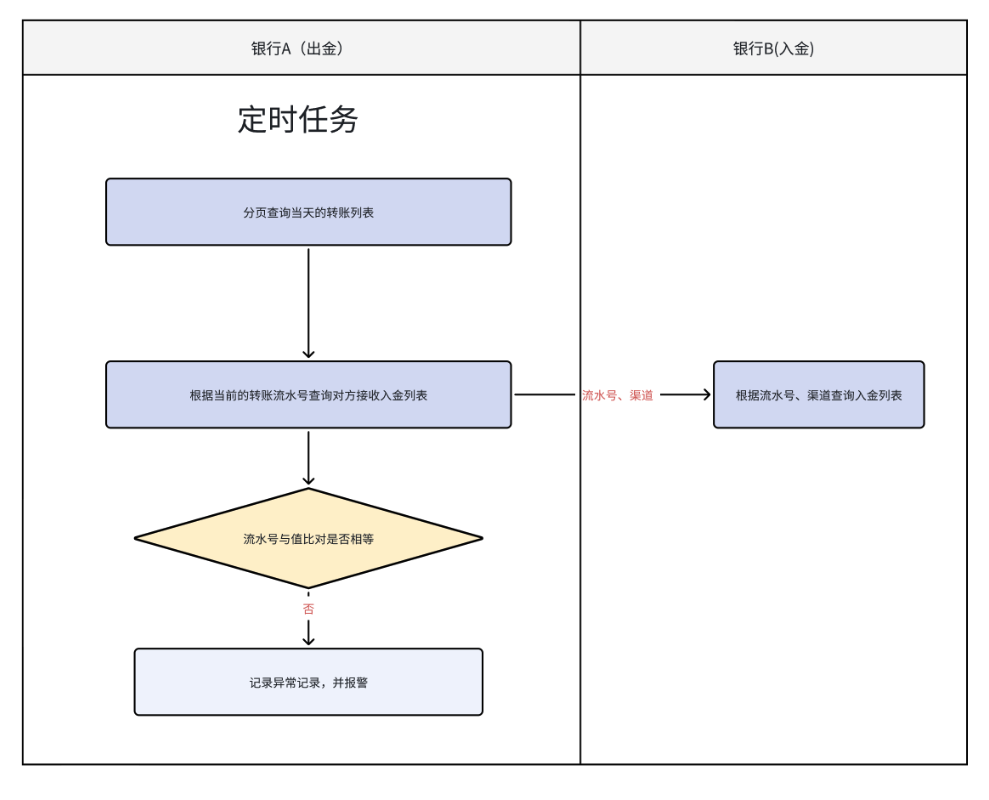
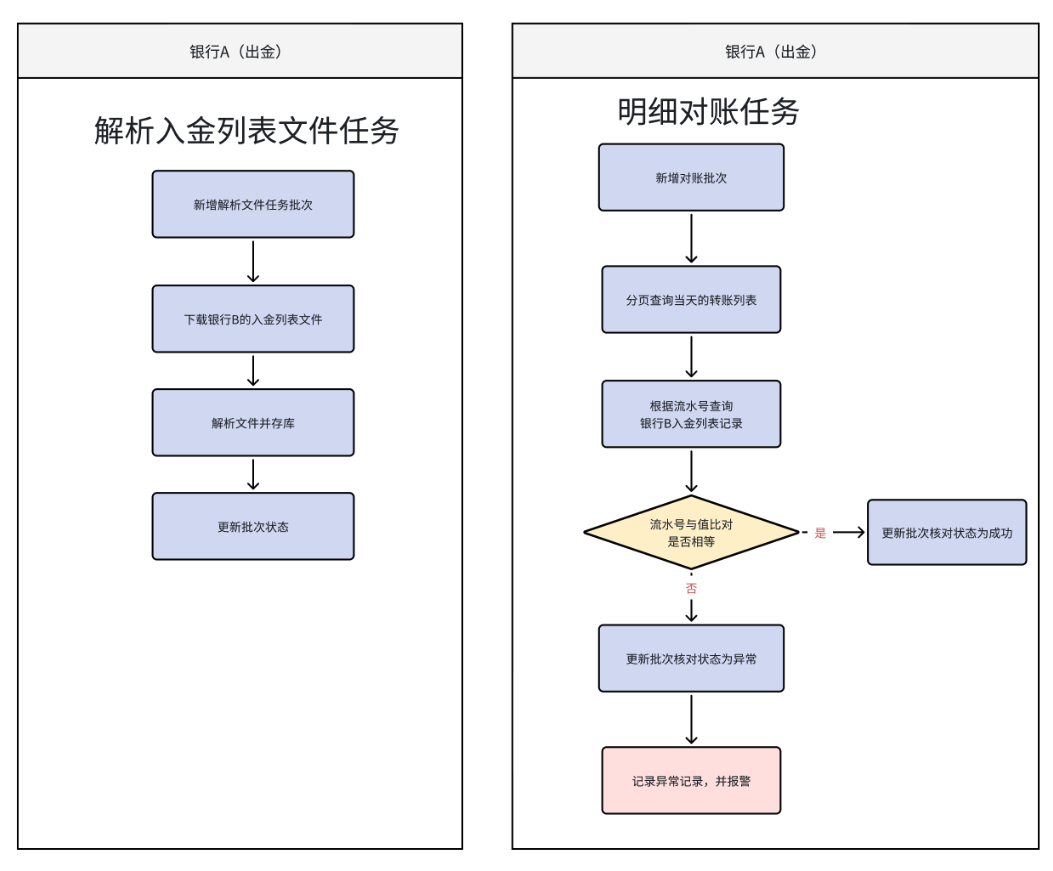
41. 干货系列从零用Rust编写负载均衡及代理,websocket与tcp的映射,WS与TCP互转
wmproxy
wmproxy
已用
Rust
实现
http/https
代理,
socks5
代理, 反向代理, 静态文件服务器,四层TCP/UDP转发,七层负载均衡,内网穿透,后续将实现
websocket
代理等,会将实现过程分享出来,感兴趣的可以一起造个轮子
项目地址
国内: https://gitee.com/tickbh/wmproxy
github: https://github.com/tickbh/wmproxy
项目设计目标
针对有一些应用场景需要将TCP转成websocket的,就比如旧的客户端或者旧的服务端比较不合适进行改造,但是又需要借助阿里的全站加速DCDN等这类服务或者其它可能需要特定浏览器协议的情况下,需要进行协议的转化而服务。
Tcp转Websocket
流程图
以下展示Tcp转Websocket的流程图,就纯粹的Tcp客户端在不经过任何源码修改的情况下成功连接websocket服务端
A[tcp客户端] -->|连接服务| B[服务节点]
B -->|服务转化| C[websocket客户端]
C -->|连接服务| D[websocket服务端]
比较适合原生客户端,又不想引入第三方库,又能在需要的时候直接使用websocket来做配合。
源码实现
实现源码在
stream_to_ws
/// 将tcp的流量转化成websocket的流量
pub struct StreamToWs<T: AsyncRead + AsyncWrite + Unpin> {
url: Url,
io: T,
}
- 需要传入的参数为原生的tcp,此处tcp是具备异步读异步写功能的虚拟tcp
- 传入连接websocket的url地址,可以连接到websocket的服务端地址
定义回调类:
struct Operate {
/// 将tcp来的数据流转发到websocket
stream_sender: Sender<Vec<u8>>,
/// 从websocket那接收信息
receiver: Option<Receiver<OwnedMessage>>,
}
- stream_sender
将数据进行发送到websocket中 - receiver
从websocket中获取信息流
核心转发逻辑:
pub async fn copy_bidirectional(self) -> ProtResult<()> {
let (ws_sender, ws_receiver) = channel::<OwnedMessage>(10);
let (stream_sender, stream_receiver) = channel::<Vec<u8>>(10);
let url = self.url;
tokio::spawn(async move {
if let Ok(mut client) = Client::builder().url(url).unwrap().connect().await {
client.set_callback_ws(Box::new(Operate {
stream_sender,
