【版权声明】未经博主同意,谢绝转载!(请尊重原创,博主保留追究权)
https://www.cnblogs.com/cnb-yuchen/p/18032072
出自【
进步*于辰的博客
】
纯文字阐述,内容比较干。并且,由于考虑到时间长了恐有所遗漏,便即兴记录,并没有对内容进行筛选、排序。因此,大家在阅读时可以直接 Ctrl + F 进行检索。
1、细节积累
1000 == new Integer(1000)
。
"CS" + ne w String("DN") = "CSDN"
。- protected 的限制范围是同体系(继承关系)、同包。
- 构造方法无返回值,
void
属于一种返回值类型。
- final、static、private 修饰的方法不能被重写。
- 封装的主要作用:对外隐藏内部实现细节、增强程序的安全性。
- boolean、byte 类型变量都占一个字节。
- 每个类都有各自的常量池,需要时从JVM总常量池中分配;
- 装饰模式的原理类似继承,作用是实现读写的扩展。
- 表示“空指针”是
null
,不是
NULL
。
- 进入同步代码块、
wait()
、读取输入流、降低优先级这些方法都可使线程停止。
- 接口的方法只能由
public
、
abstract
、
default
或
static
修饰,不能是
private
,因为接口不能私有化。
- 形参可以声明为
final
,只是方法内不能修改。
- $文数$指正序与倒序相同的数,如:
12321
。
- Scanner 类的
next()
获取输入以
“ ”
(空格)结尾,
nextLine()
以“
\n
”(回车)结尾。
- 无论程序多复杂,运行时都、且之会生成一个JVM进程。
default
的三个使用场景:
switch
、默认方法、自定义注解注解元素的默认值。- float 和 double 都是小数,java规定:
1.0
隐式为
1.0d
,其中的
d
是 double 的标志。因此,
float f1 = 1.0
这条语句编译报错,因为 double 所占字节数大于 float。这就是给
float
类型变量赋初值时要加
f
的原因。
- 不能作为
switch
参数的类型有:float、double、long、boolean 和复杂表达式。
- java源文件(后缀是
.java
)编译时默认使用操作系统所设定的编码进行编译。这就是为什么使用记事本编写 java 源代码可以正常编译并在 JVM 运行的原因。
- 原始 / 基本数据类型:short、int、long、char、byte、float、double、boolean。
- 若仅实例化子类,由于
this
代表的是当前实例,故当在父类中使用
this
时,
this
代表的是子类实例,而非父类实例。
- 实例化时,会先从方法区中检查构造方法是否相符(相同),再初始化成员变量和成员方法。
- 在多层 for 循环中,有时
for
前面有一个
outer:/inner:
,作用是便于控制循环,这只是一个标识,不固定。
- boolean 不能为
null
的原因:(1)、boolean 只有
true/false
两种取值;(2)、
null
表示空指针,而 boolean 是基本数据类型。
- JVM 方法区用于存放静态资源和类信息,多线程共享(线程安全)。当多线程同时使用一个类时,若此类未加载,则只有一个线程去加载类,其他线程等待。
2、一些类的使用细节
2.1 Object
- 因为 Object 类型不能作比较(
obj1 > obj2
语法不允许),故不能通过 Object 作为“上转类型”来比较不同包装类,需使用 Comparable 类代替 Object。(暂不知原因)
int
、
int[]
、
Integer
、
Integer[]
都可上转为 Object,
Integer[]
也可上转为
Object[]
,但
int[]
不可上转为
Object[]
。(暂不知原因)
2.2 String
为了标记字符串为 unicode 字符,在字符串末尾默认存在一个空格,此空格不存在于字符序列(
value
)中(即不包含在
length
中),但使用
subString()
截取字符串时,开始索引可以是
length
,能得到一个空格。
2.3 String与字符串缓冲区的区别
String是常量,不可变;字符串缓冲区(StringBuffer/StringBuilder)支持可变的字符串。当需要对字符串进行频繁操作时,两者的性能差异很大。
String 赋值的步骤:
String → StringBuffer/StringBuilder → append() → toString() → String
引用 String 类的
API
中的一张图:

2.4 基本数据类型、包装类与String三者间的转换关系
参考笔记一,P40.7。

2.5 Package
参考笔记二,P29.6。
- Java属跨平台语言,与操作系统无关,Package`是用来组织源文件的一种虚拟文件系统。
import
的作用是引入,而不是拷贝,目的是告诉编译器编译时应去哪读取外部文件。- Java的包机制与 IDE 无关。
- 同一包下的类可不使用
import
而直接调用(不是指实例化时用全类名)。
3、关于比较
3.1
==
==
是运算符,只能用于基本数据类型之间、以及相同包装类之间的比较。
3.2
equals()
所有包装类都重写了 Object 类的
equals()
,但无论
equals()
底层调用的是
toString()
、
intValue()
、还是
longValue()
,结果都是获取值,与地址无关。
