编写高效的代码,你应该了解Array、Memory、ReadOnlySequence
针对“缓冲区”编程是一个非常注重“性能”的地方,我们应该尽可能地避免武断地创建字节数组来存储读取的内容,这样不但会导致大量的字节拷贝,临时创建的字节数组还会带来GC压力。要正确、高效地读写缓冲内容,我们应该对几个我们可能熟悉的类型具有更深的认识。
一、Array、ArraySegment、Span<T>、Memory<T>与String
二、MemoryManager<T>
三、ReadOnlySequence<T>
四、创建“多段式”ReadOnlySequence<T>
五、高效读取ReadOnlySequence<T>
一、Array、ArraySegment、Span<T>、Memory<T>与String
Array、ArraySegment、Span<T>、Memory<T>,以及ReadOnlySpan<T>与ReadOnlyMemory<T>本质上都映射一段连续的内存,但是它们又有些差异,导致它们具有各自不同的应用场景。Array是一个类(引用类型),所以一个Array对象是一个托管对象,其映射的是一段托管堆内存。正因为Array是一个托管对象,所以它在托管堆中严格遵循“三段式(Object Header + TypeHandle + Payload)”内存布局,Payload部分包含前置的长度和所有的数组元素(数组的内存布局可以参阅我的文章《
.NET中的数组在内存中如何布局?
》),其生命周期受GC管理。
顾名思义,ArraySegment代表一个Array的“切片”,它利用如下所示的三个字段(_array、_offset和count)引用数组的一段连续的元素。由于Array是托管对象,所以ArraySegment映射的自然也只能是一段连续的托管内存。由于它是只读结构体(值类型),对GC无压力,在作为方法参数时按照“拷贝”传递。
public readonly struct ArraySegment<T> { private readonly T[] _array; private readonly int _offset; private readonly int _count; public T[]? Array => _array; public int Offset => _offset; public int Count => _count; }
不同于ArraySegment,一个Span<T>不仅仅可以映射一段连续的托管内存,还可以映射一段连续的非托管内存;不仅可以映射一段栈内存(比如Span<byte> buffer = stackalloc byte[8]),这一点可以从它定义的构造函数看出来。
public readonly ref struct Span<T> { public Span(T[]? array); public Span(T[]? array, int start, int length); public unsafe Span(void* pointer, int length); public Span(ref T reference); internal Span(ref T reference, int length); }