receiver: Some(ws_receiver),
}));
let _e = client.wait_ws_operate().await;
}
});
Self::bind(self.io, ws_sender, stream_receiver).await?;
Ok(())
}
创建两对发送接收对分别为
OwnedMessage
及
Vec<u8>
来进行双向绑定,并在协程中发起对websocket的连接请求。更多的逻辑请查看源码。
测试demo
示例文件
ws_stw
,当下监听
8082
的流量并将其转发到
8081
的
websocket
服务上,测试借助
websocat
做测试服务端
cargo run --example ws_stw
启动转发监听8082websocat -s 8081
监听8081telnet 127.0.0.1 8082
手动建立8082的端口
成功测试转发
Websocket转Tcp
流程图
以下展示Websocket转Tcp的流程图,通常由浏览器环境中发起(因为浏览器的标准全双工就是websocket)。然后服务器这边由TCP的方案
A[websocket客户端] -->|连接服务| B[服务节点]
B -->|服务转化| C[tcp客户端]
C -->|连接服务| D[tcp服务端]
比较适合原生服务端,又不想引入第三方库,又能兼容TCP及websocket协议,适合在这个做个中间层。
源码实现
实现源码在
ws_to_stream
/// 将websocket的流量转化成的tcp流量
pub struct WsToStream<T: AsyncRead + AsyncWrite + Unpin + Send + 'static, A: ToSocketAddrs> {
addr: A,
io: T,
}
- 需要传入的参数为原生的tcp,此处tcp是具备异步读异步写功能的虚拟tcp,其中
'static
表示io为一个类,而不是引用 - 传入连接tcp的SocketAddr地址,可以连接到Tcp的服务端地址
定义回调类:
struct Operate {
/// 将tcp来的数据流转发到websocket
stream_sender: Sender<Vec<u8>>,
/// 从websocket那接收信息
receiver: Option<Receiver<OwnedMessage>>,
}
- stream_sender
将数据进行发送到websocket中 - receiver
从websocket中获取信息流
核心转发逻辑:
pub async fn copy_bidirectional(self) -> ProtResult<()> {
let (ws_sender, ws_receiver) = channel(10);
let (stream_sender, stream_receiver) = channel::<Vec<u8>>(10);
let stream = TcpStream::connect(self.addr).await?;
let io = self.io;
tokio::spawn(async move {
let mut server = Server::new(io, None);
server.set_callback_ws(Box::new(Operate {
stream_sender,
receiver: Some(ws_receiver),
}));
let e = server.incoming().await;
println!("close server ==== addr = {:?} e = {:?}", 0, e);
});
Self::bind(stream, ws_sender, stream_receiver).await?;
Ok(())
}
与tcp转websocket类似,但是此时是将io流量转成
Server
的处理函数。
测试demo
示例文件
ws_wts
,当下监听
8082
的流量并将其转发到
8081
的
websocket
服务上,测试借助
websocat
做测试服务端
新建测试TCP的监听,原样转发的测试代码:
#[tokio::main]
async fn main() -> std::io::Result<()> {
use tokio::{net::TcpListener, io::{AsyncReadExt, AsyncWriteExt}};
let tcp_listener = TcpListener::bind(format!("127.0.0.1:{}", 8082)).await?;
loop {
let mut stream = tcp_listener.accept().await?;
tokio::spawn(async move {
let mut buf = vec![0;20480];
loop {
if let Ok(size) = stream.0.read(&mut buf).await {
println!("receiver = {:?} size = {:?}", &buf[..size], size);
let _ = stream.0.write_all(b"from tcp:").await;
let _ = stream.0.write_all(&buf[..size]).await;
} else {
break;
}
}
});
}
}
cargo run --example tcp
监听8082的端口,收到数据原样转发cargo run --example ws_wts
启动转发监听8081websocat ws://127.0.0.1:8081
用websocket的方式连接到8081

成功测试转发
组合方案
当我们现存的网络方案为
Tcp到Tcp
或者为
Websocket到Websocket
而我们在中间的传输过程中如想利用DCDN做源地址保护,而他只支持Websocket,此时我们就可以利用数据的转化,将我们的数据包通过DCDN做转发:
A[TCP客户端] -->|连接服务| B[服务节点]
B -->|转化成websocket通过加速| C[DCDN全站加速]
C -->|连接服务| E[服务节点]
E -->|转化成Tcp并串连到服务端| F[TCP服务端]
这样子我们就可以利用基础网络中的CDN或者DCDN等服务,又不用对旧的数据进行修改或者无法修改的程序就比如远程服务通过CDN进行加速等。
小结
协议的自由转化可以帮助我们创建更合适的网络环境,可以让运维更自由的构建系统。利用转化可以用好全站加速
DCDN
这类的功能,可以更好的保护源站,防止被DDOS攻击。
点击
[关注]
,
[在看]
,
[点赞]
是对作者最大的支持