什么是Helm?它是如何提升云原生应用私有化部署效率的
公众号「架构成长指南」,专注于生产实践、云原生、分布式系统、大数据技术分享
试想一下,如果有一个项目有50 个微服务,每个微服务都有service、deployment、ingress、pvc等 yaml 文件,算下来大概有 200 个文件,然后这个项目需要基于k8s进行私有化交付,如果是你会怎么快速部署应用?
首先让我们先思考一下
- 200 个文件是否通过
kubectl apply
进行部署,写个shell 脚本for 循环一个个读取执行?,但是如果这些yaml 文件更新了,如何同步? - 如果这些pod进行需要升级怎么办,一个个修改镜像 tag?
- yaml文件关联地址如何更新,比如数据库地址、文件系统地址,日志目录,资源大小等?
- 如果想进行卸载,如何做,一个个去删除?
如果有一个工具能把这些yaml文件放在一个包里,类似
npm
、
maven
这样的包管理工具,然后把关键的参数暴露出来,在部署时指定这些参数,执行一键部署,在卸载时一键卸载是不是很方便,而Helm 就是这样的工具
什么是Helm
Helm 是一个能够在 Kubernetes 上打包、部署和管理应用程序的工具,即使是最复杂的 Kubernetes 应用程序它都可以帮助定义,安装和升级,同时Helm 也是
CNCF
的毕业项目。
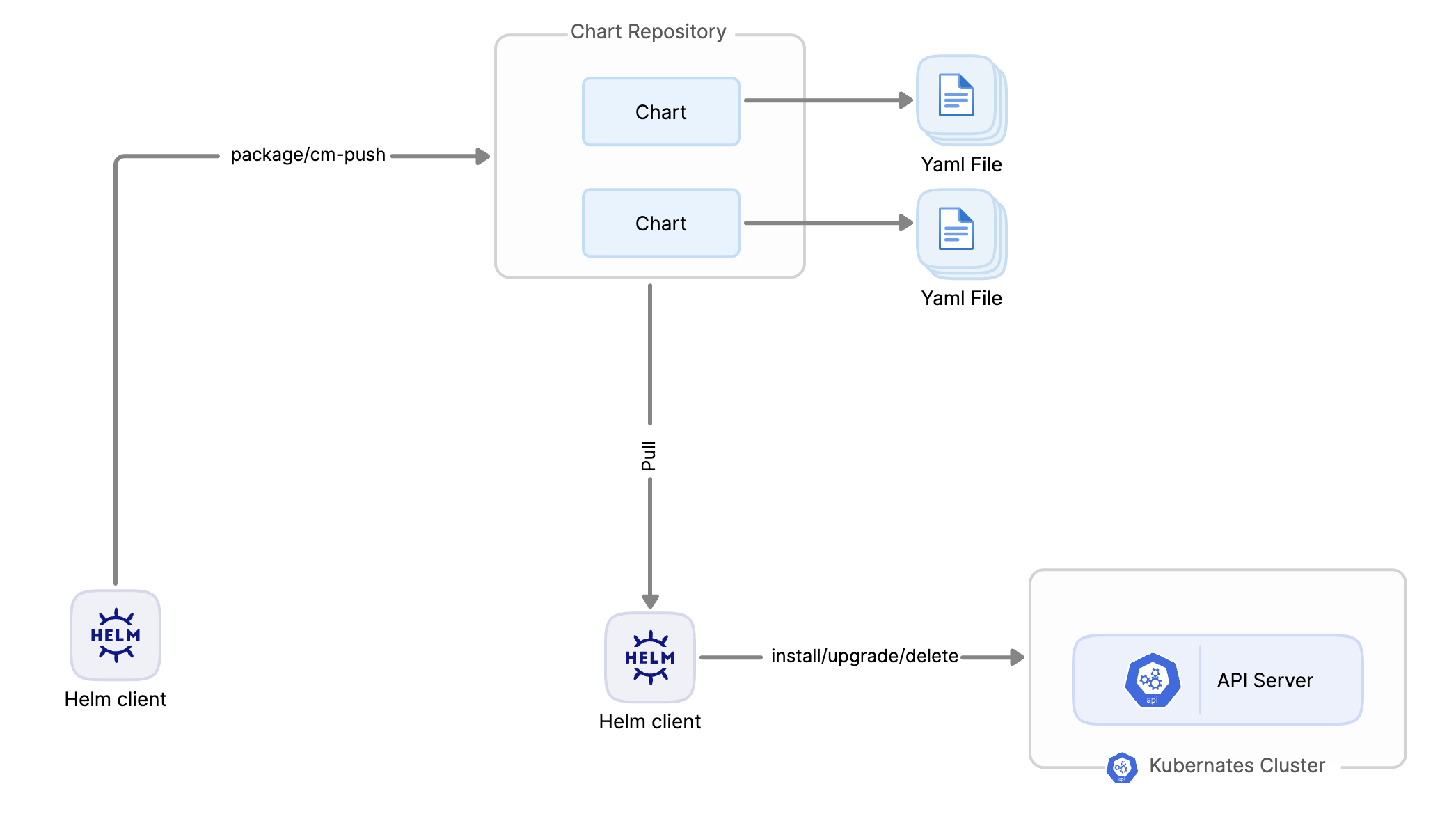
以下Helm中的概念
Helm Charts
:预先配置yaml的模板,在这里叫Chart,用于描述 Kubernetes 应用程序的yaml和配置
Helm Client
:用于与 Helm 交互并管理这些Chart版本的命令行界面
Chart 仓库
:管理Chart的仓库,跟Maven的
Nexus
一个意思,比如在公司环境构建上传,在客户的机房连接到这Chart 仓库下载Chart,并部署到k8s中。
我们要做什么?
这里我们不介绍Helm 的具体函数,具体可以查官网,这里只讲一下如何使用Helm,让你对Helm有一个认识,知道在什么场景下使用即可,所以我们结合一个示例讲一下玩法。
示例介绍
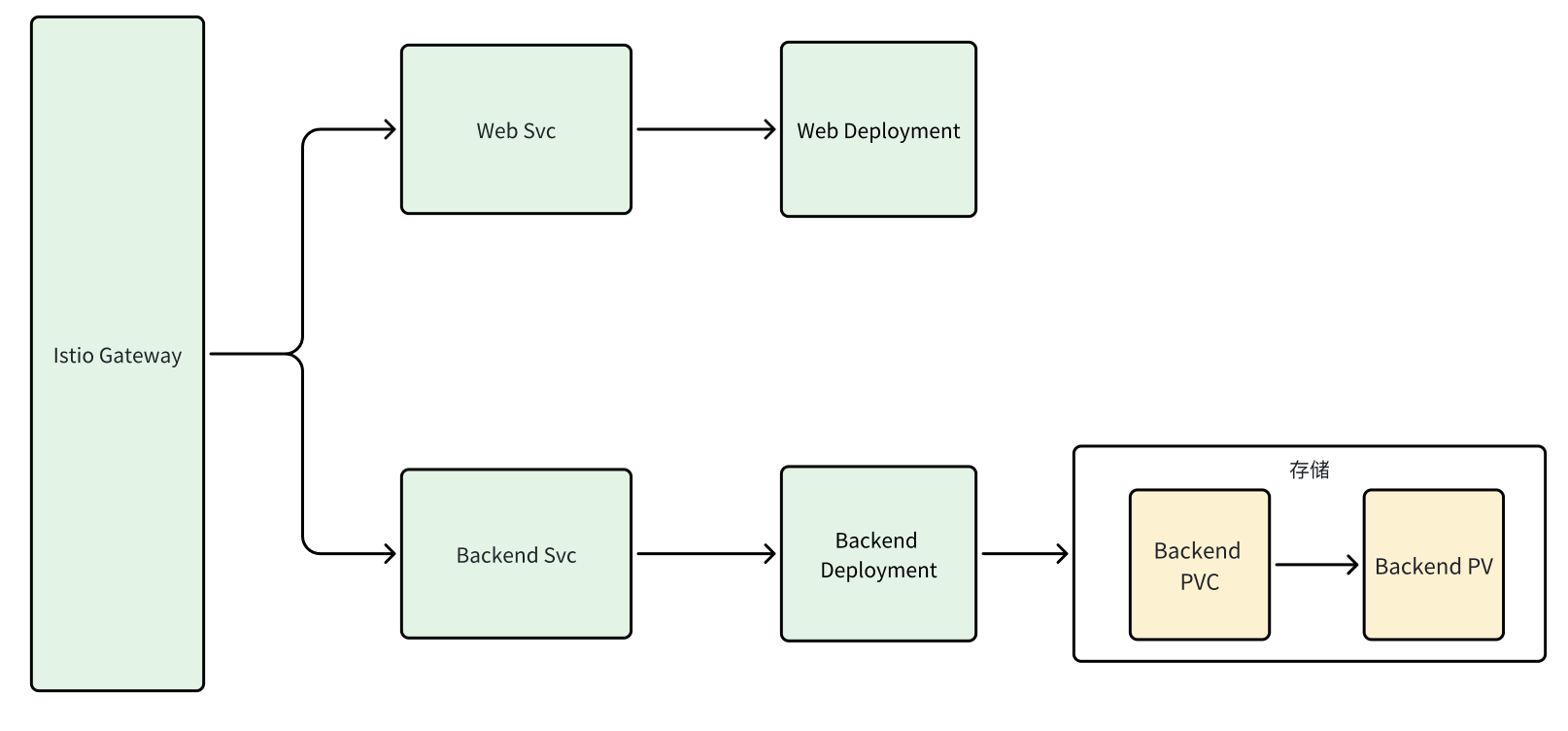
有一个运维部署系统,分为前后端,需要部署到客户机房,在k8s架构如下,可以看到需要8 个文件(其中Istio需要2个yaml文件),下面通过示例一步步创建这个Chart
示例创建
我们通过
helm create dp-manage
命令创建一个Chart,执行完以后,默认会生成一个 nginx 的Chart,如下图
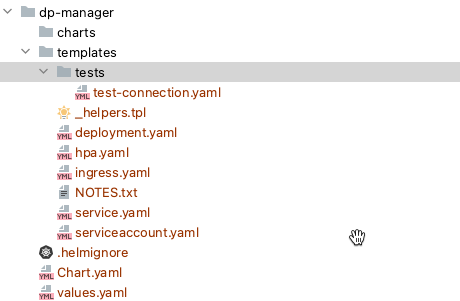
关键文件说明
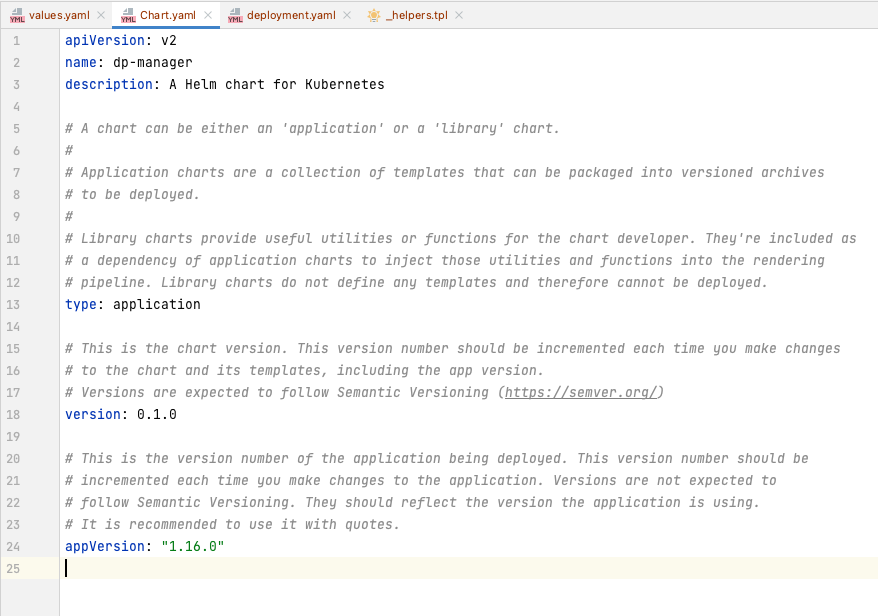
Chart.yaml
定义了当前 chart版本,以及描述当前chart用途,其中 name 参数表示 chart 名称,后期上传下载都会用此名称
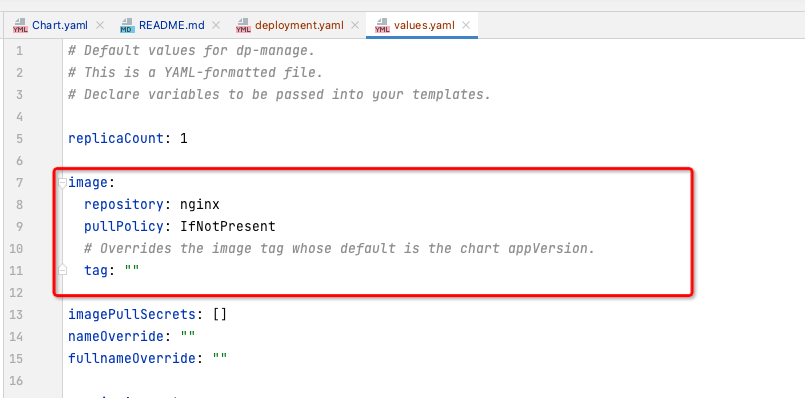
values.yaml
可变参数,都是在此文件中定义,在yaml模板中引用,比如:
image.repository
,而引用则通过
.Values
+变量的名进行引用,如下图

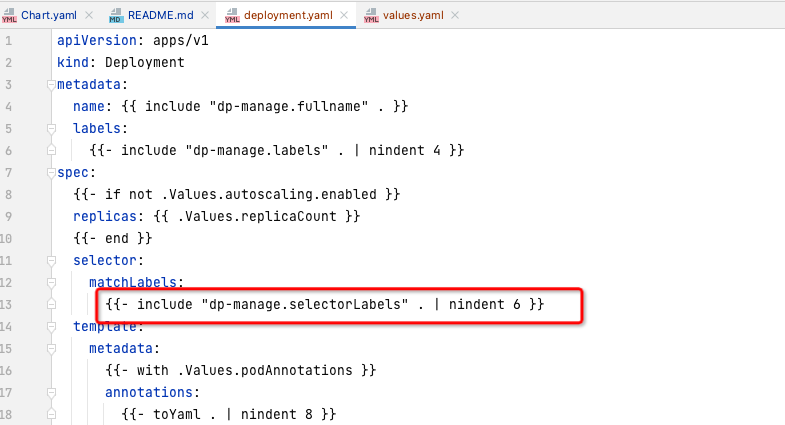
