sentinel的见解
Sentinel
是面向分布式、多语言异构化服务架构的流量治理组件,主要以流量为切入点,从流量控制、熔断降级、热点流量防护等多个维度来帮助开发者保障微服务的稳定性。
是面向分布式、多语言异构化服务架构的流量治理组件,主要以流量为切入点,从流量控制、熔断降级、热点流量防护等多个维度来帮助开发者保障微服务的稳定性。
在 Sentinel 里面,所有的资源都对应一个资源名称(
),每次资源调用都会创建一个
对象。Entry 可以通过对主流框架的适配自动创建,也可以通过注解的方式或调用
API 显式创建。Entry 创建的时候,同时也会创建一系列功能插槽(slot chain),这些插槽有不同的职责,例如:
resourceName
),每次资源调用都会创建一个
Entry
对象。Entry 可以通过对主流框架的适配自动创建,也可以通过注解的方式或调用
SphU
API 显式创建。Entry 创建的时候,同时也会创建一系列功能插槽(slot chain),这些插槽有不同的职责,例如:
NodeSelectorSlot
负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级;ClusterBuilderSlot
则用于存储资源的统计信息以及调用者信息,例如该资源的 RT, QPS, thread count 等等,这些信息将用作为多维度限流,降级的依据;StatisticSlot
则用于记录、统计不同纬度的 runtime 指标监控信息;FlowSlot
则用于根据预设的限流规则以及前面 slot 统计的状态,来进行流量控制;(
流控规则
)AuthoritySlot
则根据配置的黑白名单和调用来源信息,来做黑白名单控制;(
授权规则
)DegradeSlot
则通过统计信息以及预设的规则,来做熔断降级;(
降级规则
)SystemSlot
则通过系统的状态,例如 load1 等,来控制总的入口流量;(
系统规则
)
下面是官网的原图:
Sentinel 核心类解析
ProcessorSlotChain
- Sentinel 的核心骨架,将不同的 Slot 按照顺序串在一起(责任链模式),从而将不同的功能(限流、降级、系统保护)组合在一起。slot chain 其实可以分为两部分:统计数据构建部分(statistic)和判断部分(rule checking)。核心结构:
Context
- Context 代表调用链路上下文,贯穿一次调用链路中的所有
Entry
。Context 名称即为调用链路入口名称。 - Context 维持的方式:
enter
- 每一次资源调用都会创建一个
Entry
。
Entry
包含了资源名、curNode(当前统计节点)、originNode(来源统计节点)等信息。 CtEntry
为普通的
Entry
,在调用
SphU.entry(xxx)
的时候创建。特性:Linked entry within current context(内部维护着
parent
和
child
)- 需要注意的一点
:CtEntry 构造函数中会做
调用链的变换
,即将当前 Entry 接到传入 Context 的调用链路上(
setUpEntryFor
)。 - 资源调用结束时需要
entry.exit()
。exit 操作会过一遍 slot chain exit,恢复调用栈,exit context 然后清空 entry 中的 context 防止重复调用。
- 每一次资源调用都会创建一个
- Context 代表调用链路上下文,贯穿一次调用链路中的所有
Node
Sentinel 里面的各种种类的统计节点:
EntranceNode
:
入口节点
,特殊的链路节点,对应某个 Context 入口的所有调用数据。DefaultNode
:
链路节点
,用于统计调用链路上某个资源的数据,维持树状结构。ClusterNode
:
簇点
,用于统计每个资源全局的数据(不区分调用链路),以及存放该资源的按来源区分的调用数据StatisticNode
:最为基础的统计节点,包含秒级和分钟级两个滑动窗口结构
例子:入现在有两个入口业务同时访问goods
业务1: controller中的资源@PostMapping("/order/query") 访问了service中的资源/goods
结果:
- 不同的入口有不同的
EntranceNode - 不同的链路有不同/goods资源都有单独的一个
ClusterNode
,统计所有链路
S
PI
扩展
Sentinel 提供多样化的 SPI 接口用于提供扩展的能力。开发者可以在用同一个
sentinel-core
的基础上自行扩展接口实现,从而可以方便地根据业务需求给 Sentinel 添加自定义的逻辑。目前 Sentinel 提供如下的扩展点:
- 初始化过程扩展:提供
InitFunc
SPI接口,可以添加自定义的一些初始化逻辑,如动态规则源注册等。- Slot/Slot Chain 扩展:用于给 Sentinel 功能链添加自定义的功能并自由编排。
- 指标统计扩展(StatisticSlot Callback):用于扩展 StatisticSlot 指标统计相关的逻辑。
- Transport 扩展:提供 CommandHandler、CommandCenter 等接口,用于对心跳发送、监控 API Server 进行扩展。
- 集群流控扩展:可以方便地定制 token client/server 自定义实现,可参考
对应文档- 日志扩展:用于自定义 record log Logger,可用于对接 slf4j 等标准日志实现。
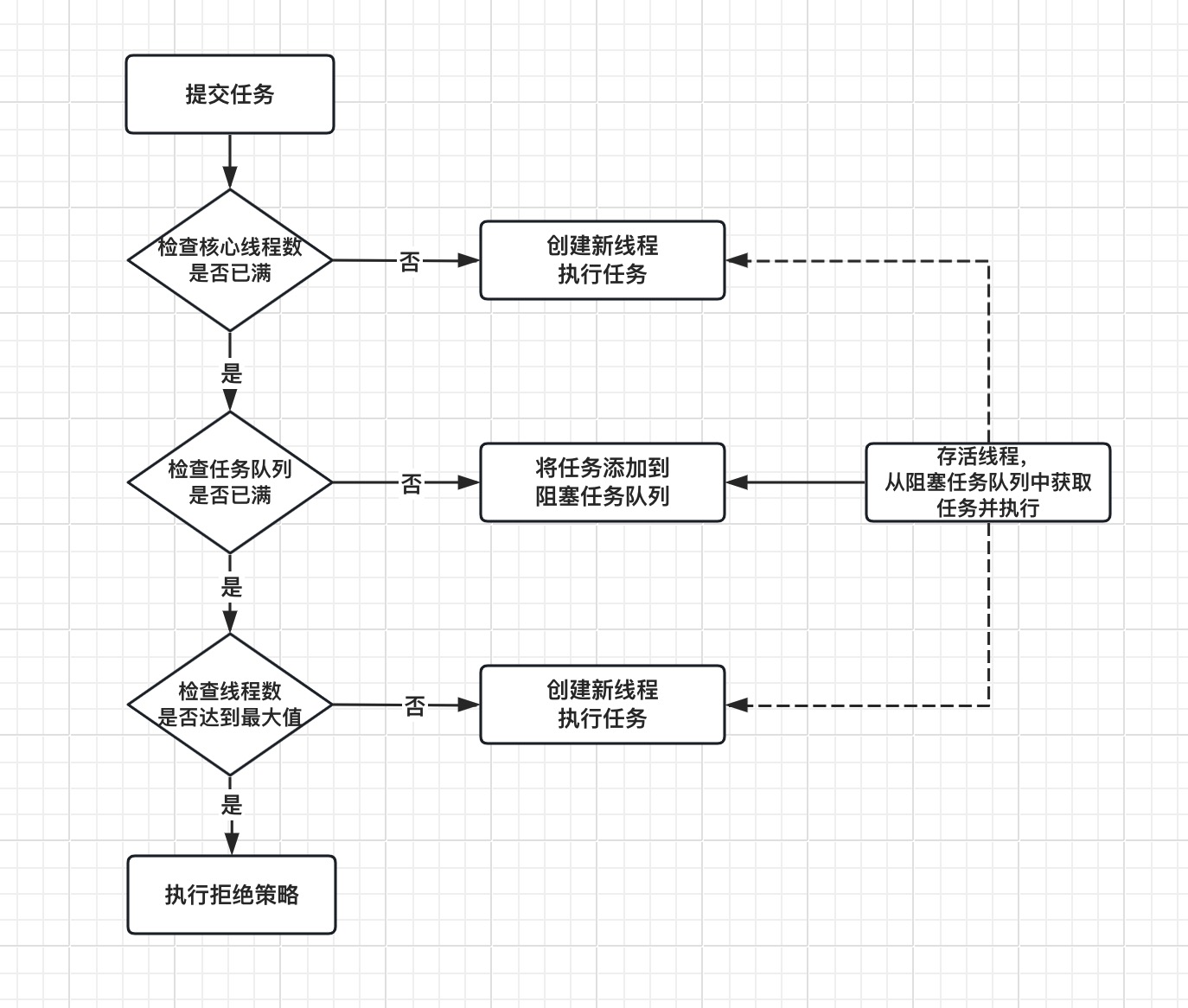
Sentinel 工作原理
1、
@SentinelResource基于Aspect的
AOP
实现spring.factories加载SentinelAutoConfiguration.java-->SentinelResourceAspect.java-->@Aspect定义标记-->定义切入点@Pointcut("@annotation(com.alibaba.csp.sentinel.annotation.SentinelResource)")-->增强拦截@Around("sentinelResourceAnnotationPointcut()")
- entryWithPriority()接口,entry统一会进入此接口,
ThreadLocal保护线程之中,一个线程使用一个context,
-->SphU.entry()-->Env. sph.entryWithType
()-->CtSph#entryWithPriority()
private Entry entryWithPriority(ResourceWrapper resourceWrapper, int count, boolean prioritized, Object... args)
throws BlockException {
// ThreadLocal<Context> contextHolder,使用ThreadLocal线程保护获取上下文
Context context = ContextUtil.getContext();
// 默认获取名称为sentinel_default_context的上下文
if (context == null) {
context = InternalContextUtil.internalEnter(Constants.CONTEXT_DEFAULT_NAME);
}
ProcessorSlot<Object> chain = lookProcessChain(resourceWrapper);
Entry e = new CtEntry(resourceWrapper, chain, context);
try {
chain.entry(context, resourceWrapper, null, count, prioritized, args);
} catch (BlockException e1) {
e.exit(count, args);
throw e1;
} catch (Throwable e1) {
// This should not happen, unless there are errors existing in Sentinel internal.
RecordLog.info("Sentinel unexpected exception", e1);
}
return e;
}- 创建context上下文,ContextUtil.trueEnter()接口的实现
- 里面使用到Lock锁和两次get()操作实现双重校验锁 DCL,保证原子性和性能问题
protected static Context trueEnter(String name, String origin) { Context context = contextHolder.get(); if (context == null) { Map<String, DefaultNode> localCacheNameMap = contextNameNodeMap; // Lock锁和两次get()操作实现双重校验锁 DCL,保证原子性和性能问题 DefaultNode node = localCacheNameMap.get(name); if (node == null) { if (localCacheNameMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) { setNullContext(); return NULL_CONTEXT; } else { try { LOCK.lock(); node = contextNameNodeMap.get(name); if (node == null) { if (contextNameNodeMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) { setNullContext(); return NULL_CONTEXT; } else { node = new EntranceNode(new StringResourceWrapper(name, EntryType.IN), null); // Add entrance node. Constants.ROOT.addChild(node); // 里面使用到CopyOnWrite技术,首先将旧的contextNameNodeMap拷贝一份,然后更新拷贝的map,再用更新后的实例列表来覆盖旧的实例列表。防止高并发读脏数据。 Map<String, DefaultNode> newMap = new HashMap<>(contextNameNodeMap.size() + 1); newMap.putAll(contextNameNodeMap); newMap.put(name, node); contextNameNodeMap = newMap; } } } finally { LOCK.unlock(); } } } context = new Context(node, name); context.setOrigin(origin); contextHolder.set(context); } return context; }
2、
接口基于AbstractSentinellnterceptor
拦截器
实现
- 1.获取resourceName (controller方法的RegestMapping)
- 2.获取contextName,默认是sentinel-springweb-context
- 3.获取origin,基于自定义的RequestOriginParser
- 4初始化Context ContextUtil.enter(contextilame, oring)
4.1.创建EntranceNode(contextName)4.2创建Context,放入ThreadLocal - 5.标记资源,创建Entry,Entry e = SphU.entry(resourceName)
- 执行ProcesserSlotChain
Sentinel 的
SlotChain
slot chain设计是一个槽卡调用链,其实可以分为两部分:
统计数据构建部分
(statistic)和
规则判断部分
(rule checking)。
统计数据构建部分
(statistic)和
规则判断部分
(rule checking)。
统计数据构建部分:
、
、
NodeSelectorSlot
、
ClusterBuilderSlot
、
StatisticSlot
规则判断部分:
、
、
、
、
ParamFlowSlot
、
FlowSlot
、
AuthoritySlot
、
DegradeSlot
、
SystemSlot
调用顺序:
NodeSelectorSlot
负责收集资源的路径,并将这些资源的调用路径,以树状结构存储
Node
起来,用于根据调用路径来限流降级,入下图收集node:
Node
起来,用于根据调用路径来限流降级,入下图收集node:
ClusterBuilderSlot
则用于存储资源的统计信息以及调用者信息,例如该资源的 RT, QPS, thread count 等等,这些信息将用作为多维度限流,降级的依据;
StatisticSlot
负责统计实时调用数据
,包括运行信息 (访问次数、线程数)、来源信息等是实现限流的关键,其中基于
滑动时间窗口
算法维护了计数器,统计进入某个资源的请求次数
核心代码如下:
ParamFlowSlot
热点规则:使用令牌通算法实现
SystemSlot
系统规则
:则通过系统的状态,例如 load1 等,来控制总的入口流量;
:则通过系统的状态,例如 load1 等,来控制总的入口流量;
AuthoritySlot
授权规则
:则根据配置的黑白名单和调用来源信息,来做黑白名单控制。
:则根据配置的黑白名单和调用来源信息,来做黑白名单控制。
FlowSlot
流控规则
:则用于根据预设的限流规则以及前面 slot 统计的状态,来进行流量控制。
:则用于根据预设的限流规则以及前面 slot 统计的状态,来进行流量控制。
包括:
- 三种流控模式:直接模式、关联模式、链路模式
- 三种流控效果:快速失败、warm up、排队等待
限流算法:
滑动时间窗口算法
: 快速失败、warm up
: 快速失败、warm up
漏桶算法
: 排队等待效果,(sentinel主要通过

: 排队等待效果,(sentinel主要通过
DegradeSlot
降级规则
:则通过统计信息以及预设的规则,来做熔断降级
:则通过统计信息以及预设的规则,来做熔断降级
实现原理
:通过StatisticSlot 获取的统计数据,通过三个状态OPEN、Close、Half-Open(中间状态)来判断是否降级熔断。
:通过StatisticSlot 获取的统计数据,通过三个状态OPEN、Close、Half-Open(中间状态)来判断是否降级熔断。
限流算法
限流
:对应用服务器的请求做限制,避免因过多请求而导致服务器过载甚至宕机。
:对应用服务器的请求做限制,避免因过多请求而导致服务器过载甚至宕机。
限流算法常见的包括两种:
- 计数器算法
,又包括窗口计数器算法、滑动窗口计数器算法 - 令牌桶
算法
(Token Bucket) - 漏桶算法
(Leaky Bucket)
sentinel在不同的场景下使用了以上三中不同的算法:
滑动窗口计数器算法
窗口计数器算法有固定窗口算法、滑动窗口计数算法


- 固定窗口算法
缺点:
对于在两个窗口中间临界点的流量突刺,不能统计起来
- 滑动窗口算法
优点:每次根据当前时间获取时间
窗口期
,可以统计流量突刺
缺点:统计量大
sentinel使用了
滑动窗口算法,
把每个时间窗口期划分为多个
样本
,然后每个样本去统计流量数量,定义⼀个存储结构(bucket),⽤于存储计数的值(count),它与时间单元格⼦⼀⼀对应。数据结构可以采⽤数组或链表,Sentinel中采⽤的是定⻓的数组,⽐较有意思。
滑动窗口算法,
把每个时间窗口期划分为多个
样本
,然后每个样本去统计流量数量,定义⼀个存储结构(bucket),⽤于存储计数的值(count),它与时间单元格⼦⼀⼀对应。数据结构可以采⽤数组或链表,Sentinel中采⽤的是定⻓的数组,⽐较有意思。
使用环形的数据存储,避免数据无限长
令牌桶
算法
令牌桶算法说明:
- 以固定的速率生成令牌,存入令牌桶中,如果令牌桶满了以后,多余令牌丢弃
- 请求进入后,必须先尝试从桶中获取令牌,获取到令牌后才可以被处理
- 如果令牌桶中没有令牌,则请求等待或丢弃
漏桶算法
漏桶算法说明
- 将每个请求视作作”水滴”放入”漏桶”进行存储
- ”漏桶”以固定速率向外"漏”出请求来执行,如果”漏桶”空了则停止”漏水”
sentinel实现
RateLimiterController.java
,然后
排队
的实现是通过:
Thread. sleep(
RateLimiterController.java
,然后
排队
的实现是通过:
Thread. sleep(
waitTime
);
@Override
public boolean canPass(Node node, int acquireCount, boolean prioritized) {
// Pass when acquire count is less or equal than 0.
if (acquireCount <= 0) {
return true;
}
// Reject when count is less or equal than 0.
// Otherwise,the costTime will be max of long and waitTime will overflow in some cases.
if (count <= 0) {
return false;
}
long currentTime = TimeUtil.currentTimeMillis();
// Calculate the interval between every two requests.
long costTime = Math.round(1.0 * (acquireCount) / count * 1000);
// Expected pass time of this request.
long expectedTime = costTime + latestPassedTime.get();
if (expectedTime <= currentTime) {
// Contention may exist here, but it's okay.
latestPassedTime.set(currentTime);
return true;
} else {
// Calculate the time to wait.
long waitTime = costTime + latestPassedTime.get() - TimeUtil.currentTimeMillis();
if (waitTime > maxQueueingTimeMs) {
return false;
} else {
long oldTime = latestPassedTime.addAndGet(costTime);
try {
waitTime = oldTime - TimeUtil.currentTimeMillis();
if (waitTime > maxQueueingTimeMs) {
latestPassedTime.addAndGet(-costTime);
return false;
}
// in race condition waitTime may <= 0
if (waitTime > 0) {
Thread.sleep(waitTime);
}
return true;
} catch (InterruptedException e) {
}
}
}
return false;
}限流算法对比