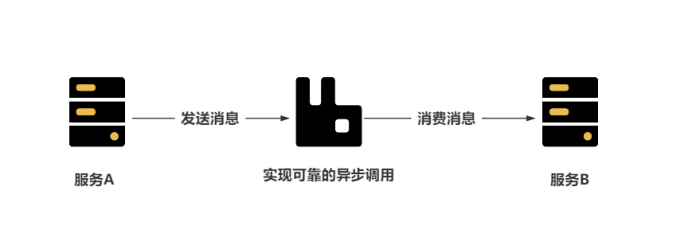
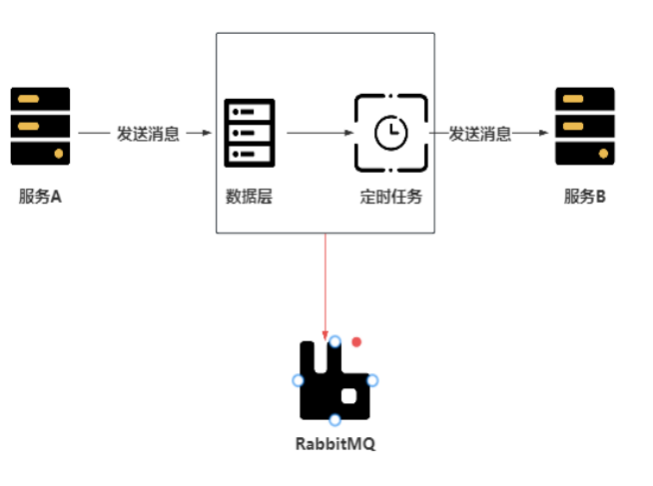
【深度思考】一线开发大头兵对于工作的感悟分享
前言
写在前面的是关于自己的一点介绍,21年本科毕业,学的是计算机科学与技术专业,到现在工作(实习)也有两三年了。自己本身对编程和开发是有兴趣的,同时也对项目管理、团队建设方面有兴趣。
目前有两段工作经历,都是在一线当开发大头兵,职级倒是随着跳槽而有所上升。做过从0-1的SaaS、PaaS的自研项目,也做过多租户的定制化开发项目,还有过半年的 PM 的经历...这些都让我有了一些关于工作上的感悟。现在简单总结一下,拿出来和大家做分享交流。
下面主要从工作的方式方法、构建知识体系、尽早规划职业这三个大的方面展开。文章有点长,但都是自己一步步实践总结得来的,有写得不好的地方,还希望大家多包涵。
一、工作方式方法
在企业上班/打工的这一根本前提,决定了我们是企业的劳动力这个最大的基本盘。
所以既然是工作,那么就可以有一些工作上的方式方法值得总结和分享。
想要自己创业或者考公/考编,或者做自由职业的朋友可以绕道了,可能这篇文章对你的帮助不是很大。
1.1先尽人事
拿出积极的态度:
首先需要自己努力去解决问题,其次包括调动资源、团队协助,最好要让领导/同事知晓你的情况。摆烂并不可取,劳动是用来换取报酬的。
如果平时的工作表现/绩效过不去,那么将可能会直接影响到我们的收入。对于工作量的估算要留有余地
。学会平衡别人的预期,如果 3 天内能完成,那最好回复一个星期:总有别的事情会打扰你。遵守基本的职业道德:
如果你负责的服务出现故障或发现一个严重的 bug ,作为开发我们应该马上对其进行修复/解决。少一些牢骚和抱怨
:面对难题或者挑战时,更多地应该思考可行的解决方案,并做好与干系人的沟通和反馈。工作里对事不对人
:我们需要推进的是项目,是一件件具体的事情,聚焦于如何解决问题,而不是和人做无效拉扯。
做好上面这些,假如是对于刚毕业的我来说可能并不容易,但过了两年自己开始负责项目了以后,我就能慢慢理解并适应了。
1.2关注个人成长
人对于企业没有100%的忠诚度,规章制度才是可靠的。
所以我们可以有意识地提炼日常工作成果,
形成自己的个人源码库和工具库、解决某类问题的通用系统体系结构、甚至进化为框架。
众所周知对软件开发人员而言,有、无经验的一个显著区别是:新手无论完成什么开发任务都从头开始,而有经验的开发往往通过重组自己的可复用模块、类库来解决问题。
这并不是说所有可复用的东西都必须自己实现,
别人成熟的、通过测试的成果也可以收集、整理到自己的知识库中。
1.3work&life balance
工作与生活的平衡,这是个老生常谈的话题。
实际程序员们可能很难做到:总有一些会议拉上你去 battle,总有一些线上的 bug 困扰着你,总会有领导安排的其它事情让你分身乏力...还有很多。
工作是为了更好的生活这个主旨不会变,
所以我也有自己的一些想法:
- 拒绝无效加班。
注重上班8个小时内的工作效率,即使有紧急任务,也不要自己一个人默默加班,而是看团队安排。 - 健康的生活方式。
不抽烟、不喝酒、不熬夜,不吃太饱,中午尽量休息 30-60 mins,也可以适当健身锻炼锻炼身体。 - 合理化解压力。
寻求家人/伴侣的陪伴和支持,吃完饭一起到楼下散散步溜溜弯,始终要有良好的心态去化解工作上的压力。 - 有点兴趣爱好。
周末爬爬山、去周边城市旅旅游、和家人/伴侣一起包顿饺子...都可以让我们的生活充满更多乐趣。
二、构建知识体系
知识体系是系统化的知识,具有连续性的特点,反映了一个人经过学习后所拥有的知识构成情况与结合方式。如果一个开发人员在1、2年内都没有更新过自己的知识,那么他可能已经不再属于这个行业了。
2.1夯实基础
万层高楼平地起,基础的扎实程度,可以决定开发人员在技术的道路上能走多远。
一个开发无论工作了多少年,越是到后面就越能体会,
再高级的东西拆解后,就是基础知识。
我自己是在工作中切实地感受到了基础的重要性,在夯实基础方面总结了以下几点:
- Java 最基本概念,包括类、接口和抽象类、方法和类属性
- 面向对象的思想,继承、封装、多态的运用
- Java 的集合、其它数据结构、常用工具类,Stream 流
- Spring 框架的 AOP、IOC 和 Bean 的原理与应用
- 编程思想的培养,代码与业务的结合,积累解决问题的经验等等
- ......
2.2抽象思维
抽象思维能够超越感官直接感知信息,通过对事物的本质属性和规律的把握,使人们在认识活动中获得更深层次的知识。
程序员如何培养抽象思维?在这里我也分享一下自己的理解:
多阅读优秀的代码,多思考本质和原因,多通过实践来检验
写出可阅读的、简洁易懂、可维护的代码,应该是程序员在工作中都需要追求的。在实现业务的时候,通过借助模仿优秀的开源实现,学习他人在提高代码效率、逻辑思维、处理高并发等方面是怎么做的。学会总结复盘,从中抽取有价值的经验,将成长记录下来
复盘的内容,可以是一次线上 bug 的处理过程,可以是一次代码重构优化的过程,也可以是对一个中间件的新认识等等。复盘不是问责也不是甩锅,而是聚焦于好和不好,知其然再知其所以然,同时避免重蹈覆辙。不是所有人都愿意直面自己的缺点和不足
,我自己最开始也不明白复盘有什么用处,觉得对领导和业务能有交代就行。但随着自己做过的项目多了起来,受到身边优秀同事的影响也在日益增多,我才明白复盘是可以让人迅速成长的不二法宝。有意识地站在更高的角度去看待问题,可能会得到不一样的答案
作为一线开发我们更多关注的,可能是接口的参数和实现逻辑,数据库字段的设计,中间件的使用,异常的处理等实际编码问题;而你的 TeamLeader 可能关注的是项目的高可用,处理高并发的性能,硬件资源的成本,服务挂了怎么降低对业务的影响等;
部门的总监则可能在考虑这个项目要不要做二期三期?对业务方有什么价值?能带来多少新用户?让谁来负责后续的运营等。
2.3广度与深度
我认为广度和深度在每个阶段的侧重点可能有所不同:
初/中级可以先从广度出发,多见识一些主流技术或者解决方案,这样在面对业务的时候可以更从容地进行设计,也能更清楚自己 CURD 的目的是什么。