当使用
equals()
比较包装类时,多用于相同包装类之间。之所以不用于不同包装类,是因为所有包装类重写的
equals()
底层都封装了类型判断,若是不同包装类,则直接返回
false
,即无法比较。
4、自动装箱与自动拆箱
所有包装类都具备自动装箱和自动拆箱机制,只是 Double、Float、Boolean 这三个包装类变量的值始终是对象。其中,Double、Float 的常量未存放在 JVM 方法区常量池的原因是浮点数无限。
如果大家想进一步了解自动装箱和自动拆箱机制,可参考博文《
[Java]基本数据类型与引用类型赋值的底层分析的小结
》的第4.2项。
6、一个关于
static
容易混淆的细节
大家先看个示例。
int a;
public static void main(String[] args) throws Exception {
C c1 = new C();// C 是类名
int i = 10;
while (i-- > 0) {
new Thread(() -> {
int n = 10000;
while (n-- > 0)
c1.a++;
}).start();
}
Thread t1 = new Thread(() -> {});
t1.start();
t1.join();
System.out.println(c1.a);
}
请问
a
的打印结果是多少,
100000
?不是,因为存在多线程并发访问。那如果把
a
改成类变量,结果是
100000
吗?仍然不是,依旧存在多线程并发访问。
不是由
static
修饰吗,为什么不是
00000
?这就是容易混淆的地方。
- 类变量属于类,为所有对象共享;
- 并发问题指线程对同一个数据的更改对其他线程不可见而导致的数据不一致问题。
所以,类变量不是为所有线程共享。
换言之,
a
必须进行同步处理(
synchronized
)。至于
a
定义为类变量、还是成员变量,看具体需求,与多线程无关。(注意下面这一点)
我突发奇想。(上面的线程在跑着)
public static void main(String[] args) throws Exception {
System.out.println(new C().a);
}
请问能获取到
a
的实时数据吗?当然不能,为什么?因为是两个 JVM。
18、关于数组定义
定义数组的4种格式:
1、int[] arr1 = new int[5];------------A
2、int arr2[] = new int[5];
3、int[] arr3 = {1, 2, 3};-------------B
4、int[] arr4 = new int[]{1, 2, 3};----C // [] 内不能指定元素个数
特例:
public static void main(String[] args) throws Exception {
print({1, 2, 3});// 编译报错
int[] arr = {1, 2, 3};
print(arr);// 打印:[1, 2, 3]
}
public static void print(int[] arr) {
System.out.println(Arrays.toString(arr));
}
若形参类型为数组,调用时不能进行数组初始化。
19、实现多接口时的细节
1
、方法 A 与 B 参数列表、返回值类型、方法名都相同时。
interface AnimalService {
void print();----------------------A
}
interface LifeService {
void print();----------------------B
}
class Person implements AnimalService, LifeService {
@Override
public void print() {--------------C // 重写A
}
}
C 重写 A 还是 B,取决于类 Person 实现接口的顺序,故 C 重写A。
2
、方法 A 与 B 仅返回值类型不同时。
interface AnimalService {
void print();----------------------A
}
interface LifeService {
int print();----------------------B
}
class Person implements AnimalService, LifeService {
@Override
public void print() {--------------C // 编译报错
}
或
@Override
public intC print() {--------------D // 编译报错
}
}
A 与 B 仅返回值类型不同,这种情形不允许,故 C、D 都编译报错。
3
、方法 A 与 B 完全不同时。
interface AnimalService {
void print();----------------------A
}
interface LifeService {
int print(int age);----------------------B
}
class Person implements AnimalService, LifeService {
@Override
public void print() {--------------C // 重写A
}
@Override
public int print(int age) {--------D // 重写B
}
}
