Logstash
开源一篇ELK运维文档,如果有描述不对的希望,欢迎大家纠正。
Monitoring API
官方提供了4个Monitoring API,如下:
用于查看Node级别的基本信息,选参数为
pipelines
、
os
和
jvm
,如下查看基本的os和jvm信息:
curl 127.0.0.1:9600/_node/os,jvm
如下展示了pipeline的默认配置,os和jvm的基本信息。其中一个比较重要的字段是
status
,其展示了logstash的当前健康状态:
{
"host": "dragon-logging-logstash-c6b8798bf-8rvkp",
"version": "7.17.9",
"http_address": "0.0.0.0:9600",
"id": "4c68e86b-0858-4c01-b52d-f59a346892a4",
"name": "dragon-logging-logstash-c6b8798bf-8rvkp",
"ephemeral_id": "804f0684-c2c3-4dea-8033-f368ab029d61",
"status": "green",
"snapshot": false,
"pipeline": {
"workers": 100,
"batch_size": 250,
"batch_delay": 50
},
"os": {
"name": "Linux",
"arch": "amd64",
"version": "5.4.0-1094-azure",
"available_processors": 2
},
"jvm": {
"pid": 1,
"version": "11.0.18",
"vm_version": "11.0.18",
"vm_vendor": "Eclipse Adoptium",
"vm_name": "OpenJDK 64-Bit Server VM",
"start_time_in_millis": 1678872170592,
"mem": {
"heap_init_in_bytes": 1073741824,
"heap_max_in_bytes": 1056309248,
"non_heap_init_in_bytes": 7667712,
"non_heap_max_in_bytes": 0
},
"gc_collectors": [
"ParNew",
"ConcurrentMarkSweep"
]
}
}
用于查看插件的版本信息:
curl 127.0.0.1:9600/_node/plugins
用于查看logstash的运行时状态,可选参数为:
jvm
: 查看jvm的mem和gc情况,可以使用
collection_time_in_millis/collection_count
查看GC的速率
process
:查看进程概况,如当前打开文件句柄数/最大打开文件句柄数/允许的最大文件句柄数,还有当前CPU的百分比和负载
events
:展示事件相关的信息,如果
queue_push_duration_in_millis
大于
duration_in_millis
,说明 Logstash 的输入插件速率很快,而 filter/output 的处理很慢,导致等待时间非常的长,这时候要注意优化后面两个插件。可以通过
pipelines
接口查看各个插件处理花费的具体时间。
queue_push_duration_in_millis
: input阶段花费的时间
duration_in_millis
: filter和output阶段花费的时间
"events": {
"in": 794568,
"filtered": 794568,
"out": 1095644,
"duration_in_millis": 20695169,
"queue_push_duration_in_millis": 186248
}
flow
:logstash 8的功能,可以查看pipeline的吞吐量信息,如
input_throughput
、
filter_throughput
、
output_throughput
等
pipelines
: 展示个每个pipeline各个阶段的详细信息,如input、filter和output,其中也包含了该pipeline的events和flow信息,以及output的返回值和失败次数等信息。
reloads
:展示了重新加载配置的成功和失败次数
os
:当logstash运行在容器中时,可以展示cgroup的信息
geoip_download_manager
下面用于查看logstash 的pipeline信息
curl 127.0.0.1:9600/_node/stats/pipelines
用于查看logstash的热点线程信息。可以查看各个线程的线程ID和
占用的CPU时间
以及线程状态,以此可以确认高负载的线程:
curl 127.0.0.1:9600/_node/hot_threads
logstash exporter指标
logstash exporter的指标取自monitoring API的
_node/stats
接口,采集了
jvm
、
events
、
process
、
reloads
这四个维度的信息
插件管理
离线安装插件
bin/logstash-plugin install file:///path/to/logstash-offline-plugins-8.6.2.zip
更新插件
bin/logstash-plugin update #更新所有插件
bin/logstash-plugin update logstash-input-github #更新特定插件
移除插件
bin/logstash-plugin install /path/to/logstash-output-kafka-1.0.0.gem
使用Gem私有库
Logstash 插件管理器会连接到一个Ruby gem仓库,默认为
http://rubygems.org
。logstash插件的gemfile中的
source
行指定了插件的位置,如默认的gemfile的
source
为:
source "https://rubygems.org"
将这一行指向自己的插件地址即可:
source "https://my.private.repository"
性能调优
Logstash提供了三个参数来调试pipeline的性能:
pipeline.workers
:设置了处理filter和output的线程数。如果发现事件处理拥塞,或CPU不饱和,可以考虑增大该值。默认等于CPU的个数。
pipeline.batch.size
:设置了单个worker线程在执行filter和output前采集的事件总数。通常batch越大,处理效率越高,但也会增大内存开销。该数值过大可能会导致频繁GC或JVM出现OOM。默认125。
pipeline.batch.delay
:该配置基本不需要进行调节。
logstash中inflight的事件(即内存队列中的事件)的总数与
pipeline.workers
和
pipeline.batch.size
的配置有关。inflight事件过多会导致GC和CPU曲线出现突刺,而合理的inflight事件的场景下,GC和CPU曲线会比较平滑。
下面给出的是原文的部分场景。
在
jvm.options
文件中添加如下配置可以让logstash在启动的时候忽略告警。
--add-opens=java.base/java.security=ALL-UNNAMED
--add-opens=java.base/java.io=ALL-UNNAMED
--add-opens=java.base/java.nio.channels=ALL-UNNAMED
--add-opens=java.base/sun.nio.ch=org.ALL-UNNAMED
--add-opens=java.management/sun.management=ALL-UNNAMED
请求返回429。说明应用繁忙,如elasticsearch在由于ingest队列满导致bulk失败之后会给logstash返回429。
FAQ
logstash可能出现的问题?
一般成熟的架构中,logstash会从消息队列(如kafka)中pull数据,然后写入后端(如elasticsearch),因此logstash承担的是一个数据处理转发的功能,其本身一般不会保存过程数据(除非使用了
persistent queue
)。
方式1:
logstash比较吃内存,首先检查logstash的jvm内存利用率。
方式2:
logstash一般可能会出现input和filter/output处理效率不匹配的问题。假如logstash是从kafka摄取消息的,可以在kafka上针对logstash消费的消息做一个lag告警,当lag较大时说明出现lagstash处理不及时,通过logstash消费的topic可以进一步定位出哪个logstash pipeline出现了性能问题。使用
/_node/stats/pipelines
接口可以得到更细节的信息,通过增加特定pipeline的
pipeline.workers
和
pipeline.batch.size
来提高pipeline的吞吐量,也可以通过各个插件的
queue_push_duration_in_millis
或
duration_in_millis
找到消耗性能的插件,针对
input
、
filter
、
output
、
codec
等插件进行性能调优。
方式3:
logstash处理能力不足,可能是由于其对CPU的和内存的利用不足导致的。可以在
logstash.yml
或
pipelines.yml
中配置
pipeline.workers
和
pipeline.batch.size
来提高资源利用率,前者的调节基于CPU饱和度,后者会导致JVM使用量增加。
最佳的
pipeline.workers
和
pipeline.batch.size
配比应该是使得GC和CPU使用曲线都趋于
平滑
。
如何保证logstash事件不丢失?
默认情况下,logstash使用内存队列来缓存pipeline各个阶段的事件,内存队列的上限等于
pipeline.workers
(默认为CPU个数) 乘以
pipeline.batch.size
(默认: 125) 个事件数。
在logstash的input接收事件并在事件没有发送到output之前出现异常的话可能丢失事件。可以使用
persistent queue
来防止事件丢失,它位于input和filter阶段之间:
input → queue → filter + output
。当input接收到事件并成功写入队列之后,input就可以向事件源返回确认信息。队列会记录事件的处理状态,只有当filter和output都处理完成之后,该事件才会被标记为"已完成"。当logstash出现异常并重启之后,会继续处理那些"未完成"的事件。
在事件成功持久化到persistent queue(PQ)之后,kafka input插件才会提交offset?
否。kafka input插件会周期性地提交offset。如果PQ处理慢或被阻塞,那么会提交没有达到PQ的事件的offset
logstash是否可以保证消息处理的顺序?
logstash默认
不会
保证消息处理的顺序的,在如下两种场景中可能会出现乱序:
- filter批量处理过程中可能会出现乱序
- 多个批量事件可能会因为处理快慢导致乱序
通过启动单个logstash实例并设置
pipeline.ordered ⇒ true
来保证顺序处理。不过一般logstash的事件会包含时间戳,在es侧再按照时间或其他维度的信息进行排序。
logstash是如何
退出
的?
logstash接收到
SIGTERM
(kubelet停止pod时也会发送该信号)信号之后会执行如下步骤:
- 停止所有input、filter和output插件
- 处理所有未完成的事件(events)
- 结束logstash进程
下面因素会影响到logstash的退出:
- input插件的事件接收速度慢
- filter慢
- output插件链路断开,等待重连来刷入未完成的事件
可以使用上面的monitor API查看各个阶段的执行情况。可以在启动时通过指定
--pipeline.unsafe_shutdown
参数来强制logstash退出,但这种方式可能会导致事件丢失。
TIPS
- logstash自动加载
配置
:包含两个参数
config.reload.automatic
和
config.reload.interval
- 建议logstash的内存不低于4GB,且不高于8GB
- logstash的plugin默认位于
/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems
,不同版本的插件支持的参数可能不一样,版本差异可参见
integration-kafka-index
- 不同版本的logstash的jvm配置
文件
Elasticsearch(基于es8)
安装事项
生产中的内核参数
vm.max_map_count
最少设置为
262144
elasticsearch默认用户
elasticsearch
,uid:gid为
1000:0
。elasticsearch需要读取
path.data
和
path.logs
的权限。
设置打开的文件句柄数
--ulimit nofile=65535:65535
设置可创建的线程数
ulimit -u 4096
推荐使用
/usr/share/elasticsearch/config/jvm.options.d
来设置JVM参数(不推荐使用
ES_JAVA_OPTS
)
Elasticsearch会使用
bin/elasticsearch-keystore create -p
来创建keystore。可以使用如下方式添加bootstrap的密码:
echo "demopwd"|elasticsearch-keystore add -x "bootstrap.password"
可以使用如下方式查看keystore中的内容:
elasticsearch-keystore list
elasticsearch-keystore show bootstrap.password
初始化重要配置
路径配置
path.data
:保存了索引数据和data stream数据
path.logs
:保存了集群状态和操作数据
集群名称
一个es集群就是配置了相同
cluster.name
的节点的集合,默认是
elasticsearch
。
节点名称
node.name
,默认为机器的主机名
网络主机配置
elasticsearch默认的绑定地址为
127.0.0.1
和
[::1]
,可以使用
network.host
来变更elasticsearch的绑定地址。
节点发现和选举master节点
discovery.seed_hosts
:设置为集群的master-eligible节点。可以使IP地址或主机名。
discovery.seed_hosts:
- 192.168.1.10:9300
- 192.168.1.11
- seeds.mydomain.com
- [0:0:0:0:0:ffff:c0a8:10c]:9301
cluster.initial_master_nodes
:首次集群引导时使用。参见
集群引导
章节
JVM配置
Xms
和
Xmx
不应超过总内存的
50%- circuit break的设置
推荐
85%的节点内存
网络
elasticsearch有两个网络接口:
HTTP 接口
,用于处理客户端请求;
transport 接口
,用于和其他节点通信。常用配置如下:
network.host
:设置HTTP和transport流量的地址。可以是IP地址,主机名称,
0.0.0.0
等。
http.port
:HTTP客户端的通信端口,支持单个值会范围值。如果指定了范围,则会绑定范围中第一个可用的端口。默认
9200-9300
。
transport.port
:节点间通信的端口。配置方式同
http.port
。在master-eligible 节点上需要设置为
单个
端口。默认
9300-9400
。
通过
elasticsearch.yml
的
node.roles
字段来设置节点的角色,主要角色如下:
Master-eligible node
:角色为
master
,负责集群范围内的轻量工作,如创建或删除索引,探测节点是否健康,并决定将哪些分片分配到哪些节点。可以被选举为master节点,master节点需要配置一个
path.data
目录来保存集群的元数据,集群元数据描述了如何读取data节点上保存的数据,因此如果元数据丢失,那么将es无法读取数据节点上的数据。生产上
推荐给master角色配置单独的节点
,防止节点过载,以保证集群的稳定。master eligible节点负责master节点的选举以及新集群状态的提交。
node.roles: [ master ]
Voting-only master-eligible node
:角色为
voting_only
,只参与选举但不会变为master的节点。
node.roles: [ voting_only ]
Data node
:角色为
data
,Data节点负责数据相关的操作,如CRUD,查找以及聚合。Data节点是I/O、内存和CPU密集的,
当监控到这些资源过载之后,需要添加新的Data节点
。在多层架构中,Data节点的角色还可以为
data_content
,
data_hot
,
data_warm
,
data_cold
, 或
data_frozen
,但同时只能设置一个Data角色。
node.roles: [ data ]
Ingest node
:角色为
ingest
,负责数据采集的节点
Coordinating node
:查询或bulk索引都会涉及多台data节点的数据,
接收到客户端请求
的节点称为
coordinating
节点。例如一个查询包含两个阶段:
每个节点都可能成为coordinating节点,如果一个节点的
node.roles
为空,则说明该节点只能作为coordinating节点。gather阶段会消耗大量CPU和内存,因此为了保证集群的稳定性,不应该将master节点作为coordinating节点。
node.roles: [ ]
一个节点可能配置多个角色,即可能既是master,同时也是data。在实际的使用中,应该把请求(如kibana)发送给data节点,而不能发送给master节点。
发现和组建集群
master-eligible节点
需要协作完成master节点的选举和集群状态变更,在选举新的master或提交新的集群状态时,要求voting configuration中至少一半以上的节点同意之后才能执行相应的动作,因此为了保证集群的稳定性,不能在同一时间停掉voting configuration中一半及以上的节点。
每个elasticsearch集群都有一个voting configuration,通常voting configuration等同于集群中的所有master-eligible节点的集合,但某些情况下会有所不同,如节点的加入和离开,以及包含不可用的节点时。当一个节点加入或离开集群时,elasticsearch会自动调整对应的voting configuration。可以使用如下方式查看当前的voting configuration:
GET /_cluster/state?filter_path=metadata.cluster_coordination.last_committed_config
voting configuration的片段如下:
"cluster_coordination": {
"term": 5,
"last_committed_config": [
"kG4FQeW5SYy-5MzYJwJ7sA",
