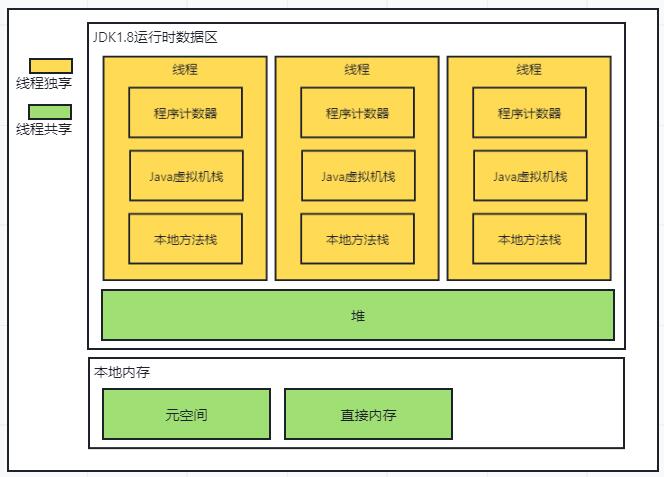
netty Recycler对象池
前言
池化思想在实际开发中有很多应用,指的是针对一些创建成本高,创建频繁的对象,
用完不弃
,将其缓存在对象池子里,下次使用时优先从池子里获取,如果获取到则可以直接使用,以此降低创建对象的开销。
我们最熟悉的数据库连接池就是一种池化思想的应用,数据库操作是非常频繁的,数据库连接的创建、销毁开销很大,每次都需要进行TCP三次握手和四次挥手,权限检查等,所以如果每次操作数据库都重新创建连接,用完就丢弃,对于应用程序来说是不可接受的。在java世界里,一切皆对象,所以需要有一个数据库对象连接池,用于保存连接池对象。例如使用hikari,可以配置spring.datasource.hikari.maximum-pool-size=20,表示最多可以池化20个数据库连接对象。
此外,频繁的创建销毁对象还会影响GC,当一个对象使用完,再没被GC root引用,就变成不可达,所引用的内存可以被垃圾回收,GC是需要STW的,频繁的GC也会影响程序的吞吐量。
本篇我们要介绍的是netty的对象池
Recycler
,Recycler是对象池核心类,netty为了减少依赖,以及追求高性能,并没有使用第三方的对象池,而是自己设计了一套。
netty在高并发处理IO读写,内存对象的使用是非常频繁的,如果每次都重新申请,无疑性能会大打折扣,特别是对于堆外内存,申请和销毁的成本更高,所以对内存对象使用池化是很有必要的。
例如:PooledHeapByteBuf,PooledDirectByteBuf,ChannelOutboundBuffer.Entry都使用了对象池,这些类内部都有一个Recycler静态变量和一个Handle实例变量。
static final class Entry {
private static final Recycler<Entry> RECYCLER = new Recycler<Entry>() {
@Override
protected Entry newObject(Handle<Entry> handle) {
return new Entry(handle);
}
};
private final Handle<Entry> handle;
}
原理
我们先通过一个例子感受一下Recycler的使用,然后再来分析它的原理。
public final class Connection {
private Recycler.Handle handle;
private Connection(Recycler.Handle handle) {
this.handle = handle;
}
private static final Recycler<Connection> RECYCLER = new Recycler<Connection>() {
@Override
protected Connection newObject(Handle<Connection> handle) {
return new Connection(handle);
}
};
public static Connection newInstance() {
return RECYCLER.get();
}
public void recycle() {
handle.recycle(this);
}
public static void main(String[] args) {
Connection c1 = Connection.newInstance();
int hc1 = c1.hashCode();
c1.recycle();
Connection c2 = Connection.newInstance();
int hc2 = c2.hashCode();
c2.recycle();
System.out.println(hc1 == hc2); //true
}
}
代码非常简单,我们用final修饰Connection,这样就无法通过继承创建对象。同时构造方法定义为私有,防止外部直接new创建对象,这样就只能通过newInstance静态方法创建对象。
Recycler是一个抽象类,newObject是它的抽象方法,这里使用匿名类继承Recycler并重写newObject,用于创建一个新的对象。
Handle是一个接口,Recycler会创建并通过newObject方法传进来,默认是DefaultHandle,它的作用是用来回收对象,放回对象池。
接着我们创建两个Connection实例,可以看到它们的hashcode是一样的,证明是同一个对象。
需要注意的是,使用对象池创建的对象,用完需要调用recycle回收。
原理分析
想象一下,如果由我们设计,怎么设计一个高性能的对象池呢?对象池的操作很简单,一取一放,但考虑到多线程,实际情况就变得复杂了。
如果只有一个全局的对象池,多线程操作需要保证线程安全,那就需要通过加锁或者CAS,这都会影响存取效率,由于线程竞争,锁等待,可能通过对象池获取对象的效率还不如直接new一个,这样就得不偿失了。
针对这种情况,已经有很多的经验供我们借鉴,核心思想都是一样的,
降低锁竞争
。例如ConcurrentHashMap,通过每个节点上锁,hash到不同节点的线程就不会相互竞争;例如ThreadLocal,通过在线程级别绑定一个ThreadLocalMap,每个线程操作的都是自己的私有变量,不会相互竞争;再比如jvm在分配内存的时候,内存区域是共享的,所以jvm为每个线程设计了一块私有的TLAB,可以高效进行内存分配,关于TLAB可以参考:
这篇文章
。
这种无锁化的设计在netty中非常常见,例如对象池,内存分配,netty还设计了FastThreadLocal来代替jdk的ThreadLocal,使得线程内的存取更加高效。
Recycler设计如下:

如上图,Recycler内部维护了两个重要的变量,
Stack
和
WeakOrderQueue
,实际对象就是包装成DefaultHandle,保存在这两个结构中。
默认情况一个线程最多存储4 * 1024个对象,可以根据实际情况,通过Recycler的构造函数指定。
private static final int DEFAULT_INITIAL_MAX_CAPACITY_PER_THREAD = 4 * 1024; // Use 4k instances as default.
Stack是一个栈结构,是线程私有的,Recycler内部通过FastThreadLocal进行定义,对Stack的操作不会有线程安全问题。
private final FastThreadLocal<Stack<T>> threadLocal = new FastThreadLocal<Stack<T>>() {};
FastThreadLocal是netty版的ThreadLocal,搭配FastThreadLocalThread,FastThreadLocalMap使用,主要优化jdk ThreadLocal扩容需要rehash,和hash冲突问题。
当获取对象时,就是尝试从Stack栈顶pop出一个对象,如果有,则直接使用。如果没有就尝试从WeakOrderQueue“借”一点过来,放到Stack,如果借不到,那就调用newObject()创建一个。
WeakOrderQueue主要是用来解决多线程问题的,考虑这种情况,线程A创建的对象,可能被线程B使用,那么对象的释放就应该由线程B决定。如果线程B也将对象归还到线程A的Stack,那就出现了线程安全问题,线程A对Stack的读取,写入就需要加锁,影响并发效率。
为了无锁化操作,netty为其它每个线程都设计了一个WeakOrderQueue,各个线程只会操作自己的WeakOrderQueue,不会有并发问题了。其它线程的WeakOrderQueue会通过指针构成一个链表,Stack对象内部通过3个指针指向链表,这样就可以遍历整个链表对象。
站在线程A的角度,其它线程就是B,C,D...,站在线程B的角度,其它线程就是A,C,D...
从上图可以看到,WeakOrderQueue实际不是一个队列,内部是由一些Link对象构成的双向链表,它也是一个链表。
Link对象是一个包含读写索引,和一个长度为16的数组的对象,数组存储的就是DefaultHandler对象。
整个过程是这样的,当本线程从Stack获取不到可用对象时,就会通过cursor指针变量WeakOrderQueue链表,开始从其它线程获取对象。如果找到一个可用的Link,就会将整个Link里的对象迁移到Stack,然后删除链表节点,为了保证效率,每次最多迁移一个Link。如果还获取不到,就通过newObject()方法创建一个新的对象。
Recycler#get 方法如下:
public final T get() {
if (maxCapacityPerThread == 0) {
return newObject((Handle<T>) NOOP_HANDLE);
}
Stack<T> stack = threadLocal.get();
DefaultHandle<T> handle = stack.pop();
if (handle == null) {
handle = stack.newHandle();
handle.value = newObject(handle);
}
return (T) handle.value;
}
pop方法判断Stack没有对象,就会调用scavenge方法,从WeakOrderQueue迁移对象。scavenge,翻译过来是拾荒,捡的意思。
DefaultHandle<T> pop() {
int size = this.size;
if (size == 0) {
if (!scavenge()) {
return null;
}
size = this.size;
}
//...
