原文链接:
https://gaoyubo.cn/blogs/f57f32cf.html
前置
Golang实现JAVA虚拟机-解析class文件
Golang实现JAVA虚拟机-运行时数据区
一、字节码、class文件、指令集的关系
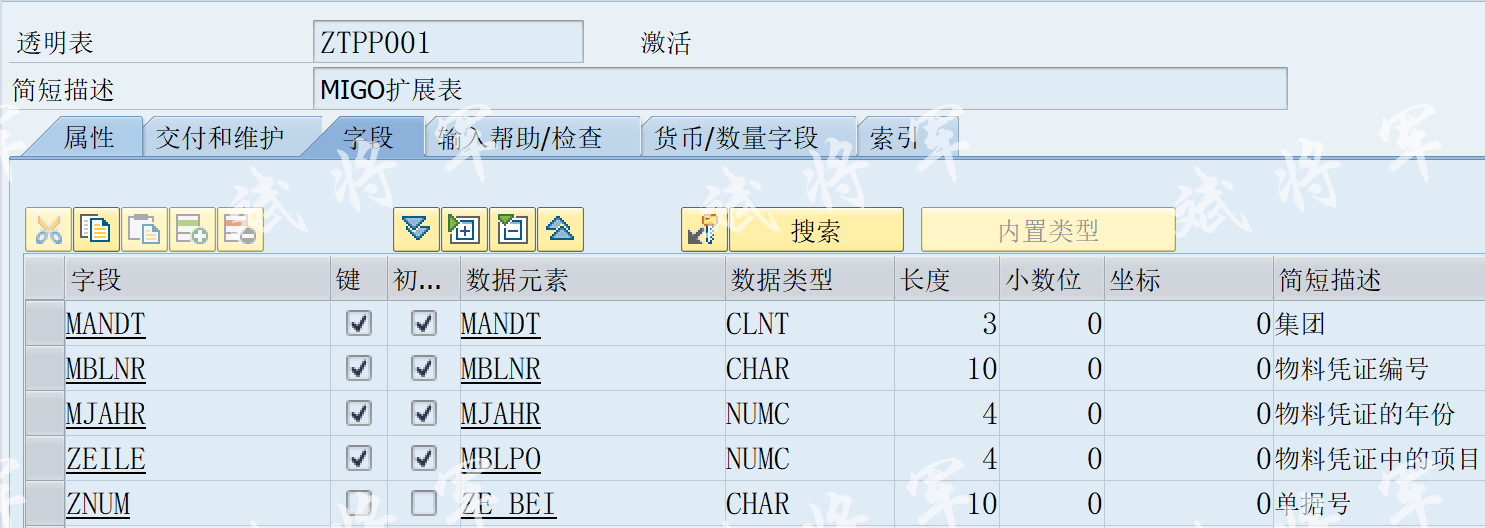
class文件(二进制)和字节码(十六进制)的关系
class文件
字节码
如图:操作码为B2,助记符为助记符是
getstatic
。它的操作数是0x0002,代表常量池里的第二个常量。
操作数栈和局部变量表只存放数据的值, 并不记录数据类型。
结果就是:指令必须知道自己在操作什么类型的数据。
这一点也直接反映在了操作码的
助记符
上。
例如,iadd指令:对int值进行加法操作;
dstore指令:把操作数栈顶的double值弹出,存储到局部变量表中;
areturn:从方法中返回引用值。
助记符
如果某类指令可以操作不同类型的变量,则助记符的第一个字母表示变量类型。助记符首字母和变量类型的对应关系如下:

指令分类
Java虚拟机规范把已经定义的205条指令按用途分成了11类, 分别是:
- 常量(constants)指令
- 加载(loads)指令
- 存储(stores)指令
- 操作数栈(stack)指令
- 数学(math)指令
- 转换(conversions)指令
- 比较(comparisons)指令
- 控制(control)指令
- 引用(references)指令
- 扩展(extended)指令
- 保留(reserved)指令:
- 操作码:202(0xCA),助记符:breakpoint,用于调试器的断点调试
- 254(0xFE),助记符:impdep1
- 266(0xFF),助记符:impdep2
- 这三条指令不允许出现在class文件中
本章将要实现的指令涉及11类中的9类
二、JVM执行引擎
执行引擎是Java虚拟机四大组成部分中一个核心组成(另外三个分别是
类加载器子系统
、
运行时数据区
、
垃圾回收器
),
Java虚拟机的执行引擎主要是用来执行Java字节码。
它有两种主要执行方式:通过
字节码解释器
执行,通过
即时编译器
执行
解释和编译
在了解字节码解释器和即使编译器之前,需要先了解
解释
和
编译
- 解释是将代码逐行或逐条指令地转换为机器代码并立即执行的方式,适合实现跨平台性。
- 编译是将整个程序或代码块翻译成机器代码的方式,生成的机器代码可反复执行,通常更快,但不具备跨平台性。
字节码解释器
字节码解释器将逐条解释执行Java字节码指令。这意味着它会逐个读取字节码文件中的指令,并根据每个指令执行相应的操作。虽然解释执行相对较慢。
逐行解释和执行代码。它会逐行读取源代码或字节码,将每一行翻译成计算机指令,然后立即执行该指令。
因此具有平台无关性,因为字节码可以在不同的平台上运行。
即时编译器(Just-In-Time Compiler,JIT)
即时编译器将字节码编译成本地机器代码,然后执行本地代码。
这种方式更快,因为它避免了字节码解释的过程,但编译需要一些时间。
即时编译器通常会选择性地编译某些热点代码路径,以提高性能。
解释器规范
Java虚拟机规范的2.11节介绍了Java虚拟机解释器的大致逻辑,如下所示:
do {
atomically calculate pc and fetch opcode at pc;
if (operands) fetch operands;
execute the action for the opcode;
} while (there is more to do);
- 从当前程序计数器(Program Counter,通常简称为 PC)中获取当前要执行的字节码指令的地址。
- 从该地址获取字节码指令的操作码(opcode),并执行该操作码对应的操作。
- 如果指令需要操作数(operands),则获取操作数。
- 执行指令对应的操作。
- 更新 PC,以便继续执行下一条字节码指令。
- 循环执行上述步骤,直到没有更多的指令需要执行。
每次循环都包含三个部分:计算pc、指令解码、指令执行
可以把这个逻辑用Go语言写成一个for循环,里面是个大大的
switch-case
语句。但这样的话,代码的可读性将非常差。
所以采用另外一种方式:把指令抽象成接口,解码和执行逻辑写在具体的指令实现中。
这样编写出的解释器就和Java虚拟机规范里的伪代码一样简单,伪代码如下:
for {
pc := calculatePC()
opcode := bytecode[pc]
inst := createInst(opcode)
inst.fetchOperands(bytecode)
inst.execute()
}
三、指令和指令解码
本节先定义指令接口,然后定义一个结构体用来辅助指令解码
Instruction接口
为了便于管理,把每种指令的源文件都放在各自的包里,所有指令都共用的代码则放在
base包
里。
因此
instructions目录
下会有如下10个子目录:

base目录
下创建
instruction.go
文件,在其中定义
Instruction接口
,代码如下:
type Instruction interface {
FetchOperands(reader *BytecodeReader)
Execute(frame *rtda.Frame)
}
FetchOperands()
方法从字节码中提取操作数,
Execute()
方法执行指令逻辑。
有很多指令的操作数都是类似的。为了避免重复代码,按照操作数类型定义一些结构体,并实现
FetchOperands()
方 法。
无操作数指令
在
instruction.go
文件中定义
NoOperandsInstruction
结构体,代码如下:
type NoOperandsInstruction struct {}
NoOperandsInstruction
表示没有操作数的指令,所以没有定义 任何字段。
FetchOperands()
方法自然也是空空如也,什么也不用 读,代码如下:
func (self *NoOperandsInstruction) FetchOperands(reader *BytecodeReader) {
// nothing to do
}
跳转指令
定义
BranchInstruction结构体
,代码如下:
type BranchInstruction struct {
//偏移量
Offset int
}
BranchInstruction
表示跳转指令,
Offset字段
存放跳转偏移量。
FetchOperands()
方法从字节码中读取一个
uint16
整数,转成int后赋给
Offset字段
。代码如下:
func (self *BranchInstruction) FetchOperands(reader *BytecodeReader) {
self.Offset = int(reader.ReadInt16())
}
存储和加载指令
存储和加载类指令需要根据索引存取局部变量表,索引由单字节操作数给出。把这类指令抽象成
Index8Instruction结构体
,定义
Index8Instruction结构体
,代码如下:
type Index8Instruction struct {
//索引
Index uint
}
FetchOperands()
方法从字节码中读取一个int8整数,转成
uint
后赋给
Index字段
。代码如下:
func (self *Index8Instruction) FetchOperands(reader *BytecodeReader) {
self.Index = uint(reader.ReadUint8())
}
访问常量池的指令
有一些指令需要访问运行时常量池,
常量池索引
由两字节操作数给出,用
Index字段
表示常量池索引。定义
Index16Instruction结构体
,代码如下:
type Index16Instruction struct {
Index uint
}
FetchOperands()
方法从字节码中读取一个
uint16
整数,转成
uint
后赋给
Index字段
。代码如下
func (self *Index16Instruction) FetchOperands(reader *BytecodeReader) {
self.Index = uint(reader.ReadUint16())
}
指令接口和“抽象”指令定义好了,下面来看
BytecodeReader结构体
BytecodeReader结构体
base目录
下创建
bytecode_reader.go
文件,在 其中定义
BytecodeReader结构体
type BytecodeReader struct {
code []byte // bytecodes
pc int
}
code字段
存放字节码,pc字段记录读取到了哪个字节。
为了避免每次解码指令都新创建一个
BytecodeReader
实例,给它定义一个
Reset()
方法,代码如下:
func (self *BytecodeReader) Reset(code []byte, pc int) {
self.code = code
self.pc = pc
}
面实现一系列的
Read()
方法。首先是最简单的
ReadUint8()
方法,代码如下:
func (self *BytecodeReader) ReadUint8() uint8 {
i := self.code[self.pc]
self.pc++
return i
}
- 从
self.code
字节切片中的
self.pc
位置读取一个字节(8 位)的整数值。
- 然后将
self.pc
的值增加1,以便下次读取下一个字节。
- 最后,返回读取的字节作为无符号 8 位整数
ReadInt8()
方法调用
ReadUint8()
,然后把读取到的值转成
int8
返回,代码如下:
func (self *BytecodeReader) ReadInt8() int8 {
return int8(self.ReadUint8())
}
ReadUint16()
连续读取两字节
func (self *BytecodeReader) ReadUint16() uint16 {
byte1 := uint16(self.ReadUint8())
byte2 := uint16(self.ReadUint8())
return (byte1 << 8) | byte2
}
ReadInt16()
方法调用
ReadUint16()
,然后把读取到的值转成
int16
返回,代码如下:
func (self *BytecodeReader) ReadInt16() int16 {
return int16(self.ReadUint16())
}
ReadInt32()
方法连续读取4字节,代码如下:
func (self *BytecodeReader) ReadInt32() int32 {
byte1 := int32(self.ReadUint8())
byte2 := int32(self.ReadUint8())
byte3 := int32(self.ReadUint8())
byte4 := int32(self.ReadUint8())
return (byte1 << 24) | (byte2 << 16) | (byte3 << 8) | byte4
}
在接下来的小节中,将按照分类依次实现约150条指令,占整个指令集的3/4
四、常量指令
