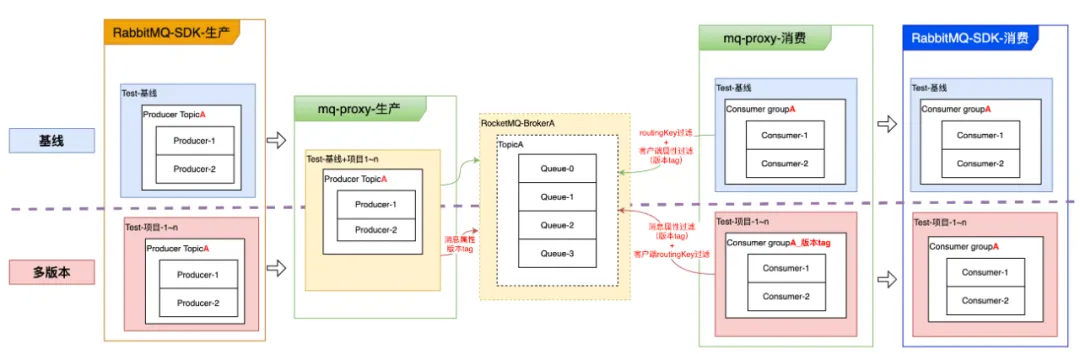
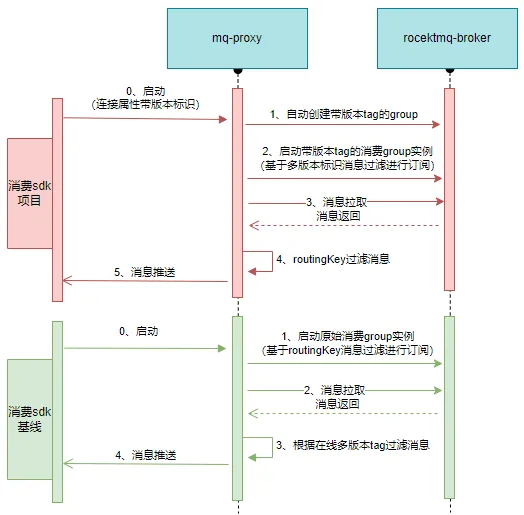
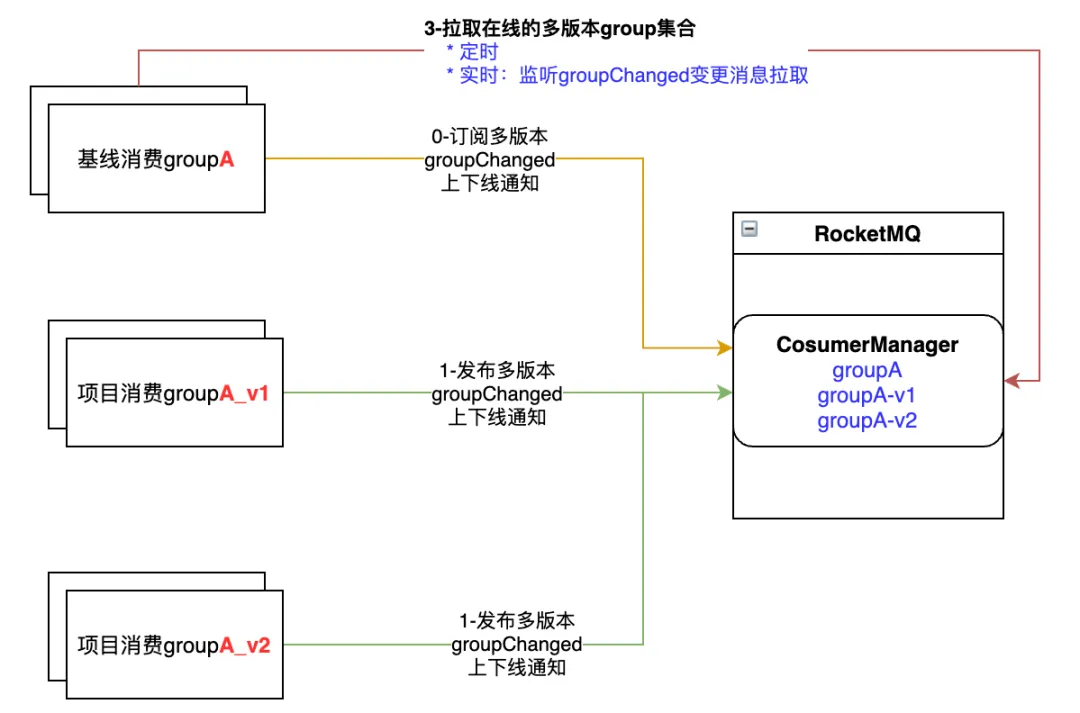
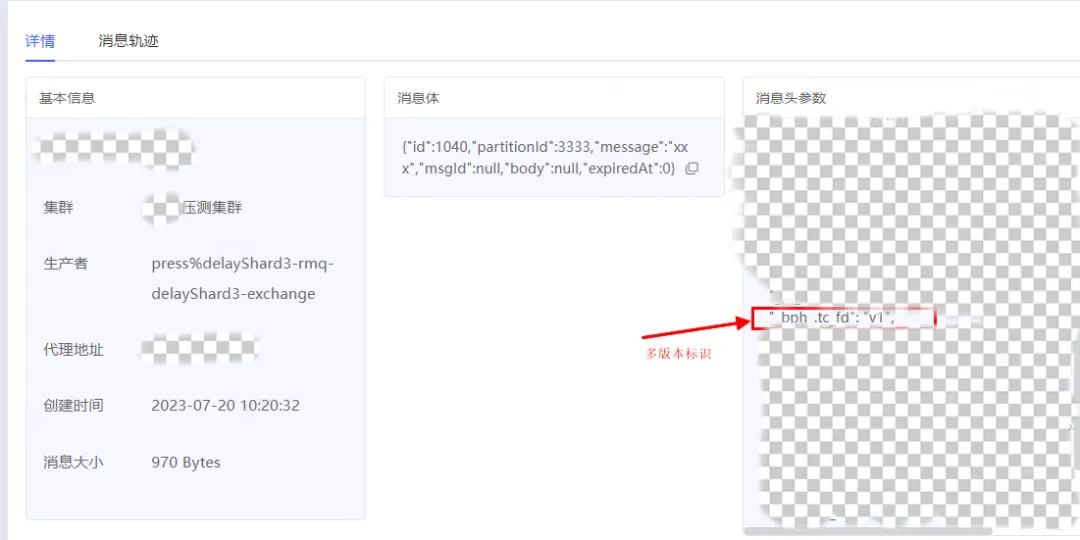
.NET Emit 入门教程:第六部分:IL 指令:2:详解 ILGenerator 辅助方法
前言:
经过前面几大部分的学习,已经掌握了 Emit 的前因后果,今天来详细讲解 Emit 中 IL 的部分内容。
如前文所讲,通过 DynamicMethod(或 MethodBuilder)可获得 ILGenerator 这个用于编写 IL 指令的类,并用它来编写 IL 指令。
本篇主要讲解 ILGenerator 的介绍,以及主要的辅助方法,详细的指令方法,则拆分到下一篇介绍。
下面就开邕它的介绍吧:
1、ILGenerator 介绍
ILGenerator 是.NET 中的一个重要组件,用于动态生成 Intermediate Language(IL)代码。
通过ILGenerator,开发人员可以在运行时创建和修改方法体内的IL指令,实现动态方法的生成和优化。
ILGenerator 提供了一组方法,允许程序员发出各种IL指令,包括加载、存储、运算、流程控制等操作,从而实现对方法体逻辑的灵活控制。
在 .NET 开发中,ILGenerator 通常与 DynamicMethod 类结合使用。
通过 DynamicMethod 创建动态方法对象,然后使用 ILGenerator 在其中生成IL代码。
