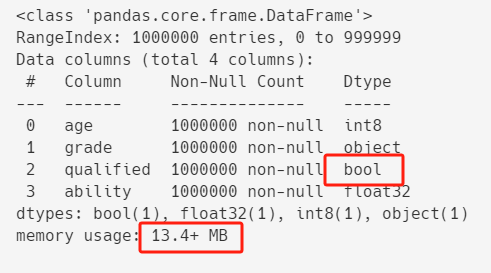
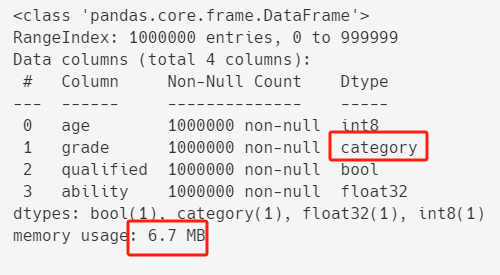
4)Playbook
4.1)Playbook 介绍
PlayBook
与
ad-hoc
相比,是一种完全不同的运用 Ansible 的方式,类似与 Saltstack 的 state 状态文件。ad-hoc 无法持久使用,PlayBook 可以持久使用。
PlayBook 剧本是 由一个或多个 "Play" 组成 的列表
Play 的主要功能在于将预定义的一组主机,装扮成事先通过 Ansible 中的 Task 定义好的角色。
从根本上来讲,所谓的 Task 无非是调用 Ansible 的一个 module。将多个 Play 组织在一个 PlayBook 中,即可以让它们联合起来按事先编排的机制完成某一任务。
PlayBook 文件是采用 YAML 语言 编写的。

4.1.1)PlayBook 核心元素
- Host:
执行的远程主机列表
- Tasks:
任务集
- Varniables:
内置变量或自定义变量在 PlayBook 中调用
- Templates:
模板文件,即使用模板语法的文件,比如配置文件等
- Handlers:
和 notity 结合使用,由特定条件触发的操作,满足条件方才执行,否则不执行
- Tags:
标签,指定某条任务执行,用于选择运行 PlayBook中的部分代码。
PlayBook
翻译过来就是
剧本
,可以简单理解为使用不同的模块完成一件事情,
具体 PlayBook 组成如下
- Play
:定义的是主机的角色
- Task
:定义的是具体执行的任务
- PlayBook
:由一个或多个 Play 组成,一个 Play 可以包含多个 Task 任务

4.1.2)PlayBook 优势
- 功能比 ad-hoc 更全
- 能很好的控制先后执行顺序,以及依赖关系
- 语法展现更加的直观
- ad-hoc 无法持久使用,PlayBook 可以持久使用
4.1.3)PlayBook 语法
PlayBook 的配置语法是由 yaml 语法描述的,扩展名是 yml 或 yaml,遵循 yaml 格式
- 缩进:
YAML 使用固定的缩进风格表示层级结构,每个缩进由两个空格组成,不能使用 Tab
- 冒号:
以冒号结尾的除外,其他所有冒号后面所有必须有空格
- 短横线:
表示列表项,使用一个短横杠加一个空格,多个项使用同样的缩进级别作为同一列表
4.2)YAML 语言
4.2.1)YAML 语言介绍
YAML:
YAML Ain't Markup Language,即 YAML 不是标记语言。
不过,在开发的这种语言时,YAML 的意思其实是:"Yet Another Markup Language"( 仍是一种标记语言 )
YAML 是一个可读性高的用来表达资料序列的格式。
YAML 参考了其他多种语言,包括:XML、C 语言、Python、Perl 以及电子邮件格式 RFC2822 等。Clark Evans 在 2001 年在首次发表了这种语言,另外 Ingy döt Net 与 Oren Ben-Kiki 也是这语言的共同设计者,目前很多最新的软件比较流行采用此格式的文件存放配置信息,如:Ubuntu,Anisble,Docker,Kubernetes 等
YAML 官方网站:
http://www.yaml.org
Ansible 官网:
https://docs.ansible.com/ansible/latest/reference_appendices/YAMLSyntax.html

4.2.2)YAML 语言特性
- YAML 的可读性好
- YAML 和脚本语言的交互性好
- YAML 使用实现语言的数据类型
- YAML 有一个一致的信息模型
- YAML 易于实现
- YAML 可以基于流来处理
- YAML 表达能力强,扩展性好
4.2.3)YAML 语法简介
- 在单一文件第一行,用连续** 三个连字号 "-" 开始**
- 还有 选择性的连续三个点号 ( ... ) 用来
表示文件的结尾
- 次行开始正常写 Playbook 的内容,一般建议写明该 Playbook 的功能描述
- 可以使用 # 号注释代码
- 缩进必须是统一的,不能空格和 Tab 混用
( 正常使用两个空格缩进 )
- 缩进的级别也必须是一致的,同样的缩进代表同样的级别,程序判别配置的级别是通过缩进结合换行来实现的
- YAML 文件内容是区别大小写的,key/value 的值
均需大小写敏感
- 多个 key/value 可同行写也可换行写
,同行使用,分隔
- key 后面冒号要加一个空格,比如:key: value
- value 可是个字符串,也可是另一个列表
- YAML 文件扩展名通常为 yml 或 yaml
4.2.4)支持的数据类型
YAML 支持以下
常用几种数据类型
- 标量:
单个的、不可再分的值
- 对象:
键值对的集合,又称为映射(mapping)/ 哈希(hashes) /
字典
(dictionary)
- 数组:
一组按次序排列的值,又称为序列(sequence) /
列表
(list)
- 示例:
course: [ linux , golang , python ]
4.2.4.1)标量:scalar
方式一:
键值对
name: wang
age: 18
方式二:
使用缩进方式
name:
wang
age:
18
标量是最基本的,不可再分的值,包括:
- 字符串
- 布尔值
- 整数
- 浮点数
- Null
- 时间
- 日期
4.2.4.2)字典:Dictionary
字典由多个 key 与 value 构成,key 和 value 之间用
:
分隔
并且,后面有一个空格,所有 k/v 可以放在一行,或者每个 k/v 分别放在不同行
格式
account: { name: wang, age: 30 }
使用缩进方式
account:
name: wang
age: 18
范例:
# 不同行
# An employee record
name: Example Developer
job: Developer
skill: Elite(社会精英)
# 同一行, 也可以将 key:value放置于{}中进行表示,用,分隔多个key:value
# An employee record
{name: "Example Developer", job: "Developer", skill: "Elite"}
4.2.4.3)列表:List
列表由多个元素组成,每个元素放在不同行,且元素前均使用 "-" 打头,并且 - 后有一个空格
或者将所有元素用 [ ] 括起来放在同一行
// 格式
course: [ linux , golang , python ]
// 也可以写成以 - 开头的多行
course:
- linux
- golang
- python
// 数据里面也可以包含字典
course:
- linux: manjaro
- golang: gin
- python: django
范例:
# 不同行, 行以-开头, 后面有一个空格
# A list of tasty fruits
- Apple
- Orange
- Strawberry
- Mango
# 同一行
[Apple,Orange,Strawberry,Mango]
范例:
YAML 表示一个家庭
name: John Smith
age: 41
gender: Male
spouse: { name: Jane Smith, age: 37, gender: Female } # 1) 写在一行里
name: Jane Smith # 2) 也可以写成多行
age: 37
gender: Female
children: [ {name: Jimmy Smith,age: 17, gender: Male}, {name: Jenny Smith, age: 13, gender: Female}, {name: hao Smith, age: 20, gender: Male } ] # 写在一行
- name: Jimmy Smith # 3) 写在多行, 更为推荐的写法
age: 17
gender: Male
- {name: Jenny Smith, age: 13, gender: Female}
- {name: hao Smith, age: 20, gender: Male }
4.2.5)三种常见的数据格式
参考:
https://juejin.cn/post/7041815877825593374
XML:Extensible Markup Language,可扩展标记语言,可用于数据交换和配置。
JSON:JavaScript Object Notation,JavaScript 对象表记法,主要用来数据交换或配置,不支持注释。
YAML:YAML Ain't Markup Language YAML 不是一种标记语言, 主要用来配置,大小写敏感,不支持 Tab。


