【标准解读】物联网安全的系统回顾
本文分享自华为云社区《
【标准解读】物联网安全的系统回顾:研究潜力、挑战和未来方向
》,作者:MDKing。
1 引言
内容提要:物联网(IoT)包括嵌入传感器、软件和数据处理技术的物理对象网络,这些物理对象可以通过互联网与其他设备和系统建立连接并交换数据。物联网设备被融入到各种产品中,从普通的家庭用品到复杂的工业电器。尽管人们对物联网的需求越来越大,但安全问题一直阻碍着它的发展。本文系统回顾了IoT安全研究,关注漏洞、挑战、技术和未来方向。它对该领域的171篇近期出版物进行了调查,对物联网的发展现状、挑战和解决方案进行了全面的讨论。本文概述了物联网架构模式和典型特征,评估了现有的限制,并探索了增强物联网安全性的策略。此外,本文还深入探讨了已知的物联网攻击,并讨论了应对这些挑战的安全对策和机制。对物联网安全的功能需求进行了探索,并对相关技术和标准进行了探索。最后,本文讨论了物联网安全的潜在未来研究方向。

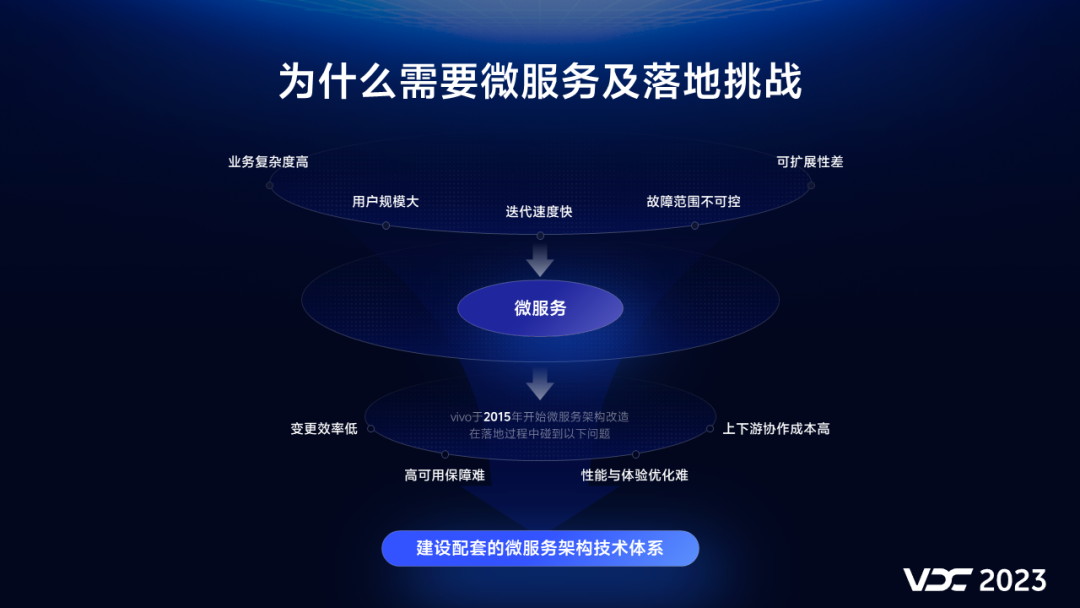
随着物联网技术的发展与普及,消费者网络、工业网络、公共网络等都协同物联网基础设置、云计算等完成支撑物联网设备在线化、自动化、智能化的网络闭环。随着全球物联网规模不断扩大,消费时长涌现了大量的物联网应用,由于大多数制造商在这个时期主要追求市场、关注成本,安全的优先级放的比较低,不会在安全上做过多投入,也不会提供响应的安全补丁与更新,导致长期以来积攒了大量的物联网相关的安全漏洞、隐患(如默认密码、明文传输等),物联网安全事件频发的现象也愈发严重。
本文介绍了
- 物联网架构、基础设施、标准物联网无线技术;
- 基于该领域171篇同行出版物进行了安全攻击(及其缓解措施)的分类;
- 物联网安全的挑战与策略;
- 物联网安全领域未来的研究方向;
2 物联网架构
核心由传感器、执行器、网关、协议、云服务、网络和应用服务器组成。物联网网络需要将所有资源、硬件、软件和系统整合到一个框架中,形成一个集成的、可靠的、高性价比的解决方案。对于不同的物联网应用领域,由于其业务、功能、实现、基础设置的质量等的不同,架构层的复杂度与数量也会不同,但是大致是符合三层或者五层架构规律的。三层是五层的子集。五层架构具体为:
- 感知层:也成为传感器层,使用传感器或者嵌入式系统来识别物体并从他们中收集数据。攻击者会热衷于使用对齐进行攻击,使用攻击者的传感器进行替代。
- 网络层:以有钱或者无线的方式承载与传输传感器收集到的数据。还跟各种只能对象、网络设备以及服务器进行连接。与信息认证、完整性相关的安全问题发生在这一层。
- 中间件层:中间件或者服务管理层具有数据存储、计算、处理和分析等功能。该层通过对接收到的数据进行处理来做出决策,并根据设备地址和名称提供相应的服务。
- 应用层:管理所有的基于从中间件层获取的信息的应用进程。该层对接IoT设备、网络、用户交互。为用户提供高质量的满足需求的应用服务。例如,包括智能家居、智能交通、工业自动化等垂直市场。
- 业务层:管理整个IoT系统,构建流程图、图形、分析结果、IoT设备改进。它对底层的四层进行监控和管理,将每一层的输出与预期进行比较,以确保数据的一致性和有效性,从而改善服务,维护用户隐私。
3 IoT无线技术