这就是普遍实现多接口的情况,此时,C、D 也属于重载。
21、关于时间类和时间处理
21.1 Date、Calendar
Date 类倾向于
获取
时间,Calendar 类倾向于
处理
时间。
示例:获取30分钟后的时间。
Date client = new Date();// 当未指定参数时,获取当前时间
System.out.println(client);// 打印:Wed Apr 12 19:48:10 CST 2023
Calendar handler = Calendar.getInstance();// Calendar是抽象类,故需要通过调用getInstance()创建实例
handler.setTime(client);// 设置初始时间
handler.add(Calendar.MINUTE, 30);// 将初始时间增加30分钟
System.out.println(handler.getTime());// 打印:Wed Apr 12 20:18:10 CST 2023
普通的时间格式:
yyyy-MM-dd HH:mm:ss
。
有时候会是“
hh
”,区别是:前者是24小时制。
22、我误解的一个基础
问题:子类修改父类成员,通过反射获取修改前后父类成员、值未改变。
示例1
。
待反射类。
class Platform {
String name;
public void initail() {
name = "csdn";
}
}
测试代码。
Platform p1 = new Platform();
Class z1 = p1.getClass();
Field f1 = z1.getDeclaredField("name");
System.out.println(f1.get(p1));// 打印:null
p1.initail();
System.out.println(f1.get(p1));// 打印:csdn
示例2。
待反射类。
class Platform {
String name;
}
class CSDN extends Platform {
public void initail() {
name = "csdn";
}
}
测试代码。
Platform p1 = new Platform();
Class z1 = p1.getClass();
Field f1 = z1.getDeclaredField("name");
System.out.println(f1.get(p1));// 打印:null
CSDN c1 = new CSDN();
c1.initail();
System.out.println(f1.get(p1));// 打印:null------A
System.out.println(p1.name);// 打印:null---------B
System.out.println(c1.name);// 打印:csdn
这2个示例的区别在哪?前者是通过父类自身实例修改其成员变量,而后者是通过子类实例修改父类成员变量。
明明已经调用
c1.initail()
,为何A、B两处的
name
仍为
null
?
关于子类或父类初始化,详述可参考博文《
[Java]知识点
》的第5.4项。
原因很简单:假设
c1
的父类实例是
p0
(当然,实际上 Platform 类仅进行了实例初始化,未实例化),
p0
与
p1
是两个实例
。
上述只是一个基础知识,为何我觉得可作为一个细节?
下述代码是我研究 ArrayList
<E>
类的迭代器
Itr
和子迭代器
ListItr
时的一个示例。
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
Iterator<Integer> it = list.iterator();
Class z1 = Class.forName("java.util.ArrayList$Itr");
Field f1 = z1.getDeclaredField("expectedModCount");
f1.setAccessible(true);
System.out.println(f1.get(it));// 打印:3------A
ListIterator<Integer> lit = list.listIterator();
lit.add(4);
System.out.println(f1.get(it));// 打印:3------B
lit.add(5);
System.out.println(f1.get(it));// 打印:3------C
it.next();// 抛出:ConcurrentModificationException
关于
expectedModCount
,见
ArrayList
<E>
类
的第7.1项。
由于之前调用了3次
add()
,故A处的值为
3
。同理,B、C两处的值应分别为
4
、
5
,可实际都是
3
。
PS
:我被潜意识误导了,即原因所在。
23、大家可能无意中避过的一个坑
相信大家都写过这么一段代码:
String str;
if (str != null && str.equals("")) {}
并且,可能自己领悟,或者他人指点,一般会这么写:
String str;
if (str != null && "".equals(str)) {}
因为这样可以避免
空指针异常
。
其实,这两种写法并没有什么区别,用第二种纯粹是个人习惯或者是一种规范,我也是如此。
曾经我有一个疑惑:“第一种写法中同样会执行
str.equals()
,它是如何规避空指针异常的?”
