本文出自本人写的书,谢绝转载,更勿抄袭。
本人有多年的Java面试官经验,经常要和一些包装项目经验的求职者打交道。当然平时也兼职做些Java面试辅导工作,最近也陆续帮一些在校生朋友成功找到Java工作。
在辅导在校生朋友找工作的过程中,本人发现,其实真有不少朋友,是跟着视频跑通了一个或多个学习项目,再背了些面试题和算法题,然后去找工作,对此本人也有专门的文章来说明。
虽然校招其实是没有商业项目要求的,换句话说,如果零项目经验再去找工作,其实也能成,但这样就和其它大多数在校生没差别了,事实上本人在辅导就业的过程中深有体会,如果求职者朋友能在面试过程中充分展示商业项目经验,一定能提升面试成功的可能。
这点其实很多在校生朋友也知道,所以不少人真会把学习项目包装成商业项目,或者干脆在没项目的前提下自己去编一个,所谓就是“吹牛不打草稿”,对此其实很多面试官是能轻易看出的,本人在面试官的经历中也经常听到些啼笑皆非的回答。
对此,本文先不说如何介绍商业项目经验,就先讲讲Java真实项目的开发流程和常用工具,这样,对于那些有真实Java项目经验的朋友,至少也知道该如何说。
1 接需求和前期设计
商业项目的需求一般来自两个途径,一类是本公司的产品设计人员提出需求,另一类是公司对接客户方需求的业务人员从客户方承接需求。
如果是公司自研的项目,比如某公司自研一个支付类的app,那么该公司的产品设计人员会设计出该app的界面和功能,然后交付程序员开发。如果是公司从客户方承接项目,那么该公司的项目开发团队是通过该公司的业务人员,从客户方获取界面、功能以及业务流程方面的需求。
在明确需求后,项目经理或架构师会根据业务需求点,在linux等操作系统的服务器上创建数据库服务器,并在其中创建数据库和数据表。在此基础上,项目经理或架构师会在服务器上搭建所需的基础设置,比如Redis等分布式组件、Nacos等微服务组件,或者是Git等代码管理组件。
随后,前端开发人员会用Vue.js等组件搭建前端框架,而后端架构师会用Spring Boot框架内加入控制器、服务层和整合MyBatis的数据服务层代码,同时整合Logback日志组件以及AOP切面组件,这样程序员就能在该框架内,通过加入必要的模板类代码,较为高效地实现各种基于增删改查的业务流程。
而在开发商业项目的过程中,程序员如果对功能点或业务流程有疑问,那么应当通过项目经理,向产品方或业务方确认,而不是用自己理解的方式来开发。
有些软件工程教科书会把开发项目的流程细分成“需求分析”、“概要设计”、“详细设计”以及之后的开发测试部署等环节,在“需求分析”、“概要设计”和“详细设计”等环节里,需要产出需求和设计文档,只有当所需文档通过评审后,才能进入下个环节,而且一旦需求发生变更,还需要及时更新相关的需求和设计文档。
但是在不少真实项目的开发场景里,由于开发工期较紧,项目组会用较为简单的文档来和产品或客户方确认需求,在中小型项目或者是外包型项目里,这种情况尤为明显。
比如在一个文档里画出客户所需的界面以及记录各业务的开发流程,而不会详细地按规范地编写文档。而且在需求变更后,也不会及时更新相关文档,甚至是有些需求和变动是直接从客户方这边获取到,然后通过邮件而不是文档来确认。
也就是说,在开发中小型项目或外包项目时,由于项目利润不高,项目经理会尽可能地压缩开发周期,所以,一般不会有太多的时间来按规范整理、评审和更新文档。相比之下,在开发学习项目时,一般会按部就班地按规范来写文档。
所以如果求职者给出项目规模较小,但说明在开发过程中用1个月的时间准备文档,而且项目开发流程完全符合教科书级别的软件开发规范,那么面试官还真可能会质疑该项目的真实性。
或者,如果有求职者说,在项目开发过程中,参与了接需求、设计数据表、绘制前端页面和开发后端代码等全部的工作,那么也是不大可信的。比如初级开发,在项目组里的开发工作一般是,在项目经理搭建好的Spring Boot框架里,参考现有的代码,完成开发工作。
2 敏捷开发模式
当下不少项目经理,尤其是需要赶工期的项目经理,是用敏捷模式来管理项目。在实践过程中,敏捷模式包含“每天例会”和“迭代开发”这两个实践要点。
在每天的例会里,项目组的每位成员需要说下当前任务的开发情况,如果遇到个人无法解决的问题就提出来,由组内成员帮助或协调解决,如果程序员完成开发了一个任务点,在例会中还可以演示一下,让相关人员确认下是否符合预期。
而迭代开发的含义是,项目经历根据开发周期和工作量,需求点合理地拆分到每个周期内,每个周期在完成任务后做一次发版。比如某项目开发周期是8个月,有50个功能点,那么项目经理能以“月”为单位设计8个迭代周期,并为每个周期制定如下表所示的工作任务。
| 迭代周期编号 |
工作任务 |
完成标志 |
| 1 |
完成创建数据表,完成搭建日志、Redis和Nacos等开发环境,完成3个功能点 |
相关组件搭建完成,成功发版,发版后的代码包含对应业务功能 |
| 2到7个周期 |
平均每个周期完成8个功能点,同时解决之前发现的线上问题 |
成功发版,发版后的代码包含对应业务功能,同时线上问题成功修复 |
| 8 |
全面测试,修复问题 |
成功发版,发版后的代码包含对应业务功能,同时线上问题成功修复 |
每个迭代周期有固定的发版日,比如是第四周的周五,当然在实际开发过程中,如果有待紧急上线的功能点或出现比较严重的线上问题,还可以再额外发版。而在每个迭代周期内,一般再会以“周”为单位来安排任务并管理代码,相关情况如下表所述。
| 时间段 |
工作任务 |
实践要点 |
| 该迭代周期开始后的1到2天内 |
项目经理会和产品或客户确认该周期内需要完成的任务点,同时确认该周期内需要解决的线上问题 |
项目经理用jira或禅道等工具,为每个程序员创建开发任务,同时不定期地为程序员分配修bug等任务 |
| 前三周 |
程序员根据所分配的任务开发功能点,或修复bug |
完成后的代码应及时部署到测试环境,同时经过测试后的代码应及时提交到Git或其它代码管理工具上 |
| 最后一周 |
全面测试,修复问题 |
发版后的代码在经测试后,应当在Git等工具上打上标记,以便管理 |
上文提到的,在每个迭代周期结束后的发版,是发布到生产环境。比如某项目组做的是自研项目,那么一般会在买的或租的服务器上搭建对外提供服务的生产环境,发版后的项目,即能对外提供服务。如果做的是外包项目,那么发版的环境一般是客户方提供的服务器。
每次发版结束后,项目经理一般也会让产品或业务人员来确认功能点。而在迭代开发过程中,难免会遇到需求变更等情况,此时项目经理可能就不得不更改原有计划,在对应的迭代周期内添加任务点。通过这种迭代模式,项目经理能有效地拆分任务,并且能定期演示所完成的功能点。
3 开发、测试与测试环境
在每个迭代开发周期内,程序员会根据所分配的任务,在Spring Boot等框架内开发增删改查功能点。
项目开发完成后,最终是需要部署到生产环境,这点上文已经提到过。不过大多数项目组还会在生产环境之外,在另外一台服务器上搭建测试环境,在测试环境上,一般也会安装Redis和数据库等项目基础设置,程序员一般有权限部署或修改测试环境的代码和配置文件。
大多数学习项目更注重功能开发,一般没有测试和部署等环节,也不会专门搭建测试环境和生产环境,这也是商业项目和学习项目的一个重要差别。事实上大多数的学习项目一般是在Windows操作系统的开发主机上启动并运行,所以如果求职者只做过学习项目,一般在面试过程中是说不好测试和部署的流程。
在开发完成后,虽然项目组一般还会配置测试人员,但是程序员一般还需要通过单元测试、接口测试和功能测试等手段来确保代码的质量,上述测试动作一般是在测试环境上进行,相关测试的实践要点归纳如下。
1. Spring Boot的单元测试一般用Junit进行,程序员通过编写测试案例,来确保自己所开发的方法和模块的正确性,在不少项目里,还会专门引入Sonar等组件来确保单元测试代码的覆盖率。
2. 程序员在完成开发代码并通过单元测试初步确定功能正确后,可以把后端代码打包部署到测试环境。Spring Boot项目会通过控制器类定义对外服务的URL接口和测试,程序员可以通过Postman等工具,向测试环境发出携带参数的URL请求,从而确保每个接口的正确性。
3. 接口测试能确保后端接口的正确性,此时如果在前端代码里已经包含了调用后端接口方法,那么程序员可以通过操作前端页面的方式来验证功能的正确性。当然这部分的测试更多地应该是由测试人员来完成,但如果有些项目规模很小,没配置专门的测试人员,这块一般也是由程序员自行完成。
4 项目部署细节说明
在商业项目的开发过程中,一般都会在每个迭代开发周期的结束时把项目代码发布待生产环境上,这个动作也叫项目部署。
在项目部署前,项目经理往往会带领程序员和测试人员完成如下的动作。
1. 通过接口测试和功能测试,确保待发布业务功能点的正确性。
2. 明确本次发布对应的功能点,以及明确对应功能点的检查方式。
3. 明确待发布项目的代码分支,比如用Git的master分支来发布,在发布前若干天,除非有紧急修复等需求,应当禁止程序员再修改该分支的代码。
4. 明确发布时需要运行的数据库脚本以及待修改的项目配置文件。
下表归纳了发布当前的常规任务。
| 操作人员 |
工作任务 |
| 项目经理或运维人员 |
打包前后端代码,比如把后端项目打成jar包。并把功能包部署到生产服务上的指定路径,并启动项目。 |
| 项目经理或运维人员 |
根据事先准备好的数据库脚本,更新生产环境上的数据库,同时更新生产环境上的项目配置文件 |
| 项目经理或运维人员 |
如果有必要,通过脚本等方式导入数据,或者在生产服务器上做其它操作 |
| 测试人员和程序员 |
发布完成后,程序员到生产环境上验证自己所开发功能的正确性,同时测试人员通过测试,验证质量 |
后端Spring Boot项目的发布流程一般是,用Maven等工具把项目打成jar包,再把该jar包复制粘贴到生产环境上,再通过java -jar等命令启动该jar包,当然整个过程也可以用jenkins等自动化部署工具来完成。
在发布过程中,如果发现所开发的功能有bug,项目经理能根据实际情况决定是完成部署还是终止部署。如果要终止部署,就需要把生产环境上的代码、数据和配置参数回退到本次部署前的状态。发布完成后,项目经理也可以请产品设计人员或业务人员等提出需求的人员,到生产环境上通过实际操作,来确认所开发的功能符合预期。
5 监控系统,解决线上问题
在生产环境上,运维人员一般会搭建监控系统,用来监控系统运行的状态。常用的监控系统有newrelic, cat和zabbix,程序员一般不需要关心监控系统是如何搭建和如何运行的,但监控系统一旦发现问题,会通过邮件或手机短信等方式告知程序员,此时程序员就需要排查解决问题。
不管是哪种监控系统,一般都会提供如下表所示的监控服务。
| 监控维度 |
告警时机 |
| 服务器 |
比如某项目部署在3台服务器上,一旦有一台服务器宕机,且时间操作30秒,监控系统会告警。 |
| 慢查询 |
数据库的某SQL语句运行时间超过10秒,监控系统会告警 |
| 慢请求 |
某后端请求的处理时间超过10秒,监控系统会告警 |
| CPU负载过高 |
某服务器的CPU负载率高于50,且持续时间超过2分钟,监控系统会告警 |
| 内存负载过高 |
某服务器的JVM虚拟机负载率高于75,且持续时间超过2分钟,监控系统会告警 |
| 异常数过多 |
比如在5分钟内,某服务器日志里出现Error或Exception等关键字的次数超过10次,监控系统会告警 |
在实践场景里,运维人员会在Zabbix等监控组件里设置多个告警条件,在其中配置告警的阈值,比如上文里提到的“某后端请求的处理时间超过10秒会告警”,其中告警阈值是10秒还是其它,这可以在监控组件内设置。
程序员在商业项目里一般会去解决实际的线上问题,而大多数的线上问题一般都是由监控系统发现。而程序员解决线上问题的一般步骤是,第一看系统日志或运行linux明确确认问题,第二找到该问题对应的代码或配置文件,同时明确修复步骤,第三在修复后测试并部署,并到生产环境上确认问题已经修复。
6 项目管理和部署工具
商业项目一般会用Maven或Gradle工具来管理系统,通过此类工具,程序员除了能引入该项目所需要的依赖包之外,还能设置编译项目时的工作任务。
具体地,如果使用Maven工具, 一般是通过mvn build命令来编译项目,如果是用Gradle工具,一般是用gradlew build命令来编译,在编译过程中,如果后端代码有语法问题,编译会失败。
在实际项目里,项目经理一般还会通过编写配置文件的方式,设置Maven或Gradle工具在编译时还要运行代码检查工具,从而确保项目代码的质量。比如可以通过Maven整合Sonar组件的方式,确保后端项目的Junit单元测试覆盖率要高于80%,否则就会编译失败。
而在上文提到的项目部署过程中,可以手动运行mvn build等命令把后端项目打成jar包,再把该jar部署到linux测试或生产环境上再启动,但是为了提升部署的效率,还可以用Jenkins等工具来部署。
具体在用jenkins等工具时,程序员可以通过编写配置文件,指定待部署项目的Git分支,打包命令和部署项目的服务器地址以及部署后启动项目的命令,这样在部署时就能通过点击Jenkins工具的菜单按钮自动完成部署动作。
7 代码管理工具
当下大多数项目是用Git来管理代码,当然依然有不少项目采用SVN等工具来管理代码。在每个迭代开发周期里,程序员在开发任务和修复bug前,需要从master等主分支上创建具体的开发分支,在开发分支上完成开发后,再把代码提交并合并到主分支,相关操作要点如下所述。
要点1:在上一个迭代周期结束时,主分支(master)上的代码已经发布到生产环境,同时会给此时的master主分支代码打上一个tag标签,比如是20230825标签,这样如果之后在生产环境上发布的代码有问题,可以回退到由该标签标志的Git分支。
要点2:项目组里的Git工具一般会安装在专门的服务器上,这台服务器也叫Git服务器。而程序员自己的主机上需要安装Git客户端,并通过git命令从服务器上拉取代码或向服务器推送代码,相关效果如下图所示。而在不少学习项目里, Git服务器和Git客户端会被安装在同一台Windows操作系统的主机上。
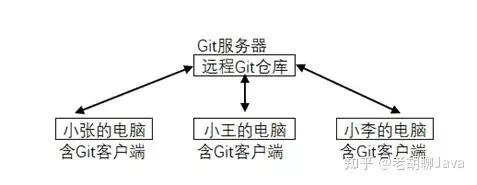
要点3,程序员在开发功能或修复bug时,一般需要用git pull命令,把处在远端Git服务器上的master代码拉到本地主机,并在主分支代码的基础上创建一个开发分支。比如小张创建了一个名为task_001的代码分支,小李创建了名为task_002的代码分支,他们分别在各自的分支上开发代码。此时请注意,这里的task_001等开发分支只是处在本地,并没有提交到Git服务器。
要点4,程序员在自己的分支上完成开发和测试后,可以通过git commit命令,把代码提交到本地(即程序员电脑的Git客户端)的task_001等开发分支上,并通过git push命令,把本地的task_001等开发分支推送到Git服务器。
要点5,程序员在把自己的开发分支推送(push)到Git服务器后,需要创建一个合并请求(pull request,简称pr),请求把task_001里的代码合并到主分支里。在创建合并请求时,一般需要指定由其它程序员评审(Review)代码,经过评审后,task_001里包含的实现新功能的代码就能被合并(merged)到主分支上。
