前言
前段时间摸了下机器学习,然后我发现其实openCV还是一个很浩瀚的库的,现在也正在写一篇有关yolo的博客,不过感觉理论偏多,所以在学yolo之前先摸一下opencv,简单先写个项目感受感受opencv。
流程
openCV实际上已经有一个比较完整的模型了,下载在
haarcascades
这里我们下haarcascade_frontalface_default.xml以备用。
在做人脸识别的时候流程就比较简单了
- 读取图片
- 创建Haar级联器
- 图片转灰度图(可以不转,转了能更快而已)
- 通过Haar级联分类器来检测人脸面部特征,返回faces结构
- 使用openCV的接口,在原图上框选出结果,并展示
编码
这里代码偏简单,就不过多介绍了
import numpy as np
import cv2
img = './faces/lena.bmp'
#脸部Haar级联器
facer_path = './faces/haarcascade_frontalface_default.xml'
facer = cv2.CascadeClassifier(facer_path)
img = cv2.imread(img)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#执行人脸识别
#现在可以使用Haar级联分类器来检测人脸和其他面部特征
faces = facer.detectMultiScale(gray,1.35,3)
for(x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(0,0,255),2)
roi_img = img[y:y+h, x:x+w]
cv2.imshow('img', img)
cv2.waitKey()
结果:
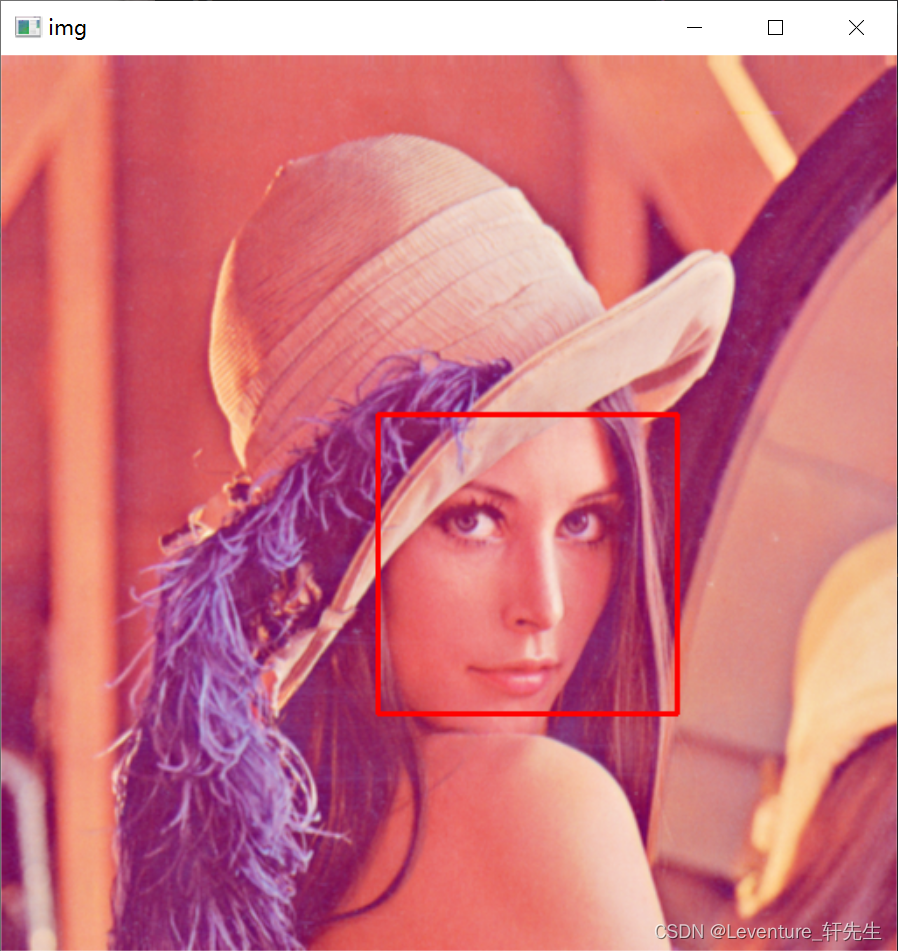
进阶
且不看运行的结果如何,但从结果你就可以看出来,这里只是把人脸从图片中框出来了。但这还不够,我们实际上不仅希望你可以把人脸圈出来,还希望能把人脸分类,比如A是A,B是B这样。
OpenCV提供了3种人脸识别方法,分别是Eigenfaces、Fisherfaces和LBPH。这3种方法都是通过对比样本的特征最终实现人脸识别。因为这3种算法提取特征的方式不一样,侧重点不同,所以不能分出孰优孰劣,只能说每种方法都有各自的识别风格。 OpenCV为每一种人脸识别方法都提供了创建识别器、训练识别器和识别3种方法,这3种方法的语法非常相似。我这里只简单说说Eigenfaces怎么调用,至于其他的两种读者感兴趣可以自己去搜索。
Eigenfaces人脸识别器
Eigenfaces也叫作“特征脸”。Eigenfaces通过PCA(主成分分析)方法将人脸数据转换到另外一个空间维度做相似性计算。在计算过程中,算法可以忽略一些无关紧要的数据,仅识别一些具有代表性的特征数据,最后根据这些特征识别人脸。 开发者需要通过以下3种方法完成人脸识别操作。
(1)通过cv2.face.EigenFaceRecognizer_create()方法创建Eigenfaces人脸识别器,其语法如下:
recognizer = cv2.face.EigenFaceRecognizer_create(num_components, threshold)
参数说明:
num_components:可选参数,PCA方法中保留的分量个数,建议使用默认值。
threshold:可选参数,人脸识别时使用的阈值,建议使用默认值。
返回值说明:
recognizer:创建的Eigenfaces人脸识别器对象。
(2)创建识别器对象后,需要通过对象的train()方法训练识别器。建议每个人都给出2幅以上的人脸图像作为训练样本。train()方法的语法如下:
recognizer.train(src, labels)
对象说明:
recognizer:已有的Eigenfaces人脸识别器对象。 参数说明:
src:用来训练的人脸图像样本列表,格式为list。样本图像必须宽、高一致。
