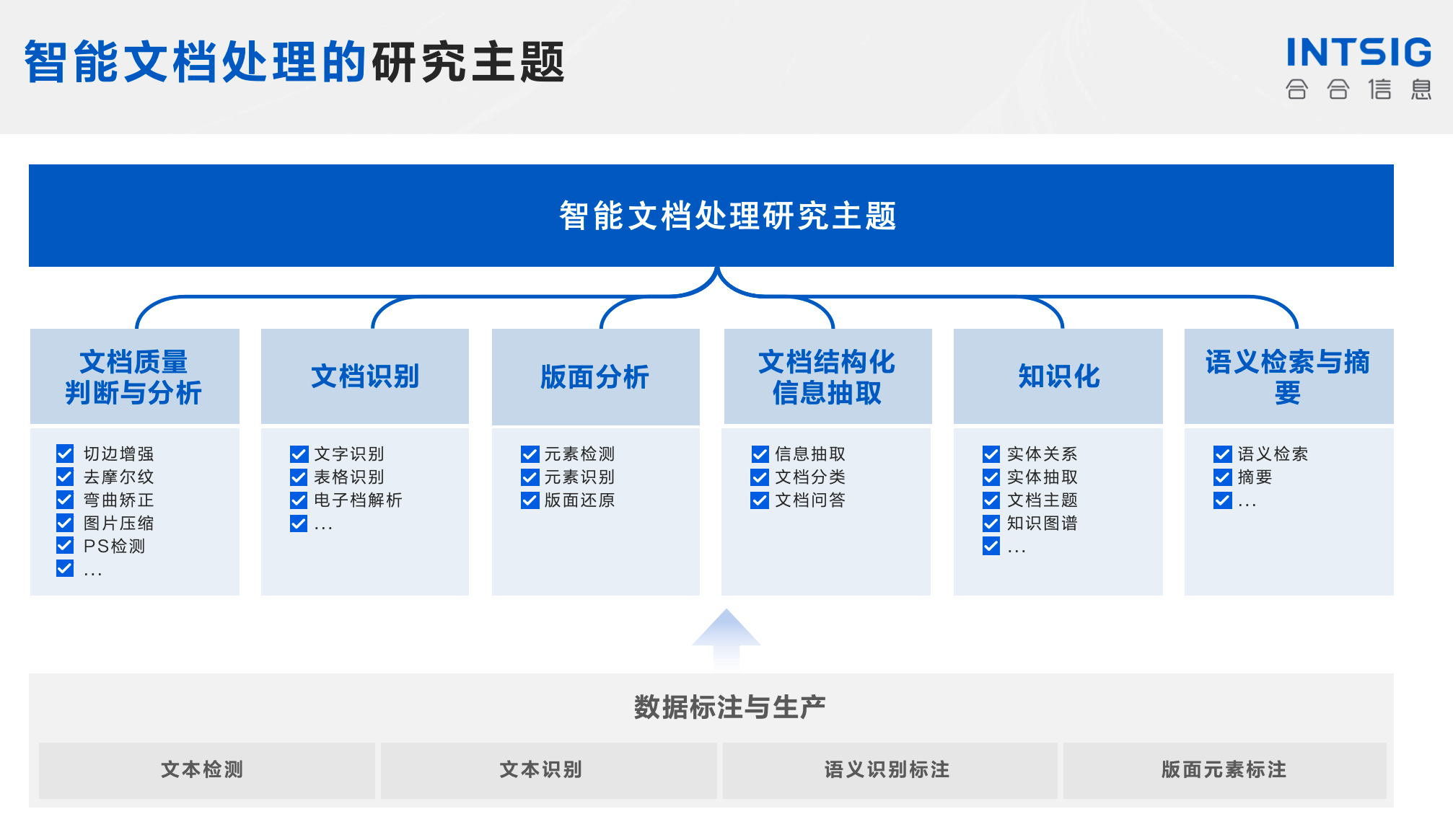
mybatis案例程序
前置工作
- 导包(mysql-connector-java、mybatis)
- 实体类
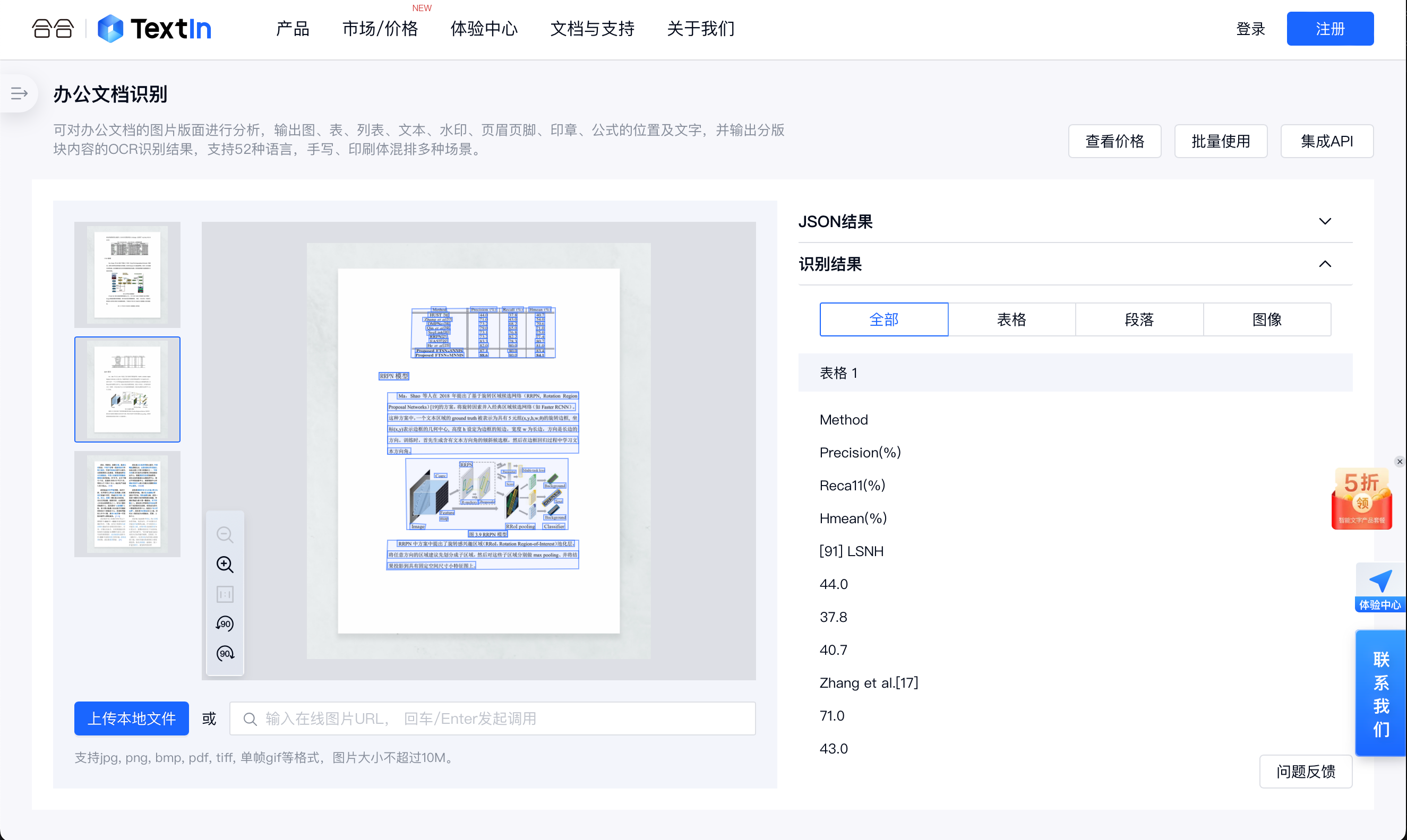
Mapper层
1.接口
public interface BookMapper {
public Book getBookById(Integer bookID);
}
2.创建Mapper的映射文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.ylzl.mapper.BookMapper">
<select id="getBookById" resultType="com.ylzl.pojo.Book">
select * from books where bookID=#{bookID}
</select>
</mapper>
Service层
可以不使用Service层,使用其他方式包含以下核心代码也可以。
核心代码
static {
String resource = "mybatis-config.xml";
try {
InputStream inputStream = Resources.getResourceAsStream(resource);
} catch (IOException e) {
e.printStackTrace();
}
}
//1.读取xml配置文件,创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory=new SqlSessionFactoryBuilder().build(inputStream);
//2.通过创建SqlSessionFactory对象获取SqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
//3.通过SqlSession对象获取代理对象mapper,传入接口class对象
BookMapper mapper=sqlSession.getMapper(BookMapper.class);
//4.通过mapper调用接口对应方法
mapper.getBookById(bookID);
以下为使用Service层实现的方式
1.接口
public interface BookService {
Book getBookById(Integer bookID);
}
2.接口实现类
(重点关注)
public class BookServiceImpl implements BookService{
static InputStream inputStream = null;
static {
String resource = "mybatis-config.xml";
try {
inputStream = Resources.getResourceAsStream(resource);
} catch (IOException e) {
e.printStackTrace();
}
}
//1.读取xml配置文件,创建SqlSessionFactory对象
private final SqlSessionFactory sqlSessionFactory
= new SqlSessionFactoryBuilder().build(inputStream);
@Override
public Book getBookById(Integer bookID) {
//2.通过创建SqlSessionFactory对象获取SqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
//3.通过SqlSession对象获取代理对象mapper,传入接口class对象,
BookMapper mapper = sqlSession.getMapper(BookMapper.class);
//4.通过mapper调用接口对应方法
return mapper.getBookById(bookID);
}
}
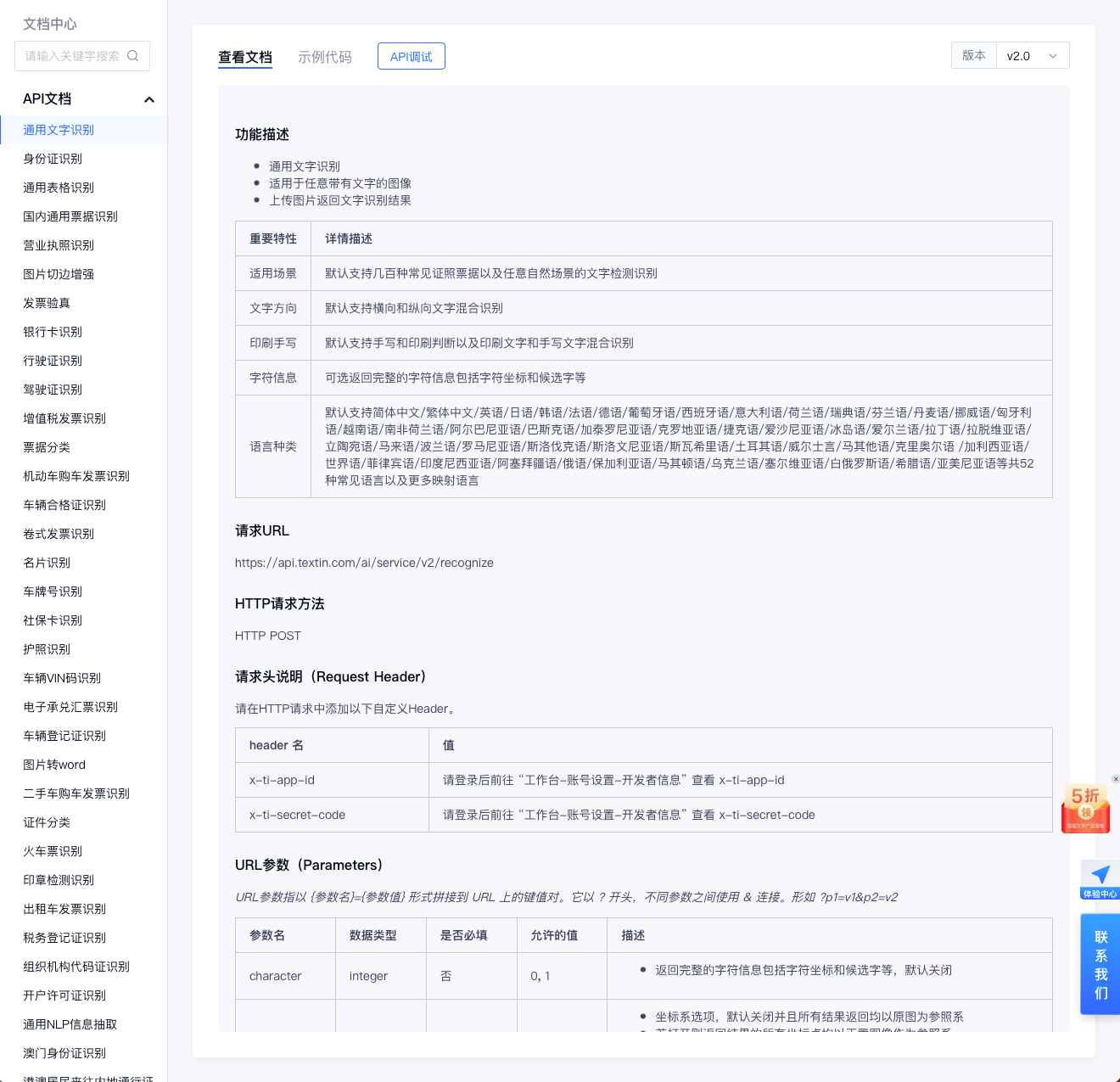
Mybatis配置文件mybatis-config.xml
(重点关注)
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<!--配置数据源-->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/ssmbuild"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<!--配置映射文件-->
<mappers>
<mapper resource="com/ylzl/mapper/BookMapper.xml"/>
</mappers>
</configuration>
测试
BookService bookServicelmpl = new BookServiceImpl();
System.out.println(bookServicelmpl.getBookById(2));
遇到的问题
1.BookMapper.xml不放在resources下,加过滤
<build>
<resources>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
</resources>
</build>
2.解决xml编码问题:1 字节的 UTF-8 序列的字节 1 无效:
https://www.cnblogs.com/thetree/p/12991403.html