要点6,如果有多人同时修改同一个文件里的同一段代码,那么在通过合并请求(pull request,简称pr)把分支代码合并到主分支时,就会出现代码冲突(conflict)的现象。此时相关人员就要一起讨论,在确保功能正确的前提下修改代码,从而解决代码冲突的情况。
也就是说,如果程序员参与过真实的项目,那么应该有上述Git等代码管理工具的实践经验,相比之下,在学习项目的开发过程中,由于不涉及到多人协同开发,一般会直接在主分支上开发代码,而不会有创建开发分支、把开发分支合并到主分支、代码评审和和解决冲突等动作。
8 Java项目开发的常用组件
在商业项目里,一般也是用到IDEA集成开发工具,也是用到Spring Boot框架,但是和学习项目相比,商业项目一般还会用到如下表所示的项目基础设施组件。
| 功能效果 |
商业项目 |
学习项目 |
| 输出日志 |
用logback或log4j组件向控制台和文件里输出日志 |
一般仅会用System.out.println语句向控制台输出日志 |
| 安全防护 |
通过Spring Security组件实现身份验证和鉴权 |
不大会实现此类功能,或仅用Spring Security组件的基本功能 |
| 展示API |
通过Swagger组件展示API,以供前端等人员调试 |
一般也会用到Swagger组件 |
| 提升数据库性能 |
会综合使用索引、Redis,再视情况使用MyCat分库组件 |
一般仅用到Redis单机版节点 |
| 监控项目 |
Zabbix或Cat等 |
一般不会用到 |
从上表里大家能看到,后端商业项目所用的一些组件,在开发学习项目时根本用不到,也就是说,如果大家能在面试中,结合场景和使用细节正确地说明日志等组件的使用方式,其实也能从侧面证明自己的商业项目开发经验。
9 测试类工具
在实际项目里,程序员一般也会用到Postman和Jmeter等测试工具,其中Postman一般用在接口测试(也叫API测试)场景,而Jmeter一般用在自动化测试或性能测试等场景。
比如某仓库管理系统后端项目,在控制器层里通过@urlmapping等注解定义了如下表所示的实现增删改查功能的接口,其中分别用到了POST、DELETE、PUT和GET类型的http动作,当该项目部署到测试环境或生产环境后,程序员可以通过Postman工具发请求的方式来测试各API接口的正确性。
| 动作 |
URL请求 |
http动作 |
参数说明 |
| 查询指定id的库存 |
/stock/{id} |
GET |
{id}表示待查询的库存数据id |
| 查询所有库存信息 |
/stocks |
GET |
返回所有库存,无需参数 |
| 创建新的库存数据 |
/stock |
POST |
在请求体(Body)里传入待插入的库存数据 |
| 修改指定id的库存 |
/stock/{id} |
PUT |
{id}表示待修改的库存数据id,而具体待修改的库存数据会通过请求体(Body)传入 |
| 删除指定id的库存 |
/stock/{id} |
DELETE |
{id}表示待删除的库存数据id |
比如通过Postman工具,发出了POST类型的/stock请求,并在该请求的参数里设置了待插入的库存信息,如果看到该请求的Http返回码是200,那么能说明该POST接口工作正常。再如,如果用Postman工具发出DELETE类型的/stock/{id}请求,并且正确地输入了待删除库存的参数,如果看到返回码是500,那么就说明该接口的代码有问题,程序员就需要介入并排查。
在项目部署前,一般需要确保该项目所有的接口都正常工作,如果该后端项目已经在控制器里定义了20多个接口,那么手动测试的工作量会比较大。
在此类场景里,可在Jmeter里加入所有API接口,并设置每个接口正常工作的标准,比如返回码是200就算工作正常,那么就可以在每次部署前通过Jmeter自动发起针对所有接口的调用,并能通过返回结果自动确认接口的正确性,这就是用Jmeter进行自动化测试的一般步骤。