由于Span<T>是一个只读引用结构体,意味着它总是以引用的方式被使用,换言之当我们使用它作为参数传递时,传递的总是这个变量自身的栈地址。正因为如此,在某个方法中创建的Span<T>只能在当前方法执行范围中被消费,如果“逃逸”出这个范围,方法对应的栈内存会被回收。所以和其他引用结构体一样,具有很多的使用上限制(可以参阅我的文章《
除了参数,ref关键字还可以用在什么地方?
》),所以我们才有了Memory<T>。
由于Memory<T>就是一个普通的只读结构体,所以在使用上没有任何限制。但是也正因为如此,它只能映射一段连续的托管堆内存和非托管内存,不能映射栈内存。从如下所示的构造函数可以看出,我们可以根据一个数组对象的切片创建一个Memory<T>,此时它相当于一个ArraySegment<T>,针对非托管内存的映射需要是借助一个MemoryManager<T>对象来实现的。
public readonly struct Memory<T> { public Memory(T[]? array);
internal Memory(T[] array, int start); public Memory(T[]? array, int start, int length); internal Memory(MemoryManager<T> manager, int length); internal Memory(MemoryManager<T> manager, int start, int length); }
Span<T>和Memory<T>虽然自身是自读结构体,但是它Cover的“片段”并不是只读的,我们可以在对应的位置写入相应的内容。在只读的场景中,我们一般会使用它们的只读版本ReadOnlySpan<T>和ReadOnlySpanMemory<T>。除了这些,我们还会经常使用另一种类型的“连续内存片段”,那就是字符串,其内存布局可以参阅《
你知道.NET的字符串在内存中是如何存储的吗?
》
二、MemoryManager<T>
从上面给出的Memory<T>构造函数可以看出,一个Memory<T>可以根据一个MemoryManager<T>来创建的。MemoryManager<T>是一个抽象类,从其命名可以看出,它用来“管理一段内存”。具体它可以实施怎样的内存管理功能呢?我们先从它实现的两个接口开始说起。
MemoryManager<T>实现的第一个接口为如下这个IMemoryOwner<T> ,顾名思义,它代表某个Memory<T>对象(对应Memory属性)的持有者,我们用它来管理Memory<T>对象的生命周期。比如表示内存池的MemoryPool<T>返回的就是一个IMemoryOwner<T>对象,我们利用该对象得到从内存池中“借出”的Memory<T>对象,如果不再需要,直接调用IMemoryOwner<T>对象的Dispose方法将其“归还”到池中。
