【Unity3D】Unity与Android交互
1 前言
本文主要介绍 Unity 打包发布 Android apk 流程、基于 AndroidJavaObject(或 AndroidJavaClass)实现 Unity 调用 Java 代码、基于 UnityPlayer 实现 Java 调用 Unity 代码,官方介绍见→
Android
。
Unity 项目 C# 中获取平台的代码如下,需要引入 UnityEngine 命名空间。
RuntimePlatform platform = Application.platform;
RuntimePlatform 是枚举类型,主要平台如下。
public enum RuntimePlatform {
OSXEditor = 0, // editor on macOS.
OSXPlayer = 1, // player on macOS.
WindowsPlayer = 2, // player on Windows.
OSXWebPlayer = 3, // web player on macOS.
...
WindowsWebPlayer = 5, // web player on Windows.
WindowsEditor = 7, // editor on Windows.
IPhonePlayer = 8, // player on the iPhone.
Android = 11, // player on Android.
...
WebGLPlayer = 17, // player on WebGL
...
LinuxPlayer = 13, // player on Linux.
LinuxEditor = 16, // editor on Linux.
...
}
2 Unity 发布 apk
2.1 安装 Android Build Support
在 Unity Hub 中打开添加模块窗口,操作如下。

选择 Android Build Support 安装,如下(笔者这里已安装过)。

创建一个 Unity 项目,依次点击【File→Build Settings→Android→Switch Platform】,配置如下。

依次点击【Edit→Preferences→External Tools】打开 JDK、SDK、NDK、Gradle 配置页面,勾选默认配置,如下。

Unity Editor 不同版本默认下载的 Gradle 版本如下,官方介绍见→
Gradle for Android
。

用户也可以选择已安装的 JDK、SDK、NDK、Gradle 路径,如下。

笔者的具体环境配置如下:
Unity Editor: 2021.3.11f1c2
JDK: 1.8.0_391
SDK Platforms: 29
SDK Build-Tools: 30.0.3
SDK Command-line Tools: 11.0
SDK Platform-Tools: 34.0.5
NDK: 21.3.6528147
Gradle: 6.1.1
Gradle Plugin: 4.0.1
2.2 配置密钥
依次点击【Edit→Project Settings→Player→Keystore Manager】(也可以从【File→Build Settings→Player Settings→Keystore Manager】中进入),操作如下。

打开 Keystore Manager 后, 依次点击【Create New→Anywhere】,选择一个目录保存密钥库文件,笔者保存在项目目录下面的【Keystore/user.keystore】中。

接着设置密码和别名,其他选项不是必设项。

Add Key 后,会弹出 “是否将创建的密钥库作为项目的密钥库” 弹窗,点击 yes 确认。

设置密钥后,回到 Project Settings 页面,显示如下。

创建密钥时,也可以通过以下命令创建。
keytool -genkey -keyalg RSA -alias key_name -keystore keystore_name -validity day_time
keytool -genkey -keyalg RSA -alias first -keystore user -validity 36500

2.3 打包 apk
依次点击【File→Build Settings→Player Settings】,配置公司名、项目名、版本号等信息,如下。

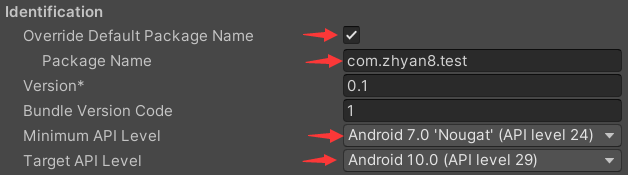
在 Other Settings 中配置包名、Android SDK 的最小 API 版本、目标 API 版本等信息,如下。
关闭 Player Settings,在 Build Settings 页面点击底部的 Build,构建 apk。
2.4 案例
新建一个 Unity 项目,修改 Game 页面的屏幕尺寸,如下。

搭建页面如下。

给 Button 按钮添加脚本,如下。
Test.cs
using UnityEngine;
using UnityEngine.UI;
public class Test : MonoBehaviour {
private Button button;
private void Start() {
button = GetComponent<Button>();
button.onClick.AddListener(OnClick);
}
private void OnClick() {
Debug.Log("Test-OnClick");
}
}
编译 apk 后,打开命令行窗口,输入以下命令,将 apk 安装到手机上。
adb instll -r -t -d Test.apk
运行 apk 后,在命令行窗口中通过以下命令查看日志。
adb logcat | findstr "Test-OnClick"
点击 Button 按钮,打印日志如下。