也可以用工具互相转换,参考网站:
https://www.json2yaml.com/
http://www.bejson.com/json/json2yaml/

4.3)Playbook 核心组件
官方文档:
https://docs.ansible.com/ansible/latest/reference_appendices/playbooks_keywords.html#playbook-keywords
一个 PlayBook 中由多个组件组成,其中所用到的 **常见组件类型 **如下:
- Hosts
:执行的 远程主机列表
- Tasks:
任务集,由多个 task 的元素组成的列表实现,每个 task 是一个字典,一个完整的代码块功能需最少元素需包括 name 和 task,一个 name 只能包括一个 task
- Variables:
内置变量或自定义变量 在 PlayBook 中调用
- Templates:
模板,可替换模板文件中的变量并实现一些简单逻辑的文件
- Handlers
和
notify
结合使用,由特定条件触发的操作,满足条件方才执行,否则不执行
- Tags:
标签 指定某条任务执行,用于选择运行 playbook 中的部分代码。ansible 具有幂等性,因此会自动跳过没有变化的部分,即便如此,有些代码为测试其确实没有发生变化的时间依然会非常地长。此时,如果确信其没有变化,就可以通过tags 跳过此些代码片段。
4.3.1)hosts 组件
Hosts:
PlayBook 中的每一个 Play 的目的都是为了让特定主机以某个指定的用户身份执行任务。hosts 用于指定要执行指定任务的主机,须事先定义在主机清单中。
one.example.com
one.example.com:two.example.com
192.168.1.50
192.168.1.*
Websrvs:dbsrvs # 或者, 两个组的并集
Websrvs:&dbsrvs # 与, 两个组的交集
webservers:!dbsrvs # 在 websrvs 组, 但不在dbsrvs组
案例:
- hosts: websrvs:appsrvs
4.3.2)remote_user 组件
remote_user:可用于 Host 和 task 中。也可以通过指定其通过 sudo 的方式在远程主机上执行任务,其可用于 play 全局或某任务;此外,甚至可以在 sudo 时使用 sudo_user 指定 sudo 时切换的用户
remote_user: root # 方式一
tasks:
- name: test connection
ping:
remote_user: magedu # 方式二
sudo: yes # 默认 sudo 为 root
sudo_user:wang # sudo 为 wang
4.3.3)task 列表和 action 组件
Play 的主体部分是 task list,task list 中有一个或多个 task,各个 task 按次序逐个在 hosts 中指定的所有主机上执行,即在所有主机上完成第一个 task 后,再开始第二个 task。
task 的目的是使用指定的参数执行模块,而在模块参数中可以使用变量。模块执行是幂等的,这意味着多次执行是安全的,因为其结果均一致。
每个 task 都应该有其 name,用于 PlayBook 的执行结果输出,建议其内容能清晰地描述任务执行步骤。如果未提供 name,则 action 的结果将用于输出。
task 两种格式:
action: module arguments # 示例: action: shell wall hello
module: arguments # 建议使用 # 示例: shell: wall hello
注意:
Shell 和 Command 模块后面跟命令,而非 key=value
范例:
[root@ansible ansible] cat hello.yaml
---
# first yaml file
- hosts: websrvs
remote_user: root
gather_facts: no # 不收集系统信息, 提高执行效率
tasks:
- name: test network connection
ping:
- name: wall
shell: wall "hello world!"
# 检查语法
[root@ansible ansible] ansible-playbook --syntax-check hello.yaml
# 验证脚本 ( 不真实执行 )
# 模拟执行 hello.yaml 文件中定义的 playbook, 不会在被控节点上应用任何更改
[root@ansible ansible] ansible-playbook -C hello.yaml
# 真实执行
[root@ansible ansible] ansible-playbook hello.yaml

范例:
初识 Ansible
[root@ansible ansible] vim test.yml
---
# 初识 Ansible
- hosts: websrvs
remote_user: root
gather_facts: yes # 需开启,否则无法收集到主机信息
tasks:
- name: '存活性检测'
ping:
- name: '查看主机名信息'
setup: filter=ansible_nodename
- name: '查看操作系统版本'
setup: filter=ansible_distribution_major_version
- name: '查看内核版本'
setup: filter=ansible_kernel
- name: '查看时间'
shell: date
tasks:
- name: '安装 HTTPD'
yum: name=httpd
- name: '启动 HTTPD'
service: name=httpd state=started enabled=yes
# 检查语法
[root@ansible ansible] ansible-playbook --syntax-check test.yml
# 执行脚本
[root@ansible ansible] ansible-playbook test.yml
范例:
Ansible PlayBook 由有序列表中的一个或多个 Play 组成。在这里,您可以认为剧本是执行指令以实现剧本总体目标的代码的一部分。
每个 Play 运行一个
Task
,每个 Task 调用 Ansible Modules 在一个或多个 Nodes 托管目标节点上执行指令。

---
- hosts: websrvs
remote_user: root
gather_facts: no # 是否收集系统 facts 信息
tasks:
- name: install httpd # 描述信息
yum: name=httpd # 调用 yum 模块
- name: start httpd
service: name=httpd state=started enabled=yes # 调用 service 模块

