什么是 doris,为什么几乎国内大厂都会使用它
转载至我的博客
https://www.infrastack.cn
,公众号:架构成长指南
今天给各位分享一个非常牛的实时分析型数据库Apache Doris,几乎国内的一二线大厂都在使用它做数据分析,如下图,这只是一小部分

同时我司也在使用它,他目前支撑了我们亿级业务数据的多维实时查询分析,而且性能很不错
Doris 介绍
官方地址:
https://doris.apache.org/
Apache Doris源于百度2008年启动的产品Palo在2018年捐献给Apache基金会,是一个基于 MPP 架构的高性能、实时的分析型数据库,他非常简单易用,而且性能还不错,仅需亚秒级响应时间即可获得查询结果,不仅支持高并发的查询场景,也可以支持高吞吐的复杂分析场景,比如你可以基于它做用户行为分析、日志检索平台、用户画像分析、订单分析等应用。
Doris的架构非常简洁,易于运维,并且可以支持10PB以上的超大数据集
特性

这里特性很多,但是如果没接触过大数据的同学,可能不是特别了解,但是注意这个特性,
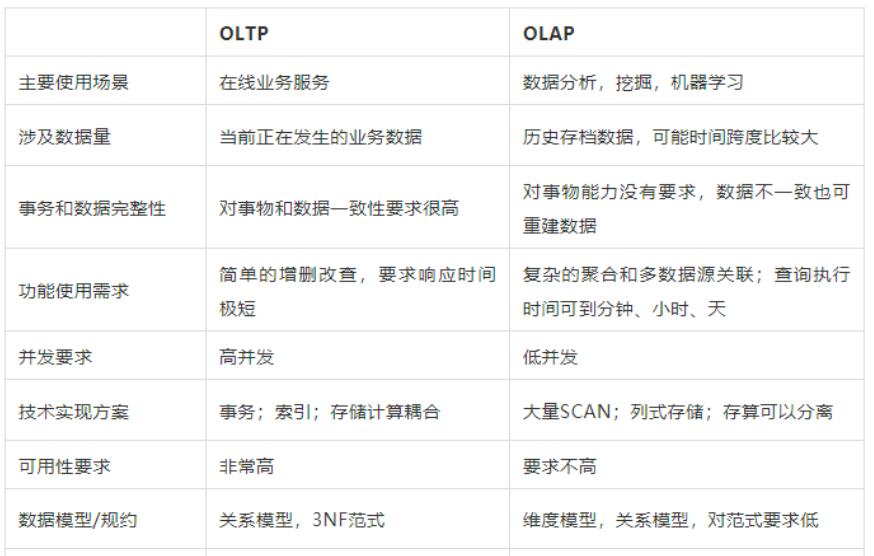
支持SQL 语言,兼容MySQL
,比如:通过Mybatis 写好 sql,就可以调用查询,而且他能支持亿级数据检索响应,以前还是想分库分表呢,现在有了它可以在考虑一下它了,看分库分表有必要吗,但是这里要注意下,它是一个 OLAP 引擎与 OLTP还是有点区别,如果业务场景,新增多后期更新少,同时查询场景多,那么可以在 mysql 中保存一段时间的热点数据,来进行相关业务操作,而报表查询都走Doris
这里可能有些人员不懂什么是 OLAP,下面是一个OLAP与OLTP对比图
架构
Doirs只有两个主进程模块。一个是 Frontend(FE),另一个是Backend(BE)
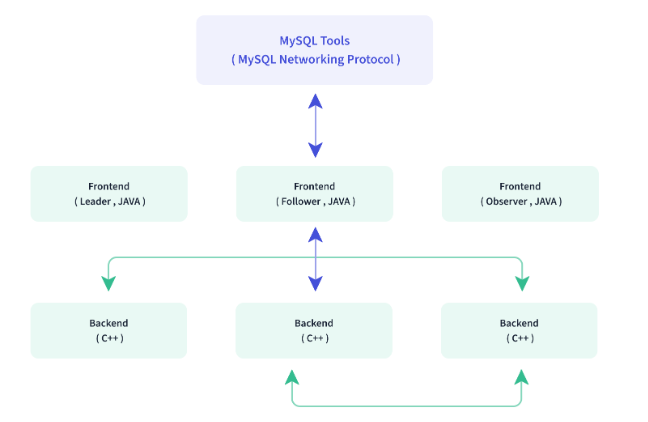
Frontend(FE)
主要负责用户请求的接入、查询计划的解析、元数据的存储和集群管理相关工作, Doris采用Paxos协议以及Memory + Checkpoint + Journal的机制来确保元数据的高性能及高可靠。
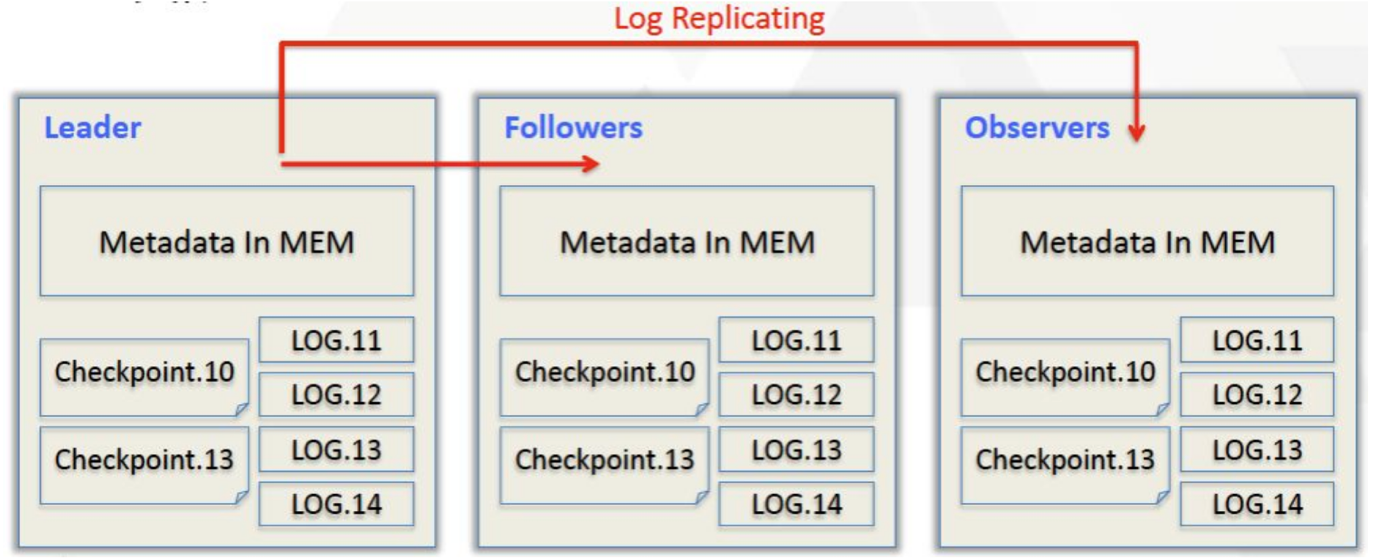
Leader、follower和 observer它们三个构成一个可靠的服务