3 Unity 调 Android 的逻辑
3.1 Unity 项目中部署 Android 代码
1)拷贝 Java 源码到 Unity 项目
可以将 Android 项目中 Java 代码拷贝到 Unity 项目中 Assets 子目录下,如下,接着就可以通过 AndroidJavaClass 或 AndroidJavaObject 访问 Java 代码了。

2)打包 Jar 到 Unity 项目
可以将 Android 项目打包为 Jar,再将 Jar 拷贝到 Unity 项目中 Assets 子目录下,接着就可以通过 AndroidJavaClass 或 AndroidJavaObject 访问 Java 代码了。
修改 Android 项目中 Module 的 build.gradle 文件,如下,主要将 id 由 'com.android.application' 修改为 'com.android.library',删除 android { } 模块中的 defaultConfig、buildTypes、compileOptions 等子模块。
build.gradle
apply plugin: 'com.android.library'
android {
compileSdkVersion 29
buildToolsVersion '30.0.3'
compileOptions {
sourceCompatibility JavaVersion.VERSION_1_8
targetCompatibility JavaVersion.VERSION_1_8
}
}
dependencies {
implementation 'androidx.appcompat:appcompat:1.6.1'
implementation 'com.google.android.material:material:1.8.0'
implementation 'androidx.constraintlayout:constraintlayout:2.1.4'
testImplementation 'junit:junit:4.13.2'
androidTestImplementation 'androidx.test.ext:junit:1.1.5'
androidTestImplementation 'androidx.test.espresso:espresso-core:3.5.1'
}
修改 build.gradle 文件后,需要点击右上角的 Sync Now 同步,接着按以下步骤编译项目。

编译结束后,在 Module 的【build\intermediates\aar_main_jar\debug】目录下生成打包的 classes.jar。

预览 classes.jar 文件如下。

3.2 AndroidJavaObject 和 AndroidJavaClass
AndroidJavaObject 和 AndroidJavaClass 是 Unity 提供的调用 Java 代码的 2 个类,AndroidJavaClass 继承 AndroidJavaObject,它们只有构造方法有一点差异,没有其他的差异,因此,本节只介绍 AndroidJavaObject。
1)Set 和 Get 属性
JavaTest.java
package com.zhyan8.test;
public class JavaTest {
public static int intVal = 0;
private String strVal = "abc";
}
说明:对于 JavaTest 的 private 属性,AndroidJavaObject 也可以访问到。
UnityTest.cs
using UnityEngine;
public class UnityTest : MonoBehaviour {
private void Start() {
AndroidJavaObject javaObject = new AndroidJavaObject("com.zhyan8.test.JavaTest");
// 静态属性Set/Get
javaObject.SetStatic<int>("intVal", 123);
int intVal = javaObject.GetStatic<int>("intVal");
Debug.Log("UnityTest, intVal=" + intVal); // 打印: UnityTest, intVal=123
// 非静态属性Set/Get
javaObject.Set<string>("strVal", "xyz");
string strVal = javaObject.Get<string>("strVal");
Debug.Log("UnityTest, strVal=" + strVal); // 打印: UnityTest, strVal=xyz
}
}
2)调用方法
JavaTest.java
package com.zhyan8.test;
import android.util.Log;
public class JavaTest {
public static void fun1() {
Log.d("JavaTest", "fun1"); // 打印: JavaTest: fun1
}
private int fun2() {
Log.d("JavaTest", "fun2"); // 打印: JavaTest: fun2
return 123;
}
public String fun3(int value) {
Log.d("JavaTest", "fun3, value=" + value); // 打印: JavaTest: fun3, value=235
return "Call fun3";
}
public String fun4(String value1, int value2) {
Log.d("JavaTest", "fun4, value1=" + value1 + ", value2=" + value2); // 打印: JavaTest: fun4, value1=abc, value2=123
return value1 + value2;
}
}
说明:对于 JavaTest 的 private 方法,AndroidJavaObject 也可以访问到。
UnityTest.cs
using UnityEngine;
public class UnityTest : MonoBehaviour {
private void Start() {
AndroidJavaObject javaObject = new AndroidJavaObject("com.zhyan8.test.JavaTest");
// 静态方法
javaObject.CallStatic("fun1");
// 非静态无参方法
int val2 = javaObject.Call<int>("fun2");
Debug.Log("UnityTest, val2=" + val2); // 打印: UnityTest, val2=123
// 非静单参方法
string val3 = javaObject.Call<string>("fun3", 235);
Debug.Log("UnityTest, val3=" + val3); // 打印: UnityTest, val3=Call fun3
// 非静双参方法
string val4 = javaObject.Call<string>("fun4", "abc", 123);
Debug.Log("UnityTest, val4=" + val4); // 打印: UnityTest, val4=abc123
}
}
运行程序后,打印日志如下。

3.3 Unity 调用 Android 的 Toast
UnityTest.cs
using UnityEngine;
using UnityEngine.UI;
public class UnityTest : MonoBehaviour {
private void Start() {
GetComponent<Button>().onClick.AddListener(() => {
Toast("Clicked", 1);
});
}
// 调用Android的代码: Toast.makeText(context, msg, durationFlag).show();
private void Toast(string msg, int durationFlag) { // durationFlag: Toast.LENGTH_SHORT=0, Toast.LENGTH_LONG=1
AndroidJavaClass toastClass = new AndroidJavaClass("android.widget.Toast");
AndroidJavaClass unityPlayerClass = new AndroidJavaClass("com.unity3d.player.UnityPlayer");
AndroidJavaObject currentActivity = unityPlayerClass.GetStatic<AndroidJavaObject>("currentActivity");
AndroidJavaObject toast = toastClass.CallStatic<AndroidJavaObject>("makeText", currentActivity, msg, durationFlag);
toast.Call("show");
}
}
UnityPlayer 是 Unity 引擎提供的 Java 类,在 Unity Editor 目录下的【Data\PlaybackEngines\AndroidPlayer\Variations\mono\Release\Classes\classes.jar】 中。
运行效果如下。

4 Android 调 Unity 的逻辑
4.1 Unity 打包为 Android 项目
在 Build Settings 页面勾选 Export Project 后,点击 Export 按钮,如下。

构建成功后,Unity 项目将会被打包成一个 Android 项目,我们可以使用 Android Studio 打开生成的 Android 项目,如下。

其中,UnityPlayerActivity 是启动的 Main Activity,unity-classes.jar 是 Unity Editor 中的 Jar 包,位置见【Unity Hub\Unity\Editor\2021.3.11f1c2\Editor\Data\PlaybackEngines\AndroidPlayer\Variations\mono\Release\Classes\classes.jar】,我们常用的 UnityPlayer 类就在该 Jar 文件中。
如果用户想将 Android 项目打包到 Unity 项目中,但是 Android 项目中又要引用 Unity 的接口,用户可以将 Unity Editor 中的 classes.jar 拷贝到 Android 项目中,如下。

右键 classes.jar,在弹出菜单中选择 Add As Library。
4.2 UnityPlayer
UnityPlayer 继承 FrameLayout,主要用于 Java 调用 Unity 代码,其主要属性和方法如下。
// 在UnityPlayer的构造方法中初始化, currentActivity = this.mActivity
public static Activity currentActivity = null;
// java调用Unity中的方法, gameObject: 游戏对象名, method: 游戏对象上挂载脚本中的方法名, params: 方法参数
public static void UnitySendMessage(String gameObject, String method, String params)
说明:UnitySendMessage 可以调用 private 方法,只能调用无参和单参数方法,不能调用 static 方法,无法获取方法返回值。
4.3 案例
UseUnity.cs
using UnityEngine;
public class UseUnity : MonoBehaviour {
private void Start() {
AndroidJavaObject javaObject = new AndroidJavaObject("com.zhyan8.test.JavaTest");
javaObject.Call("start");
}
public void Fun1() {
Debug.Log("UseUnity-Fun1"); // 打印: UseUnity-Fun1
}
private void Fun2(string value) {
Debug.Log("UseUnity-Fun2, value=" + value); // 打印: UseUnity-Fun2, value=xyz
}
}
说明:UseUnity 脚本组件挂在 TestObj 对象上。
JavaTest.java
package com.zhyan8.test;
import android.util.Log;
import com.unity3d.player.UnityPlayer;
public class JavaTest {
public void start() {
fun1();
fun2();
}
private void fun1() {
Log.d("JavaTest", "fun1"); // 打印: JavaTest: fun1
UnityPlayer.UnitySendMessage("TestObj", "Fun1", "");
}
private void fun2() {
Log.d("JavaTest", "fun2"); // 打印: JavaTest: fun2
UnityPlayer.UnitySendMessage("TestObj", "Fun2", "xyz");
}
}
打印日志如下:

声明:本文转自
【Unity3D】Unity与Android交互
。









































