Rocketmq学习3——消息发送原理源码浅析
一丶概述
RocketMQ 消息发送的原理流程可以分为以下几个步骤:
1. 创建生产者
在发送消息前,客户端首先需要创建一个消息生产者(Producer)实例,并设置必要的配置参数,如NameServer地址、生产组名称、消息发送失败的重试次数等。
2. 启动生产者
创建生产者后,需要调用启动方法来初始化生产者实例。在这个过程中,生产者会与NameServer建立连接,从NameServer获取到所有Broker的地址信息。
3. 发送消息
消息发送分为同步发送、异步发送和单向发送三种方式:
- 同步发送(Synchronous):
生产者发送消息后,会在发送线程中等待服务器的响应,直到收到消息发送确认。 - 异步发送(Asynchronous):
生产者发送消息后,不会等待服务器的响应,而是通过回调接口处理服务器的响应。 - 单向发送(One-way):
生产者只负责发送消息,不等待服务器响应,也不关心消息是否到达服务器。
无论采用哪种发送方式,消息发送的主要流程如下:
- 消息路由:
生产者通过负载均衡算法选择一个队列,通常是根据topic和队列选择一个Broker的一个队列来发送消息。 - 消息发送:
生产者向选定的Broker发送消息。消息包含了topic、tags、keys、body等信息。 - 消息存储:
Broker接收到消息后,会将消息存储到
CommitLog
(消息存储文件)中。如果配置了消息重试或者高可靠性相关的配置,Broker可能会执行额外的消息复制或持久化操作以确保消息的可靠性。 - 写入响应:
Broker将消息存储确认响应返回给生产者。如果是同步发送,生产者会在这一步等待该响应;如果是异步发送,生产者会在回调函数中处理该响应。
本篇,我们就来简单看下rocketmq从生产者发送消息,学习一下其中优秀的设计!
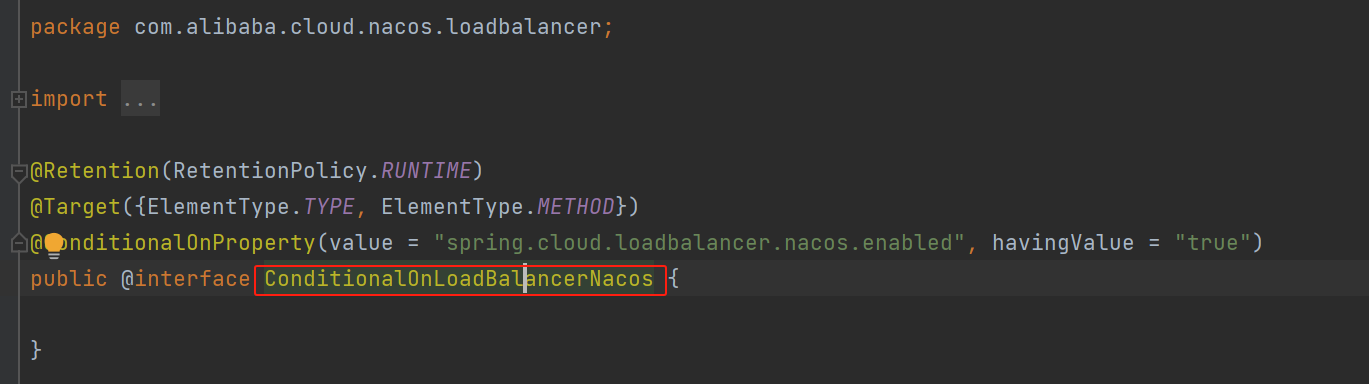
二丶生产者消息发送
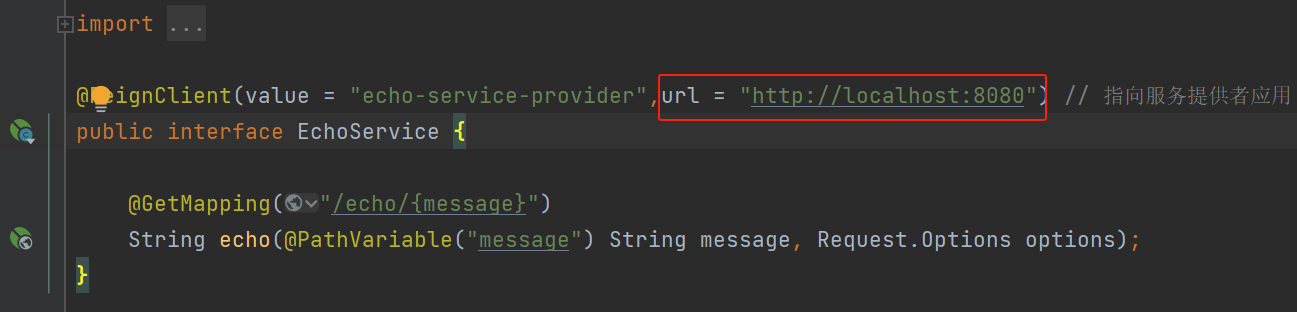
生产者消息发送本质是通过网络io将消息发送到broker中,通常通过
DefaultMQProducer#send(Message)
进行简单的消息发送,如下是其源码
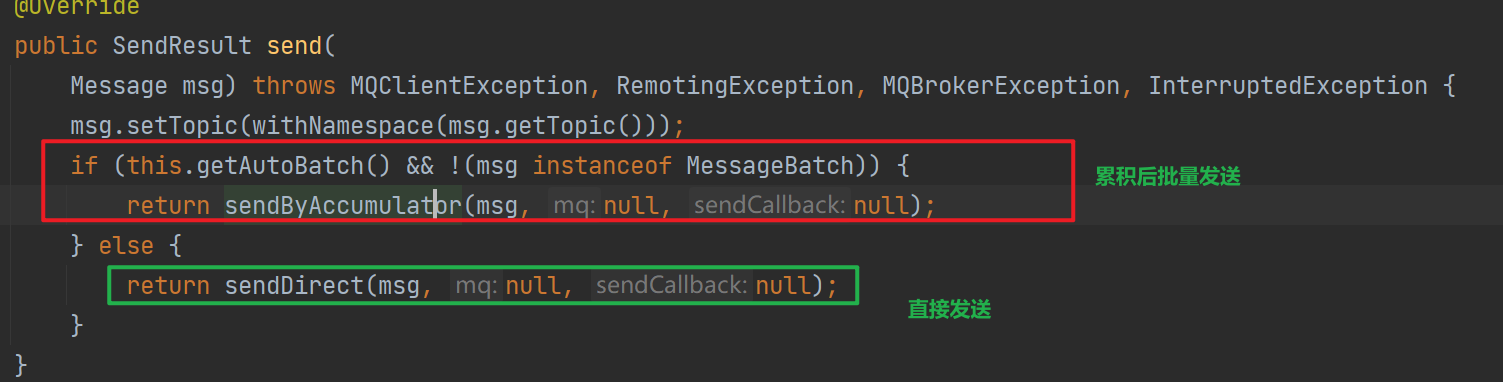
可看到如果设置了autoBatch并且消息本身不是一个批量消息,那么会调用
sendByAccumulator
(使用消息累计器进行发送,猜测会累计到内存中然后批量进行发送)
反之会调用
sendDirect
进行消息发送
1.sendByAccumulator 如何累计消息发送
rocketmq抽象出
ProduceAccumulator
进行消息的累计发送
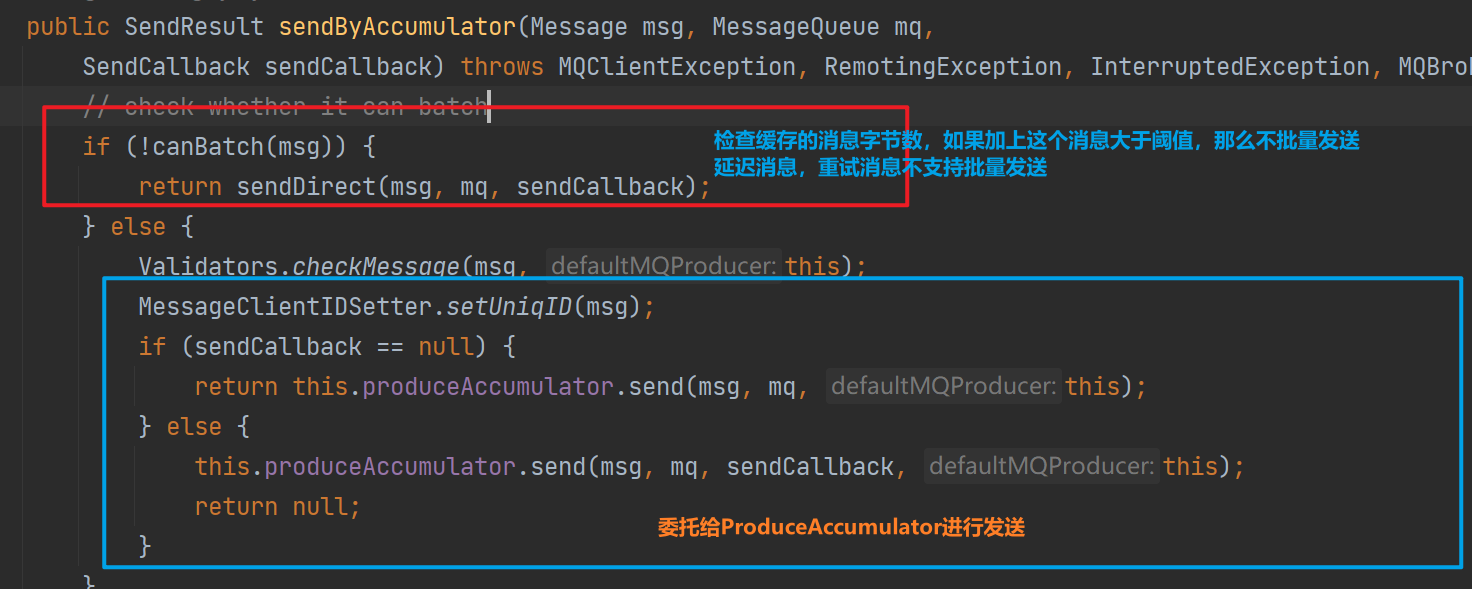
ProduceAccumulator会将消息根据Topic和tag进行分组存储,然后包装为MessageBatch调用DefaultMQProducer进行发送
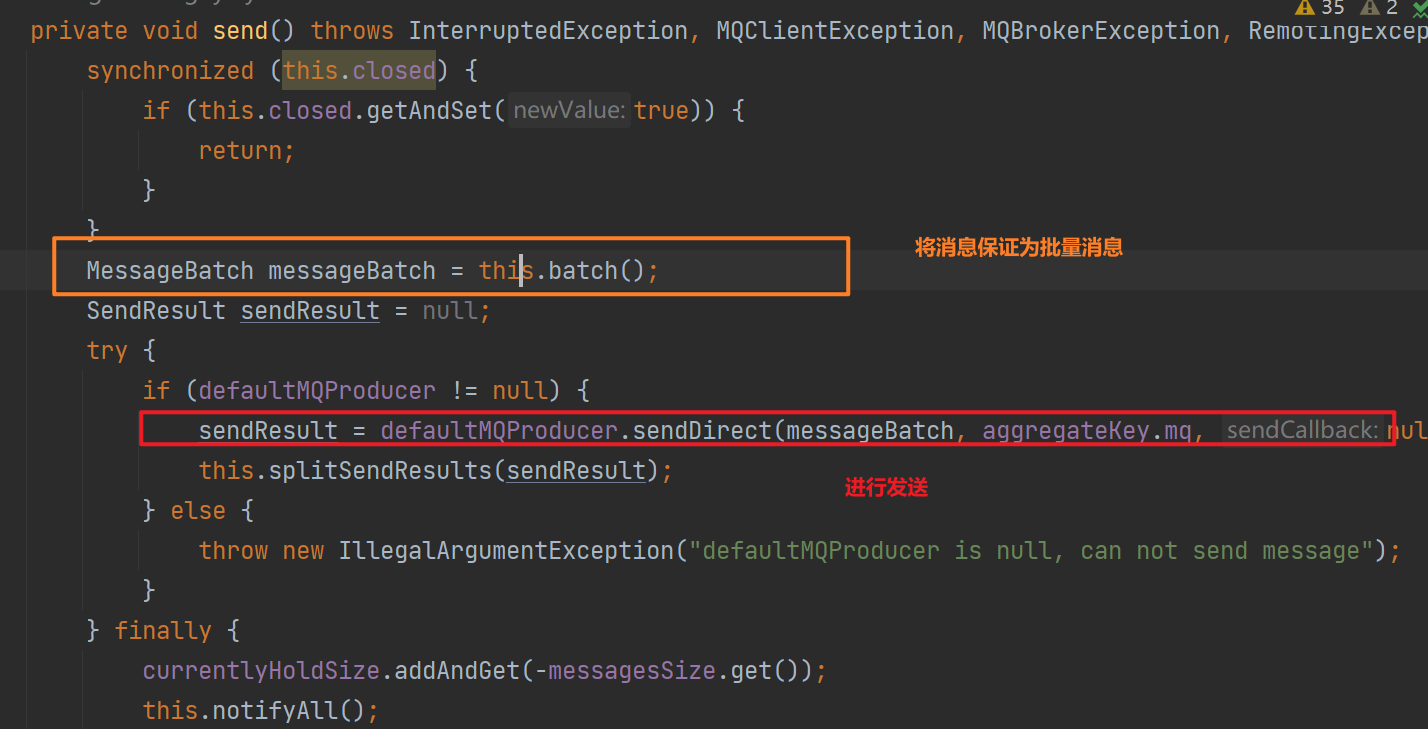
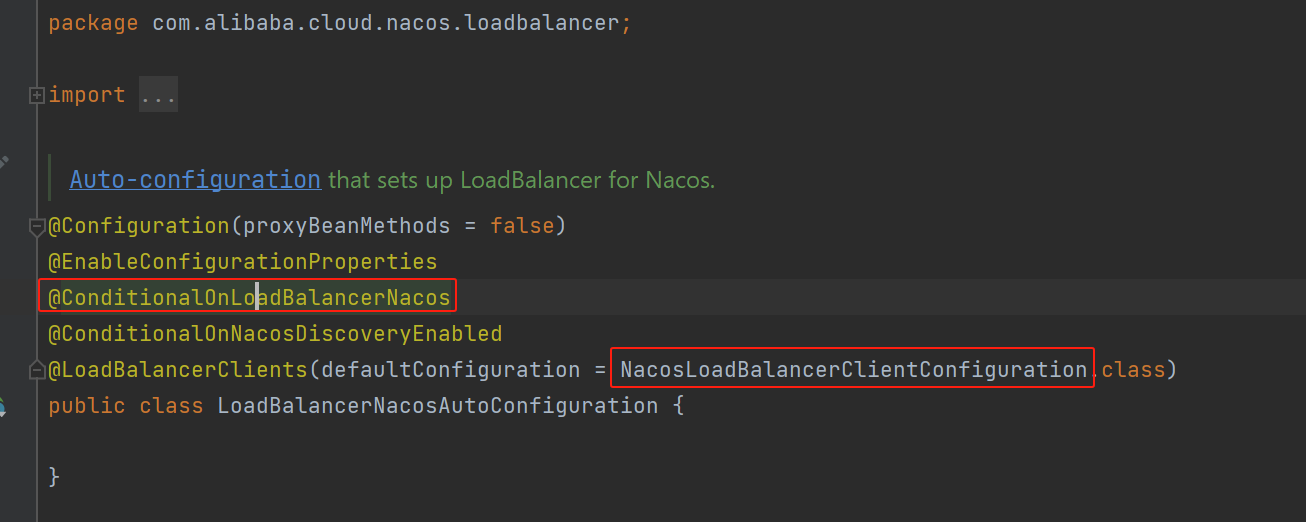
2.sendDirect
DefaultMQProducer消息发送会委托给DefaultMQProducerImpl进行发送,这两个类名称很像但是DefaultMQProducerImpl不是DefaultMQProducer的实现,二者是不同维度的:
- DefaultMQProducer是给调用方使用的,相当于门面
- DefaultMQProducerImpl:实现了MQProducerInner,真正实现消息发送机制
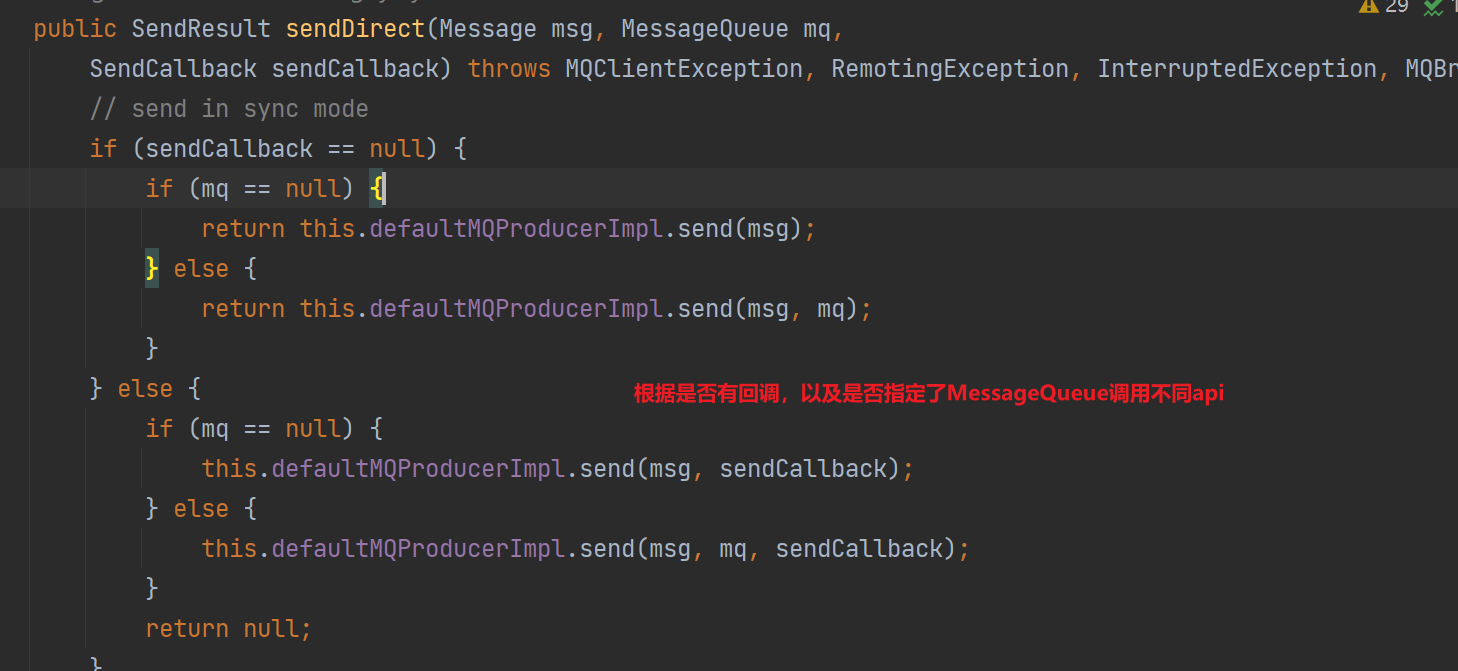
- 指定SendCallback:当异步发送消息的时候,可以实现此接口,实现消息发送成功or失败后的回调
- 指定MessageQueue:MessageQueue是由
Topic
,
broker
,
queueId
组成,一个topic可以分布在多个Broker上(横向扩展),一个broker上可以由多个queue(多个queue并行消费提升吞吐量),因此通过发送消息指定MessageQueue可以实现消息的局部有序(消费者使用
MessageListenerOrderly
单线程进行消费)
下面我们来看看消息发送的具体实现,这部分代码在
DefaultMQProducerImpl#sendDefaultImpl
1.获取路由信息
获取路由信息,即从
生产者向 NameServer 查询特定 Topic 的路由信息。这个路由信息包括了这个 Topic 有哪些 Broker 持有,以及这些 Broker 上各自的 Queue 数据
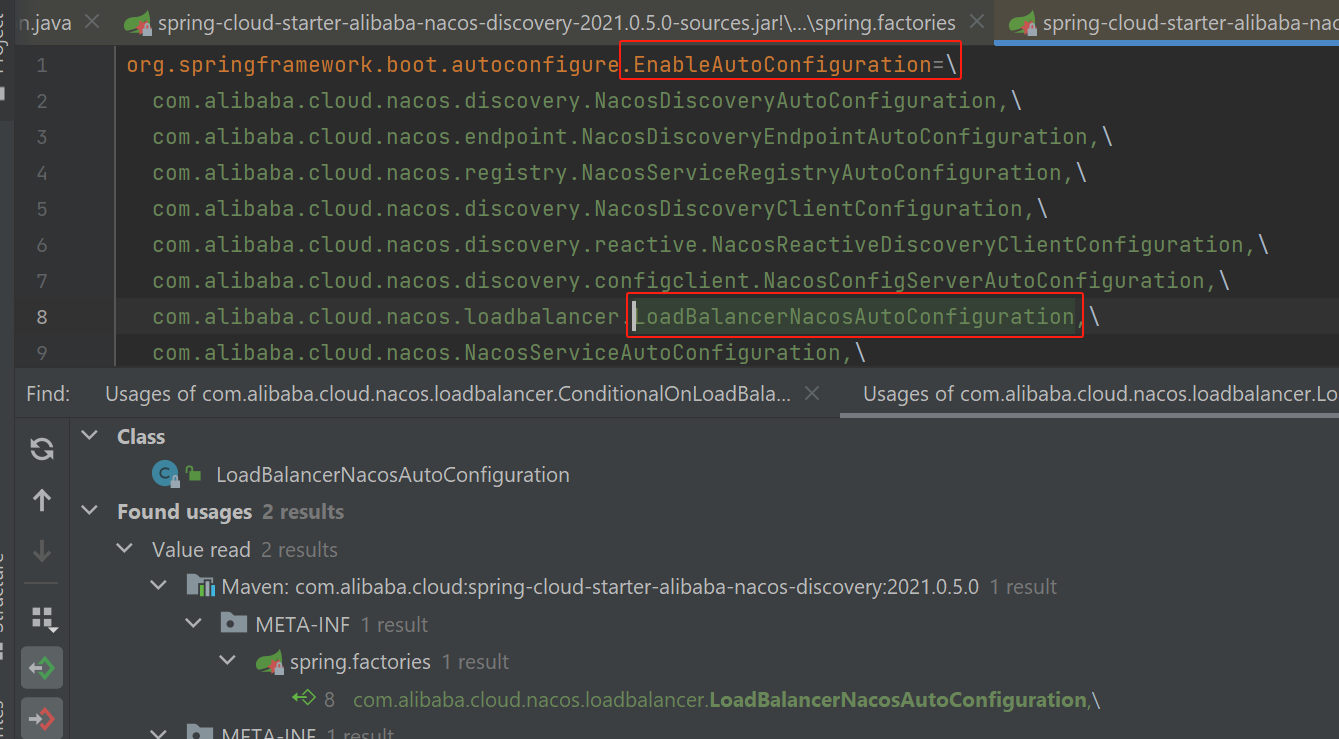
- NameServer 是 RocketMQ 中的一个关键组件,起到了服务注册中心的作用。所有的 Broker 启动时会向所有的 NameServer 注册,包括其 IP 地址、端口、存活状态以及所持有的 Topic 信息。NameServer 会持有整个消息系统的 Broker 服务器列表及其路由信息。
- 当生产者启动时,它会根据配置好的 NameServer 地址列表与 NameServer 集群建立连接。
- 生产者会在本地缓存从 NameServer 获取到的路由信息,以便快速选择目标 Queue 进行消息发送。为了确保路由信息的准确性,生产者会定期(如每隔30秒)或在发送消息时发现路由信息不可用时,重新从 NameServer 更新这些信息,并且生产者发送消息的时候根据本地缓存的路由信息选择一个 Queue 来发送消息。
通过这种方式,RocketMQ 确保生产者能够及时获取和更新路由信息,以及将消息发送到正确的 Broker 和 Queue。这个机制也使得 RocketMQ 能够在 Broker 或队列变化时动态适应,保证消息传输的高可用性和可扩展性。
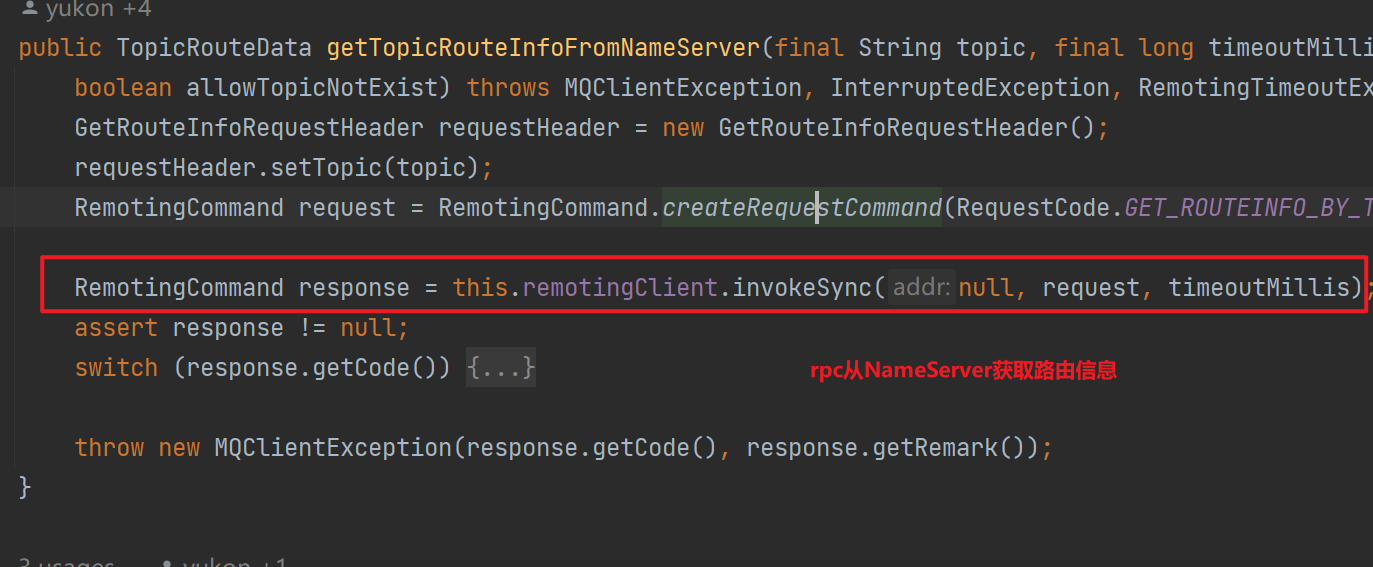
生产者会优先从
ConcurrentMap<String/* topic */, TopicPublishInfo> topicPublishInfoTable
中获取路由,反之使用rpc请求nameServer获取路由信息
另外在生产者启动的时候,会触发MQClientInstance的start,其中会使用juc调度线程池进行路由信息的定期更新(默认30秒一次)。
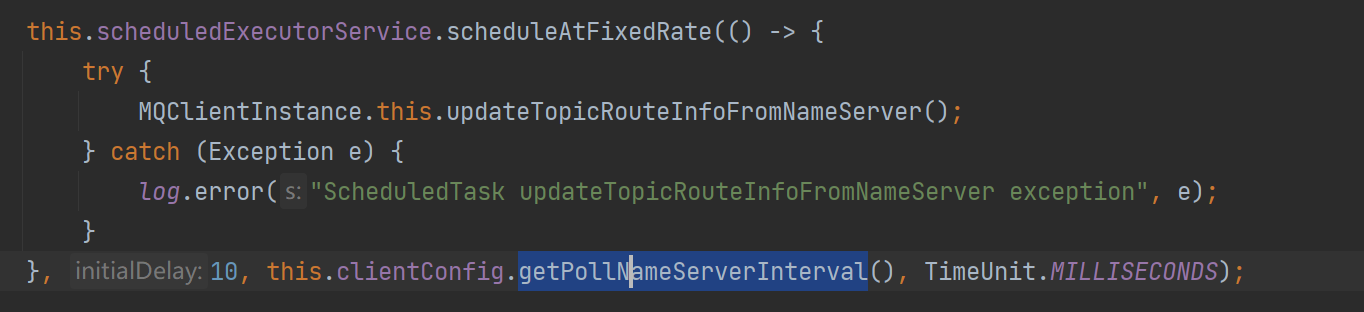
这里居然没有使用长轮询,理论上长轮询相比于这种周期请求有更好的及时性,rocketmq可能是考虑到
- 长轮询的方式需nameServer维护连接状态,而周期轮询对于nameServer负担更小
- 周期请求可以让生产者设置周期频率
- 流量更加均匀:长轮询在路由信息发生变化的时候,nameServer需要立马将变化后的信息发送给hang住的producer,不如周期轮询来得流量均衡。
- 大部分情况下,路由信息不会频繁变化的,定期轮询可满足需要,不像配置中心配置变更是比较频繁的,并且配置中心对于配置变更及时性有比较高的要求。
2.负载均衡的选择一个MessageQueue
如下,如果是同步发送消息,一般会尝试3次,在获取到路由信息后会负载均衡的选择一个MessageQueue进行发送。

RocketMq支持三种选择MessageQueue的方式
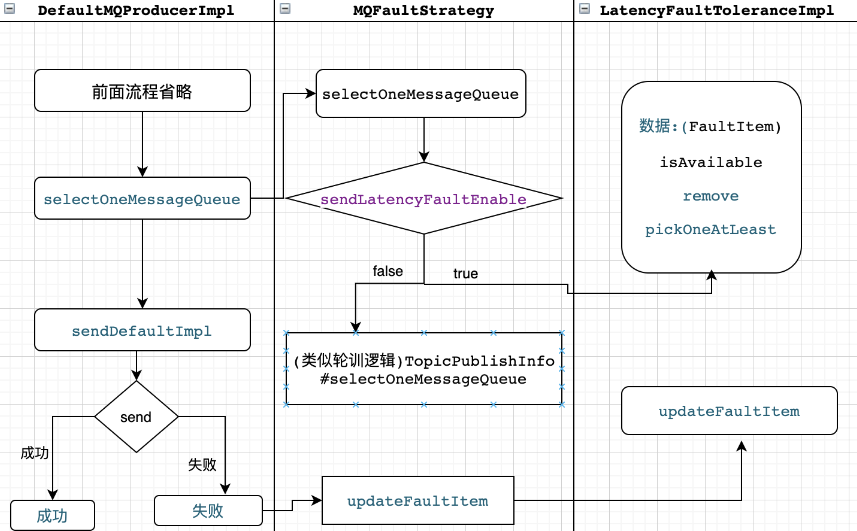
发送消息的时候,传入MessageQueueSelector的实现选择队列;
未开启Broker故障延迟机制(sendLatencyFaultEnable:false),会采用默认轮训机制(默认是此种实现方式)
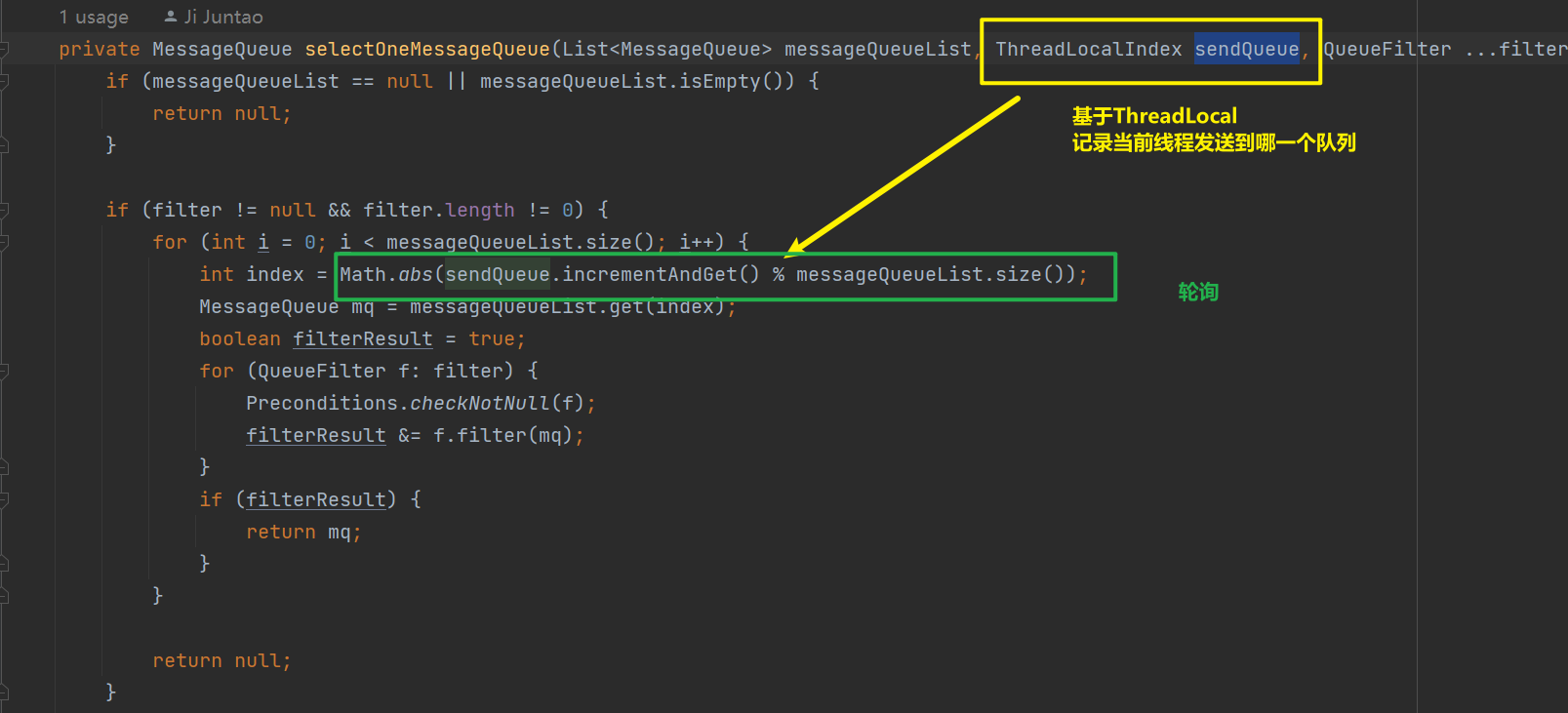
开启Broker故障延迟机制(sendLatencyFaultEnable:true),会根据brokerName的可用性选择队列发送(当需要顺序消息的时候不建议打开,会影响到消息的顺序性)
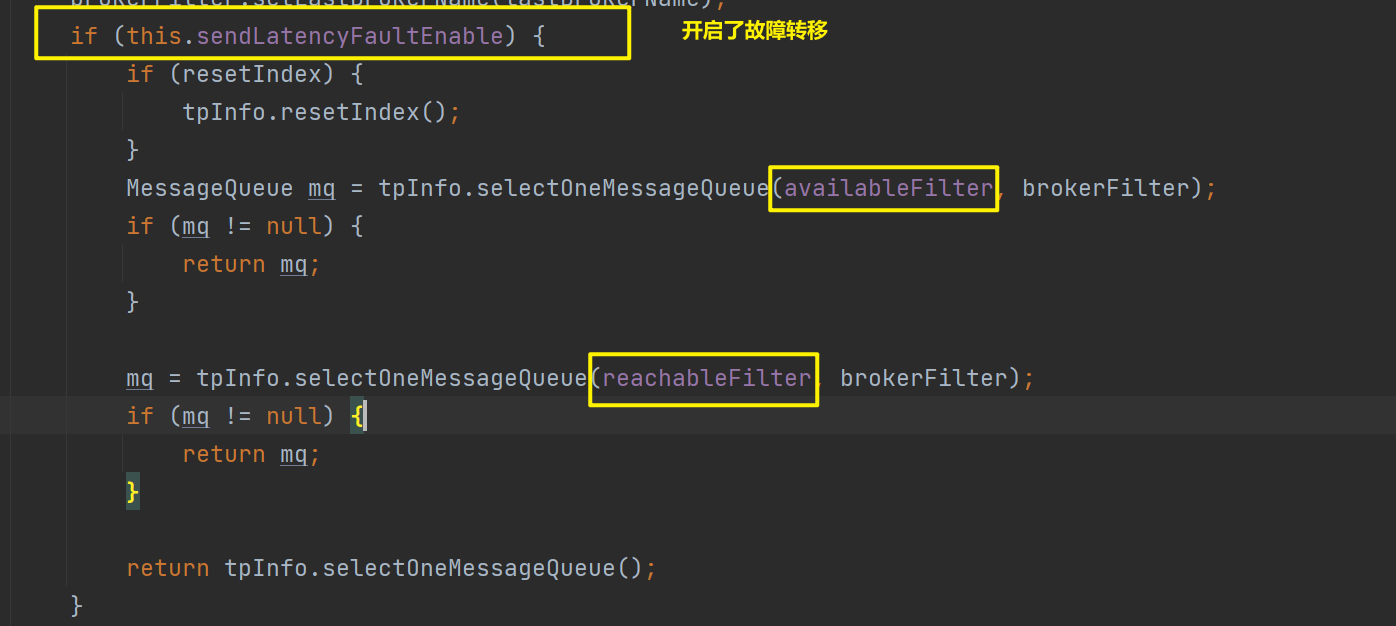
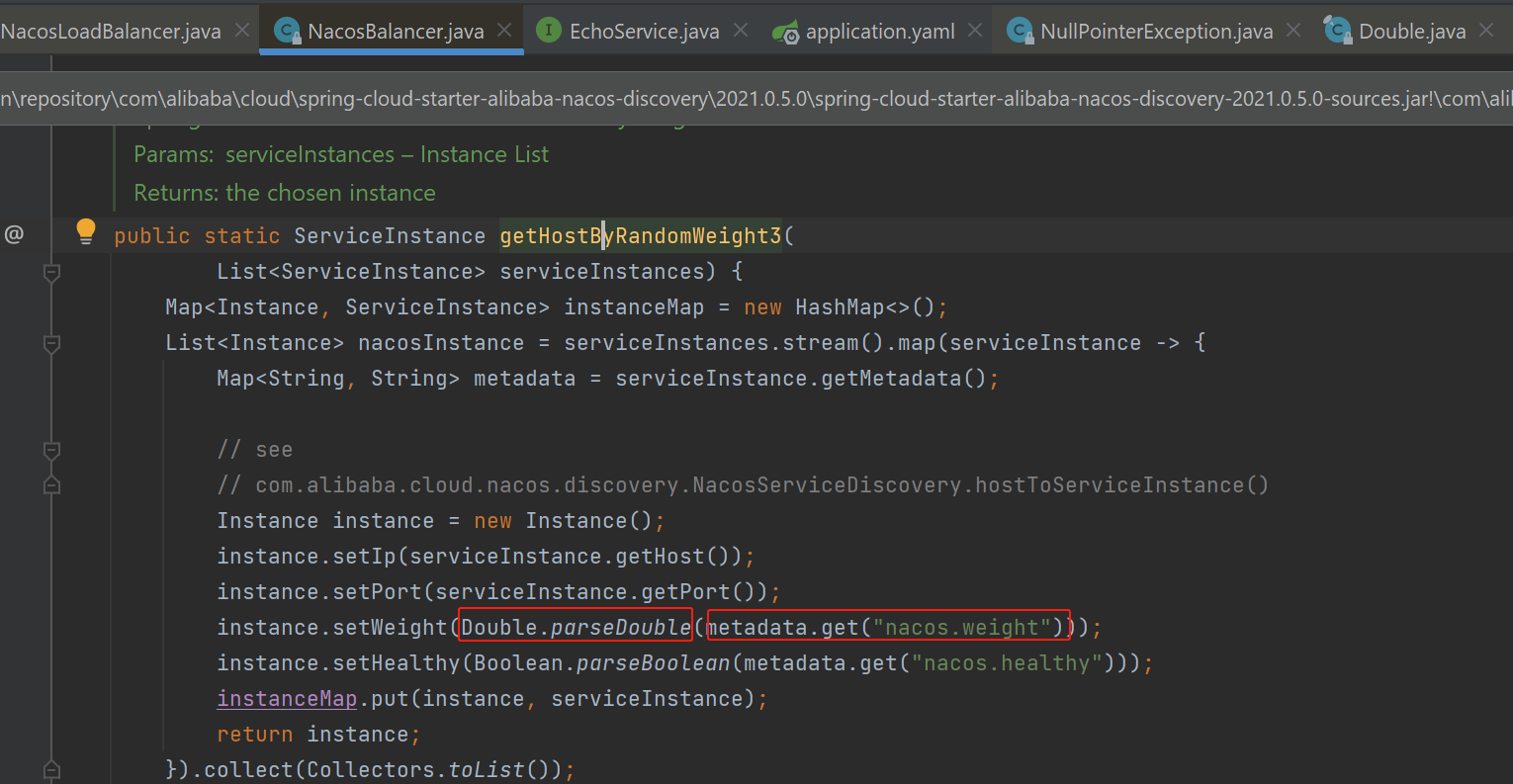
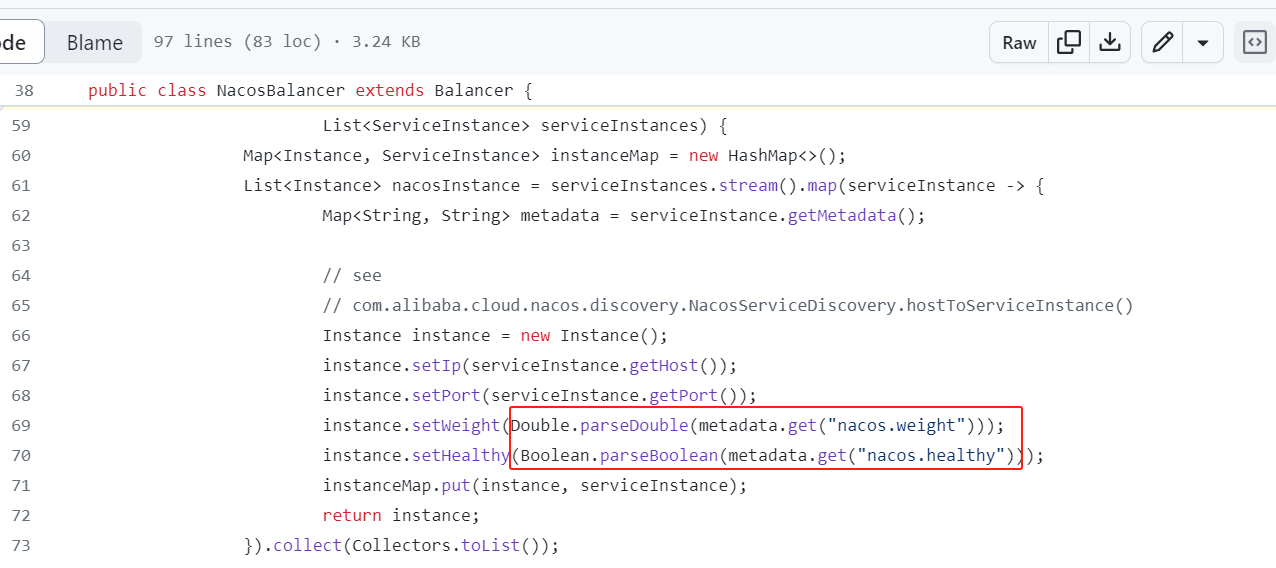
其中是否可用,是否可达,依赖LatencyFaultTolerance进行实现:
LatencyFaultTolerance 实现了一个基于延迟的容错策略。它记录了每个 Broker 的历史网络延迟记录和可用性状态,并根据这些信息智能选择最佳的 Broker 进行消息发送。原理包括以下几个关键点:
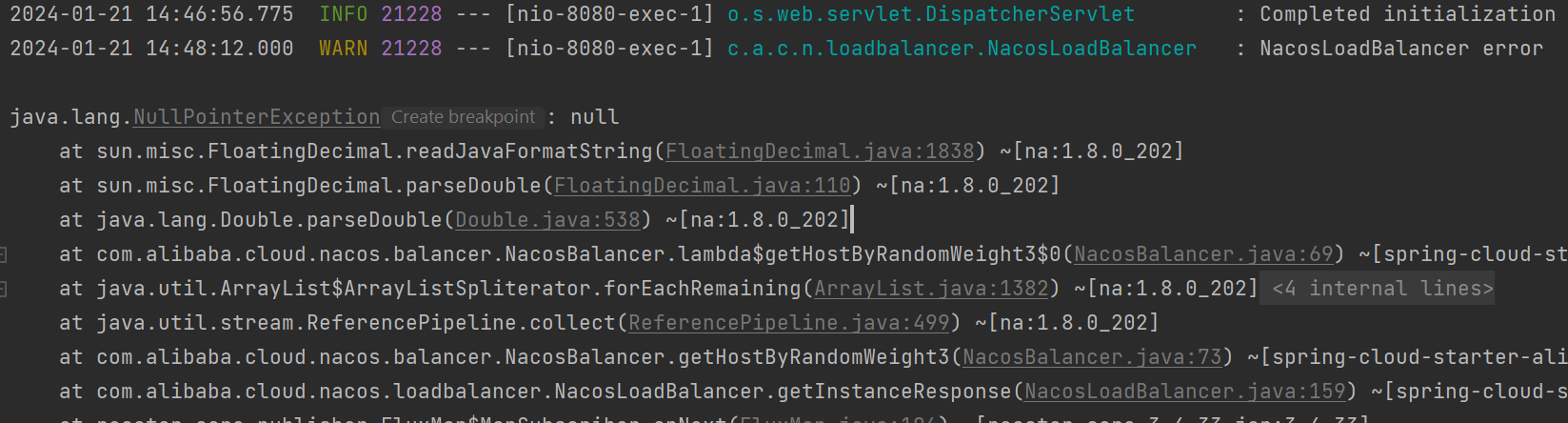
- 延迟记录:每次发送消息时,LatencyFaultTolerance 都会记录下发送操作的延迟时间。如果发送成功,那么这次操作的延迟时间就会被记录下来。
- 故障切换:如果发送消息时发生超时或异常,LatencyFaultTolerance 会将该 Broker 标记为不可用,并计算一个“不可用时长”。在该时长内,Broker 将不会被选中发送消息。
- 动态容错:
LatencyFaultTolerance 会根据之前记录的延迟时间,动态计算每个 Broker 的权重,并选择权重最小(表示网络状态最好)的 Broker 进行消息发送。 - 自动恢复:
被标记为不可用的 Broker 不是永久性的。随着时间的推移,Broker 的状态可以从不可用恢复到可用,这通常是通过“不可用时长”来确定的。一旦超过这个时长,Broker 将重新参与到Broker选择过程中。 - Broker选择:
生产者在发送消息前会从 LatencyFaultTolerance 中获取一个推荐的 Broker。选择过程排除了不可用的 Broker,并考虑了网络延迟和Broker的历史表现。
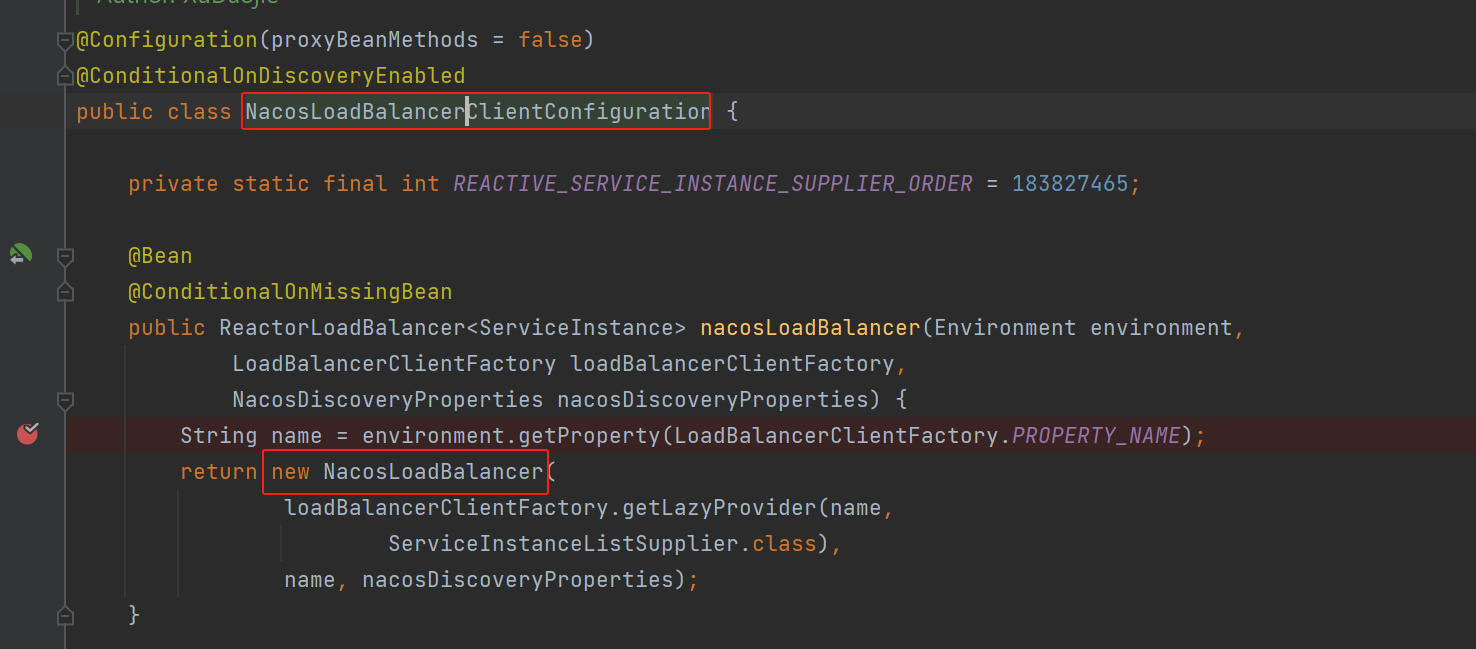
3.消息发送
至此,我们以及选择了一个MessageQueue接下来就是发送消息了。
在发生之前会从路由信息中获取发送的地址,这里只会选择master角色的broker进行发送
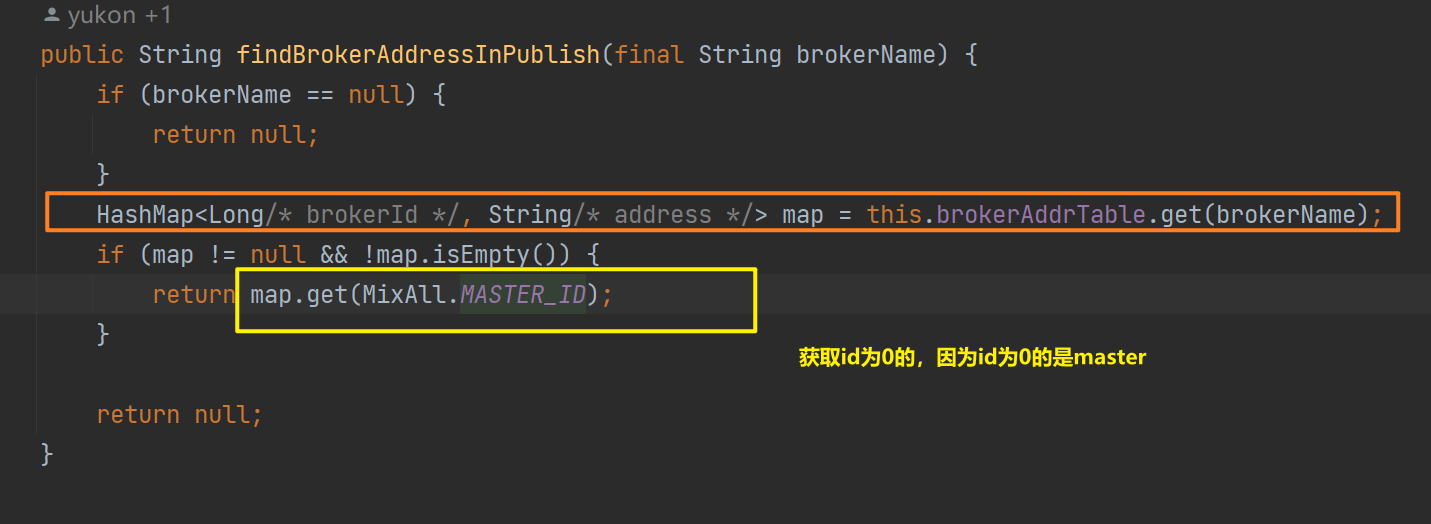
接下来会回调一些扩展性的钩子,如CheckForbiddenHook,SendMessageHook。
然后调用MQClientAPIImpl#sendMessage进行发送,最终调用RemotingClient进行消息发送,RemotingClient是rocketmq对网络通信的实现

无论是单向,还是异步,还是同步,最终都是使用tcp协议进行发送,这里rocketmq使用了netty提供高效的网络通信。源码如下:
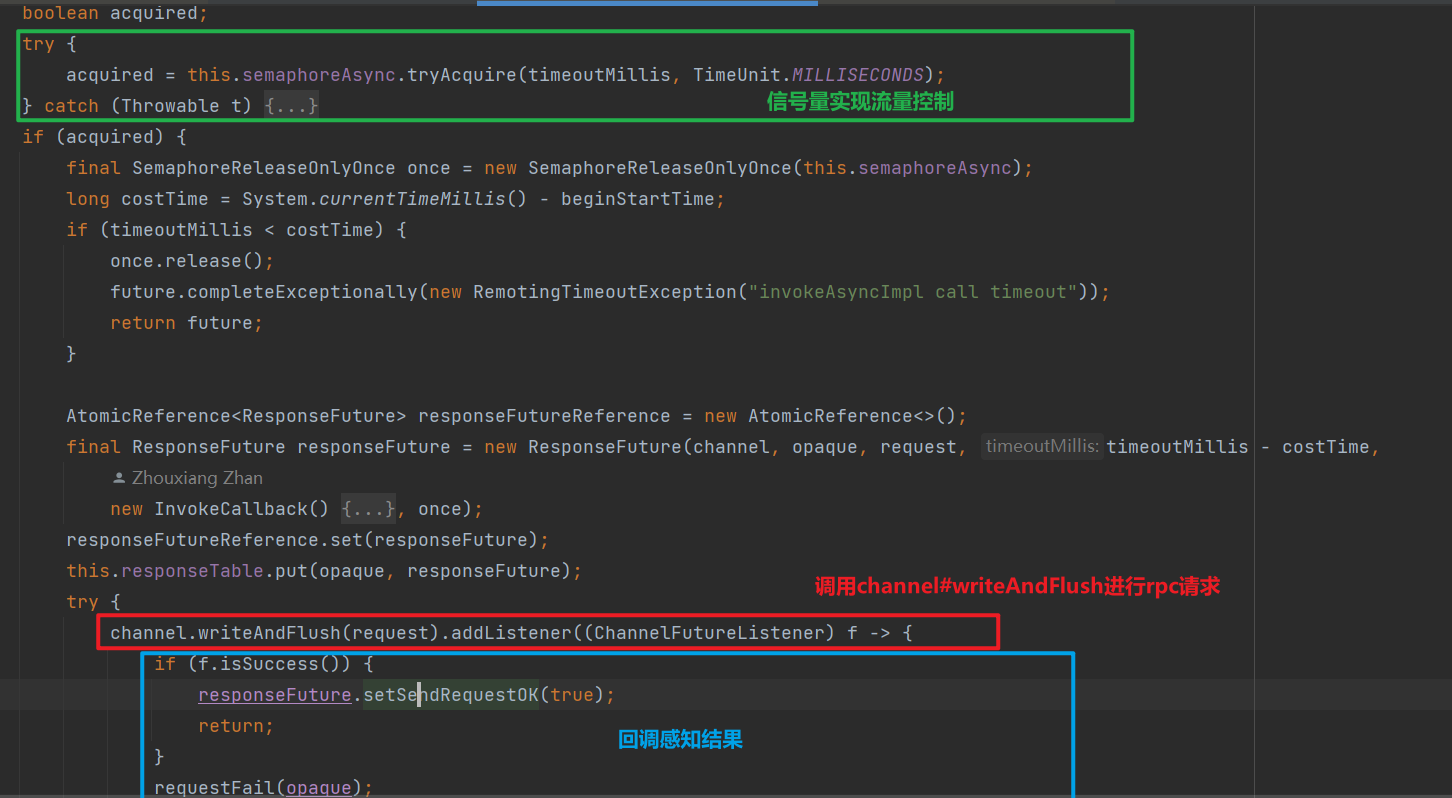
netty的部分,不做过多赘述,详细学习:
Netty源码学习7——netty是如何发送数据的 - Cuzzz - 博客园 (cnblogs.com)
三丶总结
感觉学到了什么,又感觉什么都没学到
- NameServer:实现producor,broker,consumer的解耦合,互相不需要感知彼此的村子,本质是一个注册中心。
- 路由信息使用定期轮询,而不是长轮询
- 长轮询的方式需nameServer维护连接状态,而周期轮询对于nameServer负担更小
- 周期请求可以让生产者设置周期频率
- 流量更加均匀:长轮询在路由信息发生变化的时候,nameServer需要立马将变化后的信息发送给hang住的producer,不如周期轮询来得流量均衡。
- 大部分情况下,路由信息不会频繁变化的,定期轮询可满足需要,不像配置中心配置变更是比较频繁的,并且配置中心对于配置变更及时性有比较高的要求。
- 负载均衡:
- rocketmq的负载均衡,大多实在客户端做的,在消息发送中的体现就是,producer自己实现负载均衡,而不是由一个中心化的网关实现,这样去中心化的设计,利于producer的横向扩展!
- 默认情况下使用轮询,而且使用ThreadLocal记录轮询到的index,一定程度上减少大量消息发送时候的锁竞争
- LatencyFaultTolerance:基于每一次发送消息的统计信息,如果发送消息时发生超时或异常,LatencyFaultTolerance 会将该 Broker 标记为不可用,并计算一个“不可用时长”。在该时长内,Broker 将不会被选中发送消息