技术背景
所谓的分子力场,就是用一些计算量较小的函数,来拟合并替代一部分传统第一性原理计算的结果。这个结果,包含了势能和作用力,再用朗之万动力学进行演化,这才使得我们可以在计算机上模拟一个分子动力学的过程。否则在第一性原理计算的框架下,要想获得动力学统计的信息,是非常困难的。
分子力场,常见的有成键相互作用、非成键相互作用以及多体相互作用。本文主要解释一下其中的成键相互作用的Bond Energy和Angle Energy这两项,并给出一些简单的计算演示。
Bond Energy
关于键能的定义,一般采用谐振势的形式,这里用
\(\textbf{r}_B\)
和
\(\textbf{r}_A\)
来分别表示原子
\(B\)
和
\(A\)
的空间坐标:
\[E_{bond_{AB}}=\frac{1}{2}k_b(|\textbf{r}_B-\textbf{r}_A|-b)^2
\]
这里有个细节是,在很多非成键相互作用中,会采用无穷远处的势能为0。而成键相互作用,例如这里的键能,则是采用了平衡位置
\(|\textbf{r}_B-\textbf{r}_A|=b\)
处的势能为0。因为自然作用力下,物体会从高势能位置向低势能位置运动,因此这里
\(E_{bond}\)
采取的是正号。而计算作用力
\(\textbf{F}_{bond}=-\frac{d E_{bond}}{d l}\)
时,前面会带有一个负号。其表示的意义是:当键长大于平衡键长时,通过成键相互作用力把键长拉短。而势能表达式前的系数
\(\frac{1}{2}\)
主要是为了使得力的形式符合胡克定律,更方便理解,但实际上很多力场中把这个系数融入到了参数
\(k_b\)
中,且
\(k_b>0\)
。
由于我们在动力学模拟的过程中,保存的轨迹信息只有分子的空间坐标和速度的信息,因此我们可以把
\(\textbf{F}_{bond_i}\)
写成
\(\textbf{F}_{bond_i}(\textbf{r}_A)\)
和
\(\textbf{F}_{bond_i}(\textbf{r}_B)\)
的函数形式,其中
\(i\)
表示的是第
\(i\)
根键带来的作用力,而一个原子可能同时有多根键连接,因此每一个原子上的作用力最后需要把所有相关的键都加和起来:
\[\textbf{F}_b=\sum_j\textbf{F}_{bond_j}(\textbf{r}_b)
\]
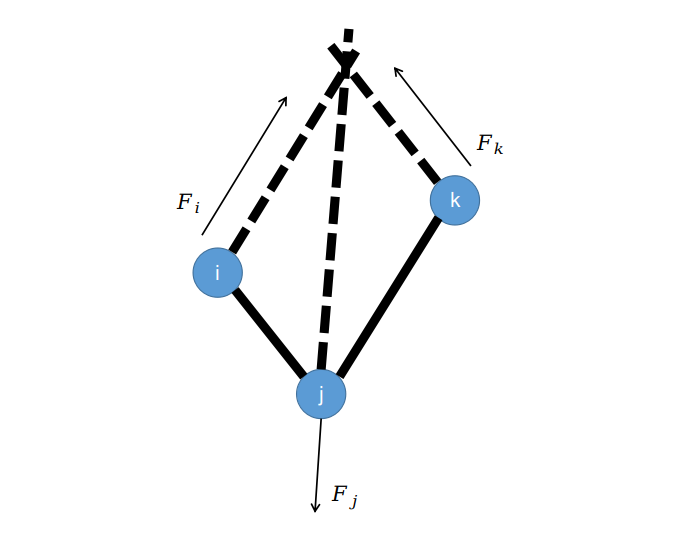
因此,要求解力,首先要求解每一根键上的作用力。由于是同一根键相连的两个原子,所以对应的力应该是大小相等、方向相反:
\(F_{bond_i}(\textbf{r}_A)=-F_{bond_i}(\textbf{r}_B)\)
。那么理论上说,我们只要保存其中的一个力向量
\(F_{bond_i}\)
就够了。那么令
\(l=|\textbf{r}_B-\textbf{r}_A|\)
,有第
\(i\)
根键上的作用力:
\[\textbf{F}_{bond_i}=-\frac{d E_{bond_i}}{d l}=-k_b(l-b)=-k_b(|\textbf{r}_B-\textbf{r}_A|-b)
\]
这里有个问题是,上述公式计算出来的作用力的符号只表示用于拉伸键的方向,并不表示实际空间中对应单个原子的受力方向。但我们要计算
\(\textbf{F}_{bond_i}(\textbf{r}_A)\)
怎么办呢?其实拉伸的方向就是每一个原子相对于键的中点
\(\frac{\textbf{r}_B+\textbf{r}_A}{2}\)
的向量。以原子
\(A,B\)
和第
\(i\)
根键为例,原子
\(A\)
相对于
\(A\)
和
\(B\)
的中点
\(C\)
的向量为:
\(\textbf{r}_{AC}=\frac{\textbf{r}_B+\textbf{r}_A}{2}-\textbf{r}_A=\frac{\textbf{r}_B-\textbf{r}_A}{2}\)
,单位化之后就是
\(\textbf{e}_{AC}=\frac{\textbf{r}_B-\textbf{r}_A}{|\textbf{r}_B-\textbf{r}_A|}\)
。类似的,
\(\textbf{e}_{BC}=\frac{\textbf{r}_A-\textbf{r}_B}{|\textbf{r}_B-\textbf{r}_A|}=-\textbf{e}_{AC}\)
。
结合上述分析的关于作用力的符号的物理意义,当力为负数时,表示跟
\(\textbf{r}_{AC}\)
和
\(\textbf{r}_{BC}\)
同向,当力为正数时,表示跟
\(\textbf{r}_{AC}\)
和
\(\textbf{r}_{BC}\)
反向:
\[\textbf{F}_{bond_i}(\textbf{r}_A)=
k_b(|\textbf{r}_B-\textbf{r}_A|-b)\textbf{e}_{AC}=k_b(\textbf{r}_B-\textbf{r}_A)-k_bb\frac{\textbf{r}_B-\textbf{r}_A}{|\textbf{r}_B-\textbf{r}_A|}