labels:样本对应的标签,格式为数组,元素类型为整数。数组长度必须与样本列表长度相同。样本与标签按照插入顺序一一对应。
(3)训练识别器后可以通过识别器的predict()方法识别人脸,该方法对比样本的特征,给出最相近的结果和评分,其语法如下:
label, confidence = recognizer.predict(src)
对象说明:
recognizer:已有的Eigenfaces人脸识别器对象。 参数说明:
src:需要识别的人脸图像,该图像宽、高必须与样本一致。 返回值说明:
label:与样本匹配程度最高的标签值。
confidence:匹配程度最高的信用度评分。评分小于5000匹配程度较高,0分表示2幅图像完全一样。 下面通过一个实例来演示Eigenfaces人脸识别器的用法。
确定流程
最后我们来确定一下流程:
- 读取数据
- 创建特征脸识别器
- 输入图片和labels开始训练
- 输入需要识别的人脸图像
- 得到输出
我这里把我的训练集整理了以下,名称打在前面。我这里照片是我自己找的,具体的图片训练集大伙可以自己去设定。
具体代码如下,代码的功能可以参考注释
import numpy as np
import cv2
import os
face_path = './faces'
photos = list()
labels = list()
# 设置期望的图像大小
desired_size = (811, 843)
#定义labels
names = {"0":"mengzi","1":"qy","2":"lx","3":"qq"}
# 从当前路径中读取到所有的file
for root, dirs, files in os.walk(face_path):
for file in files:
if '.xml' in file:
continue
img_path = os.path.join(root, file)
img = cv2.imread(img_path, 0)
# 图片需要设置到期望大小,因为模型输入的图片大小都必须是统一值,否则会无法训练
img_resized = cv2.resize(img, desired_size)
# 根据图片的人脸,对应到names,插入到labels
if 'mengzi' in file:
# 读取图像并调整大小
labels.append(0)
elif 'qy' in file:
labels.append(1)
elif 'lx' in file:
labels.append(2)
elif 'qq' in file:
labels.append(3)
else:
continue
photos.append(img_resized)
#创建人脸识别器
recognizer = cv2.face.EigenFaceRecognizer_create()
recognizer.train(photos, np.array(labels))
# 读取测试图像并调整大小
target = cv2.imread(face_path + '/test5.jpg', 0)
target_resized = cv2.resize(target, desired_size)
#输出待识别对象
label, confidence = recognizer.predict(target_resized)
print('confidence = ' + str(confidence))
print(names[str(label)])
结果
这里代码其实也能看得出,最后之能输出图片中人物的label和执行度,这样我们倒是完成了一个分类的工作。但是这里有个问题,就是我们不仅仅需要分类,还需要知道人脸的具体位置。
结合Haar级联器和Eigenfaces人脸识别器实现人脸划分
前言
刚刚说了两种,一个是划分区域,一个是打标签,那么能不能即划分区域,又打上标签呢?当然是可以的,接下来就简单说说怎么做。
流程
实际上流程就是把两个模式结合起来,先使用Haar级联器划分出脸部区域,然后再用Eigenfaces人脸识别器去检查分出的脸部区域的对象名称,然后将标签放在图片上即可。
