一、简介
在很多场景下,我们经常听到采用
多线程编程
,能显著的提升程序的执行效率。例如执行大批量数据的插入操作,采用单线程编程进行插入可能需要 30 分钟,采用多线程编程进行插入可能只需要 5 分钟就够了。
既然多线程编程技术如此厉害,那什么是多线程呢?
在介绍多线程之前,我们还得先讲讲进程和线程的概念。
二、进程和线程
2.1、什么是进程?
从计算机角度来讲,
进程是操作系统中的基本执行单元,也是操作系统进行资源分配和调度的基本单位,并且进程之间相互独立,互不干扰
。
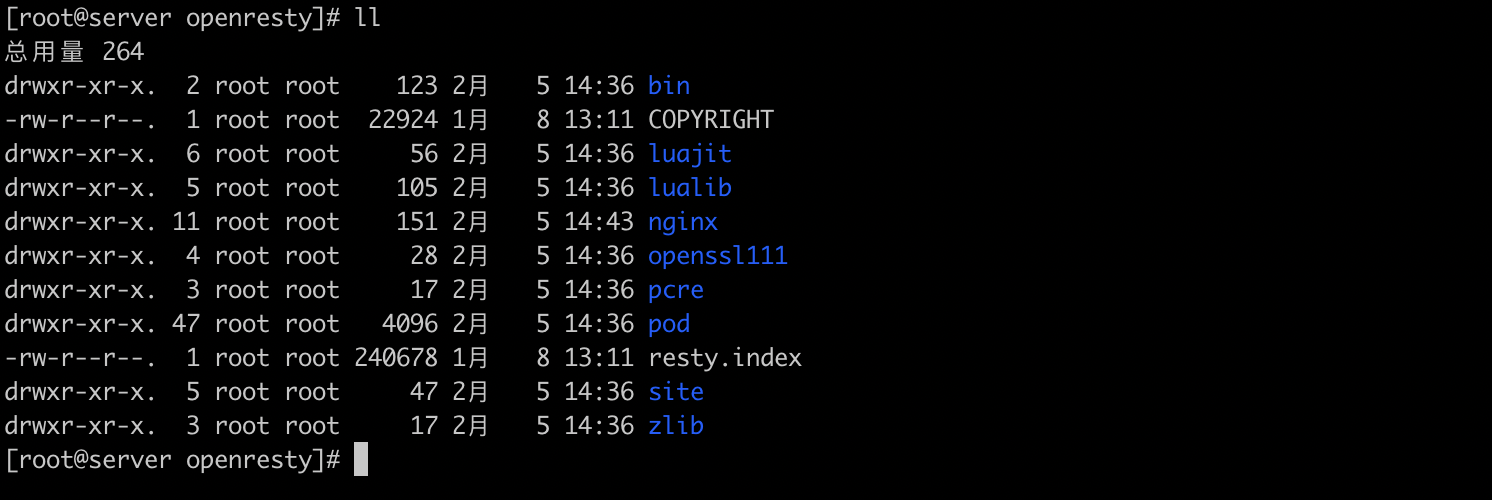
例如,我们
windows
电脑中的 Chrome 浏览器是一个进程、WeChat 也是一个进程,正在操作系统中运行的
.exe
都可以理解为一个进程。
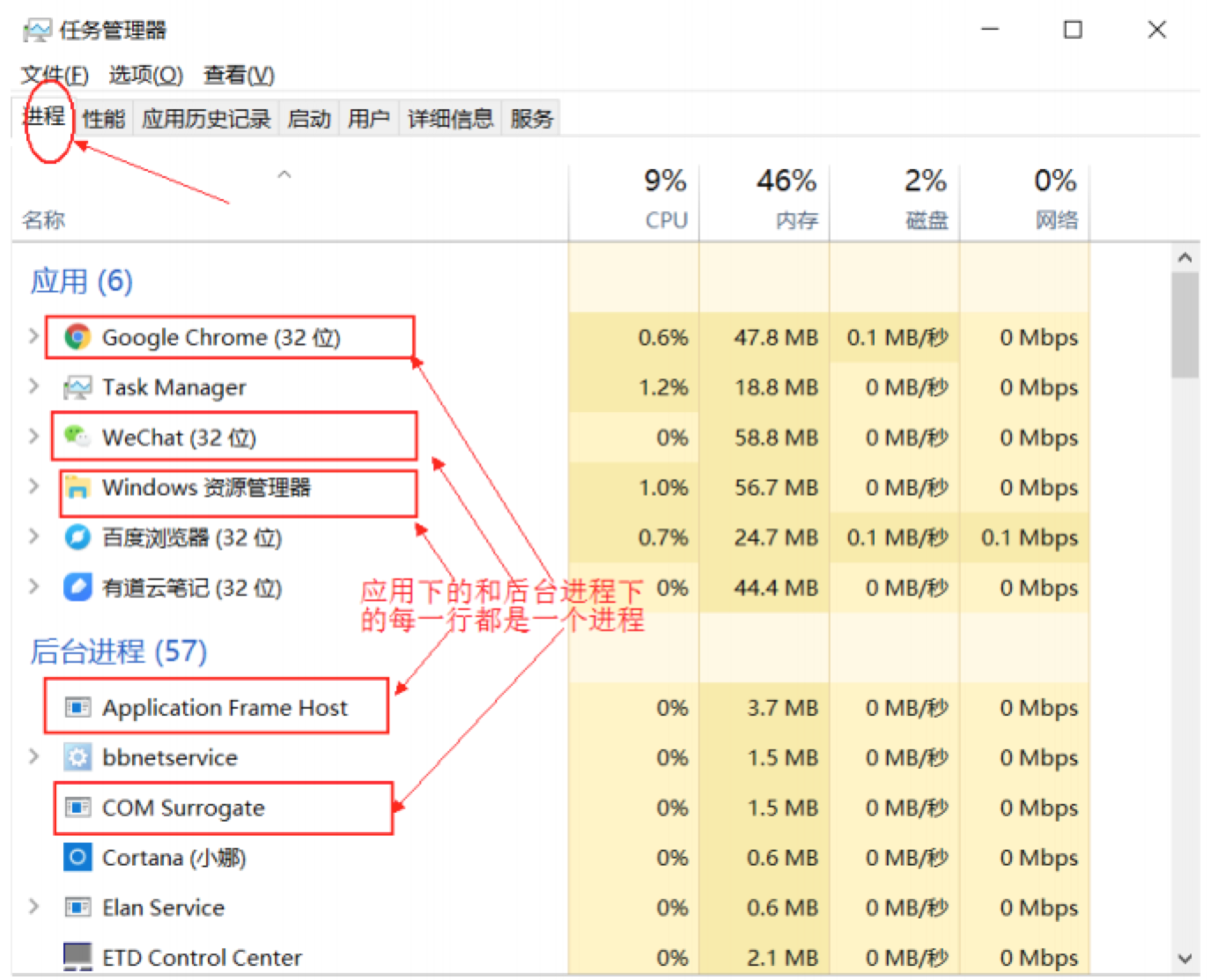
2.2、什么是线程?
关于线程,比较官方的定义是,
线程是进程中的⼀个执⾏单元,也是操作系统能够进行运算调度的最小单位,负责当前进程中程序的执⾏
。同时⼀个进程中⾄少有⼀个线程,⼀个进程中也可以有多个线程,它们共享这个进程的资源,拥有多个线程的程序,我们也称为多线程编程。
举个例子,Chrome 浏览器和 WeChat 是两个进程,Chrome 浏览器进程里面有很多线程,例如 HTTP 请求线程、事件响应线程、渲染线程等等,线程的并发执行使得在浏览器中点击一个新链接从而发起 HTTP 请求时,浏览器还可以响应用户的其它事件。
2.3、进程和线程的关系
关于进程和线程,可能上面的解释过于抽象,还是很难理解,下面是一段出自
阮一峰老师博客文章
的介绍,可能描述不是非常严谨,但是足够形象,有助于我们对它们关系的理解。
- 1.我们都知道,计算机的核心是 CPU,它承担了所有的计算任务。它就像一座工厂,时刻在运行;(
CPU 类似于工厂
)
- 2.假定工厂的电力有限,一次只能供给一个车间使用。也就是说,一个车间开工的时候,其他车间都必须停工。背后的含义就是,单个 CPU 一次只能运行一个任务;
- 3.进程就好比工厂的车间,它代表 CPU 所能处理的单个任务。任一时刻,CPU 总是运行一个进程,其他进程处于非运行状态;(
进程类似于车间
)
- 4.一个车间里,可以有很多工人。他们协同完成一个任务;
- 5.线程就好比车间里的工人。一个进程可以包括多个线程;(
线程类似于工人
)
- 6.车间的空间是工人们共享的,比如许多房间是每个工人都可以进出的。这象征一个进程的内存空间是共享的,每个线程都可以使用这些共享内存;(
每个线程共享进程下的内存资源
)
- 7.一个防止他人进入的简单方法,就是门口加一把锁。先到的人锁上门,后到的人看到上锁,就在门口排队,等锁打开再进去。这就叫"互斥锁"(Mutual exclusion,缩写 Mutex),防止多个线程同时读写某一块内存区域;(
多个线程下可以通过互斥锁,实现资源独占
)
- 8.还有些房间,可以同时容纳 n 个人,比如厨房。也就是说,如果人数大于 n,多出来的人只能在外面等着。这好比某些内存区域,只能供给固定数目的线程使用;
- 9.这时的解决方法,就是在门口挂 n 把钥匙。进去的人就取一把钥匙,出来时再把钥匙挂回原处。后到的人发现钥匙架空了,就知道必须在门口排队等着了。这种做法叫做 "信号量"(Semaphore),用来保证多个线程不会互相冲突。(
多个线程下可以通过信号量,实现互不冲突
)
不难看出,互斥锁 Mutex 是信号量 semaphore 的一种特殊情况(n = 1时)。也就是说,完全可以用后者替代前者。但是,因为 Mutex 较为简单,且效率高,所以在必须保证资源独占的情况下,还是采用这种方式。
2.4、为什么要引入线程?
早期的操作系统都是以进程作为独立运行的基本单位的,直到后期计算机科学家们又提出了更小的能独立运行的基本单位,也就是线程。
那为什么要引入线程呢?我们只需要记住这句话:
线程又称为迷你进程,但是它比进程更容易创建,也更容易撤销
。
引入线程之后,
可以将复杂的操作进一步分解,让程序的执行效率进一步提升
。
举个例子,进程就如同一个随时背着粮草和机枪的士兵,这样肯定会造成士兵的执行战斗的速度。因此,一个简单想法就是:分配两个人来执行,一个士兵负责随时背着粮草,另一个士兵负责抗机枪战斗,这样执行战斗的速度会大幅提升。这些轻装上阵的士兵,可以理解为我们上文提到的线程!
从计算机角度来说,由于创建或撤销进程时,系统都要为之分配或回收资源,如内存空间、I/O 设备等,需要较大的时间和空间开销。
为了减少进程切换的开销,把进程作为资源分配单位和调度单位这两个属性分开处理,即进程还是作为资源分配的基本单位,但是把调度执行与切换的责任交给线程,即线程成为独立调度的基本单位,它比进程更容易(更快)创建,也更容易撤销。
一句话总结就是:引入线程前,进程是资源分配和独立调度的基本单位。引入线程后,进程是资源分配的基本单位,线程是独立调度的基本单位,线程也是进程中的⼀个执⾏单元。
三、创建线程的方式
在 Java 里面,创建线程有以下两种方式:
- 继承
java.lang.Thread
类,重写
run()
方法
- 实现
java.lang.Runnable
接口,然后通过一个
java.lang.Thread
类来启动
不管是哪种方式,所有的线程对象都必须是
Thread
类或其⼦类的实例,每个线程的作⽤是完成⼀定的任务,实际上就是执⾏⼀段程序流,即⼀段顺序执⾏的代码,任务执行完毕之后就结束了。
在 Java 中,通过
Thread
类来创建并启动线程的步骤如下:
- 1.定义
Thread
类的⼦类,并重写该类的
run()
方法
- 2.通过
Thread
子类,初始化线程对象
- 3.通过线程对象,调用
start()
方法启动线程
下面我们具体来看看创建线程的代码实践。
3.1、继承 Thread 类,重写 run 方法介绍
/**
* 创建一个 Thread 子类
*/
public class Thread0 extends Thread {
@Override
public void run() {
for (int i = 0; i < 5; i++) {
String time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS").format(new Date());
System.out.println(time + " 当前线程:" + Thread.currentThread().getName() + ",正在运行");
}
}
}
/**
* 创建一个测试类
*/
public class ThreadTest0 {
public static void main(String[] args) {
// 初始化一个线程对象,然后启动线程
Thread0 thread0 = new Thread0();
thread0.start();
for (int i = 0; i < 5; i++) {
String time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS").format(new Date());
System.out.println(time + " 当前线程:" + Thread.currentThread().getName() + ",正在运行");
}
}
}
输出结果:
2023-08-23 17:58:03:726 当前线程:Thread-0,正在运行
2023-08-23 17:58:03:727 当前线程:Thread-0,正在运行
2023-08-23 17:58:03:726 当前线程:main,正在运行
2023-08-23 17:58:03:727 当前线程:Thread-0,正在运行
2023-08-23 17:58:03:727 当前线程:main,正在运行
2023-08-23 17:58:03:728 当前线程:Thread-0,正在运行
2023-08-23 17:58:03:728 当前线程:main,正在运行
2023-08-23 17:58:03:728 当前线程:Thread-0,正在运行
2023-08-23 17:58:03:728 当前线程:main,正在运行
2023-08-23 17:58:03:728 当前线程:main,正在运行
从执行时间上可以看到,
main
线程和
Thread-0
线程交替运行,效果十分明显!
所谓的多线程,其实就是两个及以上线程的代码可以同时运行,而不必一个线程需要等待另一个线程内的代码执行完才可以运行。
对于单核 CPU 来说,是无法做到真正的多线程的;但是对于多核 CPU 来说,在一段时间内,可以执行多个任务的,由于 CPU 执行代码时间很快,所以两个线程的代码交替执行看起来像是同时执行的一样,具体执行某段代码多少时间,就和分时机制系统有关了。
分时机制系统,简单的说,就是将 CPU 时间划分为多个时间片,操作系统以时间片为单位来执行各个线程的代码,越好的 CPU 分出的时间片越小。
例如某个时段, CPU 将 1 秒划分成 50 个时间片,1 个时间片耗时 20 ms,每个时间片均进行线程切换,也就是说 1 秒可以执行 50 个任务,给人的感觉好像计算机能同时处理多件事情,其实是 CPU 执行任务速度太快给人产生的错觉感。
3.2、实现 Runnable 接口,然后通过 Thread 类来启动介绍
/**
* 实现 Runnable 接口
*/
public class Thread2 implements Runnable{
@Override
public void run() {
for (int i = 0; i < 5; i++) {
String time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS").format(new Date());
System.out.println(time + " 当前线程:" + Thread.currentThread().getName() + ",正在运行");
}
}
}
/**
* 创建一个测试类
*/
public class ThreadTest2 {
public static void main(String[] args) {
// 通过一个Thread来启动线程
Thread thread2 = new Thread(new Thread2());
thread2.start();
for (int i = 0; i < 5; i++) {
String time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS").format(new Date());
System.out.println(time + " 当前线程:" + Thread.currentThread().getName() + ",正在运行");
}
}
}
输出结果:
2023-08-23 18:30:28:664 当前线程:Thread-0,正在运行
2023-08-23 18:30:28:666 当前线程:Thread-0,正在运行
2023-08-23 18:30:28:666 当前线程:Thread-0,正在运行
2023-08-23 18:30:28:664 当前线程:main,正在运行
2023-08-23 18:30:28:666 当前线程:Thread-0,正在运行
2023-08-23 18:30:28:667 当前线程:Thread-0,正在运行
2023-08-23 18:30:28:668 当前线程:main,正在运行
2023-08-23 18:30:28:668 当前线程:main,正在运行
2023-08-23 18:30:28:668 当前线程:main,正在运行
2023-08-23 18:30:28:668 当前线程:main,正在运行
效果跟上面介绍的一样,如果循环的打印次数越多,效果越明显!
四、线程状态
下图是一张从操作系统角度划分的线程模型状态!
