教你用Rust实现Smpp协议
本文分享自华为云社区《
华为云短信服务教你用Rust实现Smpp协议
》,作者: 张俭。
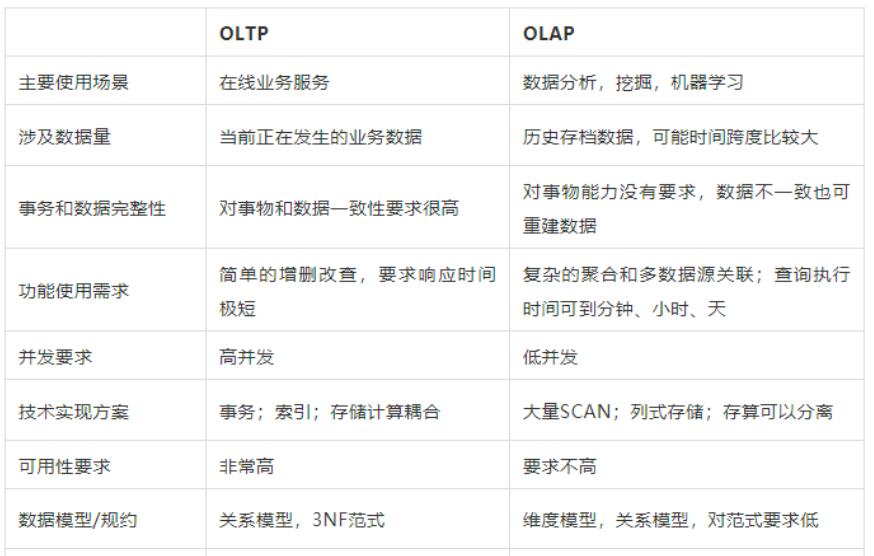
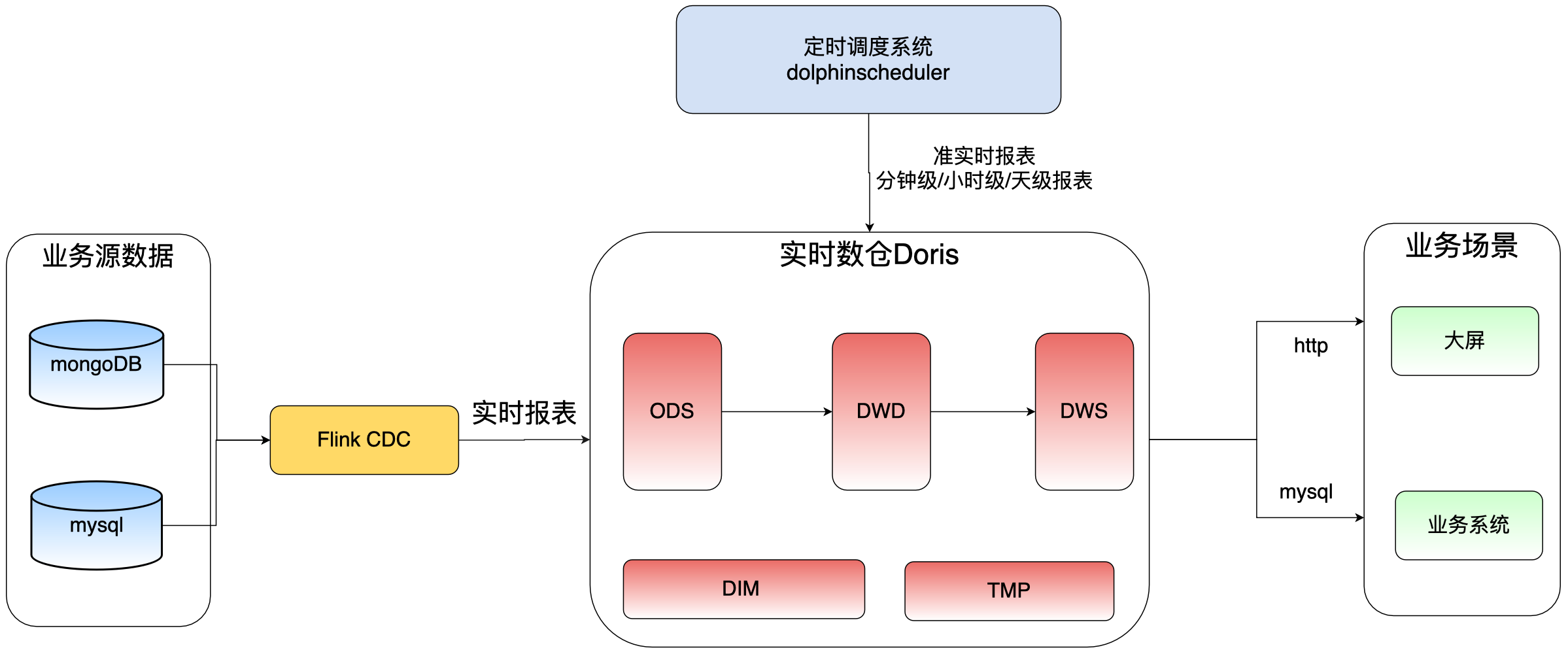
协议概述
SMPP(Short Message Peer-to-Peer)协议起源于90年代,最初由Aldiscon公司开发,后来由SMPP开发者论坛维护和推广。SMPP常用于在SMSC(Short Message Service Center,短信中心)和短信应用之间传输短消息,支持高效的短信息发送、接收和查询功能,是电信运营商和短信服务提供商之间互通短信的主要协议之一。
SMPP协议基于客户端/服务端模型工作。由客户端(短信应用,如手机,应用程序等)先和SMSC建立起TCP长连接,并使用SMPP命令与SMSC进行交互,实现短信的发送和接收。在SMPP协议中,无需同步等待响应就可以发送下一个指令,实现者可以根据自己的需要,实现同步、异步两种消息传输模式,满足不同场景下的性能要求。
时序图
绑定transmitter模式,发送短信并查询短信发送成功

绑定receiver模式,从SMSC接收到短信

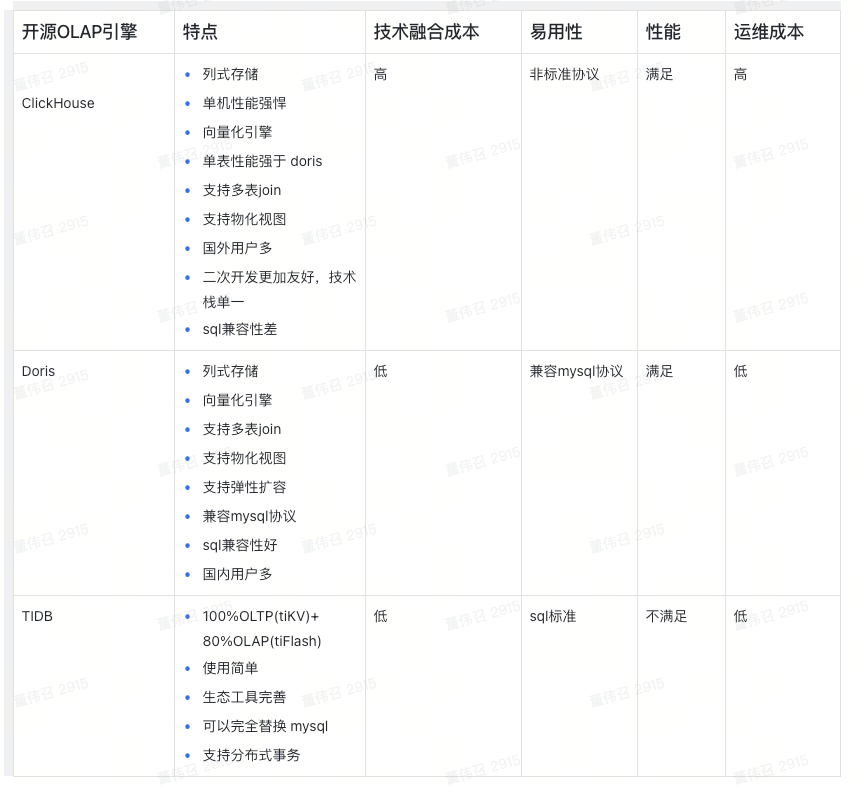
协议帧介绍

在SMPP协议中,每个PDU都包含两个部分:SMPP Header和SMPP Body。
SMPP Header
Header包含以下字段,大小长度都是4字节:
- Command Length:整个PDU的长度,包括Header和Body。
- Command ID:用于标识PDU的类型(例如,BindReceiver、QuerySM等)。
- Command Status:响应状态码,表示处理的结果。
- Sequence Number:序列号,用来匹配请求和响应。
用Rust实现SMPP协议栈里的BindTransmitter
本文的代码均已上传到
smpp-rust
选用Tokio作为基础的异步运行时环境,tokio有非常强大的异步IO支持,也是rust库的事实标准。
代码结构组织如下:
├── lib.rs
├──const.rs
├── protocol.rs
├── smpp_client.rs
└── smpp_server.rs
- lib.rs
Rust项目的入口点 - const.rs
包含常量定义,如commandId、状态码等 - protocol.rs
包含PDU定义,编解码处理等 - smpp_client.rs 实现smpp客户端逻辑
- smpp_server.rs 实现
利用rust原子类实现sequence_number
sequence_number是从1到0x7FFFFFFF的值,利用Rust的AtomicI32来生成这个值。
use std::sync::atomic::{AtomicI32, Ordering};
use std::num::TryFromIntError;structBoundAtomicInt {
min: i32,
max: i32,
integer: AtomicI32,
}
impl BoundAtomicInt {
pub fnnew(min: i32, max: i32) ->Self {
assert!(min <= max, "min must be less than or equal to max");
Self {
min,
max,
integer: AtomicI32::new(min),
}
}
pub fn next_val(&self) -> Result<i32, TryFromIntError>{
let next= self.integer.fetch_update(Ordering::SeqCst, Ordering::SeqCst, |x|{
Some(if x >= self.max { self.min } else { x + 1})
})?;
Ok(next)
}
}
在Rust中定义SMPP PDU
pub structSmppPdu {
pub header: SmppHeader,
pub body: SmppBody,
}
pubstructSmppHeader {
pub command_length: i32,
pub command_id: i32,
pub command_status: i32,
pub sequence_number: i32,
}
pubenumSmppBody {
BindReceiver(BindReceiver),
BindReceiverResp(BindReceiverResp),
BindTransmitter(BindTransmitter),
BindTransmitterResp(BindTransmitterResp),
QuerySm(QuerySm),
QuerySmResp(QuerySmResp),
SubmitSm(SubmitSm),
SubmitSmResp(SubmitSmResp),
DeliverSm(DeliverSm),
DeliverSmResp(DeliverSmResp),
Unbind(Unbind),
UnbindResp(UnbindResp),
ReplaceSm(ReplaceSm),
ReplaceSmResp(ReplaceSmResp),
CancelSm(CancelSm),
CancelSmResp(CancelSmResp),
BindTransceiver(BindTransceiver),
BindTransceiverResp(BindTransceiverResp),
Outbind(Outbind),
EnquireLink(EnquireLink),
EnquireLinkResp(EnquireLinkResp),
SubmitMulti(SubmitMulti),
SubmitMultiResp(SubmitMultiResp),
}
实现编解码方法
impl SmppPdu {
pub fn encode(&self) -> Vec<u8>{
let mut body_buf= match &self.body {
SmppBody::BindTransmitter(bind_transmitter)=>bind_transmitter.encode(),
_=> unimplemented!(),
};
let command_length= (body_buf.len() + 16) asi32;
let header=SmppHeader {
command_length,
command_id: self.header.command_id,
command_status: self.header.command_status,
sequence_number: self.header.sequence_number,
};
let mut buf=header.encode();
buf.append(&mut body_buf);
buf
}
pub fn decode(buf:&[u8]) -> io::Result<Self>{
let header= SmppHeader::decode(&buf[0..16])?;
let body=match header.command_id {
constant::BIND_TRANSMITTER_RESP_ID=> SmppBody::BindTransmitterResp(BindTransmitterResp::decode(&buf[16..])?),
_=> unimplemented!(),
};
Ok(SmppPdu { header, body })
}
}
impl SmppHeader {
pub(crate) fn encode(&self) -> Vec<u8>{
let mut buf= vec![];
buf.extend_from_slice(&self.command_length.to_be_bytes());
buf.extend_from_slice(&self.command_id.to_be_bytes());
buf.extend_from_slice(&self.command_status.to_be_bytes());
buf.extend_from_slice(&self.sequence_number.to_be_bytes());
buf
}
pub(crate) fn decode(buf:&[u8]) -> io::Result<Self>{if buf.len() < 16{return Err(io::Error::new(io::ErrorKind::InvalidData, "Buffer too short for SmppHeader"));
}
let command_id= u32::from_be_bytes(buf[0..4].try_into().unwrap());
let command_status= i32::from_be_bytes(buf[4..8].try_into().unwrap());
let sequence_number= i32::from_be_bytes(buf[8..12].try_into().unwrap());
Ok(SmppHeader {
command_length:0,
command_id,
command_status,
sequence_number,
})
}
}
impl BindTransmitter {
pub(crate) fn encode(&self) -> Vec<u8>{
let mut buf= vec![];
write_cstring(&mut buf, &self.system_id);
write_cstring(&mut buf, &self.password);
write_cstring(&mut buf, &self.system_type);
buf.push(self.interface_version);
buf.push(self.addr_ton);
buf.push(self.addr_npi);
write_cstring(&mut buf, &self.address_range);
buf
}
pub(crate) fn decode(buf:&[u8]) -> io::Result<Self>{
let mut offset= 0;
let system_id= read_cstring(buf, &mut offset)?;
let password= read_cstring(buf, &mut offset)?;
let system_type= read_cstring(buf, &mut offset)?;
let interface_version=buf[offset];
offset+= 1;
let addr_ton=buf[offset];
offset+= 1;
let addr_npi=buf[offset];
offset+= 1;
let address_range= read_cstring(buf, &mut offset)?;
Ok(BindTransmitter {
system_id,
password,
system_type,
interface_version,
addr_ton,
addr_npi,
address_range,
})
}
}
实现同步的bind_transmitter方法
pub asyncfn bind_transmitter(&mut self,
bind_transmitter: BindTransmitter,
)-> io::Result<BindTransmitterResp>{if let Some(stream) = &mut self.stream {
let sequence_number=self.sequence_number.next_val();
let pdu=SmppPdu {
header: SmppHeader {
command_length:0,
command_id: constant::BIND_TRANSMITTER_ID,
command_status:0,
sequence_number,
},
body: SmppBody::BindTransmitter(bind_transmitter),
};
let encoded_request=pdu.encode();
stream.write_all(&encoded_request).await?;
let mut length_buf= [0u8; 4];
stream.read_exact(&mut length_buf).await?;
let msg_length= u32::from_be_bytes(length_buf) as usize - 4;
let mut msg_buf= vec![0u8; msg_length];
stream.read_exact(&mut msg_buf).await?;
let response= SmppPdu::decode(&msg_buf)?;if response.header.command_status != 0{
Err(io::Error::new(
io::ErrorKind::Other,
format!("Error response: {:?}", response.header.command_status),
))
}else{//Assuming response.body is of type BindTransmitterResp match response.body {
SmppBody::BindTransmitterResp(resp)=>Ok(resp),
_=> Err(io::Error::new(io::ErrorKind::InvalidData, "Unexpected response body")),
}
}
}else{
Err(io::Error::new(io::ErrorKind::NotConnected, "Not connected"))
}
}
运行example,验证连接成功
use smpp_rust::protocol::BindTransmitter;
use smpp_rust::smpp_client::SmppClient;
#[tokio::main]async fn main() -> Result<(), Box<dyn std::error::Error>>{
let mut client= SmppClient::new("127.0.0.1", 2775);
client.connect().await?;
let bind_transmitter=BindTransmitter{
system_id:"system_id".to_string(),
password:"password".to_string(),
system_type:"system_type".to_string(),
interface_version:0x34,
addr_ton:0,
addr_npi:0,
address_range:"".to_string(),
};
client.bind_transmitter(bind_transmitter).await?;
client.close().await?;
Ok(())
}

相关开源项目
- netty-codec-sms
存放各种SMS协议(如cmpp、sgip、smpp)的netty编解码器 - sms-client-java
存放各种SMS协议的Java客户端 - sms-server-java
存放各种SMS协议的Java服务端 - smpp-rust
smpp协议的rust实现
总结
本文简单对SMPP协议进行了介绍,并尝试用rust实现协议栈,但实际商用发送短信往往更加复杂,面临诸如流控、运营商对接、传输层安全等问题,可以选择华为云消息&短信(Message & SMS)服务,华为云短信服务是华为云携手全球多家优质运营商和渠道,为企业用户提供的通信服务。企业调用API或使用群发助手,即可使用验证码、通知短信服务。