LPWAN:低功耗广域网提供了运行在小型、廉价电池上的(可使用数年)大规模物联网网络所需的低功耗、低成本、长距离通信的收发器。连接适合低频、低速传输数据,低移动性设备的场景。该系列技术专为支持大型工业和商业园区的大规模物联网网络而建,应用包括消耗品监控、环境监测、占用检测与资产跟踪。LPWAN包含不同的技术和相互竞争的标准。技术在授权(例如NB-IoT、LTE-M)和非授权(例如MYTHING、LoRa、Sigfox)频谱中运行,在关键网络因素上表现不同。例如,可扩展性和服务质量对于非授权技术和授权LPWAN的功耗可能是重大问题。
蜂窝(3G/4G/5G):为移动消费市场提供可靠的宽带通信,支持各种语音、视频流应用。这些无线技术具有较高的功耗、运营成本,适用无电池供电的传感器网络应用(例如交通路由和车队远程信息处理)。蜂窝连接作为一个出色的回传,使用LPWAN连接到物联网设备和传感器,然后蜂窝网络连接到云端以提供物联网数据,这使得它们成为特定用例的理想选择,如互联汽车或运输和物流车队管理。此外,NB-IoT和LTE-M等新型蜂窝技术旨在通过降低每个传感器的功率要求和数据成本来支持不同的物联网应用。此外,这些支持NB-IoT的设备将从远程位置提供定期更新,同时确保低功耗。
Wi-Fi:无线保真(WiFi)为附近特定范围内的设备提供互联网连接。另一种方式是创建热点,手机或电脑可以通过广播信号与其它设备共享无线或者有线互联网连接。WiFi使用无线电波以特定频率广播信息,其互联网连接的范围和速度取决于环境和它提供的内部或外部覆盖范围。与其他无线技术的一个关键区别是,Wi-Fi以更高的频率传输,这意味着它可以承载更多的数据。但Wi-Fi对功率要求高,覆盖范围有限。这些问题和可扩展性限制使得Wi-Fi在物联网领域不那么受欢迎。此外,由于高能耗要求,Wi-Fi通常不是电池供电的物联网传感器的大型网络的可行解决方案,尤其是在工业物联网和智能建筑场景中。相反,它更适合连接容易连接到电源插座的设备,例如智能家居小工具和电器、数字标牌或安全摄像头。
Zigbee和其他网状协议:ZigBee协议采用802.15.4标准,是一种低功耗、高可靠性的无线网络技术,设计用于短期通信,通常通过在多个传感器节点上中继传感器数据来部署在网状拓扑中。与LPWAN相比,Zigbee提供了更高的数据速率,但同时,由于网状配置,它的能效要低得多。由于其物理距离短(<100米),Zigbee和类似的网状协议(例如,Z-Wave、Thread)非常适合于均匀分布在节点附近的终端物联网应用。因此,Zigbee是家庭自动化应用的绝佳选择,如HVAC控制、智能照明、智能电表、家庭能源、安防监控和智能温控器。此外,Thread专为智能家居产品而设计,并具有IPv6连接功能,可使连接的设备通过Thread移动应用程序进行通信、访问云中的服务或与用户进行交互。
蓝牙和BLE:蓝牙是一种允许各种电子设备无线连接的技术,是IEEE 802.15.1规范【30】中描述的开放标准。为了将蓝牙的应用扩展到无线传感器等功率受限设备,低功耗、灵活性和可扩展性的低功耗蓝牙(BLE)于2010年推出。经典蓝牙最初旨在用于消费设备之间的点对点或点对多点数据交换。低功耗蓝牙针对功耗进行了优化,后来推出来解决小型消费类物联网应用。与Wi-Fi不同,BLE协议是一种高带宽、低范围的无线连接选项,其设计具有成本效益和更低的功耗,只需极少的设备功耗。这项技术经常被用于健身和医疗可穿戴设备(例如,智能手表、血糖仪、脉搏血氧仪等)和智能家居设备(例如,门锁),数据可以很容易地传输到智能手机上并存储在智能手机上。但是,当频繁传输大量数据时,BLE可能不是最有效的解决方案。
