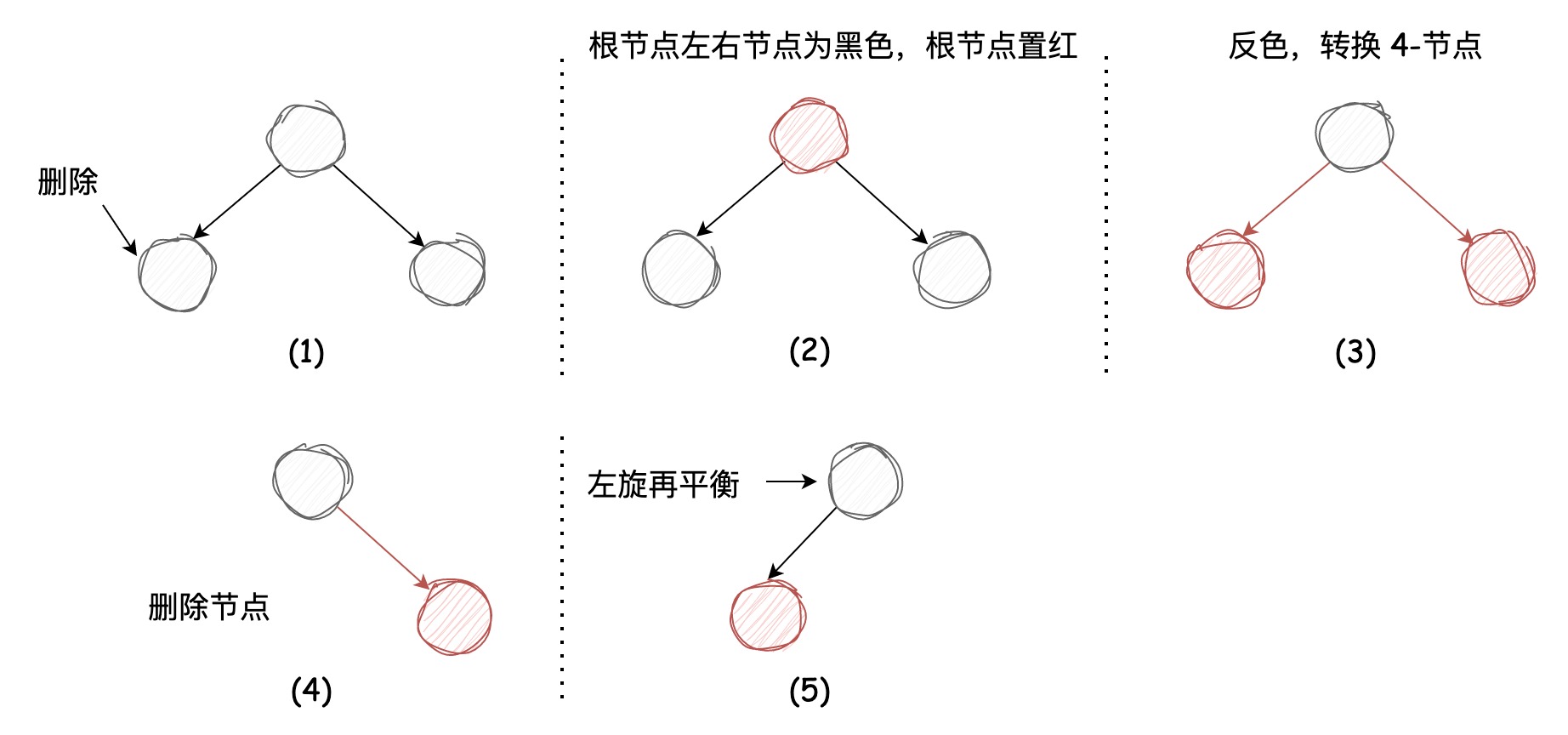
图示中由(1)到(2)将根节点转化成了红色,不知道大家还记不记得,在插入节点时4-节点转换成3个2-节点不只将左右节点转换成了黑色,还将该节点染成了红色,表示该节点会插入到父节点中,由于该节点为根节点,所以在(1)中表示为黑色,图(2)将根节点切换回了红色,对应了4-节点转换成3个2-节点的一般情况,图(3)中将这3个节点颜色均取反便得到了4-节点
我们接着看第二种情况,要被删除的节点为2-节点,它的兄弟节点为3-节点,《算法》中介绍了“借键方法”:左子节点将根节点中较小的节点借过来组成3-节点,根节点将右节点中较小的节点借过来保持自身原来节点样式不变,而右节点便成了一个2-节点,借键完毕后再将左子节点(3-节点)中较小的键(红色节点)移除,不会影响树的完美平衡性,图示如下:
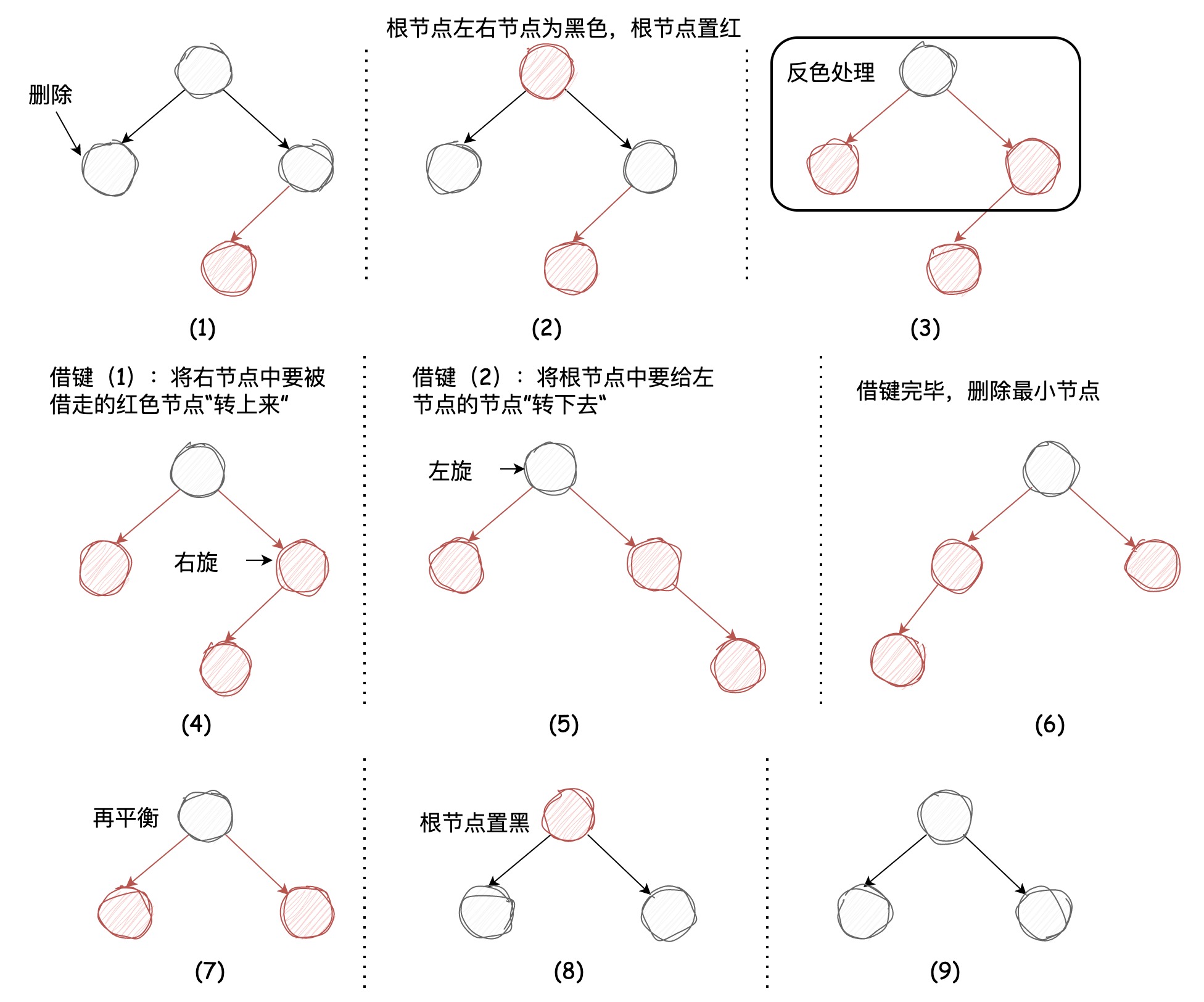
现在我们已经整理好了删除最小节点的过程,试着写一下代码:
/**
* 删除最小节点
*/
public void deleteMin() {
if (!isRed(root.right)) {
root.color = RED;
}
root = deleteMin(root);
// 根节点永远都是黑色
if (root != null) {
root.color = BLACK;
}
}
/**
* 删除最小节点
*/
private Node deleteMin(Node node) {
if (node.left == null) {
return null;
}
// 判断当前节点和左子节点是不是3-节点,不是的话执行借键逻辑
if (!isRed(node.left.left)) {
node = moveRedLeft(node);
}
node.left = deleteMin(node.left);
return balance(node);
}
/**
* 从右向左借键
*/
private Node moveRedLeft(Node node) {
flipColors(node);
// 兄弟节点为3-节点的情况
if (isRed(node.right.left)) {
node.right = rotateRight(node.right);
node = rotateLeft(node);
}
return node;
}
/**
* 从下到上再平衡
*/
private Node balance(Node node) {
if (isRed(node.right)) {
node = rotateLeft(node);
}
if (isRed(node.left) isRed(node.left.left)) {
node = rotateRight(node);
}
if (isRed(node.left) isRed(node.right)) {
flipColors(node);
}
return node;
}
需要注意的是,在插入节点定义的
flipColors
如下,本质上在插入节点时,该操作是将当前节点颜色取反:
private void flipColors(Node node) {
node.color = RED;
node.left.color = BLACK;
node.right.color = BLACK;
}
现在将该方法改成了反色处理,为了在删除节点方法中复用,如下:
private void flipColors(Node node) {
node.color = !node.color;
node.left.color = !node.left.color;
node.right.color = !node.right.color;
}
本质上,删除最小节点的过程是从上到下不断地
将当前节点染红,保证当前节点始终不为2-节点,避免移除节点后发生树的不平衡
,因为不知道什么时候能找到最小节点,所以该路径上的每个节点都需要执行该操作。
删除最大节点
删除最大节点我们只讨论被删除节点为2-节点,其兄弟节点为3-节点的情况,另一种被删除节点和它的兄弟节点均为2-节点的情况非常简单,不再赘述。
其兄弟节点为3-节点时,我们仍需要采用“借键”的方法,过程如下图所示:
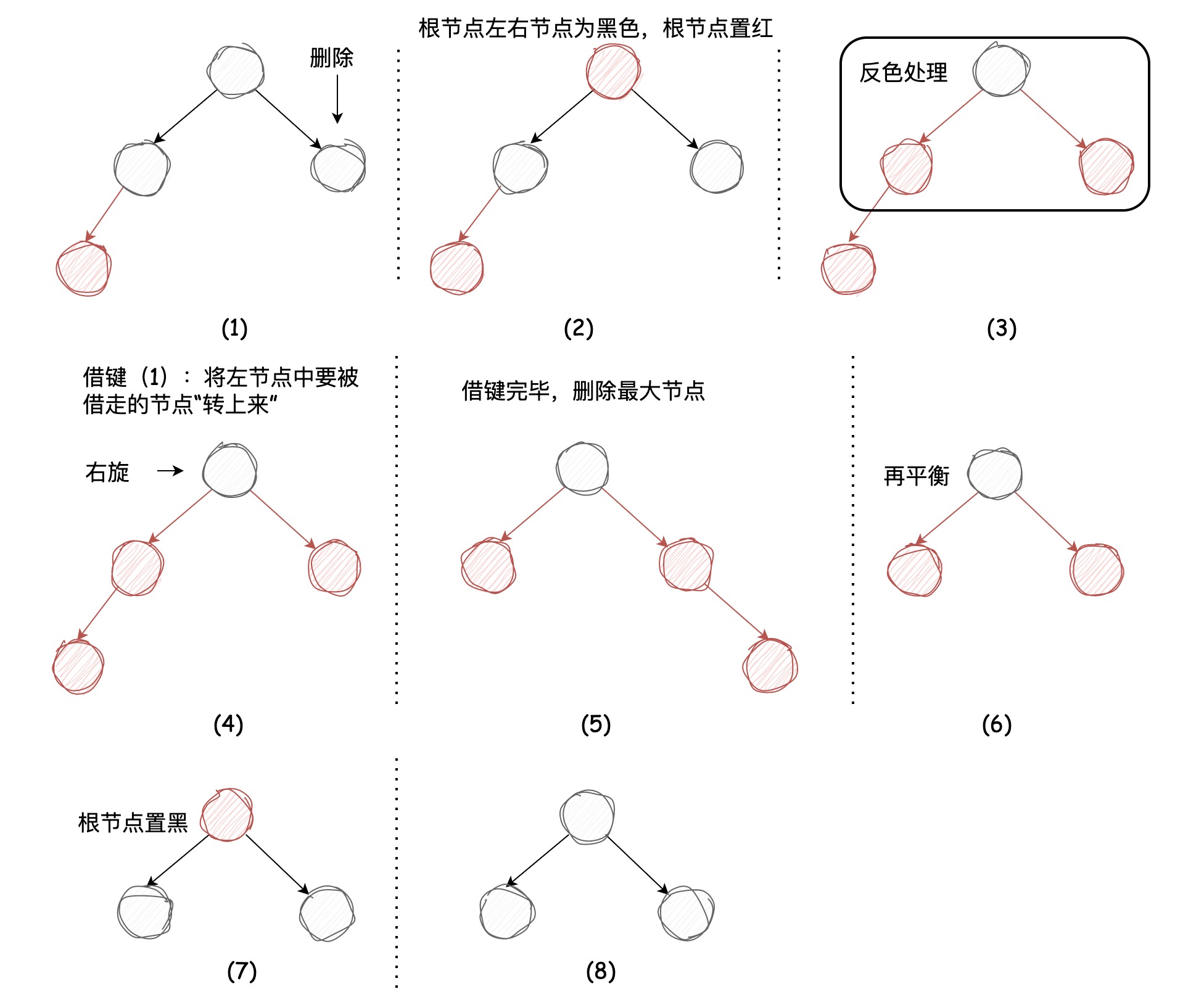
删除最大节点的代码逻辑如下所示:
/**
* 删除最大节点
*/
public void deleteMax() {
if (!isRed(root.right)) {
root.color = RED;
}
root = deleteMax(root);
// 根节点永远都是黑色
if (root != null) {
root.color = BLACK;
}
}
/**
* 删除最大节点
*/
private Node deleteMax(Node node) {
if (isRed(node.left)) {
node = rotateRight(node);
}
if (node.right == null) {
return null;
}
// 当前节点的右引用不是红链接且右节点不是3-节点
if (!isRed(node.right.left)) {
node = moveRedRight(node);
}
node.right = deleteMax(node.right);
return balance(node);
}
/**
* 从左向右借键
*/
private Node moveRedRight(Node node) {
flipColors(node);
if (isRed(node.left.left)) {
node = rotateRight(node);
}
return node;
}
其中有如下代码是在删除最小节点没有的:
private Node deleteMax(Node node) {
// 区别于删除最小节点的操作
if (isRed(node.left)) {
node = rotateRight(node);
}
// ...
}
我们来解释一下这段逻辑:在左倾红黑树中,如果当前节点的左节点为红色,那么会有可能存在这种情况:
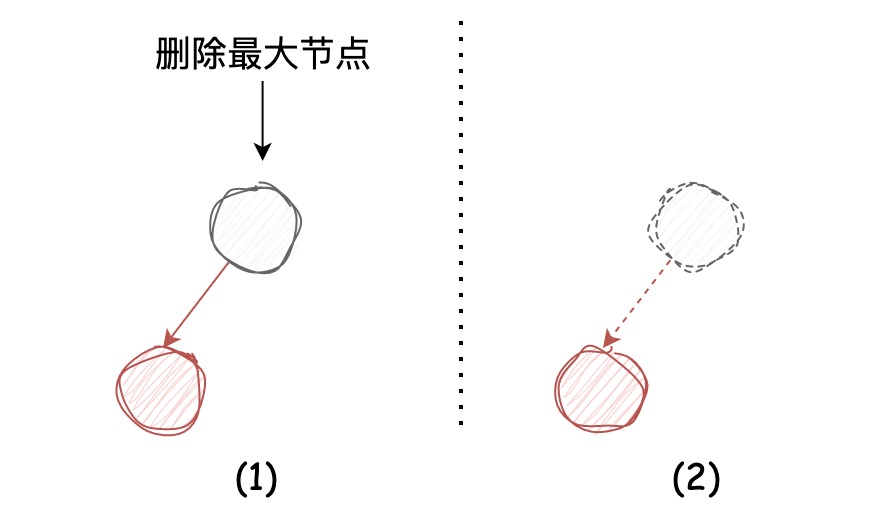
直接将图示中最大节点移除的话,会导致它的左节点丢失,为了避免,会先执行右旋,将要被删除的节点旋转到右引用的位置。
删除节点
删除节点的方法在弄明白了删除最大和最小节点的方法后,理解起来是非常容易的。它其实是删除最大节点和删除最小节点方法的结合,同样也是需要保证经过的节点为3-节点或临时的4-节点,在找到对应节点时,将该节点值替换为右子树中的最小节点值,再执行删除右子树最小节点,删除完成后执行平衡修复,大家需要关注其中的注释信息,如下:
/**
* 删除节点
*/
public void delete(Integer key) {
if (!isRed(root.right)) {
root.color = RED;
}
root = delete(root, key);
if (root != null) {
root.color = BLACK;
}
}
/**
* 删除节点
*/
private Node delete(Node node, Integer key) {
if (key .key) {
// 要删除的节点在左子树,保证当前节点为红色
if (!isRed(node.left.left)) {
node = moveRedLeft(node);
}
node.left = delete(node.left, key);
} else {
if (isRed(node.left)) {
node = rotateRight(node);
}
// node.right == null 可知上面右旋没有发生,右子树为 null,左节点不是红色节点,能证明左子树必然为null(满足黑色平衡)
if (key.equals(node.key) .right == null) {
return null;
}
// 要删除的节点在右子树
if (!isRed(node.right.left)) {
node = moveRedRight(node);
}
if (key.equals(node.key)) {
// 找到右子树中最小的节点替换当前节点的键和值
Node min = min(node.right);
node.key = min.key;
node.value = min.value;
// 再将该右子树最小的节点移除
deleteMin(node.right);
} else {
node.right = delete(node.right, key);
}
}
return balance(node);
}
为方便大家学习参考,全量代码如下:
public class LeftLeaningRedBlackTree {
private static final boolean RED = true;
private static final boolean BLACK = false;
static class Node {
int key;
int value;
boolean color;
Node left;
Node right;
public Node(int key, int value, boolean color) {
this.key = key;
this.value = value;
this.color = color;
}
}
private Node root;
/**
* 插入节点
*/
public void put(Integer key, Integer value) {
root = put(root, key, value);
// 根节点永远都是黑色
root.color = BLACK;
}
/**
* 插入节点的执行逻辑
*/
private Node put(Node node, Integer key, Integer value) {
if (node == null) {
return new Node(key, value, RED);
}
if (key .key) {
node.right = put(node.right, key, value);
} else if (key .key) {
node.left = put(node.left, key, value);
} else {
node.value = value;
}
// 将3-节点的红链接右引用左旋
if (isRed(node.right) !isRed(node.left)) {
node = rotateLeft(node);
}
// 将4-节点两条连续的红链接左引用左旋
if (isRed(node.left) isRed(node.left.left)) {
node = rotateRight(node);
}
// 进行颜色转换并将红链接在树中向上传递
if (isRed(node.left) isRed(node.right)) {
flipColors(node);
}
return node;
}
/**
* 删除最小节点
*/
public void deleteMin() {
if (!isRed(root.right)) {
root.color = RED;
}
root = deleteMin(root);
// 根节点永远都是黑色
if (root != null) {
root.color = BLACK;
}
}
/**
* 删除最小节点
*/
private Node deleteMin(Node node) {
if (node.left == null) {
return null;
}
// 判断当前节点和左子节点是不是3-节点,不是的话执行借键逻辑
if (!isRed(node.left.left)) {
node = moveRedLeft(node);
}
node.left = deleteMin(node.left);
return balance(node);
}
/**
* 从右向左借键
*/
private Node moveRedLeft(Node node) {