"Kz2QwUWDS8CsFH-lUTBm1w",
"wBopsPAPSHeNDC7yK982HA"
],
"last_accepted_config": [
"kG4FQeW5SYy-5MzYJwJ7sA",
"Kz2QwUWDS8CsFH-lUTBm1w",
"wBopsPAPSHeNDC7yK982HA"
],
"voting_config_exclusions": []
},
通过
cluster.auto_shrink_voting_configuration
来设置是否允许自动移除voting configuration中的节点(前提是voting configuration中至少有三个节点),默认是true。如果将其设置为false,则必须手动调用
voting exclusions API
来从voting configuration中移除节点。
elasticsearch的集群的master eligible节点数应该是
奇数
,但如果配置了偶数个master eligible节点,那么elasticsearch会将其中一个节点排除在voting configuration之外。当出现网络分区问题,可以避免导致两个分区master eligible节点数相同,以此提升集群的稳定性。
在集群引导时需要配置具有投票权的master eligiable节点列表。新启动的节点可以从集群的master节点获取所需的信息,先前启动过的节点则将信息保存到了磁盘,在重启之后可以使用这些信息。
通过
cluster.initial_master_nodes
来设置初始的master eligible节点列表,可以是
node.name
,IP地址或
IP:PORT
格式的内容。
在集群形成之后,从各个节点上
移除
cluster.initial_master_nodes
配置
,且不要使用该配置来重启集群或添加新节点。如果在集群形成之后还留着该配置,可能会导致未来在已有集群之后引导出一个新的集群,且无法在不丢失数据的情况下恢复回来。
集群引导只需要配置如下参数既可:
elasticsearch在集群启动或现有master故障的情况下会启动master选举流程。任何master eligible节点都可以参与选举,通常第一个执行选举的节点会成为master。但如果两个节点同时执行选举,会出现选举失败,此时会等待下一次选举,后续选举会添加随机退避时间(随机时间上限为
cluster.election.back_off_time
,默认为100ms),防止再次冲突。
- cluster.election.duration
:每次选举的时间,超过该时间后,节点认为选举失败,重新选举。默认500ms
- cluster.election.initial_timeout
:一开始或master故障的情况下,节点首次尝试选举前等待的最长时间。默认100ms
- cluster.election.max_timeout
:设置第一次选举前节点等待的时间上限。目的是为了在网络分割创建下不会导致选举频率过低。
master节点会周期性的检测集群中的每个节点是否健康,集群中的每个节点也会周期性地检测master是否健康。
master和follower通过
cluster.fault_detection.*
配置进行故障检测。
但当master发现一个节点断开连接之后,它会绕过timeout和retry检测,并尝试将该节点从集群中移除。同样地,当一个节点检测到master断开连接之后,它会绕过timeout和retry检测并尝试发现或选举出新的master。
此外每个节点会通过周期性地往磁盘写入小文件然后删除的方式来检测其data路径是否健康,如果检测到
data
路径不健康,则会将其从集群中移除掉,参见
monitor.fs.health
配置
。
如果一个节点无法在合理的时间内apply更新的集群状态,master会将其移除。默认为2分钟(
cluster.publish.timeout
+
cluster.follower_lag.timeout
)。
master节点是可以变更集群状态的唯一节点。master节点会计算出状态变更,并将一批更新的集群状态发布给集群中的其他节点。每次发布时:
- master节点会将更新的集群状态广播到集群的所有节点上
- 其他节点在接收到该消息之后,会回复一个确认信息(但还没有apply接收到的状态)
- 一旦master节点接收到大多数master eligible节点的确认信息后,则说明
提交
了新的集群状态
- master节点发布另一个消息,让其他节点apply新提交的状态。
- 其他节点在接收到该消息之后,会apply新状态,并再次回复一个确认信息。
从第一步开始,到第三步必须在 30s 内完成。这由参数
cluster.publish.timeout
控制,默认30s 。如果超时,则会拒绝此次集群状态变更,并认为master节点出现了故障,此时会尝试选举一个新的master节点。
如果在
cluster.publish.timeout
超时之前提交了新的集群状态,则master节点会认为变更成功,它会一直等待超时或知道接收到集群中的所有节点都apply了更新状态的确认信息,然后开始处理和发布下一个集群状态更新。如果没有在
cluster.publish.timeout
之间内接收到某些确认信息,则认为这些节点出现了延迟,其集群状态落后于master的最新状态。master节点会等待
cluster.follower_lag.timeout
(默认90s)来让出现延迟的节点追赶当前的状态,如果在超时之前这些节点仍然无法apply新的集群状态,则认为其出现故障,master节点会从集群中移除掉该节点。
集群状态变更时,通常会发布相比之前集群状态的差异,以降低时间和带宽。但在节点丢失先前(如节点重新加入)的集群状态的情况下,master会发布完整的集群状态。
elasticsearch是一个点对点的系统,每个节点会直接与另一个节点进行通信。高吞吐量的API(index、delete、search)通常不会和master节点交互。master节点的责任是负责维护全局的集群状态,包括在节点加入和离开集群时分配分片。每次集群状态变更时,都会将新的状态发布到所有节点。
一个在节点加入或离开集群时,集群会自动识别到该事件,并将数据平均分发到其他可用节点上。
添加节点
本节是使用enroll的方式添加节点。但大部分情况下使用bootstrap的方式自发现节点(与enroll方式互斥),即:
当elasticsearch节点
首次
启动时,节点会尝试启用
自动安全功能
,并检查如下配置,如果检查失败,则不会启用自动安全功能:
- 节点是否首次启动
- 是否配置了安全特性
- 启动进程是否可以修改
当启用自动安全功能时,新节点(elasticsearch和
kibana
)需要enrollment token才能加入集群,方式如下:
在现有节点上执行
elasticsearch-create-enrollment-token
命令生成一个enrollment token:
bin\elasticsearch-create-enrollment-token -s node
使用上面生成的enrollment token启动新节点,elasticsearch会在
config\certs
中自动生成证书和密钥
bin\elasticsearch --enrollment-token <enrollment-token>
重复上述步骤来添加更多新节点。
在如下场景中,将不会启用自动安全功能:
- elasticsearch的
/data
目录存在但不为空:节点并非首次启动的重要信号,该节点可能是集群的一部分。
- elasticsearch.yml
不存在(或不可读),或
elasticsearch.keystore
不可读:节点启动的进程没有足够的权限修改节点配置。
- elasticsearch配置目录不可写:可能是管理员配置了目录只读权限,或启动elasticsearch的用不并不是安全elasticsearch的用户
如下配置不兼容自动安全功能,当存在任一配置时,节点启动进程会跳过配置自动安全功能阶段(自动安全功能会自动配置如下参数):
移除节点
在移除master-eligible节点时,如果集群中至少有三个master-eligible节点时,通常是一个一个移除,好让集群自动对voting configuration进行调整。
当需要在elasticsearch集群中移除
至少一半
的master eligible节点时,可以使用
Voting configuration exclusions
API将需要移除的master eligible节点加入exclusions列表,这样就可以同时移除这些节点。当一个节点添加到voting configuration exclusion列表后,除集群不再需要它的投票之外,该节点仍然能正常工作。另外需要注意的是elasticsearch不会自动将voting exclusions列表中的节点添加回voting configuration中。
注意移非master eligible节点不需要调用该接口,且移除的master eligible节点少于一半时也不需要调用该接口。
使用如下接口将节点从voting configuration中移除,返回成功表示移除成功:
# Add node to voting configuration exclusions list and wait for the system
# to auto-reconfigure the node out of the voting configuration up to the
# default timeout of 30 seconds
POST /_cluster/voting_config_exclusions?node_names=node_name
# Add node to voting configuration exclusions list and wait for
# auto-reconfiguration up to one minute
POST /_cluster/voting_config_exclusions?node_names=node_name&timeout=1m
可以使用如下接口查看exclusion列表:
curl -X GET "localhost:9200/_cluster/state?filter_path=metadata.cluster_coordination.voting_config_exclusions&pretty"
当一个master节点从voting configuration移除之后,会从voting configuration中选择另一个master eligible节点作为master。通常在进行维护时会将mater eligible节点加入exclusion列表,在维护结束之后清空exclusion列表。
# Wait for all the nodes with voting configuration exclusions to be removed from
# the cluster and then remove all the exclusions, allowing any node to return to
# the voting configuration in the future.
DELETE /_cluster/voting_config_exclusions
# Immediately remove all the voting configuration exclusions, allowing any node
# to return to the voting configuration in the future.
DELETE /_cluster/voting_config_exclusions?wait_for_removal=false
分片分配
是将分片分配到节点的过程,该过程可能发生在初始恢复阶段、副本分配阶段、rebalance或增删节点阶段。master节点的一个主要任务就是确定需要将哪些分片分配到哪些节点以及什么时候在节点之间移动分片,以达到rebalance集群的目的。
分片分配的结果保存在cluster state中。
集群级别的分片分配设置
可以使用如下参数来设置分片分配:
cluster.routing.allocation.enable
:
all
- (默认) 允许为所有类型的分配分片
primaries
- 仅允许分配主分片
new_primaries
- 仅为主分片的新索引分配分片
none
- 不允许为任何索引进行任何类型的分片分配
cluster.routing.allocation.node_concurrent_incoming_recoveries
一个节点执行incoming分片分配的并发数,incoming分片是指在节点上分配的目标分片(除非正在重分配分配,一般指副本分片)。默认2。
cluster.routing.allocation.node_concurrent_outgoing_recoveries
一个节点执行outgoing分片分配的并发数,outgoing分片是指在节点上分配的源分片(除非正在重分配分配,一般指主分片)。默认2。
cluster.routing.allocation.node_concurrent_recoveries
设置
cluster.routing.allocation.node_concurrent_incoming_recoveries
和
cluster.routing.allocation.node_concurrent_outgoing_recoveries
的快捷方式,默认2。
线上ES集群参数配置引起的业务异常分析
一文中就是因为手动设置了较大的
cluster.routing.allocation.node_concurrent_recoveries
值,导致并发relocate或recovery的分片过多导致磁盘出现问题。
分片的rebalance设置
elasticsearch会自动在节点之间均衡分片,但前提是不能违背
分配过滤器
和
cluster.routing.allocation.awareness.force
的限制。
用于在集群节点之间均衡索引的分片。主要配置参数如下:
cluster.routing.rebalance.enable
all
- (默认) 允许均衡所有类型的分片
primaries
- 仅均衡主分片
replicas
- 仅均衡副本分片
none
- 不均衡任何索引任何类型的分片
cluster.routing.allocation.allow_rebalance
:什么时候均衡分片
always
- 总是允许执行分片rebalance
indices_primaries_active
- 只有在集群的主分片分配之后才进行rebalance
indices_all_active
- (默认) 在集群的主分片和副本分片分配之后才进行rebalance
分片均衡的启发式配置
Rebalance会基于每个节点上分配的分片计算权重,并在节点之间移动分片来降低高权重的节点,并增加低权重的节点。一个节点的重量取决于它所持有的分片的数量,以及这些分片估计的总资源使用量,这些资源使用量为分片所在的磁盘大小以及往分片写入流量所需的线程数量。
用于配置什么时候会触发rebalance。有如下三个考量的配置:
cluster.routing.allocation.balance.shard
:每个节点上分配的分片总数的权重因子,默认是
0.45f
。提高该值可以让集群节点上的分片数目趋于一致。
cluster.routing.allocation.balance.index
:每个节点上分配的单个索引的分片数的权重因子,默认是
0.55f
。提高该值可以让集群节点上的每个索引的分片数目趋于一致。
cluster.routing.allocation.balance.disk_usage
:根据预测的磁盘字节大小来均衡分片,默认是
2e-11f
。提高该值可以让集群节点的底盘使用趋于一致。
cluster.routing.allocation.balance.write_load
:根据分片所需的索引线程的估计数量,默认是
10.0f
。定义每个分片的写负载权重因子。提高该值可以让节点的写负载趋于一致。
cluster.routing.allocation.balance.threshold
:设置触发rebalance 分片移动的因子(非负浮点数)。默认值为
1.0f
,提高该值将导致elasticsearch更快停止rebalance,使集群处于更加不均衡的状态
基于磁盘的分片分配是为了保证所有节点都能有足够的磁盘空间,该分配方式有一对阈值:低水位和高水位,目的是让节点不超过高水位,或只是暂时超过高水位。如果一个节点超过高水位,elasticsearch会转移部分分片来解决该问题。如果所有节点都超过高水位,elasticsearch将不会移动任何分片。
该分配模式需要满足过滤器和
forced awareness
的约束。
如果节点磁盘的写入速度高于elasticsearch移动分片的速度,则可能会让磁盘爆满。为了防止发生这种问题,elasticsearch使用了flood-stage水位(
cluster.routing.allocation.disk.watermark.flood_stage
),当磁盘达到该水位之后,elasticsearch会阻止向受影响的节点的索引分片写入数据,并继续向其他节点转移分片。当磁盘低于高水位之后,elasticsearch会自动取消写阻塞。
- cluster.routing.allocation.disk.watermark.low
:低水位,默认85%。当高于该数值之后,elasticsearch将不会往该节点分配分片
- cluster.routing.allocation.disk.watermark.high
:高水位,默认90%。当高于该数值之后,elasticsearch将会尝试移除该节点的分片
- cluster.routing.allocation.disk.watermark.flood_stage
:默认95%。当高于该数值之后,elasticsearch会将节点上的分片变为只读。
该方式需要首先在
elasticsearch.yml
中设置节点属性,然后通过
cluster.routing.allocation.awareness.attributes
配置分片所需的节点属性,这样elasticsearch会将分片分配到具有这些属性的节点上。
在一个节点出现故障之后,elasticsearch默认会将分片转移到其他节点上,为了防止这种情况发生,可以使用
forced-awareness
,这样在节点出现故障时,elasticsearch不会进行分片分配。更多可以参见官方文档。
可以使用分片分配过滤器来控制将索引的分片分配到哪里。分片分配过滤器可以基于自定义节点属性或内置的
_name
,
_host_ip
,
_publish_ip
,
_ip
,
_host
,
_id
和
_tier
属性。
在停用节点时通常会使用到集群级别的分片分配过滤器。可以创建一个过滤器来排除掉需要停用的节点,此时elasticsearch会将该节点的分片转移到其他节点上:
PUT _cluster/settings
{
"persistent" : {
"cluster.routing.allocation.exclude._ip" : "10.0.0.1"
}
}
cluster routing设置有如下几种(
attribute
可以包含多个,使用逗号分割):
cluster.routing.allocation.include.{attribute}
:将分片分配到至少包含其中一个
{attribute}
的节点
cluster.routing.allocation.require.{attribute}
:将分片分配到包含所有