RFID:射频识别(RFID)是一种利用无线电波识别和寻找物体的无线通信技术。它包括一个RFID标签、阅读器、天线和后端数据库服务器。RFID阅读器将无线电波转换为数据形式,然后转发到后端服务器,供用户访问和分析数据。RFID使用无线电波在短距离内将少量数据从RFID标签传输到阅读器,为物联网应用提供了定位解决方案。这种物联网无线技术在看不见的情况下工作,并附有标签,在英寸甚至米内即可读取。该技术主要应用于供应链管理和物流。通过将RFID标签链接到各种产品和设备,公司可以实时跟踪其库存和资产,从而实现更好的库存和生产计划以及优化的供应链管理。
4 物联网安全漏洞/缺陷
问题主要特点有:
- 缺乏内置的安全措施;
- IoT设备的受限环境与有限的计算能力;
- 低功耗的设备无法适应强大的安全机制与数据保护;
- 种类繁多的传输技术导致标准化保护方案和协议难建立;
- 关键组件存在漏洞;
- 用户意识不足。
加密不当:保护静态、传输中或处理期间的物联网数据对物联网应用的可靠性和完整性非常重要。尽管许多IoT供应商专注于安全存储,但确保数据在传输中保持安全却经常被忽视。传输中缺乏加密涉及设备与云之间、设备与网关之间、设备与移动应用之间、一个设备与另一个设备之间以及网关与云之间的通信不安全。由于加密算法的强度会受到物联网应用的资源限制的影响,攻击者可以利用加密算法的漏洞泄露敏感信息或控制操作。在整个物联网数据生命周期中进行强加密将有助于保护物联网数据免受损坏和破坏。
认证机制不充分:由于有限的能源和算力限制,在物联网设备上实现复杂的认证机制并不容易。目前支持物联网系统认证的协议有消息队列遥测传输(MQTT)、数据分发服务(DDS)、Zigbee和Zwave。然而,即使开发人员提供了物联网通信、配对和消息传递所需的身份验证工具,物联网设备和网络通信仍有被劫持的机会。例如,认证密钥由于没有安全存储或传输而存在丢失、破坏或损坏的风险。
不正确的补丁管理功能:保持物联网操作系统和嵌入式固件/软件的更新和修复非常重要。随着时间的推移,物联网设备系统中会出现安全漏洞,从而使物联网设备易受攻击。因此,物联网设备需要使用没有已知漏洞的最新系统,并且系统必须具有更新功能,在设备部署后修补任何已知漏洞。此外,网络管理员还应注意更新机制。
访问控制不足:访问控制是连接的物联网设备的一组权限,用于指定哪些用户被授予访问权限,以及允许他们执行的操作。访问控制攻击是指未经授权的用户访问物联网网络。攻击者可以利用ACL(Access Control List)中的漏洞访问机密信息,使个人和组织面临数据泄露的风险。
安全可配置性不足:由于在物联网设备中经常使用硬编码的凭证,它导致安全可配置性不足。弱密码、默认密码和硬编码密码是攻击者入侵物联网设备并进一步发动大规模僵尸网络和其他恶意软件的最简单方式,导致硬编码凭证很容易被破坏。此外,物联网设备附带默认的硬编码设置。因此,一旦这些设置被破坏,攻击者就可以窃取硬编码的默认密码、隐藏的后门以及设备固件中的漏洞。
物理安全不足:物理安全不足是由硬件造成的安全漏洞。由于物联网设备部署在分布式远程环境中,攻击者可以访问和篡改物理层,获取敏感信息,中断物联网设备提供的服务。此外,由于传感器等物联网设备的简单性,在这些物联网设备上构建完整的加密算法并不容易。但是,可以在物联网设备中实施轻量级加密,以确保用户的机密性和安全性。
不必要的开放端口:物联网设备在运行易受攻击的服务时,会开放一些不必要的端口。攻击者可以利用这些端口漏洞访问物联网设备中的敏感信息。