常量指令把常量推入操作数栈顶。
常量可以来自三个地方:隐含在
操作码里
、
操作数
和
运行时常量池
。
常量指令共有21条,本节实现其中的18条。另外3条是
ldc
系列指令,用于从运行时常量池中加载常量,将在后续实现。
nop指令
nop指令
是最简单的一条指令,因为它什么也不做。
在
\instructions\constants
目录下创建
nop.go
文件,在其中实现nop指令,代码如下:
type NOP struct{ base.NoOperandsInstruction }
func (self *NOP) Execute(frame *rtda.Frame) {
// 什么也不用做
}
const系列指令
这一系列指令把
隐含在操作码中的常量值
推入操作数栈顶。
constants
目录下创建
const.go
文件,在其中定义15条指令,代码如下
type ACONST_NULL struct{ base.NoOperandsInstruction }
type DCONST_0 struct{ base.NoOperandsInstruction }
type DCONST_1 struct{ base.NoOperandsInstruction }
type FCONST_0 struct{ base.NoOperandsInstruction }
type FCONST_1 struct{ base.NoOperandsInstruction }
type FCONST_2 struct{ base.NoOperandsInstruction }
type ICONST_M1 struct{ base.NoOperandsInstruction }
type ICONST_0 struct{ base.NoOperandsInstruction }
type ICONST_1 struct{ base.NoOperandsInstruction }
type ICONST_2 struct{ base.NoOperandsInstruction }
type ICONST_3 struct{ base.NoOperandsInstruction }
type ICONST_4 struct{ base.NoOperandsInstruction }
type ICONST_5 struct{ base.NoOperandsInstruction }
type LCONST_0 struct{ base.NoOperandsInstruction }
type LCONST_1 struct{ base.NoOperandsInstruction }
以3条指令为例进行说明。aconst_null指令把null引用推入操作 数栈顶,代码如下
func (self *ACONST_NULL) Execute(frame *rtda.Frame) {
frame.OperandStack().PushRef(nil)
}
dconst_0指令把double型0推入操作数栈顶,代码如下
func (self *DCONST_0) Execute(frame *rtda.Frame) {
frame.OperandStack().PushDouble(0.0)
}
iconst_m1指令把int型-1推入操作数栈顶,代码如下:
func (self *ICONST_M1) Execute(frame *rtda.Frame) {
frame.OperandStack().PushInt(-1)
}
bipush和sipush指令
bipush指令
从操作数中获取一个byte型整数,扩展成int型,然后推入栈顶。
sipush指令
从操作数中获取一个short型整数,扩展成int型,然后推入栈顶。
constants目录下创建 ipush.go文件,在其中定义bipush和sipush指令,代码如下:
type BIPUSH struct { val int8 } // Push byte
type SIPUSH struct { val int16 } // Push short
BIPUSH结构体实现方法如下:
type BIPUSH struct {
val int8
}
func (self *BIPUSH) FetchOperands(reader *base.BytecodeReader) {
self.val = reader.ReadInt8()
}
func (self *BIPUSH) Execute(frame *rtda.Frame) {
i := int32(self.val)
frame.OperandStack().PushInt(i)
}
五、加载指令
加载指令用于从局部变量表获取变量,并将其推入操作数栈顶。总共有 33 条加载指令,它们按照所操作的变量类型可以分为 6 类:
aload
系列指令:用于操作
引用类型
变量。
dload
系列指令:用于操作
double
类型变量。
fload
系列指令:用于操作
float
变量。
iload
系列指令:用于操作
int
变量。
lload
系列指令:用于操作
long
变量。
xaload
指令:用于操作数组。
本节将实现其中的 25 条加载指令。数组和xaload系列指令先不实现。
loads目录
下创建
iload.go
文件,在其中定义5 条指令,代码如下:
完整代码移步:
jvmgo
// 从局部变量表加载int类型
type ILOAD struct{ base.Index8Instruction }
type ILOAD_0 struct{ base.NoOperandsInstruction }
type ILOAD_1 struct{ base.NoOperandsInstruction }