\]
同理可以得到:
\[\textbf{F}_{bond_i}(\textbf{r}_B)=
k_b(|\textbf{r}_B-\textbf{r}_A|-b)\textbf{e}_{BC}=k_b(\textbf{r}_A-\textbf{r}_B)-k_bb\frac{\textbf{r}_A-\textbf{r}_B}{|\textbf{r}_B-\textbf{r}_A|}=-\textbf{F}_{bond_i}(\textbf{r}_A)
\]
有了力的表达式之后,可以探讨一下计算Bond Force在CPU上的时间复杂度。假设有
\(N\)
个原子和
\(P\)
对键连原子,在一个3维空间下,首先要计算一个矢量
\(\textbf{r}=\textbf{r}_A-\textbf{r}_B\)
,这需要
\(3P\)
的加法计算量。然后是计算这些向量的模
\(|\textbf{r}|\)
,需要做
\(3P\)
次乘法运算和
\(2P\)
次加法运算以及
\(P\)
次指数运算,一共是
\(6P\)
次运算。再计算
\(k_b(\textbf{r}_B-\textbf{r}_A)\)
再计算
\(k_bb(\textbf{r}_B-\textbf{r}_A)\)
,一共是
\(6P\)
次乘法运算。最后要把得到的
Pair-Wise-Force
加和到
Atom-Wise-Force
上,需要做
\(6P\)
次加法运算。最后,我们统计出来计算Bond Force的复杂度为
\(\Omega(21P)\)
。
接下来要说的是一个关于代码实现上的问题。如果我们选择用CPU上(如果选择用GPU计算,那么评估标准会有所不同)的Python来计算一个bond force的话,那么就可能有这么几种思路:
- 用现有的自动微分框架,只需要实现一个
bond_energy
的计算函数,就可以自动求得每个原子上的力;
- 用for循环来实现一个
bond_force
函数,使得计算满足最低的复杂度要求;
- 用Python的向量化运算来实现一个
vector_bond_force
函数,可以直接调用比较成熟的、经过多种优化的向量化运算函数。
自动微分实现
这里我们使用MindSpore框架的函数式编程来实现bond energy的自动微分:
import numpy as np
np.random.seed(1)
import mindspore as ms
from mindspore import context, Tensor, grad
from mindspore import numpy as msnp
# 动态图模式,在CPU上运行
context.set_context(mode=context.PYNATIVE_MODE, device_target="CPU")
# 键能函数,这里简化k为1,b为0
def bond_energy(crd, bonds, k=1., b=0.):
bond_vector = crd[bonds]
energy = 0.5 * k * (msnp.norm(bond_vector[:, 1] - bond_vector[:, 0], axis=-1) - b) ** 2
return energy.sum()
# 初始化10个原子的坐标信息
N = 10
crd = Tensor(np.random.random((N, 3)), ms.float32)
bonds_np = np.random.randint(0, N, (N*2, 2))
bonds = Tensor(bonds_np, ms.int32)
bond_force = grad(bond_energy)
adf_force = -bond_force(crd, bonds)
print (adf_force)
运行输出结果如下所示:
[[-0.6740933 -0.59173465 0.8205794 ]
[ 0.31077877 0.7709253 0.77850956]
[ 1.2435249 0.717391 -0.49775103]
[-1.4042054 -0.39493966 -0.07195999]
[ 0.84755206 -1.7858155 2.0126157 ]
[-0.9960958 0.24160932 -0.28924745]
[ 2.0020847 1.6122136 -1.6734666666 ]
[-3.06986 -0.14928058 0.0689815 ]
[-2.0460608 -2.140861 1.438695 ]
[ 3.7863746 1.7204924 -2.5869672 ]]
最后我们得到的是每一个原子的受力总和,用自动微分框架实现的最大好处就是:方便、简单。我们甚至都不需要去手动推导bond force的解析形式和各种正负符号,只需要把bond energy函数写对就可以了,这也是对科研人员的一大福音。而这其中的计算的效率,那就只能依赖于AI框架本身的实现和优化。
For循环实现
