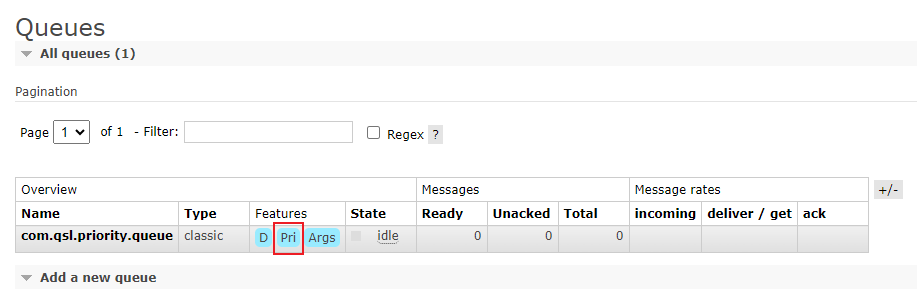
软件架构模式之第五章:事件驱动架构
第五章:事件驱动架构
近年来,事件驱动架构风格显著增长并广泛应用,我们对其理解方式也发生了改变。这种高采用率并不令人意外,因为事件驱动架构能够解决复杂的非确定性工作流和高度反应和响应的系统等难题。此外,新技术、工具、框架和基于云的服务使得事件驱动架构比以往更易访问和可行,并且许多团队正在转向事件驱动架构来解决他们复杂的业务问题。
拓扑结构
事件驱动架构是一种基于异步处理的架构风格,通过高度解耦的事件处理器来触发和响应系统中发生的事件。大多数事件驱动架构由以下组件组成:一个事件处理器、一个主动事件、一个处理事件和一个事件通道。这些组件及其关系如图
5-1
所示。
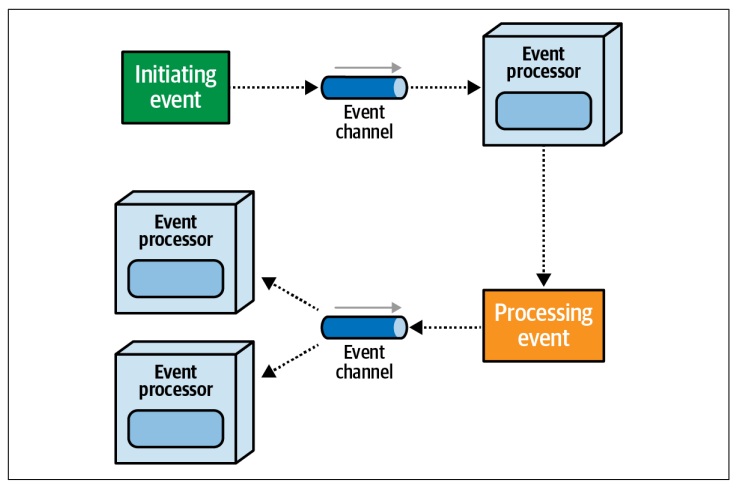
Figure 5-1. The main components of event-driven architecture
事件处理器(通常称为服务)是事件驱动架构中的主要部署单元。它可以以不同的粒度存在,从一个单一目的函数(例如订单验证)到一个庞大而复杂的流程(例如金融交易执行或结算)。事件处理器能够触发异步事件,并对被触发的异步事件作出响应。在大多数情况下,事件处理器同时具备这两个功能。
初始事件通常来自于主系统外部,并启动某种异步工作流程或过程。举例来说,下订单、购买苹果股票、在拍卖中对特定物品进行竞标、提出保险索赔等都属于初始事件。在大多数情况下,只有一个服务接收到初始事件,然后开始一系列处理该初始事件相关联的其他事件链条,但并非必须如此。例如,在在线拍卖中对物品进行竞标(即初始事件),可能会被
Bid Capture
服务和
Bid Tracker
服务同时捕捉到。
当某个服务的状态发生变化并且该服务向系统中其他部分广播了这个状态改变时,就会生成一个处理事件(今天通常称为派生事件)。触发事件和处理事件之间是一对多的关系
-
一个触发事件通常会产生许多不同的内部处理事件。例如,在工作流程中,下订单的触发事件可能会导致订单已下达的处理事件、应用付款的处理事件、库存更新的处理时间等等。请注意,触发事件通常以名词
-
动词格式表示,而处理时间通常以动词
-
名词格式表示。
事件通道是物理消息传递工具(如队列或主题),用于存储触发的事件并将这些触发的时间交付给响应这些时间的服务。在大多数情况下,触发时间使用点对点通道使用队列或消息传递服务,而处理时间则通常使用发布
-
订阅通道使用主题或通知服务。
示例
为了观察所有这些组件如何在一个完整的事件驱动架构中协同工作,考虑一下图
5-2
所示的例子:一个顾客希望订购
Mark Richards
和
Neal Ford
(
O'Reilly
)合著的《软件架构基础》。在这种情况下,触发事件将是
“
下订单
”
。该触发事件被订单放置服务接收,然后该服务为书籍进行订购。订单放置服务通过处理
“
已下订单
”
事件向系统中其他部分广播其所执行的操作。
请注意,在此示例中,当订单放置服务触发
“
已下订单
”
事件时,并不知道哪些其他服务(如果有)会对此事件做出响应。这说明了事件驱动架构具有高度解耦、非确定性的特点。
继续上述例子,请注意图
5-2
中有三个不同的服务对
“
已下订单
”
事件作出响应:支付服务、库存管理服务和通知服务。这些服务执行相应的业务功能,并通过其他处理事件向系统中其他部分广播它们所执行的操作。
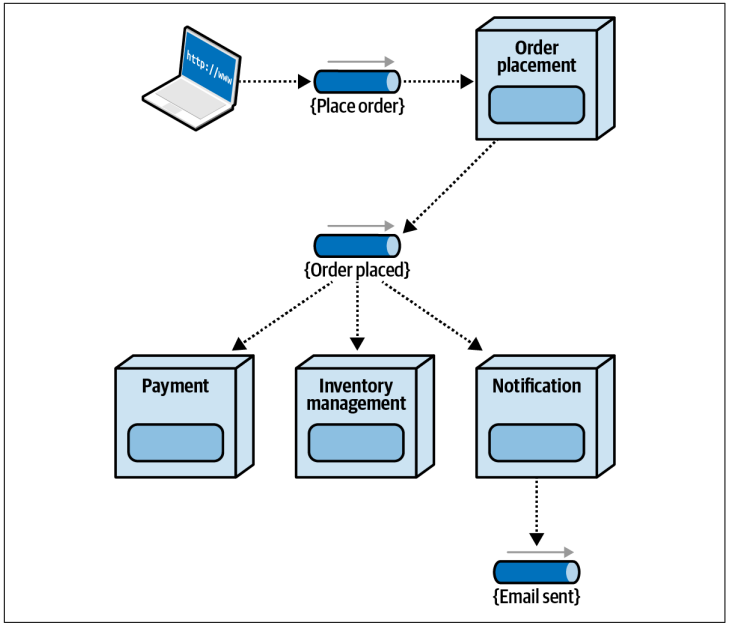
Figure 5-2. Processing a book order using event-driven architecture
在这个例子中,需要特别注意的是,通知服务通过生成一个
NotifiedCustomer
处理事件来宣传自己所做的事情,但其他服务并不关心或响应该事件。那么为什么要触发一个没有人关心的事件呢?答案是出于架构可扩展性考虑。通过触发该事件,通知服务提供了未来可能有其他服务响应的钩子(例如通知跟踪服务),而无需对系统进行任何其他修改。因此,在事件驱动架构中,一个重要原则是始终让服务广告其状态变化(即采取了什么行动),无论其他服务是否对该事件作出响应。如果没有其他服务关心该事件,则该事件将从主题中消失(或根据使用的消息技术保存以供将来处理)。
事件驱动 vs 消息驱动
事件驱动系统和消息驱动系统之间存在差异吗?实际上确实存在微妙但重要的区别,需要进行了解和理解。事件驱动系统处理事件,而消息驱动系统处理消息。
第一个区别与您向整个系统发送的内容上下文有关。事件通知其他人状态变化或您所做的某些事情,例如
“
我刚刚下了订单
”
或
“
我刚刚提交了对某个物品的竞价
”
。另一方面,消息是针对特定服务发出的命令或请求,例如
“
将此付款应用于此订单
”
、
“
将该物品运送到此地址
”
或
“
给我客户的电子邮件地址
”
。请注意这里的区别
-
通过触发事件来响应事件的服务不知道哪些服务(或多少个)会作出响应,而消息通常指向已知单个服务(如支付)。
事件和消息之间另一个区别在于对于事件通道所有权问题。在事件中,发送者拥有该事件通道;而在消息中,则接收者拥有该通道。当考虑到时间或信息合同时,所有权变得更加重要。请考虑图
5-3
中
Order Placement
服务发送
Order Placed event
并由
Payment service
回复
的示例
。在这种情况下
,
发送者
(Order Placement)
拥有
event channel
和
contract.
换句话说
, contract
变更将由
Order Placement
服务启动,并且
Payment
服务以及所有其他响应该
event
的
service
都必须遵守并适应这些变化。
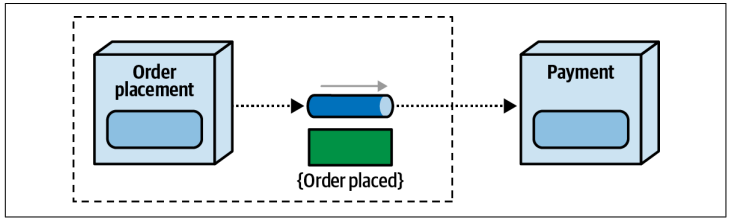
Figure 5-3. With events, the sender owns the event channel and
contract
然而,在消息驱动的系统中,情况正好相反
-
接收者拥有消息通道。如图
5-4
所示,订单放置服务以命令的形式告知支付服务应用付款。在这种情况下,支付服务不仅具备消息通道(队列),还具备消息合同。请注意,在基于消息的处理中,订单放置服务需要遵守由支付服务发起的合同更改。
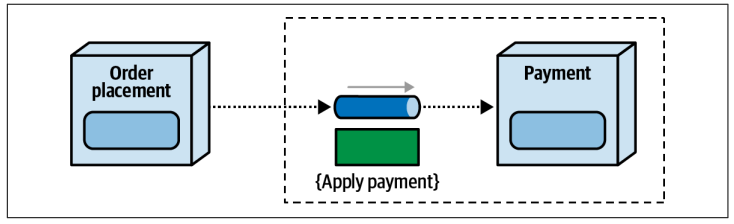
Figure 5-4. With messages, the receiver owns the message channel and
contract
事件通道工件的类型也是区分事件驱动系统和消息驱动系统的一个关键因素。一般情况下,当触发事件时,事件驱动系统采用基于主题或通知服务的发布
-
订阅式消息传递方式,而消息驱动系统则常使用基于队列或消息服务的点对点消息传递方式。然而,并不意味着事件驱动系统不能使用点对点消息传递
——
在某些情况下,为了从另一个服务中检索特定信息或控制系统中事件顺序或时间,可能需要采用点对点消息传递。
斟酌与分析
由于事件驱动架构的异步和解耦特性,它在容错性、可扩展性和高性能方面表现卓越。在添加额外功能时,它还提供了出色的可扩展性。然而,尽管这些特点非常吸引人,尤其是对于当今复杂系统而言,在不采用事件驱动架构时也存在许多理由。以下两个部分概述了考虑使用事件驱动架构的原因,并更重要地指出了何时需要谨慎使用。
什么时候考虑这种风格
简而言之,事件驱动架构是在需要高性能、高可扩展性和高容错性的系统选择中具备重要地位的一种架构。然而,除了这些超级功能外,还有其他原因可以考虑采用这种架构风格。
如果您的业务处理方式是对系统内外发生的事件做出反应(而不仅仅是响应用户请求),那么这就是一个值得考虑的优秀架构风格。请听取您业务利益相关者的意见
-
他们是否使用
“
事件
”
、
“
触发器
”
和
“
对某事做出反应
”
的词汇?如果确实如此,那么很可能您面临的业务问题与该架构风格相匹配。此外,请自问
-
我是在响应用户请求还是对用户所作操作作出反应?这些都是用来确定业务问题是否与该架构风格相匹配的重要问题。
当您面临难以建模复杂、非确定性工作流程时,事件驱动架构也将成为一个不错的选择。几十年来,开发人员一直试图通过建立复杂决策树来概述复杂工作流程中每个可能结果,并屡次失败于此繁琐任务。像这样的系统有时被归类为
CEP
(复杂事件处理),并在事件驱动体系结构中进行本地管理。
什么时候不要考虑这种风格
如果大部分的处理都是基于请求的,那么你不应该考虑这种架构风格。基于请求的处理是指用户从数据库中获取数据(例如客户资料)或对系统中的实体进行基本
CRUD
操作(创建、读取、更新、删除)。此外,如果大部分的处理需要同步执行,即用户必须等待特定请求完成后才能继续,那么事件驱动架构很可能不适合你。
由于事件驱动架构中的所有处理最终都是一致的,因此对于需要高水平数据一致性的业务问题来说,这并非一个理想的架构风格。在事件驱动架构中,几乎没有或者很少保证处理何时发生,因此如果您期望某个特定时间点存在某些数据,请寻找其他能够确保数据一致性的架构风格,例如基于服务的架构。
另一个放弃事件驱动架构并考虑其他架构风格的原因是在需要对事件的工作流程和时间控制时,管理异步事件处理变得非常困难。例如,想象一下协调以下场景的复杂情况:在触发事件
C
之前,必须完成事件
A
和事件
B
的处理,并且在等待
Event C
完成之后,
Event D
和
Event E
必须等待
Event C
开始处理之前启动。要成功应对这种混乱局面最好使用编排式服务导向架构或编排式微服务进行复杂协调。
错误处理也是使团队远离事件驱动架构的复杂性的另一个原因。由于通常没有中央工作流程编排器或控制器,在出现错误时,该服务尝试修复错误。此外,在该事件的工作流程中可能已经发生了其他操作,因为所有操作都是异步进行的。例如,假设订单放置服务为客户订购书籍触发了
OrderPlaced
件
。通知服务、支付服务和库存服务同时响应该
件
。然而,假设通知和支付服务都响应并完成其处理
,但当接收到该
件
时库存服
务抛出错误
,因为没有更多可用
的书籍
。现在如何解决?客户已经被通知并且他们
的信用卡已经被扣款
,但没有更多可供发送给
客户
的书籍了
。是否应撤销付款?是否应向客
户发送另一条通知?还是只需等待有更多库存?
哪个服
务
执行所有这些
错误
处理逻辑呢?
错误处
理确实
是事情
驱动
架
构
中
更
复
杂
的
方
面之一。
架构特征
图
5-5
中的图表综合评估了事件驱动架构在体系结构特征方面的整体能力(架构特性)。星级评定表示一颗星代表该架构特性支持较弱,而五颗星则表示它非常适用于该特定的架构特性。
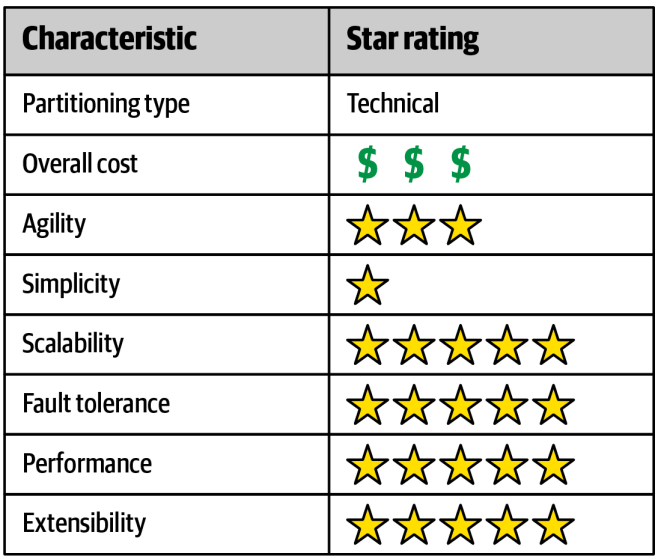
Figure 5-5. Architecture characteristics star ratings for event-driven
architecture