type ILOAD_2 struct{ base.NoOperandsInstruction }
type ILOAD_3 struct{ base.NoOperandsInstruction }
为了避免重复代码,定义一个函数供iload系列指令使用,代码如下:
func _iload(frame *rtda.Frame, index uint) {
val := frame.LocalVars().GetInt(index)
frame.OperandStack().PushInt(val)
}
iload指令的索引来自操作数,其Execute()方法如下:
func (self *ILOAD) Execute(frame *rtda.Frame) {
_iload(frame, uint(self.Index))
}
其余4条指令的索引隐含在操作码中,以iload_1为例,其 Execute()方法如下:
func (self *ILOAD_1) Execute(frame *rtda.Frame) {
_iload(frame, 1)
}
六、存储指令
和加载指令刚好相反,存储指令把变量从操作数栈顶弹出,然后存入局部变量表。
和加载指令一样,存储指令也可以分为6类。以
lstore系列
指令为例进行介绍。
完整代码移步:
jvmgo
instructions\stores目录下创建
lstore.go
文件,在其中定义5条指令,代码如下:
type LSTORE struct{ base.Index8Instruction }
type LSTORE_0 struct{ base.NoOperandsInstruction }
type LSTORE_1 struct{ base.NoOperandsInstruction }
type LSTORE_2 struct{ base.NoOperandsInstruction }
type LSTORE_3 struct{ base.NoOperandsInstruction }
同样定义一个函数供5条指令使用,代码如下:
func _lstore(frame *rtda.Frame, index uint) {
val := frame.OperandStack().PopLong()
frame.LocalVars().SetLong(index, val)
}
lstore指令的索引来自操作数,其Execute()方法如下:
func (self *LSTORE) Execute(frame *rtda.Frame) {
_lstore(frame, uint(self.Index))
}
其余4条指令的索引隐含在操作码中,以lstore_2为例,其 Execute()方法如下
func (self *LSTORE_2) Execute(frame *rtda.Frame) {
_lstore(frame, 2)
}
七、栈指令
栈指令直接对操作数栈进行操作,共9条:
pop和pop2指令将栈顶变量弹出
dup系列指令复制栈顶变量
swap指令交换栈顶的两个变量
和其他类型的指令不同,栈指令并不关心变量类型。为了实现栈指令,需要给
OperandStack结构体
添加两个方法。
操作数栈实现
rtda\operand_stack.go文件中,在其中定义
PushSlot()
和
PopSlot()
方法,代码如下:
func (self *OperandStack) PushSlot(slot Slot) {
self.slots[self.size] = slot
self.size++
}
func (self *OperandStack) PopSlot() Slot {
self.size--
return self.slots[self.size]
}
pop和pop2指令
stack目录下创建pop.go文件,在其中定义 pop和pop2指令,代码如下:
type POP struct{ base.NoOperandsInstruction }
type POP2 struct{ base.NoOperandsInstruction }
pop指令把栈顶变量弹出,代码如下:
func (self *POP) Execute(frame *rtda.Frame) {
stack := frame.OperandStack()
stack.PopSlot()
}
pop指令只能用于弹出int、float等占用一个操作数栈位置的变量。
double和long变量在操作数栈中占据两个位置,需要使用pop2指令弹出,代码如下:
func (self *POP2) Execute(frame *rtda.Frame) {
stack := frame.OperandStack()
stack.PopSlot()
stack.PopSlot()
}
dup指令
创建
dup.go
文件,在其中定义6 条指令,代码如下:
完整代码移步:
jvmgo
type DUP struct{ base.NoOperandsInstruction }
type DUP_X1 struct{ base.NoOperandsInstruction }
type DUP_X2 struct{ base.NoOperandsInstruction }
type DUP2 struct{ base.NoOperandsInstruction }
type DUP2_X1 struct{ base.NoOperandsInstruction }
type DUP2_X2 struct{ base.NoOperandsInstruction }
dup指令复制栈顶的单个变量,代码如下:
func (self *DUP) Execute(frame *rtda.Frame) {
stack := frame.OperandStack()
