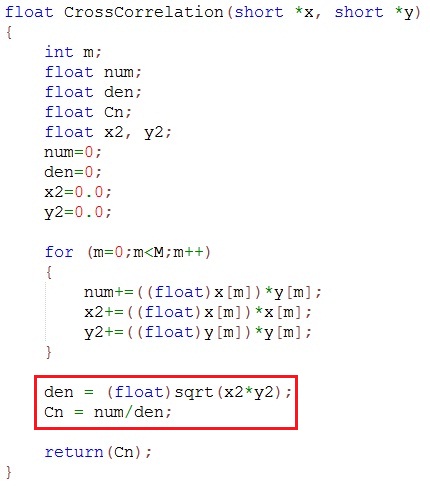
一文搞懂idea中的根目录和路径(以Mybatis为例)
1.根目录概念:
1.1 项目根目录(Project Root)
- 项目根目录是你在文件系统中为整个项目选择的顶层目录。
- 它通常包含了项目的所有内容,包括源代码、构建配置文件、文档、测试文件等。
- 在版本控制系统中(如 Git),项目根目录通常是仓库的根目录。
1.2 内容根目录(Content Root)
- 在 IntelliJ IDEA 或其他 JetBrains IDE 中,内容根目录指的是一个模块(Module)的文件系统根目录。
- 它通常包含该模块的源代码、资源文件、测试代码等。
- 内容根目录是相对于 IntelliJ IDEA 项目而言的,并不等同于文件系统上的项目根目录。
- 一个项目可以包含多个模块,每个模块可以有自己的内容根目录。
1.3
两者的关系
:
- 项目根目录是一个更大的概念,它包含了整个项目的所有内容。
- 内容根目录是 IntelliJ IDEA 中模块级别的概念,它位于项目根目录之下,并包含模块特定的文件和目录结构。
1.4 示例
假设你有一个名为
MyProject
的项目,该项目包含两个模块:
CoreModule
和
WebModule
。在本地硬盘上,
MyProject
的根目录可能看起来像这样:
MyProject/ //项目根目录
|-- .idea/
|-- CoreModule/ //模块内容根目录(Content Root)
| |-- src/
| | |-- main/
| | | |-- java/ (CoreModule 的源代码)
| | | |-- resources/ (CoreModule 的资源文件)
| |-- test/
| |-- CoreModule.iml
|-- WebModule/ //模块内容根目录(Content Root)
| |-- src/
| | |-- main/
| | | |-- java/ (WebModule 的源代码)
| | | |-- resources/ (WebModule 的资源文件)
| |-- test/
| |-- WebModule.iml
|-- MyProject.iml
在这个例子中,
MyProject
是项目根目录,而
CoreModule
和
WebModule
则分别有自己的内容根目录。每个模块的内容根目录下进一步细分了源代码目录、测试代码目录和资源文件目录,在 Maven 构建工具的项目结构中,这些目录通常会被自动标记为
源根目录
1.5 总结:
通过 IntelliJ IDEA 的项目结构设置,你可以轻松地管理这些目录和它们的依赖关系,从而确保项目的构建和运行符合预期。
2. 路径概念:
2.1 首先,我们回顾一下
目录
概念:
- 项目根目录(Project Root)
项目根目录是整个项目在本地硬盘上的顶层目录。它包含了项目所需的所有文件和子目录,如源代码、构建文件、配置文件等。在 IntelliJ IDEA 中,当你打开一个项目时,这个项目根目录就是你在文件系统中选择的目录。 - 内容根目录(Content Root)
内容根目录是存储模块文件(如源代码、资源等)的目录。在 IntelliJ IDEA 中,每个模块(Module)可以有自己的 Content Root。Content Root 是模块层次结构中的顶层目录,它包含了该模块的所有相关文件和子目录。 - 源根目录(Source Root)
源根目录(Source Root):Source Root
是 Content Root 下的一个特殊类型
的目录。在 IntelliJ IDEA 中,一个 Content Root 下可以有多个 Source Root,它们可以有不同的类型,如
src
、
test
、
resources
等,用于区分不同类型的源代码或资源文件。
在实际的 MyBatis 项目中,源代码(如 Java 类)通常放在
src/main/java
目录下,而 MyBatis 的映射文件(如
.xml
文件)通常放在
src/main/resources
目录下。这两个目录都是源根目录,但它们存放的文件类型不同。在 IntelliJ IDEA 中,你可以通过模块设置来配置这些源根目录。
2.2 接下来,我们讨论
路径
概念:
- 内容根路径(path from content root)
:这是从内容根目录到特定文件的路径。例如,如果
src
是 Content Root,那么
src/main/resources/com/itheima/mapper/UserMapper.xml
就是相对于 Content Root 的路径。 - 源根路径(path from source root)
:这是从源根目录到特定文件的路径。对于 MyBatis 的映射文件,它们通常存放在资源目录(如
src/main/resources
)下,该目录被标记为 Source Root。因此,
com/itheima/mapper/UserMapper.xml
就是相对于该 Source Root 的路径。
2.3 MyBatis 示例
假设你有一个基于 Maven 的 MyBatis 项目,其结构如下:
MyBatisProject/ (项目根目录)
|-- .idea/
|-- pom.xml
|-- src/ (Content Root)
| |-- main/
| | |-- java/ (Source Root for Java sources)
| | | |-- com/
| | | |-- itheima/
| | | |-- mapper/
| | | |-- UserMapper.java
| | |-- resources/ (Source Root for resources)
| | |-- com/
| | |-- itheima/
| | |-- mapper/
| | |-- UserMapper.xml
|-- MyBatisProject.iml (项目模块文件)
在这个例子中:
- 项目根目录
是
MyBatisProject/
。 - 内容根目录
是
src/
,它包含了项目的所有源代码和资源文件。 - 源根目录
有两个:
src/main/java/
用于 Java 源代码,
src/main/resources/
用于资源文件(如 MyBatis 映射文件)。 - 内容根路径
(对于
UserMapper.xml
)是
src/main/resources/com/itheima/mapper/UserMapper.xml
。 - 源根路径
(对于
UserMapper.xml
)是
com/itheima/mapper/UserMapper.xml
,这是从
src/main/resources/
这个源根目录开始的相对路径。
在 MyBatis 的配置中,你通常会使用源根路径来引用映射文件。例如,在
mybatis-config.xml
文件中:
<configuration>
<mappers>
<mapper resource="com/itheima/mapper/UserMapper.xml"/>
</mappers>
</configuration>
这里的
resource
属性期望的是相对于类路径(classpath)的资源路径,这通常与源根路径相对应。当 IntelliJ IDEA 构建项目时,它会确保这些源根目录下的文件被包含在类路径中,从而 MyBatis 能够正确地加载映射文件。
2.4 总结:
了解这些路径概念对于在 IntelliJ IDEA 中正确配置和管理 MyBatis 项目是非常重要的。它们帮助开发者清晰地组织项目结构,并确保文件能够被正确地引用和加载。