public interface IMemoryOwner<T> : IDisposable { Memory<T> Memory { get; } }
托管对象可以以内存地址的形式进行操作,但前提是托管对象在内存中的地址不会改变,但是我们知道GC在进行压缩的时候是会对托管对象进行移动,所以我们需要固定托管内存的地址。MemoryManager<T>实现了第二个接口IPinnable提供了两个方法,指定元素对象内存地址的固定通过Pin方法来完成,该方法返回一个MemoryHandle对象,后者利用封装的GCHandle句柄来持有执行指针指向的内存。另一个方法Unpin用来解除内存固定。
public interface IPinnable { MemoryHandle Pin(int elementIndex); void Unpin(); } public struct MemoryHandle : IDisposable { private unsafe void* _pointer; private GCHandle _handle; private IPinnable _pinnable; [CLSCompliant(false)] public unsafe void* Pointer => _pointer; [CLSCompliant(false)] public unsafe MemoryHandle(void* pointer, GCHandle handle = default(GCHandle), IPinnable? pinnable = null) { _pointer = pointer; _handle = handle; _pinnable = pinnable; } public unsafe void Dispose() { if (_handle.IsAllocated) { _handle.Free(); } if (_pinnable != null) { _pinnable.Unpin(); _pinnable = null; } _pointer = null; } }
抽象类MemoryManager<T>定义如下。它提供了一个抽象方法GetSpan,并利用它返回的Span<T>来创建Memory属性返回的Memory<T>。针对IPinnable接口的两个方法Pin和Unpin体现为两个抽象方法。
public abstract class MemoryManager<T> : IMemoryOwner<T>, IPinnable { public virtual Memory<T> Memory => new(this, GetSpan().Length); public abstract Span<T> GetSpan(); public abstract MemoryHandle Pin(int elementIndex = 0); public abstract void Unpin(); protected Memory<T> CreateMemory(int length) => new(this, length); protected Memory<T> CreateMemory(int start, int length)=> new(this, start, length); protected internal virtual bool TryGetArray(out ArraySegment<T> segment) { segment = default; return false; } void IDisposable.Dispose() { Dispose(disposing: true); GC.SuppressFinalize(this); } protected abstract void Dispose(bool disposing); }
如果我们需要创建了针对非托管内存的Memory<T>,可以按照如下的形式自定义一个MemoryManager<T>派生类UnmanagedMemoryManager<T>,然后根据这样一个对象创建Memory<T>对象即可。
public sealed unsafe class UnmanagedMemoryManager<T> : MemoryManager<T> where T : unmanaged { private readonly T* _pointer; private readonly int _length; private MemoryHandle? _handle; public UnmanagedMemoryManager(T* pointer, int length) { _pointer = pointer; _length = length; } public override Span<T> GetSpan() => new(_pointer, _length); public override MemoryHandle Pin(int elementIndex = 0)=> _handle ??= new (_pointer + elementIndex); public override void Unpin() => _handle?.Dispose(); protected override void Dispose(bool disposing) { } }
三、ReadOnlySequence<T>
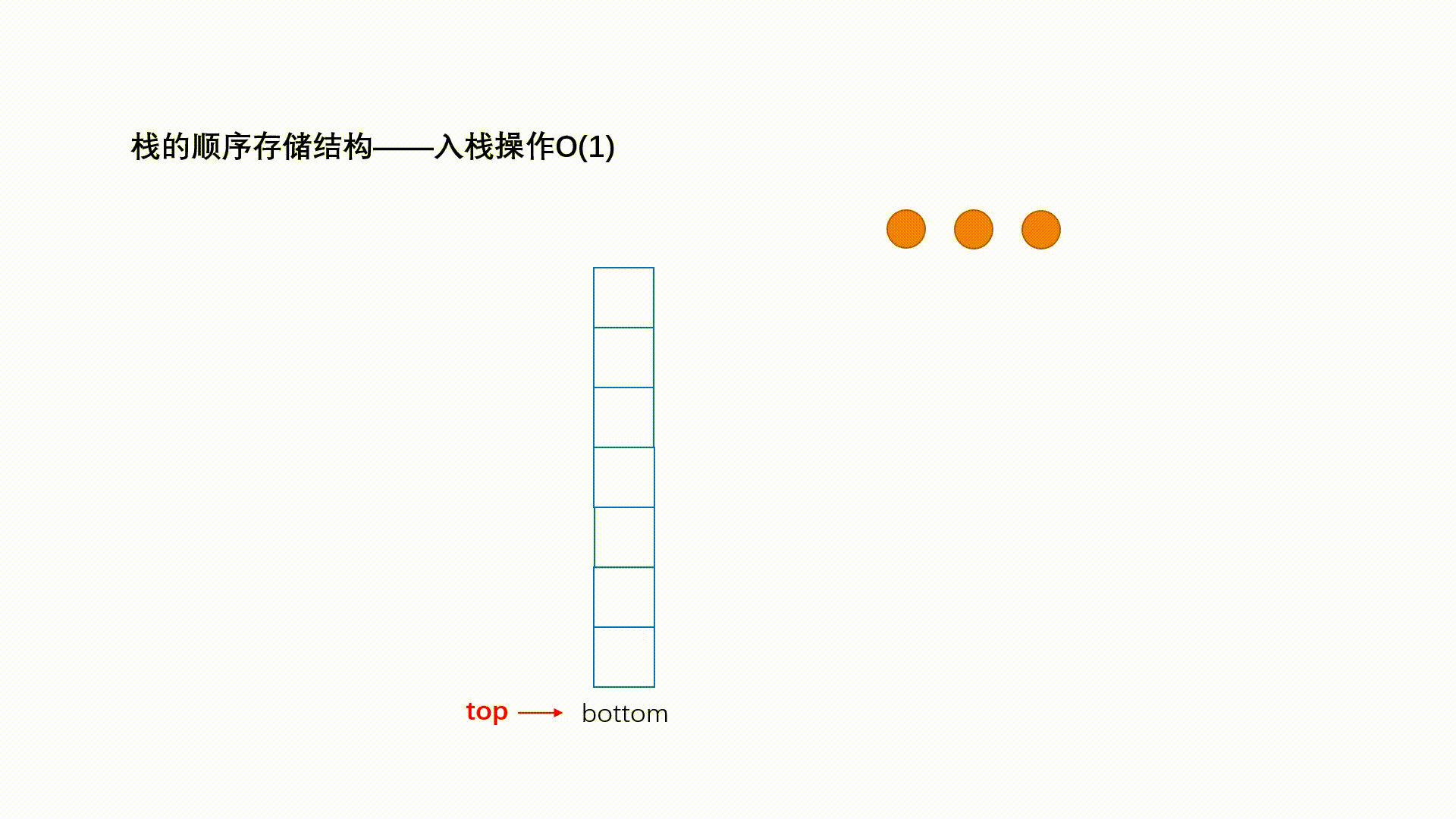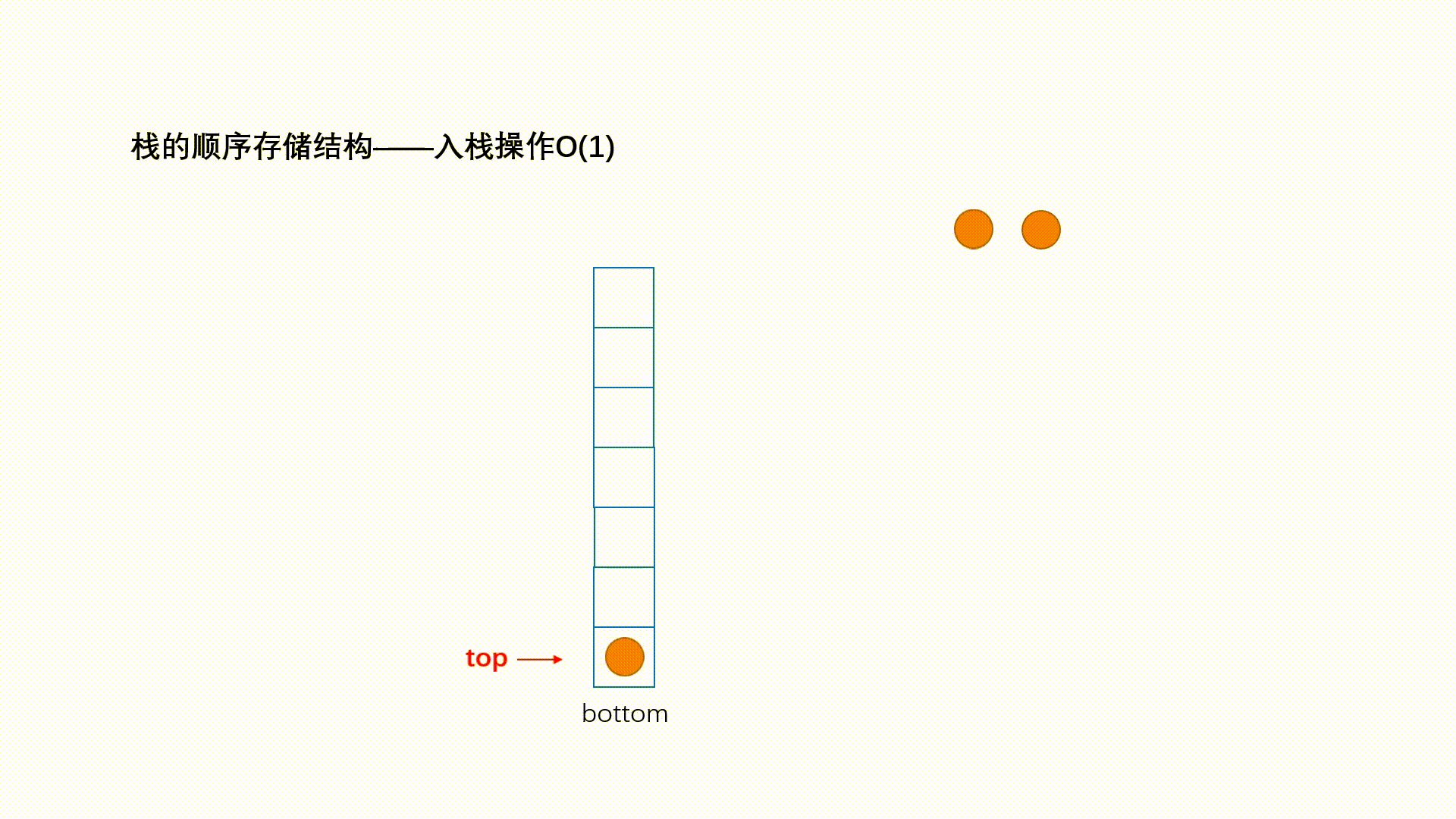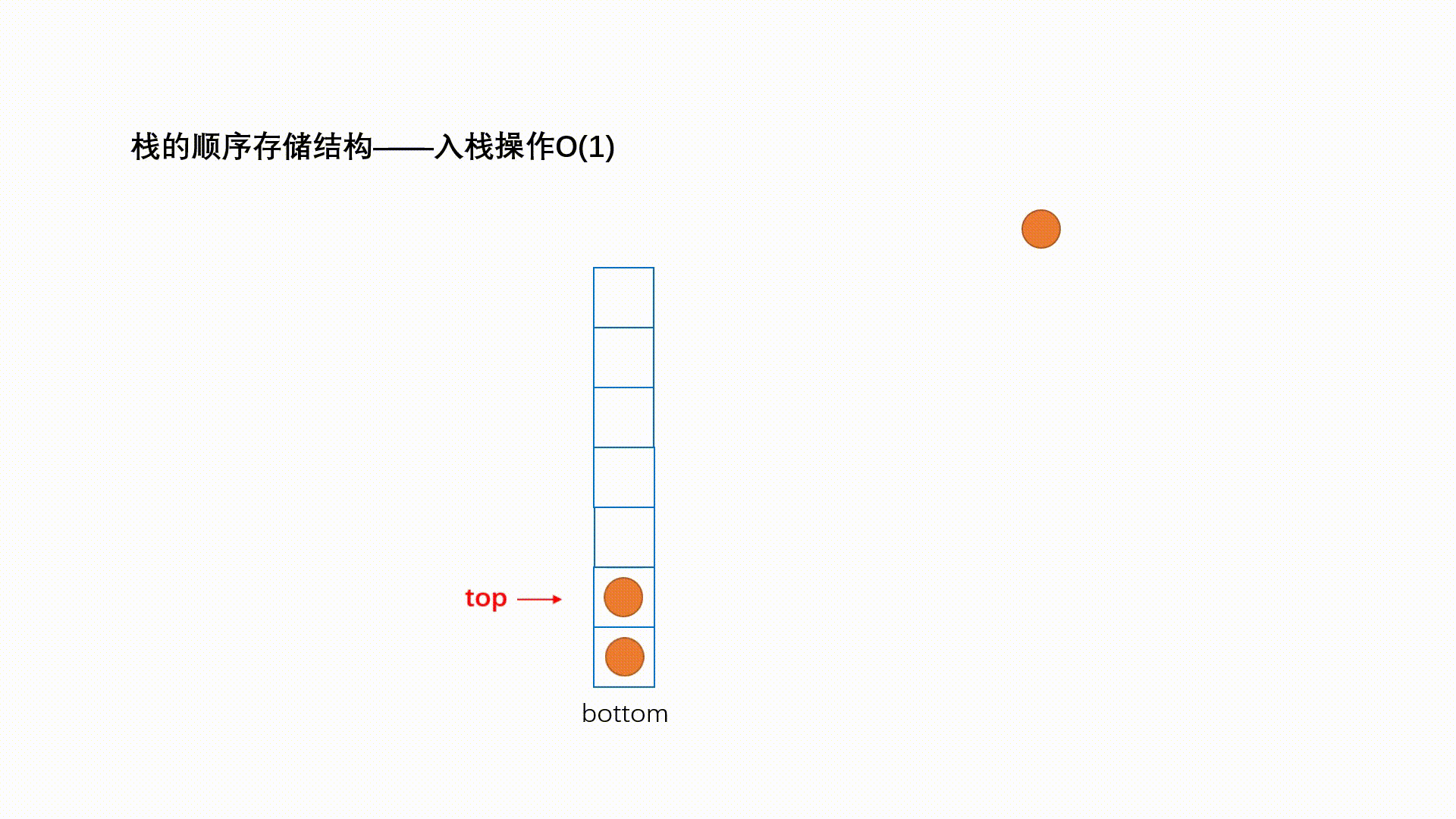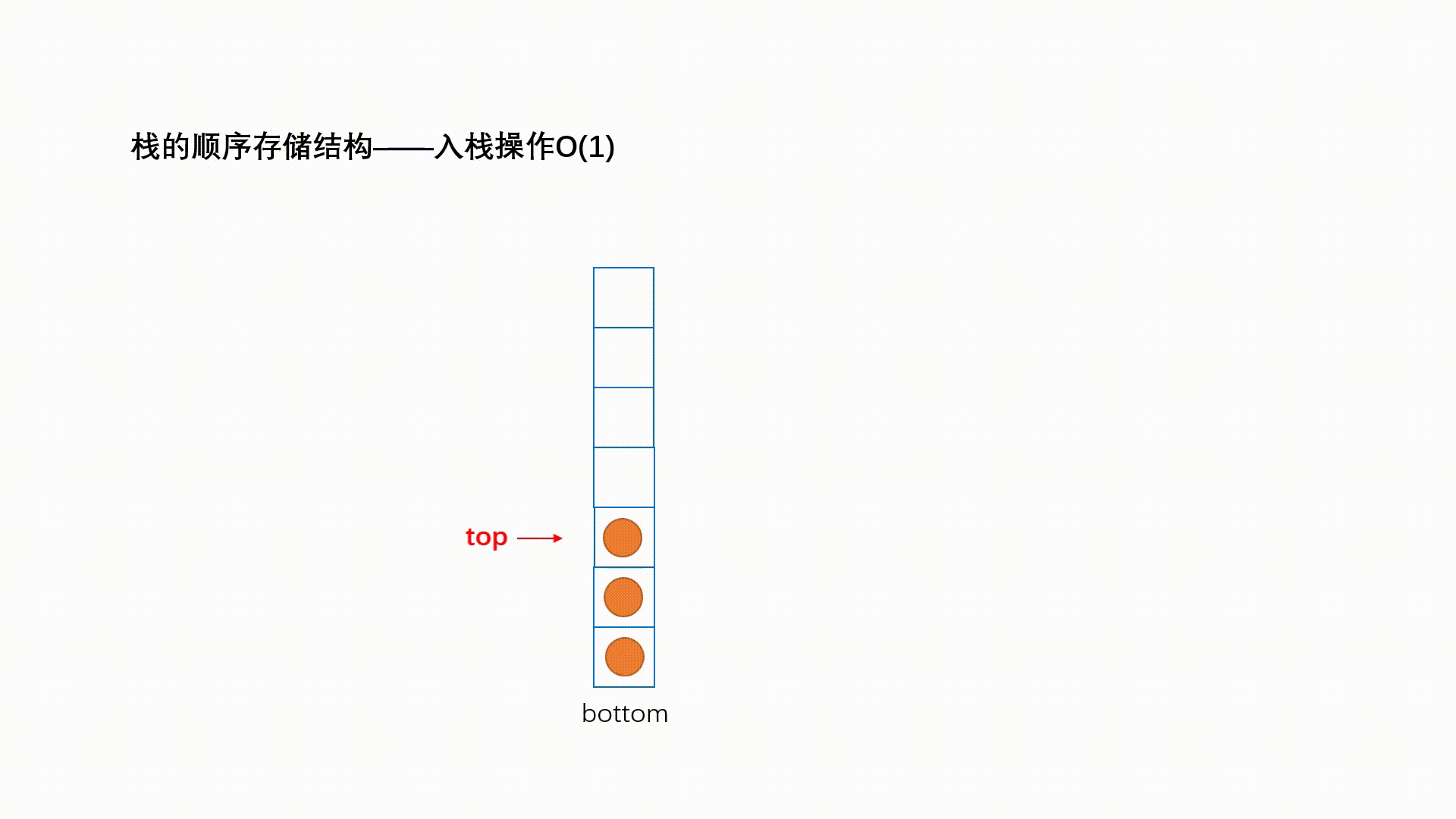
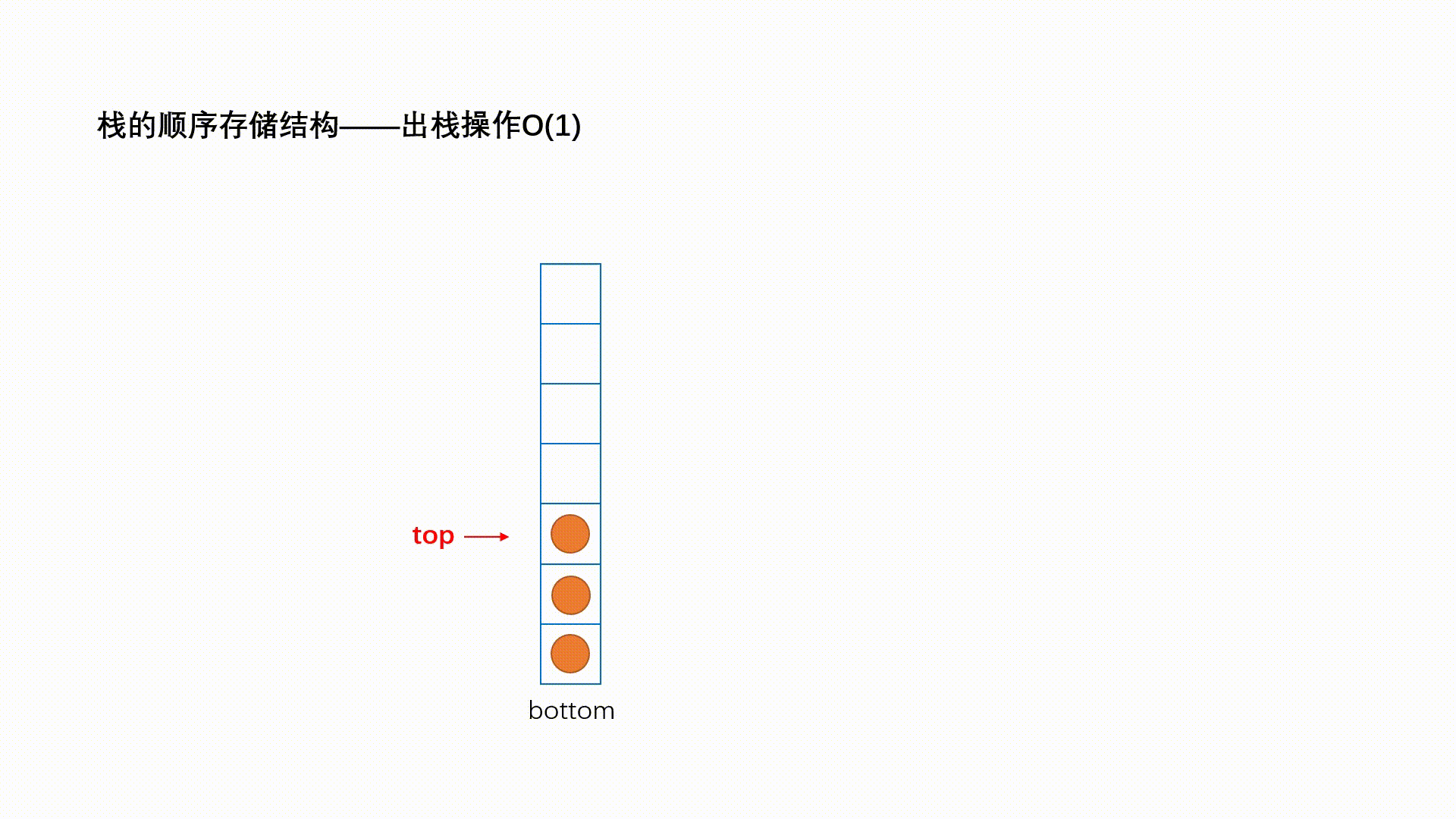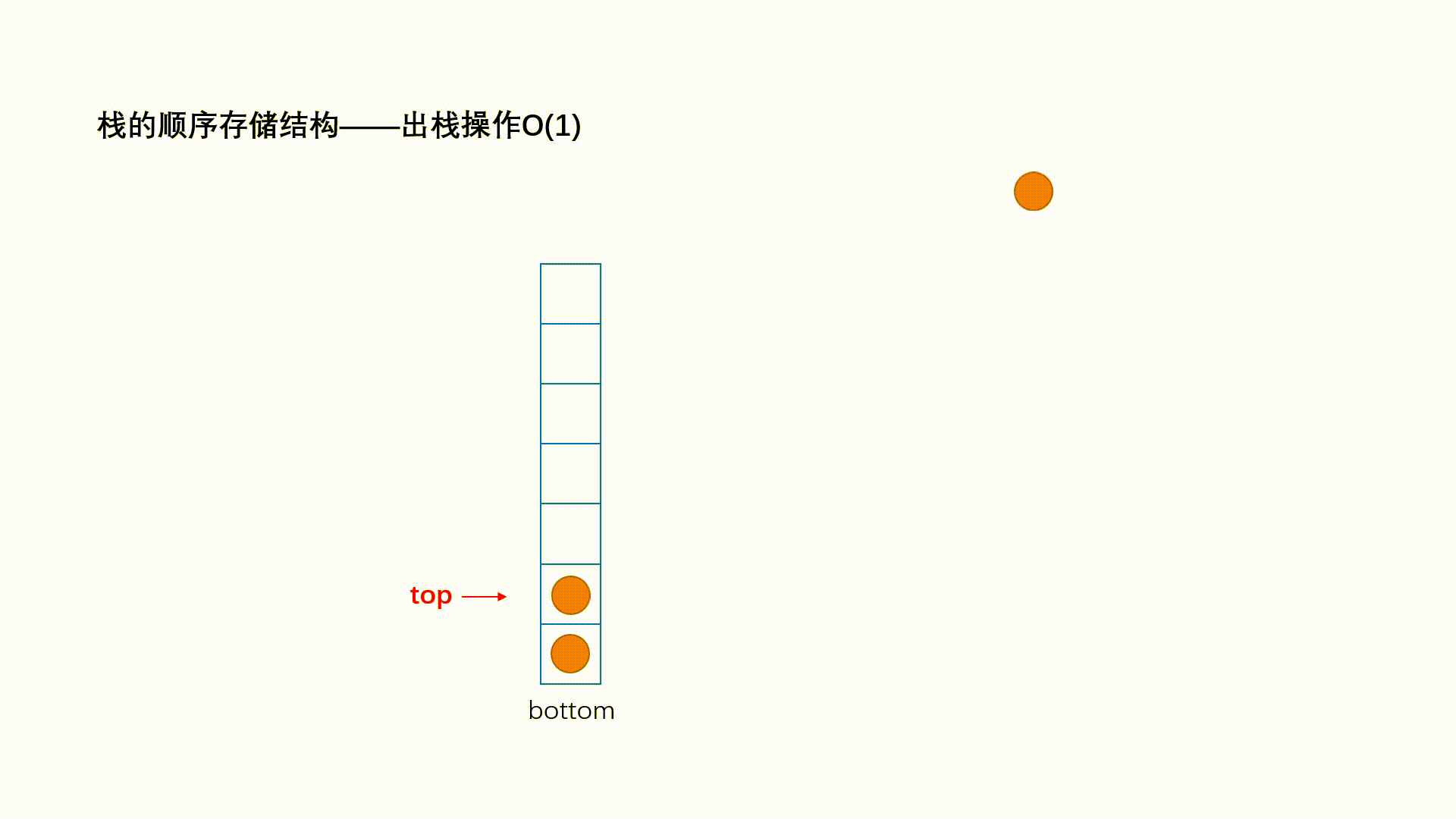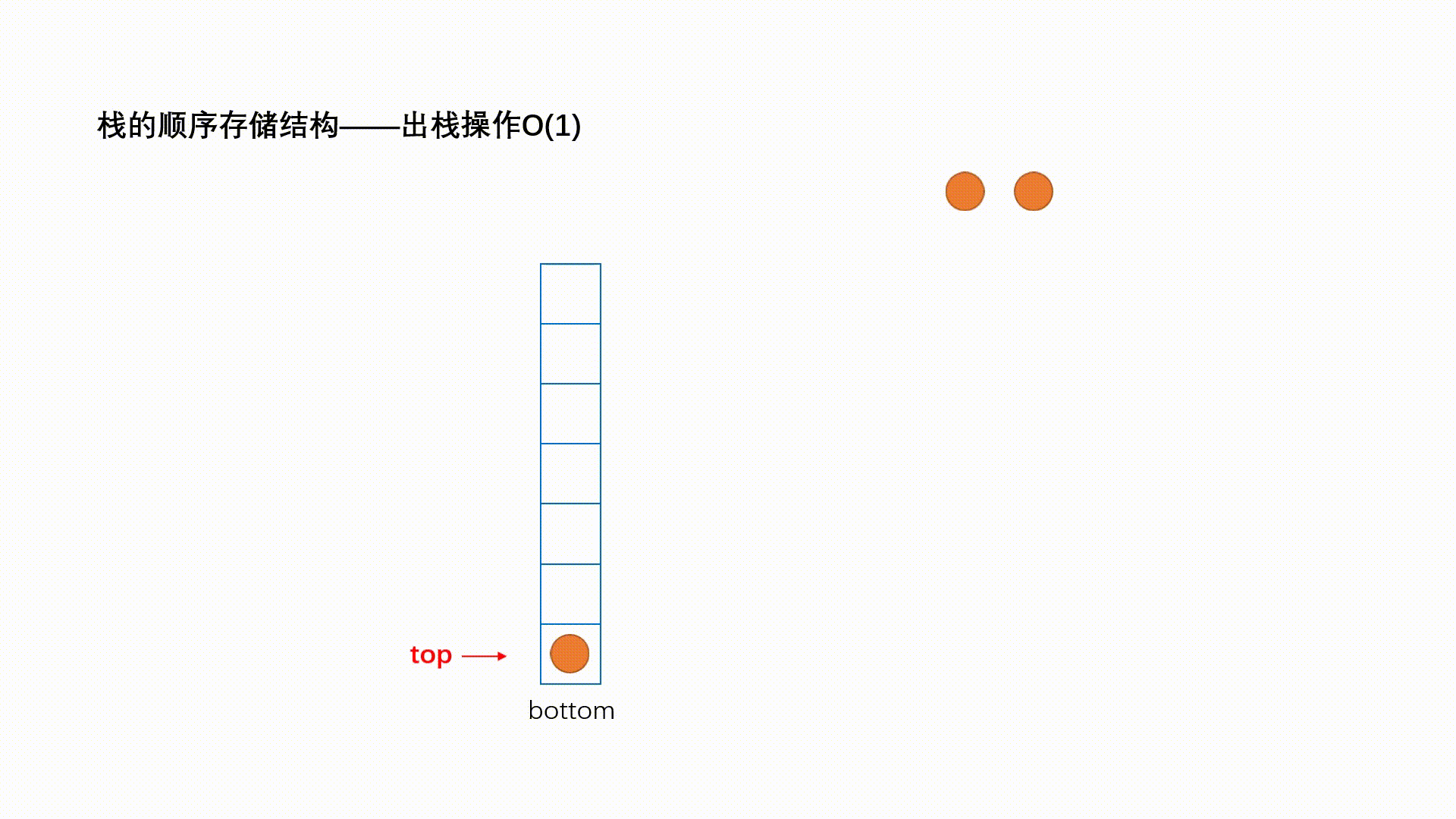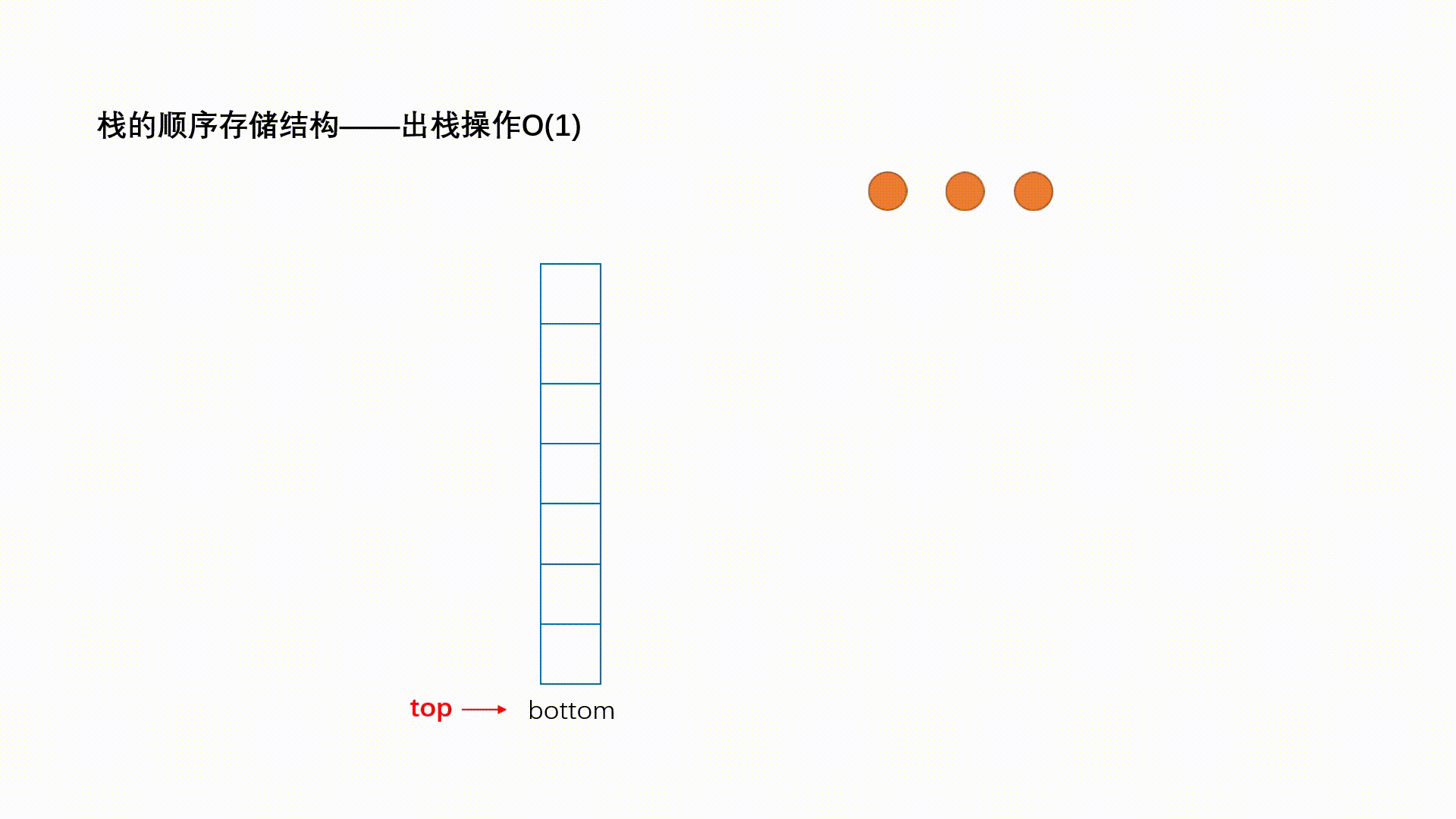
ReadOnlySequence<T>代表由一个或者多个连续内存“拼接”而成的只读序列,下图演示了一个典型的”三段式序列。“单段式”序列本质上就是一个ReadOnlyMemory<T>对象,“多段式”序列则由多个ReadOnlyMemory<T>多个借助ReadOnlySequenceSegment<T>连接而成。

ReadOnlySequenceSegment<T>是一个抽象类,它表示组成序列的一个片段。ReadOnlySequenceSegment<T>是对一个ReadOnlyMemory<T>对象(对应Memory属性)的封装,同时利用Next属性连接下一个片段,另一个RunningIndex属性表示序列从头到此的元素总量。
public abstract class ReadOnlySequenceSegment<T> { public ReadOnlyMemory<T> Memory { get; protected set; } public ReadOnlySequenceSegment<T>? Next { get; protected set; } public long RunningIndex { get; protected set; } }
结构体SequencePosition定义如下,它表示ReadOnlySequence<T>序列的某个“位置”。具体来说,GetObject方法返回的对象代表具有连续内存布局的某个对象,可能是托管数组、非托管指针,还可能是一个字符串对象(如果泛型参数类型为char)。GetInteger返回针对该对象的“偏移量”。
public readonly struct SequencePosition { public object? GetObject(); public int GetInteger(); public SequencePosition(object? @object, int integer); }
ReadOnlySequence<T>结构体的成员定义如下,我们可以通过Length属性得到序列总长度,通过First和FirstSpan属性以ReadOnlyMemory<T>和ReadOnlySpan<T>的形式得到第一个连续的内存片段,通过Start和End属性得到以SequencePosition结构表示起止位置,还可以通过IsSingleSegment确定它是否是一个“单段”序列。通过四个构造函数重载,我们可以利用Array、ReadOnlyMemory<T>和ReadOnlySequenceSegment<T>来创建ReadOnlySequence<T>结构。
public readonly struct ReadOnlySequence<T>
{
public long Length { get; }
public bool IsEmpty { get; }
public bool IsSingleSegment { get; }
public ReadOnlyMemory<T> First { get; }
public ReadOnlySpan<T> FirstSpan { get; }
public SequencePosition Start { get; }
public SequencePosition End { get; }public ReadOnlySequence(T[] array);
public ReadOnlySequence(T[] array, int start, int length);
public ReadOnlySequence(ReadOnlyMemory<T> memory);
public ReadOnlySequence(ReadOnlySequenceSegment<T> startSegment, int startIndex, ReadOnlySequenceSegment<T> endSegment, int endIndex);
public ReadOnlySequence<T> Slice(long start, long length);
public ReadOnlySequence<T> Slice(long start, SequencePosition end);
public ReadOnlySequence<T> Slice(SequencePosition start, long length);
public ReadOnlySequence<T> Slice(int start, int length);
public ReadOnlySequence<T> Slice(int start, SequencePosition end);
public ReadOnlySequence<T> Slice(SequencePosition start, int length);
public ReadOnlySequence<T> Slice(SequencePosition start, SequencePosition end);
public ReadOnlySequence<T> Slice(SequencePosition start);
public ReadOnlySequence<T> Slice(long start);public Enumerator GetEnumerator();
public SequencePosition GetPosition(long offset);
public long GetOffset(SequencePosition position);
public SequencePosition GetPosition(long offset, SequencePosition origin);
public bool TryGet(ref SequencePosition position, out ReadOnlyMemory<T> memory, bool advance = true);
}
利用定义的若干Slice方法重载,我们可以对一个ReadOnlySequence<T>对象进行“切片”。GetPosition方法根据指定的偏移量得到所在的位置,而GetOffset则根据指定的位置得到对应的偏移量。TryGet方法根据指定的位置得到所在的ReadOnlyMemory<T> 。我们还可以利用foreach对ReadOnlySequence<T>实施遍历,迭代器通过GetEnumerator方法返回。
四、创建“多段式”ReadOnlySequence<T>
“单段式”ReadOnlySequence<T>本质上就相当于一个ReadOnlyMemory<T>对象,“多段式”ReadOnlySequence则需要利用ReadOnlySequenceSegment<T>将多个ReadOnlyMemory<T>按照指定的顺序“串联”起来。如下这个BufferSegment<T>类型提供了简单的实现。
var segment1 = new BufferSegment<int>([7, 8, 9]); var segment2 = new BufferSegment<int>([4, 5, 6], segment1); var segment3 = new BufferSegment<int>([1, 2, 3], segment2); var index = 0; foreach (var memory in new ReadOnlySequence<int>(segment3, 0, segment1, 4)) { var span = memory.Span; for (var i = 0; i < span.Length; i++) { Debug.Assert(span[i] == index++); } } public sealed class BufferSegment<T> : ReadOnlySequenceSegment<T> { public BufferSegment(T[] array, BufferSegment<T>? next = null) : this(new ReadOnlyMemory<T>(array), next) { } public BufferSegment(T[] array, int start, int length, BufferSegment<T>? next = null):this(new ReadOnlyMemory<T>(array,start,length), next) { } public BufferSegment(ReadOnlyMemory<T> memory, BufferSegment<T>? next = null) { Memory = memory; Next = next; var current = next; while (current is not null) { current.RunningIndex += memory.Length; } } }
五、高效读取ReadOnlySequence<T>
由于ReadOnlySequence<T>具有“单段”和“多段”之分,在读取的时候应该区分这两种情况以实现最高的性能。比如我们在处理缓冲内容的时候,经常会读取前4个字节内容来确定后续内容的长度,就应该按照如下所示的这个TryReadInt32方法来实现。如代码所示,我们先判断ReadOnlySequence<
byte
>的长度大于4个字节,然后再切取前四个字节。如果切片是一个“单段式”ReadOnlySequence<
byte
>(大概率是),我们直接读取FirstSpan属性返回的ReadOnlySpan<byte>就可以了。如果是多段式,为了避免创建一个字节数组,而是采用stackalloc关键字在线程堆栈中创建一个4字节的Span<byte>,并将切片内容拷贝其中,然后读取其中内容即可。由于长度已经读取出来了,我们最后还应该重置ReadOnlySequence<
byte
>将前4个字节剔除。
static bool TryReadInt32(ref ReadOnlySequence<byte> buffer, out int? value) { if (buffer.Length < 4) { value = null; return false; } var slice = buffer.Slice(buffer.Start, 4); if (slice.IsSingleSegment) { value = BinaryPrimitives.ReadInt32BigEndian(slice.FirstSpan); } else { Span<byte> bytes = stackalloc byte[4]; slice.CopyTo(bytes); value = BinaryPrimitives.ReadInt32BigEndian(bytes); } buffer = buffer.Slice(slice.End); return true; },
其实针对ReadOnlySequence<T>的读取还有更简单的方式,那就是直接使用SequenceReader,比如上面这个TryReadInt32方法也可以写成如下的形式。
static bool TryReadInt32(ref ReadOnlySequence<byte> buffer, out int? value) { var reader = new SequenceReader<byte>(buffer); if (reader.TryReadBigEndian(out int v)) { value = v; buffer = buffer.Slice(4); return true; } value = null; return false; }