本文为从零开始写 Docker 系列第三篇,在
mydocker run
基础上基于 cgroups 实现容器的资源限制。
完整代码见:
https://github.com/lixd/mydocker
欢迎 Star
如果你对云原生技术充满好奇,想要深入了解更多相关的文章和资讯,欢迎关注微信公众号。
搜索公众号【
探索云原生
】即可订阅
推荐阅读以下文章对 docker 基本实现有一个大致认识:
开发环境如下:
root@mydocker:~# lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 20.04.2 LTS
Release: 20.04
Codename: focal
root@mydocker:~# uname -r
5.4.0-74-generic
注意:需要使用 root 用户
1. 概述
上一节中,已经可以通过命令行
mydocker run -it
的方式创建并启动容器。这一节,将
通过 cgroups 实现对容器资源进行限制
。
这一节中,将实现通过增加
-mem
、
-cpu
等 flag 来实现容器 cpu、内存资源限制,完整命令如下:
./mydocker run -it -mem 10m -cpu 20 /bin/sh
包含以下几个部分:
- mydocker run 命令增加对应 flag
- 实现统一 CgroupsManager
- 实现各个 Subsystem
- 容器创建、停止时调用对应方法配置 cgroup
2. 具体实现
2.1. Cli 增加 flags
run 命令增加
mem
、
cpu
、
cpuset
这几个 flag,具体如下:
var runCommand = cli.Command{
Name: "run",
Usage: `Create a container with namespace and cgroups limit
mydocker run -it [command]`,
Flags: []cli.Flag{
cli.BoolFlag{
Name: "it", // 简单起见,这里把 -i 和 -t 参数合并成一个
Usage: "enable tty",
},
cli.StringFlag{
Name: "mem", // 限制进程内存使用量,为了避免和 stress 命令的 -m 参数冲突 这里使用 -mem,到时候可以看下解决冲突的方法
Usage: "memory limit,e.g.: -mem 100m",
},
cli.StringFlag{
Name: "cpu",
Usage: "cpu quota,e.g.: -cpu 100", // 限制进程 cpu 使用率
},
cli.StringFlag{
Name: "cpuset",
Usage: "cpuset limit,e.g.: -cpuset 2,4", // 限制进程 cpu 使用率
},
},
/*
这里是run命令执行的真正函数。
1.判断参数是否包含command
2.获取用户指定的command
3.调用Run function去准备启动容器:
*/
Action: func(context *cli.Context) error {
if len(context.Args()) < 1 {
return fmt.Errorf("missing container command")
}
var cmdArray []string
for _, arg := range context.Args() {
cmdArray = append(cmdArray, arg)
}
tty := context.Bool("it")
resConf := &subsystems.ResourceConfig{
MemoryLimit: context.String("mem"),
CpuSet: context.String("cpuset"),
CpuCfsQuota: context.Int("cpu"),
}
Run(tty, cmdArray, resConf)
return nil
},
}
从命令行中解析对应参数并传给 subsystem 以配置 cgroups。
2.2. Subsystem 实现
核心思想就是根据传递过来的参数,创建对应的 cgroups 并配置 subsystem。
例如指定了 -m 100m 就创建 memory subsystem,限制只能使用 100m 内存
定义 Subsystem
首先定义 Subsystem,这里将其抽象为一个接口以适应各种 subsystem:
// Subsystem 接口,每个Subsystem可以实现下面的4个接口,
// 这里将cgroup抽象成了path,原因是cgroup在hierarchy的路径,便是虚拟文件系统中的虚拟路径
type Subsystem interface {
// Name 返回当前Subsystem的名称,比如cpu、memory
Name() string
// Set 设置某个cgroup在这个Subsystem中的资源限制
Set(path string, res *ResourceConfig) error
// Apply 将进程添加到某个cgroup中
Apply(path string, pid int) error
// Remove 移除某个cgroup
Remove(path string) error
}
// ResourceConfig 用于传递资源限制配置的结构体,包含内存限制,CPU 时间片权重,CPU核心数
type ResourceConfig struct {
MemoryLimit string
CpuCfsQuota int
CpuShare string
CpuSet string
}
- Name:Subsystem 名称,例如 memory、cpu。
- Set:根据 ResourceConfig 设置 cgroup,即将阈值写入对应配置文件。
- 例如 memory subsystem 则需将配置写入 memory.limit_in_bytes 文件
- cpu subsystem 则是写入 cpu.cfs_period_us 和 cpu.cfs_quota_us
- Apply:将对应 pid 添加到指定 cgroup 里
- Remove:删除指定 cgroup
不同 Subsystem 只需要实现该接口即可。
找到 cgroup 挂载路径
在实现 Subsystem 之前,我们还需要先找到 cgroup 的挂载路径,这样才能对 cgroup 进行操作。
那么,是如何找到挂载了 subsystem 的 hierarchy 的挂载目录的呢?