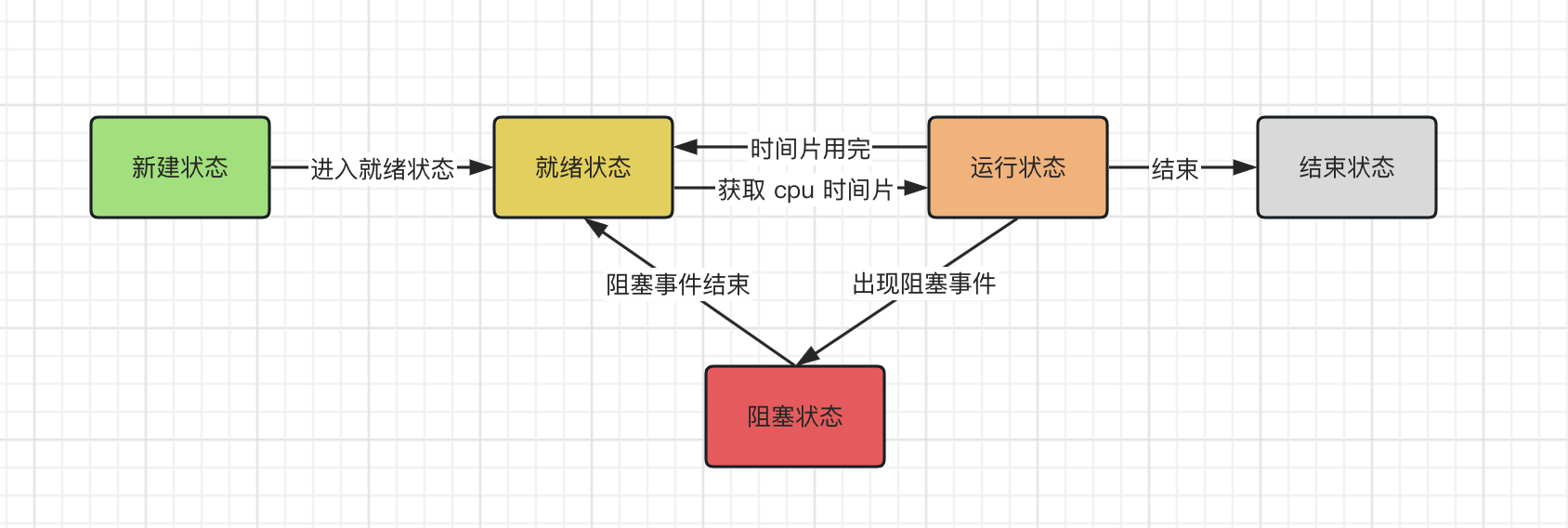
线程被分为五种状态,各个状态说明如下:
- 1.
新建状态
:表示创建了一个新的线程对象,例如
Thread thread = new Thread()
- 2.
就绪状态
:比如调用线程的
start()
方法,就会处于就绪状态,也被称为可执行状态,随时可能被 CPU 调度执行
- 3.
运行状态
:获得了 CPU 时间片,执行程序代码。需要注意的是,
线程只能从就绪状态进入到运行状态
- 4.
阻塞状态
:因为某种原因出现了阻塞,线程放弃对 CPU 的使用权,停止执行,直到阻塞事件结束,重新进入就绪状态才有可能再次被 CPU 调度。
- 5.
结束状态
:线程里面的方法正常执行结束或者因为某种异常退出了,则该线程结束生命周期
针对操作系统的线程模型,Java 进行部分封装和扩充,JVM 中的线程状态总共有六种,它们之间的关系,可以用如下图来表示:
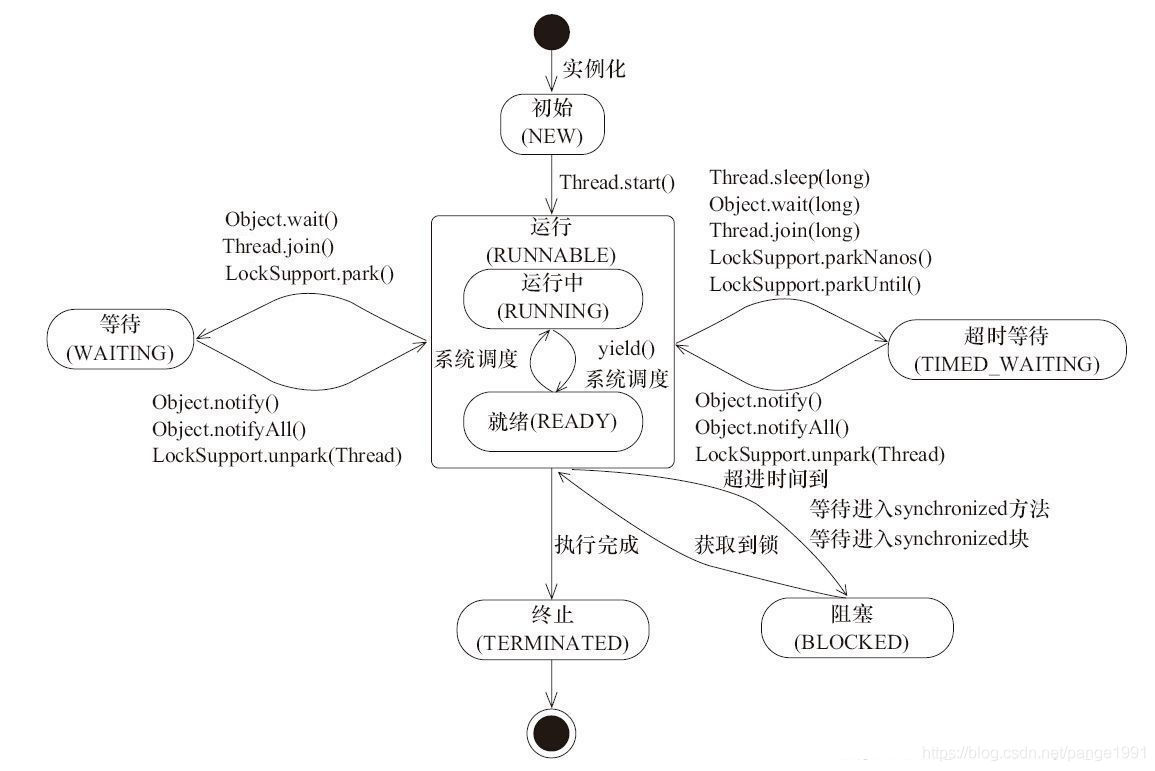
各个状态说明如下:
- 1.
新建状态
(NEW):新创建了一个线程对象
- 2.运行状态(RUNNABLE):Java 线程中将就绪状态和运行中两种状态,笼统的称为“
运行
”。线程对象创建后,调用了该对象的
start()
方法,该线程处于就绪状态,获得 CPU 时间片后变为运行中状态
- 3.
阻塞状态
(BLOCKED):因为某种原因,线程放弃对 CPU 的使用权,停止执行,直到进入就绪状态才有可能再次被 CPU 调度。比如线程在获得
synchronized
同步锁失败后,会把线程放入锁池中,线程进入同步阻塞状态。
- 4.
等待状态
(WAITING):处于这种状态的线程不会被分配 CPU 执行时间,它们要等待被显式地唤醒,否则会处于无限期等待的状态。比如运行状态的线程执行
wait
方法,会把线程放在等待队列中,直到被唤醒或者因异常自动退出
- 5.
超时等待状态
(TIMED_WAITING):处于这种状态的线程不会被分配 CPU 执行时间,不过无须无限期等待被其他线程显式地唤醒,在到达一定时间后它们会自动唤醒。比如运行状态的线程执行
Thread.sleep(1000)
方法,当到达目标时间后,会自动唤醒或者因异常自动退出
- 6.
终止状态
(TERMINATED):表示该线程已经执行完毕,处于终止状态的线程不具备继续运行的能力
五、小结
本文主要围绕进程和线程的一些基础知识,进行简单的入门知识总结。
线程的特征和进程差不多,进程有的它基本都有。
相对于进程而言,线程更加的轻量化,主要承担任务的执行工作,优点如下:
- 一个进程中可以同时拥有多个线程,这些线程共享该进程的资源。我们知道进程间的通信必须请求操作系统服务(因为 CPU 要切换到内核态),开销很大。而同进程下的线程间通信,无需操作系统干预,开销更小
- 线程间可以并发执行任务,线程间的并发比进程的开销更小,系统并发性更好
- 在多 CPU 环境下,各个线程也可以分派到不同的 CPU 上并行执行
- 通过多线程编程,可以显著的提升程序任务的执行效率
不过线程也有缺点:
- 当程序编程不合理,多个线程发生较长时间的等待或资源竞争时,可能会出现死锁
- 等候使用共享资源时可能会造成程序的运行速度变慢。这些共享资源主要是独占性的资源,如打印机、IO 设备等
总的来说,进程和线程各有各优势,站在操作系统的设计角度而言,可以归结为以下几点:
- 采用多进程方式,可以保证多个任务同时运行;
- 采用多线程方式,可以将单个任务分成不同的部分进行执行;
- 提供协调机制,防止进程之间和线程之间产生冲突,同时允许进程之间和线程之间共享资源,以充分的利用系统资源
整篇内容难免有描述不对的地方,欢迎网友留言指出!
六、参考
1、
飞天小牛肉 - 五分钟扫盲:进程与线程基础必知
2、
潘建南 - Java线程的6种状态及切换