{attribute}
的节点
cluster.routing.allocation.exclude.{attribute}
:将分片分配到不包含任一个
{attribute}
的节点
如果超过如下限制,elasticsearch将不会允许创建新的分片。主要涉及如下两种类型的分片:
- cluster.max_shards_per_node
:限制了集群中主分片和副本分片的总数,默认1000。计算方式为:
cluster.max_shards_per_node * number of non-frozen data nodes
- cluster.max_shards_per_node.frozen
:限制了集群中frozen类型的主分片和副本分片的总数,默认3000。计算方式为:
cluster.max_shards_per_node.frozen * number of frozen data nodes
elasticsearch中的每个索引都会被切分为多个分片,每个分片可以有多份拷贝,这些拷贝称为
replication group(包含主分片和副本分片)
,在添加和删除document时需要保证replication group的同步,否则会导致读数据不一致。
elasticsearch的数据复制模型基于
主备
模型,replication group中的某个拷贝作为主分片(
primary shard
),其余为副本分片(
replica shard
)。主分片为所有
索引
操作的入口,负责对索引操作的校验和分发。
写模型
Elasticsearch中的每个索引操作首先会通过
routing
找到对应的replication group,通常会基于对
document ID
的哈希。一旦确定了replication group,会将操作路由到该group的主分片上。该索引阶段称为
coordinating
stage。
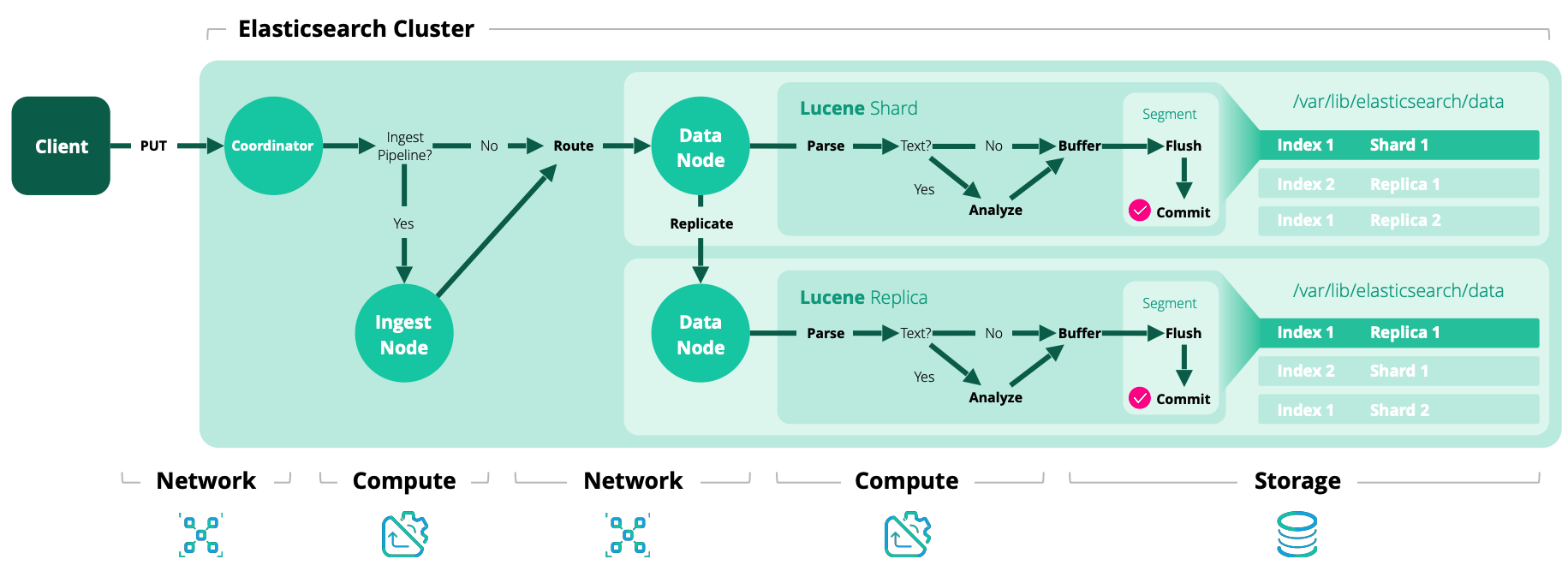
默认的分片检索方式如下:
shard_num = hash(_routing) % num_primary_shards
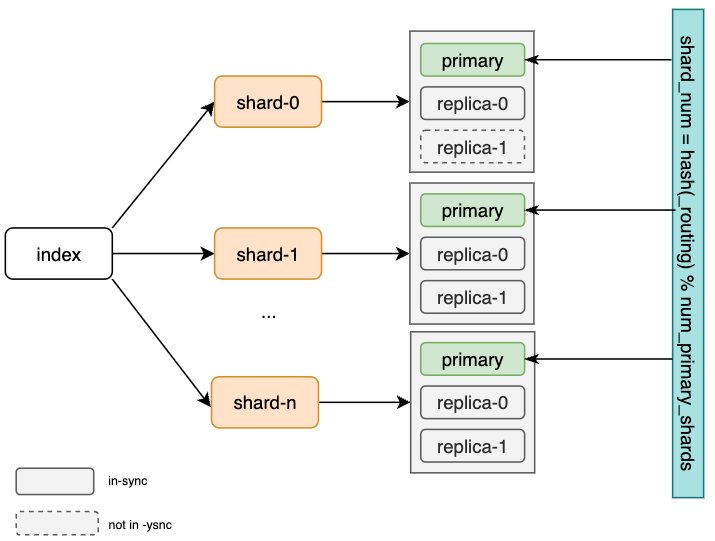
索引的下一个阶段是由主分片负责的
primary
stage。主分片负责校验操作并将其转发到其他副本,由于副本可能下线,因此主分片不需要将操作复制到所有副本。elasticsearch 的master节点维护了一组可以接受索引操作的副本列表,称为
in-sync
副本,该列表中的分片可以保证处理所有用户所需的索引和删除操作。主分片负责维护该集合,并将操作复制到集合中的所有副本。
分片的in-sync信息保存在cluster state中,因此需要通过
/_cluster/state
进行查询。如使用下面命令查看索引名为
my_index
的in-sync信息:
GET /_cluster/state?filter_path=metadata.indices.my_index.in_sync_allocations.*,routing_table.indices.my_index.*
在
in_sync_allocations
中可以看到in-sync的副本的
allocation_id
,在
routing_table
中可以看到
allocation_id
和副本的对应关系:
{
"metadata": {
"indices": {
"my_index": {
"in_sync_allocations": {
"0": [
"HNeGpt5aS3W9it3a7tJusg",
"wP-Z5fuGSM-HbADjMNpSIQ"
]
}
}
}
},
"routing_table": {
"indices": {
"my_index": {
"shards": {
"0": [
{
"primary": true,
"state": "STARTED",
"allocation_id": { "id": "HNeGpt5aS3W9it3a7tJusg" },
"node": "CX-rFmoPQF21tgt3MYGSQA",
...
},
{
"primary": false,
"state": "STARTED",
"allocation_id": { "id": "wP-Z5fuGSM-HbADjMNpSIQ" },
"node": "AzYoyzzSSwG6v_ypdRXYkw",
...
}
]
}
}
}
}
}
也可以使用如下命令查看所有的index和route table信息:
curl localhost:9200/_cluster/state?filter_path=metadata.indices.*,routing_table.indices.*|jq
更多参见
tracking-in-sync-shard-copies
主分片的流程如下:
- 校验输入的操作,如果无效则拒绝
- 本地执行该操作,如索引或删除相关的document,该阶段也会校验内容字段(如keyword的值太长)
- 将操作转发到当前in-sync的副本,如果有多个副本,则并行操作
- 一旦所有in-sync的副本完成操作并响应主分片,主分片会向客户端确认操作成功
每个in-sync的副本都会本地执行索引操作,称为replica阶段。
这些索引阶段(coordinating, primary和 replica)是按序执行的。每个阶段包含子阶段的生命周期。如在所有primary stage结束之前,coordinating stage不会结束(该过程可能会涉及多个主分片)。而在所有in-sync的副本分片完成本地索引之前,primary stage也不会结束。
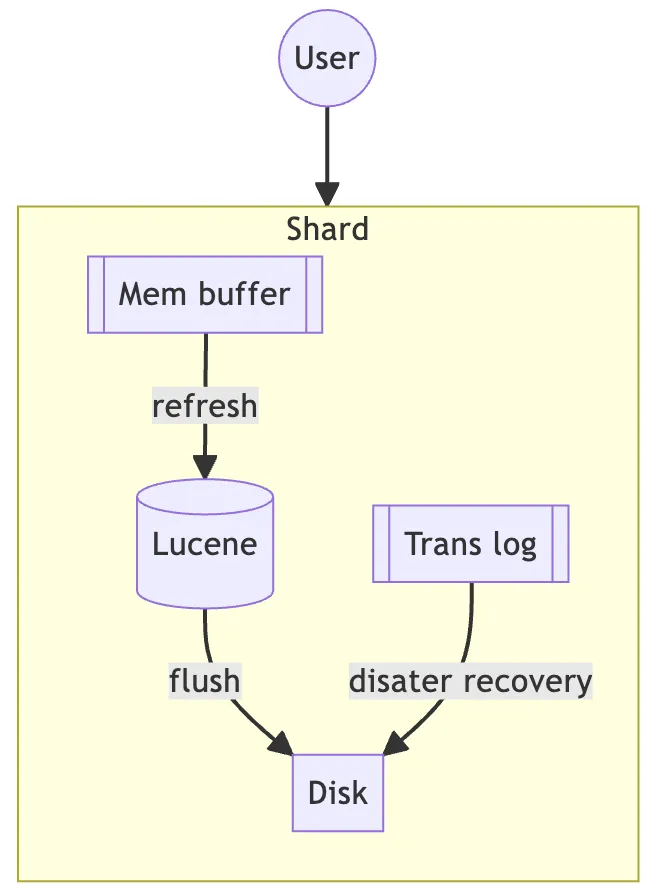
Refresh和flush
索引操作可以看做是传统数据系统中的写操作。分片中的每个索引操作包含两部分:refresh和flush。
在索引中添加、更新和删除document后,并不能立即被search到。这些document首先会被写入in-memory buffer中,等待refresh(默认1s)。refresh会将in-memory buffer的数据转化为一个内存中的segment(类似倒排索引),并清空buffer,此时才能够被search到。
shards由多个segments构成,其中包含了索引的变更操作,segments由refresh以及后续的merge操作所创建。segment是不可修改的,因此每次索引操作都会创建新的segment。

Flush
如上图所示,新的被索引的document会被添加到in-memory buffer的同时,还会被写入分片的translog中。每30min或translog达到512MB时会执行一次flush操作。如下图所示,在flush时,会将小的segment合并为一个大的segment,然后将合并后的segment同步到磁盘,并清空translog。

使用
flush API
可以提交translog中的操作。
参考:
故障处理
当主分片故障时,所在节点会给master节点发送消息,此时索引操作会被中断(默认最长1分钟)。master在接收到消息之后会将一个副本分片提升为新的主分片,然后会将操作转发到新的节点进行处理。master节点也会监控node的健康状态,在持有主分片的节点因为网络等问题被隔离情况下,master会主动提升一个主分片。
在主分片的操作完成之后,它需要处理副本分片执行时可能出现的问题,如副本本身的故障或网络原因导致无法连接到副本。此时,主分片会给master发送从in-sync 副本集中移除故障分片的请求,在master确认移除该分片之后,主分片会最终确认该移除操作。之后,master会在其他节点构建一个新的副本拷贝来让集群恢复到健康状态。
主分片在给副本分片转发操作的同时,它也需要副本分片来维护其主分片的角色。当一个主分片由于网络分割(或长时间GC)被隔离之后,在其感知到被降级之前,可能会继续处理索引操作。副本会拒绝处理来自老的主分片的操作,当主分片接收到其他分片的拒绝响应之后,它会请求master来了解此次变更,之后的操作会被路由到新的主分片。
这部分内容类似kafka的ack功能:
在创建索引时可以指定
wait_for_active_shards
来提高数据的可靠性。默认情况下,写操作只要求主分片active即可,通过指定该值可以执行写操作时要求active的分片数。
默认情况下,当只有主分片时,该分片在处理操作的过程中不再涉及外部校验。
读模型
elasticsearch的主备模型可以保证所有分片的拷贝是相同的,因此in-sync的分片就可以处理读请求。
当一个
coordinating
节点接收到读请求后,该节点会负责将其转发到持有相关分片的节点,并整理响应,然后将响应转发给客户端,基本流程如下:
- 将请求解析为相关的分片,由于大部分查找会涉及一个或多个分片,因此通常需要读取多个分片,每个分片包含一部分数据。
- 为每个相关的分片选择一个active的拷贝,可以是主分片也可以是副本分片。elasticsearch默认采用
Adaptive replica selection
的方式选择分片拷贝
- 向选择的拷贝发送分片级别的读请求
- 组合结果并作出响应
当一个分片无法响应读请求时,coordinating节点会将请求发送到另一个副本拷贝。
当一个多个分片故障的情况下,如下接口会返回部分结果,其HTTP状态码为
200
,可以通过
time_out
和
shards
字段查看是否有分片故障。
下面是一个search操作的
示意图
,分为query 和fetch两个阶段:

故障
发生故障时可能会出现如下问题
- 一个分片拖慢了整个索引操作:每次操作时,由于主分片会得到所有in-sync的分片,因此一个较慢的分片可能会拖慢整个replication group的处理
- 被隔离的主分片可能会继续处理无法被确认的写操作。这是因为被隔离的主分片只有在给其副本发送请求或连接到master时才会知道它被隔离。此时已经到达该分片的请求可能会被并行读操作读取到,elasticsearch通过(默认每秒)ping master和在无法连接到master时拒绝索引操作来缓解这个问题。
index template可以让用户在创建索引(index)时,引用已保存的模板来减少配置项,如指定副本数。一个index template可以由多个component template组成。如下定义了两个component template
my-mappings
和
my-settings
,并在
my-index-template
中引用它们。
# Creates a component template for mappings
PUT _component_template/my-mappings
{
"template": {
"mappings": {
"properties": {
"@timestamp": {
"type": "date",
"format": "date_optional_time||epoch_millis"
},
"message": {
"type": "wildcard"
}
}
}
}
}
# Creates a component template for index settings
PUT _component_template/my-settings
{
"template": {
"settings": {
"index.lifecycle.name": "my-lifecycle-policy"
}
},
"_meta": {
"description": "Settings for ILM",
"my-custom-meta-field": "More arbitrary metadata"
}
}
PUT _index_template/my-index-template
{
"index_patterns": ["my-data-stream*"],
"data_stream": { },
"composed_of": [ "my-mappings", "my-settings" ],
"priority": 500,
"_meta": {
"description": "Template for my time series data",
"my-custom-meta-field": "More arbitrary metadata"
}
}
ILM用于自动管理索引,如:
- 在索引达到一定大小或document打到一定数目时创建一个新的索引
- 按天、周、月来创建新的索引
- 根据数据retention规则来删除老的索引
ILM定义了如下 lifecycle
phases
:
- Hot
: 索引是活动的,可以被更新和查询
- Warm
: 索引无法被更新,但可以被查询
- Cold
: 索引无法被更新,但可以被查询,且查询的频率
较低
- Frozen
: 索引无法被更新,但可以被查询,且查询的频率
极低
- Delete
: 索引可以被安全地删除
更新policy
当更新一个索引的policy后,当前phase仍然会使用之前的policy,当索引进入下一个phase后,会使用新的policy。rollover操作会创建一个新的索引,使用新的policy。
data steam可以跨索引处理只追加的时序数据,非常适用于日志、事件、指标和其他持续产生的数据。可以直接向data stream提交索引或查找请求,data stream会将其自动路由到保存流数据的后端索引。推荐使用
ILM
来在数据达到一定时间或大小时滚动data stream,也可以手动
配置
roll over
(roll over可以在滚动data stream时创建新的索引)
创建data stream 前需要创建一个index template。然后在index template中包含
data_stream
对象即可。
PUT _index_template/my-index-template
{
"index_patterns": ["my-data-stream*"],
"data_stream": { },
"composed_of": [ "my-mappings", "my-settings" ],
"priority": 500,
"_meta": {
"description": "Template for my time series data",
"my-custom-meta-field": "More arbitrary metadata"
}
}
当请求的索引符合index template的索引模式时,就会
自动
创建一个data stream
POST my-data-stream/_doc
{
"@timestamp": "2099-05-06T16:21:15.000Z",
"message": "192.0.2.42 - - [06/May/2099:16:21:15 +0000] \"GET /images/bg.jpg HTTP/1.0\" 200 24736"
}
也可以通过如下接口手动创建data stream:
PUT _data_stream/my-data-stream
运维
elasticsearch的master节点负责创建和维护集群状态,master节点的日志要比其他节点更丰富,因此当集群不健康时,可以通过查看master日志来定位问题。
审计日志
可以记录安全相关的事件,如认证失败,连接拒绝和数据访问等事件。如果需要配置审计,则必须在集群中的所有节点上都进行配置。对于静态配置,例如
xpack.security.audit.enabled
,就需要在所有节点的
elasticsearch.yml
中进行配置;对于动态配置,则可以使用
集群配置更新API
。
- xpack.security.audit.enabled
:默认false
集群
查看集群状态
GET /_cluster/stats
GET _cluster/health
当一个data节点重启之后,分配进程在将该节点的分片转移到其他节点之前,会等待
index.unassigned.node_left.delayed_timeout
(默认1分钟),此时会出现大量I/O。但如果节点需要短暂重启,为了避免出现这类I/O,可以在节点重启前临时
禁用
副本分片分配功能:
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "primaries"
}
}
刷新到translog:
POST /_flush
在节点重启之后,记得恢复默认的分片分配方式:
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": null
}
}
节点
查看节点磁盘和分片分配
# curl 127.0.0.1:9200/_cat/allocation?v=true
shards disk.indices disk.used disk.avail disk.total disk.percent host ip node
1205 510.7gb 577.4gb 430.3gb 1007.7gb 57 10.157.4.83 10.157.4.83 elkdata01
1205 406.2gb 470.4gb 537.3gb 1007.7gb 46 10.157.4.82 10.157.4.82 elkdata02
1205 438.3gb 502.5gb 505.2gb 1007.7gb 49 10.157.4.79 10.157.4.79 elkdata03
1205 502.1gb 567.4gb 440.3gb 1007.7gb 56 10.157.4.80 10.157.4.80 elkdata04
1204 530.7gb 595.1gb 412.6gb 1007.7gb 59 10.157.4.21 10.157.4.21 elkdata05
1205 496.5gb 560.4gb 447.3gb 1007.7gb 55 10.157.4.81 10.157.4.81 elkdata06
1204 503.4gb 568gb 439.7gb 1007.7gb 56 10.157.4.23 10.157.4.23 elkdata07
1205 452.2gb 517.1gb 490.6gb 1007.7gb 51 10.157.4.22 10.157.4.22 elkdata08
GET /_nodes
GET /_nodes/<node_id>
GET /_nodes/<metric>
GET /_nodes/<node_id>/<metric>
metrics支持如下选项:
aggregations
:给出可用的聚合类型信息
http
:给出该节点的HTTP接口信息
indices
:节点界别的索引信息
total_indexing_buffer
: 该节点上的最大索引缓存
ingest
:给出ingest pipelines 和 processors信息。
jvm
:jvm的名称、版本和配置信息。
os
:系统信息。
plugins
:单个节点安装的插件和模块详情。
process
:进程信息。
settings
:elasticsearch.yml文件中的所有节点配置。
thread_pool
:每个线程池的信息。
transport
:节点的传输接口信息。
索引
列出
集群中的索引
curl -XGET "localhost:9200/_cat/indices?h=index"
增加分片可以提高查询速度。
target可以是data stream,索引名称或别名:
GET /_cat/shards/<target>
GET /_cat/shards
主要参数使用的参数为
h
,其指定了展示的列表名称,一般使用
index, i, idx
:索引名称
shard, s, sh
:分片名称
prirep, p, pr, primaryOrReplica
:分片类型,
primary
或
replica
.