- 加载Haar级联分类器
- 读取文件并训练Eigenfaces人脸识别器
- 读取目标图片
- 通过Haar级联分类器扫描得到目标图片中的所有人脸框
- 对所有人脸框使用Eigenfaces人脸识别器进行识别
- 画上方框,并打上标签
代码
代码如下:
import numpy as np
import cv2
import os
# 加载Haar级联分类器
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
face_path = './faces'
photos = list()
labels = list()
# 读取学习图片
desired_size = (811, 843)
names = {"0":"mengzi","1":"qy","2":"lx","3":"qq","4":"ch"}
for root, dirs, files in os.walk(face_path):
for file in files:
if '.xml' in file:
continue
img_path = os.path.join(root, file)
img = cv2.imread(img_path, 0)
img_resized = cv2.resize(img, desired_size)
if 'mengzi' in file:
# 读取图像并调整大小
labels.append(0)
elif 'qy' in file:
labels.append(1)
elif 'lx' in file:
labels.append(2)
elif 'qq' in file:
labels.append(3)
elif 'ch' in file:
labels.append(4)
else:
continue
photos.append(img_resized)
# 训练人脸识别器
recognizer = cv2.face.EigenFaceRecognizer_create()
recognizer.train(photos, np.array(labels))
# 读取测试图像
target = cv2.imread(face_path + '/test_ch.jpg')
target_gray = cv2.cvtColor(target, cv2.COLOR_BGR2GRAY)
# 检测人脸
faces = face_cascade.detectMultiScale(target_gray, scaleFactor=1.2, minNeighbors=5, minSize=(30, 30))
# 对于每个检测到的人脸
for (x, y, w, h) in faces:
# 在原图上绘制矩形框出人脸
cv2.rectangle(target, (x, y), (x+w, y+h), (255, 0, 0), 2)
# 提取人脸区域并调整到期望大小
face_region = target_gray[y:y+h, x:x+w]
face_resized = cv2.resize(face_region, desired_size)
# 使用EigenFaceRecognizer进行预测
label, confidence = recognizer.predict(face_resized)
# 将识别的名字和置信度打印在图像上方
cv2.putText(target, f'{names[str(label)]} - {confidence:.2f}', (x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (36,255,12), 2)
# 显示图像
cv2.imshow('Face Recognition', target)
cv2.waitKey(0)
cv2.destroyAllWindows()
测试结果:
虽然打了马赛克,但是实际上结果是可以置信的。在这里,还可以根据置信程度来对不同的人脸进行筛选,比如不想要的脸或者置信程度不高的脸可以再进行舍弃。