2023 是 AI 大爆发的一年,这一年我在我的生产力工具中(
一个叫 lowcode 的 vscode 插件
)接入了 ChatGPT API,插件也进行了重构,日常搬砖也因为 ChatGPT 的引入发生了很大的变化。
在介绍 ChatGPT 是如何与
lowcode
插件结合之前,先说说
lowcode
插件的发展历史,毕竟从 2020 年第一个版本发布到现在也迭代 3 年多了。
介绍
轮子的产生
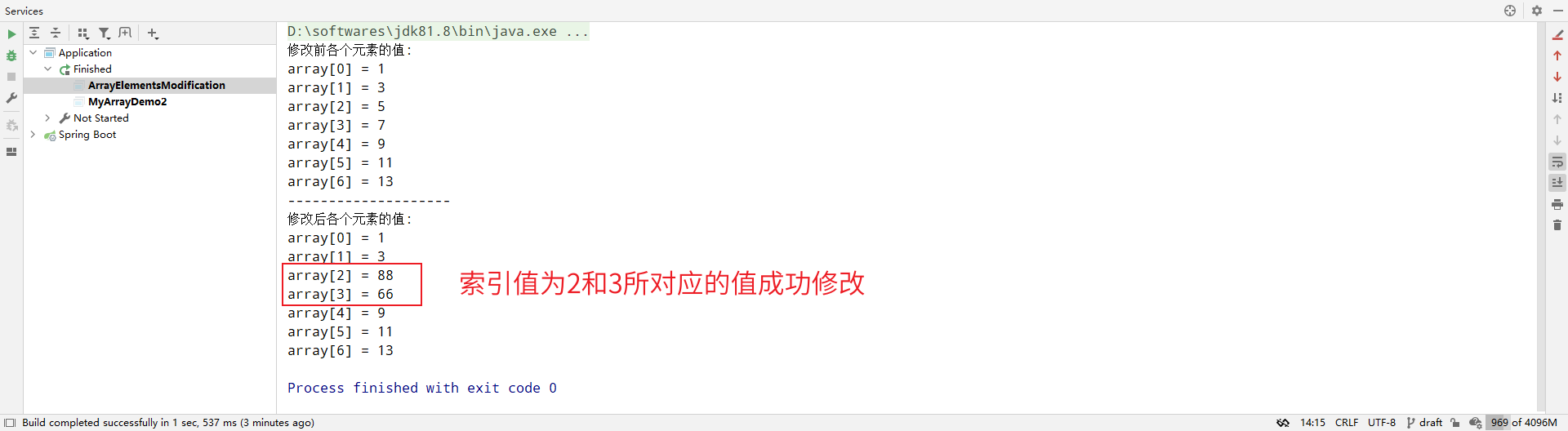
一开始写这么个插件的目的为了拉取 YAPI 接口文档信息生成前端 API 请求方法,如下
export interface IFetchUserListResult {
code: number;
msg: string;
result: {
rows: {
name: string;
age: number;
mobile: string;
address: string;
tags: string[];
id: number;
}[];
total: number;
};
}
export interface IFetchUserListParams {
name?: string;
page: number;
size: number;
}
/**
* 用户列表
* http://yapi.smart-xwork.cn/project/129987/interface/api/1796953
* @author 划水摸鱼糊屎工程师
*
* @param {IFetchUserListParams} params
* @returns
*/
export function fetchUserList(params: IFetchUserListParams) {
return request<IFetchUserListResult>(`${env.API_HOST}/api/user/page`, {
method: 'GET',
params,
});
}
之后增加了根据 JSON 生成 API 请求、根据 JSON 生成 TS 类型等功能。
物料的概念
再之后就是引入了物料的概念:代码片段和区块。上面说的根据 YAPI 接口信息生成 API 请求方法、根据 JSON 生成 API 请求、根据 JSON 生成 TS 类型都属于代码片段,只在当前激活的文件里生成代码。而区块就是在多个文件里生成代码(或者说创建多个文件)。
代码片段
代码片段可以通过右键菜单、输入提示、可视化界面进行使用,区块只能通过可视化界面使用。
右键菜单
输入提示
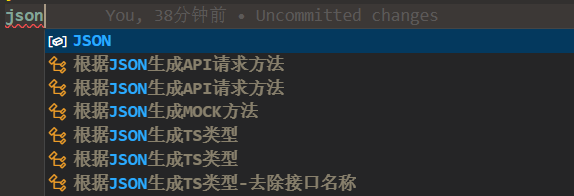
输入提示类似 vscode 自带的代码片段功能,同时兼容 vscode 代码片段的语法
可视化界面
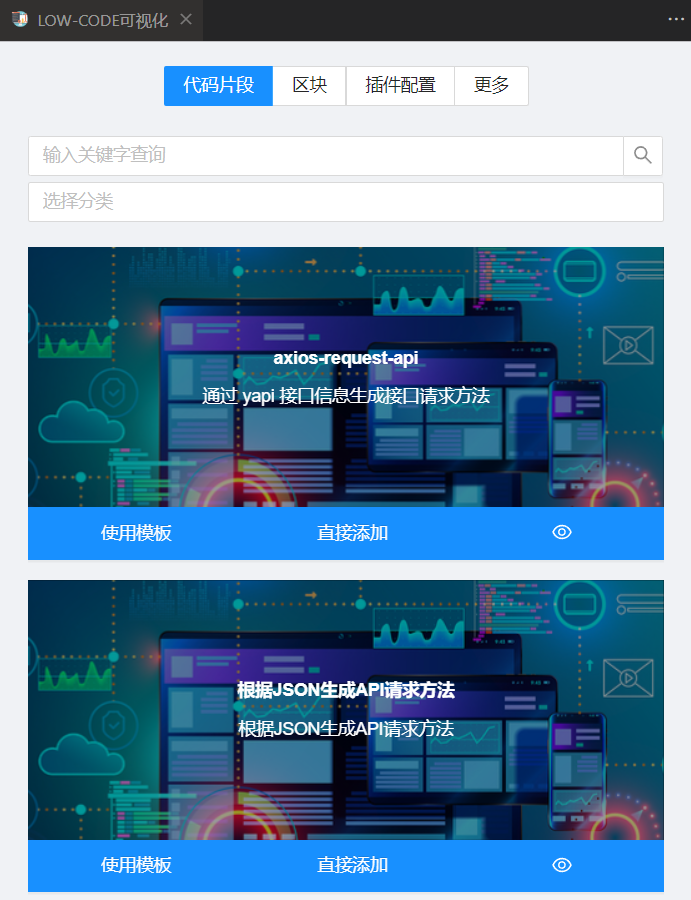
代码片段可视化的功能目前我也很少用到(可以不用,但不能没有)
区块
前面也说了,区块是为了在多个文件里生成代码(或者创建多个文件)。比如写一个 react 组件的时候,可能包含 js 文件和 css 文件。
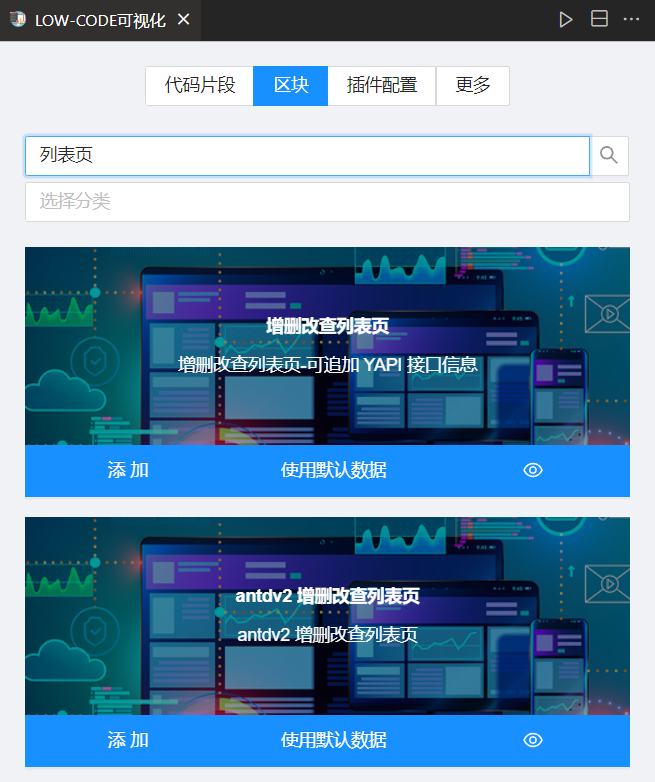
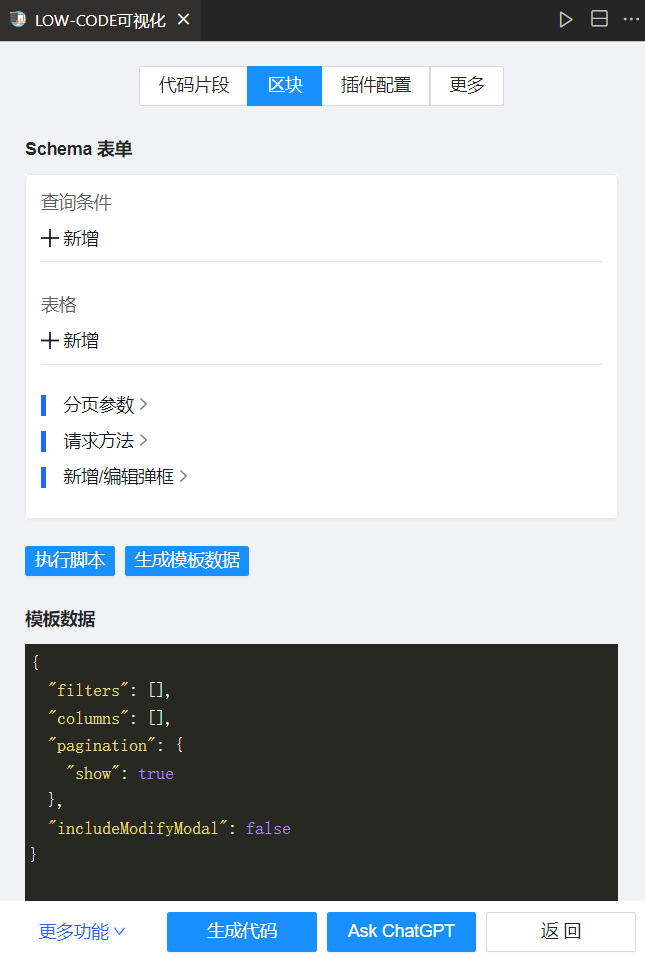
不同区块的 Schema 表单不一样,产生不一样的模板数据,就可以达到模板数据 + 模板生成代码的目的。
内部细节
插件读取项目根目录下的 materials/blocks 作为区块,读取 materials/snippets 作为代码片段。
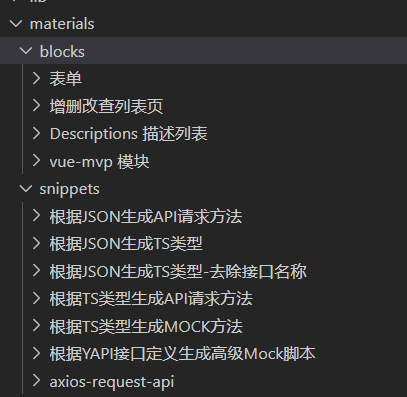
目前已经支持配置任意目录,在所有项目中共享物料
代码片段和区块目录内的内容如下
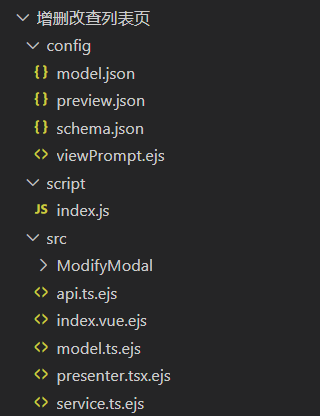
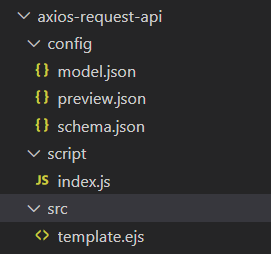
主要是 src 目录内的内容存在差异,代码片段的 src 目录内必须是 template.ejs 文件,区块的 src 目录内可以是任意内容。生成代码的时候,使用 ejs 模板引擎编译 ejs 文件。代码片段是将编译以后的内容插入到编辑器光标所在的位置,区块是将编译后的文件拷贝到指定的目录里(非 ejs 文件直接拷贝)。
model.json
默认模板数据
preview.json
物料相关配置
{
"title": "",
"description": "",
"img": [
"https://gitee.com/img-host/img-host/raw/master/2020/11/05/1604587962875.jpg"
],
"category": [],
"notShowInCommand": true,
"notShowInSnippetsList": true,
"notShowInintellisense": true,
"showInRunSnippetScript": true,
"schema": "amis",
"scripts": []
}
schema.json
可视化界面 Schema 表单配置,支持 form-render、formily、amis。
script/index.js
模板编译周期钩子函数
module.exports = {
beforeCompile: context => {
console.log(context)
},
afterCompile: context => {
console.log(context)
},
complete: context => {
console.log(context)
},
}
重构之后会利用这个文件做更多有趣的事
缺陷
右键菜单使用代码片段的适用范围有限
export const generateCode = (context: vscode.ExtensionContext) => {
context.subscriptions.push(
vscode.commands.registerTextEditorCommand(
'lowcode.generateCode',
async () => {
const rawClipboardText = getClipboardText();
let clipboardText = rawClipboardText.trim();
clipboardText = JSON.stringify(jsonParse(clipboardText));
const validYapiId = isYapiId(clipboardText);
const validJson = jsonIsValid(clipboardText);
const valid = validJson || validYapiId;
if (valid) {
if (validYapiId) {
await genCodeByYapi(clipboardText, rawClipboardText);
} else {
await genCodeByJson(clipboardText, rawClipboardText);
}
return;
}
try {
await genCodeByTypescript(rawClipboardText, rawClipboardText);
} catch {
window.showErrorMessage('请复制Yapi接口ID或JSON字符串或TS类型');
}
},
),
);
};
代码里写死了逻辑,只能处理 json 、ts 类型、YAPI 接口。
与 ChatGPT 的结合
引入 ChatGPT 的最初目的是为了翻译区块 Schema 表单对应的模板数据里的指定字段。
翻译物料模板数据指定字段
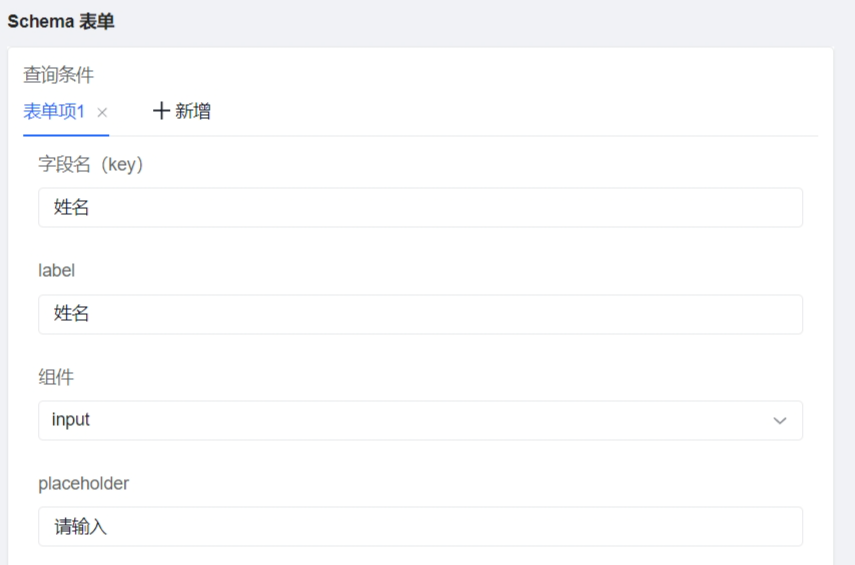
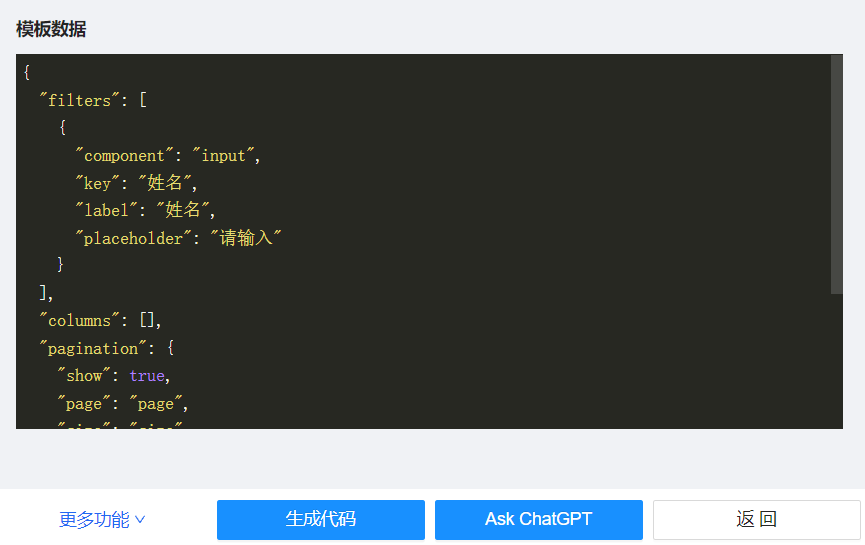
点击 Ask ChatGPT 就会打开 ChatGPT 的 WebView 界面,并自动发送预设的 Prompt。
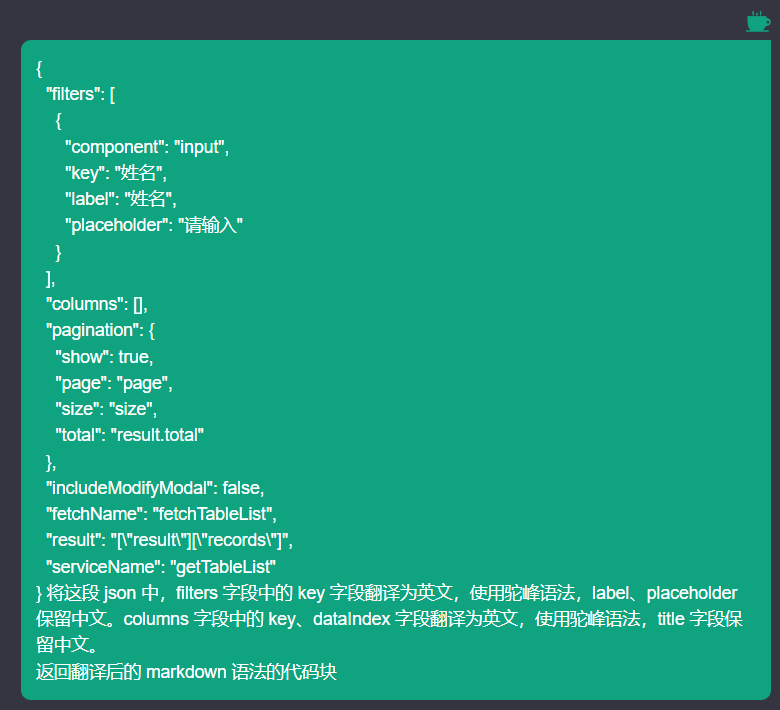
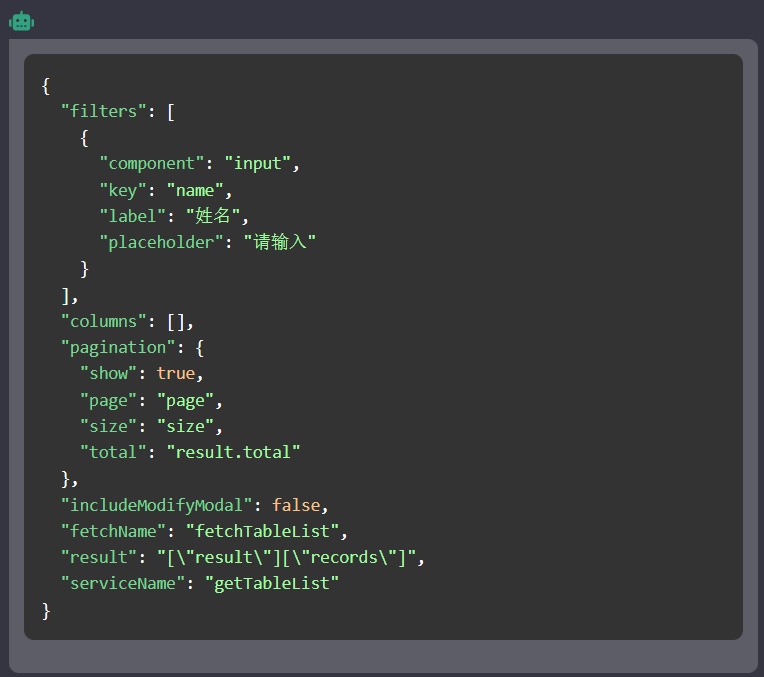
预设的 Prompt 就是放在 viewPrompt.ejs 中
内容如下:
<%- model %> 将这段 json 中,filters 字段中的 key 字段翻译为英文,使用驼峰语法,label、placeholder
保留中文。columns 字段中的 key、dataIndex 字段翻译为英文,使用驼峰语法,title 字段保留中文。
返回翻译后的 markdown 语法的代码块
这种方式和 ChatGPT 交流会有各种玄学问题,比如翻译的字段不对或者所有的字段都翻译了,也可能是我写的 Prompt 有问题,这个功能也几乎不用了,后面会介绍另一种方式。
代码片段当作 Prompt 管理工具
看过几个 vscode 里 ChatGPT 的插件,大都是写死几个菜单,比如解释一段代码的意思、重构一段代码、给代码添加单元测试,说实话,有点 low low 的。
我是加了两个菜单:Ask ChatGPT、Ask ChatGPT With Template
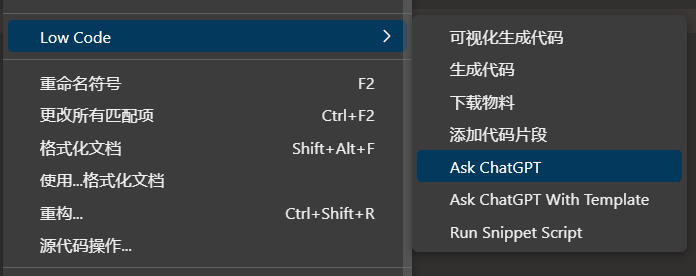
Ask ChatGPT
逻辑很简单,直接把当前选中的代码或者剪贴板里的内容原封不动的发给 ChatGPT。
vscode.commands.registerCommand('lowcode.askChatGPT', () => {
showChatGPTView({
task: {
task: 'askChatGPT',
data: getSelectedText() || getClipboardText(),
},
});
}),
其实这个菜单完全可以去掉,用 Ask ChatGPT With Template 也能实现
Ask ChatGPT With Template
顾名思义就是根据不同的场景使用不同的 Prompt 模版去问 ChatGPT。
只需要在代码片段的目录下添加 commandPrompt.ejs 文件即可
内容可能如下
下面我让你来充当翻译家,你的目标是把中文翻译成英文单词,请翻译时使用驼峰格式,小写字母开头,不要带翻译腔,而是要翻译得自然、流畅和地道,使用优美和高雅的表达方式。
请翻译下面的内容:“<%- rawSelectedText || rawClipboardText %>”
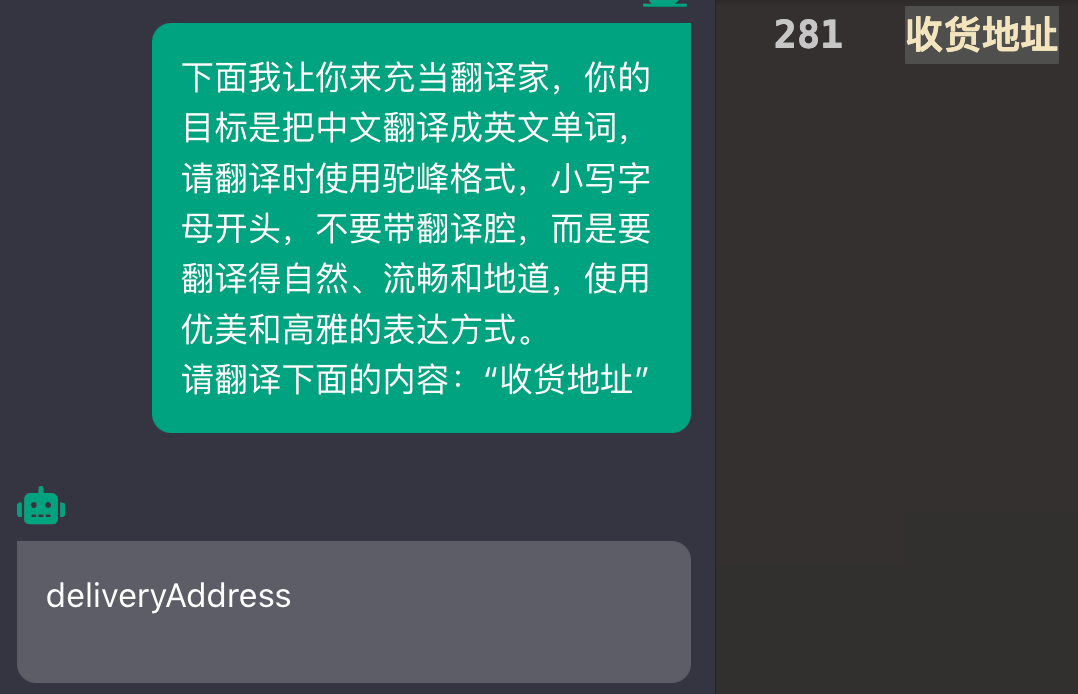
重构、优化
之前提到过右键菜单使用代码片段的适用范围有限,只能处理 json 、ts 类型、YAPI 接口。接入 ChatGPT 后,又加了两个菜单。如果之后要加什么新功能还得接着加菜单,那就太 low 了。
虽然引入了 ChatGPT,但是 ChatGPT 的交互页面是独立的,ChatGPT 返回结果后还需要手动复制,我这种懒人是无法接受的。
webview 界面调用 nodejs 脚本
可视化界面配置表单还是挺费时的,而且原来的 Ask ChatGPT 的功能也比较玄学。加了一个“执行脚本”的按钮,可以实现调用物料目录下 src/index.js 文件内指定方法。
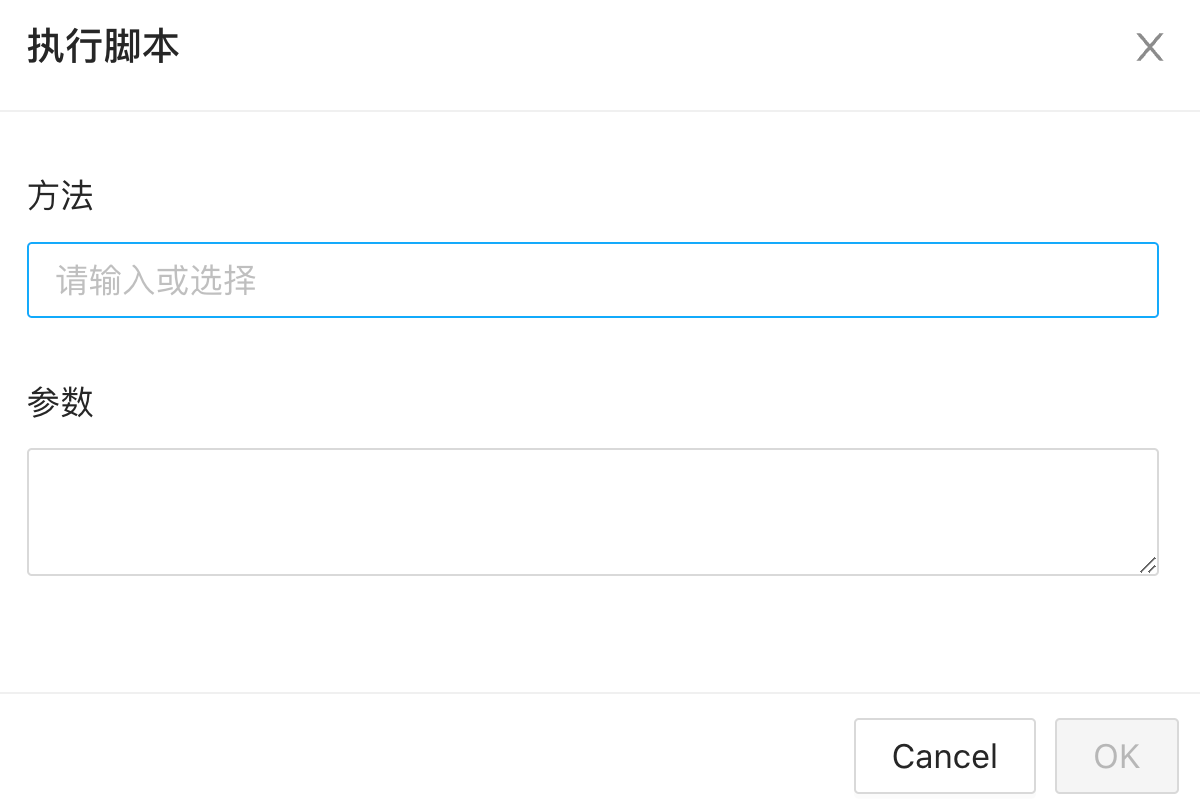
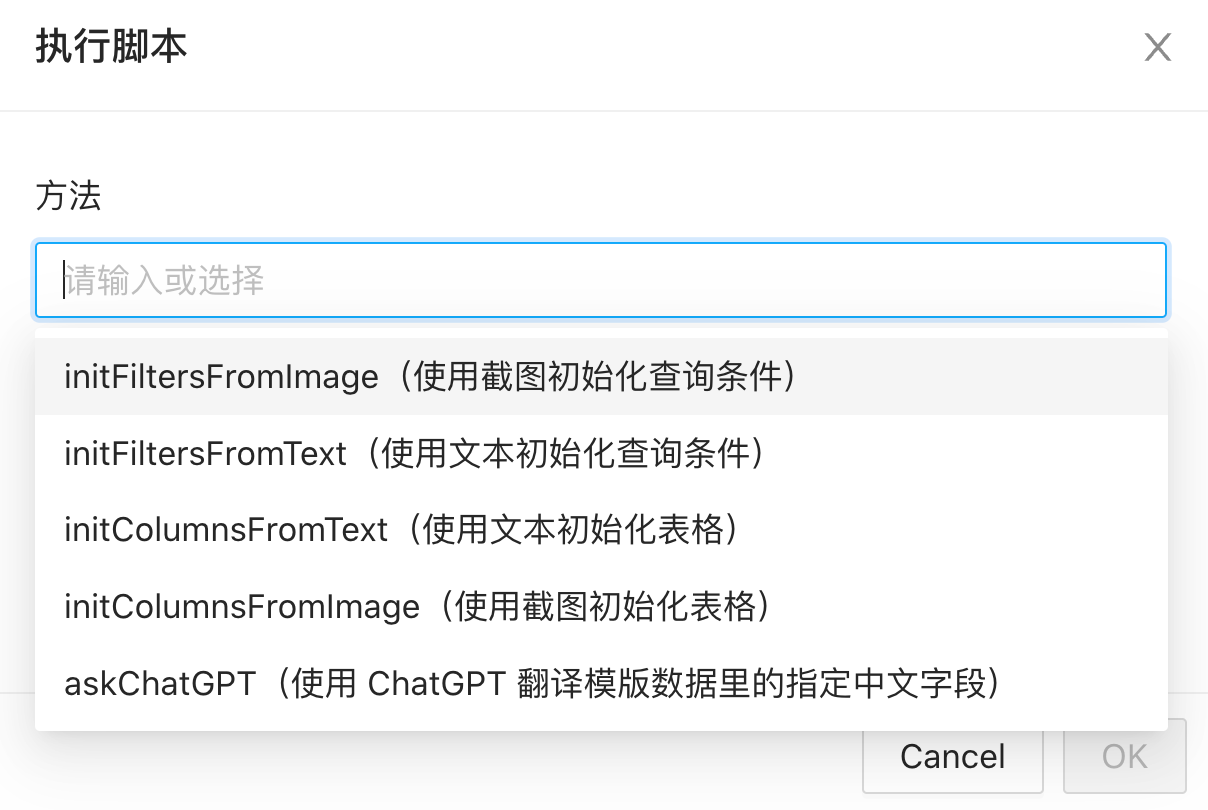
在使用 ChatGPT 进行翻译的时候,使用了 TypeChat(关于 TypeChat 可以看
TypeChat、JSONSchemaChat实战 - 让ChatGPT更听你的话
),但是并不需要在插件内部引入 TypeChat。如下
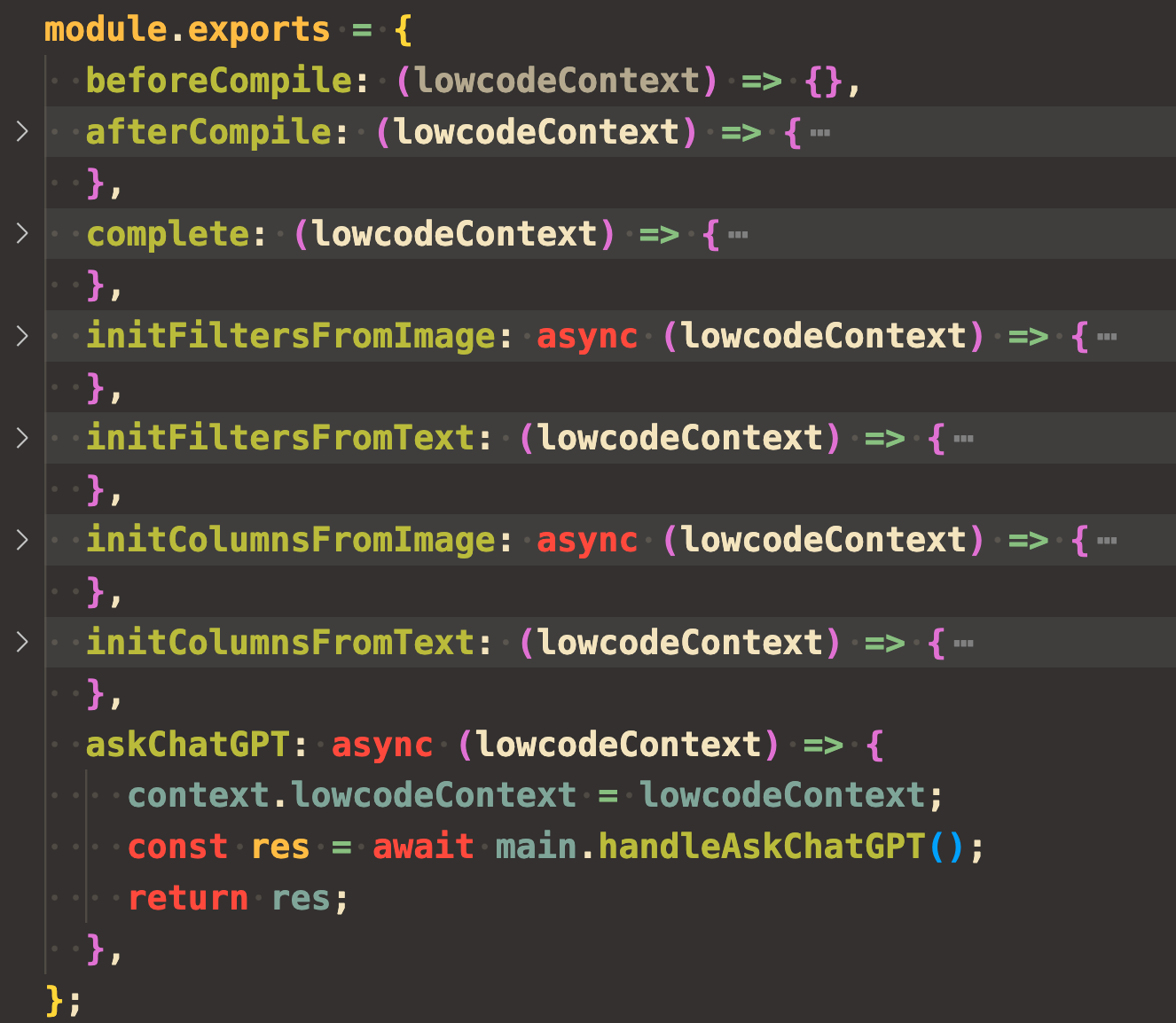
export async function handleAskChatGPT() {
const { lowcodeContext } = context;
const schema = fs.readFileSync(
path.join(lowcodeContext!.materialPath, 'config/schema.ts'),
'utf8',
);
const typeName = 'PageConfig';
const res = await translate<PageConfig>({
schema,
typeName,
request: JSON.stringify(lowcodeContext!.model as PageConfig),
completePrompt:
`你是一个根据以下 TypeScript 类型定义将用户请求转换为 "${typeName}" 类型的 JSON 对象的服务,并且按照字段的注释进行处理:\n` +
`\`\`\`\n${schema}\`\`\`\n` +
`以下是用户请求:\n` +
`"""\n${JSON.stringify(lowcodeContext!.model as PageConfig)}\n"""\n` +
`The following is the user request translated into a JSON object with 2 spaces of indentation and no properties with the value undefined:\n`,
createChatCompletion: lowcodeContext!.createChatCompletion,
showWebview: true,
extendValidate: (jsonObject) => ({ success: true, data: jsonObject }),
});
lowcodeContext!.outputChannel.appendLine(JSON.stringify(res, null, 2));
if (res.success) {
return { ...res.data };
}
return lowcodeContext!.model;
}
脚本方法执行完后将模版数据(model)返回,省去手动复制。
可以像写业务代码一样,根据自己需要添加各种处理方法,尝试各种新的技术。
如果 schema 表单用的是 amis,还可以在 schema 中配置执行脚本,比如:
{
"type": "button",
"label": "插入// lowcode-model-import-api",
"onEvent": {
"click": {
"actions": [{
"actionType": "runScript",
"args": {
"method": "insertPlaceholder",
"params": "// lowcode-model-import-api"
}
}]
}
}
}
点击按钮的时候,会调用
insertPlaceholder
方法,参数为
// lowcode-model-import-api
Run Snippet Script
添加了
Run Snippet Script
菜单
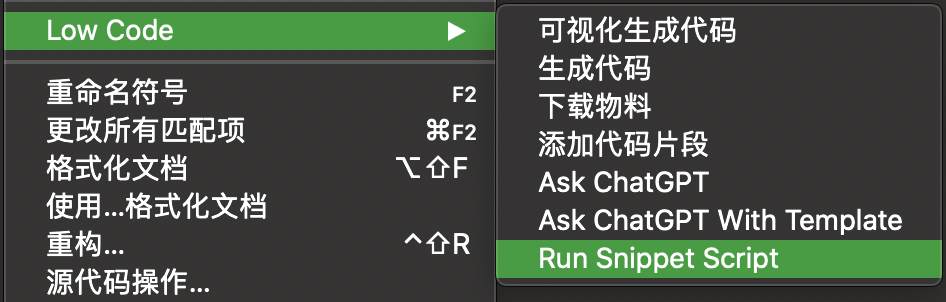
选择对应的模版(代码片段)后,会执行模版目录下 src/index.js 的
onSelect
方法,方法里可以写任何逻辑。
只需要将代码片段目录下的
config/preview.json
文件里的
showInRunSnippetScript
设置为
true
,代码片段就会出现在菜单中。
{
"title": "",
"description": "",
"img": [
"https://gitee.com/img-host/img-host/raw/master/2020/11/05/1604587962875.jpg"
],
"category": [],
"notShowInCommand": false,
"notShowInSnippetsList": true,
"notShowInintellisense": true,
"showInRunSnippetScript": true,
"schema": "amis",
"scripts": []
}
这个功能的加入,可以做很多有趣的事情,如下:
axios-request-api
把插件内部根据 YAPI 接口文档信息生成前端 API 请求方法的代码挪到了外面,并且加了个有意思的功能,让 ChatGPT 生成请求方法的名称,部分代码如下:
const res = await fetchApiDetailInfo(domain, yapiId, token);
if (!res.data.data) {
throw res.data.errmsg;
}
funcName = await context.lowcodeContext!.createChatCompletion({
messages: [
{
role: 'system',
content: `你是一个代码专家,按照用户传给你的 api 接口地址,和接口请求方法,根据接口地址里的信息推测出一个生动形象的方法名称,驼峰格式,返回方法名称`,
},
{
role: 'user',
content: `api 地址:${res.data.data.query_path},${res.data.data.method} 方法,作用是${res.data.data.title}`,
},
],
});
typeName = `I${funcName.charAt(0).toUpperCase() + funcName.slice(1)}Result`;
完整代码:
https://github.com/lowcode-scaffold/lowcode-materials/tree/master/materials/snippets/axios-request-api-外挂脚本/script
OCR
使用百度 OCR 识别图片文字
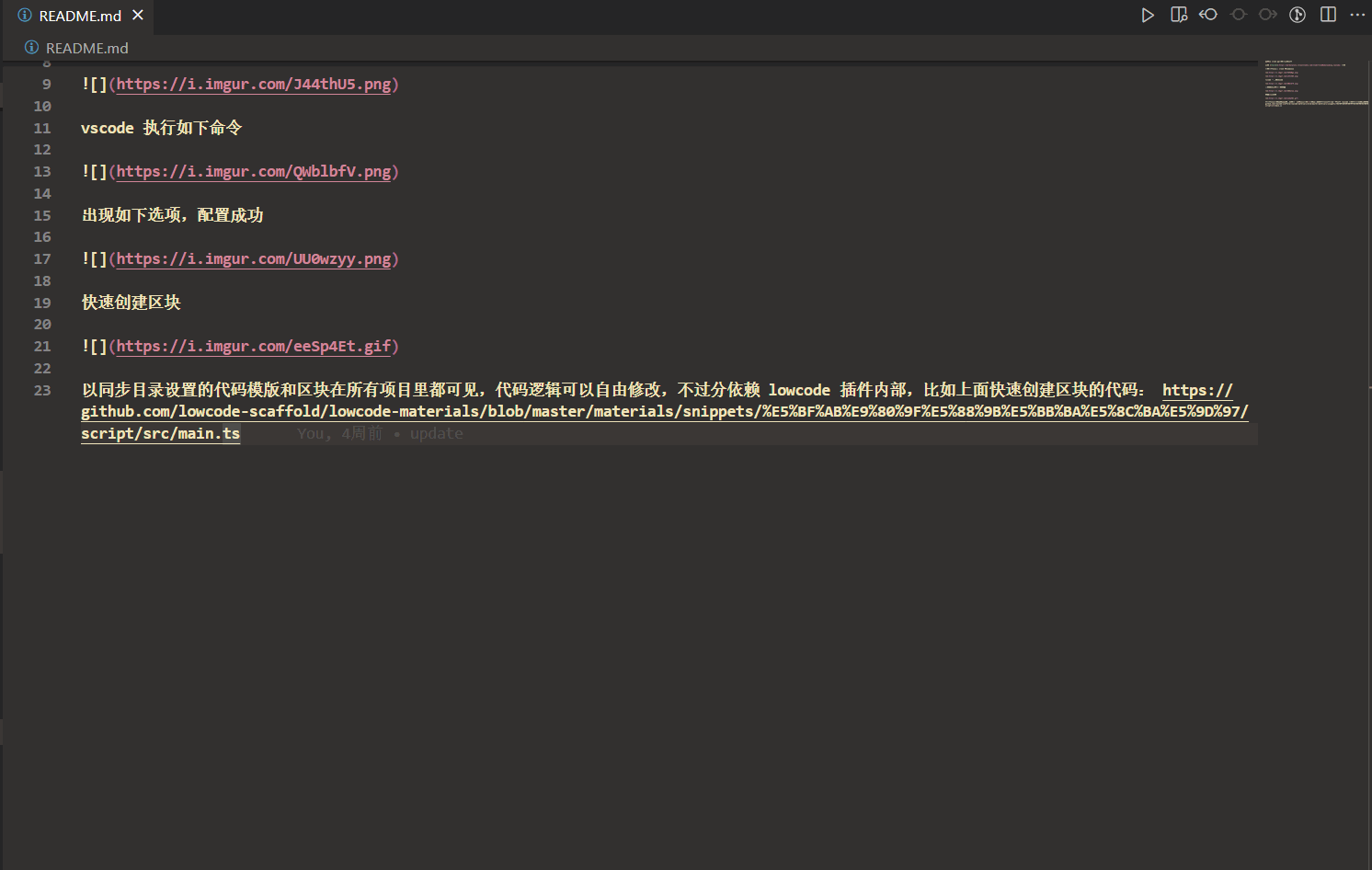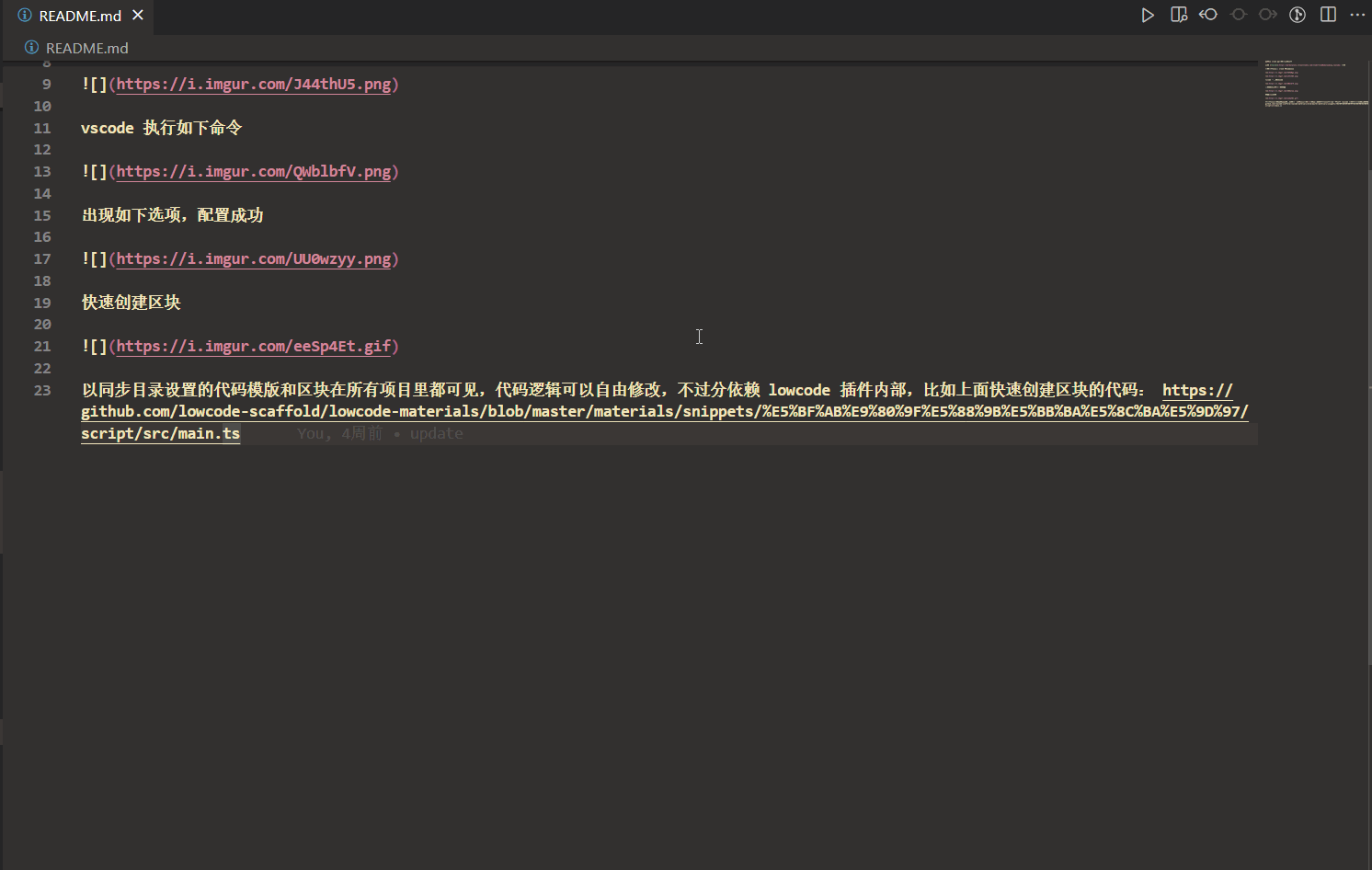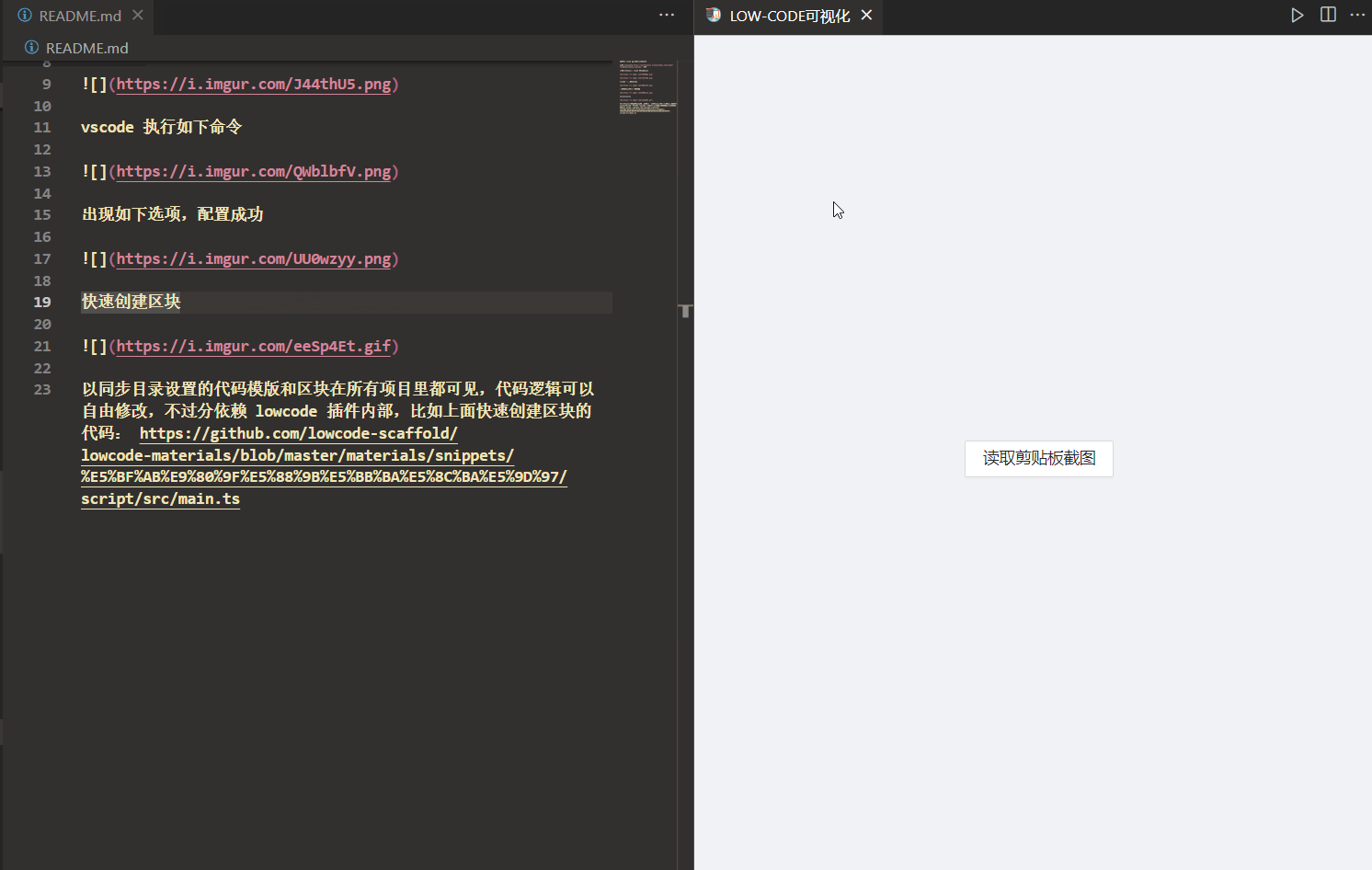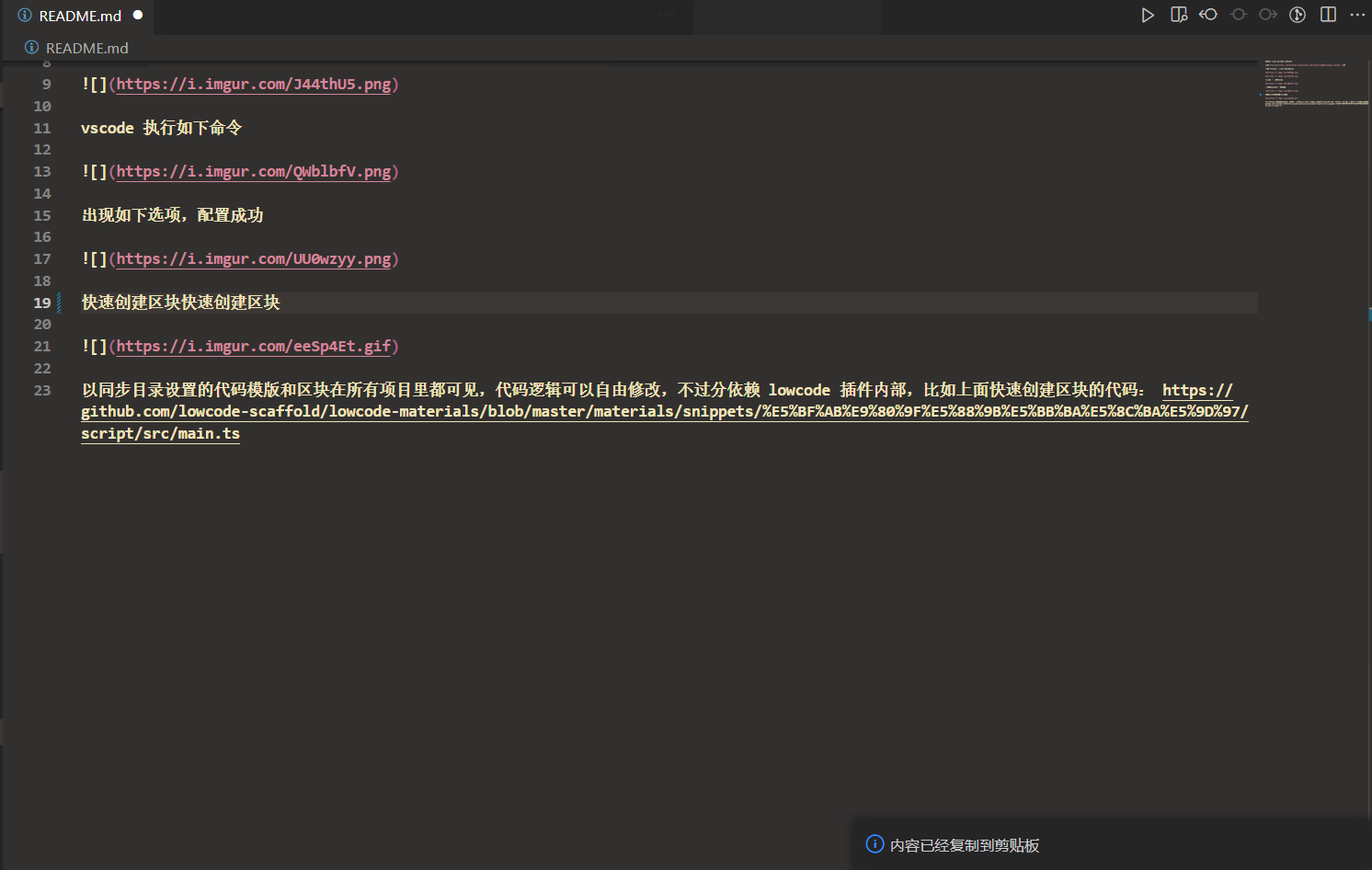
因为 nodejs 没法读取剪贴板里的图片,只能打开一个 webview 去读取,核心代码如下:
import { window, Range, env } from 'vscode';
import { generalBasic } from '../../../../../share/BaiduOCR/index';
import { context } from './context';
export async function bootstrap() {
const { lowcodeContext } = context;
const clipboardImage = await lowcodeContext?.getClipboardImage();