在前面的推导中我们已经得到了成键相互作用力的计算公式,那么我们只需要先计算出每一个键上的受力,然后用一个for循环加到对应的原子位置上即可:
import numpy as np
np.random.seed(1)
# for循环实现的力函数
def bond_force(crd, bonds):
bond_crd = crd[bonds]
bond_vector = bond_crd[:, 1] - bond_crd[:, 0]
force = np.zeros_like(crd)
for i, bond in enumerate(bonds):
force[bond[0]] += bond_vector[i]
force[bond[1]] -= bond_vector[i]
return force
# 初始化10个原子的坐标
N = 10
crd = np.random.random((N, 3)).astype(np.float32)
bonds_np = np.random.randint(0, N, (N*2, 2))
loop_force = bond_force(crd, bonds_np)
print (loop_force)
得到的结果如下:
[[-0.6740933 -0.59173465 0.8205794 ]
[ 0.31077877 0.7709253 0.77850956]
[ 1.2435249 0.717391 -0.49775103]
[-1.4042056 -0.39493972 -0.07195997]
[ 0.84755206 -1.7858155 2.0126157 ]
[-0.9960958 0.2416093 -0.28924745]
[ 2.002085 1.6122137 -1.6734666666 ]
[-3.06986 -0.14928058 0.0689815 ]
[-2.046061 -2.140861 1.4386952 ]
[ 3.786375 1.7204924 -2.5869677 ]]
我们可以看到,得到的结果是跟自动微分框架计算出来的保持一致的。
向量化运算
在这几个方案中,向量化运算在计算复杂度上是不占优势的,这是因为成键相互作用力的向量化运算要求
双向索引
和
静态Shape
。在这个问题中,比较难的一点是,每一个原子的键连数量都是不一样的,所以要做一个向量化的实现很有可能是吃力不讨好的,这里仅提供一个可以参考的实现方案:
import numpy as np
np.random.seed(1)
# for循环实现的力函数
def vector_bond_force(crd, bonds, atom_bond, atom_bond_mask, atom_bond_zeros_mask):
bond_crd = crd[bonds]
bond_vector = bond_crd[:, 1] - bond_crd[:, 0]
force = (bond_vector[atom_bond] * atom_bond_zeros_mask[..., None] * atom_bond_mask[..., None]).sum(axis=-2)
return force
# 初始化10个原子的坐标
N = 10
crd = np.random.random((N, 3)).astype(np.float32)
bonds_np = np.random.randint(0, N, (N*2, 2))
# 计算单原子最大成键数量
max_bonded_atom = np.bincount(bonds_np.reshape(-1)).max()
print ('The maximum bonds per atom is: {}'.format(max_bonded_atom))
# 初始化一个反向索引矩阵
atom_bond = -1 * np.ones((N, max_bonded_atom)).astype(np.int32)
# 初始化一个反向标记矩阵,用于区分力的方向
atom_bond_mask = np.zeros((N, max_bonded_atom))
for i, bond in enumerate(bonds_np):
# 在每一轮的迭代中,要roll一个位置,把上一步更新的元素轮转到第一位,这样就可以一直轮转更新
atom_bond[bond[0]] = np.roll(atom_bond[bond[0]], 1)
atom_bond_mask[bond[0]] = np.roll(atom_bond_mask[bond[0]], 1)
atom_bond[bond[0]][-1] = i
# 正方向标记为正1
atom_bond_mask[bond[0]][-1] = 1.
atom_bond[bond[1]] = np.roll(atom_bond[bond[1]], 1)
atom_bond_mask[bond[1]] = np.roll(atom_bond_mask[bond[1]], 1)
atom_bond[bond[1]][-1] = i
# 逆方向标记为负1
atom_bond_mask[bond[1]][-1] = -1.