能源获取不足:由于IoT设备的能源有限,攻击者可能会通过生成大量合法或损坏的消息耗尽IoT设备存储的能源,从而使设备对有效进程或用户不可用。
审计机制不足:大多数物联网设备没有完整的日志记录程序,导致物联网设备或服务中产生的恶意活动被隐藏。
5 物联网安全攻击分类
物联网系统的通信架构由感知层、网络层、中间件层和应用层组成。这四层在功能上发挥着不同的作用,本节将这四层中各种可能的物联网攻击进行分类。
感知层
恶意节点攻击:恶意节点是拒绝为网络中其他节点提供服务的节点,其目的是攻击网络中的其他节点或整个网络。恶意节点会通过篡改、重传、丢弃等方式进行攻击。业界专家提出了基于在线学习算法的恶意节点信任检测机制、基于人工神经网络(ANN)的恶意节点检测方法(分类成功率为77.51%)。
边信道攻击(SCA):可用于从设备检索任何敏感信息。敏感信息的泄露可能与时间、功率、电磁信号、声音、光线等因素有关。SCA是一种非侵入式和被动式攻击,在不移除芯片的情况下执行,以获得对设备内部组件的直接访问或主动篡改其任何操作。SCA最常用于针对加密设备。SCA不是针对标准加密算法,而是针对它们在物理设备上的实现,通过测量和分析泄漏的信息(如功率分析、时序分析、电磁分析等)来恢复保密的参数。
虚假数据注入攻击:攻击者可以利用劫持的节点向物联网系统注入错误数据,从而破坏数据完整性。此攻击可导致物联网系统崩溃或故障。或者,攻击者也可以利用这种方法进行DDoS攻击。
窃听/嗅探攻击:窃听也称为嗅探攻击,利用不安全的网络流量访问用户发送或接收的数据。由于执行攻击时网络流量似乎正常,因此很难检测到。此外,它通常发生在无保护或未加密的网络上,攻击者通过在客户端和服务器上安装网络检测嗅探器来截获数据。窃听可能导致个人或组织的重要隐私信息丢失或被截获,存在财务损失和身份被盗的风险。
硬件故障:由于物联网设备用于大多数物联网应用,例如智能家居、智能电网、智能医疗等,因此保护它们免受物联网攻击至关重要。一旦这些设备出现产品故障或遭受任何形式的网络攻击,将严重影响设备系统和用户的生活。有业界专家提出了一种在不干扰IC涉及的情况下使用功率分析、网络流量数据检测恶意活动的技术,可以有效地防止IC设计和测试过程中基于HT的攻击。作者研究了五种随机攻击的IoT-ED行为:隐蔽信道、DoS、ARQ、电力耗尽和模拟攻击。结果表明,所提出的技术可以在不需要设计时干预的情况下,以高达99%的准确率单独检测每个攻击。此外,该技术可以以92%的准确率同时检测所有攻击。
电池耗尽攻击:攻击者通过不断发送请求耗尽资源受限的物联网设备的电池电量,从而导致物联网应用中的节点因电池电量耗尽而拒绝服务。此外,攻击者可以通过使用恶意代码在IoT设备中运行无限循环来耗尽设备的电池,或者人为地增加IoT设备的功耗,以防止设备进入睡眠或省电模式。
对设备的未授权访问:由于物联网设备的数量和种类不断增长,以及生产者使用默认密码和内置凭证,物联网设备容易受到无人值守的攻击。此外,开发人员故意将不安全的API留给远程访问,并忽略定期的系统审计,对物联网设备构成了安全威胁。
网络层
身份仿冒攻击:是一种攻击者伪装身份,通过身份验证获取信任的攻击方法。攻击者利用身份验证机制中的缺陷将自己伪装成他人,并使用各种方法和技术窃取受害者的敏感信息。欺骗攻击包括电子邮件欺骗、DNS欺骗、IP欺骗、DdoS欺骗和ARP欺骗。
路由攻击:路由攻击是指通过发送伪造的路由信息,产生错误的路由,干扰正常的路由。路由攻击有两种类型。一种是通过伪造带有错误路由信息的合法路由控制报文,在合法节点上生成错误的路由表项,增加网络传输成本,破坏合法路由数据,或者将大量流量引向其他节点,快速消耗能量。另一种攻击是伪造带有非法头域的数据包。
恶意节点攻击:恶意节点是拒绝为网络中其他节点提供服务的节点,其目的是攻击网络中的其他节点或整个网络。恶意节点会通过篡改、重传、丢弃等方式进行攻击。业界专家提出了基于在线学习算法的恶意节点信任检测机制、基于人工神经网络(ANN)的恶意节点检测方法(分类成功率为77.51%)。
窃听/嗅探攻击:窃听也称为嗅探攻击,利用不安全的网络流量访问用户发送或接收的数据。由于执行攻击时网络流量似乎正常,因此很难检测到。此外,它通常发生在无保护或未加密的网络上,攻击者通过在客户端和服务器上安装网络检测嗅探器来截获数据。窃听可能导致个人或组织的重要隐私信息丢失或被截获,存在财务损失和身份被盗的风险。
分布式拒绝服务(DDos)/Dos攻击:使用多台/单台计算器或机器来泛洪目标资源,直到目标流域流量过载而无法响应正常请求或者崩溃,从而阻止合法用户访问预期的服务或者资源。
中间人(MITM)攻击:中间人(Man-in-the-Middle,MITM)攻击的目标是捕获和修改两个独立系统之间的通信,并截获其中的信息。由于物联网设备实时共享数据,因此MITM攻击可以同时攻击多个物联网设备,导致严重的故障。常见的MITM攻击类型包括电子邮件劫持、Wi-Fi窃听、会话劫持和域名系统(DNS)欺骗。
访问控制攻击:访问控制(Access control)是连接物联网设备的一组权限,用于指定哪些用户被授予访问权限,以及允许他们执行的操作。访问控制攻击是指未经授权的用户可以访问物联网网络。攻击者可以利用ACL(Access control List)中的漏洞访问机密信息,使个人和组织面临数据泄露的风险。
中间件层
中间人(MITM)攻击:中间人(Man-in-the-Middle,MITM)攻击的目标是捕获和修改两个独立系统之间的通信,并截获其中的信息。由于物联网设备实时共享数据,因此MITM攻击可以同时攻击多个物联网设备,导致严重的故障。常见的MITM攻击类型包括电子邮件劫持、Wi-Fi窃听、会话劫持和域名系统(DNS)欺骗。
SQL注入攻击:随着SQL驱动的物联网应用的快速增长,中间件层的SQL注入攻击(SQLIA)威胁显著增加。SQL注入(SQLi)是一种针对使用SQL的数据库的网络攻击。该攻击通过向应用程序中注入恶意SQL语句来干扰或操纵数据库,并获得对潜在有价值的信息的访问。
泛洪攻击:泛洪攻击是DoS攻击的一种,其目的是向特定设备发送一系列数据包请求,使目标服务器泛洪,从而消耗其资源,使其无法处理来自合法用户的请求。
云恶意软件注入:云恶意软件注入攻击将恶意代码或虚拟机注入到云中。攻击者通过尝试创建虚拟机实例或恶意服务模块来伪装成合法服务,然后设法获得来自受害服务的服务请求的访问权限,并捕获敏感数据。
签名包装攻击:在签名包装攻击中,攻击者通过破坏签名算法或利用SOAP(Simple Object Access Protocol)中的漏洞来执行或修改窃听消息。
应用层
虚假数据注入攻击:攻击者可以利用劫持的节点向物联网系统注入错误数据,从而破坏数据完整性。此攻击可导致物联网系统崩溃或故障。或者,攻击者也可以利用这种方法进行DDoS攻击。
分布式拒绝服务(DDos)/Dos攻击:使用多台/单台计算器或机器来泛洪目标资源,直到目标流域流量过载而无法响应正常请求或者崩溃,从而阻止合法用户访问预期的服务或者资源。
身份仿冒攻击:是一种攻击者伪装身份,通过身份验证获取信任的攻击方法。攻击者利用身份验证机制中的缺陷将自己伪装成他人,并使用各种方法和技术窃取受害者的敏感信息。欺骗攻击包括电子邮件欺骗、DNS欺骗、IP欺骗、DdoS欺骗和ARP欺骗。
访问控制攻击:访问控制(Access control)是连接物联网设备的一组权限,用于指定哪些用户被授予访问权限,以及允许他们执行的操作。访问控制攻击是指未经授权的用户可以访问物联网网络。攻击者可以利用ACL(Access control List)中的漏洞访问机密信息,使个人和组织面临数据泄露的风险。
暴力/字典攻击:暴力攻击使用试错来破解密码、登录凭证和加密密钥,从而允许对个人账户以及组织的系统和网络进行未经授权的访问。攻击者通过在计算机上测试各种用户名和密码来获取用户的登录信息。字典攻击是暴力破解攻击的一种基本形式。与暴力破解攻击(攻击者只攻击单个用户)不同,字典攻击会破坏密码数据库的加密,从而获得对所有服务或网络用户帐户的访问权限。攻击者选择一个目标,并通过遍历字典并使用特定字符或数字修改单词来针对该个人的用户名测试可能的密码。
其它(网关)
后门接口:攻击者利用IoT网关的额外端口进行后门认证,导致用户信息泄露。因此,物联网网关制造商应仅实现必要的接口和协议,并限制最终用户使用的服务和功能。
端到端加密:Suresh和Priyadarsini 提出了一种增强的现代对称加密方法来保护数据,以确保在云端物联网数据传输和存储中的数据安全。提出的增强型现代对称数据加密(EMSDE)是一种使用单个密钥加密和解密数据的分组密码加密技术,旨在保护基于云的物联网环境中的数据。结果表明,与其他现有加密技术相比,提出的EMSDE需要更少的加密和解密时间,并且它是专门为保护存储在云中的数据免受物联网设备的侵害而量身定制的。
固件更新:由于大多数物联网设备都是资源受限的,因此它们没有用户界面或计算能力来下载和安装固件更新。但是,物联网网关可用于下载和应用固件更新。因此,请确保物联网网关下载当前版本和新版本的固件,并检查签名的有效性。
6 当前物联网的安全对策
针对IoT安全挑战与机制,对当前的IoT安全解决方案进行分类
应对IoT安全挑战的安全对策
数据安全相关:由于物联网设备的不断增加,产生了大量的数据,其中不乏个人信息等机密数据,会带来敏感数据丢失等安全问题。因此,物联网设备和服务需要正确、安全地处理敏感数据,同时保证传输数据的机密性和真实性。密码学是解决这一挑战的有效方法。数据加密和解密可以确保数据的隐私和机密性得到保护,并将数据被盗的风险降至最低。
对称密钥加密:也称为秘密密钥加密,其中消息的发送者和接收者使用相同的密钥对消息进行加密和解密。它是一种简单的加密形式,但问题是发送方和接收方必须安全地交换密钥,以避免密钥被泄露。
非对称密钥密码学又称公钥密码学,使用一对密钥(公钥和私钥)对消息进行加密和解密。公钥用于加密,私钥用于解密。与对称密钥密码不同的是,即使使用公钥进行加密,也没有办法用它来解密消息,只能使用私钥来解密消息。而且,私钥不能从公钥推导出来,但公钥可以从私钥推导出来。私钥不应该被分发,而只保留给所有者。公钥可以在网络上共享,因此可以通过公钥传输消息。
哈希函数:是不可逆的单向函数,算法不使用任何密钥。它将给定的字符串转换为固定长度的字符串,使明文内容不可恢复。它是安全的,因为破解哈希的唯一方法是尝试所有可能的输入,直到攻击者得到相同的哈希。业界专家提出了混合密码系统、新颖的随机秘钥技术(在物联网设备之间共享一个随机矩阵)等为物联网系统提供更适合的加密算法。