---
- hosts: websrvs
remote_user: root
gather_facts: no # 是否收集系统 facts 信息
tasks:
- name: ping
ping:
- name: wall
shell: wall hello
- hosts: websrvs
remote_user: root
tasks:
- name: install httpd
yum: name=httpd
- name: start httpd
service: name=httpd state=started enabled=yes
# 验证脚本 ( 不真实执行 )
[root@ansible ansible] ansible-playbook -C hello.yaml
# 真实执行
[root@ansible ansible] ansible-playbook hello.yaml

4.3.4)其它组件
某任务的状态在运行后为
changed
时,可通过
"notify"
通知给相应的 handlers 任务。
还可以通过
"tags"
给 task 打标签,可在 ansible-playbook 命令上使用
-t
指定进行调用
4.3.5)Shell Scripts VS Playbook 案例
# SHELL 脚本实现
#!/bin/bash
# 安装 Apache
yum install --quiet -y httpd
# 复制配置文件
cp /tmp/httpd.conf /etc/httpd/conf/httpd.conf
cp /tmp/vhosts.conf /etc/httpd/conf.d/
# 启动 Apache, 并设置开机启动
systemctl enable --now httpd
# Playbook 实现
---
- hosts: dbsrvs
remote_user: root
gather_facts: no # 是否收集系统 facts 信息 ( 取消收集能提高 ansible 执行速度 )
tasks:
- name: "安装Apache"
yum: name=httpd
- name: "复制配置文件"
copy: src=/tmp/httpd.conf dest=/etc/httpd/conf/
- name: "复制配置文件"
copy: src=/tmp/vhosts.conf dest=/etc/httpd/conf.d/
- name: "启动Apache, 并设置开机启动"
service: name=httpd state=started enabled=yes

4.4)PlayBook 命令
// 格式
ansible-playbook <filename.yml> ... [options]
PlayBook 常用选项
// "常见选项"
--syntax-check # 语法检查, 可缩写成 --syntax, 相当于 bash -n
-C --check # 模拟执行, 只检测可能会发生的改变, 但不真正执行操作, dry run
--list-hosts # 列出运行任务的主机 # 举例: ansible-playbook hello.yaml --list-hosts
--list-tags # 列出 tag
--list-tasks # 列出 task # 举例: ansible-playbook hello.yaml --list-tasks
--limit 主机列表 # 针对主机列表中的特定主机执行 # 举例: ansible-playbook hello.yaml --limit 192.168.80.28
-i INVENTORY # 指定主机清单文件, 通常一个项对应一个主机清单文件 # 举例: ansible-playbook hello.yaml -i /root/hosts
--start-at-task START_AT_TASK # 从指定 task 开始执行, 而非从头开始, START_AT_TASK 为任务的 name # 举例: ansible-playbook hello.yml --start-at="start httpd"
-v -vv -vvv # 显示过程
// 举例: ansible-playbook hello.yaml --list-hosts
// 举例: ansible-playbook hello.yaml --list-tasks
// 举例: ansible-playbook hello.yaml --limit 192.168.80.28
// 举例: ansible-playbook hello.yaml -i /root/hosts
// 举例: ansible-playbook hello.yml --start-at="start httpd"

4.5)Playbook 初步
4.5.1)利用 PlayBook 创建 MySQL 用户
根据写 Shell 脚本的思路来编写 PlayBook 即可。( 顺序执行 )
范例:
mysql_user.yml
---
- hosts: dbsrvs
name: 创建 MySQL 用户
remote_user: root
gather_facts: no
tasks:
- name: '创建 MySQL 用户组'
group:
name: mysql
gid: 306
system: yes
- name: '创建 MySQL 用户'
user:
name: mysql
uid: 306
group: mysql
system: yes
shell: /sbin/nologin
home: /data/mysql
create_home: yes
- name: '查看 MySQL 用户信息'
shell: id mysql
# 检查远程主机用户信息
[root@ansible ansible] ansible dbsrvs -m shell -a "id mysql"
# 验证 PlayBook 脚本
[root@ansible ansible] ansible-playbook -C mysql_user.yml
# 执行脚本
[root@ansible ansible] ansible-playbook mysql_user.yml

范例:
delete-mysql-user.yaml
[root@ansible ansible] vim delete-mysql-user.yaml
---
- hosts: dbsrvs
name: 移除 MySQL 用户
remote_user: root
gather_facts: no
tasks:
- name: '删除 MySQL 用户'
user: name=mysql state=absent remove=yes
[root@ansible ansible] ansible-playbook delete-mysql-user.yaml

4.5.2)利用 PlayBook 安装 nginx
范例:
install_nginx.yml
# 先将远程主机的 HTTPD 服务卸载
[root@ansible ansible] ansible websrvs -m yum -a 'name=httpd state=absent'
# Ansible 控制节点 安装 nginx 软件包 ( 实验: 主要为了拿到 nginx conf 文件 )
[root@ansible ansible] yum install nginx -y
[root@ansible ansible] mkdir files
# 拷贝 nginx 配置文件
[root@ansible ansible] cp /etc/nginx/nginx.conf files/
[root@ansible ansible] vim files/nginx.conf
server {
listen 8080; # 修改该行
listen [::]:80;
server_name _;
root /usr/share/nginx/html;
# 编写 HTML 文件 ( 增加 UTF-8 防止乱码 )
[root@ansible ansible] vim files/index.html
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<h1> 微信公众号: 开源极客行 </h1>
</head>
<body>
</body>
</html>
# 编写 PlayBook 文件
[root@ansible ansible] vim install_nginx.yml
---
# install nginx
- hosts: websrvs
remote_user: root
gather_facts: no
tasks:
- name: "创建 nginx 用户组"
group: name=nginx state=present
- name: "创建 nginx 用户"
user: name=nginx state=present group=nginx
- name: "安装 nginx"
yum: name=nginx state=present
- name: "拷贝 nginx 配置文件"
copy: src=files/nginx.conf dest=/etc/nginx/nginx.conf
- name: "拷贝 nginx 网页文件"
copy: src=files/index.html dest=/usr/share/nginx/html/index.html
- name: "启动 nginx 服务"
service: name=nginx state=started enabled=yes
# 验证 PlayBook 脚本 ( 重要 )
[root@ansible ansible] ansible-playbook -C install_nginx.yml
# 执行 PalyBook 脚本
[root@ansible ansible] ansible-playbook install_nginx.yml
# 验证控制节点端口启用情况
[root@ansible ansible] ansible websrvs -m shell -a 'netstat -nltp | grep 8080'