# 初始化一个冗余标记矩阵,用于标记反向索引矩阵中的冗余位置
atom_bond_zeros_mask = np.where(atom_bond >= 0, 1, 0)
vector_force = vector_bond_force(crd, bonds_np, atom_bond, atom_bond_mask, atom_bond_zeros_mask)
print (vector_force)
在这个向量化运算的代码实现中,有个比较显著的缺点是,我们需要给力的计算函数传入三个额外的参量:
反向索引矩阵、方向标记矩阵和冗余标记矩阵
。从形式上来说,不仅仅是算法变得更加复杂了,而且可读性也并不是很好,但是这里面包含了几个值得思考的点:
- 对于分子动力学模拟中可能出现的大部分体系而言,成键关系总是稀疏的;
- 额外的三个初始化操作是在力的计算函数外部完成的,并不参与力的迭代过程;
- 向量化的运算,并且排去除了自动微分可能带来的一些性能上的损失,在个别大规模体系下,预期能够展现较好的性能增益效果。
上述代码的运行结果如下图所示:
The maximum bonds per atom is: 8
[[-0.67409331 -0.59173465 0.82057939]
[ 0.31077877 0.77092531 0.77850953]
[ 1.24352494 0.71739101 -0.49775103]
[-1.40420556 -0.39493971 -0.07195997]
[ 0.84755203 -1.78581548 2.01261576]
[-0.99609581 0.24160931 -0.28924745]
[ 2.00208497 1.6122137 -1.67346666664]
[-3.0698598 -0.14928058 0.0689815 ]
[-2.04606098 -2.14086115 1.43869516]
[ 3.78637475 1.72049223 -2.58696735]]
在这个案例中,由于成键关系只是随机生成的,所以出现了一个非常尴尬的最大键连数量,这种键连数量在正常的分子动力学模拟中也是不太可能出现的。也正是因为各种模拟体系的特殊性,所以这里暂不对以上的几个算法进行进一步的性能测试,我们只是介绍一下这些计算方案的可行性,同时对于分子之间键连关系的计算进行一定的思考。
Angle Force
要计算键角相互作用力,我们首先回顾一下两个向量之间夹角的计算方法:
\[\theta_{ijk}=Arccos\left(\textbf{e}_{ji}\cdot\textbf{e}_{jk}\right), (i,j)\in \{Bonds\},(j,k)\in \{Bonds\},\theta_{ijk}\in[0,\pi]
\]
其中
\(\textbf{e}_{ji}=\frac{\textbf{v}_{ji}}{|\textbf{v}_{ji}|},\textbf{v}_{ji}=\textbf{r}_i-\textbf{r}_j\)
。那么,如果把
\(\theta_{ijk}\)
类比于前面介绍的键连关系中的
\(bond_{AB}\)
,我们也可以使用一个谐振势的力场形式来计算键角势能:
\[E(\theta_{ijk})=\frac{1}{2}k_a(\theta_{ijk}-\theta_{a})^2
\]
类似于前面键作用力的推导,这里我们可以得到角作用力的形式:
\[\textbf{F}(\theta_{ijk})=-\frac{d E(\theta_{ijk})}{d \theta_{ijk}}=-k_a(\theta_{ijk}-\theta_{a})
\]
对于一个键相互作用力而言,我们比较容易可以理解,力的符号用于表示将键拉伸或者缩短。而这里键角作用力也是如此,如果计算出来的力为负数,就是往键角变小的方向演化,如果力为正数,则表示把键角拉大。而如果力为0,按照谐振势的定义,也就是处于平衡位置的时候,此时键角势能
\(E(\theta_{ijk})\)
的值也是0。接下来我们关注一个力的方向问题,对于Bond Force我们很容易可以理解,力的方向自然是沿着键的方向,那么
键角作用力是沿着什么方向
的呢?按照经验来说,只有三种可能性,一种是沿着
\(e_{ik}\)
的方向,一种是分别垂直于
\(e_{ji}\)
和
\(e_{jk}\)
的方向,还有一种是沿着对向成键的方向。接下来要通过计算来确认一下单个原子的受力方向,我们先计算一下作用在原子
\(i\)
上的作用力:
\[\left.\textbf{F}_{\theta_{ijk}}\right|_i=\frac{d E(\theta_{ijk})}{d \textbf{r}_i}=\frac{d E(\theta_{ijk})}{d \theta_{ijk}}\frac{d \theta_{ijk}}{d \textbf{e}_{ji}}\frac{d \textbf{e}_{ji}}{d \textbf{r}_i}=k_a(\theta_{ijk}-\theta_{a})\frac{\textbf{e}_{jk}}{\sqrt{1-\left(\textbf{e}_{ji}\cdot\textbf{e}_{jk}\right)^2}}
=\frac{k_a(\theta_{ijk}-\theta_{a})}{1-\textbf{e}_{ji}\cdot\textbf{e}_{jk}}\textbf{e}_{jk}
\]
这里面还涉及到一个向量点乘的求导,例如
\(f=\textbf{v}_i\cdot\textbf{v}_j=x_ix_j+y_iy_j+z_iz_j\)
,那么对于其中一个向量的求导形式为:
\[\frac{d f}{d \textbf{v}_i}=\left(\frac{d f}{d x_i}, \frac{d f}{d y_i}, \frac{d f}{d z_i}\right)=\left(x_j, y_j, z_j\right)=\textbf{v}_j
\]
所以向量求导也是符合我们日常所用到的求导法则的。另外还涉及到一个归一化的求导函数:
\[\textbf{e}_{i}=\frac{\textbf{v}_{i}}{|\textbf{v}_{i}|}=\left(\frac{x_i}{\sqrt{x_i^2+y_i^2+z_i^2}}, \frac{y_i}{\sqrt{x_i^2+y_i^2+z_i^2}}, \frac{z_i}{\sqrt{x_i^2+y_i^2+z_i^2}}\right)
\]
由于
\(\textbf{e}_i\)
的长度始终是保持不变的,按照导数的定义有
\[\frac{d \textbf{e}_{i}}{d \textbf{v}_{i}}=\left.\lim_{\Delta \textbf{v}\to 0}\frac{\Delta \textbf{e}}{\Delta \textbf{v}}\right|_{\textbf{v}_i}=\lim_{\Delta \textbf{v}\to 0}\frac{\frac{\textbf{v}_i+\Delta \textbf{v}}{|\textbf{v}_i+\Delta \textbf{v}|}-\frac{\textbf{v}_i}{|\textbf{v}_i|}}{\Delta \textbf{v}}=\lim_{\Delta \textbf{v}\to 0}\frac{\frac{\textbf{v}_i+\Delta \textbf{v}}{|\textbf{v}_i|}-\frac{\textbf{v}_i}{|\textbf{v}_i|}}{\Delta \textbf{v}}=\frac{1}{|\textbf{v}_i|}
\]
另外,由于键矢量的定义
\(\textbf{v}_{ji}=\textbf{r}_i-\textbf{r}_j\)
,因此可以得到关系:
\[\frac{d \textbf{v}_{ji}}{d \textbf{r}_{i}}=1, \frac{d \textbf{v}_{ji}}{d \textbf{r}_{j}}=-1\Rightarrow \frac{d \textbf{e}_{ji}}{d \textbf{r}_i}=\frac{d \textbf{e}_{ji}}{d \textbf{v}_{ji}}\frac{d \textbf{v}_{ji}}{d \textbf{r}_{i}}=\frac{1}{|\textbf{v}_{ji}|},
\frac{d \textbf{e}_{ji}}{d \textbf{r}_{j}}=-\frac{1}{|\textbf{v}_{ji}|}
\]
那么,通过观察
\(i\)
原子的键角作用力,我们可以发现,
\(\left.\textbf{F}_{\theta_{ijk}}\right|_i\)
的方向仅仅与
\(\textbf{v}_{jk}\)
有关,也就是说,第
\(i\)
个原子受到的键角作用力是沿着
\(e_{jk}\)
方向的。类似的我们可以推导出来第
\(k\)
个原子的键角作用力:
\[\left.\textbf{F}_{\theta_{ijk}}\right|_k=\frac{k_a(\theta_{ijk}-\theta_{a})}{1-\textbf{e}_{ji}\cdot\textbf{e}_{jk}}\textbf{e}_{ji}
