flex布局之美,以后就靠它来布局了
写在前面
在很久很久以前,网页布局基本上通过
table
元素来实现。通过操作
table
中单元格的
align
和
valign
可以实现水平垂直居中等
再后来,由于
CSS
不断完善,便演变出了:
标准文档流
、
浮动布局
和
定位布局
3种布局 来实现水平垂直居中等各种布局需求。
下面我们来看看实现如下效果,各种布局是怎么完成的

实现这样的布局方式很多,为了方便演示效果,我们在html代码种添加一个父元素,一个子元素,css样式种添加一个公共样式来设置盒子大小,背景颜色
<div class="parent">
<div class="child">我是子元素</div>
</div>
/* css公共样式代码 */
.parent{
background-color: orange;
width: 300px;
height: 300px;
}
.child{
background-color: lightcoral;
width: 100px;
height: 100px;
}
①absolute + 负margin 实现
/* 此处引用上面的公共代码 */
/* 定位代码 */
.parent {
position: relative;
}
.child {
position: absolute;;
top: 50%;
left: 50%;
margin-left: -50px;
margin-top: -50px;
}
②absolute + transform 实现
/* 此处引用上面的公共代码 */
/* 定位代码 */
.parent {
position: relative;
}
.child {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
}
③ flex实现
.parent {
display: flex;
justify-content: center;
align-items: center;
}
通过上面三种实现来看,我们应该可以发现
flex
布局是最简单了吧。
对于一个后端开发人员来说,flex布局算是最友好的了,因为它操作简单方便
一、flex 布局简介
flex
全称是
flexible Box
,意为
弹性布局
,用来为盒状模型提供布局,任何容器都可以指定为flex布局。通过给父盒子添加flex属性即可开启弹性布局,来控制子盒子的位置和排列方式。
父容器可以统一设置子容器的排列方式,子容器也可以单独设置自身的排列方式,如果两者同时设置,以子容器的设置为准
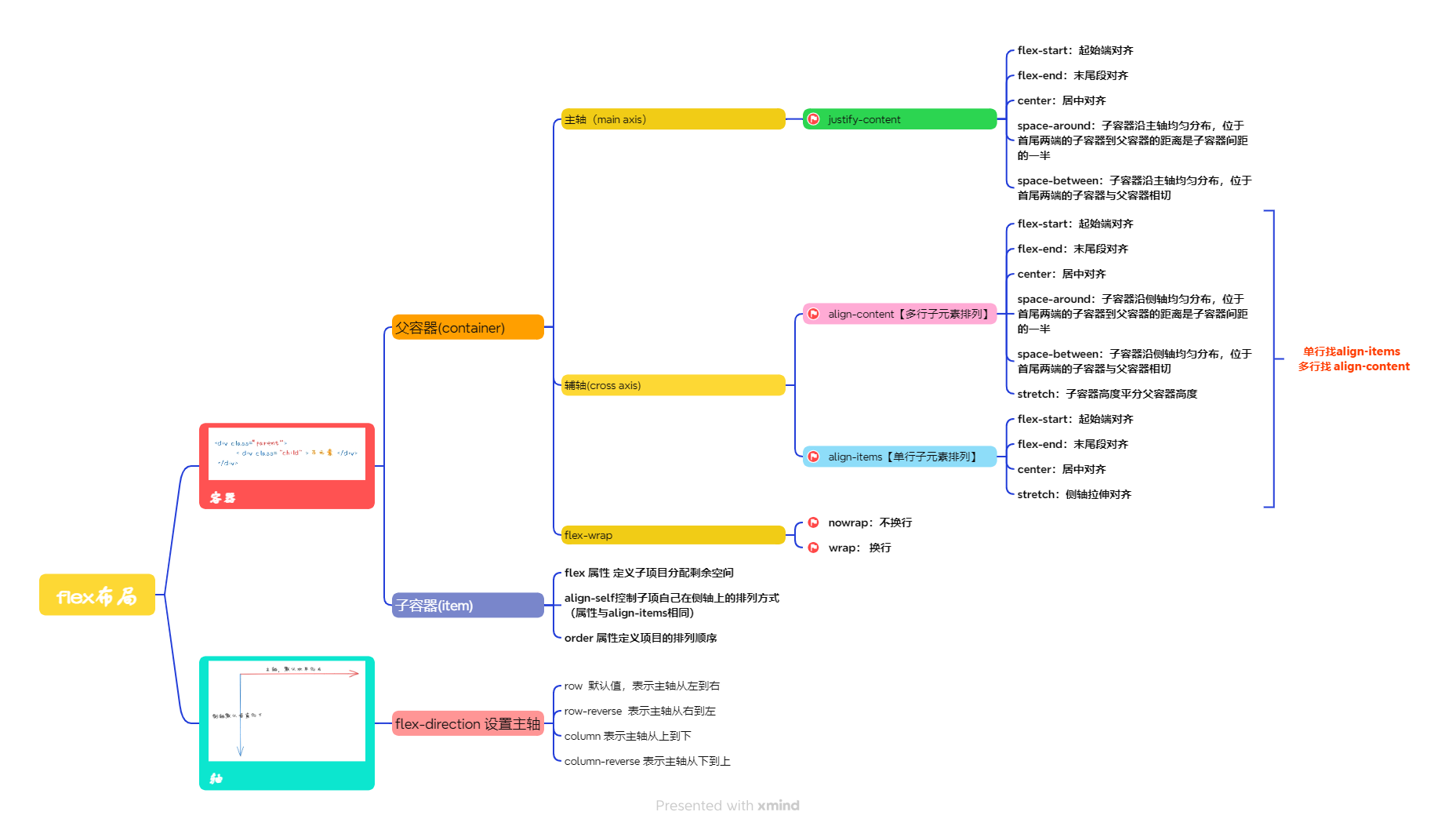
二、flex基本概念
flex的核心概念是
容器
和
轴
,容器包括外层的
父容器
和内层的
子容器
,轴包括
主轴
和
辅轴
<div class="parent">
<div class="child">我是子元素</div>
</div>
2.1 轴
在 flex 布局中,是分为主轴和侧轴两个方向,同样的叫法有 : 行和列、x 轴和y 轴,主轴和交叉轴
默认主轴方向就是 x 轴方向,水平向右
默认侧轴方向就是 y 轴方向,水平向下

注:主轴和侧轴是会变化的,就看
flex-direction
设置谁为主轴,剩下的就是侧轴。而我们的子元素是跟着主轴来排列的
| --flex-direction 值 | --含义 |
|---|---|
row
|
默认值,表示主轴从左到右 |
row-reverse
|
表示主轴从右到左 |
column
|
表示主轴从上到下 |
column-reverse
|
表示主轴从下到上 |
2.2 容器
容器的属性可以作用于父容器(container)或者子容器(item)上
①父容器(container)-->属性添加在父容器上
- flex-direction 设置主轴的方向
- justify-content 设置主轴上的子元素排列方式
- flex-wrap 设置是否换行
- align-items 设置侧轴上的子元素排列方式(单行 )
- align-content 设置侧轴上的子元素的排列方式(多行)
②子容器(item)-->属性添加在子容器上
- flex 属性 定义子项目分配剩余空间,用flex来表示占多少份数
- align-self控制子项自己在侧轴上的排列方式
- order 属性定义项目的排列顺序
三、主轴侧轴设置
3.1 flex-direction: row
flex-direction: row 为默认属性,
主轴沿着水平方向向右,元素从左向右排列。

3.2 flex-direction: row-reverse
主轴沿着水平方向向左,子元素从右向左排列

3.3 flex-direction: column
主轴垂直向下,元素从上向下排列

3.4 flex-direction: column-reverse
主轴垂直向下,元素从下向上排列

四、父容器常见属性设置
4.1 主轴上子元素排列方式
4.1.1 justify-content
justify-content
属性用于定义主轴上子元素排列方式justify-content: flex-start|flex-end|center|space-between|space-around
①
flex-start
:起始端对齐

②
flex-end
:末尾段对齐

③
center
:居中对齐

④
space-around
:子容器沿主轴均匀分布,位于首尾两端的子容器到父容器的距离是子容器间距的一半。

⑤
space-between
:子容器沿主轴均匀分布,位于首尾两端的子容器与父容器相切。

4.2 侧轴上子元素排列方式
4.2.1 align-items 单行子元素排列
这里我们就以默认的x轴作为主轴
①
align-items:flex-start
:起始端对齐

②
align-items:flex-end
:末尾段对齐

③
align-items:center
:居中对齐

④
align-items:stretch
侧轴拉伸对齐
如果设置子元素大小后不生效

4.2.2 align-content 多行子元素排列
设置子项在侧轴上的排列方式 并且只能用于子项出现 换行 的情况(多行),在单行下是没有效果的
我们需要在父容器中添加
flex-wrap: wrap;
flex-wrap: wrap;
是啥意思了,具体会在下一小节中细说,就是当所有子容器的宽度超过父元素时,换行显示
①
align-content: flex-start 起始端对齐
/* 父容器添加如下代码 */
display: flex;
align-content: flex-start;
flex-wrap: wrap;

②
align-content: flex-end :末端对齐
/* 父容器添加如下代码 */
display: flex;
align-content: flex-end;
flex-wrap: wrap;