flipColors(node);
// 兄弟节点为3-节点的情况
if (isRed(node.right.left)) {
node.right = rotateRight(node.right);
node = rotateLeft(node);
}
return node;
}
/**
* 删除最大节点
*/
public void deleteMax() {
if (!isRed(root.right)) {
root.color = RED;
}
root = deleteMax(root);
// 根节点永远都是黑色
if (root != null) {
root.color = BLACK;
}
}
/**
* 删除最大节点
*/
private Node deleteMax(Node node) {
if (isRed(node.left)) {
node = rotateRight(node);
}
if (node.right == null) {
return null;
}
// 当前节点的右引用不是红链接且右节点不是3-节点
if (!isRed(node.right.left)) {
node = moveRedRight(node);
}
node.right = deleteMax(node.right);
return balance(node);
}
/**
* 从左向右借键
*/
private Node moveRedRight(Node node) {
flipColors(node);
if (isRed(node.left.left)) {
node = rotateRight(node);
}
return node;
}
/**
* 删除节点
*/
public void delete(Integer key) {
if (!isRed(root.right)) {
root.color = RED;
}
root = delete(root, key);
if (root != null) {
root.color = BLACK;
}
}
/**
* 删除节点
*/
private Node delete(Node node, Integer key) {
if (key .key) {
// 要删除的节点在左子树,保证当前节点为红色
if (!isRed(node.left.left)) {
node = moveRedLeft(node);
}
node.left = delete(node.left, key);
} else {
if (isRed(node.left)) {
node = rotateRight(node);
}
// node.right == null 可知上面右旋没有发生,右子树为 null,左节点不是红色节点,能证明左子树必然为null(满足黑色平衡)
if (key.equals(node.key) .right == null) {
return null;
}
// 要删除的节点在右子树
if (!isRed(node.right.left)) {
node = moveRedRight(node);
}
if (key.equals(node.key)) {
// 找到右子树中最小的节点替换当前节点的键和值
Node min = min(node.right);
node.key = min.key;
node.value = min.value;
// 再将该右子树最小的节点移除
deleteMin(node.right);
} else {
node.right = delete(node.right, key);
}
}
return balance(node);
}
/**
* 获取最小节点
*/
private Node min(Node node) {
if (node.left == null) {
return node;
}
return min(node.left);
}
/**
* 从下到上再平衡
*/
private Node balance(Node node) {
if (isRed(node.right)) {
node = rotateLeft(node);
}
if (isRed(node.left) isRed(node.left.left)) {
node = rotateRight(node);
}
if (isRed(node.left) isRed(node.right)) {
flipColors(node);
}
return node;
}
/**
* 左旋
*/
private Node rotateLeft(Node node) {
Node newNode = node.right;
node.right = newNode.left;
newNode.left = node;
newNode.color = node.color;
node.color = RED;
return newNode;
}
/**
* 右旋
*/
private Node rotateRight(Node node) {
Node newNode = node.left;
node.left = newNode.right;
newNode.right = node;
newNode.color = node.color;
node.color = RED;
return newNode;
}
/**
* 颜色转换
*/
private void flipColors(Node node) {
node.color = !node.color;
node.left.color = !node.left.color;
node.right.color = !node.right.color;
}
/**
* 判断节点是否为红色
*/
private boolean isRed(Node node) {
if (node == null) {
return false;
} else {
return node.color == RED;
}
}
}
巨人的肩膀