_helpers.tpl
通用代码块定义,类似于freemaker的宏,然后在yaml中通过名称进行引用,
include
修饰的都是,比如
dp-manager.selectorLabels

示例修改
由于默认创建一个Nginx 的 Chart 无法满足我们需求,所以删除掉多余的文件,并添加运维部署系统的yaml 文件,如下图

可以看到有8个模板文件,其中backend-dp.yaml定义如下
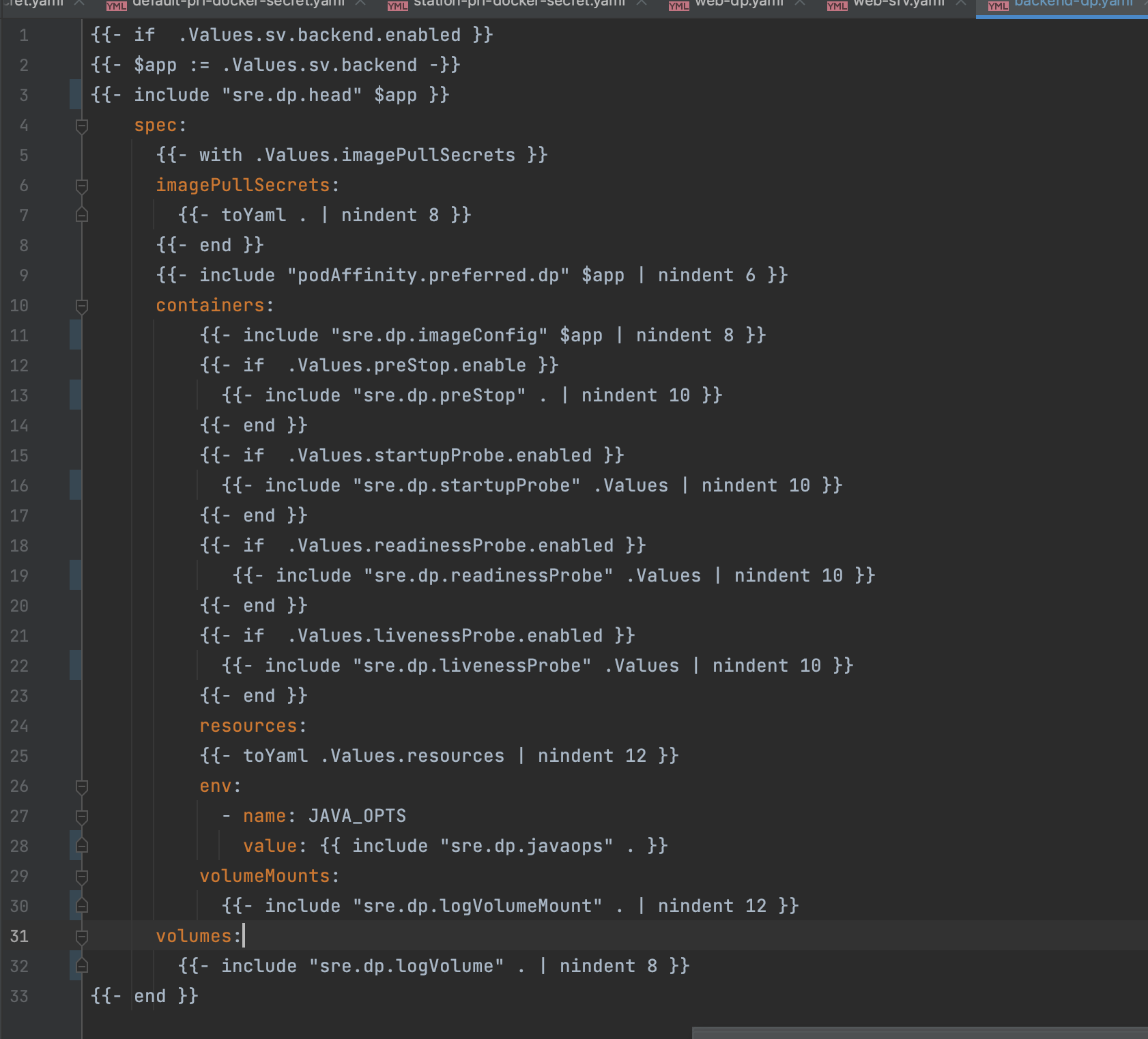
通过引用
values.yml
参数和
_helpers.tpl
的通用代码块,最终会生成一个k8s的deployment.yml文件,其他文件就不一一介绍
构建与部署
通过前面的介绍,需要把Chart构建好以后,上传到Chart仓库,然后在客户机房连接这个仓库,进行下载,因此需要一个Chart 仓库,这里我们使用Harbor ,Habor可以作为容器镜像仓库也可以作为 Chart仓库一举两得,推荐使用。

关联仓库
在安装好 Helm client 以后,在本地执行以下命令,关联到仓库,
helm repo add myrepo https://host/仓库地址 \
--username sre \
--password xxxx
添加以后,执行
helm repo list
可以查到添加的
myrepo
仓库

构建打包
仓库关联好以后,执行
helm package dp-manager
命令打包,会生成一个
dp-manager-1.0.0.tgz
包

执行
helm cm-push dp-manager-1.0.0.tgz myrepo
推送至Harbor 仓库,myrepo为我们的仓库名称,推送完以后登录Harbor 查看,如下图
拉取部署
Chart 上传以后,我们在客户机房安装Helm Client和Kubectl客户端,具体安装方法查询网上,通过
helm repo add
关联Habor仓库地址,关联以后执行search 命令查找运维部署系统的Chart
helm search repo myrepo/dp-manager

Chart查询到以后,就可以进行部署了,部署分为两种方式,一种是下载Chart至本地,修改values.yaml文件在部署,另外一种是不用下载直接指定参数部署,我们使用第二种
helm install dp-manager myrepo/dp-manager \
--set istioGateway.hosts={dpmanager.test.com} \
--set pv.log.pvEnabled=false \
--set pv.log.type=storageClass \
--set pv.log.pvc.storageName=gfs-storage \
--set pv.log.pvc.storage=20Gi \
--set apollo.cluster=default
我们在这个命令中指定了域名,存储大小等参数,这些参数通过values.yaml文件暴露,另外此命令部署运维部署系统至default命令空间,可以通过
-n
参数指定命名空间
命令执行完以后,可以通过
helm list
进行查看,如下图
helm list

更新
假设apollo.cluster值由 default修改为prod,执行
upgrade
更新即可
helm upgrade dp-manager myrepo/dp-manager \
--set istioGateway.hosts={dpmanager.test.com} \
--set pv.log.pvEnabled=false \
--set pv.log.type=storageClass \
--set pv.log.pvc.storageName=gfs-storage \
--set pv.log.pvc.storage=20Gi \
--set apollo.cluster=prod
卸载
卸载非常简单,执行以下命令即可
helm uninsall dp-manager
如果本篇文章对您有所帮助,麻烦帮忙一键三连(
点赞、转发、收藏
)~
扫描下面的二维码关注我们的微信公众帐号,在微信公众帐号中回复◉加群◉即可加入到我们的技术讨论群里面共同学习。