高级/资深可能就要精通某一或者某几方面的通用架构/解决方案了,同时对于负责的业务有深刻的认识,可能也要负责团队的建设,从更广阔的视角去思考问题。
但其实无论是深度还是广度,都是可以遵循:
先掌握基础结构,然后熟悉基本使用,最后输出解决方案。
三、尽早规划职业
我是在工作一年半左右慢慢有了对未来进行职业规划的想法,因为时间会向前走,人也会渐渐地成长。对于未来想要什么,可以慢慢给自己多找找方向去尝试。
尽管
我们的工作很可能对于改变这个世界没有多大意义
,但还是可以在每天的工作中用自己的方式创造价值。
3.1市场现状
首先,最重要的是目前的市场趋于饱和。
2010-2020 这十年,互联网发展如火如荼,各种公司如雨后春笋般冒出来,那时候招聘需求量大,互联网就业市场一片欣欣向荣。
而现在没有了当年的辉煌,
很多互联网公司业务发展停滞
,同时经过前面多年的发展,
产品架构已经成熟稳定
,不再需要这么多的程序员,势必要进行结构优化,那优化的对象自然是性价比低的人群。
其次,IT互联网行业高薪的宣传又吸引了一大批年轻人跑步进场,需求变少的情况下人又变多,内卷就这么产生了。高学历的人才多了很多,所谓学历贬值的论调在这几年一直都有出现。
3.2如何破局
让我们透过现象看本质:IT互联网行业的特殊性在于
产出是可迭代的
。这个行业程序员的产出就是软件&代码,而这个东西就是可以不断的迭代的。
分析了上面的原因,就有针对性了。软件代码这些东西是可迭代的,但
有些东西是没法复制和迭代的
:像是
沟通协调能力、解决问题能力、规划组织能力、管理能力和人脉资源
等等。这些其实就是我们经常说的
软实力
,这些能力才是越久越吃香。
这些能力不仅可以在日常工作中有意识的积累,也可以通过考取相关的证书来掌握理论知识,比如:软考高项(信息系统项目管理师、系统架构师)、PMP认证、阿里云/华为云高级认证等。
打开认知的局限,不只着眼于手里掌握的技术,拓展自己职业的综合能力,明白不是只有靠技术才能活下去,才能更好地“破局”。
四、文章小结
文章最后,我还有一些想说的。的确,技术逐渐会变得越来越“廉价”,不再是必须要工作多年的大佬才能驾驭的高级东西。
这里面有个很重要的原因,就是
开源的力量
。大家可以想一想自己参与的一些项目,用到了多少开源的东西?以一个典型的后端项目为例,可能涉及到了 MySQL、Redis、ElasticSearch、RocketMQ、Nginx、SprintBoot、Jenkins、CI/CD、Docker......
程序员要做的就是根据业务需求,把上面那一堆组件按照规则合理地堆在一起。
一般就是 Nginx 负载均衡,Spring Boot/Cloud 写后端业务逻辑,Redis 做缓存,MySQL、ES、MongoDB 做数据存储,OSS/COS 做云对象存储,RocketMQ/Kafka 做消息队列,最后进行 CI/CD 操作塞到 Docker 里面部署运行。现在绝大多数的功能,开源组件都能提供,再加上现在是云的时代,各种
服务都上云
了,那么问题就更简单了。
既然我们身处在这个行业,那么就要做好持续学习的准备,不断打怪升级,锻炼综合能力,做到让经验随着年龄的增长成真正的正比。
毕竟,所有平凡的日子加起来,就将汇集成为你的一生。