从零开始写 Docker(一)---实现 mydocker run 命令

本文为从零开始写 Docker 系列第一篇,主要实现 mydocker run 命令,构造了一个具有基本的 Namespace 隔离的简单容器。
如果你对云原生技术充满好奇,想要深入了解更多相关的文章和资讯,欢迎关注微信公众号。
搜索公众号【
探索云原生
】即可订阅

本文主要实现我们的第一个命令
mydocker run
,类似于
docker run -it [command]
。
docker run 命令是通过创建新的 namespace 对新的进程进行视图隔离。
完整代码见:
https://github.com/lixd/mydocker
欢迎 Star
推荐阅读以下文章对 docker 基本实现有一个大致认识:
- 核心原理
:
深入理解 Docker 核心原理:Namespace、Cgroups 和 Rootfs - 基于 namespace 的视图隔离
:
探索 Linux Namespace:Docker 隔离的神奇背后 - 基于 cgroups 的资源限制
- 基于 overlayfs 的文件系统
:
Docker 魔法解密:探索 UnionFS 与 OverlayFS - 基于 veth pair、bridge、iptables 等等技术的 Docker 网络
:
揭秘 Docker 网络:手动实现 Docker 桥接网络
开发环境如下:
root@mydocker:~# lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 20.04.2 LTS
Release: 20.04
Codename: focal
root@mydocker:~# uname -r
5.4.0-74-generic
注意:需要使用 root 用户
urfave/cli 工具
主要用到了
urfave/cli
来实现命令行工具,具体用法参考官方文档。
两个常用 cli 库对比:
urfave/cli 比较简洁,实现简单的 cli 工具推荐使用。
spf13/cobra
功能强大,实现复杂的 cli 工具推荐使用。
一个简单的 urfave/cli Demo 如下:
// urfaveCli cli 包简单使用,具体可以参考官方文档
func urfaveCli() {
app := cli.NewApp()
// 指定全局参数
app.Flags = []cli.Flag{
cli.StringFlag{
Name: "lang, l",
Value: "english",
Usage: "Language for the greeting",
},
cli.StringFlag{
Name: "config, c",
Usage: "Load configuration from `FILE`",
},
}
// 指定支持的命令列表
app.Commands = []cli.Command{
{
Name: "complete",
Aliases: []string{"c"},
Usage: "complete a task on the list",
Action: func(c *cli.Context) error {
log.Println("run command complete")
for i, v := range c.Args() {
log.Printf("args i:%v v:%v\n", i, v)
}
return nil
},
},
{
Name: "add",
Aliases: []string{"a"},
// 每个命令下面还可以指定自己的参数
Flags: []cli.Flag{cli.Int64Flag{
Name: "priority",
Value: 1,
Usage: "priority for the task",
}},
Usage: "add a task to the list",
Action: func(c *cli.Context) error {
log.Println("run command add")
for i, v := range c.Args() {
log.Printf("args i:%v v:%v\n", i, v)
}
return nil
},
},
}
err := app.Run(os.Args)
if err != nil {
log.Fatal(err)
}
}
具体效果如下:
$ go run main.go -h
NAME:
main - A new cli application
USAGE:
main [global options] command [command options] [arguments...]
COMMANDS:
complete, c complete a task on the list
add, a add a task to the list
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--lang value, -l value Language for the greeting (default: "english")
--config FILE, -c FILE Load configuration from FILE
--help, -h show help
可以看到指定的指令和参数,就是这么简单。
具体实现
目录结构
mydocker 项目当前目录结构如下:
$ tree .
.
├── LICENSE
├── Makefile
├── README.md
├── container
│ ├── container_process.go
│ └── init.go
├── example
│ └── main.go
├── go.mod
├── go.sum
├── main.go
├── main_command.go
└── run.go
- main.go 作为项目入口
- main_command.go 中包含了所有的 command
- run.go 则是 run 命令核心逻辑
- container 目录则是一些 container 的核心实现
main.go
首先是 main 文件:
使用 urfave/cli 提供 的命令行工具定义了 mydocker 的几个基本命令,包括
runCommand
和
initCommand
,然后在 app.Before 内初始化 logrus 的日志配置。
package main
import (
"os"
log "github.com/sirupsen/logrus"
"github.com/urfave/cli"
)
const usage = `mydocker is a simple container runtime implementation.