,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务,与zookeeper角色一样。
Backend(BE)
BE主要负责数据存储、查询计划的执行。
BE管理tablet副本, tablet是table经过分区分桶形成的子表, 采用列式存储。
BE受FE指导, 创建或删除子表。
BE接收FE分发的物理执行计划与其他BE共同协作完成执行。
BE读本地的列存储引擎, 获取数据, 通过索引和谓词下沉快速过滤数据。
BE后台执行compact任务, 减少查询时的读放大。
以上FE和 BE支持动态弹性扩容,而且在扩容过程中对应用无影响,同时Doris 不依赖
zk
、
hdfs
等,所以架构很简单,这种架构设计极大的简化了运维成本,
其实一个好的产品就应该这样,把复杂留给自己,把简单留给用户
OLAP对比
在我们解决大数据查询分析时,也调研了比较知名的一些产品,下面是一个对比
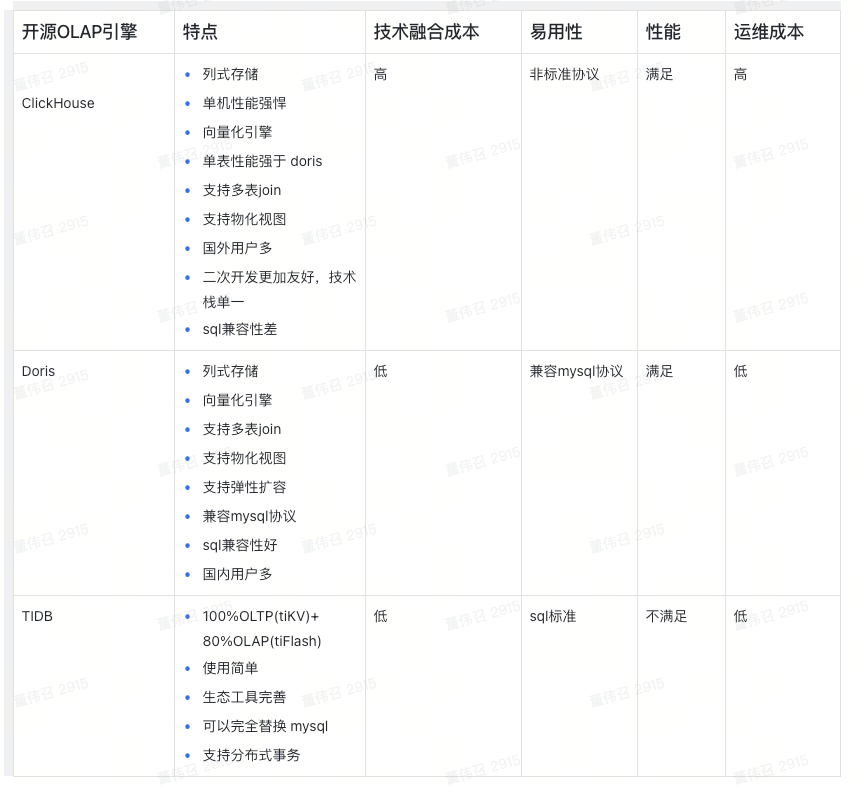
TIDB
TIDB 是一个非常优秀的国产分布式数据库,他的主要优势OLTP处理上,但是也支持OLAP,但是在我们调研过程中,抱着使用一个TIDB 完全替代掉Mysql 想法,我们进行了测试,我们使用的版本是
v5.3.3
,但是在测试过程中效果不理想,因为 TIDB 解析引擎会对SQL进行分析,来决定走 OLTP 还是OLAP,比如我们期望走OLAP 但是走了OLTP导致性能有所降低
ClickHouse
提到 Doris 不得不提ClickHouse,CK是
由俄罗斯IT公司Yandex为Yandex.Metrica网络分析服务开发的
开发的实时数仓,以性能著称,但是经过测试,与 Doris在不同场景各有优劣, 但是它的架构复杂、运维成本高,同时对 sql 语法兼容性没有Doris好,因此没有选择,不过国内也有不少公司在使用
Doris
运维成本低、兼容Mysql 语法、架构足够简单、社区支持性好(非常活跃),同时经过百度内部长达10 多年的大规模使用,成熟度不容置疑,没有理由不选它
性能测试报告
Doris 版本:0.15.0,目前最新版本是:2.03
- 1 FE + 3 BE 独立部署
- CPU:8core 16G Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz
- 内存:16GB
- 硬盘:1块机械硬盘
- 网卡:万兆网卡
测试1
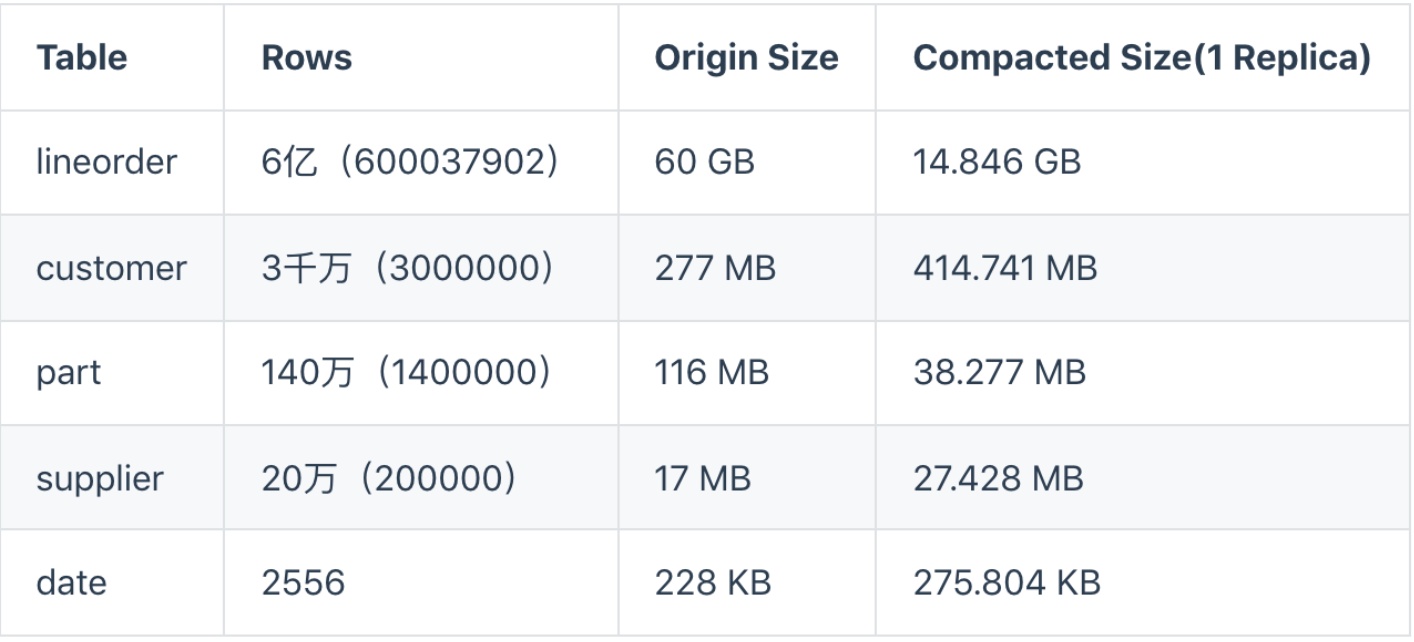
6亿数据进行多表查询,响应
1.98s
SELECT SUM(lo_revenue), d_year, p_brand FROM lineorder, date, part, supplier WHERE lo_orderdate = d_datekey AND lo_partkey = p_partkey AND lo_suppkey = s_suppkey AND p_category = 'MFGR#12' AND s_region = 'AMERICA' GROUP BY d_year, p_brand ORDER BY d_year, p_brand;
测试2
ods_test_mysql_test_record_s数据量:148399619,67 个字段
ods_test_mysql_test_barrier_s数据量:1385,12个字段
执行以下 sql,耗时:
0.277s
SELECT
i.a1 AS p_code,
IFNULL(IFNULL(i.a56, b.a2), '0') AS gateway_no,
1 AS inout_type,
DATE_FORMAT(i.a2, '%Y-%m-%d') AS report_date,
DATE_FORMAT(i.a2, '%Y') AS report_year,
DATE_FORMAT(i.a2, '%c') AS report_month,
1 AS total_num,
(CASE WHEN i.a6 = 1 THEN 1 ELSE 0 END) AS big_car_num,
(CASE WHEN i.a6 != 1 THEN 1 ELSE 0 END) AS small_car_num,
(CASE WHEN i.a44 REGEXP '[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}(([0-9]{5}[DABCEFGHJK])|([DABCEFGHJK][A-HJ-NP-Z0-9][0-9]{4}))$' THEN 1 ELSE 0 END) AS new_power_car_num,
(CASE WHEN i.a61 = 2 OR i.a61 = 3 THEN 1 ELSE 0 END) AS reserve_num,
(CASE WHEN i.a61 = 1 THEN 1 ELSE 0 END) AS white_list_num,
(CASE WHEN i.a6 = 1 AND (i.a61 = 2 OR i.a61 = 3) THEN 1 ELSE 0 END) AS big_car_reserve_num,
(CASE WHEN i.a6 = 1 AND i.a61 = 1 THEN 1 ELSE 0 END) AS big_car_white_list_num,
(CASE WHEN i.a6 != 1 AND (i.a61 = 2 OR i.a61 = 3) THEN 1 ELSE 0 END) AS small_car_reserve_num,
(CASE WHEN i.a6 != 1 AND i.a61 = 1 THEN 1 ELSE 0 END) AS small_car_white_list_num,
(CASE WHEN (i.a61 = 2 OR i.a61 = 3) AND i.a44 REGEXP '[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}(([0-9]{5}[DABCEFGHJK])|([DABCEFGHJK][A-HJ-NP-Z0-9][0-9]{4}))$' THEN 1 ELSE 0 END) AS new_power_reserve_num,
(CASE WHEN i.a61 = 1 AND i.a44 REGEXP '[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}(([0-9]{5}[DABCEFGHJK])|([DABCEFGHJK][A-HJ-NP-Z0-9][0-9]{4}))$' THEN 1 ELSE 0 END) AS new_power_white_list_num,
CURRENT_TIMESTAMP() AS update_time
FROM
ods_test_mysql_test_record_s i
LEFT JOIN ods_test_mysql_test_barrier_s b ON i.a22 = b.a1
WHERE
i.a67 = 0
AND i.a1 = '100280023213'
AND i.a2 < '2021-11-20 00:00:00'
AND (
i.a2 BETWEEN DATE_FORMAT(i.a2, '%Y-%m-%d 00:00:00') AND FROM_UNIXTIME(UNIX_TIMESTAMP(DATE_FORMAT(i.a2, '%Y-%m-%d 00:00:00')) + 90000, '%Y-%m-%d %H:%i:%s')
)
LIMIT 1000;

测试3
只查询小于
2022-12-30 00:00:00
数据,响应时间:
0.241s
SELECT
i.a1 AS p_code,
IFNULL(IFNULL(i.a56, b.a2), '0') AS gateway_no,
1 AS inout_type,
DATE_FORMAT(i.a2, '%Y-%m-%d') AS report_date,
DATE_FORMAT(i.a2, '%Y') AS report_year,
DATE_FORMAT(i.a2, '%c') AS report_month,
1 AS total_num,
(CASE WHEN i.a6 = 1 THEN 1 ELSE 0 END) AS big_car_num,
(CASE WHEN i.a6 != 1 THEN 1 ELSE 0 END) AS small_car_num,
(CASE WHEN i.a44 REGEXP '[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}(([0-9]{5}[DABCEFGHJK])|([DABCEFGHJK][A-HJ-NP-Z0-9][0-9]{4}))$' THEN 1 ELSE 0 END) AS new_power_car_num,
(CASE WHEN i.a61 = 2 OR i.a61 = 3 THEN 1 ELSE 0 END) AS reserve_num,
(CASE WHEN i.a61 = 1 THEN 1 ELSE 0 END) AS white_list_num,
(CASE WHEN i.a6 = 1 AND (i.a61 = 2 OR i.a61 = 3) THEN 1 ELSE 0 END) AS big_car_reserve_num,
(CASE WHEN i.a6 = 1 AND i.a61 = 1 THEN 1 ELSE 0 END) AS big_car_white_list_num,
(CASE WHEN i.a6 != 1 AND (i.a61 = 2 OR i.a61 = 3) THEN 1 ELSE 0 END) AS small_car_reserve_num,
(CASE WHEN i.a6 != 1 AND i.a61 = 1 THEN 1 ELSE 0 END) AS small_car_white_list_num,
(CASE WHEN (i.a61 = 2 OR i.a61 = 3) AND i.a44 REGEXP '[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}(([0-9]{5}[DABCEFGHJK])|([DABCEFGHJK][A-HJ-NP-Z0-9][0-9]{4}))$' THEN 1 ELSE 0 END) AS new_power_reserve_num,
(CASE WHEN i.a61 = 1 AND i.a44 REGEXP '[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}(([0-9]{5}[DABCEFGHJK])|([DABCEFGHJK][A-HJ-NP-Z0-9][0-9]{4}))$' THEN 1 ELSE 0 END) AS new_power_white_list_num,
CURRENT_TIMESTAMP() AS update_time
FROM
ods_test_mysql_test_record_s i
LEFT JOIN ods_test_mysql_test_barrier_s b ON i.a22 = b.a1
WHERE i.a2 < '2022-12-30 00:00:00' LIMIT 10000;

测试 4
最新官方性能测试报告:
https://doris.apache.org/zh-CN/docs/benchmark/ssb/
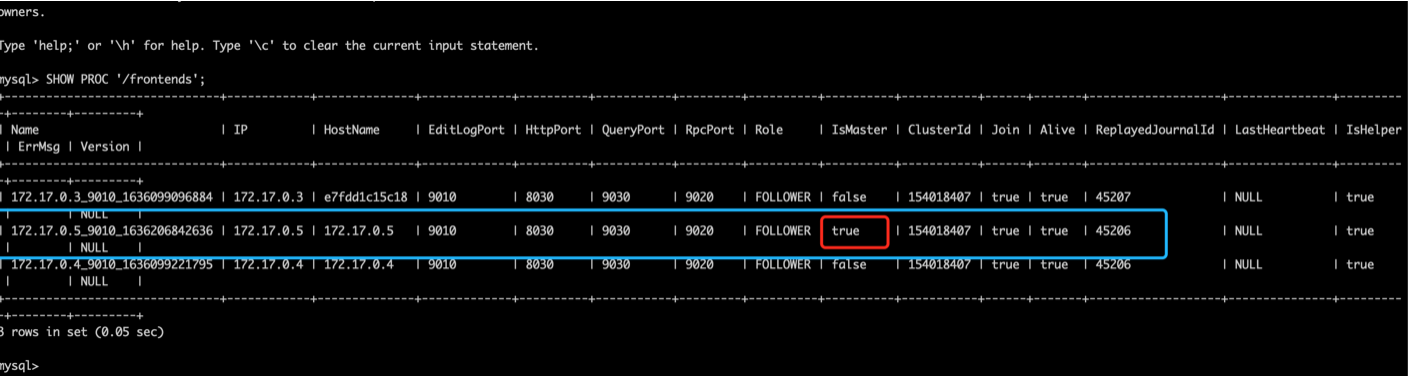
高可用测试
如下图FE3台组建一个高可用集群,分别为:
- 172.17.0.3 FOLLOWER
- 172.17.0.4 FOLLOWER
- 172.17.0.5 MASTER
下面对会对常见一些异常场景进行测试验证,以下部分测试案例
MASTER下线测试
测试结果
成功,所有操作符合预期
测试过程
登录172.17.0.5 服务器杀掉FE节点
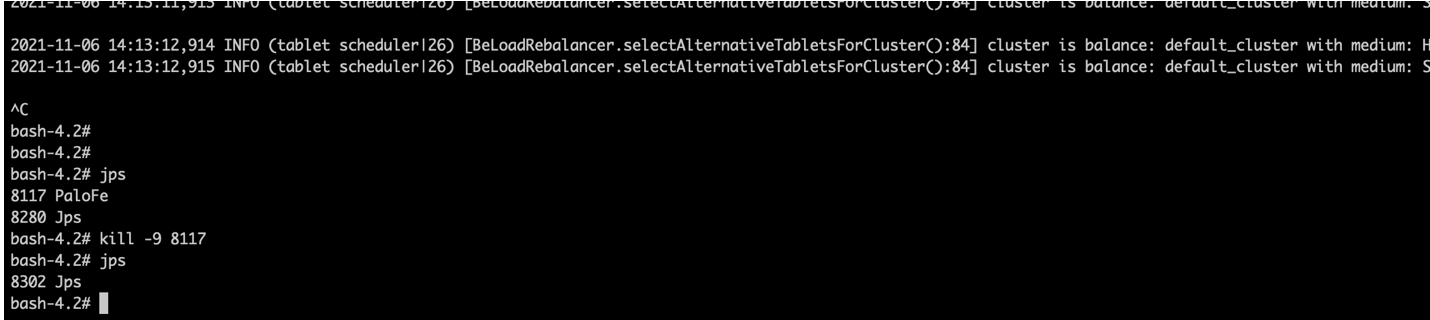
查看FE节点状态是否正常, 登录172.17.0.3服务器查看状态,执行以下命令
SHOW PROC '/frontends';
可以看到172.17.0.4成为了master,而172.17.0.5显示已经不在线了 Alive=false

执行插入数据操作,可以看到执行成功。
启动172.17.0.5,查看是否能加入集群
sh /root/fe/bin/start_fe.sh 172.17.0.3:9010 --daemon
通过日志可以看到启动成功,并成为了FOLLOWER节点

修复缺失或损坏副本
测试结果
成功,所有操作符合预期
测试过程
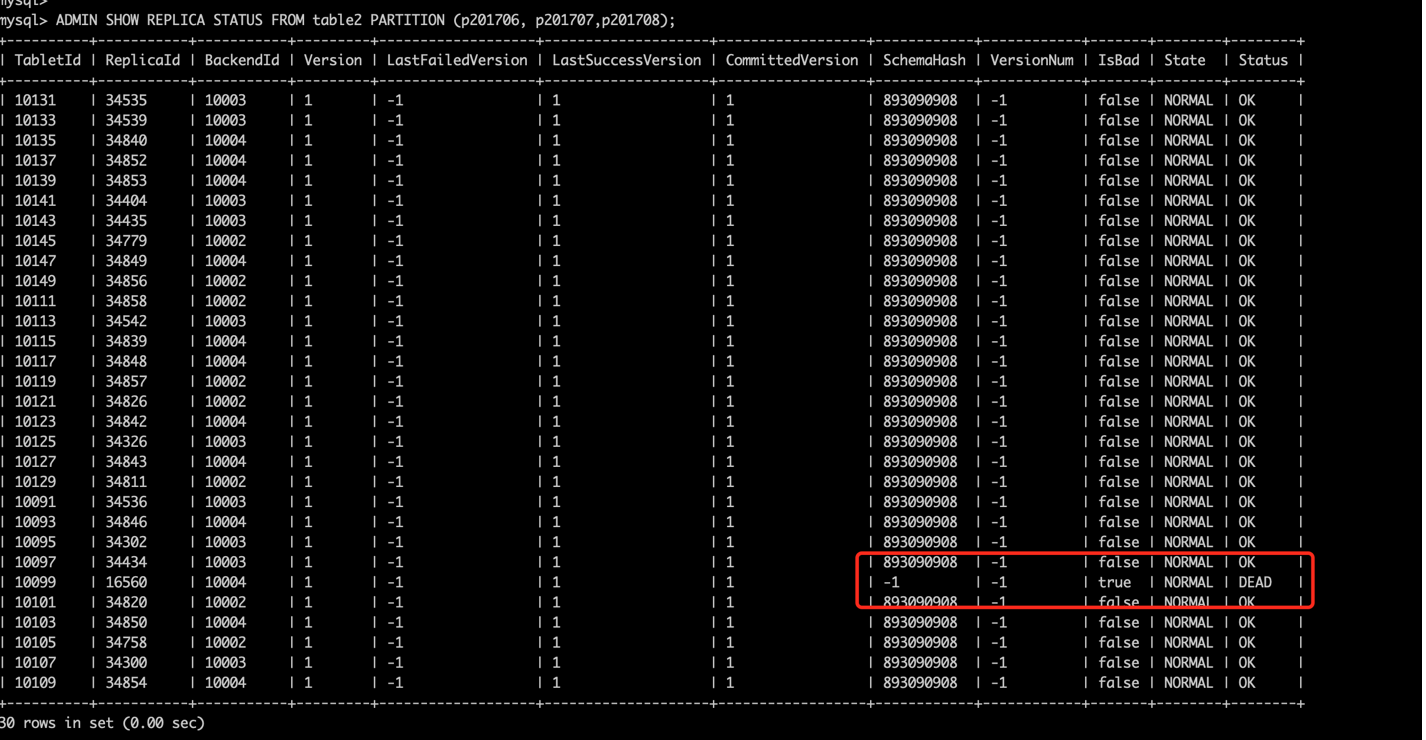
1.执行如下命令看到分区10099的副本损坏,需要对他进行恢复创建空白副本
ADMIN SHOW REPLICA STATUS FROM table2 PARTITION (p201706, p201707,p201708);
2.登录master fe
ADMIN SET FRONTEND CONFIG ("recover_with_empty_tablet" = "true");
3.查看数据副本状态
ADMIN SHOW REPLICA STATUS FROM table2 PARTITION (p201706, p201707,p201708);

4.恢复设置
ADMIN SET FRONTEND CONFIG ("recover_with_empty_tablet" = "false");
系统Down机重启副本测试
测试结果
成功,所有操作符合预期
测试过程
1.停止0.5服务
2.查询副本状态
ADMIN SHOW REPLICA STATUS FROM table4;

3.重启服务,副本状态恢复正常

总结
以上介绍了Doris架构、性能、故障恢复、动态弹性扩容等特性,正因为这些特性,使不少大厂都在使用它,如果贵司有大数据处理需求,可以深入了解一下它,同时想深入了解 Doris,可以加我微信,拉你进官方社区群
扫描下面的二维码关注我们的微信公众帐号,在微信公众帐号中回复◉加群◉即可加入到我们的技术讨论群里面共同学习。