state, st
:分片状态
INITIALIZING: 正在从同类分片或网关初始化分片
RELOCATING: 正在分配分片
STARTED: 分片已经启动,说明分片正常工作
UNASSIGNED: 无法分配分片
ip
:节点IP
node
:节点名称
unassigned.at, ua
:分片变为UNASSIGNED状态的UTC时间
unassigned.reason, ur
:分片变为UNASSIGNED状态的原因,原因代码参见
官方文档
举例如下:
GET _cat/shards?h=index,shard,prirep,state,node,unassigned.reason
对于unassigned的分片,该接口可以解释为什么没有对其进行分配,对于已分配的分片,则解释为什么该分片位于当前节点上。
GET _cluster/allocation/explain
{
"index": "my-index-000001",
"shard": 0,
"primary": true
}
如果没有指定参数,则elasticsearch会随机检索一个unassigned的主分片会副本分片,如果没有检索到unassigned的分片,则返回400。
查看分片分配进度
Recovery可能发生在如下场景中:
如下接口可以查看recovery信息,主要查看recovery进度,
target
可以是索引、data stream或别名。
GET /_cat/recovery/<target>
GET /_cat/recovery
elasticsearch的分片数目是通过
index.number_of_shards
静态配置的,但副本数目可以通过
index.number_of_replicas
动态配置。key使用split功能将现有索引拆分为有更多主分片的新索引,这样就可以提高数据处理的速度。
POST /<index>/_split/<target-index>
PUT /<index>/_split/<target-index>
首先需要将拆分的索引设置为只读:
PUT /my_source_index/_settings
{
"settings": {
"index.blocks.write": true
}
}
POST /my_source_index/_split/my_target_index
{
"settings": {
"index.number_of_shards": 2
}
}
注意:data stream需要配置
rolled over
之后才能拆分data stream中的索引。拆分上限为1024个分片。
索引拆分的工作原理如下:
- 创建目标索引,除主分片数目不同之外,具有和源所有相同的配置
- 如果系统支持硬链接,则使用硬链接将源索引的segments链接到目标索引,否则将所有segments拷贝到新索引。
- 重新哈希所有document
可以使用
_cat recovery
API
查看拆分进度。
与split API相反,该API用减少索引的主分片数目。
alias可以为index或data stream创建别名。一个alias可以指向多个index或data stream,用于数据的读写。
创建别名
POST _aliases
{
"actions": [
{
"add": {
"index": "logs-nginx.access-prod",
"alias": "logs"
}
}
]
}
支持通配符模式
POST _aliases
{
"actions": [
{
"add": {
"index": "logs-*",
"alias": "logs"
}
}
]
}
可以在component或index template中为index或data stream创建索引:
# Component template with index aliases
PUT _component_template/my-aliases
{
"template": {
"aliases": {
"my-alias": {}
}
}
}
# Index template with index aliases
PUT _index_template/my-index-template
{
"index_patterns": [
"my-index-*"
],
"composed_of": [
"my-aliases",
"my-mappings",
"my-settings"
],
"template": {
"aliases": {
"yet-another-alias": {}
}
}
}
如果需要对alias写入数据(如使用
POST /<allias>/_doc
),需要在alias中指定is_write_index的index或data stream:
POST _aliases
{
"actions": [
{
"add": {
"index": "logs-nginx.access-prod",
"alias": "logs"
}
},
{
"add": {
"index": "logs-my_app-default",
"alias": "logs",
"is_write_index": true
}
}
]
}
可以对alias创建index pattern,用于检索数据。
document
查询可以使用
search API
和
documen API
查询索引的所有doc:
curl -X GET "localhost:9200/my-index-000001/_search?pretty"
查询特定的doc:
curl -X GET "localhost:9200/my-index-000001/_doc/0?pretty"
移动数据
将集群分片移动到特定节点
该方式并不会区分特定的索引,主要用于故障隔离或节点维护。参见
集群分片分配过滤器
。
该方式以
索引
为单位,可以将特定索引转移到特定的节点上,主要用于将索引转移到合适的节点处理(如使用硬件更好的节点来处理某些需要优先保证的索引)。过滤器的属性可以使用自定义属性,也可以使用内置属性,如
_name
,
_ip
,
_host
等。如下表达式用于将
test
索引转移到IP为
192.168.2.*
的节点:
PUT test/_settings
{
"index.routing.allocation.include._ip": "192.168.2.*"
}
与
集群分片分配过滤器
类似,支持如下三种过滤方式,可以指定多个过滤器,但在执行分片分配时需要同时满足这些过滤器的要求:
- index.routing.allocation.include.{attribute}
- index.routing.allocation.require.{attribute}
- index.routing.allocation.exclude.{attribute}
该方式以
分片
为单位,可以手动配置分片分配,如将一个分片从一个节点迁移到另一个节点,取消分片分配以及将unassigned的分片分配到特定节点。
需要注意的是在执行
reroute
命令之后,elasticsearch也会执行rebalance(
cluster.routing.rebalance.enable
为true)。
在执行
reroute
时可以使用dry run模式,即在请求时添加
?dry_run
参数即可,在命令执行后会计算并返回命令应用之后的集群状态,但不会真正修改集群状态。主要参数如下:
dry_run
:如上
explain
:如果为true,则响应中会包含一段针对命令为什么可以或无法执行的解释。
请求体的commands支持如下:
move
:将
STARTED
状态的分片从一个节点移到另一个节点,需要的参数为:
index
:索引名称
shard
:索引的分片号
from_node
:分片所在的节点
to_node
:迁移分片的目的节点
cancel
:取消分配分片。用于强制从主分片同步重新同步现有的副本。默认只能取消
副本
分片,如果需要取消主分片,则需要在请求中指定
allow_primary
标记。所需参数如下:
index
:索引名称
shard
:索引的分片号
node
:分片所在的节点
allocate_replica
:在节点上申请
unassigned
的
副本
分片。所需参数和
cancel
相同。如果需要移动主分片,则需要额外的命令。由于主分片通常是由elasticsearch自动管理的,因此不建议对主分片进行操作。但在如下场景下elasticsearch无法自动分配主分片:
- 创建了主分片,但没有找到合适的节点
- 当前数据节点上没有找到最新数据的分片,为了防止数据丢失,系统不会将老分片提升为主分片。
下面两条命令可能导致数据丢失,主要用于原始数据无法恢复且能够接受数据丢失的场景。需要注意的是,在执行如下命令之后,如果新加入了一个包含受影响的分片的节点,那么该节点上的分片会被删除或覆盖。
- allocate_stale_primary
:将主分片分配到一个有旧数据拷贝的节点。参数同
cancel
- allocate_empty_primary
:将空的主分片分配到一个节点。这样会导致数据全部丢失。
POST /_cluster/reroute?metric=none
{
"commands": [
{
"move": {
"index": "test", "shard": 0,
"from_node": "node1", "to_node": "node2"
}
},
{
"allocate_replica": {
"index": "test", "shard": 1,
"node": "node3"
}
}
]
}
不能通过拷贝data目录的方式来备份节点数据,通过这种方式来恢复数据可能会导致数据丢失或不一致。
使用snapshot可以:
在使用snapshot之前需要
注册snapshot仓库
,之后可以使用
snapshot 生命周期管理
(SLM)来自动管理snapshot。
snapshot默认包含
集群状态(include_global_state为true)
,所有常规的data stream和索引,但不包含节点配置文件和
安全配置文件
。集群状态包含:
Elasticsearch 8.0 以及之后的版本中,feature state是唯一可以备份和恢复系统索引和系统data stream的方法。
在备份一个索引时,snapshot会拷贝该索引的segment并会将其保存到snapshot仓库中。由于segment是不可变的,因此snapshot只会拷贝相比仓库中新增的segment。每个snapshot逻辑上是独立的,因此在删除一个snapshot时不会对仓库中的其他snapshot造成影响。
snapshot和分片分配
snapshot会从索引的
主分片
拷贝segment,当启动一个snapshot时,elasticsearch会
立即
从所有可用的主分片上拷贝segment,如果一个分片正在启动或relocating,则elasticsearch会等到该流程结束后才启动拷贝,如果一个或多个主分片不可用,则snapshot会失败。
一旦一个snapshot开始拷贝分片的segment,则elasticsearch不会将该分片转移到其他节点(即使发生了rebalancing或分片分配设置触发了reallocation),elasticsearch会在snapshot分片拷贝结束之后才会移动该分片。
snapshot的兼容性
不能将snapshot恢复给一个更早版本的elasticsearch。
索引兼容性
从snapshot中恢复的索引必须兼容当前的集群版本
创建snapshot仓库
以
Azure repository
为例
如果elasticsearch版本小于8.0(8.0及以上版本以及继承该插件),则需要在所有节点上安装
repository-azure
插件:
sudo bin/elasticsearch-plugin install repository-azure
所有节点添加storage account认证信息:
echo "$(storageaccountName)" | /usr/share/elasticsearch/bin/elasticsearch-keystore add azure.client.default.account
echo "${azurestorage_key}" | /usr/share/elasticsearch/bin/elasticsearch-keystore add azure.client.default.key
在所有节点的
elasticsearch.yml
中
添加
azure.client.default.endpoint_suffix: core.chinacloudapi.cn
配置,并重启服务。使用如下命令可以已查看节点配置是否生效:
GET /_nodes/<node_id>/_all/
配置仓库
container
:Azure Storage account的container名称,在创建仓库前需要提前创建好。3-63个字符长度
base_path
:container中存放备份数据的路径,下面例子中为
backup-container/backups
curl -X PUT "localhost:9200/_snapshot/my_backup2?pretty" -H 'Content-Type: application/json' -d'
{
"type": "azure",
"settings": {
"container": "backup-container",
"base_path": "backups", //container中的路径
"chunk_size": "32MB",
"compress": true
}
}
'
查看仓库
GET /_snapshot/<repository>
GET /_snapshot
校验仓库
POST _snapshot/<repository>/_verify
删除仓库
DELETE /_snapshot/my_repository
备份
备份的请求
配置
中主要填写
indices
和
feature_states
,前者默认是空
[]
,不包含所有index和data stream;后者与
include_global_state
有关,如果
include_global_state
为
true
,则包含所有
feature_states
,反之不包含任何
feature_states
。
indices
字段可以使用
-
排除掉不需要备份的索引,如
"indices": "*,-.*"
表示备份所有data stream和index,但不包含系统索引以及以
.
开头的索引。
SLM 方式自动创建snapshot
创建SLM来管理snapshot,调度时间
参考
。
schedule
字段的含义如下,
hours
取值为0-23。
"schedule": "0 30 1 * * ?",
表示每天
1:30
触发调度。
<seconds> <minutes> <hours> <day_of_month> <month> <day_of_week> [year]
name
字段用于自动生成snapshot名称,用法参考
Data math
。
SLM_settings
配置
PUT _slm/policy/nightly-snapshots
{
"schedule": "0 30 1 * * ?",
"name": "<nightly-snap-{now/d}>",
"repository": "my_repository", //注册的snapshot仓库
"config": {
"indices": "*", //需要保存的data stream或索引
"include_global_state": true
},
"retention": {
"expire_after": "30d",
"min_count": 5,
"max_count": 50
}
}
使用如下命令可以手动触发创建一个snapshot
curl -X POST "localhost:9200/_slm/policy/nightly-snapshots/_execute?pretty"
使用如下命令配置retention任务:
PUT _cluster/settings
{
"persistent" : {
"slm.retention_schedule" : "0 30 1 * * ?"