slot := stack.PopSlot()
stack.PushSlot(slot)
stack.PushSlot(slot)
}
DUP_X1
:复制栈顶操作数一份放在第二个操作数的下方。Execute代码如下:
/*
bottom -> top
[...][c][b][a]
__/
|
V
[...][c][a][b][a]
*/
func (self *DUP_X1) Execute(frame *rtda.Frame) {
stack := frame.OperandStack()
slot1 := stack.PopSlot()
slot2 := stack.PopSlot()
stack.PushSlot(slot1)
stack.PushSlot(slot2)
stack.PushSlot(slot1)
}
DUP_X2
:复制栈顶操作数栈的一个或两个值,并将它们插入到操作数栈中的第三个值的下面。
/*
bottom -> top
[...][c][b][a]
_____/
|
V
[...][a][c][b][a]
*/
func (self *DUP_X2) Execute(frame *rtda.Frame) {
stack := frame.OperandStack()
slot1 := stack.PopSlot()
slot2 := stack.PopSlot()
slot3 := stack.PopSlot()
stack.PushSlot(slot1)
stack.PushSlot(slot3)
stack.PushSlot(slot2)
stack.PushSlot(slot1)
}
swap指令
swap指令作用是交换栈顶的两个操作数
下创建
swap.go
文件,在其中定义
swap指令
,代码如下:
type SWAP struct{ base.NoOperandsInstruction }
Execute()方法如下
func (self *SWAP) Execute(frame *rtda.Frame) {
stack := frame.OperandStack()
slot1 := stack.PopSlot()
slot2 := stack.PopSlot()
stack.PushSlot(slot1)
stack.PushSlot(slot2)
}
八、数学指令
数学指令大致对应Java语言中的加、减、乘、除等数学运算符。
数学指令包括算术指令、位移指令和布尔运算指令等,共37条,将全部在本节实现。
算术指令
算术指令又可以进一步分为:
- 加法(add)指令
- 减法(sub)指令
- 乘法(mul)指令
- 除法(div)指令
- 求余(rem)指令
- 取反(neg)指令
加、减、乘、除和取反指令都比较简单,本节以复杂的
求余指令
介绍。
math目录
下创建
rem.go
文件,在其中定义4条求余指令,代码如下:
type DREM struct{ base.NoOperandsInstruction }
type FREM struct{ base.NoOperandsInstruction }
type IREM struct{ base.NoOperandsInstruction }
type LREM struct{ base.NoOperandsInstruction }
DREM
结构体:表示对双精度浮点数 (
double
) 执行取余操作。
FREM
结构体:表示对单精度浮点数 (
float
) 执行取余操作
IREM
结构体:表示对整数 (
int
) 执行取余操作。
LREM
结构体:表示对长整数 (
long
) 执行取余操作。
irem
和
lrem
代码差不多,以
irem
为例,其
Execute()
方法如下:
func (self *IREM) Execute(frame *rtda.Frame) {
stack := frame.OperandStack()
v2 := stack.PopInt()
v1 := stack.PopInt()
if v2 == 0 {
panic("java.lang.ArithmeticException: / by zero")
}
result := v1 % v2
stack.PushInt(result)
}
先从操作数栈中弹出两个int变量,求余,然后把结果推入操作 数栈。
注意!对int或long变量做除法和求余运算时,是有可能抛出ArithmeticException异常的。
frem和drem指令差不多,以 drem为例,其Execute()方法如下:
func (self *DREM) Execute(frame *rtda.Frame) {
stack := frame.OperandStack()
v2 := stack.PopDouble()
v1 := stack.PopDouble()
result := math.Mod(v1, v2)
stack.PushDouble(result)
}
Go语言没有给浮点数类型定义求余操作符,所以需要使用
math包
的
Mod()
函数。
浮点数类型因为有Infinity(无穷大)值,所以即使是除零,也不会导致ArithmeticException异常抛出
位移指令
分为左移和右移
- 左移
- 右移
- 算术右移(有符号右移)
- 逻辑右移(无符号右移)两种。
算术右移和逻 辑位移的区别仅在于符号位的扩展,如下面的Java代码所示。
int x = -1;
println(Integer.toBinaryString(x)); // 66666666666666666666666666666666666666666666666666666666666611