$ vim remove-nginx.yaml
---
- hosts: websrvs
name: 移除 nginx 软件
remote_user: root
gather_facts: no
tasks:
- name: 停止nginx服务
service: name=nginx state=stopped
- name: 移除nginx软件
yum: name=nginx state=absent
- name: 删除nginx用户
user: name=nginx state=absent remove=yes
- name: 删除nginx用户组
group: name=nginx state=absent
4.5.3)利用 PlayBook 安装和卸载 httpd
范例:
install_httpd.yml
[root@centos8 ansible] vim files/index.html
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<h1> 微信公众号: 开源极客行 </h1>
</head>
<body>
</body>
</html>
[root@centos8 ansible] vim install_httpd.yml
---
# install httpd
- hosts: websrvs
remote_user: root
gather_facts: no
tasks:
- name: "Install httpd"
yum: name=httpd state=present
- name: "Modify config listen port"
lineinfile:
path: /etc/httpd/conf/httpd.conf
regexp: '^Listen'
line: 'Listen 8080'
- name: "Modify config data directory one"
lineinfile:
path: /etc/httpd/conf/httpd.conf
regexp: '^DocumentRoot "/var/www/html"'
line: 'DocumentRoot "/data/html"'
- name: "Modify config data directory two"
lineinfile:
path: /etc/httpd/conf/httpd.conf
regexp: '^<Directory "/var/www/html">'
line: '<Directory "/data/html">'
- name: "Mkdir website directory"
file: path=/data/html state=directory
- name: "copy Web html file"
copy: src=files/index.html dest=/data/html/
- name: "Start httpd service"
service: name=httpd state=started enabled=yes
# 仅针对 192.168.80.28 执行操作
[root@centos8 ansible] ansible-playbook install_httpd.yml --limit 192.168.80.28


范例:
remove_httpd.yml
[root@centos8 ansible] vim remove_httpd.yml
---
- hosts: websrvs
remote_user: root
gather_facts: no
tasks:
- name: "remove httpd package"
yum: name=httpd state=absent
- name: "remove apache user"
user: name=apache state=absent
- name: "remove config file"
file: name=/etc/httpd state=absent
- name: "remove web html"
file: name=/data/html/ state=absent
# 验证 PlayBook 脚本 ( 重要 )
[root@centos8 ansible] ansible-playbook -C remove_httpd.yml
# 执行 PlayBook 脚本
[root@centos8 ansible] ansible-playbook remove_httpd.yml

4.5.4)利用 PlayBook 安装 MySQL 5.6
范例:
安装 mysql-5.6.46-linux-glibc2.12
注意:
建议 MySQL 客户机的内存需超过 2 G,否则可能会报错
# 下载 MySQL 软件包
[root@ansible ~] mkdir /data/ansible/files -p && cd /data/ansible/files
[root@ansible ~] wget https://ftp.iij.ad.jp/pub/db/mysql/Downloads/MySQL-5.6/mysql-5.6.46-linux-glibc2.12-x86_64.tar.gz
# MySQL 配置文件
[root@ansible ~] vim /data/ansible/files/my.cnf
[mysqld]
socket=/tmp/mysql.sock
user=mysql
symbolic-links=0
datadir=/data/mysql
innodb_file_per_table=1
log-bin
pid-file=/data/mysql/mysqld.pid
[client]
port=3306
socket=/tmp/mysql.sock
[mysqld_safe]
log-error=/var/log/mysqld.log
# 编写 MySQL 初始脚本
[root@ansible ~] vim /data/ansible/files/secure_mysql.sh
#!/bin/bash
/usr/local/mysql/bin/mysql_secure_installation <<EOF
y
123456
123456
y
y
y
y
[root@ansible files] chmod +x secure_mysql.sh
[root@ansible files]# tree /data/ansible/files/
/data/ansible/files/
├── my.cnf
├── mysql-5.6.46-linux-glibc2.12-x86_64.tar.gz
└── secure_mysql.sh
0 directories, 3 files
# 编写 PlayBook
[root@ansible ~] vim /data/ansible/install_mysql.yml
---
# install mysql-5.6.46-linux-glibc2.12-x86_64.tar.gz
- hosts: dbsrvs
remote_user: root
gather_facts: no
tasks:
- name: "install packages"
yum: name=libaio,perl-Data-Dumper,perl-Getopt-Long
- name: "create mysql group"
group: name=mysql gid=306
- name: "create mysql user"
user: name=mysql uid=306 group=mysql shell=/sbin/nologin system=yes create_home=no home=/data/mysql
- name: "copy tar to remote host and file mode"
unarchive: src=/data/ansible/files/mysql-5.6.46-linux-glibc2.12-x86_64.tar.gz dest=/usr/local/ owner=root group=root
- name: "create linkfile /usr/local/mysql"
file: src=/usr/local/mysql-5.6.46-linux-glibc2.12-x86_64 dest=/usr/local/mysql state=link
- name: "create dir /data/mysql"
file: path=/data/mysql state=directory
- name: "data dir" # 该步骤貌似有点问题
shell: chdir=/usr/local/mysql ./scripts/mysql_install_db --datadir=/data/mysql --user=mysql
tags: data
ignore_errors: yes # 忽略错误,继续执行
- name: "config my.cnf"
copy: src=/data/ansible/files/my.cnf dest=/etc/my.cnf
- name: "service script"
shell: /bin/cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
- name: "enable service"
shell: /etc/init.d/mysqld start;chkconfig --add mysqld;chkconfig mysqld on
tags: service
- name: "PATH variable"
copy: content='PATH=/usr/local/mysql/bin:$PATH' dest=/etc/profile.d/mysql.sh
- name: "secure script"
script: src=/data/ansible/files/secure_mysql.sh
tags: script
# 执行 PlayBook 脚本
[root@ansible ~] ansible-playbook install_mysql.yml