这种结合使开发人员能够在运行时动态生成高效的代码,应用于一些需要动态生成代码的场景,如动态代理、AOP等。
ILGenerator 的灵活性和强大功能为.NET开发提供了更多可能性和自定义性。
2、ILGenerator 简单示例:
先看一下之前文章提到的代码:
DynamicMethod dynamicMethod = new DynamicMethod("MyMethod", typeof(void), null);
ILGenerator il=dynamicMethod.GetILGenerator();
il.EmitWriteLine("hello world!");
il.Emit(OpCodes.Ret);
从示例代码使用了两类方法:
指令方法:il.Emit(OpCodes.Ret)
辅助方法:il.EmitWriteLine("hello world!")
所有的辅助方法,都是基于指令方法的封装,即用指令也可以实现该方法功能,
但用辅助方法,可以更简单的调用,下面开始介绍辅助方法。
3、ILGenerator 辅助方法:EmitWriteLine
该方法封装好的调用 WriteLine 输出控制台消息,使用它可以简单输出控制台方法,而不用编写 Emit 指令方法。
如果用 Emit 指令,编写是这样的:
var il =methodBuilder.GetILGenerator();
il.Emit(OpCodes.Ldstr,"这是一个示例消息");
il.Emit(OpCodes.Call,typeof(Console).GetMethod("WriteLine", new Type[] { typeof(string) }));
il.Emit(OpCodes.Ret);
实现效果对应代码:

4、ILGenerator 辅助方法:异常处理 try catch finally
辅助方法中,提供了关于常用的 try catch finally 的封装方法,可以帮助我们更简单的编写IL方法:
看示例代码:
var il =methodBuilder.GetILGenerator();
il.BeginExceptionBlock();//开始 try il.EmitWriteLine("hello world!");
il.BeginCatchBlock(typeof(Exception));//开始 catch il.EmitWriteLine("hello world on error!");
il.BeginFinallyBlock();//开始 finally il.EmitWriteLine("hello world on finally!");
il.EndExceptionBlock();//结束 il.Emit(OpCodes.Ldarg_0);
il.Emit(OpCodes.Ret);
参照对应生成的代码:

5、ILGenerator 辅助方法:异常抛出
辅助方法中,也提供了一个抛出异常的方法,示例代码:
var il =methodBuilder.GetILGenerator();
il.ThrowException(typeof(Exception));
il.Emit(OpCodes.Ret);
查看对应生成:

但是该辅助方法只能生成抛出异常,没有提供异常的参数。
如果需要更详细的异常抛出,则需要使用指令的方法:
指令方法如:
var il =methodBuilder.GetILGenerator();
il.Emit(OpCodes.Ldstr,"这是一个示例异常消息");//创建一个新的 Exception 实例 ConstructorInfo ctor = typeof(Exception).GetConstructor(new Type[] { typeof(string) });
il.Emit(OpCodes.Newobj, ctor);//使用 ThrowException 方法引发异常 il.Emit(OpCodes.Throw);
il.Emit(OpCodes.Ret);
生成的对应代码:

6、ILGenerator 辅助方法:定义变量
辅助方法中,有一个是用来辅助定义变量的。
但是它需要配置 Emit 指令使用,示例代码:
ILGenerator il =methodBuilder.GetILGenerator();
LocalBuilder local= il.DeclareLocal(typeof(string)); // 定义变量
il.Emit(OpCodes.Ldstr,"hello world"); // 加载字符串
il.Emit(OpCodes.Stloc, local); // 将字符串赋值给变量 il.Emit(OpCodes.Ldloc, local); //从变量中 加载值进栈
il.Emit(OpCodes.Ret);//返回(带值)
对应生成的代码:

在这个示例中(为了举例,多了中间的赋值取值的过程):
可以看出,定义的临时变量,都是没有名称的,只有类型。
它可以用来临时存值,需要用到的时候,再将值取出,对应两个 Emit 指令:
赋值:il.Emit(OpCodes.Stloc, local); //将字符串赋值给变量 取值:il.Emit(OpCodes.Ldloc, local); //从变量中 加载值进栈
7、ILGenerator 辅助方法:定义标签
标签的定义,可以理解为跳转,即现在不常用的 goto 语句所需的的标签。
标签的定义,在 if else 中, switch 中,for 循环中,都会常常使用到标签。
标签的使用分为3步,定义标签、设定标签、跳转到标签。
标签定义:
Label label = il.DefineLabel();
设定标签:
il.MarkLabel(label);
跳转标签:
在 IL(Intermediate Language)中,可以使用以下指令来跳转到标签(Label):
条件跳转指令:
beq
:如果两个值相等,则跳转到指定的标签。bge
:如果第一个值大于或等于第二个值,则跳转到指定的标签。bgt
:如果第一个值大于第二个值,则跳转到指定的标签。ble
:如果第一个值小于或等于第二个值,则跳转到指定的标签。blt
:如果第一个值小于第二个值,则跳转到指定的标签.bne.un
:如果两个无符号整数值不相等,则跳转到指定的标签。brtrue
:如果值为 true,则跳转到指定的标签。brfalse
:如果值为 false,则跳转到指定的标签。brtrue.s
:如果值为 true,则跳转到指定的标签(短格式)。brfalse.s
:如果值为 false,则跳转到指定的标签(短格式).
无条件跳转指令:
br
:无条件跳转到指定的标签。br.s
:短格式的无条件跳转到指定的标签。leave
:无条件跳转到 try、filter 或 finally 块的末尾。leave.s
:短格式的无条件跳转到 try、filter 或 finally 块的末尾.
比较跳转指令:
bgt.un
:如果第一个无符号整数值大于第二个值,则跳转到指定的标签。bge.un
:如果第一个无符号整数值大于或等于第二个值,则跳转到指定的标签。blt.un
:如果第一个无符号整数值小于第二个值,则跳转到指定的标签。ble.un
:如果第一个无符号整数值小于或等于第二个值,则跳转到指定的标签.
其他跳转指令:
switch
:根据给定的索引值跳转到不同的标签。brnull
:如果值为 null,则跳转到指定的标签。brinst
:如果对象是类的实例,则跳转到指定的标签。
这些指令可以帮助控制流程,在特定条件下跳转到指定的标签位置执行相应的代码。
通过合理使用这些跳转指令,可以实现复杂的逻辑控制和条件判断。
总结:
这篇教程总结了.NET Emit 中关于 IL 指令的第六部分,着重介绍了 ILGenerator 辅助方法的详细内容。
ILGenerator 是在动态生成程序集时用来生成 Intermediate Language(IL)指令的一个重要工具。
读者通过本篇文章,可以迅速了解到该教程的主要内容和重点,更好地掌握 ILGenerator 辅助方法的使用及 IL 指令的生成过程。
下一篇,我们将重点讲解 IL 的指令内容。