}
最终会调用到WeakOrderQueue的transfer方法,这个方法比较复杂,主要是对WeakOrderQueue链表和内部Link链表的遍历。
这里dst就是前面说的Stack对象,可以看到会把element元素迁移过去。
boolean transfer(Stack<?> dst) {
//...
if (srcStart != srcEnd) {
final DefaultHandle[] srcElems = head.elements;
final DefaultHandle[] dstElems = dst.elements;
int newDstSize = dstSize;
for (int i = srcStart; i < srcEnd; i++) {
DefaultHandle element = srcElems[i];
if (element.recycleId == 0) {
element.recycleId = element.lastRecycledId;
} else if (element.recycleId != element.lastRecycledId) {
throw new IllegalStateException("recycled already");
}
srcElems[i] = null;
if (dst.dropHandle(element)) {
// Drop the object.
continue;
}
element.stack = dst;
dstElems[newDstSize ++] = element;
}
}
//...
}
应用
我们项目使用了mybatis plus作为orm,其中用得最多的就是QueryWrapper了,每次查询都需要new一个QueryWrapper。例如:
QueryWrapper<User> queryWrapper = new QueryWrapper();
queryWrapper.eq("uid", 123);
return userMapper.selectOne(queryWrapper);
数据库查询是非常频繁的,QueryWrapper的创建虽然不会很耗时,但过多的对象也会给GC带来压力。
QueryWrapper是mp提供的类,它没有池化的实现,不过我们可以参考上面netty DefaultHandle的思路,在它外面再包一层,然后池化包装后的对象。
回收的时候还要注意清空对象的属性,例如上面给uid赋值了123,下个对象就不能用这个条件,否则就乱套了,QueryWrapper提供了clear方法可以重置所有属性。
同时,每次用完都需要手动recycle也是比较麻烦的,开发容易忘记,可以借助AutoCloseable接口,使用try-with-resource的写法,在结束后自动完成回收。
对于修改和删除还有UpdateWrapper
有了这些思路,代码就出来了:
public final class WrapperUtils {
private WrapperUtils() {}
private static final Recycler<PooledQueryWrapper> QUERY_WRAPPER_RECYCLER = new Recycler<PooledQueryWrapper>() {
@Override
protected PooledQueryWrapper newObject(Handle<PooledQueryWrapper> handle) {
return new PooledQueryWrapper<>(handle);
}
};
public static <T> PooledQueryWrapper<T> newInstance() {
return QUERY_WRAPPER_RECYCLER.get();
}
static class PooledQueryWrapper<T> implements AutoCloseable {
private QueryWrapper<T> queryWrapper;
private Recycler.Handle<PooledQueryWrapper> handle;
public PooledQueryWrapper(Recycler.Handle<PooledQueryWrapper> handle) {
this.queryWrapper = new QueryWrapper<>();
this.handle = handle;
}
public QueryWrapper<T> getWrapper() {
return this.queryWrapper;
}
@Override
public void close() {
queryWrapper.clear();
handle.recycle(this);
}
}
}
使用如下,可以看到打印出来的hashcode都是一样的,每次执行后都会自动调用close方法,进行QueryWrapper属性重置。
public static void main(String[] args) {
try (PooledQueryWrapper<Case> objectPooledWrapper = WrapperUtils.newInstance()) {
QueryWrapper<Case> wrapper = objectPooledWrapper.getWrapper();
wrapper.eq("age", 1);
wrapper.select("id,name");
wrapper.last("limit 1");
System.out.println(wrapper.hashCode());
}
try (PooledQueryWrapper<Case> objectPooledWrapper = WrapperUtils.newInstance()) {
QueryWrapper<Case> wrapper = objectPooledWrapper.getWrapper();
wrapper.eq("age", 2);
wrapper.select("id,email");
wrapper.last("limit 2");
System.out.println(wrapper.hashCode());
}
try (PooledQueryWrapper<Case> objectPooledWrapper = WrapperUtils.newInstance()) {
QueryWrapper<Case> wrapper = objectPooledWrapper.getWrapper();
wrapper.eq("age", 3);
wrapper.select("id,phone");
wrapper.last("limit 3");
System.out.println(wrapper.hashCode());
}
}
总结
之前我们也分析过
apache common pool
,这也是一个池化实现,在redis客户端也有应用,但它是通过加锁解决并发问题的,设计没有netty这么精细。
上面的源码来自netty4.1.42,从整体上看整个Recycler的设计还是比较复杂的,主要为了解决多线程竞争和GC问题,导致整个代码复杂度比较高,所以netty在后来的版本中对其进行重构。
不过这不影响我们对它思想的学习,以后也可以借鉴到实际开发中。
更多分享,欢迎关注我的github:
https://github.com/jmilktea/jtea