用C#实现最小二乘法(用OxyPlot绘图)✨
最小二乘法介绍✨
最小二乘法(Least Squares Method)是一种常见的数学优化技术,广泛应用于数据拟合、回归分析和参数估计等领域。其目标是通过最小化残差平方和来找到一组参数,使得模型预测值与观测值之间的差异最小化。
最小二乘法的原理✨
线性回归模型将因变量 (y) 与至少一个自变量 (x) 之间的关系建立为:
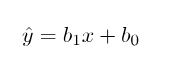
在 OLS 方法中,我们必须选择一个b1和b0的值,以便将 y 的实际值和拟合值之间的差值的平方和最小化。
平方和的公式如下:
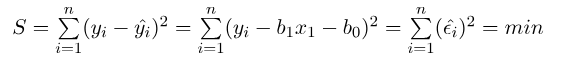
我们可以把它看成是一个关于b1和b0的函数,分别对b1和b0求偏导,然后让偏导等于0,就可以得到最小平方和对应的b1和b0的值。
先说结果,斜率最后推导出来如下所示:
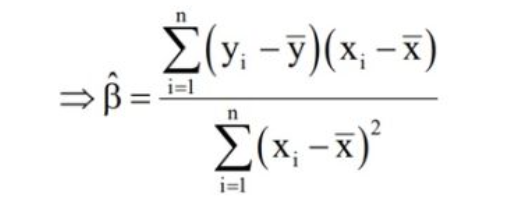
截距推导出来结果如下:
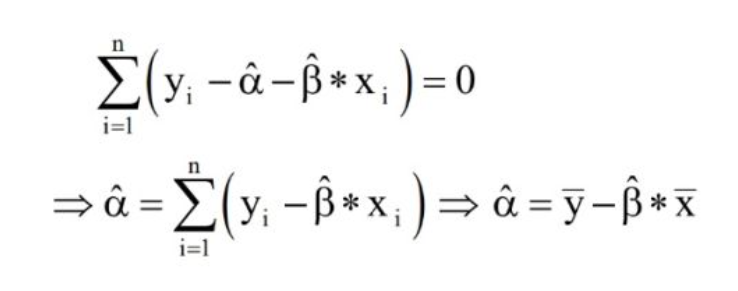
don't worry about that,慢慢推导总是可以弄明白的(不感兴趣可以直接略过):

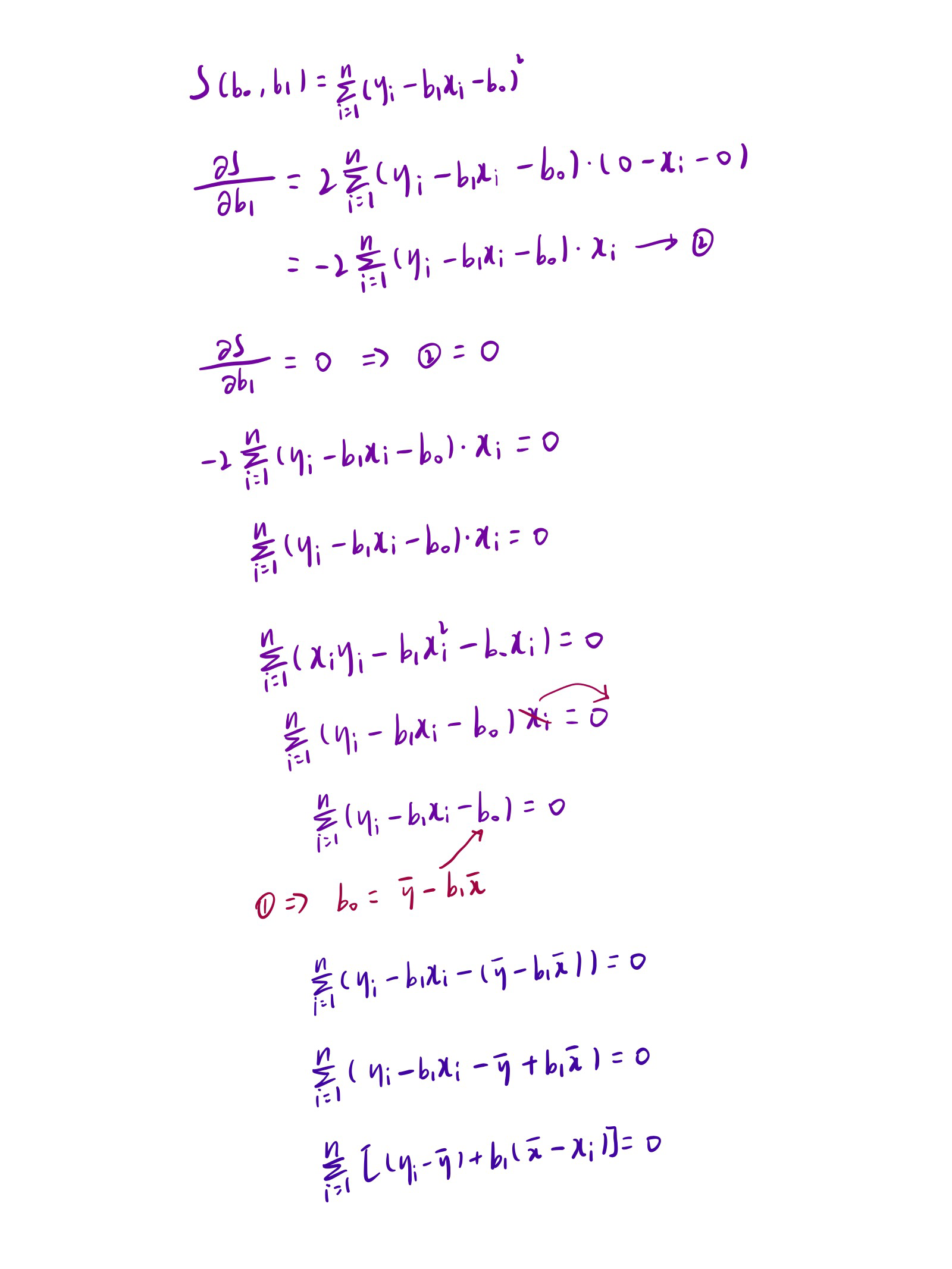
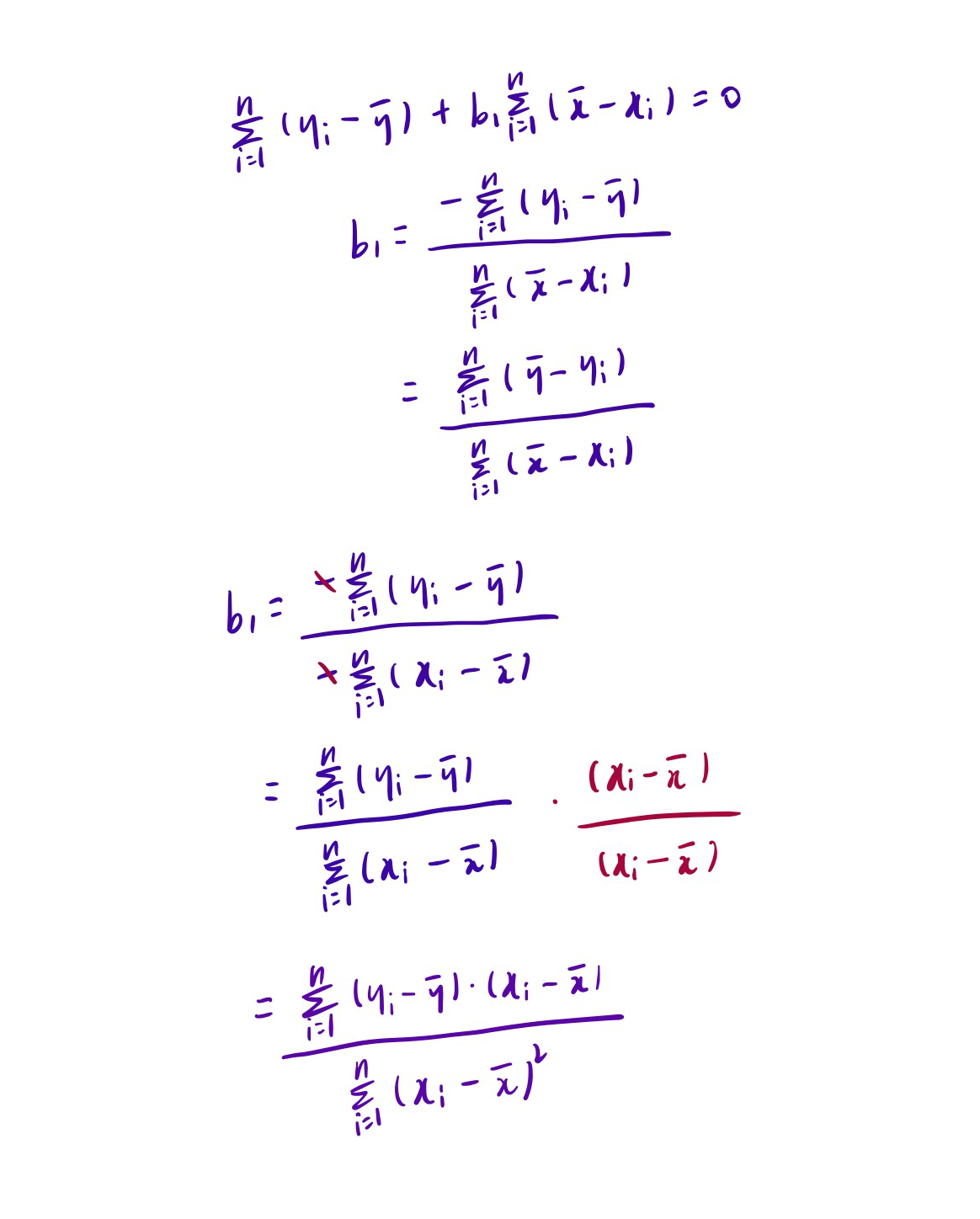
用C#实现最小二乘法✨
创建数据点✨
首先创建想要拟合的数据点:
NDArray? x, y;x,y为全局变量。
//使用NumSharp创建线性回归的数据集
x = np.arange(0, 10, 0.2);
y = 2 * x + 3 + np.random.normal(0, 3, x.size);使用到了NumSharp,需要为项目添加NumSharp包:

x = np.arange(0, 10, 0.2);的意思是x从0增加到10(不包含10),步长为0.2:

np.random.normal(0, 3, x.size);的意思是生成了一个均值为0,标准差为3,数量与x数组长度相同的正态分布随机数数组。这个数组被用作线性回归数据的噪声。
使用OxyPlot画散点图✨
OxyPlot是一个用于在.NET应用程序中创建数据可视化图表的开源图表库。它提供了丰富的功能和灵活性,使开发者能够轻松地在其应用程序中集成各种类型的图表,包括折线图、柱状图、饼图等。

添加OxyPlot.WindowsForms包:

将PlotView控件添加到窗体设计器上:
// 初始化散点图数据
var scatterSeries = new ScatterSeries
{
MarkerType = MarkerType.Circle,
MarkerSize = 5,
MarkerFill = OxyColors.Blue
};表示标志为圆形,标志用蓝色填充,标志的大小为5。
for (int i = 0; i < x.size; i++)
{
scatterSeries.Points.Add(new ScatterPoint(x[i], y[i]));
}添加数据点。
PlotModel? plotModel;将plotModel设置为全局变量。
// 创建 PlotModel
plotModel = new PlotModel()
{
Title = "散点图"
};
plotModel.Series.Add(scatterSeries);
// 将 PlotModel 设置到 PlotView
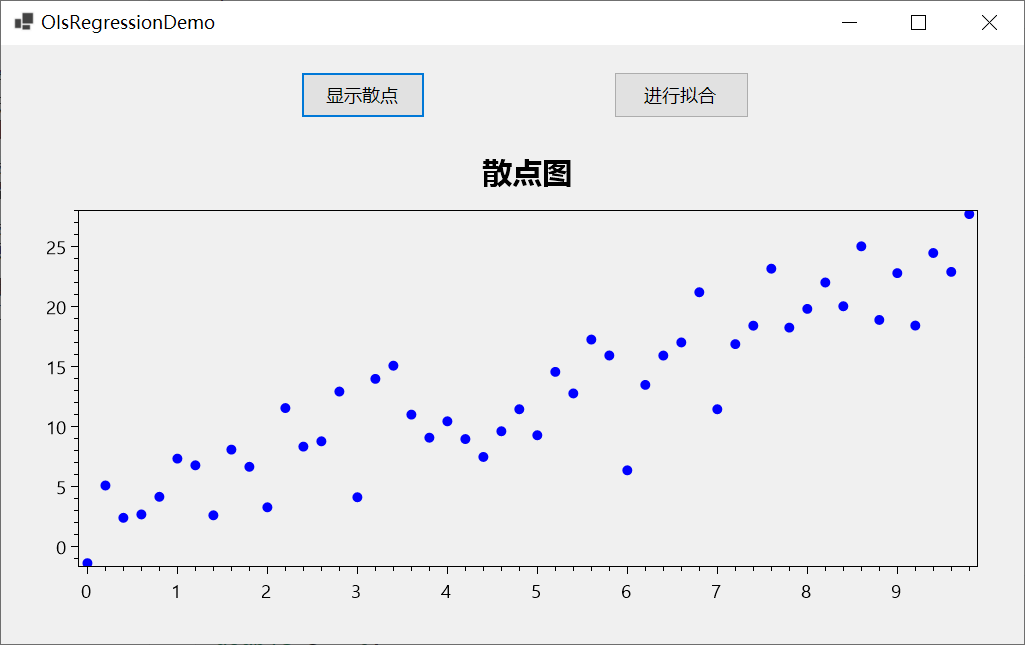
plotView1.Model = plotModel;这样就成功绘制了散点图,效果如下所示:
使用最小二乘法拟合数据点✨
double a = 0;
double c = 0;
double x_mean = x?.mean();
double y_mean = y?.mean();
//计算a和c
for(int i = 0; i < x?.size; i++)
{
a += (x[i] - x_mean) * (y?[i] - y_mean);
c += (x[i] - x_mean) * (x[i] - x_mean);
}
//计算斜率和截距
double m = a / c;
double b = y_mean - m * x_mean;
//拟合的直线
var y2 = m * x + b;套用公式就可以,a表示上面斜率公式的上面那部分,c表示上面斜率公式的下面那部分。
double x_mean = x?.mean();
double y_mean = y?.mean();计算x与y的平均值。
使用OxyPlot画拟合出来的直线✨
//画这条直线
var lineSeries = new LineSeries
{
Points = { new DataPoint(x?[0], y2[0]), new DataPoint(x?[-1], y2[-1]) },
Color = OxyColors.Red
};
// 创建 PlotModel
plotModel?.Series.Add(lineSeries);
// 为图表添加标题
if (plotModel != null)
{
plotModel.Title = $"拟合的直线 y = {m:0.00}x + {b:0.00}";
}
// 刷新 PlotView
plotView1.InvalidatePlot(true);Points = { new DataPoint(x?[0], y2[0]), new DataPoint(x?[-1], y2[-1]) },画直线只要添加两个点就好了
x?[0], y2[0]
表示x和y的第一个点,
x?[-1], y2[-1])
表示x和y的最后一个点,使用了NumSharp的切片语法。
画出来的效果如下所示:
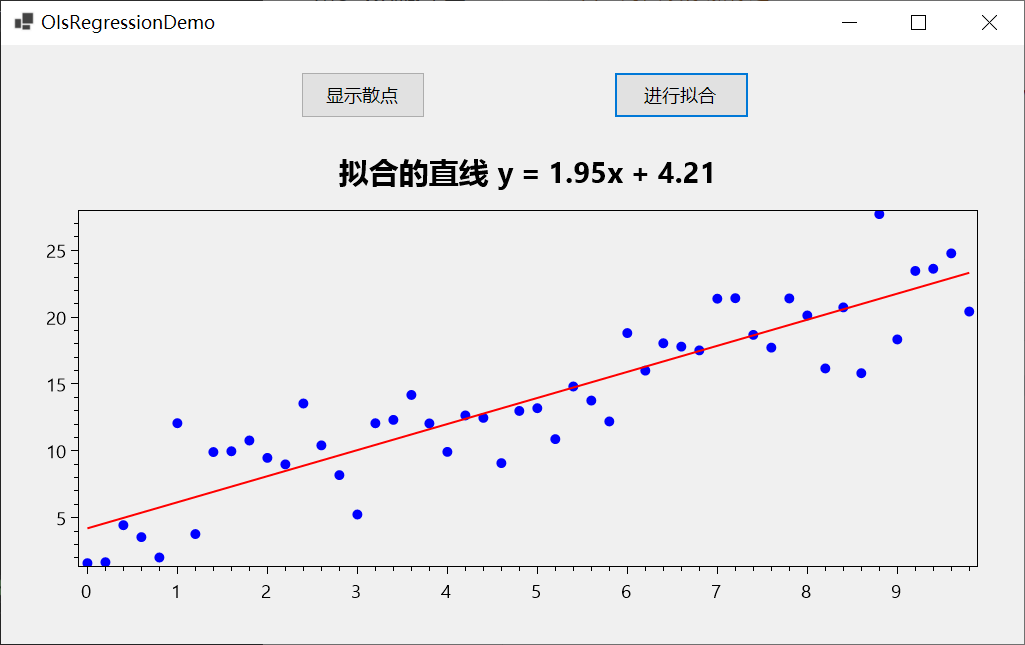
C#实现的全部代码:
using NumSharp;
using OxyPlot.Series;
using OxyPlot;
namespace OlsRegressionDemoUsingWinform
{
public partial class Form1 : Form
{
NDArray? x, y;
PlotModel? plotModel;
public Form1()
{
InitializeComponent();
}
private void button1_Click(object sender, EventArgs e)
{
//使用NumSharp创建线性回归的数据集
x = np.arange(0, 10, 0.2);
y = 2 * x + 3 + np.random.normal(0, 3, x.size);
// 初始化散点图数据
var scatterSeries = new ScatterSeries
{
MarkerType = MarkerType.Circle,
MarkerSize = 5,
MarkerFill = OxyColors.Blue
};
for (int i = 0; i < x.size; i++)
{
scatterSeries.Points.Add(new ScatterPoint(x[i], y[i]));
}
// 创建 PlotModel
plotModel = new PlotModel()
{
Title = "散点图"
};
plotModel.Series.Add(scatterSeries);
// 将 PlotModel 设置到 PlotView
plotView1.Model = plotModel;
}
private void button2_Click(object sender, EventArgs e)
{
double a = 0;
double c = 0;
double x_mean = x?.mean();
double y_mean = y?.mean();
//计算a和c
for(int i = 0; i < x?.size; i++)
{
a += (x[i] - x_mean) * (y?[i] - y_mean);
c += (x[i] - x_mean) * (x[i] - x_mean);
}