范例:
install_mariadb.yml
# 编写 PlayBook
[root@ansible ~] vim /data/ansible/install_mariadb.yml
---
# Installing MariaDB Binary Tarballs
- hosts: dbsrvs
remote_user: root
gather_facts: no
tasks:
- name: create group
group: name=mysql gid=27 system=yes
- name: create user
user: name=mysql uid=27 system=yes group=mysql shell=/sbin/nologin home=/data/mysql create_home=no
- name: mkdir datadir
file: path=/data/mysql owner=mysql group=mysql state=directory
- name: unarchive package
unarchive: src=/data/ansible/files/mariadb-10.2.27-linux-x86_64.tar.gz dest=/usr/local/ owner=root group=root
- name: link
file: src=/usr/local/mariadb-10.2.27-linux-x86_64 path=/usr/local/mysql state=link
- name: install database
shell: chdir=/usr/local/mysql ./scripts/mysql_install_db --datadir=/data/mysql --user=mysql
- name: config file
copy: src=/data/ansible/files/my.cnf dest=/etc/ backup=yes
- name: service script
shell: /bin/cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
- name: start service
service: name=mysqld state=started enabled=yes
- name: PATH variable
copy: content='PATH=/usr/local/mysql/bin:$PATH' dest=/etc/profile.d/mysql.sh
# 执行 PlayBook 脚本
[root@ansible ~] ansible-playbook install_mariadb.yml
4.6)ignore_errors 忽略错误
如果一个 Task 出错,
默认将不会继续执行后续的其它 Task
我们可以利用 **ignore_errors:yes ** 忽略此 Task 的错误,继续向下执行 PlayBook 其它 Task
[root@ansible ansible] vim test_ignore.yml
---
- hosts: websrvs
tasks:
- name: error test
command: /bin/false # 返回失败结果的命令
ignore_errors: yes # 忽略错误, 继续执行
- name: continue
command: wall continue
[root@ansible ansible] ansible-playbook test_ignore.yml

4.7)Playbook 中使用 handlers 和 notify
Handlers 本质是 task list,类似于 MySQL 中的触发器触发的行为,其中的 task 与前述的 task 并没有本质上的不同,主要用于当关注的资源发生变化时,才会采取一定的操作。
而 Notify 对应的 action 可用于在每个 play 的最后被触发,这样可避免多次有改变发生时每次都执行指定的操作,仅在所有的变化发生完成后一次性地执行指定操作。在 notify 中列出的操作称为 handler,也即 notify 中调用 handler 中定义的操作。
注意:
- 如果多个 Task 通知了相同的 handlers, 此 handlers 仅会在所有 Tasks 结束后运行一次。
- 只有 notify 对应的 task 发生改变了才会通知 handlers,没有改变则不会触发 handlers。
- handlers 是在所有前面的 tasks 都成功执行才会执行,如果前面任何一个 task 失败,会导致 handler 跳过执行,可以使用
force_handlers:yes
强制执行 handler。
案例:
---
- hosts: websrvs
remote_user: root
gather_facts: no
tasks:
- name : Install httpd
yum: name=httpd state=present
- name : Install configure file
copy: src=files/httpd.conf dest=/etc/httpd/conf/
# 修改 http 服务的端口号
- name: config httpd conf
lineinfile: "path=/etc/httpd/conf/httpd.conf regexp='^Listen' line='Listen 8080'"
notify:
- restart httpd
- wall
- name: ensure apache is running
service: name=httpd state=started enabled=yes
handlers:
- name: restart httpd
service: name=httpd state=restarted
- name: wall
command: wall "The config file is changed"
案例:
在 Ansible 中,handlers 部分 用于定义当某些条件满足时应该执行的任务。
这些任务通常是 由 notify 指令触发的,这些 notify 指令可以放在其他任务中。
当任务完成并且其状态发生变化时,与任务相关联的 notify 指令会触发相应的 handler。
案例:
当 Copy Nginx Config File 任务完成并发生改变时,它会触发名为 Restart Nginx Service 的 handler。Nginx 服务将被重启,以应用新的配置。
模块的大概执行流程:
https://blog.csdn.net/wangjiachenga/article/details/122980073

[root@ansible ansible] vim files/nginx.conf
server {
listen 80; # 修改该行
listen [::]:80;
server_name _;
root /usr/share/nginx/html;
[root@ansible ansible] vim install_nginx.yml
---
# install nginx
- hosts: websrvs
remote_user: root
gather_facts: no
tasks:
- name: "Add Nginx Group"
group: name=nginx state=present
- name: "Add Nginx User"
user: name=nginx state=present group=nginx
- name: "Install Nginx"
yum: name=nginx state=present
- name: "Copy Nginx Config File"
copy: src=files/nginx.conf dest=/etc/nginx/nginx.conf
notify: Restart Nginx Service # 定义 notify 触发器
- name: "Copy Web Page File"
copy: src=files/index.html dest=/usr/share/nginx/html/index.html
- name: "Start Nginx Service"
service: name=nginx state=started enabled=yes
handlers: # 触发如下操作
- name: "Restart Nginx Service"
service: name=nginx state=restarted enabled=yes
[root@ansible ansible] ansible-playbook install_nginx.yml

范例:
强制执行 handlers
- hosts: websrvs
force_handlers: yes # 无论 task 中的任何一个 task 失败, 仍强制执行 handlers
tasks:
- name: config file
copy: src=nginx.conf dest=/etc/nginx/nginx.conf
notify: restart nginx
- name: install package
yum: name=no_exist_package
handlers:
- name: "restart nginx"
service: name=nginx state=restarted
官方文档:
https://docs.ansible.com/ansible/latest/user_guide/playbooks_tags.html
参考文档:
https://blog.csdn.net/weixin_42171272/article/details/135268747
如果写了一个很长的 PlayBook,其中有很多的任务,这并没有什么问题,不过在实际使用这个剧本时,可能只是想要执行其中的一部分任务。
或者,你只想要执行其中一类任务而已,而并非想要执行整个剧本中的全部任务,
这个时候我们就可以借助 tags 标签实现这个需求。
tags 可以帮助我们对任务进行
打标签
的操作,与模块名同级,当任务存在标签以后,我们就可以在执行 PlayBook 时,借助标签,指定执行哪些任务,或者指定不执行哪些任务了。
在 PlayBook 文件中,利用 tags 组件,为特定 task 指定标签。
当在执行 PlayBook 时,可以只执行特定 tags 的 task,而非整个 PlayBook 文件。可以一个 task 对应多个 tag,也可以多个 task 对应一个 tag。
还有另外 3 个特殊关键字用于标签,tagged,untagged 和 all,它们分别是仅运行已标记,只有未标记和所有任务。
[root@ansible ~] vim httpd.yml
---
# tags example
- hosts: websrvs
remote_user: root
gather_facts: no
tasks:
- name: "Install httpd"
yum: name=httpd state=present
- name: "Install configure file"
copy: src=files/httpd.conf dest=/etc/httpd/conf/
tags: [ conf,file ] # 写在一行
- conf # 写成多行
- file
- name: "start httpd service"
tags: service # 写在一行
service: name=httpd state=started enabled=yes
# 查看标签
[root@ansible ~] ansible-playbook --list-tags httpd.yml
# 仅执行标签动作
[root@ansible ~] ansible-playbook -t conf,service httpd.yml
# 跳过标签动作
[root@ansible ~] ansible-playbook --skip-tags conf httpd.yml
[root@ansible ~] ansible-playbook httpd.yml --skip-tags untagged
4.9)Playbook 中 使用变量
Playbook 中同样也支持变量
变量名:
仅能由字母、数字和下划线组成,且只能以字母开头
// 变量定义
# variable=value
variable: value # 建议
范例:
# http_port=80
http_port: 80 # 建议
变量调用方式:
通过
{{ variable_name }}
调用变量,且变量名前后建议加空格,
有时用
"{{ variable_name }}"
才生效
变量来源:
- ansible 的 setup facts 远程主机的所有变量 都可直接调用
- 通过命令行指定变量,优先级最高
ansible-playbook -e varname=value test.yml
- 在 PlayBook 文件中定义
vars:
var1: value1
var2: value2
- 在独立的变量 YAML 文件中定义
- hosts: all
vars_files:
- vars.yml
- 在主机清单文件中定义
- 主机(普通)变量:主机组中主机单独定义,优先级高于公共变量
- 组(公共)变量:针对主机组中所有主机定义统一变量
- 在项目中针对主机和主机组定义
在项目目录中创建 host_vars 和 group_vars 目录
- 在 role 中定义
变量的优先级从高到低如下
-e 选项定义变量 > playbook 中 vars_files > playbook 中 vars 变量定义 > host_vars/主机名 文件 > 主机清单中主机变量 > group_vars/主机组名文件 > group_vars/all文件 > 主机清单组变量
4.9.1)使用 setup 模块中变量
本模块自动在 PlayBook 调用,不要用 ansible 命令调用,生成的系统状态信息,并存放在 facts 变量中。
facts 包括的信息很多,**如: **主机名,IP,CPU,内存,网卡等
facts 变量的实际使用场景案例
- 通过 facts 变量获取被控端 CPU 的个数信息,从而生成不同的 Nginx 配置文件
- 通过 facts 变量获取被控端内存大小信息,从而生成不同的 memcached 的配置文件
- 通过 facts 变量获取被控端主机名称信息,从而生成不同的 Zabbix 配置文件
- ......
案例:
使用 setup 变量
[root@centos8 ~] ansible 192.168.80.18 -m setup -a "filter=ansible_nodename"
[root@centos8 ~] ansible 192.168.80.18 -m setup -a 'filter="ansible_default_ipv4"'

范例:
[root@ansible ~] vim var.yml
---
# var1.yml
- hosts: websrvs
remote_user: root
gather_facts: yes # 注意: 这个需要 yes 启用
tasks:
- name: "create log file"
file: name=/root/{{ ansible_nodename }}.log state=touch owner=wangj mode=600
[root@ansible ~] ansible-playbook var.yml

范例:
显示 ens33 网卡的 IP 地址
[root@ansible ansible] vim show_ip.yml
- hosts: websrvs
tasks:
- name: show eth0 ip address {{ ansible_facts["ens33"]["ipv4"]["address"] }} # name 中也可以调用变量
debug:
msg: IP address {{ ansible_ens33.ipv4.address }} # 注意: 网卡名称
# msg: IP address {{ ansible_facts["eth0"]["ipv4"]["address"] }}
# msg: IP address {{ ansible_facts.eth0.ipv4.address }}
# msg: IP address {{ ansible_default_ipv4.address }}
# msg: IP address {{ ansible_eth0.ipv4.address }}
# msg: IP address {{ ansible_eth0.ipv4.address.split('.')[-1] }} # 取 IP 中的最后一个数字
[root@ansible ansible] ansible-playbook -v show_ip.yml

范例:
[root@ansible ~] vim test.yml
---
- hosts: websrvs
tasks:
- name: test var
file: path=/root/{{ ansible_facts["ens33"]["ipv4"]["address"] }}.log state=touch # 注意: 网卡名称信息
# file: path=/root/{{ ansible_ens33.ipv4.address }}.log state=touch # 和上面效果一样
[root@ansible ~] ansible-playbook test.yml

4.9.2)在 PlayBook 命令行中定义变量
范例:
[root@ansible ~] vim var2.yml
---
- hosts: websrvs
remote_user: root
tasks:
- name: "install package"
yum: name={{ pkname }} state=present # 调用变量
# 在 PlayBook 命令行中定义变量
[root@ansible ~] ansible-playbook -e pkname=vsftpd var2.yml

范例:
也可以将多个变量放在一个文件中
# 也可以将多个变量放在一个文件中
[root@ansible ~] cat vars
pkname1: memcached
pkname2: redis
[root@ansible ~] vim var2.yml
---
- hosts: websrvs
remote_user: root
tasks:
- name: install package {{ pkname1 }} # 名称也调用变量 ( 利于我们清楚正在安装什么软件包 )
yum: name={{ pkname1 }} state=present
- name: install package {{ pkname2 }}
yum: name={{ pkname2 }} state=present
# 方式一
[root@ansible ~] ansible-playbook -e pkname1=memcached -e pkname2=redis var2.yml
# 方式二 ( 指定存放着变量的文件 )
[root@ansible ~] ansible-playbook -e '@vars' var2.yml

4.9.3)在 PlayBook 文件中定义变量
范例:
也可以在 PlayBook 文件中定义变量
[root@ansible ~] vim var3.yml
---
- hosts: websrvs
remote_user: root
vars:
username: user1 # 定义变量
groupname: group1 # 定义变量
tasks:
- name: "create group {{ groupname }}"
group: name={{ groupname }} state=present
- name: "create user {{ username }}"
user: name={{ username }} group={{ groupname }} state=present
# 执行 PlayBook 文件
[root@ansible ~] ansible-playbook var3.yml
# 验证
[root@ansible ~] ansible websrvs -m shell -a 'id user1'

范例:
变量之间的
相互调用
[root@ansible ~] vim var4.yaml
---
- hosts: websrvs
remote_user: root
vars:
collect_info: "/data/test/{{ansible_default_ipv4['address']}}/" # 基于默认变量定义了一个新的变量
tasks:
- name: "Create IP directory"
file: name="{{collect_info}}" state=directory # 引用变量
# 执行结果
tree /data/test/
/data/test/
└── 192.168.80.18
1 directory, 0 files

范例:
变量之间的
相互调用
[root@ansible ansible] cat var2.yml
---
- hosts: websrvs
vars:
suffix: "txt"
file: "{{ ansible_nodename }}.{{suffix}}" # 基于默认变量定义了一个新的变量
tasks:
- name: test var
file: path="/data/{{file}}" state=touch # 引用变量
范例:安装多个包
# 实例一
[root@ansible ~] cat install.yml
- hosts: websrvs
vars:
web: httpd
db: mariadb-server
tasks:
- name: install {{ web }} {{ db }}
yum:
name:
- "{{ web }}"
- "{{ db }}"
state: latest
# 实例二
[root@ansible ~] cat install2.yml
- hosts: websrvs
tasks:
- name: install packages
yum: name={{ pack }}
vars:
pack:
- httpd
- memcached
范例:
安装指定版本的 MySQL
新增 PlayBook 定义变量功能
[root@ansible ansible] cat install_mysql.yml
---
# install mysql-5.6.46-linux-glibc2.12-x86_64.tar.gz
- hosts: dbsrvs
remote_user: root
gather_facts: no
vars:
version: "mysql-5.6.46-linux-glibc2.12-x86_64"
suffix: "tar.gz"
file: "{{version}}.{{suffix}}"
tasks:
- name: "install packages"
yum: name=libaio,perl-Data-Dumper,perl-Getopt-Long
- name: "create mysql group"
group: name=mysql gid=306
- name: "create mysql user"
user: name=mysql uid=306 group=mysql shell=/sbin/nologin system=yes create_home=no home=/data/mysql
- name: "copy tar to remote host and file mode"
unarchive: src=/data/ansible/files/{{file}} dest=/usr/local/ owner=root group=root
- name: "create linkfile /usr/local/mysql"
file: src=/usr/local/{{version}} dest=/usr/local/mysql state=link
- name: "data dir"
shell: chdir=/usr/local/mysql/ ./scripts/mysql_install_db --datadir=/data/mysql --user=mysql
tags: data
- name: "config my.cnf"
copy: src=/data/ansible/files/my.cnf dest=/etc/my.cnf
- name: "service script"
shell: /bin/cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
- name: "enable service"
shell: /etc/init.d/mysqld start;chkconfig --add mysqld;chkconfig mysqld on
tags: service
- name: "PATH variable"
copy: content='PATH=/usr/local/mysql/bin:$PATH' dest=/etc/profile.d/mysql.sh
- name: "secure script"
script: /data/ansible/files/secure_mysql.sh
tags: script
4.9.4)使用变量文件
可以在一个
独立的 PlayBook 文件
中定义变量,在另一个 PlayBook 文件中引用变量文件中的变量,比 PlayBook 中定义的变量优化级高
# 编写变量文件
vim vars.yml
---
# variables file
package_name: mariadb-server
service_name: mariadb
# 在 PlayBook 调用变量文件
vim var5.yml
---
# install package and start service
- hosts: dbsrvs
remote_user: root
vars_files: # 在 PlayBook 调用变量文件
- vars.yml
tasks:
- name: "install package"
yum: name={{ package_name }}
tags: install
- name: "start service"
service: name={{ service_name }} state=started enabled=yes
范例:
cat vars2.yml
---
var1: httpd
var2: nginx
cat var6.yml
---
- hosts: web
remote_user: root
vars_files:
- vars2.yml
tasks:
- name: create httpd log
file: name=/app/{{ var1 }}.log state=touch
- name: create nginx log
file: name=/app/{{ var2 }}.log state=touch
4.9.5)针对主机和主机组 定义变量
4.9.5.1)在主机清单中 针对所有项目的主机和主机分组对应变量
所有项目的 主机变量
在 inventory 主机清单文件中 为指定的主机定义变量 以便于在 PlayBook 中使用
// 范例: 定义主机变量
[websrvs]
www1.magedu.com http_port=80 maxRequestsPerChild=808
www2.magedu.com http_port=8080 maxRequestsPerChild=909
所有项目的组(公共)变量
在 inventory 主机清单文件中 赋予给指定组内所有主机上
在 PlayBook 中可用的变量,如果和主机变量是同名,优先级低于主机变量
// 范例: 公共变量
[websrvs:vars]
http_port=80
ntp_server=ntp.magedu.com
nfs_server=nfs.magedu.com
-- K8S 案例 --
[all:vars]
# --------- Main Variables ---------------
# Cluster container-runtime supported: docker, containerd
CONTAINER_RUNTIME="docker"
# Network plugins supported: calico, flannel, kube-router, cilium, kube-ovn
CLUSTER_NETWORK="calico"
# Service proxy mode of kube-proxy: 'iptables' or 'ipvs'
PROXY_MODE="ipvs"
# K8S Service CIDR, not overlap with node(host) networking
SERVICE_CIDR="192.168.0.0/16"
# Cluster CIDR (Pod CIDR), not overlap with node(host) networking
CLUSTER_CIDR="172.16.0.0/16"
# NodePort Range
NODE_PORT_RANGE="20000-60000"
# Cluster DNS Domain
CLUSTER_DNS_DOMAIN="magedu.local."
范例:
[root@ansible ~] vim /etc/ansible/hosts
[websrvs]
192.168.80.18 hname=www1 domain=magedu.io # 定义主机变量 ( 主机变量 优先级高 )
192.168.80.28 hname=www2
[websrvs:vars] # 定义分组变量
mark="-"
[all:vars] # 定义公共变量 ( 公共变量优先级低 )
domain=magedu.org
# 调用变量 ( 修改主机名 )
[root@ansible ~] ansible websrvs -m hostname -a 'name={{ hname }}{{ mark }}{{ domain }}'

# 命令行指定变量:
# -e 定义变量的优先级更高
[root@ansible ~] ansible websrvs -e domain=magedu.cn -m hostname -a 'name={{ hname }}{{ mark }}{{ domain }}'

范例:
K8S 的 ansible 变量文件
[etcd]
10.0.0.104 NODE_NAME=etcd1
10.0.0.105 NODE_NAME=etcd2
10.0.0.106 NODE_NAME=etcd3
[kube-master]
10.0.0.103 NEW_MASTER=yes
10.0.0.101
10.0.0.102
[kube-node]
10.0.0.109 NEW_NODE=yes
10.0.0.107
10.0.0.108
[harbor]
[ex-lb]
10.0.0.666666 LB_ROLE=master EX_APISERVER_VIP=10.0.0.100 EX_APISERVER_PORT=8443
10.0.0.112 LB_ROLE=backup EX_APISERVER_VIP=10.0.0.100 EX_APISERVER_PORT=8443
[chrony]
[all:vars]
CONTAINER_RUNTIME="docker"
CLUSTER_NETWORK="calico"
PROXY_MODE="ipvs"
SERVICE_CIDR="192.168.0.0/16"
CLUSTER_CIDR="172.16.0.0/16"
NODE_PORT_RANGE="20000-60000"
CLUSTER_DNS_DOMAIN="magedu.local."
bin_dir="/usr/bin"
ca_dir="/etc/kubernetes/ssl"
base_dir="/etc/ansible"
4.9.5.2)针对当前项目的主机和主机组的变量
上面的方式是针对所有项目都有效,而官方更建议的方式是使用 ansible 特定项目的主机变量和组变量。生产建议在项目目录中创建额外的两个变量目录,分别是 host_vars 和 group_vars。
host_vars:
下面的文件名和主机清单主机名一致,针对单个主机进行变量定义,格式:host_vars/hostname( 主机变量 )
group_vars:
下面的文件名和主机清单中组名一致,针对单个组进行变量定义,格式:gorup_vars/groupname( 分组变量 )
group_vars/all:
文件内定义的变量对所有组都有效( 公共变量 )
范例:
特定项目的主机变量和分组变量
建议:
主机清单不定义变量( 仅存放主机分组信息 )
变量统一定义在项目目录下的变量目录中( 条理非常清晰 )
# 创建项目目录
[root@ansible ansible] mkdir /data/ansible/test_project -p
[root@ansible ansible] cd /data/ansible/test_project
# 编写项目主机清单文件 ( 仅存放主机分组信息 )
[root@ansible test_project] vim hosts
[websrvs]
192.168.80.18
192.168.80.28
# 创建项目主机变量目录
[root@ansible test_project] mkdir host_vars
# 创建项目分组变量目录
[root@ansible test_project] mkdir group_vars
# 定义项目主机变量信息
[root@ansible test_project] vim host_vars/192.168.80.18
id: 1
[root@ansible test_project] vim host_vars/192.168.80.28
id: 2
# 定义项目分组变量信息
[root@ansible test_project] vim group_vars/websrvs
name: web
[root@ansible test_project] vim group_vars/all
domain: magedu.org
# 验证项目变量文件
[root@ansible test_project] tree host_vars/ group_vars/
host_vars/
├── 192.168.80.18
└── 192.168.80.28
group_vars/
├── all
└── websrvs
0 directories, 4 files
# 定义 PlayBook 文件
[root@ansible test_project] vim test.yml
- hosts: websrvs
tasks:
- name: get variable
command: echo "{{name}}{{id}}.{{domain}}"
register: result
- name: print variable
debug:
msg: "{{result.stdout}}"
# 执行
[root@ansible test_project] ansible-playbook test.yml

4.9.6)register 注册变量( 重要 )
参考:
https://blog.csdn.net/byygyy/article/details/105624602
在 PlayBook 中可以使用 register
将捕获命令的输出
保存在临时变量中
然后使用 debug 模块进行显示输出
范例:
利用 debug 模块输出变量
作用:
将 Shell 模块中命令的输出信息赋值给 register 注册变量中
注意:
ansible 执行结果一般都会返回一个字典类型的数据,你会看到很多你不关心的字段,可以通过指定字典的 key,例如 stdout 或 stdout_lines,只看到你关心的数据。
[root@ansible ~] vim register1.yml
- hosts: 192.168.80.18
tasks:
- name: "get variable"
shell: hostname
register: name
- name: "print variable"
debug:
msg: "{{ name }}" # 输出 register 注册的 name 变量的全部信息, 注意: 变量要加 "" 引起来
# msg: "{{ name.cmd }}" # 显示命令
# msg: "{{ name.rc }}" # 显示命令成功与否
# msg: "{{ name.stdout }}" # 显示命令的输出结果为字符串形式
# msg: "{{ name.stdout_lines }}" # 显示命令的输出结果为列表形式
# msg: "{{ name.stdout_lines[0] }}" # 显示命令的输出结果的列表中的第一个元素
# msg: "{{ name['stdout_lines'] }}" # 显示命令的执行结果为列表形式
// 说明
在第一个 task 中, 使用了 register 注册变量名为 name;
当 Shell 模块执行完毕后, 会将数据放到该
变量中.
在第二个 task 中, 使用了 debug 模块, 并从变量 name 中获取数据.
// 注意:
# 输出的 name 实际上相当于是一个字典
# 里面包含很多个键值对信息 ( 我们需要哪个键值对信息,需要指定性选择该键值 )
# 比如: name.stdout ( 在 name 变量后调用键信息 )
[root@centos8 ~] ansible-playbook register1.yml

ansible 执行结果一般都会返回一个字典类型的数据,以此你会看到很多你不关心的字段,我们可以通过指定字典的 key,例如 stdout 或 stdout_lines,只看到你关心的数据。
[root@ansible ~] vim register1.yml
- hosts: 192.168.80.18
tasks:
- name: "get variable"
shell: hostname
register: name
- name: "print variable"
debug:
msg: "{{ name.stdout }}" # 取 name 变量的 stdout 键值
[root@centos8 ~] ansible-playbook register1.yml

范例:
使用 register 注册变量
创建文件
[root@ansible ~] vim register2.yml
- hosts: websrvs
tasks:
- name: "get variable"
shell: hostname
register: name
- name: "create file"
file: dest=/root/{{ name.stdout }}.log state=touch
[root@ansible ~] ansible-playbook register2.yml
[root@centos8 ~] ll /root | grep log

范例:
register 和 debug 模块
参考:
https://www.cnblogs.com/dgp-zjz/p/15683546.html
自定义 debug 模块的输出结果( 默认输出的 msg 键内容 )
[root@ansible ~] vim debug_test.yml
---
- hosts: 192.168.80.8
tasks:
- shell: echo "hello world"
register: say_hi
- shell: "awk -F: 'NR==1{print $1}' /etc/passwd"
register: user
- debug:
var: say_hi.stdout # 自定义输出变量代替 msg
- debug:
var: user.stdout # 自定义输出变量代替 msg
[root@ansible ~] ansible-playbook debug_test.yml

范例:
安装启动服务并检查
[root@ansible ansible] vim service.yml
---
- hosts: websrvs
vars:
package_name: nginx
service_name: nginx
tasks:
- name: "install {{ package_name }}"
yum: name={{ package_name }}
- name: "start {{ service_name }}"
service: name={{ service_name }} state=started enabled=yes
- name: "check service status"
shell: ps aux | grep {{ service_name }}
register: check_service
- name: debug
debug:
msg: "{{ check_service.stdout_lines }}"
[root@ansible ansible] ansible-playbook service.yml

范例:
批量修改主机名
[root@ansible ansible] vim hostname.yml
- hosts: websrvs
vars:
host: web
domain: wuhanjiayou.cn
tasks:
- name: "get variable"
shell: echo $RANDOM | md5sum | cut -c 1-8
register: get_random
- name: "print variable"
debug:
msg: "{{ get_random.stdout }}"
- name: "set hostname"
hostname: name={{ host }}-{{ get_random.stdout }}.{{ domain }}
[root@ansible ansible] ansible-playbook hostname.yml