}
}
使用如下命令可以立即触发retention:
POST _slm/_execute_retention
查看SLM配置
curl -X GET "localhost:9200/_slm/stats?pretty"
查看slm的策略执行情况,包括策略配置和最近成功和失败情况:
curl -X GET "localhost:9200/_slm/policy/nightly-snapshots?pretty"
手动调用
创建snapshot API
:
PUT _snapshot/my_repository/my_snapshot?wait_for_completion=true
也可以添加配置:
PUT /_snapshot/my_repository/snapshot_2?wait_for_completion=true
{
"indices": "index_1,index_2",
"ignore_unavailable": true,
"include_global_state": false,
"metadata": {
"taken_by": "user123",
"taken_because": "backup before upgrading"
}
}
备份特定的feature gate
默认情况下集群状态的snapshot也会包含所有的feature gate,同样地,默认排除集群状态的snapshot也会排除掉所有feature gate。
查看支持的feature gate:
curl -X GET "localhost:9200/_features?pretty"
使用如下方式备份特定的feature gate,下面例子中只会备份kibana 和elasticsearch 安全特性:
PUT _slm/policy/nightly-snapshots
{
"schedule": "0 30 2 * * ?",
"name": "<nightly-snap-{now/d}>",
"repository": "my_repository",
"config": {
"indices": "-*",
"include_global_state": true,
"feature_states": [
"kibana",
"security"
]
},
"retention": {
"expire_after": "30d",
"min_count": 5,
"max_count": 50
}
}
上述是使用slm方式创建的只包含kibana和elasticsearch安全的 feature gate备份,当然也可以手动创建:
PUT /_snapshot/my_repository/my_repository_2023_6_7?wait_for_completion=true
{
"indices": "-*",
"ignore_unavailable": true,
"include_global_state": true,
"feature_states": [
"kibana",
"security"
]
}
查看备份状态
查看
snapshot配置和状态:
GET _snapshot/<repository>/_current //查看当前运行的snapshot,没有运行的则返回空
GET _snapshot/<repository>/_all //查看所有snapshot配置
GET _snapshot/<repository>/my_snapshot //查看特定的snapshot配置
查看snapshot中的分片的详细信息(该
接口
比较耗时):
GET _snapshot/_status //查看当前运行的snapshot,没有运行的则返回空
GET _snapshot/<repository>/_status //查看当前运行的snapshot,没有运行的则返回空
GET _snapshot/<repository>/<snapshot>/_status //查看当前特定的snapshot
删除一个snapshot
curl -X DELETE "localhost:9200/_snapshot/my_repository/my_snapshot_2099.05.06?pretty"
恢复
注意:
- 只能在 elected master节点上恢复snapshot
- 如果要恢复一个已存在的索引,要求该索引是
closed
的,且主分片的数目和snapshot的主分片数目相同
- 不能恢复open状态的索引,以及包含backing index的data stream
- 恢复操作会自动open 被恢复的索引以及backing index
为避免恢复冲突,可以事先删除集群中需要恢复的索引
# Delete an index
DELETE my-index
# Delete a data stream
DELETE _data_stream/logs-my_app-default
查看snapshot
curl -X GET "localhost:9200/_snapshot?pretty"
curl -X GET "localhost:9200/_snapshot/my_repository/*?verbose=false&pretty"
使用如下方式查看一个snapshot中的feature gate
GET _snapshot/my_repository/my_snapshot_2099.05.06
使用snapshot恢复集群状态时,默认会恢复所有的feature gates,可以使用如下方式恢复特定的feature gate。在恢复feature gate时,elasticsearch会关闭并覆盖该feature的现有索引。
curl -X POST "localhost:9200/_snapshot/my_repository/my_snapshot_2099.05.06/_restore?pretty" -H 'Content-Type: application/json' -d'
{
"feature_states": [ "geoip" ],
"include_global_state": false, # 排除掉集群状态
"indices": "-*"
}
'
用于恢复整个集群状态和feature gates,在恢复前需要关闭一些特性,恢复结束之后再打开。
查看恢复状态
查看集群和节点状态:
GET _cluster/health
GET _cat/shards?v=true&h=index,shard,prirep,state,node,unassigned.reason&s=state
使用
Index recovery API
查看当前正在进行或已经完成的备份
curl -X GET "localhost:9200/_recovery?pretty"
curl -X GET "localhost:9200/my-index/_recovery?pretty"
STAGE
字段可以显示当前的恢复阶段:
Recovery has not started.
Reading index metadata and copying bytes from source to destination.
Verifying the integrity of the index.
Replaying transaction log.
Cleanup.
Complete.
清理陈旧的数据
snapshot仓库中可能会包含不被当前snapshot引用的陈旧数据,使用
clean up
API可以清除掉这些数据:
POST /_snapshot/my_repository/_cleanup
snapshot与集群名称无关,因此可以在一个集群中创建snapshot,然后恢复到另一个兼容的集群中
网络诊断
elasticsearch的节点通信和客户端通信时都会使用一条或多条TCP通道,每条TCP通道都属于节点的某个
transport_worker
线程。每个
transport_worker
线程只负责其所有的通道的数据发送和接收。此外,elasticsearch会将每个http和transport的服务端socket分配给某个
transport_worker
线程,然后由它来接收到服务端socket的连接。
如果elasticsearch的某个线程需要在特定的通道上发送数据,它会将数据传递给其所属的
transport_worker
线程。通常
transport_worker
线程不会完成处理其接收到的消息,相反,它会做一些预处理,然后将消息分发给不同的
线程池
来完成剩余的工作。如bulk消息会被分发到
write
线程池,searches会被分发到
search
线程池等。但有些情况下,消息的处理很快,此时会在
transport_worker
中完成所有的工作,而不会再进行消息分发。
默认一个CPU一个
transport_worker
线程,但可能存在上千条TCP通道。如果从TCP通道中接收到数据,但其所在的
transport_worker
又处于繁忙状态,此时需要等待线程结束前面的工作才能处理数据。类似地,在
transport_worker
线程空闲时才能处理数据的发送。
使用
hot threads
API 可以看到一个空闲的线程如下:
"elasticsearch[instance-0000000004][transport_worker][T#1]" #32 daemon prio=5 os_prio=0 cpu=9645.94ms elapsed=501.63s tid=0x00007fb83b6307f0 nid=0x1c4 runnable [0x00007fb7b8ffe000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPoll.wait(java.base@17.0.2/Native Method)
at sun.nio.ch.EPollSelectorImpl.doSelect(java.base@17.0.2/EPollSelectorImpl.java:118)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(java.base@17.0.2/SelectorImpl.java:129)
- locked <0x00000000c443c518> (a sun.nio.ch.Util$2)
- locked <0x00000000c38f7700> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(java.base@17.0.2/SelectorImpl.java:146)
at io.netty.channel.nio.NioEventLoop.select(NioEventLoop.java:813)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:460)
at io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:986)
at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74)
at java.lang.Thread.run(java.base@17.0.2/Thread.java:833)
注意
transport_worker
线程的状态应该总是
RUNNABLE
的,
cpu=
和
other=
分别表示线程运行使用的CPU以及等待输入使用的CPU。
监控
elasticsearch_exporter
给出了Prometheus形式的指标,内部通过调用
_nodes/stats
来获取节点状态,通过调用
/_all/_stats
开获取索引状态。
elasticsearch_cluster_health_status
:查看集群状态
elasticsearch_cluster_health_number_of_nodes
:集群中的总节点数
elasticsearch_cluster_health_unassigned_shards
:为创建或分配的分片
elasticsearch_cluster_health_active_shards
:集群中active的shards的总数(含主分片和副本分片)
elasticsearch_cluster_health_relocating_shards
:elasticsearch会给予balancing或当前资源使用情况来在节点之间移动分片,使用该指标可以查看发生分片移动的时间。
Node
CPU
elasticsearch_process_cpu_percent
:elasticsearch进程的CPU使用百分比
DISK
disk可能是磁盘也可能是pvc,根据特定的指标给出如下表达:
|
Important Metrics for Node Health
|
|
| 磁盘容量 |
Total disk capacity on the node’s host machine. |
| 磁盘使用量 |
Total disk usage on the node’s host machine. |
| 可用的磁盘量 |
Total disk space available. |
| 已用磁盘百分比 |
Percentage of disk which is already used. |
JVM
elasticsearch_jvm_memory_max_bytes
: jvm内存总量,分为heap和noheap
elasticsearch_jvm_memory_used_bytes
/
elasticsearch_jvm_memory_max_bytes
:展示了各个area的内存使用量。
sum(avg_over_time(elasticsearch_jvm_memory_used_bytes{cluster_name="xx",area="heap"}[1m]))by(instance)/sum(avg_over_time(elasticsearch_jvm_memory_max_bytes{cluster_name="xx",area="heap"}[1m]))by(instance)
Thread Pools
每个节点都会使用一些线程池来执行如查找、索引、运行集群状态请求或节点发现等操作。thread Pools可以限制每种操作使用的资源。thread Pools的指标有三种:
active
、
queue
和
rejected
。
active
可以表示正在执行的操作,如active的search thread pool为10,表示当前正在处理的查询数为10。
queue
表示等待被处理的操作,设置较大的队列长度会存在请求丢失的风险(如果节点宕机)。如果出现queued和rejected的线程不断增加的情况,则需要降低请求速率,或增加节点的处理器数目,或增加集群的节点数目。
rejected
表示被拒绝的操作,此时没有可用的线程,且队列已满,通常是因为流量过大导致的。
每个节点维护了很多类型的thread pools,但最重要的是search、management和bulk(也被称为write thread pool,包括write/update/delete),对应请求类型:search、merge和bulk/write操作。在队列达到队列长度上限时,请求会被拒绝。不同类型的thread pool有不同的
队列长度
。
- search
:对应发送到es的count、search和suggest操作。如果出现大量rejected,则说明请求数目过多。
- write
:用于索引操作(document的增删改以及bulks操作),出现rejected可能会导致数据丢失。bulk操作是一种一次性发生多个请求的高效方式。出现bulk rejected通常是因为在一个bulk请求中index了过多的documents。根据elasticsearch的
文档
,出现bulk rejected并不需要过多担心,但最好实现一个线性或退避策略来处理bulk rejected。
- management
:用于集群管理。通常只会使用一两个线程,但该类型的线程池是可扩展的。
缓存
Field Data Cache
用于
fielddata
,以支持在查询的时候使用排序或聚合操作。该缓存没有限制,因此如果该缓存使用过大,可能会导致内存问题,进而影响节点和集群的健康。推荐为堆大小的20%
- elasticsearch_indices_fielddata_memory_size_bytes
Node Query Cache
用于在
filter context
中缓存查询结果,用来增加重复查询下的性能。默认为节点缓存的10%。
注意
该指标只限于2.0以前的版本。
- elasticsearch_indices_query_cache_cache_total
- elasticsearch_indices_query_cache_cache_size
- elasticsearch_indices_query_cache_count
Shard Request Cache
用于在分片级别缓存hits, aggregations和 suggestions的
总数
,注意并不包含查询结果。默认为节点最大堆内存的1%。
pending task
pending task由主分片节点处理,如果该值变大,说明主分片节点处于繁忙状态。
elasticsearch_cluster_health_number_of_pending_tasks
:
search=query+fetch
|
Metric description
|
Name
|
Metric type
|
| query总数 |
elasticsearch_indices_search_query_total
|
Work: Throughput |
| query花费的总时间 |
elasticsearch_indices_search_query_time_seconds
|
Work: Performance |
| fetch总数 |
elasticsearch_indices_search_fetch_total
|
Work: Throughput |
| fetches花费的总时间 |
elasticsearch_indices_search_fetch_time_seconds
|
Work: Performance |
- Query load
:
elasticsearch_indices_search_query_total
,出现异常的尖峰或下降说明底层可能出现了问题。
- Query latency
:
elasticsearch_indices_search_query_time_seconds / elasticsearch_indices_search_query_total
- Fetch latency
:
search处理
中的第二个阶段,该值过大,可能是因为磁盘处理过慢、正在渲染查询的documents或请求结果过多导致的。
elasticsearch_indices_search_fetch_time_seconds / elasticsearch_indices_search_fetch_total
Indexing Refresh
latency
:
elasticsearch_indices_refresh_time_seconds_total
/
elasticsearch_indices_refresh_total
。如果该值上升,说明在同一时间尝试index过多的documents。如果正在index很多documents,且不需要在第一时间查询,则可以通过
降低refresh频率
来优化index性能,在index结束之后设置回原来的值(默认1s)。
curl -XPUT <nameofhost>:9200/<name_of_index>/_settings -d '{
"index" : {
"refresh_interval" : "-1"
}
}'
Flush latency
:
elasticsearch_indices_flush_time_seconds
/
elasticsearch_indices_flush_total
将数据刷新到磁盘。此处该值增加,说可能可能出现磁盘慢的问题,此时无法写入index。可以通过降低translog flush设置中的
index.translog.flush_threshold_size
。
Merge Times
:添加、更新和删除操作都会被匹配flush到磁盘,作为新的segment,es会自动将这些小的segment merge为一个大的segment。如果merge的时间和次数增加通常会降低索引的吞吐量。此时可以考虑滚动索引或重新考虑分片策略。
elasticsearch_indices_merges_total_throttled_time_seconds_total
elasticsearch_indices_merges_total
elasticsearch_indices_merges_total_time_seconds_total
index Saturation
:
elasticsearch_indices_store_throttle_time_seconds_total
:elasticsearch index操作(input和output操作)被抑制的总时间
index rate
:
elasticsearch_indices_indexing_index_time_seconds_total
/
elasticsearch_indices_indexing_index_total
间。
参考
:
How to(官方)
下面给出了部分方法,完整方法参见
官方文档
。
提升indexing速度
- 发起index请求时尽量使用
buik
,将对多个索引的请求合并到一个请求中。
- elasticsearch默认每秒执行一次
refresh
,以便能够查找新增的数据。适当增加该值(
index.refresh_interval
)可以提升索引速度
- 增加文件系统的缓存,即增大内存
- 当检索一个document时,elasticsearch需要检查相同分片上是否存在相同id的document。如果采用自动生成id方式,则可以让elasticsearch跳过该步骤,加快检索速度
- 如果节点上需要执行大量检索,需要确保每个执行大量检索的分片的
indices.memory.index_buffer_size
不能小于512MB,elasticsearch将其作为所有active分配的共享缓冲。默认为10%的堆大小,假如JVM的10GB,则index buffer会分配到1GB,可以支持2个分片执行大量检索。
- 避免使用基于
脚本
的排序
- 使用完整的data进行查找
。在data字段中使用
now
时,通常无法进行缓存。
- force-merge只读的索引。注意不能force-merge可写的索引。
- 使用
index.store.preload
预加载热点索引文件,默认该值为空。通常不会设置预加载所有文件,一般设置为
["nvd", "dvd", "tim", "doc", "dim"]
,但使用该功能会增加主机内存使用量,在merge之后需要丢弃文件缓存,此时会导致检索和查找变慢。
不使用默认的
dynamic string mappings
。默认的dynamic string mappings会通过text和keyword来检索string字段,当只需要其中一个时会比较浪费。通常使用
id
字段作为
keyword
,使用
body
字段作为
text
。
禁用
_source
。
_source
字段保存了document的原始JSON体,如果不需要访问,则可以禁用。注意某些API需要使用
_source
才能正常运行,如update、highlight和reindex。
较大的分片在存储数据时更加有效,可以通过shrink API修改现有的索引。但较大的分片在恢复时也会花费较长时间。
TroubleShooting
Error: disk usage exceeded flood-stage watermark, index has read-only-allow-delete block
当一个节点达到高水位之后,elasticsearch会阻止写入索引,并转移高水位节点上的数据,直到低于
高水位
。此时建议增加磁盘容量。
可以通过提高高水位的值来临时解决该问题。
circuit breaker错误
elasticsearch使用
circuit breaker
来防止JVM发生
OutOfMemoryError
错误 ,默认当内存使用量达到95%时会触发circuit breaker。当出现该问题时,elasticsearch会返回
429
HTTP状态码。
{
'error': {
'type': 'circuit_breaking_exception',
'reason': '[parent] Data too large, data for [<http_request>] would be [123848638/118.1mb], which is larger than the limit of [123273216/117.5mb], real usage: [120182112/114.6mb], new bytes reserved: [3666526/3.4mb]',
'bytes_wanted': 123848638,
'bytes_limit': 123273216,
'durability': 'TRANSIENT'
},
'status': 429
}
使用如下方式查看节点的JVM使用情况:
GET _cat/nodes?v=true&h=name,node*,heap*
使用如下方式查看breaker的状态:
GET _nodes/stats/breaker
高CPU问题
elasticsearch使用
线程池
来管理并行操作的CPU资源,如果线程池枯竭,则elasticsearch会拒绝请求,并返回429状态码和
TOO_MANY_REQUESTS
错误,如当
search
线程池枯竭时,elasticsearch会拒绝查询请求。
使用如下方式查看各个节点的CPU使用情况:
GET _cat/nodes?v=true&s=cpu:desc
使用
cat thread pool API
查看各个节点上的请求处理情况:
GET /_cat/thread_pool?v=true&h=id,node_name,name,active,rejected,completed
长时间运行的查找会阻塞
search
线程池,使用如下方式查看当前运行的查询操作:
GET _tasks?actions=*search&detailed
使用如下方式查看当前运行的task的信息:
GET /_tasks?filter_path=nodes.*.tasks
description
字段包含查询请求和请求内容,
running_time_in_nanos
给出了请求运行的时间:
{
"nodes" : {
"oTUltX4IQMOUUVeiohTt8A" : {
"name" : "my-node",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1:9300",
"tasks" : {
"oTUltX4IQMOUUVeiohTt8A:464" : {
"node" : "oTUltX4IQMOUUVeiohTt8A",
"id" : 464,
"type" : "transport",
"action" : "indices:data/read/search",
"description" : "indices[my-index], search_type[QUERY_THEN_FETCH], source[{\"query\":...}]",
"start_time_in_millis" : 4081771730000,
"running_time_in_nanos" : 13991383,
"cancellable" : true
}
}
}
}
}
使用如下方式来取消请求操作:
POST _tasks/oTUltX4IQMOUUVeiohTt8A:464/_cancel
高JVM内存
使用如下方式查看各个节点的jvm内存压力:
GET _nodes/stats?filter_path=nodes.*.jvm.mem.pools.old
内存压力计算方式为:JVM Memory Pressure =
used_in_bytes
/
max_in_bytes
- 降低分片数目。大部分场景下,少量大分片使用的资源要少于大量小分片。参见
调整分片大小
集群状态为red或yellow
可能在节点维护的时候暂时禁用了分配功能,重新启用即可:
PUT _cluster/settings
{
"persistent" : {
"cluster.routing.allocation.enable" : null
}
}
在一个data节点离开集群之后,elasticsearch默认会
等待
index.unassigned.node_left.delayed_timeout
来延迟对副本分片的分片(主分片不收该配置影响)。如果在恢复一个节点时不需要等到延迟时间,可以使用如下命令触发分配流程:
POST _cluster/reroute?metric=none
如果因为磁盘问题导致分配失败,可以采用如下策略:
请求拒绝
造成请求拒绝的原因通常为:
使用如下命令检查每个线程池的请求访问情况,如果
search
和
write
线程池中出现了过多的
rejected
,说明elasticsearch正在有规律地拒绝请求:
GET /_cat/thread_pool?v=true&h=id,name,active,rejected,completed
查看CPU和内存以及circuit breaker,针对性地解决问题。
Task 队列积压
task 队列积压可能会导致请求拒绝。
首先查看队列状态,查看节点上被拒绝的task比较多:
GET /_cat/thread_pool?v&s=t,n&h=type,name,node_name,active,queue,rejected,completed
查看节点上的热点线程:
GET /_nodes/hot_threads
GET /_nodes/<node_id>/hot_threads
长时间运行的task会占用资源,可以使用如下命令查看,取消长时间运行的task:
GET /_tasks?filter_path=nodes.*.tasks
POST _tasks/oTUltX4IQMOUUVeiohTt8A:464/_cancel
定位异常消息
elasticsearch会校验从磁盘上读取的数据是否和写入的数据相同,如果不同,则会报异常,如:
org.apache.lucene.index.CorruptIndexException
org.elasticsearch.gateway.CorruptStateException
org.elasticsearch.index.translog.TranslogCorruptedException
具体参见源文档。
discover异常
没有选举master
当一个node选举为master之后,其日志中会包含
elected-as-master
且所有节点的日志中会包含
master node changed
。如果没有选举出master节点,所有节点的日志中会包含
org.elasticsearch.cluster.coordination.ClusterFormationFailureHelper
,默认10s输出一次。
master选举只会涉及master-eligible节点, 因此这种情况下需要关注这类节点的日志。
elasticsearch依赖仲裁机制来选举出master,如果集群中无法选举出master,通常原因是
缺少足够的节点
来形成仲裁。如果无法启动足够的节点来形成仲裁,则可以创建一个新的集群,并从最近的snapshot中恢复数据。
节点无法发现或加入稳定的master
如果集群中有一个稳定的master,但节点无法发现或加入其所在的集群,则日志中会包含
ClusterFormationFailureHelper
,观察日志信息来进一步定位问题。
节点加入和离开集群时,master 的日志中会分别打印
NodeJoinExecutor
和
NodeLeftExecutor
。
disconnect
elasticsearch依赖稳定的网络,它会在节点之间创建大量TCP连接。其中master到其他节点的连接尤为重要,master不会主动断开到其他节点的连接,类似地,在连接建立之后,节点也不会主动断开其入站连接(除非节点关闭)。
通过如下配置可以获取更详细的网络信息:
logger.org.elasticsearch.transport.TcpTransport: DEBUG
logger.org.elasticsearch.xpack.core.security.transport.netty4.SecurityNetty4Transport: DEBUG
lagging
elasticsearch需要每个节点都能够快速apply集群状态。master会移除掉存在lagging的节点(默认2分钟无法apply集群状态)。
使用如下配置可以获取更详细的信息
logger.org.elasticsearch.cluster.coordination.LagDetector: DEBUG
follower check retry count exceeded
出现这种问题说明follower响应慢,导致follower响应慢的原因有很多,如:
- GC时间过长
- VM暂停
- 中间设备导致延迟或丢包等
可以使用jstack导出线程的profile信息,也可以使用如下接口查看热点线程,支持
type
参数,可选
block
,
cpu
和
wait
,默认是
cpu
:
GET /_nodes/hot_threads
GET /_nodes/<node_id>/hot_threads
ShardLockObtainFailedException异常
如果一个节点离开并重新加入集群后,elasticsearch通常会停止然后重新初始化其分片。如果无法快速停止分片,则elasticsearch可能会因为
ShardLockObtainFailedException
而无法重新初始化分片。,当启用如下配置时,elasticsearch会在遇到
ShardLockObtainFailedException
时尝试运行
节点 hot threads
API:
logger.org.elasticsearch.env.NodeEnvironment: DEBUG
输出结果会被压缩编码和分块,可以使用如下方式查看:
cat shardlock.log | sed -e 's/.*://' | base64 --decode | gzip --decompress
查询异常
确保data stream或索引包含数据
GET /my-index-000001/_count
查看索引的字段
GET /my-index-000001/_field_caps?fields=*
查看最新的数据
GET my-index-000001/_search?sort=@timestamp:desc&size=1
校验和explain查询
当查询返回非预期的结果时,可以使用如下方式定位:
使用
validate API
来校验请求:
GET /my-index-000001/_validate/query?rewrite=true
{
"query": {
"match": {
"user.id": {
"query": "kimchy",
"fuzziness": "auto"
}
}
}
}
使用
explain API
来找出为什么某些文档无法匹配查询:
GET /my-index-000001/_explain/0
{
"query" : {
"match" : { "message" : "elasticsearch" }
}
}
查看索引配置
GET /my-index-000001/_settings
查找慢查询
Slow logs
可以帮助定位执行的慢查询,
audit logging
可以帮助确定查询源。在
elasticsearch.yml
中配置如下参数来追踪查询,主义在Troubleshotting之后关闭该功能:
xpack.security.audit.enabled: true
xpack.security.audit.logfile.events.include: _all
xpack.security.audit.logfile.events.emit_request_body: true
How To(自总结)
停止所有的master节点会怎样?
master节点用于
变更集群状态
,因此如果集群中没有master节点,将无法变更
集群状态
。集群状态
元数据
包括:节点、索引、分片、分片分配、索引的mappings&setting等。
elasticsearch的每个节点的数据目录都保存了集群状态信息(master节点的
path.data
中保存了最新的集群状态信息),且会在内存中维护集群状态。因此如果集群中没有master节点,仍然能进行不会影响集群状态的操作,如从index中读取document,但不能执行索引操作。
如何停止数据节点
使用如下方式排除掉不需要的数据节点,此时系统会停止在该节点上分配分片,并将该节点的分片转移到其他节点,分片迁移过程中,集群状态是
green
。待分片转移完成之后,就可以停止该节点。
curl -XPUT "http://localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"persistent" : {
"cluster.routing.allocation.exclude._ip" : "1.1.1.1"
}
}'
如何查看集群的master节点?
使用如下命令查看,带
*
号的就是当前的master节点:
# curl localhost:9200/_cat/nodes?v&h=id,ip,port,v,m
id ip port version m
pLSN 192.168.56.30 9300 2.2.0 m
k0zy 192.168.56.10 9300 2.2.0 m
6Tyi 192.168.56.20 9300 2.2.0 *
如果无法通过
POST
或
PUT
修改集群状态
,说明master节点出现了问题,可以通过查看master的server日志来查看问题原因,也可以通过重启当前master节点来触发master选举,以此尝试解决问题。
如何查看节点上生效的配置
有时候需要确认elasticsearch.yml中的配置是否生效,可以使用
node info API
查看:
GET /_nodes
GET /_nodes/_all/
GET /_nodes/<node_id>/_all/
如何查看参与选举投票的节点
GET /_cluster/state?filter_path=metadata.cluster_coordination.last_committed_config
索引按大小排序
GET /_cat/indices/?pretty&s=store.size:desc
分片按大小排序
curl -X GET "localhost:9200/_cat/shards?v&s=store"
一般解决思路
elasticsearch集群状态与分片的分配息息相关,首先确保所有节点版本一直,并使用
GET /_cluster/settings
来检查集群是否启用了分片分配功能,如果没有则启用该功能:
PUT _cluster/settings
{
"transient" : {
"cluster.routing.allocation.enable": true
}
}
首先查看集群状态
curl localhost:9200/_cluster/health
查看集群中节点分片分配状态
curl localhost:9200/_cat/allocation?v=true
如果发现有unassigned的分片,可以通过
GET _cat/shards?h=index,shard,prirep,state,node,unassigned.reason
找出unassigned的分片,同时借助
GET _cluster/allocation/explain
可以查看更细节的内容。
大部分命令都很卡
有可能是某台数据节点CPU过高导致的,首先通过下面两个命令分别找出CPU过高的节点和热点线程
curl -XGET 'http://localhost:9200/_cat/nodes?v=true&s=cpu:desc'
curl -XGET 'http://localhost:9200/_nodes/hot_threads'
然后再通过如下命令查看是哪个查询类型的task占用率过高:
curl -XGET 'http://localhost:9200/_tasks?actions=*search&detailed'
使用如下命令可以取消一个task:
POST _tasks/oTUltX4IQMOUUVeiohTt8A:464/_cancel
执行PUT或POST命令卡住,但GET没有问题
只能通过master节点执行修改集群状态的PUT或POST命令,如果此类命令卡主,说明master节点可能出现了问题,首先通过
curl -XGET http://localhost:9200/_cat/nodes
命令找到master节点,然后查看节点的CPU、内存、thread_pool和tasks。
也可以通过重启master节点的方法让master角色漂移到其他master eligible节点。
无法删除或迁移系统索引
像
.geoip_databases
这样的系统索引在主分片状态为
unassigned
时是无法通过
Delete /my-index
,接口直接删除的,可以通过停用然后启用相应功能的方式来让系统重新分配索引
PUT _cluster/settings
{
"persistent": {
"ingest.geoip.downloader.enabled": false
}
}
PUT _cluster/settings
{
"persistent": {
"ingest.geoip.downloader.enabled": true
}
}
如何删除特殊符号的索引
使用url编码。假如一个索引名称为
<my-index-{now/d}-000001>
,可以将其转化为
%3Cmy-index-%7Bnow%2Fd%7D-000001%3E
Data stream
如何删除所有unsigned的shards(非data-stream)?
获取unsigned的shards(注意下面结果中也会包含data-stream的shards):
curl -XGET 'http://localhost:9200/_cat/shards?h=index,shards,state,prirep,unassigned.reason' | grep UNASSIGNED
删除unsigned的shards:
curl -XGET http://localhost:9200/_cat/shards | grep UNASSIGNED | awk {'print $1'} | xargs -i curl -XDELETE "http://localhost:9200/{}"
修改索引副本数,适用于分片数目大于节点数目的场景:
PUT /my-index/_settings
{
"index" : {
"number_of_replicas" : 0
}
}
如何删除data-stream中unsigned的索引?
当一个索引为data-stream中的write index时是不能被删除的,需要通过rollover来创建新的write index,然后就可以删除老的索引:
POST my-data-stream/_rollover
DELETE /my-index
修改datastream的Lifecycle policy
lifecycle的rollover只对新数据(write index)有效,对老的索引无效。修改datastream的Lifecycle policy时,首先需要在
Index Management
-->
index template
中修改index patterns和index lifecycle的对应关系,注意需要在
Logistics
步骤中打开
Create data stream
选项并修改
Priority
。此外还需要修改data stream中的write index的lifecycle policy,只需删除现有的lifecycle并添加新的lifecycle即可(lifecycle policy是有版本号的,因此在修改lifecycle policy之后,需要重新apply到index中)。
如何修改(删除或更新)现有data stream的mapping字段
每个data stream都有一个template,该template中的mappings和index settings会应用到data stream的后端索引上。下面介绍如何修改一个data stream的mappings或settings。
直接修改保留字段
在elasticsearch中除一些
保留mapping字段
支持直接修改外,不能对其他字段直接进行修改。下面例子中将
ignore_malformed
修改为true:
PUT /_index_template/my-data-stream-template
{
"index_patterns": [ "my-data-stream*" ],
"data_stream": { },
"priority": 500,
"template": {
"mappings": {
"properties": {
"host": {
"properties": {
"ip": {
"type": "ip",
"ignore_malformed": true
}
}
}
}
}
}
}
然后使用
update mapping API
应用到特定的data stream上。使用
write_index_only=true
参数可以将修改仅应用到write index上:
PUT /my-data-stream/_mapping
{
"properties": {
"host": {
"properties": {
"ip": {
"type": "ip",
"ignore_malformed": true
}
}
}
}
}
更多参见
官方文档
使用reindex修改
使用resolve API检查集群中是否存已存在选择的data stream名称,如果存在则重新选择一个名称:
GET /_resolve/index/new-data-stream*
创建或更新index template,如果只是在现有的template中添加或修改很少的字段,建议创建新的template:
PUT /_index_template/new-data-stream-template
{
"index_patterns": [ "new-data-stream*" ],
"data_stream": { },
"priority": 500,
"template": {
"mappings": {
"properties": {
"@timestamp": {
"type": "date_nanos" //修改timestamp字段类型
}
}
},
"settings": {
"sort.field": [ "@timestamp"], //添加sort.field 设置
"sort.order": [ "desc"] //添加sort.order 设置
}
}
}
创建新的data stream(不要使用自动创建方式)
PUT /_data_stream/new-data-stream
获取老data stream 的后端索引信息
GET /_data_stream/my-data-stream
使用reindex API将老data stream 的索引拷贝到新的data stream中:
POST /_reindex
{
"conflicts": "proceed",
"source": {
"index": [".ds-my-data-stream-2099.03.07-000001", ".ds-my-data-stream-2099.03.07-000002"]
},
"dest": {
"index": "new-data-stream",
"op_type": "create"
}
}
使用
"conflicts": "proceed"
来防止因为数据类型无法转换导致
reindex
中断。开启debug日志:
PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":"DEBUG"
}
}
修复完之后记得恢复配置:
PUT /_cluster/settings
{
"transient": {
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":NULL
}
}
也可以将特定时间范围的数据拷贝到新的data stream中:
POST /_reindex
{
"source": {
"index": "my-data-stream",
"query": {
"range": {
"@timestamp": {
"gte": "now-7d/d",
"lte": "now/d"
}
}
}
},
"dest": {
"index": "new-data-stream",
"op_type": "create"
}
}
可以使用如下方式查看reindex的进度
curl -XGET http://localhost:9200/_tasks?actions=*reindex&wait_for_completion=false?detailed
删除老的data stream
DELETE /_data_stream/my-data-stream
这种
方式
也需要同时修改上游数据写入端(如logstash)指定的data-stream名称,来让新的数据写入到新的data stream中。可以先reindex非write index的数据,然后让上游系统写入新的data stream,然后将老data stream的write index的数据reindex 到新的data stream,防止因中断而丢失数据。
另外一种防止数据丢失的方式是使用
aliases
来管理data stream
reindex可能会遇到几种问题:
过程如下:
- 创建目标索引
- 更新目标索引配置(
refresh_interval = -1
和
number_of_replicas = 0
)
_reindex
类型为
external
- 将别名从原始索引切换到目标索引
- 使用
external
类型重新执行
_reindex
- 更新目标索引配置(
refresh_interval = null
和
number_of_replicas = null
)
如何在重启data节点时避免大量分片分配
一种方式是通过禁用副本分片分配来降低IO(注意在节点启动之后恢复该配置)
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "primaries"
}
}
PUT _cluster/settings
{
"persistent" : {
"cluster.routing.allocation.enable" : "all"
}
}
另一种可以通过增加
index.unassigned.node_left.delayed_timeout
(默认1分钟)来防止分片分配,
<INDEX_NAME>
为
all
表示应用到集群中的所有索引:
PUT _all/_settings
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "5m"
}
}
在节点重启之后使用如下方式查看节点(含master重启)状态:
GET _cat/health
GET _cat/nodes
上述重启方式实际上要求暂停数据生产端,并执行
POST /_flush
来刷新数据。为避免数据丢失,安全的方式如下:
将需要重启的节点上的shards转移到其他节点:
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.exclude._name": "<node_id>"
}
}
调用如下命令查看节点的shards数目以及unassigned的shards数目:
GET _cat/allocation/<node_id>
在节点重启之后,恢复设置,elasticsearch会在节点之间重新均衡shards:
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.exclude._name": ""
}
}
如果主分片变为unassigned,且确定不再需要原始主分片的数据,如何迁移主分片
curl -XPOST "localhost:9200/_cluster/reroute?pretty" -H 'Content-Type: application/json' -d'
{
"commands" : [
{
"allocate_empty_primary" : {
"index" : "constant-updates",
"shard" : 0,
"node" : "<NODE_NAME>",
"accept_data_loss" : "true"
}
}
]
}
'
解决使用
wildcard
方式查询不到数据的问题
当检索document时,elasticsearch会将字符串
转换为小写
再进行分割,因此如果
value
中包含大写字母且没有忽略大小写的话,会导致无法查询预期的数据。参见:
elasticsearch wild card query not working
{
"query": {
"wildcard": {
"ActId": {
"value": "integrationTestId_panda_2023*",
"boost": 1,
"rewrite": "constant_score",
"case_insensitive": true
}
}
}
}
kibana
如何修复因索引修改而失效的kibana dashboard
使用
Export objects API
导出配置,在修改之后通过
import objects API
更新配置即可。
exporter API在导出配置时,需要指定配置的类型,支持的类型为
visualization
、
dashboard
、
search
、
index-pattern
、
config
、
lens
。如下分别导出
dashboard
、
index-pattern
和
lens
的配置。
curl -X POST localhost:5601/api/saved_objects/_export -H 'kbn-xsrf: true' -H 'Content-Type: application/json' -d '
{
"objects": [
{
"type": "dashboard",
"id": "b7b04e30-4f7b-11ed-be4b-43f0b3e8e524"
}
]
}'
curl -X POST localhost:5601/api/saved_objects/_export -H 'kbn-xsrf: true' -H 'Content-Type: application/json' -d '
{
"type": "index-pattern"
}'
curl -X POST localhost:5601/api/saved_objects/_export -H 'kbn-xsrf: true' -H 'Content-Type: application/json' -d '
{
"type": "lens"
}'
在修改完对应的配置之后,可以将其保存在
file.ndjson
中,使用如下命令加载更新即可。除使用
overwrite
之外,还支持
createNewCopies
,用于生成一份要保存的对象的拷贝,重新生成每个对象ID,并重置原来的对象,这种方式可以防止配置冲突。
curl -X POST localhost:5601/api/saved_objects/_import?overwrite=true -H "kbn-xsrf: true" --form file=@file.ndjson
如何使用snapshot只备份kibana dashboard
kibana dashboard等信息保存在以
.kibana
开头的索引中,属于系统索引,使用如下配置可以只备份kibana信息。
"indices": "-*"
可以排除非系统index或系统data-stream以外的index和data-stream
"indices": "-*",
"include_global_state": true,
"feature_states": [
"kibana"
]
es分片数目限制
有两个参数可以限制es的分片数目:
cluster.routing.allocation.total_shards_per_node
和
cluster.max_shards_per_node
,
区别
如下:
cluster.routing.allocation.total_shards_per_node
:限制了单个节点上可以分片的分片上限。默认不限制。
cluster.max_shards_per_node
:限制了集群中分片的总数(集群中分片上限为:
number_of_data_nodes
*
cluster.max_shards_per_node
),并不关心单个节点上的分片数。默认1000。
如何定位kibana无数据的问题
fluentbit-->kafka-->logstash-->elasticsearch-->kibana架构下,发现kibana上面看不到日志,且es没有创建data stream/index,此时说明es没有接收到kibana的数据:
首先查看logstash的grafana,看下进来的event和出去的event是否正常,以此判断问题是出现在上游还是下游
然后在logstash上查看是否有无法在es上创建index的错误,如:
this action would add [6] shards, but this cluster currently has [2996]/[3000] maximum normal shards open;"}}}}
说明es集群的shards数目已经达到上限,es
允许
的shards数目为:
cluster.max_shards_per_node * number of non-frozen data nodes
,默认情况下,每个 non-frozen的data节点的shards数目为1000,如果有3个节点,es集群中允许的shards数目为3000。查看data节点的磁盘使用量,如果不大的话,可以适当提高每个节点允许的shards数目:
PUT /_cluster/settings
{
"persistent" : {
"cluster.max_shards_per_node" : "1500"
}
}
如果还没有日志,可以查看fluentbit是否运行正常
TIPS
elasticsearch的性能主要跟磁盘有关系
elasticsearch的mapping有两种:
Dynamic mapping
和
Explicit mapping
,第一种由系统自动发现字段并添加到mapping中,第二种是手动设置的,可以通过
GET <my-index>/_mapping
查看mapping(含自动和手动)。如果document字段发生变化(如类型变化),可能会导致mapping冲突。
elasticsearch.yml
中
xpack.ml.enabled
和
xpack.security.http.ssl.enabled
是两个单独的配置,后者不依赖前者。
使用curl时需要加引号,否则返值可能会导致参数失效:curl -XGET "
http://localhost:9200/_cat/indices?v&health=yellow
"
如果一次性移除的节点超过voting configuration的一半会导致集群无法正常运作,此时只需要重新启动被移除的节点即可。
voting configuration中的master eligible节点可以在master丢失之后成为新的master
查看索引配置
GET /my-index/_settings
elasticsearch的
日志配置
elasticsearch的索引操作默认基于document ID,可以自定义
routing
,但不建议这么做,可能会导致分片不均衡。
elasticsearch不会将副本分片分配到和主分片相同的节点
elasticsearch集群状态的含义:
- 红色:至少一个主分片为unassigned;
- 黄色:至少一个副本分片为unassigned;
- 绿色:全部主&副本都分配成功。
ECK
logstash目前处于alpha阶段,暂不采纳。
兼容性
ECK某些特性,如LDAP等需要付费才能使用。
在更新Elasticsearch配置之后,需要观察Elasticsearch资源是否正确应用配置。如果状态阈值卡在
ApplyingChanges
,可能是因为集群状态不正常,导致无法继续更新或调度等原因导致pod启动失败。
$ kubectl get es
NAME HEALTH NODES VERSION PHASE AGE
elasticsearch-sample yellow 2 7.9.2 ApplyingChanges 36m
卸载ECK
删除命名空间内容
kubectl get namespaces --no-headers -o custom-columns=:metadata.name \
| xargs -n1 kubectl delete elastic --all -n
清空CRD定义:
kubectl delete -f https://download.elastic.co/downloads/eck/2.10.0/operator.yaml
kubectl delete -f https://download.elastic.co/downloads/eck/2.10.0/crds.yaml
管理kubernetes services
可以在
http.service.spec.type
中指定暴露的服务:
apiVersion: <kind>.k8s.elastic.co/v1
kind: <Kind>
metadata:
name: hulk
spec:
version: 8.11.1
http:
service:
spec:
type: LoadBalancer
默认下,operator会为每个资源管理一个自签证书和自定义CA。
> kubectl get secret | grep es-http
hulk-es-http-ca-internal Opaque 2 28m
hulk-es-http-certs-internal Opaque 2 28m
hulk-es-http-certs-public Opaque 1 28m
使用如下方式创建自定义证书:
ca.crt
: CA 证书 (可选,当
tls.crt
由知名 CA颁发时).
tls.crt
: 证书.
tls.key
: 证书中的第一个证书的私钥.
kubectl create secret generic my-cert --from-file=ca.crt --from-file=tls.crt --from-file=tls.key
在http中引用自定义的证书
spec:
http:
tls:
certificate:
secretName: my-cert
可以使用如下方式取消Kibana、APM Server、 Enterprise Search和Elasticsearch的HTTP TLS:
spec:
http:
tls:
selfSignedCertificate:
disabled: true
连接Elasticsearch后端
在kubernetes内部:
NAME=elasticsearch
kubectl get secret "$NAME-es-http-certs-public" -o go-template='{{index .data "tls.crt" | base64decode }}' > tls.crt
PW=$(kubectl get secret "$NAME-es-elastic-user" -o go-template='{{.data.elastic | base64decode }}')
curl --cacert tls.crt -u elastic:$PW https://$NAME-es-http:9200/
在kubernetes外部:
NAME=elasticsearch
kubectl get secret "$NAME-es-http-certs-public" -o go-template='{{index .data "tls.crt" | base64decode }}' > tls.crt
IP=$(kubectl get svc "$NAME-es-http" -o jsonpath='{.status.loadBalancer.ingress[].ip}')
PW=$(kubectl get secret "$NAME-es-elastic-user" -o go-template='{{.data.elastic | base64decode }}')
curl --cacert tls.crt -u elastic:$PW https://$IP:9200/
通过
podTemplate
配置pod属性:
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: quickstart
spec:
version: 8.11.1
nodeSets:
- name: default
count: 1
podTemplate:
metadata:
labels:
my.custom.domain/label: "label-value"
annotations:
my.custom.domain/annotation: "annotation-value"
spec:
containers:
- name: elasticsearch
env:
- name: ES_JAVA_OPTS
value: "-Xms4g -Xmx4g"
ECK默认会安装一个ValidatingWebhookConfiguration:
- 在创建和更新时验证所有的Elastic自定义资源 (Elasticsearch, Kibana, APM Server, Enterprise Search, Beats, Elastic Agent, Elastic Maps Server 和 Logstash)
- operator本身也是一个webhook服务,通过elastic-system命名空间的
elastic-webhook-server
service暴露
- operator会为webhook生成一个名为
elastic-webhook-server-cert
的secret,operator负责该证书的滚动跟新
Elasticsearch
elasticsearch资源有多个配置字段。
ECK会自动管理如下字段,且不支持自定义配置如下字段:
cluster.name
discovery.seed_hosts
discovery.seed_providers
discovery.zen.minimum_master_nodes [7.0]Deprecated in 7.0.
cluster.initial_master_nodes [7.0]Added in 7.0.
network.host
network.publish_host
path.data
path.logs
xpack.security.authc.reserved_realm.enabled
xpack.security.enabled
xpack.security.http.ssl.certificate
xpack.security.http.ssl.enabled
xpack.security.http.ssl.key
xpack.security.transport.ssl.enabled
xpack.security.transport.ssl.verification_mode
elasticsearch生成的默认
elasticsearch.yml
默认配置如下:
azure:
client:
default:
endpoint_suffix: core.chinacloudapi.cn
cluster:
name: quickstart
routing:
allocation:
awareness:
attributes: k8s_node_name
discovery:
seed_hosts: []
seed_providers: file
http:
publish_host: ${POD_NAME}.${HEADLESS_SERVICE_NAME}.${NAMESPACE}.svc
network:
host: "0"
publish_host: ${POD_IP}
node:
attr:
k8s_node_name: ${NODE_NAME}
name: ${POD_NAME}
path:
data: /usr/share/elasticsearch/data
logs: /usr/share/elasticsearch/logs
xpack:
license:
upload:
types:
- trial
- enterprise
security:
authc:
realms:
file:
file1:
order: -100
native:
native1:
order: -99
reserved_realm:
enabled: "false"
enabled: "true"
http:
ssl:
certificate: /usr/share/elasticsearch/config/http-certs/tls.crt
certificate_authorities: /usr/share/elasticsearch/config/http-certs/ca.crt
enabled: true
key: /usr/share/elasticsearch/config/http-certs/tls.key
transport:
ssl:
certificate: /usr/share/elasticsearch/config/node-transport-cert/transport.tls.crt
certificate_authorities:
- /usr/share/elasticsearch/config/transport-certs/ca.crt
- /usr/share/elasticsearch/config/transport-remote-certs/ca.crt
enabled: "true"
key: /usr/share/elasticsearch/config/node-transport-cert/transport.tls.key
verification_mode: certificate
用于设置elasticsearch集群的拓扑。每个nodeSets表示一组共享相同配置的elasticsearch nodes。可以在nodeSet中定义
elasticsearch.yml
配置文件。
下面设置了master节点和data节点
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: quickstart
spec:
version: 8.11.1
nodeSets:
- name: master-nodes
count: 3
config:
node.roles: ["master"]
volumeClaimTemplates:
- metadata:
name: elasticsearch-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: standard
- name: data-nodes
count: 10
config:
node.roles: ["data"]
volumeClaimTemplates:
- metadata:
name: elasticsearch-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1000Gi
storageClassName: standard
更新集群配置
ECK可以平滑地升级集群,只需要apply新的elasticsearch配置即可。例如修改节点数目、内存限制、节点roles、elasticsearch版本等。
ECK可以保证:
在一个节点移除前,其数据会被迁移到其他节点
当一个集群拓扑变更新后,ECK会自动调整如下elasticsearch配置:
discovery.seed_hosts
cluster.initial_master_nodes
discovery.zen.minimum_master_nodes
_cluster/voting_config_exclusions
在可能的情况下,滚动升级可以安全地复用已有的PersistentVolumes
滚动升级的高级配置
Statefulset
ECK会将每个NodeSet转化为一个statefulset。
StatefulSet的名称来自 Elasticsearch 资源名称和 NodeSet 名称。使用 StatefulSet 名称加上pod序号后缀来生成一个pod名称。Elasticsearch 节点的名称与它们所运行的 Pod 相同。
当一个pod重建时,statefulset controller会确保PVC附加到新的pod上。
集群升级模式
新增一个NodeSet
ECK会创建出对应的Statefulset,并创建出TLS证书和elasticsearch配置文件对应的secret和configmap
增加已有NodeSet的节点数
ECK会增加对应Statefulset的副本数
降低已有NodeSet的节点数
ECK会首先迁移该节点数据,然后再降低对应Statefulset的副本数,与该节点对应的PVC也会被自动移除
移除已有的NodeSet
ECK会迁移该NodeSet的数据,然后移除底层Statefulset
更新已有的NodeSet,例如更新elasticsearch配置或PodTemplate字段
ECK会对对应的elasticsearch节点执行滚动更新,并在更新时保证Elasticsearch集群的可用性。大部分情况下会逐个重启elasticsearch节点。
重命名已有的NodeSet
ECK会创建一个新名称的NodeSet,并将数据从旧的NodeSet转移过来,然后删除旧的NodeSet。
滚动升级可以确保升级过程中Elasticsearch集群的状态是green,但如果索引只有一个副本,则可以在集群状态为yellow的情况下执行滚动更新。
如下情况中,会忽略集群健康状态:
- 如果一个NodeSet的所有elasticsearch节点都是unavailable(可能是因为配置错误导致),此时operator会忽略集群健康并更新该NodeSet的节点
- 如果待更新的elasticsearch节点不健康,且不是elasticsearch集群的一部分,此时operator会忽略集群健康并更新该节点
注意,减少节点数据需要人工干预,此时可能会出现副本数大于节点数的情况,可以通过
index settings
来调整索引的副本数,或使用
auto_expand_replicas
来自适应集群的数据节点数。
可以使用affinity、topologySpreadConstraints等方式指定pod调度方式。
Volume claim templates
注意volume claim必须为
elasticsearch-data
,与
data.path
有关,默认为
/usr/share/elasticsearch/data
:
spec:
nodeSets:
- name: default
count: 3
volumeClaimTemplates:
- metadata:
name: elasticsearch-data # Do not change this name unless you set up a volume mount for the data path.
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: standard
Volume claim的删除
可以通过
volumeClaimDeletePolicy
字段配置删除elasticsearch集群时ECK的动作。可选值为
DeleteOnScaledownAndClusterDeletion
和
DeleteOnScaledownOnly
,默认为
DeleteOnScaledownAndClusterDeletion
,即在删除elasticsearch集群时,同时也会删除PVC。而
DeleteOnScaledownOnly
则会在删除elasticsearch集群的时候保留PVC。如果使用相同的名称和node sets配置重新创建了被删除的集群,则新集群会采用已有的PVC(但无法使用原来的数据):
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: es
spec:
version: 8.11.1
volumeClaimDeletePolicy: DeleteOnScaledownOnly
nodeSets:
- name: default
count: 3
Storageclass的
volumeBindingMode
必须
是
WaitForFirstConsumer
。建议将
reclaimPolicy
设置为
Delete
,表示在PVC删除的时候删除掉PV。ECK会在集群缩容或删除的时候自动清理PVC,但不会清理PV。鉴于不同集群无法使用相同的数据,因此建议将
reclaimPolicy
设置为
Delete
更新Volume claim配置
如果Storageclass支持
卷扩容
,则可以在volumeClaimTemplates中增加Storage request大小,ECK会更新对应的PVC,并重新创建Statefulset。如果volume 驱动支持
ExpandInUsePersistentVolumes
,则可以在线修改文件系统,无需重启Elasticsearch进程。
除此之后不能修改volumeClaimTemplates。如果必须要修改volumeClaimTemplates,则可以使用不同的配置创建一个新的nodeSet,然后移除已有的nodeSet。
transport必须使用https
用于设置
内部节点
之间以及和外部集群之间的通信。在
spec.transport.service
字段中可以修改暴露transport模块的Service:
spec:
transport:
service:
metadata:
labels:
my-custom: label
spec:
type: LoadBalancer
ECK默认会使用自签CA为集群中的
每个节点颁发一个证书
,可以通过如下方式在生成的证书中添加额外的IP地址或DNS名称:
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: quickstart
spec:
version: 8.11.1
transport:
tls:
subjectAltNames:
- ip: 1.2.3.4
- dns: hulk.example.com
nodeSets:
- name: default
count: 3
使用自签CA
CA证书必须保存在secret的
ca.crt
字段中,key必须保存在
ca.key
中:
spec:
transport:
tls:
certificate:
secretName: custom-ca
支持通过手动、initcontainer或daemonset的方式设置vm内核参数,推荐使用initcontainer方式。下面是initcontainer方式:
cat <<EOF | kubectl apply -f -
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: quickstart
spec:
version: 8.11.1
nodeSets:
- name: default
count: 3
podTemplate:
spec:
initContainers:
- name: sysctl
securityContext:
privileged: true
runAsUser: 0
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
EOF
Secure settings
可以使用kubernetes的secrets来管理
secure settings
(如
Azure repository plugin
),这些secret都必须是key-value组合。ECK会在elasticsearch启动前将其注入到每个elasticsearch节点的keystore中。ECK operator会持续watch secrets,并在其变更时更新elasticsearch keystore。
spec:
secureSettings:
- secretName: one-secure-settings-secret
- secretName: two-secure-settings-secret
自定义配置文件和插件管理
可以使用
自定义容器镜像
或init container的方式来安装插件和配置文件
spec:
nodeSets:
- name: default
count: 3
podTemplate:
spec:
initContainers:
- name: install-plugins
command:
- sh
- -c
- |
bin/elasticsearch-plugin install --batch repository-azure
更新策略
可以使用与deployment相同的策略来更新elasticsearch pod。maxSurge表示可以额外创建的新pod数目,maxUnavailable表示unavailable的pod数目。
spec:
updateStrategy:
changeBudget:
maxSurge: 3
maxUnavailable: 1
默认行为如下,即会立即创建新的pods,且unavailable的pod数目不能超过1:
spec:
updateStrategy:r
changeBudget:e
maxSurge: -1 #负值表示不作限制
maxUnavailable: 1
Pod disruption budget
elasticsearch可以指定PDB,保证在rescheduled情况下服务的稳定性:
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: quickstart
spec:
version: 8.11.1
nodeSets:
- name: default
count: 3
podDisruptionBudget:
spec:
minAvailable: 2
selector:
matchLabels:
elasticsearch.k8s.elastic.co/cluster-name: quickstart
Readiness probe
通过
READINESS_PROBE_TIMEOUT
来修改readiness probe的超时时间,默认3s,下面设置为10s。
spec:
version: 8.11.1
nodeSets:
- name: default
count: 1
podTemplate:
spec:
containers:
- name: elasticsearch
readinessProbe:
exec:
command:
- bash
- -c
- /mnt/elastic-internal/scripts/readiness-probe-script.sh
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 12
successThreshold: 1
timeoutSeconds: 12
env:
- name: READINESS_PROBE_TIMEOUT
value: "10"
Pod PreStop hook
使用
PRE_STOP_ADDITIONAL_WAIT_SECONDS
可以设置preStop hook,防止出现Elasticsearch
连接错误
(kube-proxy识别pod的默认间隔为30s)。默认值为50:
spec:
version: 8.11.1
nodeSets:
- name: default
count: 1
podTemplate:
spec:
containers:
- name: elasticsearch
env:
- name: PRE_STOP_ADDITIONAL_WAIT_SECONDS
value: "5"
Security Context
elasticseaarch 8.8.0版本中,默认的security context如下:
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
privileged: false
readOnlyRootFilesystem: true
当创建elasticsearch资源时,会默认创建一个
elastic
用户,并赋予
superuser
角色。也可以
自定义role
。
ECK需要
付费
才能使用LDAP,目前只能使用简单的基于文件的用户名认证方式。
设置计算资源
从elasticsearch 7.11开始,会根据节点的roles和可用内存(
resources.limits.memory
)来自动计算JVM的堆大小:
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: quickstart
spec:
version: 8.11.1
nodeSets:
- name: default
count: 1
podTemplate:
spec:
containers:
- name: elasticsearch
resources:
requests:
memory: 4Gi
cpu: 8
limits:
memory: 4Gi
各个组件的
默认配置
。
Kibana
连接Elasticsearch
当kibana和Elasticsearch在同一个ECK集群中时,ECK会将所需的Secret从Elasticsearch所在的命名空间拷贝到kibana所在的命名空间,因此这种情况下,kibana无需单独配置和Elasticsearch的用户名密码。
但如果连接到集群外部的Elasticsearch,则需要单独
指定
连接信息。
在
spec.config
中可以添加Kibana配置。
apiVersion: kibana.k8s.elastic.co/v1
kind: Kibana
metadata:
name: kibana-sample
spec:
version: 8.11.1
count: 1
elasticsearchRef:
name: "elasticsearch-sample"
config:
elasticsearch.requestHeadersWhitelist:
- authorization
Http配置
HTTP配置和Elasticsearch[类似](#Http TLS 证书)
benchmark
rally
Tips
如何查看elasticsearch集群的状态?
通过
kubectl get elasticsearch
命令可以直接查看集群的状态(
HEALTH
)和当前阶段(
ApplyingChanges
,表示正在更改配置,如果是
Ready
,表示集群正常)
NAME HEALTH NODES VERSION PHASE AGE
elasticsearch green 7 8.11.1 ApplyingChanges 8d
Volume扩容对集群的影响?
如果storageclass支持卷扩容(即sc中包含
allowVolumeExpansion: true
),则ECK会更新对应的PVC,并重新创建Statefulset。如果卷驱动支持
ExpandInUsePersistentVolumes
,则文件系统会在线变更大小,无需重启Elasticsearch进程。
除此之外不支持在volumeClaimTemplates中的其他变更操作,如变更storageclass或减少卷大小。
如果kibana的对外域名没有配置tls,则Dev Tools中的
copy as cCurl
是
灰色
的
配置logstash和kibana的权限?
elasticsearch 中提供了很多内置的
roles
,用于分配
Cluster privileges
和
indics privileges
,可以满足大部分场景。
logstash的
role
如下:
kind: Secret
apiVersion: v1
metadata:
name: {{ .Values.logstash.role }}
namespace: {{ .Release.Namespace }}
labels:
{{- include "eck-operator.labels" $ | nindent 4 }}
stringData:
roles.yml: |-
{{ .Values.logstash.role }}:
cluster: ["monitor", "manage_ilm", "read_ilm", "manage_logstash_pipelines", "manage_index_templates", "cluster:admin/ingest/pipeline/get",]
indices:
- names: [ '*' ]
privileges: ["manage", "write", "create_index", "read", "view_index_metadata"]
kibana admin可以使用
kibana_admin,viewer
role。
kibana中有很多space,对于guest用户来说只需要查看个别space即可,建议根据
官方文档
配置kibana的role,user和space。
需要注意的是,像data view(即index pattern)和dashboard是按照space隔离的,因此如果多个用户需要查看相同的data view和dashboard,则需要使用相同的space。kibana中有一个默认space,名为
default
,大部分情况下不需要创建单独的space,在用户的role中直接引用该space,并指定部分space权限即可。
guest一般需要有查看Discover和Dashboard空间的权限,此时需要有
create data view
权限,在Stack Management->Roles->guest(假设创建的role名为guest)->kibana中授予
Management->Data View Management
All
权限即可。
Elasticsearch-exporter可以设置如下
role
,注意role的名称是
exporter_admins
,而不是
metadata.name
:
kind: Secret
apiVersion: v1
metadata:
name: {{ .Values.exporter.role }}
namespace: {{ .Release.Namespace }}
labels:
{{- include "eck-operator.labels" $ | nindent 4 }}
stringData:
roles.yml: |-
exporter_admins: #定义的role名称
cluster: [ 'monitor' ]
indices:
- names: [ '*' ]
privileges: [ 'monitor' ]
自定义的user会被挂载到容器中的
/usr/share/elasticsearch/config/users
文件中,而role会被挂载到
/usr/share/elasticsearch/config/roles
文件中,user和role的映射关系可以查看文件
/usr/share/elasticsearch/config/users_roles
需要注意的是:如果使用
file realm
添加的user和role,是不能通过kibana的
/Stack Management/Roles/
菜单或
api
查看的