麒麟系统修改网卡名步骤和网卡占用故障处理
第1章 单网卡环境修改网卡名
■ 修改网卡配置。
• 检查当前网卡名称和MAC
地址,网卡名称
ens
33
,
M
AC地址00:0c:29:ab:3a:40。
[root@localhost ~]# ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet127.0.0.1/8scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128scope host
valid_lft forever preferred_lft forever2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000link/ether 00:0c:29:ab:3a:40brd ff:ff:ff:ff:ff:ff
inet192.168.1.161/24 brd 192.168.1.255scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::588d:c898:3370:2cca/64scope link noprefixroute
valid_lft forever preferred_lft forever
• 修改网卡的配置文件名称。
[root@localhost ~]# cd /etc/sysconfig/network-scripts/[root@localhost network-scripts]# mv ifcfg-ens33 ifcfg-eth0
• 修改网卡配置内容,将网卡和绑定设备名改成eth0,其他不用修改。
[root@localhost network-scripts]# vi ifcfg-eth0
NAME=eth0
DEVICE=eth0
[root@localhost network-scripts]#
■ 修改BIOS参数。
• 更新内核文件,于"GRUB_CMDLINE_LINUX="行尾额外添加"net.ifnames=0 biosdevname=0"两条参数。
[root@localhost ~]# vi /etc/default/grub
GRUB_CMDLINE_LINUX="resume=/dev/mapper/klas-swap rd.lvm.lv=klas/root rd.lvm.lv=klas/swap rhgb quiet crashkernel=1024M,high audit=0 net.ifnames=0 biosdevname=0"
• 检查系统引导启动方式。
[root@localhost ~]# ll /sys/firmware/efils: cannot access '/sys/firmware/efi': No such fileor directory
[root@localhost~]# dmesg | grep "EFI v"[root@localhost~]#
说明:
一般系统有
U
EFI
和传统
B
IOS两种引导启动方式,如上述命令中,没有/sys/firmware/efi
文件,并且
dmesg命令没有E
FI
关键词输出,说明当前系统是传统
B
IOS
方式引导启动;如果有目录和关键词输出,说明是
U
EFI启动。
• 重新生成内核引导文件。
[root@localhost ~]# grub2-mkconfig -o /boot/grub2/grub.cfg
#执行成功输出如下:
Generating grub configurationfile...
Found linux image:/boot/vmlinuz-4.19.90-52.22.v2207.ky10.x86_64
Found initrd image:/boot/initramfs-4.19.90-52.22.v2207.ky10.x86_64.img
Found linux image:/boot/vmlinuz-0-rescue-c30be0c3a35649f1b686342f9354e4aa
Found initrd image:/boot/initramfs-0-rescue-c30be0c3a35649f1b686342f9354e4aa.imgdone注意:如果系统引导启动方式是UEFI,那么不能在/boot/grub2目录下生成内核引导文件,需要执行命令:“grub2-mkconfig -o /boot/efi/EFI/kylin/grub.cfg”,将内核文件生成到/boot/efi/EFI/kylin/下才能生效。
■ 修改udev,配置网卡名和MAC地址绑定。
• 注释第一行,并手动添加一行,通过网卡MAC
地址绑定
eth
0网卡名。
• [root@localhost ~]# vi /usr/lib/udev/rules.d/60-net.rules
#ACTION=="add", SUBSYSTEM=="net", DRIVERS=="?*", ATTR{type}=="1", PROGRAM="/lib/udev/rename_device", RESULT=="?*", NAME="$result"ACTION=="add", SUBSYSTEM=="net", DRIVERS=="?*", ATTR{type}=="1", ATTR{address}=="00:0c:29:ab:3a:40", NAME="eth0"
■ 验证修改结果。
• 重启系统后配置生效。
[root@localhost ~]# reboot
• 检查网卡,成功将网卡名修改为eth0。
[root@localhost ~]# ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet127.0.0.1/8scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128scope host
valid_lft forever preferred_lft forever2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000link/ether 00:0c:29:ab:3a:40brd ff:ff:ff:ff:ff:ff