\]
可以看出,第
\(k\)
个原子受到的键角作用力是沿着
\(e_{ji}\)
方向的。而第
\(j\)
个原子的受力如何呢?已知
\(j\)
原子的受力跟
\(\textbf{v}_{ji}\)
和
\(\textbf{v}_{jk}\)
都相关,则有:
\[\left.\textbf{F}_{\theta_{ijk}}\right|_j=\frac{d E(\theta_{ijk})}{d \theta_{ijk}}\frac{d \theta_{ijk}}{d \textbf{e}_{ji}}\frac{d \textbf{e}_{ji}}{d \textbf{r}_j}+\frac{d E(\theta_{ijk})}{d \theta_{ijk}}\frac{d \theta_{ijk}}{d \textbf{e}_{jk}}\frac{d \textbf{e}_{jk}}{d \textbf{r}_j}=-\left.\textbf{F}_{\theta_{ijk}}\right|_i-\left.\textbf{F}_{\theta_{ijk}}\right|_k
\]
可见,每一个键角所对应的键角作用力都是保守的,并且
\(i,k\)
原子的受力方向沿着对向成键的方向,
\(j\)
原子的受力则是沿着平行四边形的对角线方向。得到了每一个键角所产生的作用力之后,因为一个原子可能同时对应多个键角,因此,我们计算单个原子在所有键角作用力下的作用时,需要对所有相关的键角进行加和:
\[\textbf{F}_a=\sum_{a\in\{i,j,k\}}\textbf{F}_{\theta_{ijk}}|_a
\]
类似的,我们也可以统计一下键角这部分的计算复杂度。假设有
\(S\)
组键角,每组键角由3个原子组成。需要注意的是,这里所有构成键角的键矢量和单位键矢量,都已经在计算Bond Energy的时候算过了,理论上说是可以不用再进行重复计算的。那么就可以直接计算单位键矢量的两两点乘,这里面使用到了
\(3S\)
次计算,然后计算
\(S\)
次反余弦函数,就可以得到
\(S\)
个键角的值。有了键角值,代入力场参数,计算
\(2S\)
次就可以得到每个键角上的作用力大小,再计算
\(S\)
次可以得到
\(1-\textbf{e}_{ji}\cdot\textbf{e}_{jk}\)
的值,再经过
\(S\)
次计算可以得到
\(\textbf{F}_{\theta_{ijk}}|_i\)
和
\(\textbf{F}_{\theta_{ijk}}|_k\)
的前置系数。将这些系数跟每一个键矢量做点乘得到
\(\textbf{F}_{\theta_{ijk}}|_i\)
和
\(\textbf{F}_{\theta_{ijk}}|_k\)
,需要做
\(6S\)
次运算,
\(\textbf{F}_{\theta_{ijk}}|_j\)
是两者加和的相反数,需要
\(3S\)
次运算。最后要把这些键角对应的三个原子的力矢量加回到每个原子的受力上,最少需要做
\(9S\)
次运算。整体统计下来,键角作用力的计算复杂度为
\(\Omega(26S)\)
。那么,对于键长和键角这两项力场作用项而言,不可减免的计算复杂度就有
\(\Omega(21P+26S)\)
。对应到具体实现中,根据不同的实现方案,计算量只会大于这个数量级。而且需要注意的是,这里只统计了计算复杂度,实际的分子动力学模拟过程中,还会涉及到大量的索引和通信复杂度,这里不做赘述。关于Angle Force部分的代码实现先暂时忽略,因为本质上跟计算Bond Force的原理是一样的,既可以选择简单方便的自动微分,也可以自定义一些反向索引和Mask用矢量化计算的形式来实现。
总结概要
本文介绍了在分子力场中经常有可能被使用到的键长和键角项的谐振势模型,并且分别从自动微分的Python代码实现以及解析形式的矢量化编程形式给出了初步的实现方案。虽然力场形式较为简单,但是在实际的计算中,我们统计出来,至少需要21P+26S的计算量,其中P指键的数量,S指键角的数量。这里提到的矢量化计算的实现方案,虽然从计算的角度来说有大量的冗余,但由于一般情况下,一个分子系统单个原子的成键数量都在4以内(比如C原子的sp3杂化),因此矢量化计算的实现方案也不失为一个很好的参考。
版权声明
本文首发链接为:
https://www.cnblogs.com/dechinphy/p/bond-angle.html
作者ID:DechinPhy
更多原著文章:
https://www.cnblogs.com/dechinphy/
请博主喝咖啡:
https://www.cnblogs.com/dechinphy/gallery/image/379634.html