The purpose of this project is to learn how docker works and how to write a docker by ourselves
Enjoy it, just for fun.`
func main() {
app := cli.NewApp()
app.Name = "mydocker"
app.Usage = usage
app.Commands = []cli.Command{
initCommand,
runCommand,
}
app.Before = func(context *cli.Context) error {
// Log as JSON instead of the default ASCII formatter.
log.SetFormatter(&log.JSONFormatter{})
log.SetOutput(os.Stdout)
return nil
}
if err := app.Run(os.Args); err != nil {
log.Fatal(err)
}
}
main_command.go
main_command 中包含了具体的命令定义:
var runCommand = cli.Command{
Name: "run",
Usage: `Create a container with namespace and cgroups limit
mydocker run -it [command]`,
Flags: []cli.Flag{
cli.BoolFlag{
Name: "it", // 简单起见,这里把 -i 和 -t 参数合并成一个
Usage: "enable tty",
},
},
/*
这里是run命令执行的真正函数。
1.判断参数是否包含command
2.获取用户指定的command
3.调用Run function去准备启动容器:
*/
Action: func(context *cli.Context) error {
if len(context.Args()) < 1 {
return fmt.Errorf("missing container command")
}
cmd := context.Args().Get(0)
tty := context.Bool("it")
Run(tty, cmd)
return nil
},
}
var initCommand = cli.Command{
Name: "init",
Usage: "Init container process run user's process in container. Do not call it outside",
/*
1.获取传递过来的 command 参数
2.执行容器初始化操作
*/
Action: func(context *cli.Context) error {
log.Infof("init come on")
cmd := context.Args().Get(0)
log.Infof("command: %s", cmd)
err := container.RunContainerInitProcess(cmd, nil)
return err
},
}
要实现 run 命令我们需要实现 run、init 两个命令。
run.go
接着看下 Run 函数做了写什么:
// Run 执行具体 command
/*
这里的Start方法是真正开始前面创建好的command的调用,它首先会clone出来一个namespace隔离的
进程,然后在子进程中,调用/proc/self/exe,也就是调用自己,发送init参数,调用我们写的init方法,
去初始化容器的一些资源。
*/
func Run(tty bool, cmd string) {
parent := container.NewParentProcess(tty, cmd)
if err := parent.Start(); err != nil {
log.Error(err)
}
_ = parent.Wait()
os.Exit(-1)
}
Run 命令主要调用 NewParentProcess 构建 os/exec.Cmd 对象并执行,执行完成立马退出。
注意区分 os/exec 包中的 Cmd 对象和 urfave/cli 包中的 command 对象。
// NewParentProcess 启动一个新进程
/*
这里是父进程,也就是当前进程执行的内容。
1.这里的/proc/se1f/exe调用中,/proc/self/ 指的是当前运行进程自己的环境,exec 其实就是自己调用了自己,使用这种方式对创建出来的进程进行初始化
2.后面的args是参数,其中init是传递给本进程的第一个参数,在本例中,其实就是会去调用initCommand去初始化进程的一些环境和资源
3.下面的clone参数就是去fork出来一个新进程,并且使用了namespace隔离新创建的进程和外部环境。
4.如果用户指定了-it参数,就需要把当前进程的输入输出导入到标准输入输出上
*/
func NewParentProcess(tty bool, command string) *exec.Cmd {
args := []string{"init", command}
cmd := exec.Command("/proc/self/exe", args...)