println(Integer.toBinaryString(x >> 8)); // 66666666666666666666666666666666666666666666666666666666666611
println(Integer.toBinaryString(x >>> 8)); // 00000000666666666666666666666666666666666666666666666666
math目录下创建sh.go文件,在其中定义6条 位移指令,代码如下
type ISHL struct{ base.NoOperandsInstruction } // int左位移
type ISHR struct{ base.NoOperandsInstruction } // int算术右位移
type IUSHR struct{ base.NoOperandsInstruction } // int逻辑右位移(无符号右移位)
type LSHL struct{ base.NoOperandsInstruction } // long左位移
type LSHR struct{ base.NoOperandsInstruction } // long算术右位移
type LUSHR struct{ base.NoOperandsInstruction } // long逻辑右移位(无符号右移位)
左移
左移指令比较简单,以
ishl
指令为例,其
Execute()
方法如下:
func (self *ISHL) Execute(frame *rtda.Frame) {
stack := frame.OperandStack()
v2 := stack.PopInt()
v1 := stack.PopInt()
s := uint32(v2) & 0x1f
result := v1 << s
stack.PushInt(result)
}
先从操作数栈中弹出两个int变量v2和v1。v1是要进行位移操作的变量,v2指出要移位多少比特。位移之后,把结果推入操作数栈。
s := uint32(v2) & 0x1f
:这行代码将被左移的位数
v2
强制转换为
uint32
类型,然后执行按位与操作(
&
)与常数
0x1f
。
这是为了确保左移的位数在范围 0 到 31 内,因为在 Java 中,左移操作最多只能左移 31 位,超出这个范围的位数将被忽略。
这里注意两点:
int变量只有32位,所以只取v2的前5个比特就 足够表示位移位数了
Go语言位移操作符右侧必须是无符号 整数,所以需要对v2进行类型转换
右移
算数右移
算术右移指令需要扩展符号位,代码和左移指令基本上差不多。以
lshr
指令为例,其
Execute()
方法如下:
func (self *LSHR) Execute(frame *rtda.Frame) {
stack := frame.OperandStack()
v2 := stack.PopInt()
//long变量有64位,所以取v2的前6个比特。
v1 := stack.PopLong()
s := uint32(v2) & 0x3f
result := v1 >> s
stack.PushLong(result)
}
s := uint32(v2) & 0x1f:
提取
v2
变量的最低的 6 位,将其他位设置为 0,并将结果存储在
s
变量中。这是为了限制右移的位数在 0 到 63 之间,因为在 Java 中,long类型右移操作最多只能右移 63 位
逻辑右移
无符号右移位,以
iushr
为例,在移位前,先将v2转化为正数,再进行移位,最后转化为int32类型,如下代码所示:
func (self *IUSHR) Execute(frame *rtda.Frame) {
stack := frame.OperandStack()
v2 := stack.PopInt()
v1 := stack.PopInt()
s := uint32(v2) & 0x1f
result := int32(uint32(v1) >> s)
stack.PushInt(result)
}
布尔运算指令
布尔运算指令只能操作int和long变量,分为:
- 按位与(and)
- 按位 或(or)
- 按位异或(xor)
math
目录下创建
and.go
文件,在其中定义
iand
和
land
指令,代码如下:
type IAND struct{ base.NoOperandsInstruction }
type LAND struct{ base.NoOperandsInstruction }
以iand指令为例,其Execute()方法如下:
func (self *IAND) Execute(frame *rtda.Frame) {
stack := frame.OperandStack()
v2 := stack.PopInt()
v1 := stack.PopInt()
result := v1 & v2
stack.PushInt(result)
}
iinc指令
iinc指令
给局部变量表中的int变量增加常量值,局部变量表索引和常量值都由指令的操作数提供。
math目录下创建
iinc.go
文件,在其中定义
iinc指令
,代码如下:
type IINC struct {
//索引
Index uint
//常量值
Const int32
}
index
:一个字节,表示局部变量表中要增加值的变量的索引。这个索引指定了要修改的局部变量。
const
:一个有符号字节,表示要增加的常数值。这个常数值将与局部变量的当前值相加,并将结果存储回同一个局部变量。
FetchOperands()
函数从
字节码
里读取操作数,代码如下:
func (self *IINC) FetchOperands(reader *base.BytecodeReader) {