由于这看起来只是一个细节,而且不影响敲代码,也就没关注。然而今天看源码,就碰到了这么一段判断:
if (useCaches &&
reflectionData != null &&
(rd = reflectionData.get()) != null &&
rd.redefinedCount == classRedefinedCount) {}
四个 boolean,这若是无法确定每个 boolean,还如何解析?这就让我想起了开头说的例子。其实,我们并不需要确认所有的 boolean,听我细细道来。。。
这就要涉及运算符
&&
与
||
的运算规则了,为了研究这个问题,翻了一些资料。果然,这两种运算符实在太基础了,没遇到我需要的,只能自己
debug
了。。。
看下述测试。
1
、测试
&&
。

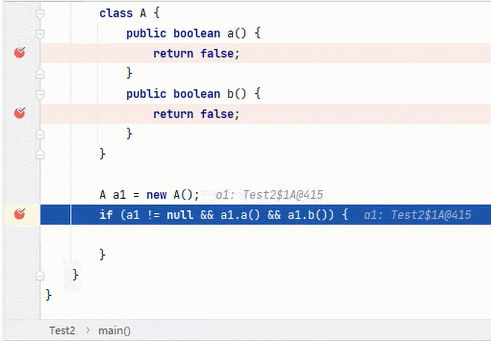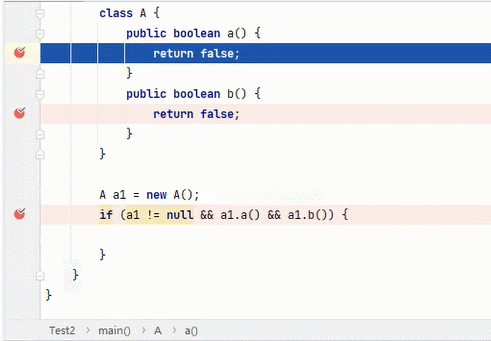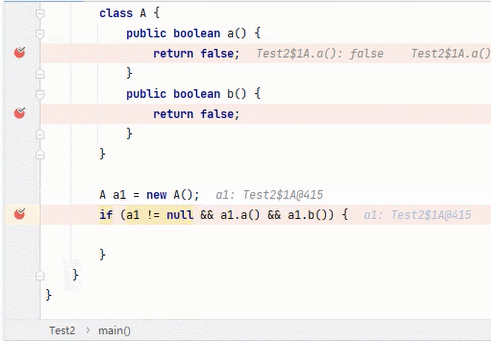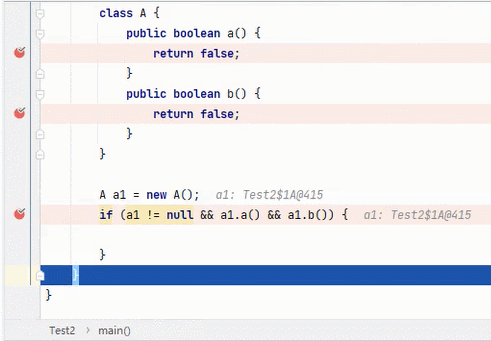

&&
结果为 true,要求每一段都为 true。从左往右逐个执行,若前面为 false,结果则为 false,后面就不会再执行;若前面为 true,则继续判断后面。(这就是开头我说那两种写法并没有区别的原因)
2
、测试
||
。
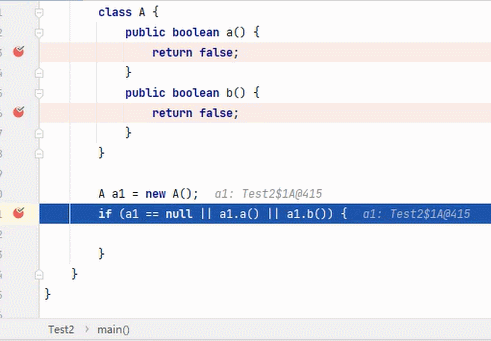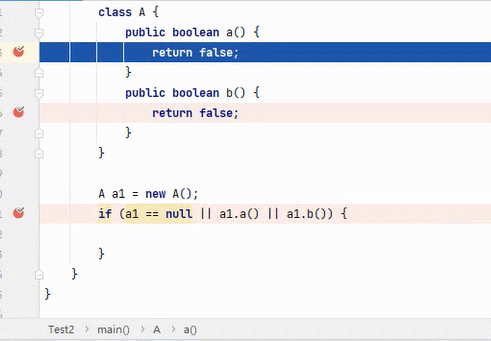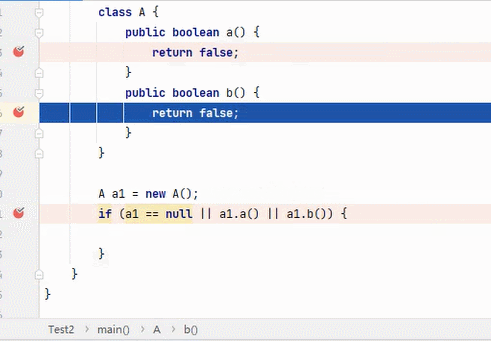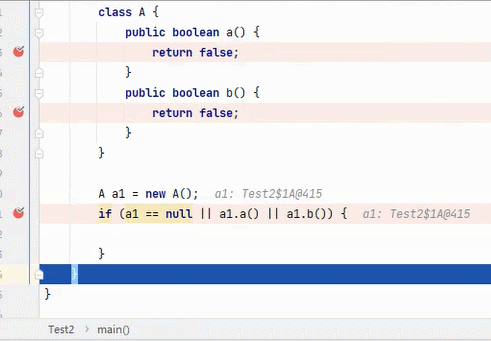
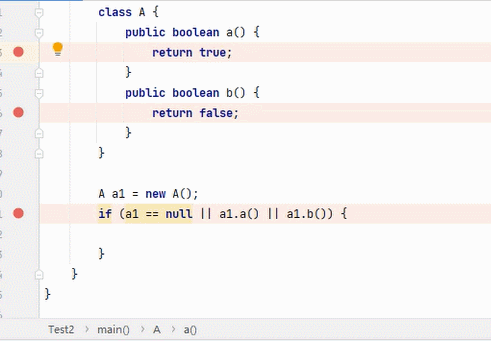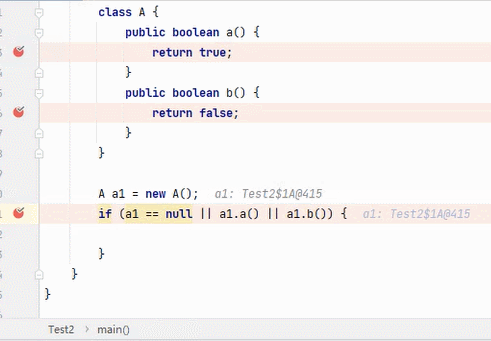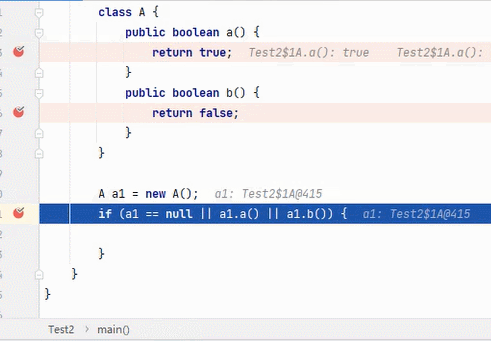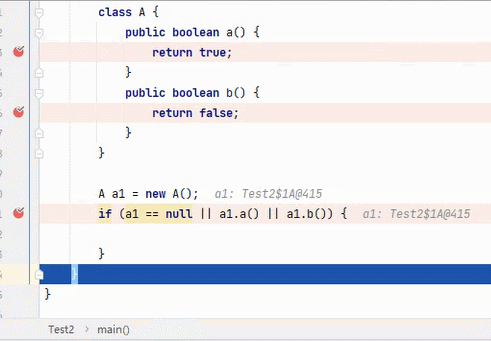
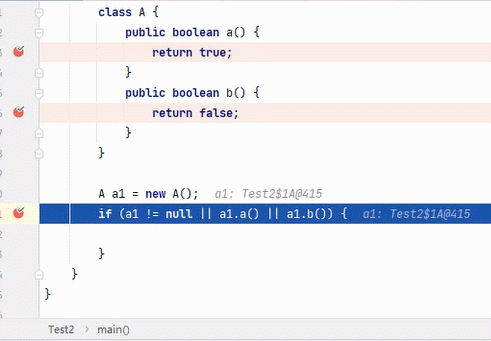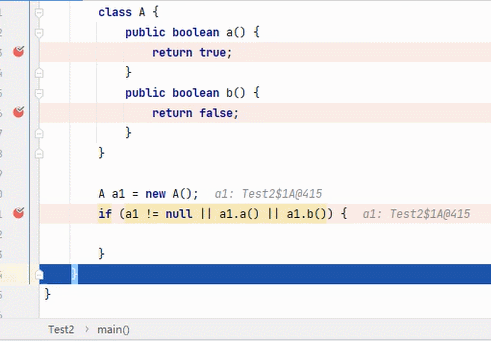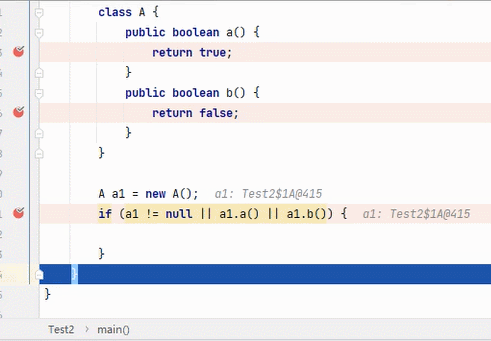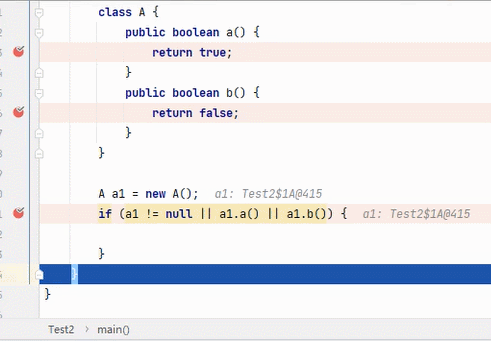
||
结果为 true,要求其中一段为 true 即可。从左往右逐个执行,若前面为 true,结果则为 true,后面就不会再执行;若前面为 false,则继续判断后面。
PS
:看到这6张不断播放的图片以及这绕口的说明,我自己都有点晕。。。大家可以根据图片自行理解。
补充一点:
String str;
if ("".equals(str)) {}
请问这样可以避免空指针异常吗?答案是不能,因为下述代码会抛出空指针异常:
Object anObject = null;
if(anObject instanceof String) {}
可能大家不明白我的意思,如果大家感兴趣,可以去看看
equals()
的源码。
直通车 ->
String类
的第2.14项。
24、关于程序与数据库之间数据类型转换说明(基于JDBC)
24.1 数据存储(DML)
- String → DateTime,需使用类java.sql.Timestamp。
24.2 数据查询(select)
- DateTime → String,先通过
rs.getTimestamp()
(rs是结果集ResultSet对象)获取Timestamp对象,再使用SimpleDateFormat类将其转为String。
最后
如果大家想要了解一些Java知识点,可查阅博文《
[Java]知识点
》。
本文持续更新中。。。