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS |
syscall.CLONE_NEWNET | syscall.CLONE_NEWIPC,
}
if tty {
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
}
return cmd
}
可以看到,NewParentProcess 方法构建的命令为
/proc/self/exe
,这个表示调用
当前文件
,我们后续编译出来是二进制文件是 mydocker,那么这个命令执行的就是 mydocker。
第一个参数为 init,也就是说这个命令最终会执行
mydocker init
这个命令。
这也就是为什么我们除了实现 run 命令之外,还要实现一个 init 命令。
另外比较重要的就是关于 tty 的:
if tty {
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
}
将 cmd 的输入和输出连接到终端,以便我们可以与命令进行交互,并看到命令的输出。
即:cmd 可以从标准输入读取输入,也可以把结果打印到标准输出或者错误输出上。
那么当我们执行
mydocker run -it /bin/ls
这种命令时,最后的
/bin/ls
就会作为标准输入给到容器进程,因此容器进程就会执行
/bin/ls
命令,列出当前目录下的文件。
init.go
最后再看下 initCommand 的具体内容:
// RunContainerInitProcess 启动容器的init进程
/*
这里的init函数是在容器内部执行的,也就是说,代码执行到这里后,容器所在的进程其实就已经创建出来了,
这是本容器执行的第一个进程。
使用mount先去挂载proc文件系统,以便后面通过ps等系统命令去查看当前进程资源的情况。
*/
func RunContainerInitProcess(command string, args []string) error {
log.Infof("command:%s", command)
defaultMountFlags := syscall.MS_NOEXEC | syscall.MS_NOSUID | syscall.MS_NODEV
_ = syscall.Mount("proc", "/proc", "proc", uintptr(defaultMountFlags), "")
argv := []string{command}
if err := syscall.Exec(command, argv, os.Environ()); err != nil {
log.Errorf(err.Error())
}
return nil
}
这里 Mount 意思如下:
MS_NOEXEC 在本文件系统 许运行其 程序。
MS_NOSUID 在本系统中运行程序的时候, 允许 set-user-ID set-group-ID
MS_NOD 这个参数是自 Linux 2.4 ,所有 mount 的系统都会默认设定的参数。
本函数最后的
syscall.Exec
是最为重要的一句黑魔法,正是这个系统调用实现了完成初始化动作并将用户进程运行起来的操作。
首先,使用 Docker 创建起来一个容器之后,会发现容器内的第一个程序,也就是 PID 为 1 的那个进程,是指定的前台进程。但是,我们知道容器创建之后,执行的第一个进程并不是用户的进程,而是 init 初始化的进程。 这时候,如果通过 ps 命令查看就会发现,容器内第一个进程变成了自己的 init,这和预想的是不一样的。
有没有什么办法把自己的进程变成 PID 为 1 的进程呢?
这里 execve 系统调用就是用来做这件事情的。
syscall.Exec 这个方法,其实最终调用了 Kernel 的
int execve(const char *filename, char *const argv[], char *const envp[);
这个系统函数。
它的作用是执行当前 filename 对应的程序,它会覆盖当前进程的镜像、数据和堆栈等信息,包括 PID,这些都会被将要运行的进程覆盖掉
。
也就是说,调用这个方法,将用户指定的进程运行起来,把最初的 init 进程给替换掉,这样当进入到容器内部的时候,就会发现容器内的第一个程序就是我们指定的进程了。
这其实也是目前 Docker 使用的容器引擎 runC 的实现方式之一。
具体启动流程如下图:
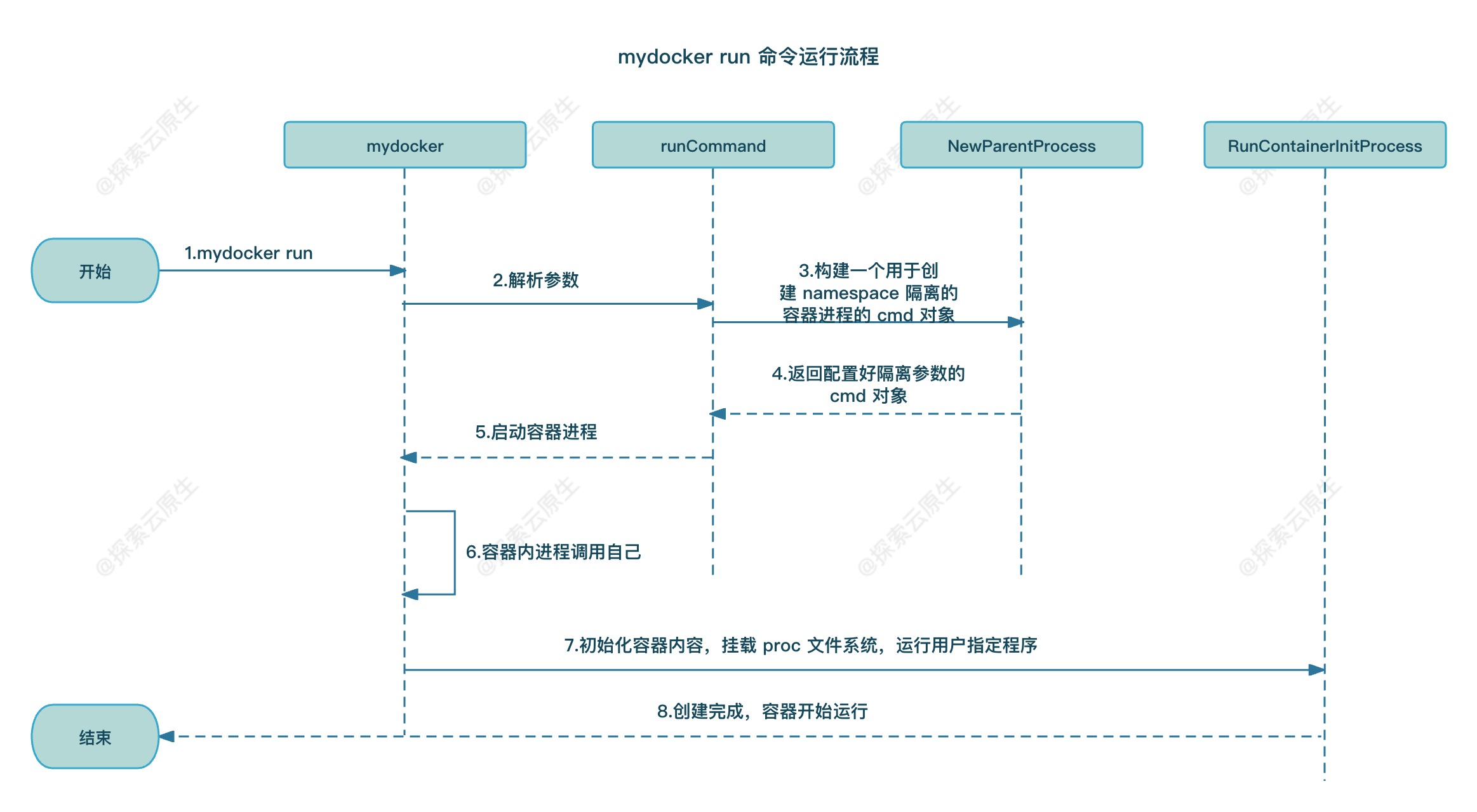
- 1)流程开始,用户手动执行 mydocker run 命令
- 2)urfave/cli 工具解析传递过来的参数
- 3)解析完成后发现第一个参数是 run,于是执行 run 命令,调用 runCommand 方法,该方法中继续调用 NewParentProcess 函数构建一个 cmd 对象
- 4)NewParentProcess 将构建好的 cmd 对象返回给 runCommand 方法
- 5)runCommand 方法中调用 cmd.exec 执行上一步构建好的 cmd 对象
- 6)容器启动后,根据 cmd 中传递的参数,/proc/self/exe init 实则最终会执行 mydocker init 命令,初始化容器环境
- 7)init 命令内部实现就是通过 mount 命令挂载 proc 文件系统
- 8)容器创建完成,整个流程结束
测试
root@mydocker:~/mydocker# go build .
root@mydocker:~/mydocker# ./mydocker run -it /bin/sh
{"level":"info","msg":"init come on","time":"2024-01-03T14:44:35+08:00"}
{"level":"info","msg":"command: /bin/sh","time":"2024-01-03T14:44:35+08:00"}
{"level":"info","msg":"command:/bin/sh","time":"2024-01-03T14:44:35+08:00"}
# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 09:47 pts/1 00:00:00 /bin/sh
root 5 1 0 09:47 pts/1 00:00:00 ps -ef
在容器运行 ps 时,可以发现 /bin/sh 程是容器内的第一个进程, PID 为 1。 ps 进程是 PID 为 1 的父进程创建出来的。
来对比 Docker 运行的容器的效果,如下:
[root@docker ~]# docker run -it ubuntu /bin/sh
# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 01:49 pts/0 00:00:00 /bin/sh
root 7 1 0 01:49 pts/0 00:00:00 ps -ef
不能说很相似,只能说是一模一样了。
这里的 /bin/sh 是一个会在前台一直运行的进程,那么可以试一下如果指定一个运行完就会退出的进程会是什么效果:
root@mydocker:~/mydocker# ./mydocker run -it /bin/ls
{"level":"info","msg":"init come on","time":"2024-01-03T14:51:48+08:00"}
{"level":"info","msg":"command: /bin/ls","time":"2024-01-03T14:51:48+08:00"}
{"level":"info","msg":"command:/bin/ls","time":"2024-01-03T14:51:48+08:00"}
LICENSE Makefile README.md container example go.mod go.sum main.go main_command.go mydocker run.go
运行了一下 ls 命令,发现容器启动起来以后,打印出了当前目录的内容,然后便退出了,这个结果和 Docker 要求容器必须有一个一直在前台运行的进程的要求一致。
由于没有 chroot ,所以目前的系统文件系统是继承自父进程的。
至此,我们的 mydocker run 命令就算是实现完成,基本能实现 docker run 的效果。
小结
run 命令实现中感觉几个比较重要的点:
- /proc/self/exe
:调用自身 init 命令,初始化容器环境 - tty
:实现交互 - Namespace 隔离
:通过在 fork 时指定对应 Cloneflags 来实现创建新 Namespace - proc 隔离
:通过重新 mount /proc 文件系统来实现进程信息隔离 - execve 系统调用
:使用指定进程覆盖 init 进程
/proc/self/exe
/proc/self/exe
是 Linux 系统中的一个符号链接,
它指向当前进程的可执行文件
。
这个路径是一个虚拟路径,实际上并不对应于文件系统中的一个文件,而是通过 /proc 文件系统提供的一种方式来访问进程相关的信息。
具体而言,/proc/self 是一个指向当前进程自身的符号链接,而 exe 则是一个特殊的文件,通过这个文件可以访问当前进程的可执行文件。
因此,/proc/self/exe 实际上是当前进程可执行文件的路径
。
也就是说在 mydocker run 命令中执行的 /proc/self/exe init 实际上最终执行的是 mydocker init,即 run 命令会调用 init 命令来初始化容器环境。
tty
if tty {
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
}
当用户指定 -it 参数时,就将 cmd 的输入和输出连接到终端,以便我们可以与命令进行交互,并看到命令的输出。
Namespace 隔离
cmd := exec.Command("/proc/self/exe", args...)
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS |
syscall.CLONE_NEWNET | syscall.CLONE_NEWIPC,
}
fork 新进程时,通过指定 Cloneflags 会创建对应的 Namespace 以实现隔离,这里包括UTS(主机名)、PID(进程ID)、挂载点、网络、IPC等方面的隔离。
proc 隔离
/proc 文件系统是一个虚拟的文件系统,提供了对内核和运行中进程的信息的访问。通过挂载 /proc,系统中的许多信息和控制接口可以通过文件的形式在这个目录下找到。
例如,你可以通过 /proc 查看系统的一些信息,如进程列表、内存使用情况、CPU 信息等。
比如当前机器上的进程信息:
[root@docker ~]# ls /proc
1 1147 16 18531 20 247 325 350 468 632 74 79 85 908 cmdline driver ioports kpagecgroup misc pressure stat tty
10 1150 16968 18533 20728 3 326 351 491 633 75 8 86 978 consoles execdomains irq kpagecount modules sched_debug swaps uptime
100 1152 17 18534 21 31652 327 352 508 635 76 80 87 acpi cpuinfo fb kallsyms kpageflags mounts schedstat sys version
1094 1155 18 18549 22 31797 333 353 544 637 7675 813 88 buddyinfo crypto filesystems kcore loadavg mtrr scsi sysrq-trigger vmallocinfo
11 13 18433 18550 244 31818 347 354 587 641 7694 82 8897 bus devices fs keys locks net self sysvipc vmstat
1100 14 18435 19 245 323 348 355 6 643 77 832 89 capi diskstats interrupts key-users mdstat pagetypeinfo slabinfo thread-self zoneinfo
1141 15 18505 2 246 324 349 4 620 73 78 84 9 cgroups dma iomem kmsg meminfo partitions softirqs timer_list
而在容器环境中,为了和宿主机的 /proc 环境隔离,因此在
mydocker init
命令中我们会重新挂载 /proc 文件系统,即:
syscall.Mount("proc", "/proc", "proc", uintptr(defaultMountFlags), "")
对应 mount 命令为:
mount -t proc proc /proc
而当前进程在 fork 时指定了
syscall.CLONE_NEWPID
等等标记,因此是在新的 Namespace 中的,那就意味着看不到宿主机上的进程信息,那么重新挂载后的 /proc 文件系统自然也就只有当前 Namespace 下的进程信息。
这也就是为什么在容器中执行 ps 命令只能看到容器中的进程信息
execve 系统调用
execve 系统调用用于取代当前进程的映像(即,当前进程的可执行文件),并用一个新的程序来替代
。
原型如下:
int execve(const char *filename, char *const argv[], char *const envp[);
filename
参数指定了要执行的新程序的文件路径。argv
参数是一个字符串数组,包含了新程序的命令行参数。数组的第一个元素通常是新程序的名称,随后的元素是命令行参数。envp
参数是一个字符串数组,包含了新程序执行时使用的环境变量。
execve 的工作方式是加载指定的程序文件,并将它替代当前进程的内存映像。因此,执行 execve 后,原进程的代码、数据等内容都会被新程序的内容替代。
即:它的作用是执行当前 filename 对应的程序,它会覆盖当前进程的镜像、数据和堆栈等信息,包括 PID,这些都会被将要运行的进程覆盖掉。
在 Go 中的调用方式为
syscall.Exe
。 通过该系统调用,可以使用用户指定的命令启动新进程来覆盖 mydocker 进程作为容器环境中的 PID 1 进程。
即:在 init 命令中解析拿到用户指定的命令并通过
syscall.Exe
使用该命令创建新进程来覆盖 mydocker 进程。这也就是为什么我们执行
mydocker run -it /bin/sh
后 sh 会成为 PID 1 进程。
看到这里的话,mydocker run 命令的具体实现及其关键点,都完整介绍了一遍了,再回过头来看一下具体流程,应该就更清晰了:
- 1)流程开始,用户手动执行 mydocker run 命令
- 2)urfave/cli 工具解析传递过来的参数
- 3)解析完成后发现第一个参数是 run,于是执行 run 命令,调用 runCommand 方法,该方法中继续调用 NewParentProcess 函数构建一个 cmd 对象
- 4)NewParentProcess 将构建好的 cmd 对象返回给 runCommand 方法
- 5)runCommand 方法中调用 cmd.exec 执行上一步构建好的 cmd 对象
- 6)容器启动后,根据 cmd 中传递的参数,/proc/self/exe init 实则最终会执行 mydocker init 命令,初始化容器环境