③
align-content: center: 中间对齐
/* 父容器添加如下代码 */
display: flex;
align-content: center;
flex-wrap: wrap;

④
align-content: space-around:
子容器沿侧轴均匀分布,位于首尾两端的子容器到父容器的距离是子容器间距的一半
/* 父容器添加如下代码 */
display: flex;
align-content: space-around;
flex-wrap: wrap;

⑤
align-content: space-between
:子容器沿侧轴均匀分布,位于首尾两端的子容器与父容器相切。
/* 父容器添加如下代码 */
display: flex;
align-content: space-between;
flex-wrap: wrap;

⑥
align-content: stretch
: 子容器高度平分父容器高度
/* 父容器添加如下代码 */
display: flex;
align-content: stretch;
flex-wrap: wrap;

4.3 设置是否换行
默认情况下,项目都排在一条线(又称”轴线”)上。flex-wrap属性定义,flex布局中默认是不换行的。
①
flex-wrap: nowrap
:不换行
/* 父容器添加如下代码 */
display: flex;
flex-wrap: nowrap;

②
flex-wrap: wrap
: 换行
/* 父容器添加如下代码 */
display: flex;
flex-wrap: wrap;

4.4 align-content 和align-items区别
- align-items 适用于单行情况下, 只有上对齐、下对齐、居中和 拉伸
- align-content适应于换行(多行)的情况下(单行情况下无效), 可以设置 上对齐、下对齐、居中、拉伸以及平均分配剩余空间等属性值。
- 总结就是单行找align-items 多行找 align-content
五、子容器常见属性设置
- flex子项目占的份数
- align-self控制子项自己在侧轴的排列方式
- order属性定义子项的排列顺序(前后顺序)
5.1 flex 属性
flex 属性定义子项目分配剩余空间,用flex来表示占多少份数。
① 语法
.item {
flex: <number>; /* 默认值 0 */
}
②将1号、3号子元素宽度设置成
80px
,其余空间分给2号子元素

5.2 align-self 属性
align-self 属性允许单个项目有与其他项目不一样的对齐方式,可覆盖 align-items 属性。
默认值为 auto,表示继承父元素的 align-items 属性,如果没有父元素,则等同于 stretch。
①
align-self: flex-start 起始端对齐
/* 父容器添加如下代码 */
display: flex;
align-items: center;
/*第一个子元素*/
align-self: flex-start;

②
align-self: flex-end 末尾段对齐
/* 父容器添加如下代码 */
display: flex;
align-items: center;
/*第一个子元素*/
align-self: flex-end;

③
align-self: center 居中对齐
/* 父容器添加如下代码 */
display: flex;
align-items: flex-start;
/*第一个子元素*/
align-self: center;

④
align-self: stretch 拉伸对齐
/* 父容器添加如下代码 */
display: flex;
align-items: flex-start;
/*第一个子元素 未指定高度才生效*/
align-self: stretch;

5.3 order 属性
数值越小,排列越靠前,默认为0。
① 语法:
.item {
order: <number>;
}
② 既然默认是0,那我们将第二个子容器order:-1,那第二个元素就跑到最前面了
/* 父容器添加如下代码 */
display: flex;
/*第二个子元素*/
order: -1;

六、小案例
最后我们用flex布局实现下面常见的商品列表布局

<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>简单商品布局</title>
<style>
.goods{
display: flex;
justify-content: center;
}
p{
text-align: center;
}
span{
margin: 0;
color: red;
font-weight: bold;
}
.goods001{
width: 230px;
height: 322px;
margin-left: 5px;
}
.goods002{
width: 230px;
height: 322px;
margin-left: 5px;
}
.goods003{
width: 230px;
height: 322px;
margin-left: 5px;
}
.goods004{
width: 230px;
height: 322px;
margin-left: 5px;
}
</style>
</head>
<body>
<div class="goods">
<div class="goods001">
<img src="./imgs/goods001.jpg" >
<p>松下(Panasonic)洗衣机滚筒</p>
<span>¥3899.00</span>
</div>
<div class="goods002">
<img src="./imgs/goods002.jpg" >
<p>官方原装浴霸灯泡</p>
<span>¥17.00</span>
</div>
<div class="goods003">
<img src="./imgs/goods003.jpg" >
<p>全自动变频滚筒超薄洗衣机</p>
<span>¥1099.00</span>
</div>
<div class="goods004">
<img src="./imgs/goods004.jpg" >
<p>绿联 车载充电器</p>
<span>¥28.90</span>
</div>
</div>
</body>
</html>
以上就是本期内容的全部,希望对你有所帮助。我们下期再见 (●'◡'●)