self.Index = uint(reader.ReadUint8())
self.Const = int32(reader.ReadInt8())
}
Execute()方法从局部变量表中读取变量,给它加上常量值,再把结果写回
局部变量表
,代码如下
func (self *IINC) Execute(frame *rtda.Frame) {
localVars := frame.LocalVars()
val := localVars.GetInt(self.Index)
val += self.Const
localVars.SetInt(self.Index, val)
}
九、类型转换指令
类型转换指令大致对应Java语言中的基本类型强制转换操作。 类型转换指令有共15条,将全部在本节实现。
引用类型转换对应的是
checkcast指令
,将在后续完成。
类型转换指令根据被
转换变量的类型
分为四种系列:
- i2x 系列指令
:这些指令将整数(int)变量强制转换为其他类型。
- l2x 系列指令
:这些指令将长整数(long)变量强制转换为其他类型。
- f2x 系列指令
:这些指令将浮点数(float)变量强制转换为其他类型。
- d2x 系列指令
:这些指令将双精度浮点数(double)变量强制转换为其他类型。
这些类型转换指令允许将不同类型的数据进行强制类型转换,以满足特定的计算或操作需求。
以
d2x系列
指令为例进行讨论。
conversions目录
下创建
d2x.go
文件,在其中 定义d2f、d2i和d2l指令,代码如下
type D2F struct{ base.NoOperandsInstruction }
type D2I struct{ base.NoOperandsInstruction }
type D2L struct{ base.NoOperandsInstruction }
以
d2i指令
为例,它的
Execute()
方法如下:
func (self *D2I) Execute(frame *rtda.Frame) {
stack := frame.OperandStack()
d := stack.PopDouble()
i := int32(d)
stack.PushInt(i)
}
因为Go语言可以很方便地转换各种基本类型的变量,所以类型转换指令实现起来还是比较容易的。
十、比较指令
比较指令可以分为两类:
比较指令是编译器实现if-else、for、while等语句的基石,共有19条
lcmp指令
lcmp指令
用于比较long变量。
comparisons目录下创建
lcmp.go
文件,在其中定义
lcmp指令
,代码如下:
type LCMP struct{ base.NoOperandsInstruction }
Execute()
方法把栈顶的两个long变量弹出,进行比较,然后把比较结果(int型0、1或-1)推入栈顶,代码如下:
func (self *LCMP) Execute(frame *rtda.Frame) {
stack := frame.OperandStack()
v2 := stack.PopLong()
v1 := stack.PopLong()
if v1 > v2 {
stack.PushInt(1)
} else if v1 == v2 {
stack.PushInt(0)
} else {
stack.PushInt(-1)
}
}
fcmp和dcmp指令
fcmpg
和
fcmpl指令
用于比较float变量,它们的区别是对于非数字参与,
fcmpg
会默认为其大于任何非NaN值,
fcmpl
则相反。
comparisons目录下创建fcmp.go文件,在其中定义
fcmpg
和
fcmpl指令
,代码如下:
type FCMPG struct{ base.NoOperandsInstruction }
type FCMPL struct{ base.NoOperandsInstruction }
由于浮点数计算有可能产生NaN(Not a Number)值,所以比较两个浮点数时,除了大于、等于、小于之外,
还有第4种结果:无法比较。
编写一个函数来统一比较float变量,如下:
func _fcmp(frame *rtda.Frame, gFlag bool) {
stack := frame.OperandStack()
v2 := stack.PopFloat()
v1 := stack.PopFloat()
if v1 > v2 {
stack.PushInt(1)
} else if v1 == v2 {
stack.PushInt(0)
} else if v1 < v2 {
stack.PushInt(-1)
} else if gFlag {
stack.PushInt(1)
} else {
stack.PushInt(-1)
}
}
Java虚拟机规范:浮点数比较指令
fcmpl
和
fcmpg
的规范要求首先弹出
v2
,然后是
v1
,以便进行浮点数比较。
Execute()如下:
func (self *FCMPG) Execute(frame *rtda.Frame) {
_fcmp(frame, true)
}
func (self *FCMPL) Execute(frame *rtda.Frame) {
_fcmp(frame, false)
}
if<cond>指令
if<cond>
指令是 Java 字节码中的条件分支指令,它根据条件
<cond>
来执行不同的分支。
条件
<cond>
可以是各种比较操作,比如等于、不等于、大于、小于等等。
常见的
if<cond>
指令包括:
ifeq
: 如果栈顶的值等于0,则跳转。
ifne
: 如果栈顶的值不等于0,则跳转。
iflt
: 如果栈顶的值小于0,则跳转。
ifge
: 如果栈顶的值大于或等于0,则跳转。
ifgt
: 如果栈顶的值大于0,则跳转。
ifle
: 如果栈顶的值小于或等于0,则跳转。
创建ifcond.go文件,在其中定义6条if指令,代码如下:
type IFEQ struct{ base.BranchInstruction }
type IFNE struct{ base.BranchInstruction }
type IFLT struct{ base.BranchInstruction }
type IFLE struct{ base.BranchInstruction }
type IFGT struct{ base.BranchInstruction }
type IFGE struct{ base.BranchInstruction }
以
ifeq指令
为例,其Execute()方法如下:
func (self *IFEQ) Execute(frame *rtda.Frame) {
val := frame.OperandStack().PopInt()
if val == 0 {
base.Branch(frame, self.Offset)
}
}
真正的跳转逻辑在Branch()函数中。因为这个函数在很多指令中都会用到,所以定义在base\branch_logic.go 文件中,代码如下:
func Branch(frame *rtda.Frame, offset int) {
pc := frame.Thread().PC()
nextPC := pc + offset
frame.SetNextPC(nextPC)
}
if_icmp<cond>指令
if_icmp<cond>
指令是 Java 字节码中的一类条件分支指令,它用于对比两个整数值,根据比较的结果来执行条件分支。这些指令的操作数栈上通常有两个整数值,它们分别用于比较。
这类指令包括:
if_icmpeq
: 如果两个整数相等,则跳转。
if_icmpne
: 如果两个整数不相等,则跳转。
if_icmplt
: 如果第一个整数小于第二个整数,则跳转。
if_icmpge
: 如果第一个整数大于等于第二个整数,则跳转。
if_icmpgt
: 如果第一个整数大于第二个整数,则跳转。
if_icmple
: 如果第一个整数小于等于第二个整数,则跳转。
创建if_icmp.go文件,在 其中定义6条if_icmp指令,代码如下:
type IF_ICMPEQ struct{ base.BranchInstruction }
type IF_ICMPNE struct{ base.BranchInstruction }
type IF_ICMPLT struct{ base.BranchInstruction }
type IF_ICMPLE struct{ base.BranchInstruction }
type IF_ICMPGT struct{ base.BranchInstruction }
type IF_ICMPGE struct{ base.BranchInstruction }
以if_icmpne指令 为例,其Execute()方法如下:
func (self *IF_ICMPNE) Execute(frame *rtda.Frame) {
if val1, val2 := _icmpPop(frame); val1 != val2 {
base.Branch(frame, self.Offset)
}
}
func _icmpPop(frame *rtda.Frame) (val1, val2 int32) {
stack := frame.OperandStack()
val2 = stack.PopInt()
val1 = stack.PopInt()
return
}
if_acmp<cond>指令
if_acmp<cond>
指令是 Java 字节码中的一类条件分支指令,用于比较两个引用类型的对象引用,根据比较的结果来执行条件分支。这些指令的操作数栈上通常有两个对象引用,它们分别用于比较。
这类指令包括:
if_acmpeq
: 如果两个引用相等,则跳转。
if_acmpne
: 如果两个引用不相等,则跳转。
创建if_acmp.go文件,在 其中定义两条if_acmp指令,代码如下:
type IF_ACMPEQ struct{ base.BranchInstruction }
type IF_ACMPNE struct{ base.BranchInstruction }
以if_acmpeq指令为例,其Execute()方法如下:
func (self *IF_ACMPEQ) Execute(frame *rtda.Frame) {
stack := frame.OperandStack()
ref2 := stack.PopRef()
ref1 := stack.PopRef()
if ref1 == ref2 {
base.Branch(frame, self.Offset)
}
}
十一、控制指令
- 控制指令共有 11 条。
- 在 Java 6 之前,
jsr
和
ret
指令用于实现
finally
子句
。从 Java 6 开始,Oracle 的 Java 编译器不再使用这两条指令。
return
系列指令有 6 条,用于从方法调用中返回,将在后续实现。- 本节将实现剩下的 3 条指令:
goto
、
tableswitch
和
lookupswitch
。
这些指令用于控制程序执行流,包括条件分支和无条件跳转等操作。其中,
goto
用于无条件跳转到指定的目标位置,而
tableswitch
和
lookupswitch
用于根据条件跳转到不同的目标位置。
control目录下创建goto.go文件,在其中定义 goto指令,代码如下: