zookeeper源码(06)ZooKeeperServer及子类
ZooKeeperServer
实现了单机版zookeeper服务端功能,子类实现了更加丰富的分布式集群功能:
ZooKeeperServer
|-- QuorumZooKeeperServer
|-- LeaderZooKeeperServer
|-- LearnerZooKeeperServer
|-- FollowerZooKeeperServer
|-- ObserverZooKeeperServer
|-- ReadOnlyZooKeeperServer
主要字段
// tickTime参数默认值
public static final int DEFAULT_TICK_TIME = 3000;
protected int tickTime = DEFAULT_TICK_TIME;
// 默认tickTime * 2
protected int minSessionTimeout = -1;
// 默认tickTime * 20
protected int maxSessionTimeout = -1;
// 会话跟踪
protected SessionTracker sessionTracker;
// 存储组件
private FileTxnSnapLog txnLogFactory = null;
private ZKDatabase zkDb;
// 缓存数据
private ResponseCache readResponseCache;
private ResponseCache getChildrenResponseCache;
// zxid会在启动阶段设置为最新lastZxid
private final AtomicLong hzxid = new AtomicLong(0);
// 请求处理器链入口
protected RequestProcessor firstProcessor;
// 缓存变化的数据
final Deque<ChangeRecord> outstandingChanges = new ArrayDeque<>();
final Map<String, ChangeRecord> outstandingChangesForPath = new HashMap<>();
protected ServerCnxnFactory serverCnxnFactory;
protected ServerCnxnFactory secureServerCnxnFactory;
// 大请求判断使用的参数
private volatile int largeRequestMaxBytes = 100 * 1024 * 1024;
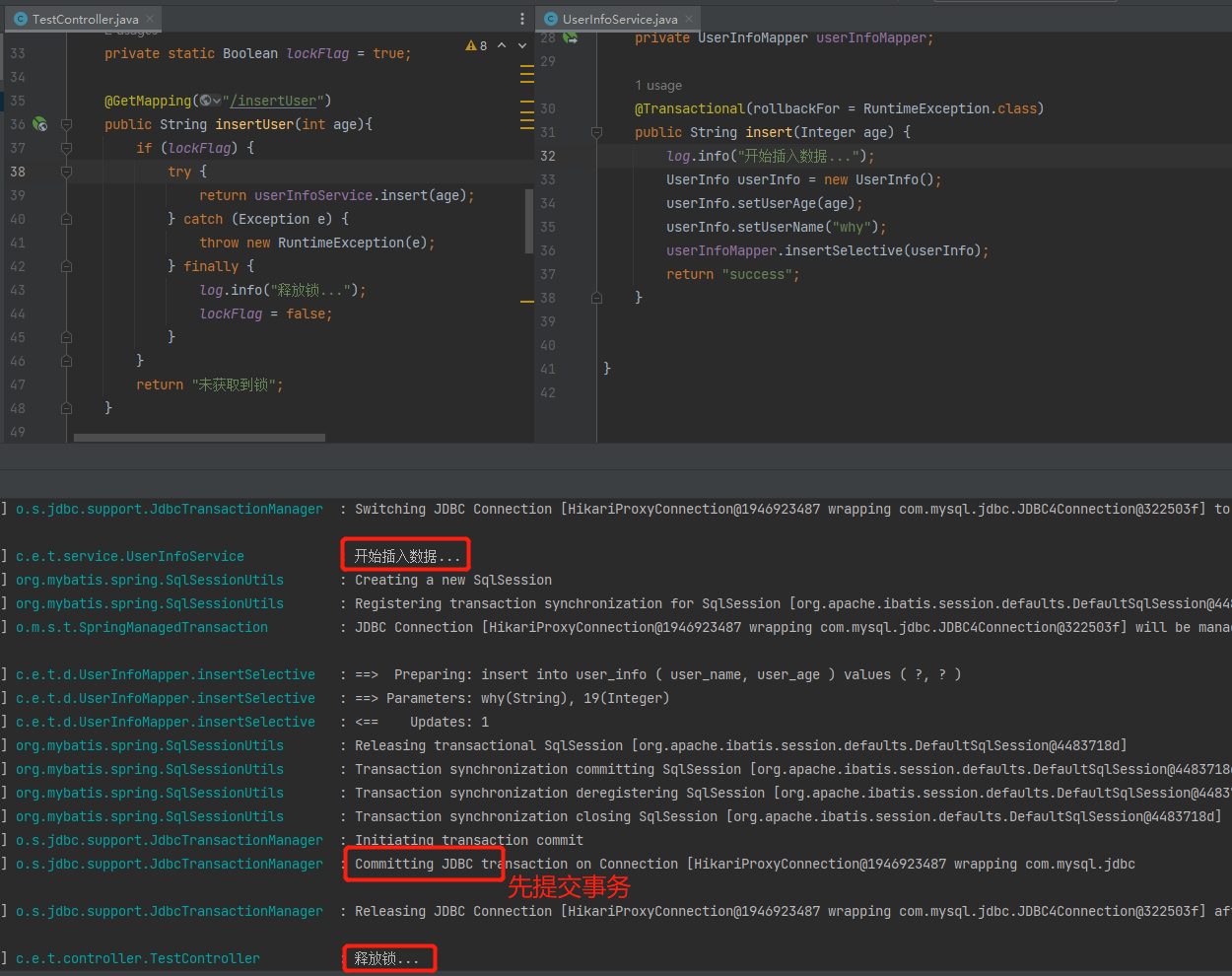
private volatile int largeRequestThreshold = -1;
主要方法
方法定义
// 通过zkDb从dataTree中删除Watcher监听器
void removeCnxn(ServerCnxn cnxn);
// 创建zkDb(为null时)并loadData加载数据
public void startdata() throws IOException, InterruptedException;
// 加载数据、清理session、生成快照
public void loadData() throws IOException, InterruptedException;
// 保存zkDb当前快照
public synchronized File takeSnapshot(boolean syncSnap, boolean isSevere,
boolean fastForwardFromEdits) throws IOException;
// 从指定的输入流解析数据,生成新的zkDb和SessionTrack
public synchronized long restoreFromSnapshot(final InputStream inputStream) throws IOException;
// 使用zkDb.truncateLog(zxid)删除快照数据
public void truncateLog(long zxid) throws IOException;
// 通过zkDb获取dataTree.lastProcessedZxid的值
public long getLastProcessedZxid();
// 提交closeSession类型的Request来关闭会话
private void close(long sessionId);
// 使用zkDb杀掉会话
protected void killSession(long sessionId, long zxid);
// 启动组件
private void startupWithServerState(State state);
// 创建RequestProcessor用来处理请求
protected void setupRequestProcessors();
// 创建SessionTracker
protected void createSessionTracker();
// 为指定的session生成一个密码
byte[] generatePasswd(long id);
// 验证session密码
protected boolean checkPasswd(long sessionId, byte[] passwd);
// 使用sessionTracker创建session、生成密码、提交一个createSession请求
long createSession(ServerCnxn cnxn, byte[] passwd, int timeout);
// 为指定的session绑定owner
public void setOwner(long id, Object owner) throws SessionExpiredException;
// 验证session之后使用finishSessionInit方法确定继续通信或者断开连接
protected void revalidateSession(ServerCnxn cnxn, long sessionId, int sessionTimeout) throws IOException;
public void finishSessionInit(ServerCnxn cnxn, boolean valid);
// checkPasswd->revalidateSession->finishSessionInit
public void reopenSession(ServerCnxn cnxn, long sessionId,
byte[] passwd, int sessionTimeout) throws IOException;
// 把请求提交给requestThrottler之后再陆续调用submitRequestNow处理
public void enqueueRequest(Request si);
// 使用firstProcessor处理请求
public void submitRequestNow(Request si);
// 处理连接请求,网络IO层调用
public void processConnectRequest(
ServerCnxn cnxn, ConnectRequest request) throws IOException, ClientCnxnLimitException;
// 处理业务请求,网络IO层调用
public void processPacket(ServerCnxn cnxn, RequestHeader h, RequestRecord request) throws IOException;
// sasl认证
private void processSasl(
RequestRecord request, ServerCnxn cnxn, RequestHeader requestHeader) throws IOException;
// 处理transaction
public ProcessTxnResult processTxn(TxnHeader hdr, Record txn);
public ProcessTxnResult processTxn(Request request);
private void processTxnForSessionEvents(Request request, TxnHeader hdr, Record txn);
private ProcessTxnResult processTxnInDB(TxnHeader hdr, Record txn, TxnDigest digest);
// Grant or deny authorization to an operation on a node
public void checkACL(ServerCnxn cnxn, List<ACL> acl, int perm, List<Id> ids,
String path, List<ACL> setAcls) throws KeeperException.NoAuthException;
// Check a path whether exceeded the quota
public void checkQuota(String path, byte[] lastData, byte[] data,
int type) throws KeeperException.QuotaExceededException;
private void checkQuota(String lastPrefix, long bytesDiff, long countDiff,
String namespace) throws KeeperException.QuotaExceededException;
// 获取上级父类path
private String parentPath(String path) throws KeeperException.BadArgumentsException;
// 从Request获取有效的path
private String effectiveACLPath(
Request request) throws KeeperException.BadArgumentsException, KeeperException.InvalidACLException;
// 根据Request获取需要的权限类型
private int effectiveACLPerms(Request request);
// 检查写权限
public boolean authWriteRequest(Request request);
loadData方法
加载数据、清理session、生成快照:
public void loadData() throws IOException, InterruptedException {
// 初始化zxid
if (zkDb.isInitialized()) {
setZxid(zkDb.getDataTreeLastProcessedZxid());
} else {
setZxid(zkDb.loadDataBase());
}
// 使用killSession方法杀死过期会话
zkDb.getSessions().stream()
.filter(session -> zkDb.getSessionWithTimeOuts().get(session) == null)
.forEach(session -> killSession(session, zkDb.getDataTreeLastProcessedZxid()));
// 保存快照
// txnLogFactory.save(zkDb.getDataTree(), zkDb.getSessionWithTimeOuts(), syncSnap)
takeSnapshot();
}
killSession方法
protected void killSession(long sessionId, long zxid) {
// 需要清理临时节点
zkDb.killSession(sessionId, zxid);
if (sessionTracker != null) {
// 删除会话跟踪信息
sessionTracker.removeSession(sessionId);
}
}
startupWithServerState方法
private void startupWithServerState(State state) {
if (sessionTracker == null) {
createSessionTracker();
}
startSessionTracker();
// 创建RequestProcessor用于处理请求
setupRequestProcessors();
// 这是一个限流的组件,不做分析
startRequestThrottler();
registerJMX();
startJvmPauseMonitor();
registerMetrics();
setState(state);
requestPathMetricsCollector.start();
localSessionEnabled = sessionTracker.isLocalSessionsEnabled();
notifyAll();
}
setupRequestProcessors方法(重要)
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor syncProcessor = new SyncRequestProcessor(this, finalProcessor);
((SyncRequestProcessor) syncProcessor).start();
firstProcessor = new PrepRequestProcessor(this, syncProcessor);
((PrepRequestProcessor) firstProcessor).start();
}
RequestProcessor接口:以处理器链方式处理事务,请求总是按顺序处理。standaloneServer、follower和leader有不同的处理器链。请求通过processRequest方法传递给其他RequestProcessor对象,通常情况总是由单个线程调用。当调用shutdown时,RequestProcessor还应关闭与其关联的其他RequestProcessor对象。
FinalRequestProcessor类:处理与请求相关的事务,并提供查询服务,给客户端发响应,位于RequestProcessor链末尾。
SyncRequestProcessor类:将请求记录到磁盘,对请求进行批处理,以有效地执行IO操作。在日志同步到磁盘之前,请求不会传递给下一个RequestProcessor对象。SyncRequestProcessor用于3种不同的情况:
- Leader - 将请求同步到磁盘,并将其转发给AckRequestProcessor,后者将ack发送回leader自己
- Follower - 将请求同步到磁盘,并将其转发给SendAckRequestProcessor,后者将ack发送给leader
- Observer - 将请求同步到磁盘,作为INFORM数据包接收。不将ack发送回leader,因此nextProcessor将为null
PrepRequestProcessor类:通常位于RequestProcessor链开头,为更新请求关联的事务做设置。
createSessionTracker方法
protected void createSessionTracker() {
sessionTracker = new SessionTrackerImpl(this, zkDb.getSessionWithTimeOuts(), tickTime,
createSessionTrackerServerId, getZooKeeperServerListener());
}
不同的子类使用了不同的SessionTracker实现类:
- LeaderZooKeeperServer - LeaderSessionTracker
- LearnerZooKeeperServer- LearnerSessionTracker
createSession方法
long createSession(ServerCnxn cnxn, byte[] passwd, int timeout) {
if (passwd == null) {
passwd = new byte[0];
}
// 创建一个session
long sessionId = sessionTracker.createSession(timeout);
// 生成session密码
Random r = new Random(sessionId ^ superSecret);
r.nextBytes(passwd);
// 提交createSession请求,该请求会被RequestProcessor处理
CreateSessionTxn txn = new CreateSessionTxn(timeout);
cnxn.setSessionId(sessionId);
Request si = new Request(cnxn, sessionId, 0, OpCode.createSession, RequestRecord.fromRecord(txn), null);
submitRequest(si);
return sessionId;
}
submitRequestNow方法
public void submitRequestNow(Request si) {
try {
touch(si.cnxn);
boolean validpacket = Request.isValid(si.type);
if (validpacket) {
setLocalSessionFlag(si);
// 使用firstProcessor处理请求
firstProcessor.processRequest(si);
if (si.cnxn != null) {
incInProcess();
}
} else {
// Update request accounting/throttling limits
requestFinished(si);
new UnimplementedRequestProcessor().processRequest(si);
}
} catch (MissingSessionException e) {
// Update request accounting/throttling limits
requestFinished(si);
} catch (RequestProcessorException e) {
// Update request accounting/throttling limits
requestFinished(si);
}
}
processConnectRequest方法
public void processConnectRequest(
ServerCnxn cnxn, ConnectRequest request) throws IOException, ClientCnxnLimitException {
long sessionId = request.getSessionId();
// 略
if (request.getLastZxidSeen() > zkDb.dataTree.lastProcessedZxid) {
// zxid参数有误
throw new CloseRequestException(msg, ServerCnxn.DisconnectReason.CLIENT_ZXID_AHEAD);
}
int sessionTimeout = request.getTimeOut();
byte[] passwd = request.getPasswd();
int minSessionTimeout = getMinSessionTimeout();
if (sessionTimeout < minSessionTimeout) {
sessionTimeout = minSessionTimeout;
}
int maxSessionTimeout = getMaxSessionTimeout();
if (sessionTimeout > maxSessionTimeout) {
sessionTimeout = maxSessionTimeout;
}
cnxn.setSessionTimeout(sessionTimeout);
// We don't want to receive any packets until we are sure that the session is setup
cnxn.disableRecv();
if (sessionId == 0) {
// 创建session
long id = createSession(cnxn, passwd, sessionTimeout);
} else {
validateSession(cnxn, sessionId); // do nothing
// 关闭旧的ServerCnxn
if (serverCnxnFactory != null) {
serverCnxnFactory.closeSession(sessionId, ServerCnxn.DisconnectReason.CLIENT_RECONNECT);
}
if (secureServerCnxnFactory != null) {
secureServerCnxnFactory.closeSession(sessionId, ServerCnxn.DisconnectReason.CLIENT_RECONNECT);
}
cnxn.setSessionId(sessionId);
// 开启新session
reopenSession(cnxn, sessionId, passwd, sessionTimeout);
}
}
processPacket方法
public void processPacket(ServerCnxn cnxn, RequestHeader h, RequestRecord request) throws IOException {
cnxn.incrOutstandingAndCheckThrottle(h);
if (h.getType() == OpCode.auth) {
AuthPacket authPacket = request.readRecord(AuthPacket::new);
String scheme = authPacket.getScheme();
ServerAuthenticationProvider ap = ProviderRegistry.getServerProvider(scheme);
Code authReturn = KeeperException.Code.AUTHFAILED;
// 认证、继续通信或者关闭连接,略
return;
} else if (h.getType() == OpCode.sasl) {
processSasl(request, cnxn, h);
} else {
if (!authHelper.enforceAuthentication(cnxn, h.getXid())) {
return;
} else {
Request si = new Request(
cnxn, cnxn.getSessionId(), h.getXid(), h.getType(), request, cnxn.getAuthInfo());
int length = request.limit();
if (isLargeRequest(length)) { // 判断large请求
checkRequestSizeWhenMessageReceived(length);
si.setLargeRequestSize(length);
}
si.setOwner(ServerCnxn.me);
// 提交请求等待firstProcessor处理
submitRequest(si);
}
}
}
processTxn相关方法
// entry point for quorum/Learner.java
public ProcessTxnResult processTxn(TxnHeader hdr, Record txn) {
processTxnForSessionEvents(null, hdr, txn);
return processTxnInDB(hdr, txn, null);
}
// entry point for FinalRequestProcessor.java
public ProcessTxnResult processTxn(Request request) {
TxnHeader hdr = request.getHdr();
processTxnForSessionEvents(request, hdr, request.getTxn());
final boolean writeRequest = (hdr != null);
final boolean quorumRequest = request.isQuorum();
// return fast w/o synchronization when we get a read
if (!writeRequest && !quorumRequest) {
return new ProcessTxnResult();
}
synchronized (outstandingChanges) {
ProcessTxnResult rc = processTxnInDB(hdr, request.getTxn(), request.getTxnDigest());
// request.hdr is set for write requests, which are the only ones
// that add to outstandingChanges.
if (writeRequest) {
long zxid = hdr.getZxid();
while (!outstandingChanges.isEmpty() && outstandingChanges.peek().zxid <= zxid) {
ChangeRecord cr = outstandingChanges.remove();
ServerMetrics.getMetrics().OUTSTANDING_CHANGES_REMOVED.add(1);
if (outstandingChangesForPath.get(cr.path) == cr) {
outstandingChangesForPath.remove(cr.path);
}
}
}
// do not add non quorum packets to the queue.
if (quorumRequest) {
getZKDatabase().addCommittedProposal(request);
}
return rc;
}
}
private void processTxnForSessionEvents(Request request, TxnHeader hdr, Record txn) {
int opCode = (request == null) ? hdr.getType() : request.type;
long sessionId = (request == null) ? hdr.getClientId() : request.sessionId;
if (opCode == OpCode.createSession) {
if (hdr != null && txn instanceof CreateSessionTxn) {
CreateSessionTxn cst = (CreateSessionTxn) txn;
// Add the session to the local session map or global one in zkDB.
sessionTracker.commitSession(sessionId, cst.getTimeOut());
}
} else if (opCode == OpCode.closeSession) {
sessionTracker.removeSession(sessionId);
}
}
private ProcessTxnResult processTxnInDB(TxnHeader hdr, Record txn, TxnDigest digest) {
if (hdr == null) {
return new ProcessTxnResult();
} else {
return getZKDatabase().processTxn(hdr, txn, digest);
}
}
QuorumZooKeeperServer
集群模式下的ZooKeeperServer基类:
- 封装了QuorumPeer用来获取节点信息
- 封装了UpgradeableSessionTracker做会话追踪
LeaderZooKeeperServer
Just like the standard ZooKeeperServer. We just replace the request processors: PrepRequestProcessor -> ProposalRequestProcessor -> CommitProcessor -> Leader.ToBeAppliedRequestProcessor -> FinalRequestProcessor
实现类概述
集群模式下leader节点使用的ZooKeeperServer实现类:
继承QuorumZooKeeperServer
使用的RequestProcessor与父类不同:
// 构建处理器链 protected void setupRequestProcessors() { RequestProcessor finalProcessor = new FinalRequestProcessor(this); RequestProcessor toBeAppliedProcessor = new Leader.ToBeAppliedRequestProcessor(finalProcessor, getLeader()); commitProcessor = new CommitProcessor( toBeAppliedProcessor, Long.toString(getServerId()), false, getZooKeeperServerListener()); commitProcessor.start(); ProposalRequestProcessor proposalProcessor = new ProposalRequestProcessor(this, commitProcessor); proposalProcessor.initialize(); prepRequestProcessor = new PrepRequestProcessor(this, proposalProcessor); prepRequestProcessor.start(); firstProcessor = new LeaderRequestProcessor(this, prepRequestProcessor); setupContainerManager(); // 启动ContainerManager用于删除ttl节点和container节点 }使用LeaderSessionTracker做会话追踪
与learner节点通信
处理器链
FinalRequestProcessor - 处理与请求相关的事务,并提供查询服务,给客户端发响应,位于RequestProcessor链末尾
ToBeAppliedRequestProcessor - 维护toBeApplied列表
CommitProcessor - 等待commit完成之后调用下游RequestProcessor处理器
ProposalRequestProcessor - 发起proposal并将Request转发给内部的SyncRequestProcessor和AckRequestProcessor
public ProposalRequestProcessor(LeaderZooKeeperServer zks, RequestProcessor nextProcessor) { this.zks = zks; this.nextProcessor = nextProcessor; // 内部有维护SyncRequestProcessor和AckRequestProcessor AckRequestProcessor ackProcessor = new AckRequestProcessor(zks.getLeader()); syncProcessor = new SyncRequestProcessor(zks, ackProcessor); forwardLearnerRequestsToCommitProcessorDisabled = Boolean.getBoolean( FORWARD_LEARNER_REQUESTS_TO_COMMIT_PROCESSOR_DISABLED); }PrepRequestProcessor - 通常位于RequestProcessor链开头,为更新请求关联的事务做设置
LeaderRequestProcessor - 负责执行本地会话升级,只有直接提交给leader的Request才能通过这个处理器
LearnerZooKeeperServer
Learner基类:
- 使用LearnerSessionTracker做会话追踪
- 使用CommitProcessor、SyncRequestProcessor做处理器链
FollowerZooKeeperServer
实现类概述
与ZooKeeperServer类似,只是处理器链不同:
FollowerRequestProcessor -> CommitProcessor -> FinalRequestProcessor
使用SyncRequestProcessor来记录leader的提案。
处理器链
setupRequestProcessors方法:
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
commitProcessor = new CommitProcessor(
finalProcessor, Long.toString(getServerId()), true, getZooKeeperServerListener());
commitProcessor.start();
firstProcessor = new FollowerRequestProcessor(this, commitProcessor);
((FollowerRequestProcessor) firstProcessor).start();
syncProcessor = new SyncRequestProcessor(this, new SendAckRequestProcessor(getFollower()));
syncProcessor.start();
}
- FinalRequestProcessor
- CommitProcessor
- FollowerRequestProcessor - 将数据更新请求转发给Leader
- SyncRequestProcessor
- SendAckRequestProcessor - 给leader发ACK
ObserverZooKeeperServer
Observer类型节点的ZooKeeperServer实现。
setupRequestProcessors方法:
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
commitProcessor = new CommitProcessor(
finalProcessor, Long.toString(getServerId()), true, getZooKeeperServerListener());
commitProcessor.start();
firstProcessor = new ObserverRequestProcessor(this, commitProcessor);
((ObserverRequestProcessor) firstProcessor).start();
// 默认false
if (syncRequestProcessorEnabled) {
syncProcessor = new SyncRequestProcessor(this, null);
syncProcessor.start();
}
}