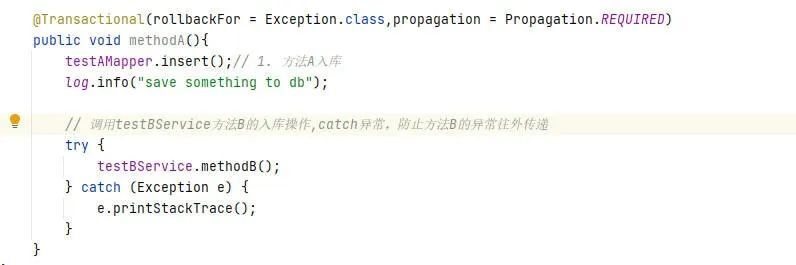
编写.NET的Dockerfile文件构建镜像
创建一个WebApi项目,并且创建一个Dockerfile空文件,添加以下代码,7.0代表的你项目使用的SDK的版本,构建的时候也需要选择好指定的镜像tag
FROM mcr.microsoft.com/dotnet/aspnet:7.0 AS base
WORKDIR /app
EXPOSE 80
EXPOSE 443
FROM mcr.microsoft.com/dotnet/sdk:7.0 AS build
ARG BUILD_CONFIGURATION=Release
WORKDIR /src
COPY ["WebApplication1/WebApplication1.csproj", "WebApplication1/"]
RUN dotnet restore "./WebApplication1/./WebApplication1.csproj"
COPY . .
WORKDIR "/src/WebApplication1"
RUN dotnet build "./WebApplication1.csproj" -c $BUILD_CONFIGURATION -o /app/build
FROM build AS publish
ARG BUILD_CONFIGURATION=Release
RUN dotnet publish "./WebApplication1.csproj" -c $BUILD_CONFIGURATION -o /app/publish /p:UseAppHost=false
FROM base AS final
WORKDIR /app
COPY --from=publish /app/publish .
ENTRYPOINT ["dotnet", "WebApplication1.dll"]
我们一步一步来进行讲解,首先第一步,FROM指定了一个mcr.microsoft.com/dotnet/aspnet:7.0镜像,并且AS别名base,这一步是选择aspnet:7.0作为基础运行镜像,as别名用于方便以下步骤使用
FROM mcr.microsoft.com/dotnet/aspnet:7.0 AS base
WORKDIR /app
EXPOSE 80
EXPOSE 443
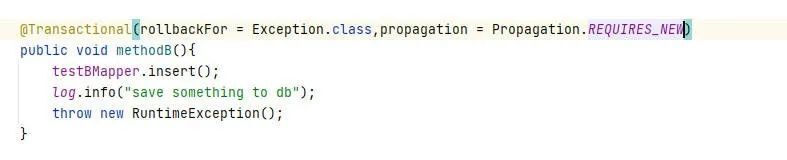
然后下一步,在这里FROM了一个mcr.microsoft.com/dotnet/sdk:7.0 的镜像并且AS别名build,这个镜像当中是使用到了.NET SDK作为镜像用于将项目构建成部署文件,在这里的COPY的目录的位置是从你docker build ./ 的这个./的目录作为根目录的,请注意如果出现文件未找到的情况下可能就是工作目录与Dockerfile目录不一致导致,在构建的时候指定了构建完成到/app/build目录中。
FROM mcr.microsoft.com/dotnet/sdk:7.0 AS build
ARG BUILD_CONFIGURATION=Release
WORKDIR /src
COPY ["WebApplication1/WebApplication1.csproj", "WebApplication1/"]
RUN dotnet restore "./WebApplication1/./WebApplication1.csproj"
COPY . .
WORKDIR "/src/WebApplication1"
RUN dotnet build "./WebApplication1.csproj" -c $BUILD_CONFIGURATION -o /app/build
在这里FROM了上面的build然后继续AS别名了publish在这里使用了dotnet publish将源码进行了构建部署,上面的build操作是为了将编译过程和构建镜像的过程分离。
FROM build AS publish
ARG BUILD_CONFIGURATION=Release
RUN dotnet publish "./WebApplication1.csproj" -c $BUILD_CONFIGURATION -o /app/publish /p:UseAppHost=false
这里使用到了最开始的base然后别名final,然后指定工作目录,使用COPY --from指定了上面的publish的构建镜像,然后将镜像构建的/app/publish中目录下面的所有的文件COPY到/app下,然后给镜像配置容器启动时运行的命令,则是我们的.NET Core项目启动命令,执行我们的项目。
FROM base AS final
WORKDIR /app
COPY --from=publish /app/publish .
ENTRYPOINT ["dotnet", "WebApplication1.dll"]
结尾
来着token的分享
技术群:737776595