inet192.168.1.161/24 brd 192.168.1.255scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::3445:a251:8e9:8c84/64scope link noprefixroute
valid_lft forever preferred_lft forever
第2章 多网卡环境修改网卡名
说明:
多网卡修改网卡名的步骤和单网卡步骤一致,不同点是
udev配置文件中需要加多行参数,对所有网卡名和网卡M
AC地址进行绑定。
■ 修改网卡配置。
• 检查当前网卡名称和MAC
地址,当前有
ens
33
、
ens3
7
、
ens3
8
,共
3块网卡。
[root@localhost network-scripts]# ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet127.0.0.1/8scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128scope host
valid_lft forever preferred_lft forever
2: ens33
: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:ab:3a:40 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.161/24 brd 192.168.1.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::588d:c898:3370:2cca/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: ens37
: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:ab:3a:4a brd ff:ff:ff:ff:ff:ff
inet 192.168.1.162/24 brd 192.168.1.255 scope global noprefixroute ens37
valid_lft forever preferred_lft forever
inet6 fe80::7820:36ad:e6f7:59c9/64 scope link noprefixroute
valid_lft forever preferred_lft forever
4: ens38
: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:ab:3a:54 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.163/24 brd 192.168.1.255 scope global noprefixroute ens38
valid_lft forever preferred_lft forever
inet6 fe80::f4e9:65e6:f38d:cba3/64 scope link noprefixroute
valid_lft forever preferred_lft forever
• 修改网卡的配置文件名称。
[root@localhost ~]# cd /etc/sysconfig/network-scripts/[root@localhost network-scripts]# mv ifcfg-ens33 ifcfg-eth0
[root@localhost network-scripts]# mv ifcfg-ens37 ifcfg-eth1
[root@localhost network-scripts]# mv ifcfg-ens38 ifcfg-eth2
• 修改网卡配置内容,将网卡和绑定设备名改成ethxx。
[root@localhost network-scripts]# vi ifcfg-eth0
NAME=eth0
DEVICE=eth0
[root@localhost network-scripts]# vi ifcfg-eth1
NAME=eth1
DEVICE=eth1
[root@localhost network-scripts]# vi ifcfg-eth2
NAME=eth2
DEVICE=eth2
[root@localhost network-scripts]#
修改
B
IOS参数。
• 更新内核文件,于"GRUB_CMDLINE_LINUX="行尾额外添加"net.ifnames=0 biosdevname=0"两条参数。
[root@localhost ~]# vi /etc/default/grub
GRUB_CMDLINE_LINUX="resume=/dev/mapper/klas-swap rd.lvm.lv=klas/root rd.lvm.lv=klas/swap rhgb quiet crashkernel=1024M,high audit=0 net.ifnames=0 biosdevname=0"
• 检查系统引导启动方式。
[root@localhost ~]# ll /sys/firmware/efils: cannot access '/sys/firmware/efi': No such fileor directory
[root@localhost~]# dmesg | grep "EFI v"[root@localhost~]#
说明:
一般系统有UEFI和传统BIOS两种引导启动方式,如上述命令中,没有/sys/firmware/efi文件,并且dmesg命令没有EFI关键词输出,说明当前系统是传统BIOS方式引导启动;如果有目录和关键词输出,说明是UEFI启动。
• 重新生成内核引导文件。
[root@localhost ~]# grub2-mkconfig -o /boot/grub2/grub.cfg
#执行成功输出如下:
Generating grub configurationfile...