const ocrRes = await generalBasic({ image: clipboardImage! });
const words = ocrRes.words_result.map((s) => s.words).join(',');
env.clipboard.writeText(words).then(() => {
window.showInformationMessage('内容已经复制到剪贴板');
});
window.activeTextEditor?.edit((editBuilder) => {
// editBuilder.replace(activeTextEditor.selection, content);
if (window.activeTextEditor?.selection.isEmpty) {
editBuilder.insert(window.activeTextEditor.selection.start, words);
} else {
editBuilder.replace(
new Range(
window.activeTextEditor!.selection.start,
window.activeTextEditor!.selection.end,
),
words,
);
}
});
}
启动一个 nestjs 服务


import { Controller, Get } from '@nestjs/common';
import { AppService } from './app.service';
@Controller()
export class AppController {
constructor(private readonly appService: AppService) {}
@Get()
getMaterialPath() {
return this.appService.getMaterialPath();
}
}
import { Injectable } from '@nestjs/common';
import { context } from './context';
@Injectable()
export class AppService {
getMaterialPath() {
return context.lowcodeContext?.materialPath;
}
}
完整代码:
https://github.com/lowcode-scaffold/lowcode-materials/tree/master/materials/snippets/start nest api server/script
生成 value-label 格式 JSON
使用了
TypeChat
,ChatGPT 返回的结果有提问,最终重试之后正确了。
完整代码:
https://github.com/lowcode-scaffold/lowcode-materials/tree/master/materials/snippets/生成 value-label 格式 JSON/script
翻译成驼峰格式

代码:
import { env, window, Range } from 'vscode';
import { context } from './context';
export async function bootstrap() {
const clipboardText = await env.clipboard.readText();
const { selection, document } = window.activeTextEditor!;
const selectText = document.getText(selection).trim();
let content = await context.lowcodeContext!.createChatCompletion({
messages: [
{
role: 'system',
content: `你是一个翻译家,你的目标是把中文翻译成英文单词,请翻译时使用驼峰格式,小写字母开头,不要带翻译腔,而是要翻译得自然、流畅和地道,使用优美和高雅的表达方式。请翻译下面用户输入的内容`,
},
{
role: 'user',
content: selectText || clipboardText,
},
],
});
content = content.charAt(0).toLowerCase() + content.slice(1);
window.activeTextEditor?.edit((editBuilder) => {
if (window.activeTextEditor?.selection.isEmpty) {
editBuilder.insert(window.activeTextEditor.selection.start, content);
} else {
editBuilder.replace(
new Range(
window.activeTextEditor!.selection.start,
window.activeTextEditor!.selection.end,
),
content,
);
}
});
}
当前目录翻译成英文

代码:
import * as path from 'path';
import * as vscode from 'vscode';
import * as fs from 'fs-extra';
import { context } from './context';
export async function bootstrap() {
const { lowcodeContext } = context;
const explorerSelectedPath = path
.join(lowcodeContext?.explorerSelectedPath || '')
.replace(/\\/g, '/');
const explorerSelectedPathArr = explorerSelectedPath.split('/');
const name = explorerSelectedPathArr.pop();
vscode.window.withProgress(
{
location: vscode.ProgressLocation.Notification,
},
async (progress) => {
progress.report({
message: `loading`,
});
let content = await context.lowcodeContext!.createChatCompletion({
messages: [
{
role: 'system',
content: `你是一个翻译家,你的目标是把中文翻译成英文单词,请翻译时使用驼峰格式,小写字母开头,不要带翻译腔,而是要翻译得自然、流畅和地道,使用优美和高雅的表达方式。请翻译下面用户输入的内容`,
},
{
role: 'user',
content: name || '',
},
],
});
content = content.charAt(0).toLowerCase() + content.slice(1);
fs.renameSync(
path.join(lowcodeContext?.explorerSelectedPath || ''),
path.join(explorerSelectedPathArr.join('/'), content),
);
},
);
}
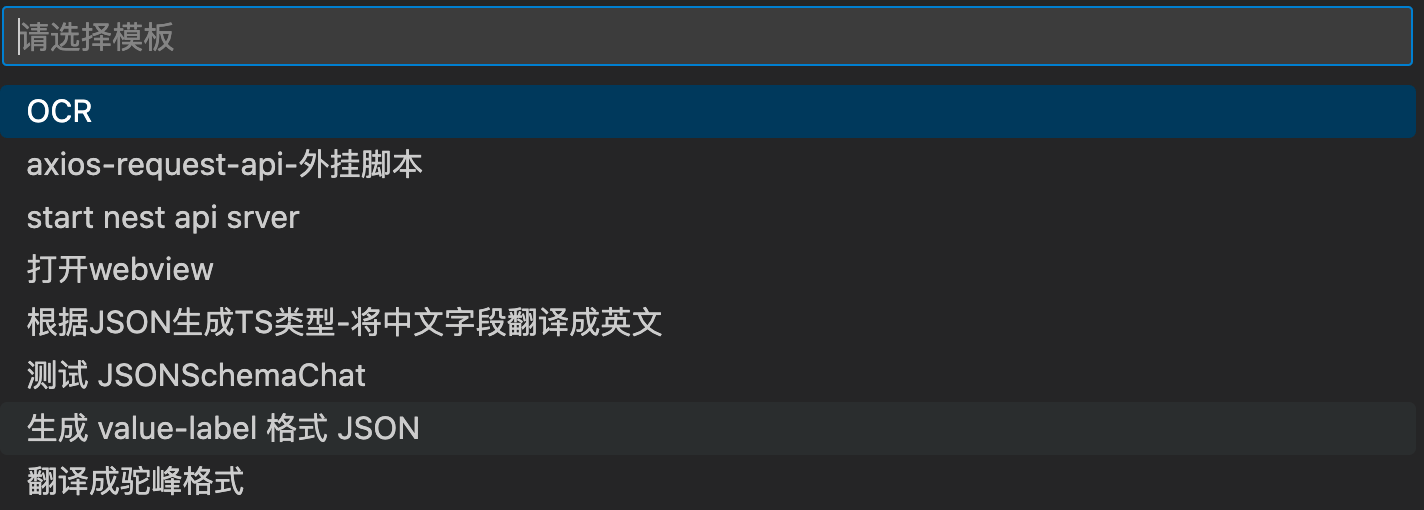
快速创建区块
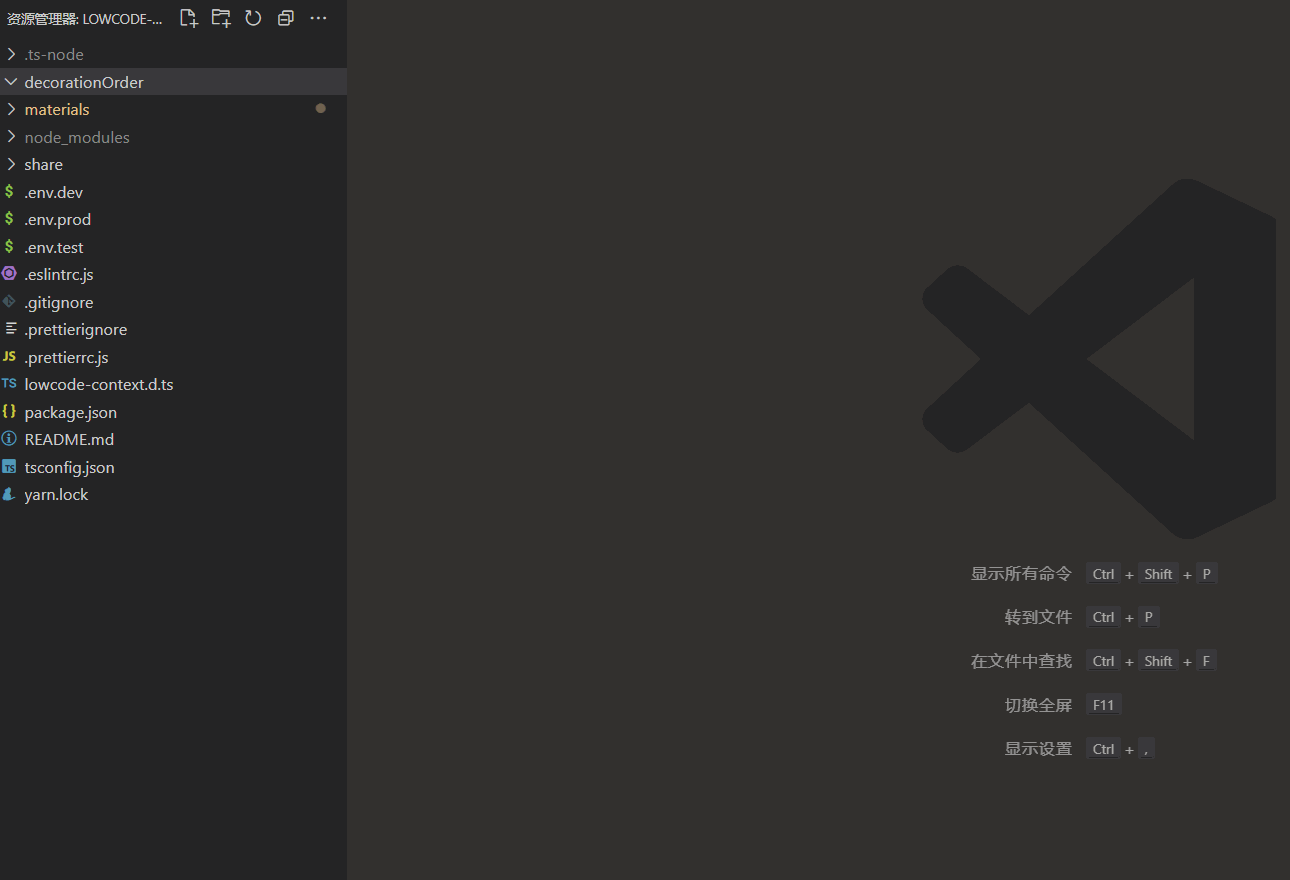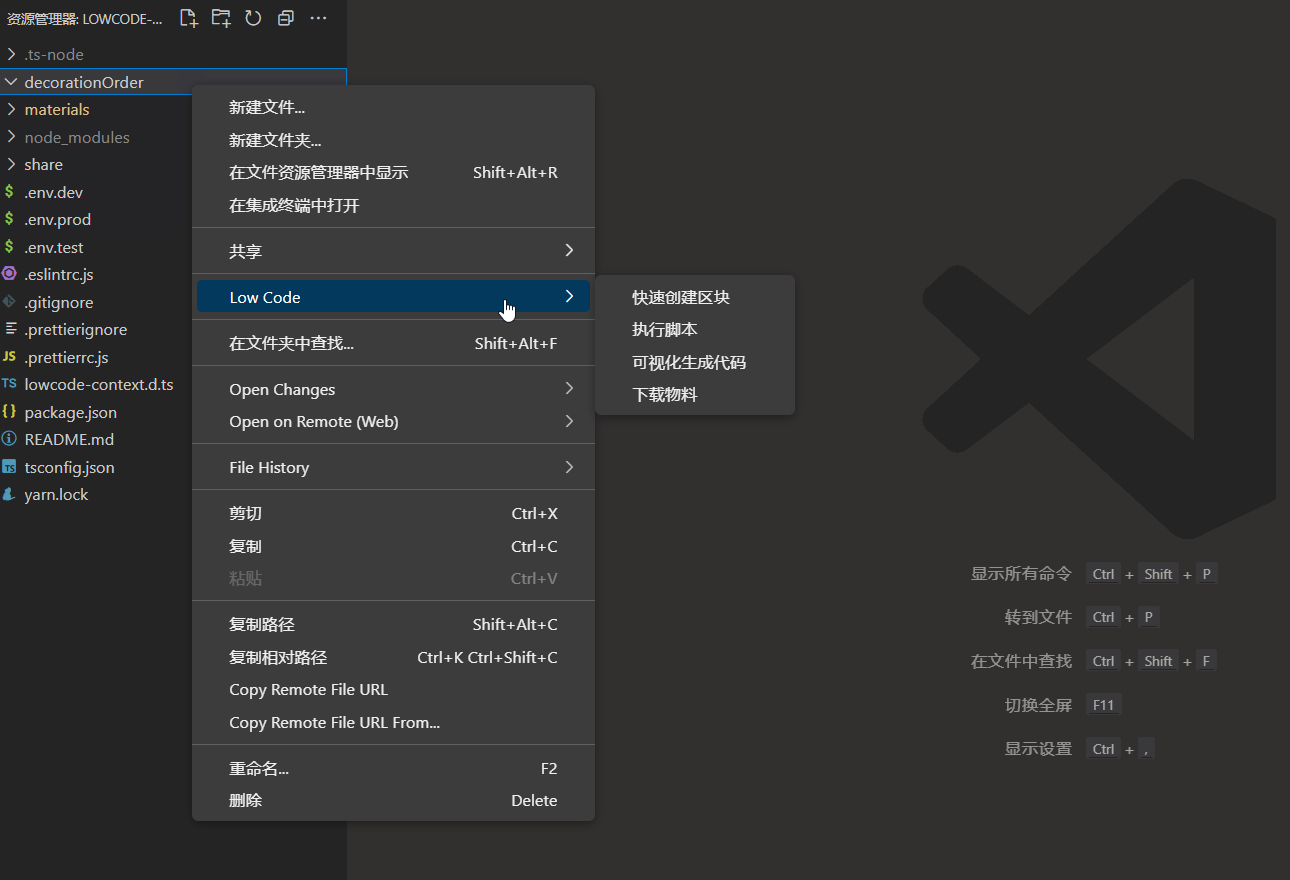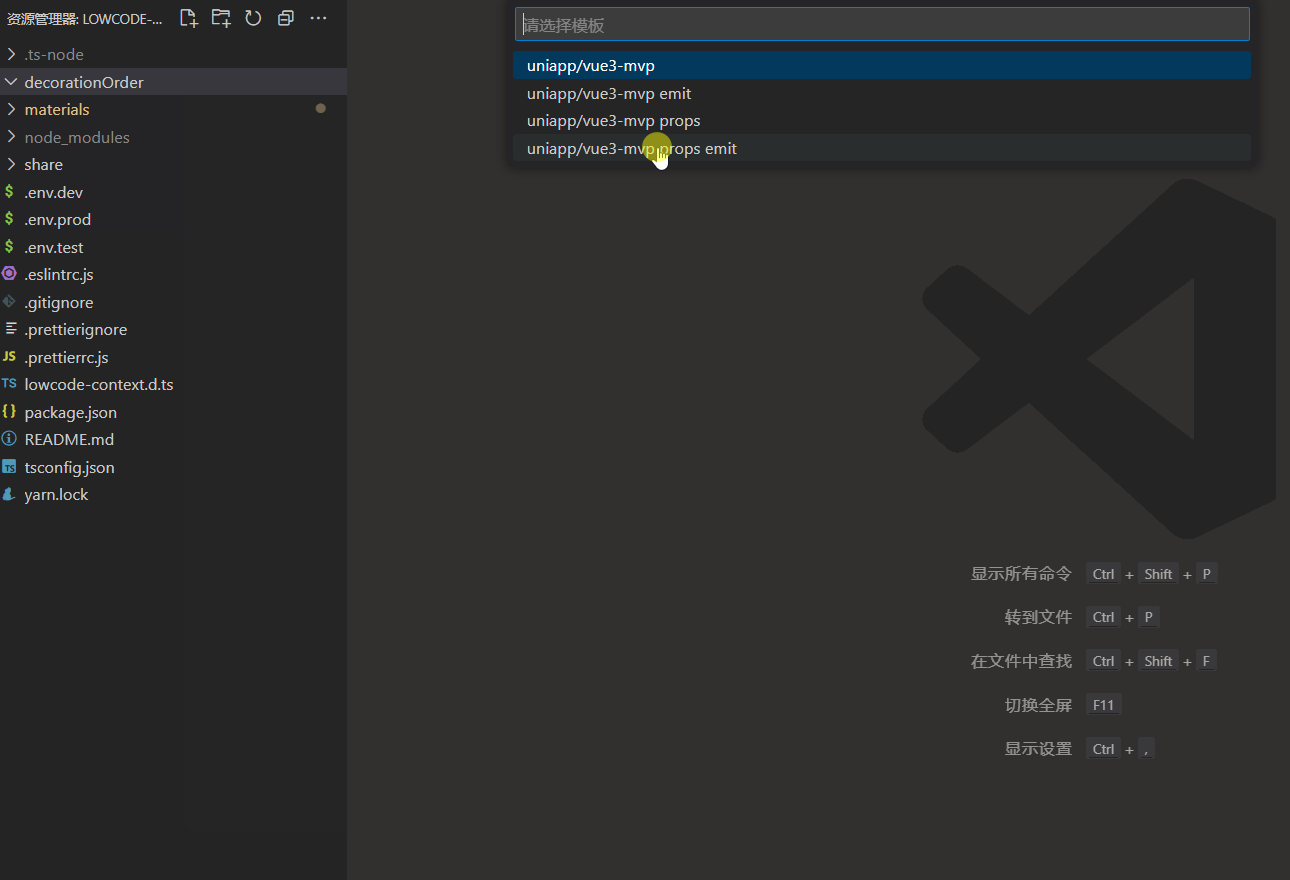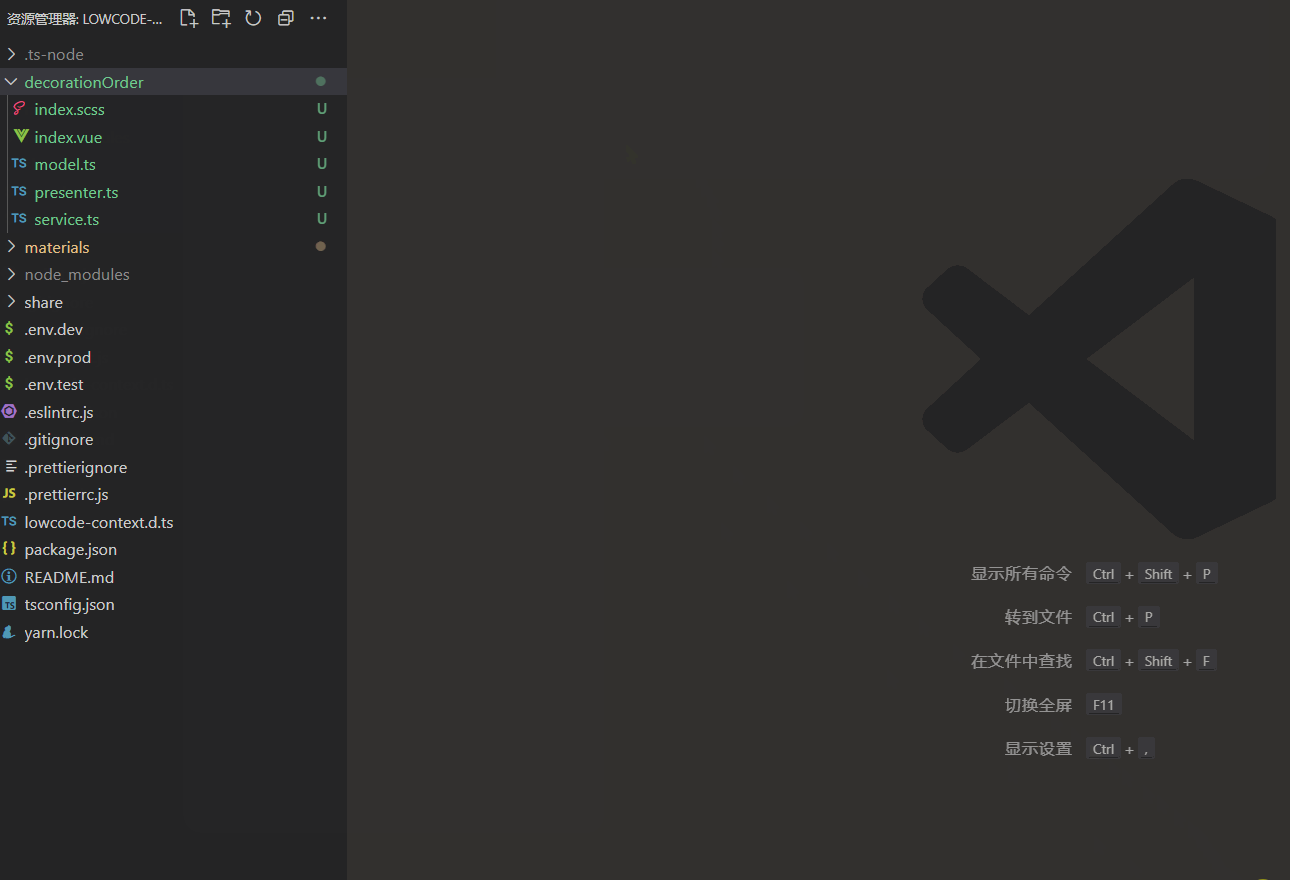
代码:
import * as path from 'path';
import { window } from 'vscode';
import * as fs from 'fs-extra';
import { context } from './context';
import { renderEjsTemplates } from '../../../../../share/utils/ejs';
export async function bootstrap() {
const { lowcodeContext } = context;
const result = await window.showQuickPick(
[
'uniapp/vue3-mvp',
'uniapp/vue3-mvp emit',
'uniapp/vue3-mvp props',
'uniapp/vue3-mvp props emit',
].map((s) => s),
{ placeHolder: '请选择模板' },
);
if (!result) {
return;
}
const tempWorkPath = path.join(
lowcodeContext?.env.rootPath || '',
'.lowcode',
);
fs.copySync(path.join(lowcodeContext?.materialPath || ''), tempWorkPath);
await renderEjsTemplates(
{
createBlockPath: path
.join(lowcodeContext?.explorerSelectedPath || '')
.replace(/\\/g, '/'),
},
path.join(tempWorkPath, 'src'),
);
fs.copySync(
path.join(tempWorkPath, 'src', result),
path.join(lowcodeContext?.explorerSelectedPath || ''),
);
fs.removeSync(tempWorkPath);
}
打开 WebView
右边 WebView 是一个独立的工程,部署在 vercel 上,主要为了学一下 UnoCSS,后续可能会把
screenshot-to-code
抄过来
完整代码:
https://github.com/lowcode-scaffold/lowcode-materials/tree/master/materials/snippets/打开webview/script
WebView 项目代码(Vue):
lowcode-webview-vue
WebView 项目代码(React):
lowcode-webview-react-vite
无限可能
上面列举了我常用的一些功能,以及正在尝试的东西,可以看出 lowcode 插件的自由度已经很高了,后续如果出现了什么好玩的技术可以立即接入玩一下。
遗憾
2023 对图片相关的 AI 研究的比较少,也想不到有什么使用场景。
2024 研究一下 Design to Code + AI 的落地。
源码
插件源码:
https://github.com/lowcoding/lowcode-vscode
物料源码:
https://github.com/lowcode-scaffold/lowcode-materials