身份验证和访问控制:物联网设备的认证和访问控制是物联网的安全挑战之一。如果IoT设备在没有正确认证的情况下接入IoT网络,则IoT设备可能成为攻击者的目标,从而危害系统。因此,物联网设备应严格规范远程和直接服务器访问,防止未经授权的访问。
- 业界专家提出了一种呼和访问控制(HAC)模型,通过将新的属性插入到基于角色的访问控制(RBAC)实体中,实现了角色级别上对COI(动态权益冲突)的有效处理。
弱口令:弱口令可能导致物联网设备受到安全攻击。易受攻击的密码包括人类经常使用的默认密码,存在安全隐患。因此,需要一种可靠的密码管理机制来降低弱口令带来的安全风险。一种解决方案是将密码设置为区分大小写的混合字符,个人应避免在不同的设备上使用相同的密码。此外,重要设备上的密码需要经常修改。
- 业界专家提出了一种基于图形的密码方案,使用网格图和眼睛凝视来推断文本密码、无需接触用户界面。该方案有易于记忆、不易被破解、资源消耗最小、随机性强、可更改等优点。
安全更新机制缺失:保持物联网设备的更新和维修非常重要。随着时间的推移,物联网设备系统中会出现安全漏洞,从而使物联网设备易受攻击。它要求物联网设备使用最新的系统,没有任何已知的漏洞,并且系统必须具有更新功能,以在设备部署后修补任何已知的漏洞。此外,网络管理员还应注意更新机制。
安全设备机制缺失:物联网设备的安全挑战包括受限设备、未授权设备和使用不支持的旧操作系统。旧的遗留系统和连接设备(如患者监护仪、呼吸机、输液泵和恒温器)的组合具有非常差的安全功能,特别容易受到攻击。受限设备是指CPU、内存和电源资源有限的小型设备。它们可以组成一个网络,其中它们被称为约束节点。通常,这些受限节点通过低功耗无线协议(如BLE)进行通信。
恶意软件和勒索软件:黑客可以通过发现物联网网络中的漏洞,并将其与恶意软件或勒索软件相结合来发动勒索软件攻击。在勒索软件攻击中,黑客控制系统或加密有价值的信息,然后向受害者索要赎金。
- 业界专家提出了一种基于可打印字符串的跨平台物联网恶意软件分类方法,通过不同的特征选择方法获得有用的特征,使用一组ML算法对恶意软件进行分类,训练集上有98%的准确率。
- 业界专家提出了一种基于CNN模型的物联网恶意软件检测动态分析,旨在减轻恶意软件对物联网是被的损害,在嵌套的云环境中动态分析物联网恶意软件,并使用调试、特征提取、特征预处理、特征选择和分类来训练、验证和测试以创建推荐模型。能够准确地检测出具有多种智能攻击技术的新型和变种物联网恶意软件。
物联网安全机制的安全对策
物联网安全中的机器学习(ML):通过使用复杂的算法分析大量数据,ML可以构建模型并预测研究对象的未来行为。ML架构一般分为三种,即监督学习、无监督学习和强化学习。对于将ML应用于物联网安全的研究兴趣激增。
物联网安全中的边缘计算:边缘计算使用云的概念,将边缘服务器放在最终用户和云服务器之间,在数据源或附近进行计算,而不是依赖云来完成所有工作。边缘计算解决了云计算的时延、通信速度等问题。边缘的近即时计算和分析减少了延迟,从而大幅提高了性能,而且边缘计算可以处理大量数据,这些数据不再需要昂贵的带宽,从而降低了云服务的负载和成本。此外,边缘计算还可以分析私有网络中的敏感物联网数据,以保护这些数据.
- 业界专家借助边缘计算提出了自动平衡功耗来节能的方案;自动检测缓解欺骗攻击和网络入侵攻击的方案;轻量级边缘服务器身份认证的方案等来解决IDS、网络性能、功耗、欺骗攻击、网络入侵、认证等物联网安全问题.
物联网安全中的云计算:云计算是一种基于应用的软件基础设施,可以通过互联网向云数据中心传输和存储数据。云计算是一种按需计算服务,允许用户轻松访问集中式云系统中的数据和程序。云计算架构包括前端和后端两个基本组件。在云计算架构中,前端作为客户端工作,通过互联网与后端通信。服务提供商使用后端管理云计算服务所需的所有资源,包括大容量数据存储设备、安全机制、虚拟机、服务器、流量控制机制等。云计算可以分为三种模式,即基础设施即服务(IaaS)、平台即服务(PaaS)和软件即服务(SaaS)。
- 云计算是物联网的重要组成部分,它聚合服务器,分析从传感器获得的信息,提高处理能力,并提供良好的存储容量[12]。云计算为用户提供了强大的安全措施。云计算系统可以对用户的访问进行管理和验证,防止数据泄露。此外,云计算还可以实现数据加密和身份验证程序,以防止未经授权的用户访问物联网设备或网络
- 云计算可以解决DoS攻击、访问控制、欺骗攻击、DDoS攻击、数据完整性、认证授权等物联网安全问题。
区块链在物联网安全中的应用:区块链系统的核心由系统参与者共享的分布式数字分类账组成,该分类账驻留在互联网上。已验证的交易或事件记录在台账中,不可修改或删除。此外,区块链允许用户社区记录和共享信息。区块链提供强大的数据篡改保护,锁定对物联网设备的访问,并允许关闭物联网网络中的损坏设备。
- 区块链可以解决数据完整性、隐私保护、安全通信、数据保密、安全存储、认证、访问控制等物联网安全问题。
7 未来研究方向
网关安全措施增强:物联网设备通过网关接入互联网,但由于网络管理内部缺乏完善的安全机制,如缺乏认证认证等,需要在这些网关上实施更多的安全措施,以提高物联网系统的整体安全性。
通过机器学习、区块链技术探索系统吞吐量和共识算法问题:由于连接的物联网设备数量众多,需要考虑系统吞吐量和共识算法问题。否则会降低系统处理效率,导致物联网设备无法正常工作。可以探索机器学习和区块链技术来解决这些问题。
轻量级加密安全协议:为了满足物联网设备的资源约束,安全协议需要设计轻量级的加密方案,并考虑物联网的可扩展性。
轻量级认证:轻量级认证也是未来安全研究方向之一。这一点非常重要,因为验证用户身份可以避免敏感数据泄露并提高物联网网络性能。
生物识别认证机制:生物识别安全是一种身份验证机制,它使用人类的生理或行为特征来验证个人的身份。未来的研究需要考虑使用生物识别技术对用户进行身份验证的成本效益以及生物识别技术的稳定性。
打造物联网安全技术标准生态圈:打造物联网生态圈,推动物联网安全技术标准和合规。此外,研究人员还需要考虑提高物联网应用的安全算法的计算速度,以及考虑授权和访问控制。
物联网隐私数据存储安全:另一个未来的研究方向是保护物联网数据存储的安全。使用基于云计算和区块链的解决方案是解决这一问题的方法之一。由于区块链中的交易是公开的,因此在未来的研究中需要考虑个人隐私问题。此外,还需要考虑使用云计算的成本。
边缘计算的能耗平衡:使用边缘计算可以缓解欺骗攻击,但在未来的研究中需要考虑边缘物联网设备有限的功率容量,因为攻击者可以在CPU上执行大量操作以缩短电池寿命。
8 结论
这篇调查文章详细介绍了物联网,分析了物联网架构、基础设施和无线技术。此外,本文还介绍了当前的安全漏洞和缓解策略。此外,文章还分析了针对不同层次的常见物联网安全攻击,并研究了当前针对这些攻击的解决方案。为了解决IoT的安全问题,本文介绍了IoT的安全目标,并根据挑战和机制对现有的解决方案进行了分类。本文介绍了这些解决方案的详细架构,以及它们如何解决IoT安全挑战,并对这些解决方案进行了比较。最后,详细讨论了提高物联网安全的未来研究方向,有助于进一步开展物联网安全研究,为个人和组织提出新技术和解决方案奠定基础。