Found linux image:/boot/vmlinuz-4.19.90-52.22.v2207.ky10.x86_64
Found initrd image: /boot/initramfs-4.19.90-52.22.v2207.ky10.x86_64.img
Found linux image: /boot/vmlinuz-0-rescue-c30be0c3a35649f1b686342f9354e4aa
Found initrd image: /boot/initramfs-0-rescue-c30be0c3a35649f1b686342f9354e4aa.img
done
注意:
如果系统引导启动方式是
U
EFI
,那么不能在
/
boot/grub2
目录下生成内核引导文件,需要执行命令:
“
grub2-mkconfig -o /boot/efi/EFI/kylin/grub.cfg”,将内核文件生成到/boot/efi/EFI/kylin/下才能生效。
■ 修改udev,配置网卡名和MAC地址绑定。
• 注释第一行,并手动添加3行,通过网卡MAC
地址绑定
ethxx网卡名。
• [root@localhost ~]# vi /usr/lib/udev/rules.d/60-net.rules
#ACTION=="add", SUBSYSTEM=="net", DRIVERS=="?*", ATTR{type}=="1", PROGRAM="/lib/udev/rename_device", RESULT=="?*", NAME="$result"ACTION=="add", SUBSYSTEM=="net", DRIVERS=="?*", ATTR{type}=="1", ATTR{address}=="00:0c:29:ab:3a:40", NAME="eth0"ACTION=="add", SUBSYSTEM=="net", DRIVERS=="?*", ATTR{type}=="1", ATTR{address}=="00:0c:29:ab:3a:4a", NAME="eth1"ACTION=="add", SUBSYSTEM=="net", DRIVERS=="?*", ATTR{type}=="1", ATTR{address}=="00:0c:29:ab:3a:54", NAME="eth2"
■ 验证修改结果。
• 重启系统后配置生效。
[root@localhost ~]# reboot
• 检查网卡,成功将网卡名修改为ethx。
[root@localhost ~]# ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet127.0.0.1/8scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128scope host
valid_lft forever preferred_lft forever2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000link/ether 00:0c:29:ab:3a:40brd ff:ff:ff:ff:ff:ff
inet192.168.1.161/24 brd 192.168.1.255scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::3445:a251:8e9:8c84/64scope link noprefixroute
valid_lft forever preferred_lft forever3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000link/ether 00:0c:29:ab:3a:4a brd ff:ff:ff:ff:ff:ff
inet192.168.1.162/24 brd 192.168.1.255scope global noprefixroute eth1
valid_lft forever preferred_lft forever
inet6 fe80::6812:c44f:ab83:9d8a/64scope link noprefixroute
valid_lft forever preferred_lft forever4: eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000link/ether 00:0c:29:ab:3a:54brd ff:ff:ff:ff:ff:ff
inet192.168.1.163/24 brd 192.168.1.255scope global noprefixroute eth2
valid_lft forever preferred_lft forever
inet6 fe80::5534:cbf5:8f66:963e/64scope link noprefixroute
valid_lft forever preferred_lft forever
第3章 网卡名故障处理
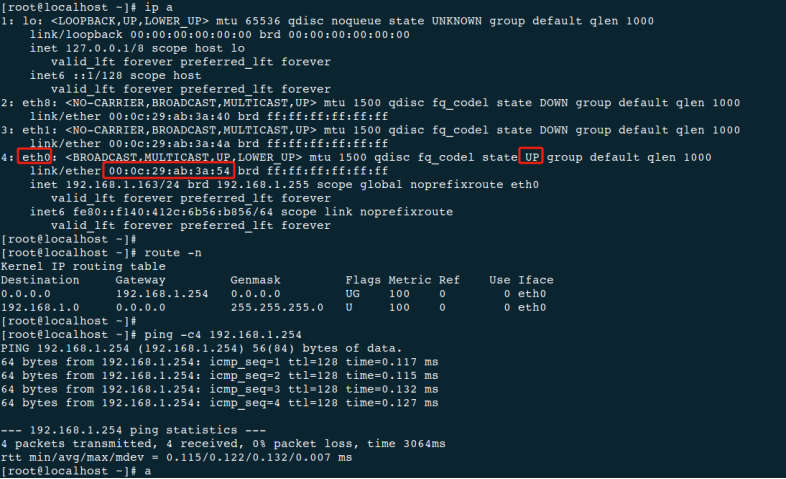
■ 说明:本故障处理方案适用于多网卡环境下,仅为某个或某几个网卡修改网卡名称。
1.1、 现象描述
■
需求:当前系统部署
k8s集群,需要k8s集群中所有节点网卡名称统一为eth
0
,虽然系统中有多块网卡,但是只有最后一块网卡是
U
P
状态,现在需要将最后一块网卡名更改为
eth
0。
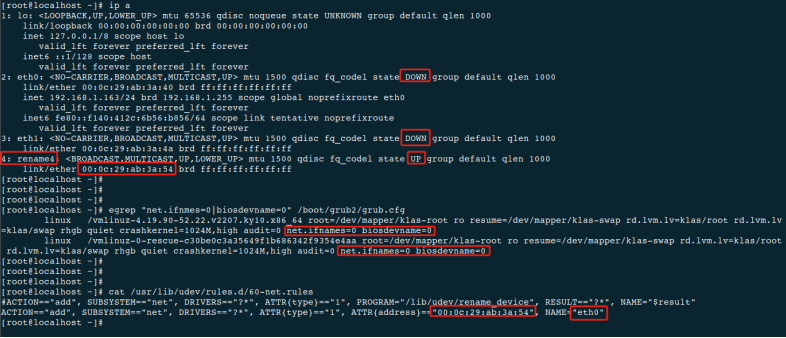
■
问题现象:如下图所示,在
udev中将最后一块网卡名称更改为eth
0
,重启后网卡名变成了
rename
4,并且IP
地址在
D
OWN的网卡上,导致网络不通。
1.2、 问题分析
■
因为内核参数中增加了
“
net.ifnames=0 biosdevname=0
”
,重启系统生效后会自动分配
ethx的名称给每一块网卡,当前eth
0
名称已经被第一块网卡占用,所以修改
udev后会发生冲突,导致最后一块网卡名变为rename
4。
1.3、 解决思路
先将第一块网卡名通过
udev改名,如改成eth
8
,解决
eth
0
名称占用问题;再将
rename
4
网卡名改成
eth
0,恢复网络故障。
1.4、 处理步骤
• 将第一块网卡名称修改为eth8
,使用第一块网卡的
M
AC
地址修改网卡名,修改
udev需要重启系统生效。
[root@localhost ~]# vi /usr/lib/udev/rules.d/60-net.rules
#ACTION=="add", SUBSYSTEM=="net", DRIVERS=="?*", ATTR{type}=="1", PROGRAM="/lib/udev/rename_device", RESULT=="?*", NAME="$result"ACTION=="add", SUBSYSTEM=="net", DRIVERS=="?*", ATTR{type}=="1", ATTR{address}=="00:0c:29:ab:3a:40", NAME="eth8"[root@localhost~]# reboot
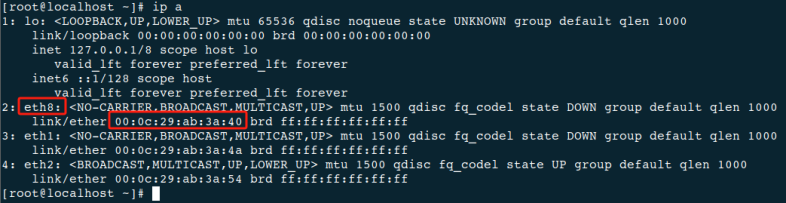
重启后如下图,第一块网卡名更改为
eth
8:
将rename4
网卡名称修改为
eth
0
,并检查网卡配置文件
N
AME
和
D
EVICE
是否为
eth
0。
[root@localhost ~]# vi /usr/lib/udev/rules.d/60-net.rules
#ACTION=="add", SUBSYSTEM=="net", DRIVERS=="?*", ATTR{type}=="1", PROGRAM="/lib/udev/rename_device", RESULT=="?*", NAME="$result"ACTION=="add", SUBSYSTEM=="net", DRIVERS=="?*", ATTR{type}=="1", ATTR{address}=="00:0c:29:ab:3a:40", NAME="eth8"ACTION=="add", SUBSYSTEM=="net", DRIVERS=="?*", ATTR{type}=="1", ATTR{address}=="00:0c:29:ab:3a:54", NAME="eth0"
[root@localhost ~]# cat /etc/sysconfig/network-scripts/ifcfg-eth0
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=none
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=eth0
DEVICE=eth0
ONBOOT=yes
IPADDR=192.168.1.163NETMASK=255.255.255.0GATEWAY=192.168.1.254[root@localhost~]# reboot
•
验证故障恢复,如下图所示,状态为
U
P
的网卡更改为
eth
0,并恢复网络故障。