- 7)init 命令内部实现就是通过 mount 命令挂载 proc 文件系统
- 8)容器创建完成,整个流程结束
FAQ
以下是在实现 mydocker run 命令时可能出现的问题
对应代码已经提交,使用本仓库代码不会出现该问题
fork/exec /proc/self/exe: no such file or directory
在正常第二次 mydocker 命令时出现该错误,具体如下:
root@mydocker:~/mydocker# ./mydocker run -it /bin/ls
{"level":"info","msg":"init come on","time":"2024-01-03T15:07:27+08:00"}
{"level":"info","msg":"command: /bin/ls","time":"2024-01-03T15:07:27+08:00"}
{"level":"info","msg":"command:/bin/ls","time":"2024-01-03T15:07:27+08:00"}
LICENSE Makefile README.md container example go.mod go.sum main.go main_command.go mydocker run.go
root@mydocker:~/mydocker# ./mydocker run -it /bin/ls
{"level":"error","msg":"fork/exec /proc/self/exe: no such file or directory","time":"2024-01-03T15:07:28+08:00"}
原因
这个是因为代码中会将容器进程的 proc 信息挂载为 proc 文件系统,具体代码如下:
// container/init.go#RunContainerInitProcess 方法
defaultMountFlags := syscall.MS_NOEXEC | syscall.MS_NOSUID | syscall.MS_NODEV
_ = syscall.Mount("proc", "/proc", "proc", uintptr(defaultMountFlags), "")
这部分代码会在 mydocker init 中执行,也就是说实际上是在容器进程中执行的 mount,当我们的 mydocker 进程运行结束退出后,容器进程就消失了。
而在引入了 systemd 之后的 linux 中,mount namespace 是 shared by default,也就是说宿主机上的 /proc 目录也被影响了。
即:宿主机 /proc 目录的内容依旧是运行 mydocker 时的信息,而此时因为 mydocker 已经退出了,对应的进程信息自然就不存在了,所以会在执行 mydocker run 中的
/proc/self/exe
这个命令时出现这个错误。
解决方案
临时解决方案
:在宿主机手动执行一次 mount,重新挂载 /proc 目录,即可将 /proc 目录恢复为正常数据
mount -t proc proc /proc
后续每次运行 mydocker 命令都会破坏掉 /proc 目录数据。
永久解决方案
:将 mount 事件显式指定为 private 即可避免挂载事件外泄,这样就不会破坏宿主机 /proc 目录数据了。
具体代码调整如下:
// container/init.go#RunContainerInitProcess 方法
// systemd 加入linux之后, mount namespace 就变成 shared by default, 所以你必须显示声明你要这个新的mount namespace独立。
// 即 mount proc 之前先把所有挂载点的传播类型改为 private,避免本 namespace 中的挂载事件外泄。
syscall.Mount("", "/", "", syscall.MS_PRIVATE|syscall.MS_REC, "")
// 如果不先做 private mount,会导致挂载事件外泄,后续再执行 mydocker 命令时 /proc 文件系统异常
// 可以执行 mount -t proc proc /proc 命令重新挂载来解决
// ---分割线---
defaultMountFlags := syscall.MS_NOEXEC | syscall.MS_NOSUID | syscall.MS_NODEV
_ = syscall.Mount("proc", "/proc", "proc", uintptr(defaultMountFlags), "")
核心为这一句:
syscall.Mount("", "/", "", syscall.MS_PRIVATE|syscall.MS_REC, "")
把所有挂载点的传播类型改为 private,避免本 namespace 中的挂载事件外泄。
相关讨论:
#33
、
#41#issuecomment-478799767
、
#58
如果你对云原生技术充满好奇,想要深入了解更多相关的文章和资讯,欢迎关注微信公众号。
搜索公众号【
探索云原生
】即可订阅
完整代码见:
https://github.com/lixd/mydocker
欢迎 Star
相关代码见 feat-run 分支,测试脚本如下:
# 克隆代码
git clone -b feat-run https://github.com/lixd/mydocker.git
cd mydocker
# 拉取依赖并编译
go mod tidy
go build .
# 测试
./mydocker run -it /bin/ls