如果某后端项目对接口的性能有要求,比如客户方要求每个接口的响应时间应该小于2秒,那么可以通过Jmeter,设置同时发起100个请求,再通过查看平均返回时间来分析接口的性能,如果有问题再进行性能调优工作。
10 数据库服务器及其客户端组件
在实际项目里,一般也会在一台服务器上搭建MySQL或Oracle等数据库服务器,而程序员在本机开发时,是通过Navicat或MySQL WorkBench等客户端组件连接到数据库服务器。
事实上不少项目组同样会在生产环境的数据库服务器之外,再搭建测试环境的数据库服务器,而且为了节省资源,会在同一台测试服务器上搭建数据库环境、上文提到的Git服务器以及Redis缓存组件等项目开发的基础设施。
程序员在开发功能的过程中,除非是排查产线问题,否则一般不会操作生产环境的数据库服务器,而是使用测试环境的数据库,在使用时一般会有如下的实践要点。
1. 在一个后端项目里,一般会包含两个配置文件,分别用于编写指向生产环境和测试环境的配置参数,而后端代码在启动时,能通过传入参数指定是连向生产环境还是测试环境。
2. 程序员在本机开发代码时,一般不会在自己的主机上再搭建数据库服务器,而是通过修改配置文件的方式,让本地运行的代码指向测试数据库。而后端代码被放置到测试环境上测试时,一般也是连向测试服务器。
3. 如果程序员要调试数据库方面的问题,比如要调试一句查询的SQL语句,一般是在本地,通过Navicat等客户端工具连上测试数据库,再其中调试。
4. 在生产环境数据库服务器上的任何操作,比如要创建索引或更改表结构,一般会先在测试环境的数据库服务器上验证,验证成功后再到生产数据库上执行。
相对应地,如果某程序员在面试时,向面试官说,在开发项目时,MySQL等数据库服务器是搭建在本地主机,或者是说,开发项目时数据库服务器不分生产环境和测试环境,只用一套环境,那么该程序员所说的项目,一般是指学习项目,而不是商业项目。
11 linux连接组件
商业项目一般是部署并运行在linux操作系统的服务器上,具体是指,后端Spring Boot项目打成的jar包会被部署到linux服务器上并启动,数据库服务器和Redis服务器,以及其它必要的项目基础设施(如分布式组件或微服务组件),一般也是部署并运行在linux服务器。
也就是说,程序员在开发项目时,会在本地Windows操作系统上,通过
SecureCRT
等组件,在输入目标服务器IP地址、连接用户名和密码之后,以命令终端或文件目录的形式连接到测试或生产环境。
程序员在把后端代码放置到测试服务器后,可通过Postman等工具发起请求测试API接口,如果发现问题,可用
SecureCRT
组件登到测试服务器,找到对应的日志文件,把该日志文件下载到本地再排查。
或者是在以命令端的方式登录到linux服务器之后,通过linux命令打开日志文件并排查问题。项目中常用的linux命令如下表1-8所示。
| 命令 |
含义和使用场景 |
| cd /opt/abc |
进入到指定路径 |
| Pwd |
查看当前路径 |
| cp |
复制文件 |
| ls |
通过cd命令进入到指定路径后,用该命令查看当前路径里的文件,确认是否存在待分析的日志文件按 |
| vi |
打开(日志等)文件,打开后可通过/keyword的方式查找字符,以确认和排查问题 |
12 总结与预告
商业项目经验是Java求职者技能的最好背书,所以在面试过程中证明自己的商业项目经验尤为重要,但不少Java程序员,尤其是商业项目经验不多的程序员,在面试过程中往往表现得像零商业项目的求职者一样,无法有效地通过项目细节来证明自己的经历。
本章系统讲述了Java商业项目的开发流程流程以及项目开发时经常会用到的组件和工具,在之后的章节,将会在此基础上,具体给出如何证明商业项目经验的详细说辞和面试准备技巧。