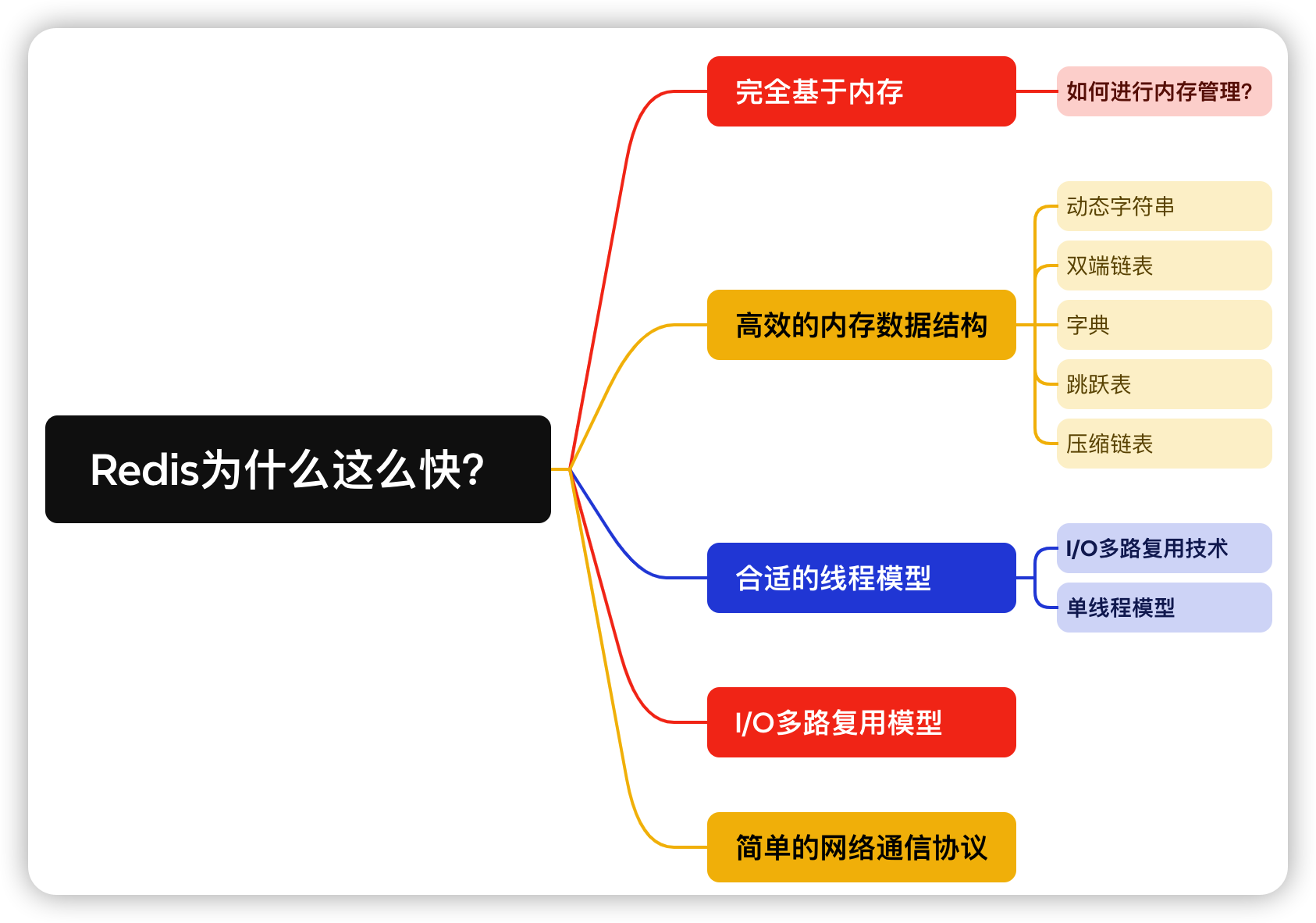
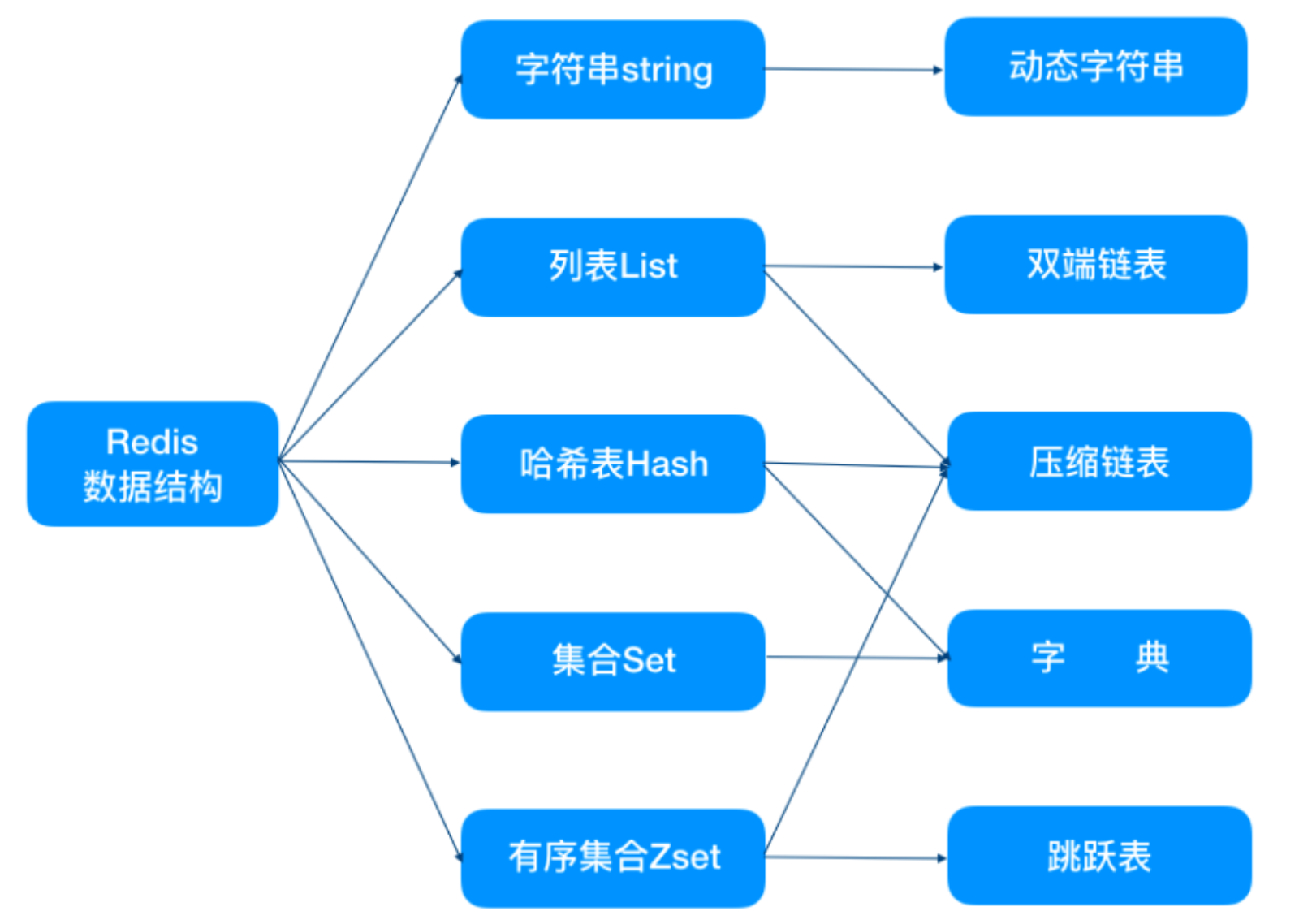
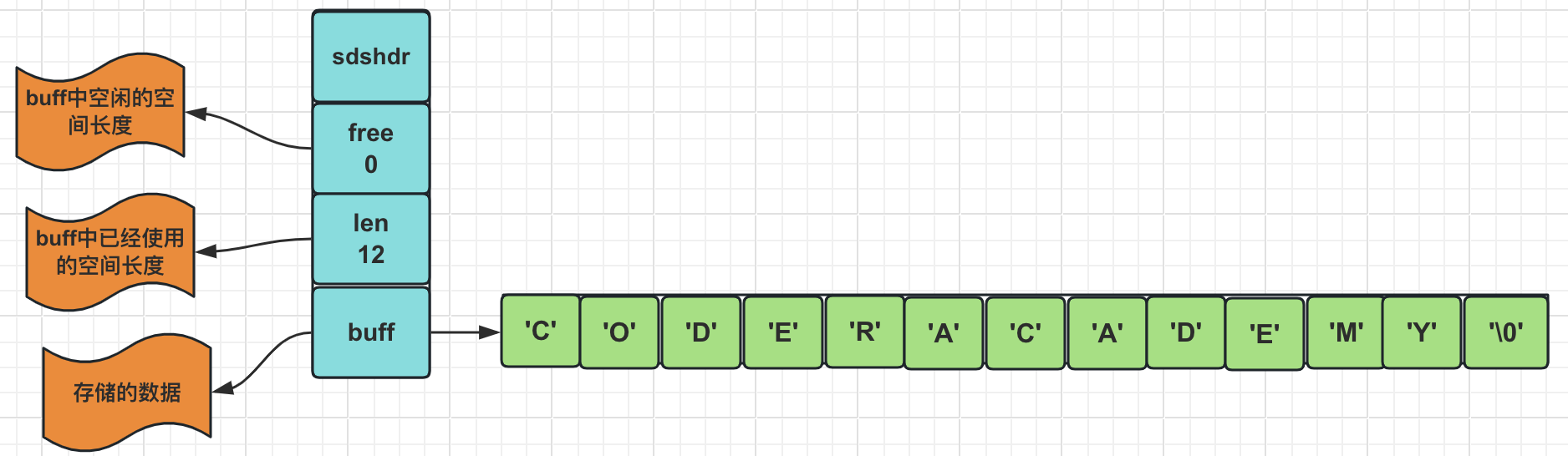
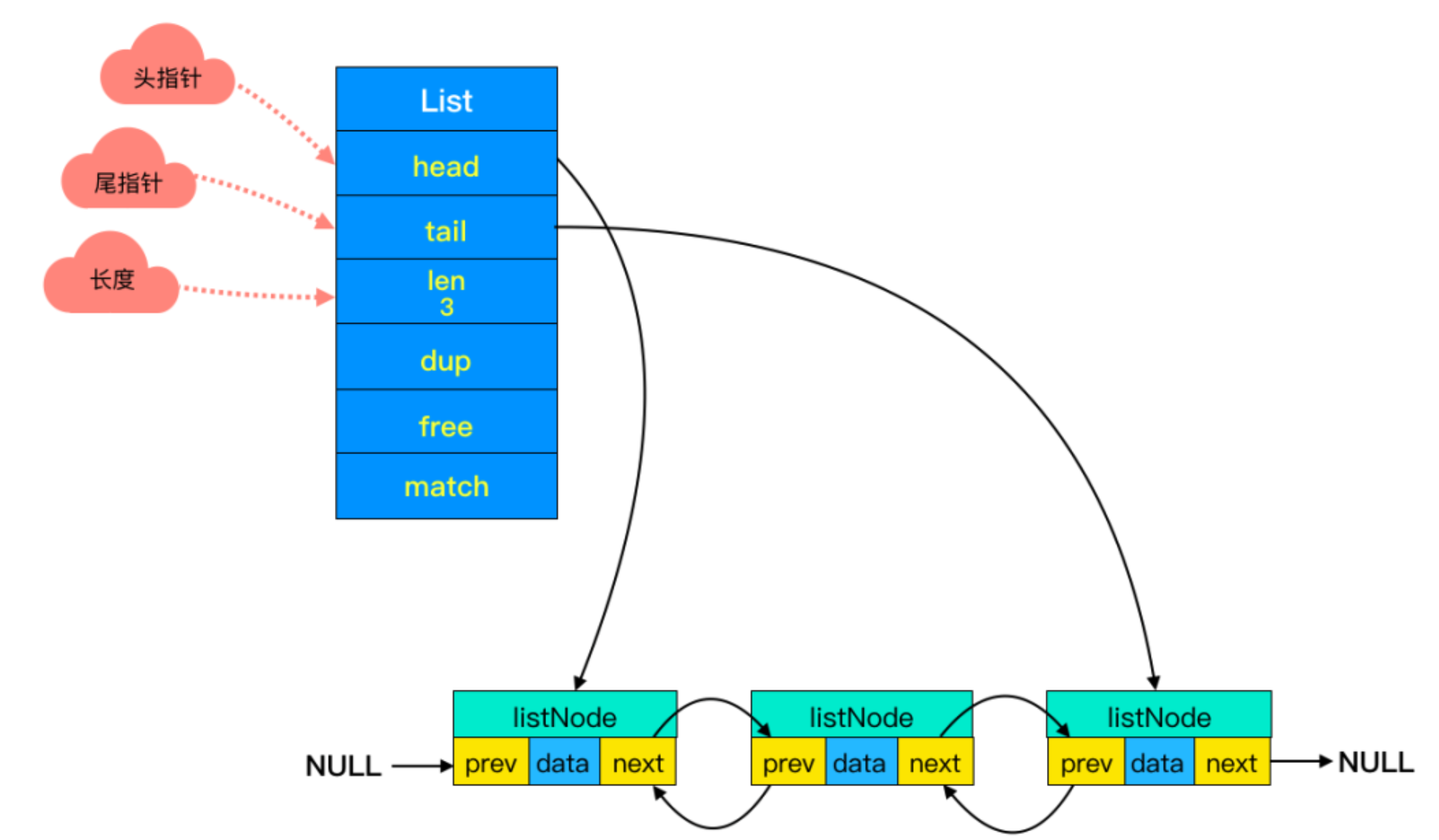
一步一步搭建,功能最全的权限管理系统之动态路由菜单(一)
一、前言
这是一篇搭建权限管理系统的系列文章。
随着网络的发展,信息安全对应任何企业来说都越发的重要,而本系列文章将和大家一起一步一步搭建一个全新的权限管理系统。
说明:由于搭建一个全新的项目过于繁琐,所有作者将挑选核心代码和核心思路进行分享。
二、技术选择

三、开始设计
1、自主搭建vue前端和.net core webapi后端,网上有很多搭建教程。
这是我搭建的
后端:
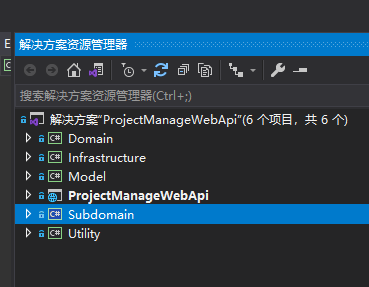
前端:
搭建好之后,vue需要把基础配置做好,比如路由、响应请求等,网上都有教程。
vue配置较为简单,webapi的框架我使用DDD领域启动设计方式,各个层的介绍如下下。
- ProjectManageWebApi webapi接口层,属于启动项
- Model 业务模型,代表着系统中的具体业务对象。
- Infrastructure 仓储层,是数据存储层,提供持久化对象的方法。
- Domain 领域层,是整个系统运行时核心业务对象的载体,是业务逻辑处理的领域。
- Subdomain 子域,子域是领域层更加细微的划分,处理整个系统最核心业务逻辑。
- Utility 工具层,存放系统的辅助工具类。
2、搭建数据库
菜单对于一个系统来说,是必不可少的,我们搭建权限管理系统就从这里开始
任务:建立菜单表,并通过程序把菜单动态加载到页面,实现树形菜单。
这是我的菜单表结构
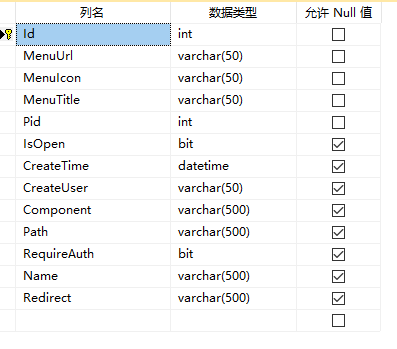
我采用的是一张表存储系统菜单,用id和pid存储上下级关系。当然这不是唯一的,根据情况可以把它拆分层多张表。
3、创建基础仓储和菜单仓储
在webapi中Infrastructure 仓储层创建基础仓储,以便提供持久化支持。
我orm框架使用的是dapper来提共数据库和编程语言间的映射关系。
首先需要建立一个增删改查的仓储接口,大致如下:


/// <summary> ///仓储接口定义/// </summary> public interfaceIRepository
{
}/// <summary> ///定义泛型仓储接口/// </summary> /// <typeparam name="T">实体类型</typeparam> /// <typeparam name="object">主键类型</typeparam> public interface IRepository<T> : IRepository where T : class, new()
{/// <summary> ///新增/// </summary> /// <param name="entity">实体</param> /// <param name="innserSql">新增sql</param> /// <returns></returns> int Insert(T entity, stringinnserSql);/// <summary> ///修改/// </summary> /// <param name="entity">实体</param> /// <param name="updateSql">更新sql</param> /// <returns></returns> int Update(T entity, stringupdateSql);/// <summary> ///删除/// </summary> /// <param name="deleteSql">删除sql</param> /// <returns></returns> int Delete(string key,stringdeleteSql);/// <summary> ///根据主键获取模型/// </summary> /// <param name="key">主键</param> /// <param name="selectSql">查询sql</param> /// <returns></returns> T GetByKey(string key, stringselectSql);/// <summary> ///获取所有数据/// </summary> /// <param name="selectAllSql">查询sql</param> /// <returns></returns> List<T> GetAll(stringselectAllSql);/// <summary> ///根据唯一主键验证数据是否存在/// </summary> /// <param name="id">主键</param> /// <param name="selectSql">查询sql</param> /// <returns>返回true存在,false不存在</returns> bool IsExist(string id, stringselectSql);/// <summary> ///dapper通用分页方法/// </summary> /// <typeparam name="T">泛型集合实体类</typeparam> /// <param name="pageResultModel">分页模型</param> /// <returns></returns> PageResultModel<T> GetPageList<T>(PageResultModel pageResultModel);
}
View Code
然后实现这个仓储接口
/// <summary> ///仓储基类/// </summary> /// <typeparam name="T">实体类型</typeparam> /// <typeparam name="TPrimaryKey">主键类型</typeparam> public abstract class Repository<T> : IRepository<T> where T : class, new()
{/// <summary> ///删除/// </summary> /// <param name="deleteSql">删除sql</param> /// <returns></returns> public int Delete(string key, stringdeleteSql)
{using var connection =DataBaseConnectConfig.GetSqlConnection();return connection.Execute(deleteSql, new { Key =key });
}/// <summary> ///根据主键获取模型/// </summary> /// <param name="id">主键</param> /// <param name="selectSql">查询sql</param> /// <returns></returns> public T GetByKey(string id, stringselectSql)
{using var connection =DataBaseConnectConfig.GetSqlConnection();return connection.QueryFirstOrDefault<T>(selectSql, new { Key =id });
}/// <summary> ///获取所有数据/// </summary> /// <param name="selectAllSql">查询sql</param> /// <returns></returns> public List<T> GetAll(stringselectAllSql)
{using var connection =DataBaseConnectConfig.GetSqlConnection();return connection.Query<T>(selectAllSql).ToList();
}/// <summary> ///新增/// </summary> /// <param name="entity">新增实体</param> /// <param name="innserSql">新增sql</param> /// <returns></returns> public int Insert(T entity, stringinnserSql)
{using var connection =DataBaseConnectConfig.GetSqlConnection();returnconnection.Execute(innserSql, entity);
}/// <summary> ///根据唯一主键验证数据是否存在/// </summary> /// <param name="id">主键</param> /// <param name="selectSql">查询sql</param> /// <returns>返回true存在,false不存在</returns> public bool IsExist(string id, stringselectSql)
{using var connection =DataBaseConnectConfig.GetSqlConnection();var count = connection.QueryFirst<int>(selectSql, new { Key =id });if (count > 0)return true;else return false;
}/// <summary> ///更新/// </summary> /// <param name="entity">更新实体</param> /// <param name="updateSql">更新sql</param> /// <returns></returns> public int Update(T entity, stringupdateSql)
{using var connection =DataBaseConnectConfig.GetSqlConnection();returnconnection.Execute(updateSql, entity);
}/// <summary> ///分页方法/// </summary> /// <typeparam name="T">泛型集合实体类</typeparam> /// <param name="pageResultModel">分页模型</param> /// <returns></returns> public PageResultModel<T> GetPageList<T>(PageResultModel pageResultModel)
{
PageResultModel<T> resultModel = new();using var connection =DataBaseConnectConfig.GetSqlConnection();int skip = 1;var orderBy = string.Empty;if (pageResultModel.pageIndex > 0)
{
skip= (pageResultModel.pageIndex - 1) * pageResultModel.pageSize + 1;
}if (!string.IsNullOrEmpty(pageResultModel.orderByField))
{
orderBy= string.Format("ORDER BY {0} {1}", pageResultModel.orderByField, pageResultModel.sortType);
}
StringBuilder sb= newStringBuilder();
sb.AppendFormat("SELECT COUNT(1) FROM {0} where 1=1 {1};", pageResultModel.tableName, pageResultModel.selectWhere);
sb.AppendFormat(@"SELECT *
FROM(SELECT ROW_NUMBER() OVER( {3}) AS RowNum,{0}
FROM {1}
where 1=1 {2}
) AS result
WHERE RowNum >= {4} AND RowNum <= {5}", pageResultModel.tableField, pageResultModel.tableName, pageResultModel.selectWhere, orderBy, skip, pageResultModel.pageIndex *pageResultModel.pageSize);using var reader =connection.QueryMultiple(sb.ToString());
resultModel.total= reader.ReadFirst<int>();
resultModel.data= reader.Read<T>().ToList();returnresultModel;
}
}
View Code
以上两段代码就实现了对数据库的增删改查。当然在上述仓储接口中有一个分页查询接口,它对于的模型如下
/// <summary> ///分页模型/// </summary> public classPageResultModel
{/// <summary> ///当前页/// </summary> public int pageIndex { get; set; }/// <summary> ///每页显示条数/// </summary> public int pageSize { get; set; }/// <summary> ///查询表字段/// </summary> public string tableField { get; set; }/// <summary> ///查询表/// </summary> public string tableName { get; set; }/// <summary> ///查询条件/// </summary> public string selectWhere { get; set; }/// <summary> ///查询条件json/// </summary> public string filterJson { get; set; }/// <summary> ///当前菜单id/// </summary> public string menuId { get; set; }/// <summary> ///排序字段(不能为空)/// </summary> public string orderByField { get; set; }/// <summary> ///排序类型/// </summary> public string sortType { get; set; }/// <summary> ///总数/// </summary> public int total { get; set; }
}/// <summary> ///查询数据/// </summary> /// <typeparam name="T"></typeparam> public class PageResultModel<T>: PageResultModel
{/// <summary> ///数据/// </summary> public List<T> data { get; set; }
}
上述代码解释:上述仓储接口中定义了所有基础接口,因为它们都是数据库操作最基本的存在,为了统一管理,降低耦合把它们定义到仓储中,以备后用。
建立好基础仓储后,我们需要建立菜单表的仓储
菜单仓储接口
/// <summary> ///菜单仓储/// </summary> public interface ISysMenuRepository : IRepository<Menu>{}
菜单仓储接口实现
/// <summary> ///菜单仓储/// </summary> public class SysMenuRepository : Repository<Menu>, ISysMenuRepository
{}
上述代码解释:可以看见上述代码继承了IRepository和Repository,这说明菜单拥有了增删改查等功能。
4、创建领域服务,递归组织树形菜单结构
在Domain领域层创建领域服务接口和实现接口
领域服务接口
/// <summary> ///菜单服务接口/// </summary> public interfaceISysMenuService
{/// <summary> ///获取所有菜单--上下级关系/// </summary> /// <returns></returns> List<MenuDao>GetAllChildren();
}
领域接口实现
/// <summary> ///菜单服务实现/// </summary> public classSysMenuService : ISysMenuService
{//仓储接口 private readonlyISysMenuRepository _menuRepository;/// <summary> ///构造函数 实现依赖注入/// </summary> /// <param name="userRepository">仓储对象</param> publicSysMenuService(ISysMenuRepository menuRepository)
{
_menuRepository=menuRepository;
}/// <summary> ///获取菜单--上下级关系/// </summary> /// <returns></returns> public List<MenuDao>GetAllChildren()
{var list =_menuRepository.GetMenusList();var menuDaoList =MenuCore.GetMenuDao(list);returnmenuDaoList;
}
}
5、在Subdomain子域中创建菜单核心代码
为什么在子域中创建菜单核心,应该菜单是整个系统的核心之一,考虑到之后系统会频繁使用,所以创建在子域中,以便提供给其他业务领域使用
下面是递归菜单实现树形结构的核心
public static classMenuCore
{#region 用于菜单导航的树形结构 /// <summary> ///递归获取菜单结构--呈现上下级关系///用于菜单的树形结构/// </summary> /// <returns></returns> public static List<MenuDao> GetMenuDao(List<Menu>menuList)
{
List<MenuDao> list = new();
List<MenuDao> menuListDto = new();foreach (var item inmenuList)
{
MenuDao model= new()
{
Title=item.MenuTitle,
Icon=item.MenuIcon,
Id= item.MenuUrl + "?MneuId=" +item.Id,
MenuKey=item.Id,
PMenuKey=item.Pid,
Component=item.Component,
Path=item.Path,
RequireAuth=item.RequireAuth,
Name=item.Name,
Redirect=item.Redirect,
IsOpen=item.IsOpen
};
list.Add(model);
}foreach (var data in list.Where(f => f.PMenuKey == 0 &&f.IsOpen))
{var childrenList =GetChildrenMenu(list, data.MenuKey);
data.children= childrenList.Count == 0 ? null: childrenList;
menuListDto.Add(data);
}returnmenuListDto;
}/// <summary> ///实现递归/// </summary> /// <param name="moduleOutput"></param> /// <param name="id"></param> /// <returns></returns> private static List<MenuDao> GetChildrenMenu(List<MenuDao> moduleOutput, intid)
{
List<MenuDao> sysShowTempMenus = new();//得到子菜单 var info = moduleOutput.Where(w => w.PMenuKey == id &&w.IsOpen).ToList();//循环 foreach (var sysMenuInfo ininfo)
{var childrenList =GetChildrenMenu(moduleOutput, sysMenuInfo.MenuKey);//把子菜单放到Children集合里 sysMenuInfo.children = childrenList.Count == 0 ? null: childrenList;//添加父级菜单 sysShowTempMenus.Add(sysMenuInfo);
}returnsysShowTempMenus;
}
}
以上便是后端实现动态菜单的核心代码,到这一节点,后端的工作基本完成。
在Controller创建好接口后,运行后端代码,出现如图所示,便说明成功。

6、vue 动态路由搭建
配置vue动态路由前,需要看你选择的前端框架是什么,不同的框架,解析的字段不一样,我选择的是layui vue,动态配置如下:
export const generator =(
routeMap: any[],
parentId:string |number,
routeItem?: any |[],
)=>{returnrouteMap//.filter(item => item.menuKey === parentId) .map(item =>{const { title, requireAuth, menuKey } = item ||{};const currentRouter: RouteRecordRaw ={//如果路由设置了 path,则作为默认 path,否则 路由地址 动态拼接生成如 /dashboard/workplace path: item.path,//路由名称,建议唯一//name: `${item.id}`,//meta: 页面标题, 菜单图标, 页面权限(供指令权限用,可去掉) meta: {
title,
requireAuth,
menuKey
},
name: item.name,
children: [],//该路由对应页面的 组件 (动态加载 @/views/ 下面的路径文件) component: item.component &&defineRouteComponentKeys.includes(item.component)?defineRouteComponents[item.component]
: ()=>url.value,
};//为了防止出现后端返回结果不规范,处理有可能出现拼接出两个 反斜杠 if (!currentRouter.path.startsWith('http')) {
currentRouter.path= currentRouter.path.replace('//', '/');
}//重定向 item.redirect && (currentRouter.redirect =item.redirect);if (item.children != null) {//子菜单,递归处理 currentRouter.children =generator(item.children, item.menuKey, currentRouter);
}if (currentRouter.children === undefined || currentRouter.children.length <= 0) {
currentRouter.children;
}returncurrentRouter;
})
.filter(item=>item);
};
View Code
通过以上代码,获取动态路由,然后把它加入到你的路由菜单中,这样便实现了页面菜单动态加载。
四、项目效果
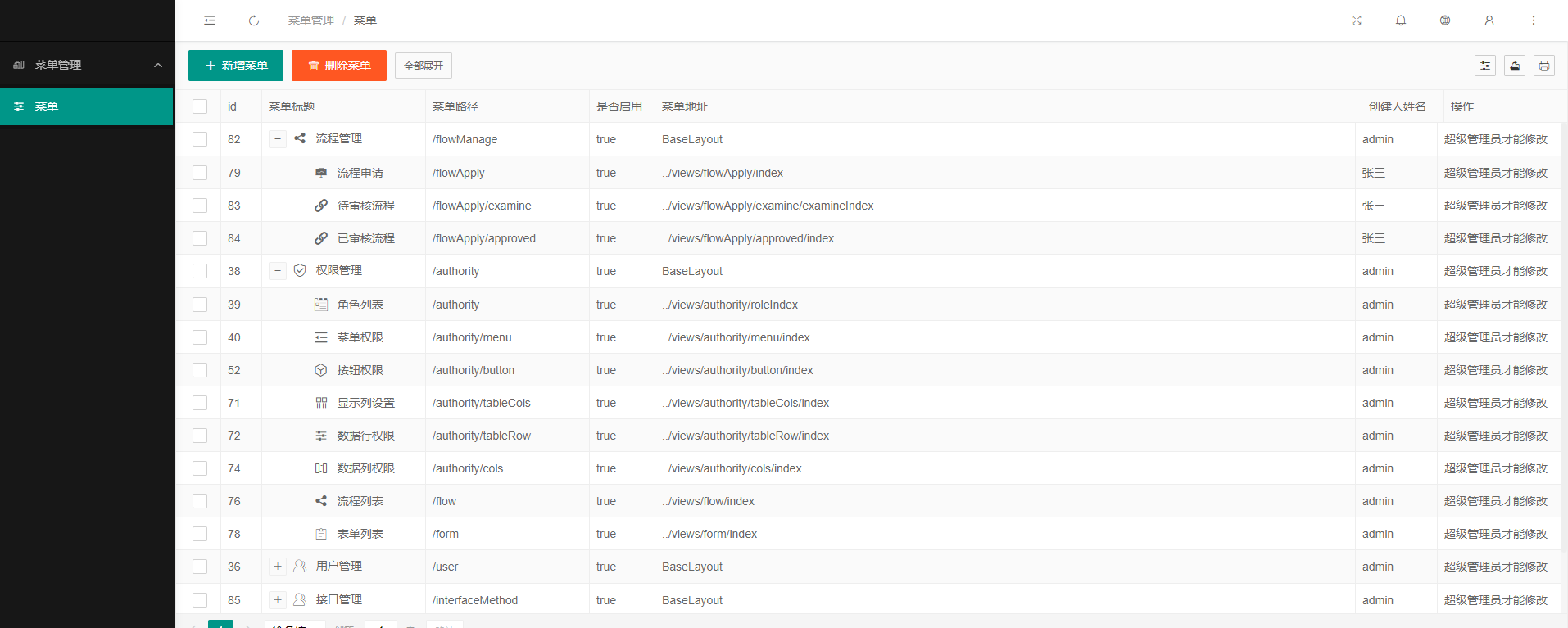
五、说明
以上便是实现vue+webapi实现动态路由的全部核心代码
注:关注我,我们一起搭建完整的权限管理系统。
1、预览地址:http://139.155.137.144:8012
2、qq群:801913255