先来熟悉下
/proc/{pid}/mountinfo
文件,如下:
$ cat /proc/24334/mountinfo
613 609 0:59 / /sys ro,nosuid,nodev,noexec,relatime - sysfs sysfs ro
620 613 0:61 / /sys/fs/cgroup rw,nosuid,nodev,noexec,relatime - tmpfs tmpfs rw,mode=755
624 620 0:26 /docker/fa4b9c67d031dd83cedbad7b744b4ae64eb689c5089f77d0c95379bd3b66d791 /sys/fs/cgroup/systemd ro,nosuid,nodev,noexec,relatime master:5 - cgroup cgroup rw,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd
625 620 0:29 /docker/fa4b9c67d031dd83cedbad7b744b4ae64eb689c5089f77d0c95379bd3b66d791 /sys/fs/cgroup/perf_event ro,nosuid,nodev,noexec,relatime master:6 - cgroup cgroup rw,perf_event
627 620 0:30 /docker/fa4b9c67d031dd83cedbad7b744b4ae64eb689c5089f77d0c95379bd3b66d791 /sys/fs/cgroup/net_cls,net_prio ro,nosuid,nodev,noexec,relatime master:7 - cgroup cgroup rw,net_cls,net_prio
629 620 0:31 /docker/fa4b9c67d031dd83cedbad7b744b4ae64eb689c5089f77d0c95379bd3b66d791 /sys/fs/cgroup/cpu,cpuacct ro,nosuid,nodev,noexec,relatime master:8 - cgroup cgroup rw,cpu,cpuacct
631 620 0:32 /docker/fa4b9c67d031dd83cedbad7b744b4ae64eb689c5089f77d0c95379bd3b66d791 /sys/fs/cgroup/pids ro,nosuid,nodev,noexec,relatime master:9 - cgroup cgroup rw,pids
634 620 0:33 / /sys/fs/cgroup/rdma ro,nosuid,nodev,noexec,relatime master:10 - cgroup cgroup rw,rdma
641 620 0:38 /docker/fa4b9c67d031dd83cedbad7b744b4ae64eb689c5089f77d0c95379bd3b66d791 /sys/fs/cgroup/hugetlb ro,nosuid,nodev,noexec,relatime master:15 - cgroup cgroup rw,hugetlb
644 620 0:39 /docker/fa4b9c67d031dd83cedbad7b744b4ae64eb689c5089f77d0c95379bd3b66d791 /sys/fs/cgroup/freezer ro,nosuid,nodev,noexec,relatime master:16 - cgroup cgroup rw,freezer
646 611 0:52 / /dev/mqueue rw,nosuid,nodev,noexec,relatime - mqueue mqueue rw
647 611 0:63 / /dev/shm rw,nosuid,nodev,noexec,relatime - tmpfs shm rw,size=65536k
648 609 253:1 /var/lib/docker/containers/fa4b9c67d031dd83cedbad7b744b4ae64eb689c5089f77d0c95379bd3b66d791/resolv.conf /etc/resolv.conf rw,relatime - xfs /dev/vda1 rw,attr2,inode64,noquota
649 609 253:1 /var/lib/docker/containers/fa4b9c67d031dd83cedbad7b744b4ae64eb689c5089f77d0c95379bd3b66d791/hostname /etc/hostname rw,relatime - xfs /dev/vda1 rw,attr2,inode64,noquota
650 609 253:1 /var/lib/docker/containers/fa4b9c67d031dd83cedbad7b744b4ae64eb689c5089f77d0c95379bd3b66d7
# ... 省略
通过
/proc/self/mountinfo
可以找出 与当前进程相关的 mount 信息。
而 Cgroups 的 hierarchy 的虚拟文件系统是以 cgroup 类型文件系统的 mount 挂载上去的,其中的 option 中加上 subsystem,代表挂载的 subsystem 类型。
根据这个就可以在 mountinfo 中找到对应的 subsystem 的挂载目录了,比如 memory:
/sys/fs/cgroup/memory ro,nosuid,nodev,noexec,relatime master:11 - cgroup cgroup rw,memory
通过最后的 option 是
rw, memory
看出这一条挂载的 subsystem 是 memory。
那么在
/sys/fs/cgroup/memory
中创建文件夹对应创建的 cgroup,就可以用来做内存的限制。
根据这个规则我们就可以找到对应 cgroup 挂载位置了,具体代码实现如下。
下面的
getCgroupPath
函数是找到对应 subsystem 挂载的 hierarchy 相对路径对应的 cgroup 在虚拟文件系统中的路径,然后通过这个目录的读写去操作 cgroup
。
const mountPointIndex = 4
// getCgroupPath 找到cgroup在文件系统中的绝对路径
/*
实际就是将根目录和cgroup名称拼接成一个路径。
如果指定了自动创建,就先检测一下是否存在,如果对应的目录不存在,则说明cgroup不存在,这里就给创建一个
*/
func getCgroupPath(subsystem string, cgroupPath string, autoCreate bool) (string, error) {
// 不需要自动创建就直接返回
cgroupRoot := findCgroupMountpoint(subsystem)
absPath := path.Join(cgroupRoot, cgroupPath)
if !autoCreate {
return absPath, nil
}
// 指定自动创建时才判断是否存在
_, err := os.Stat(absPath)
// 只有不存在才创建
if err != nil && os.IsNotExist(err) {
err = os.Mkdir(absPath, constant.Perm0755)
return absPath, err
}
// 其他错误或者没有错误都直接返回,如果err=nil,那么errors.Wrap(err, "")也会是nil
return absPath, errors.Wrap(err, "create cgroup")
}
// findCgroupMountpoint 通过/proc/self/mountinfo找出挂载了某个subsystem的hierarchy cgroup根节点所在的目录
func findCgroupMountpoint(subsystem string) string {
// /proc/self/mountinfo 为当前进程的 mountinfo 信息
// 可以直接通过 cat /proc/self/mountinfo 命令查看
f, err := os.Open("/proc/self/mountinfo")
if err != nil {
return ""
}
defer f.Close()
// 这里主要根据各种字符串处理来找到目标位置
scanner := bufio.NewScanner(f)
for scanner.Scan() {
// txt 大概是这样的:104 85 0:20 / /sys/fs/cgroup/memory rw,nosuid,nodev,noexec,relatime - cgroup cgroup rw,memory
txt := scanner.Text()
// 然后按照空格分割
fields := strings.Split(txt, " ")
// 对最后一个元素按逗号进行分割,这里的最后一个元素就是 rw,memory
// 其中的的 memory 就表示这是一个 memory subsystem
subsystems := strings.Split(fields[len(fields)-1], ",")
for _, opt := range subsystems {
if opt == subsystem {
// 如果等于指定的 subsystem,那么就返回这个挂载点跟目录,就是第四个元素,
// 这里就是`/sys/fs/cgroup/memory`,即我们要找的根目录
return fields[mountPointIndex]
}
}
}
if err = scanner.Err(); err != nil {
log.Error("read err:", err)
return ""
}
return ""
}
接下来我们就可以实现各个 Subsystem 了。
memory subsystem
memory subsystem 实现如下:
type MemorySubSystem struct {
}
// Name 返回cgroup名字
func (s *MemorySubSystem) Name() string {
return "memory"
}
// Set 设置cgroupPath对应的cgroup的内存资源限制
func (s *MemorySubSystem) Set(cgroupPath string, res *ResourceConfig) error {
if res.MemoryLimit == "" {
return nil
}
subsysCgroupPath, err := getCgroupPath(s.Name(), cgroupPath, true)
if err != nil {
return err
}
// 设置这个cgroup的内存限制,即将限制写入到cgroup对应目录的memory.limit_in_bytes 文件中。
if err := os.WriteFile(path.Join(subsysCgroupPath, "memory.limit_in_bytes"), []byte(res.MemoryLimit), constant.Perm0644); err != nil {
return fmt.Errorf("set cgroup memory fail %v", err)
}
return nil
}
// Apply 将pid加入到cgroupPath对应的cgroup中
func (s *MemorySubSystem) Apply(cgroupPath string, pid int, res *ResourceConfig) error {
if res.MemoryLimit == "" {
return nil
}
subsysCgroupPath, err := getCgroupPath(s.Name(), cgroupPath, false)
if err != nil {
return errors.Wrapf(err, "get cgroup %s", cgroupPath)
}
if err := os.WriteFile(path.Join(subsysCgroupPath, "tasks"), []byte(strconv.Itoa(pid)), constant.Perm0644); err != nil {
return fmt.Errorf("set cgroup proc fail %v", err)
}
return nil
}
// Remove 删除cgroupPath对应的cgroup
func (s *MemorySubSystem) Remove(cgroupPath string) error {
subsysCgroupPath, err := getCgroupPath(s.Name(), cgroupPath, false)
if err != nil {
return err
}
return os.RemoveAll(subsysCgroupPath)
}
可以看到,其实就是将操作 cgroups 的命令换成了 Go 语法罢了:
- 比如限制内存则是往
memory.limit_in_bytes
里写入指定值
- 添加某个进程到 cgroup 中就是往对应的 tasks 文件中写入对应的 pid
- 删除 cgroup 就是把对应目录删掉
另外的cpu subsystem 就不再贴代码了,都是类似的操作。
2.3 CgroupManager
实现了各个 Subsystem 之后,我们在往上抽象一层,
定义一个 CgroupManager 来统一管理各个 subsystem
。
这样调用方就可以不用管具体的底层的实现了,只需要调用 CgroupManager 即可。
实现也很简单,就是循环调用每个 subsystem 中的方法。
type CgroupManager struct {
// cgroup在hierarchy中的路径 相当于创建的cgroup目录相对于root cgroup目录的路径
Path string
// 资源配置
Resource *subsystems.ResourceConfig
}
func NewCgroupManager(path string) *CgroupManager {
return &CgroupManager{
Path: path,
}
}
// Apply 将进程pid加入到这个cgroup中
func (c *CgroupManager) Apply(pid int) error {
for _, subSysIns := range subsystems.SubsystemsIns {
err := subSysIns.Apply(c.Path, pid)
if err != nil {
logrus.Errorf("apply subsystem:%s err:%s", subSysIns.Name(), err)
}
}
return nil
}
// Set 设置cgroup资源限制
func (c *CgroupManager) Set(res *subsystems.ResourceConfig) error {
for _, subSysIns := range subsystems.SubsystemsIns {
err := subSysIns.Set(c.Path, res)
if err != nil {
logrus.Errorf("apply subsystem:%s err:%s", subSysIns.Name(), err)
}
}
return nil
}
// Destroy 释放cgroup
func (c *CgroupManager) Destroy() error {
for _, subSysIns := range subsystems.SubsystemsIns {
if err := subSysIns.Remove(c.Path); err != nil {
logrus.Warnf("remove cgroup fail %v", err)
}
}
return nil
}
- Set:配置 cgroup,具体实现则是循环调用各个 Subsystem 的 Set 方法
- Apply:将指定 pid 进程加入到 cgroup 中,实现同上
- Destroy:释放 cgroup,实现同上
通过 CgroupManager 将 Subsystem 进行封装,对上层隐藏了资源限制的配置,以及将进程移动到 cgroup 中等操作细节。
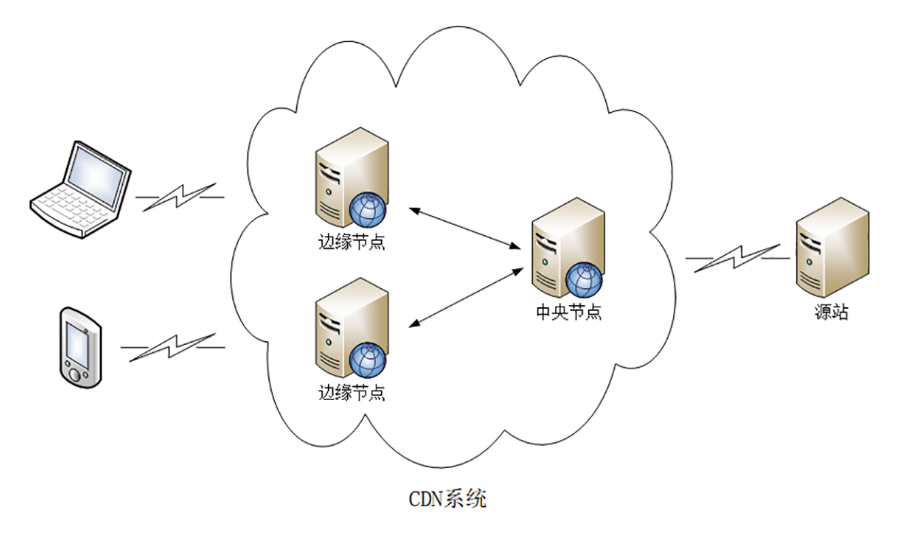
具体 CgroupManager 和 Subsystem 的调用流程如下所示:
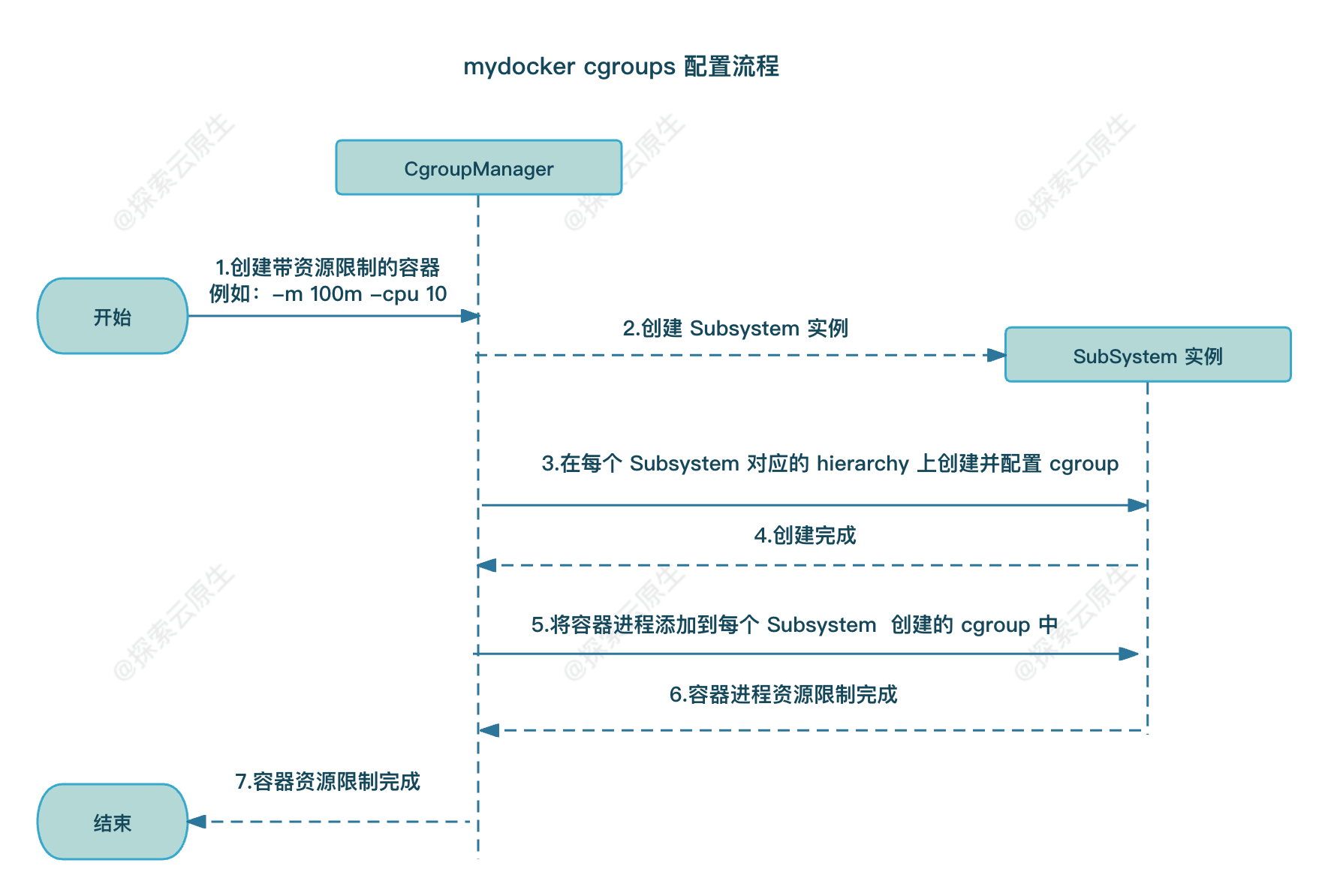
如图所示,CgroupManager 在配置容器资源限制时
- 首先会初始化 Subsystem 实例;
- 然后遍历调用 Subsystem 实例的 Set 方法,创建和配置不同 Subsystem 挂载的 hierarchy 中的 cgroup;
- 接着再通过调用 Subsystem 实例的 Apply 方法将容器进程对应 PID 分别加入到那些 cgroup 中,以实现容器的资源限制;
- 最后容器运行结束时则调用 Subsystem 实例的 Destory 销毁 cgroup。
到此,整个 Cgroups 的实现就算是完成了,后续剩下的就是在启动的时候,解析参数,并配置对应的 Cgroups 即可。
2.4. 实现 Cgroups 配置
至此,实现了参数解析以及 CgroupManager,剩下的只需要使用 flag 中解析的参数初始化 CgroupManager 实例并调用相关方法即可实现 Cgroups 配置。
前面讲解析的参数组装为 subsystems.ResourceConfig 对象,传递到 Run 方法中,
然后 Run 方法则根据前面解析好的 config 设置对应的 Cgroups。
func Run(tty bool, comArray []string, res *subsystems.ResourceConfig) {
parent, writePipe := container.NewParentProcess(tty)
if parent == nil {
log.Errorf("New parent process error")
return
}
if err := parent.Start(); err != nil {
log.Errorf("Run parent.Start err:%v", err)
}
// 创建cgroup manager, 并通过调用set和apply设置资源限制并使限制在容器上生效
cgroupManager := cgroups.NewCgroupManager("mydocker-cgroup")
defer cgroupManager.Destroy()
_ = cgroupManager.Set(res)
_ = cgroupManager.Apply(parent.Process.Pid)
// 再子进程创建后才能通过匹配来发送参数
sendInitCommand(comArray, writePipe)
_ = parent.Wait()
}
核心代码如下:
cgroupManager := cgroups.NewCgroupManager("mydocker-cgroup")
defer cgroupManager.Destroy()
_ = cgroupManager.Set(res)
_ = cgroupManager.Apply(parent.Process.Pid)
创建一个 Cgroups,然后调用 Set 方法写入对应的配置信息,最后调用 Apply 将子进程 pid 加入到这个 Cgroups 中。
这样就完成了 Cgroups 全部配置,已经可以限制子进程的资源使用了。
同时通过
defer cgroupManager.Destroy()
指定了 Destory 方法,以实现在容器退出后自动销毁对应 cgroup。
3. 测试
这里主要通过跑
stress
命令来测试 Cgroups 限制是否生效。
宿主机上需要先安装 stress,因为此时还没有切换 rootfs,因此可以直接使用宿主机上安装的程序。
memory
memory subsystem 测试流程如下:
启动容器并使用
-mem
flag 限制内存
使用程序占用大量内存,测试能否超过阈值
为了演示创建了下面这样一个程序,用来向系统申请内存,它会每秒消耗 1M 的内存。
vi ~/mem-allocate.c
完整内容如下:
cat > ~/mem-allocate.c <<EOF
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#define MB (1024 * 1024)
int main(int argc, char *argv[])
{
char *p;
int i = 0;
while(1) {
p = (char *)malloc(MB);
memset(p, 0, MB);
printf("%dM memory allocated\n", ++i);
sleep(1);
}
return 0;
}
EOF
编译一下
gcc ~/mem-allocate.c -o ~/mem-allocate
然后启动容器
root@mydocker:~/feat-cgroups/mydocker# ./mydocker run -it -mem 10m /bin/sh
{"level":"info","msg":"command all is /bin/sh","time":"2024-01-08T13:19:37+08:00"}
{"level":"info","msg":"init come on","time":"2024-01-08T13:19:37+08:00"}
{"level":"info","msg":"Find path /bin/sh","time":"2024-01-08T13:19:37+08:00"}
并在容器中运行内存占用程序
# ~/mem-allocate
1M memory allocated
2M memory allocated
3M memory allocated
4M memory allocated
5M memory allocated
6M memory allocated
7M memory allocated
8M memory allocated
9M memory allocated
Killed
可以看到,在第 10 次申请时由于达到了内存上限(10M) 程序直接被 OOM Kill 了。
内存和 CPU 不同,如果进程超过了分配的内存阈值,Linux 内核会采取 OOM (Out of Memory) 机制,以保证系统不会因内存不足而崩溃。
说明,我们的内存限制是生效的
最后在看一下 mydocker 创建的 cgroup 在哪儿
查看 memory subsystem 中的内容:
root@mydocker:~# ls /sys/fs/cgroup/memory/
cgroup.clone_children memory.kmem.tcp.failcnt memory.soft_limit_in_bytes mydocker-cgroup
tasks user.slice
可以看到,有一个 mydocker-cgroup 目录,这就是为 mydocker 容器创建的 memory cgroup。
查看内部的具体内容:
root@mydocker:~# cat /sys/fs/cgroup/memory/mydocker-cgroup/memory.limit_in_bytes
10485760
root@mydocker:~# cat /sys/fs/cgroup/memory/mydocker-cgroup/tasks
116477
memory.limit_in_bytes
中的配置 10485760 转换下单位就是我们启动时配置的 10m。
而
tasks
中的 116477 就是容器进程 PID。
最后,当我们执行 exit,退出容器后
mydocker-cgroup
也会随之删除。
cpu
cpu subsystem 测试也类似:
启动容器并使用
-cpu
flag 限制 cpu
使用程序占用大量 cpu,测试能否超过阈值
启动容器并限制只能占用 0.1核 cpu:
root@mydocker:~/feat-cgroups/mydocker# ./mydocker run -it -cpu 10 /bin/sh
{"level":"info","msg":"init come on","time":"2024-01-08T13:25:03+08:00"}
{"level":"info","msg":"command all is /bin/sh","time":"2024-01-08T13:25:03+08:00"}
{"level":"info","msg":"Find path /bin/sh","time":"2024-01-08T13:25:03+08:00"}
然后在容器中启动一个 while 循环
# while : ; do : ; done &
理论上,该 while 循环会占用满一整个 cpu,但是该容器被限制了只能占用 0.1 核 cpu。
查看CPU占用情况:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
116464 root 20 0 2608 88 0 R 10.0 0.0 0:05.37 sh
稳稳的被限制在了 10%,说明 cpu subsystem 也是生效的。
4. 小结
整个实现不算复杂,不过只要理解了实现原理,再写就很简单了。
几个重要的点如下:
- 1)找到 cgroup 挂载路径:根据
/proc/self/mountinfo
中的信息,按规则解析得到 cgroup 挂载路径
- 2)各个 Subsystem 的实现:使用 Go 实现 Cgroups 配置
- 3)使用匿名管道传递参数:在父进程和子进程间使用了匿名管道来传递参数。
具体流程就是:
- 1)解析命令行参数,取到 Cgroups 相关参数
- 比如 -mem 100m 表示把内存限制到100m
- 又比如 -cpu 20 表示把 cpu 限制在 20%
- 2)根据参数,创建对应 Cgroups 并配置对应的 subsystem,最后把 fork 出来的子进程 pid 加入到这个 Cgroups 中即可。
- 1)创建 Cgroups
- 2)配置 subsystem
- 3)fork 出子进程
- 4)把子进程 pid 加入到 Cgroups 中
- 3)子进程(容器)结束时删除对于的 Cgroup
如果你对云原生技术充满好奇,想要深入了解更多相关的文章和资讯,欢迎关注微信公众号。
搜索公众号【
探索云原生
】即可订阅

最后再推荐下 cgroups 相关的几篇文章: