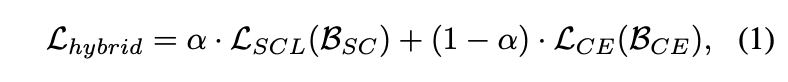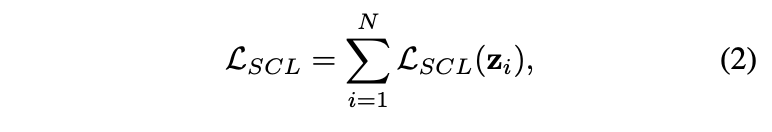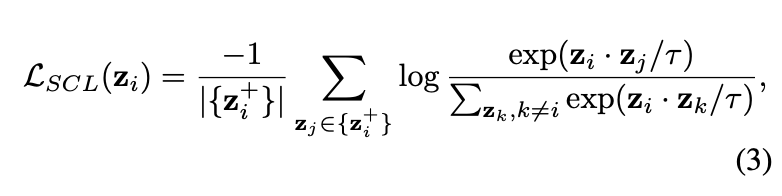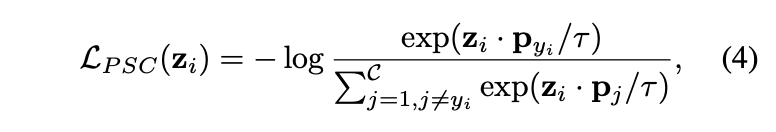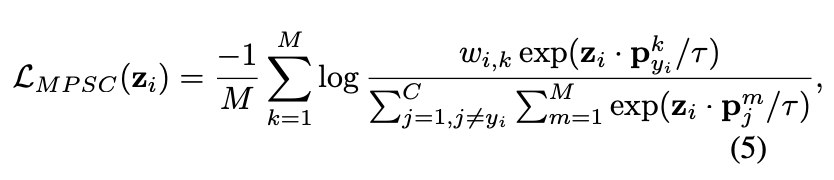一个可以让你有更多时间摸鱼的WPF控件(一)
前言
我们平时在开发软件的过程中,有这样一类比较常见的功能,它没什么技术含量,开发起来也没有什么成就感,但是你又不得不花大量的时间来处理它,它就是对数据的增删改查。当我们每增加一个需求就需要对应若干个页面来处理数据的添加、修改、删除、查询,每个页面因为数据字段的差异需要单独处理布局及排列,在处理数据录入或修改的过程中还需要校验数据的准确性。那么有没有什么方法可以简化这个过程,提升我们的工作效率?今天这篇文章我们来讨论这个问题。
一、
业
务分析
我们分析一下传统的开发流程,看看有哪些地方可以优化。
1.1 添加数据
数据录入的时候我们需要先确定要录入哪些数据,每条数据都是什么类型,然后在新增数据界面上设计布局,确认参数的排列方式,还需要做必要的数据校验工作,比如判断输入是否为空,判断电子邮箱格式是否正确,判断电话号码格式是否正确等,有时还需要在输入前提示一些必要的信息,比如告知用户正确的输入格式,限定输入的内容必须为某些字符等。
优化方案:
1)使用反射读取实体类属性,根据实体类的属性类型生成不同的数据录入控件。
2)实体类实现IDataErrorInfo接口,实现数据校验功能。
1.2 修改数据
基本与添加数据一致。
1.3 删除数据
选中数据后执行删除操作,基本无优化空间。
1.4 查询数据
查询数据一般使用DataGrid或ListView作为数据列表使用,DataGrid对很多表格功能做了封装,它可以对每行的数据进行编辑,可以自动生成列,如果不是特别复杂的需求使用DataGrid的自动列,确实可以节省很多工作,只要简单的绑定一下就可以使用这些功能。但是真实的业务场景需求千变万化,我们来看看会碰到哪些问题。
1) 设置自动列的时候,DataGrid列显示的是属性名,而属性名往往都是英文的,中文环境中基本都是使用中文列名。
2) 设置自动列的时候无法对数据进行格式化操作,无法使用转换器。
3) 设置自动列时无法对列的顺序做自定义排列。
4) 设置自动列时无法控制自定义列的排列,比如在第一列设置一个CheckBox复选框,在列尾设置编辑、删除按钮等。
5)设置自动列时无法单独指定某列的宽度。
6)设置自动列时无法单独隐藏某些列。
虽然以上问题也有解决方案,但是实现起来略显繁琐。
优化方案:
1)为实体类开发一个特性类(ColumnAttribute),添加列名、排序、宽度、是否可见、转换器、格式化字符串等属性。
2)添加一个ListView控件附加属性,读取以上特性,在ListView控件
附加属性
上实现以上功能。
二、
示
例代码
通过对业务需求的分析,我们总结出了几点优化方案,下面展示根据优化方案开发出来的Form控件,该控件可以大大节省开发期间枯燥的重复工作,提升工作效率。
View
<Windowx:Class="QuShi.Controls.Samples.Views.EntityEditorView1"xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"xmlns:i="http://schemas.microsoft.com/xaml/behaviors"xmlns:prism="http://prismlibrary.com/"Width="450"prism:ViewModelLocator.AutoWireViewModel="True"SizeToContent="Height"WindowStartupLocation="CenterScreen"> <StackPanelMargin="20"Orientation="Vertical"> <FormSource="{Binding Person}" /> <ButtonMargin="10"Padding="20,5"HorizontalAlignment="Center"Command="{Binding ConfirmCommand}"Content="提交" /> </StackPanel> </Window>
ViewModel
public classEntityEditorView1ViewModel : BindableBase
{public event Action<Person>Completed;privatePerson _person;publicPerson Person
{get =>_person;set => this.SetProperty(ref_person, value);
}public DelegateCommand<object>ConfirmCommand
{get{return new DelegateCommand<object>(parameter =>{if (!string.IsNullOrEmpty(Person.Error))
{
MessageBox.Show(Person.Error);
}else{
Completed?.Invoke(Person);
}
});
}
}
}
Model
public classPerson : ValidationObject
{private string_name;private DateTime _dateOfBirth =DateTime.Now;private int_age;private int _gender = 1;private string_phoneNumber;private string_email;private string_address;private string_idCardNumber;privateEducationInfo _education;privateMaritalStatus _maritalStatus;/// <summary> ///姓名/// </summary> [DisplayOrder(1)]
[DisplayHint("请填写姓名")]
[DisplayName("姓名")]
[StringLength(15, MinimumLength = 2, ErrorMessage = "姓名的有效长度为2-15个字符.")]
[Required(ErrorMessage= "姓名为必填项.")]
[Column(Name= "姓名", Order = 1)]public stringName
{get =>_name;set => this.SetProperty(ref_name, value);
}/// <summary> ///出生日期/// </summary> [DisplayOrder(2)]
[DisplayHint("请选择出生日期")]
[DisplayName("出生日期")]
[Required(ErrorMessage= "出生日期为必填项.")]
[Column(Name= "出生日期", StringFormat = "{0:yyyy年MM月dd日}", Order = 2)]publicDateTime DateOfBirth
{get =>_dateOfBirth;set => this.SetProperty(ref_dateOfBirth, value);
}/// <summary> ///年龄/// </summary> [DisplayOrder(3)]
[DisplayHint("请填写年龄")]
[DisplayName("年龄")]
[Range(1, 120, ErrorMessage = "年龄的有效值为1-120.")]
[Required(ErrorMessage= "年龄为必填项.")]
[Column(Name= "年龄", Order = 3)]public intAge
{get =>_age;set => this.SetProperty(ref_age, value);
}/// <summary> ///// 性别/// </summary> [DisplayOrder(4)]
[DisplayHint("请选择性别")]
[DisplayName("性别")]
[OverwriteType(HandleMethod.RadioButton,"1=男", "2=女", "3=其他")]
[Column(Name= "性别", Order = 4)]public intGender
{get =>_gender;set => this.SetProperty(ref_gender, value);
}/// <summary> ///手机号码/// </summary> [DisplayOrder(5)]
[DisplayHint("请填写电话号码")]
[DisplayName("电话号码")]
[Phone(ErrorMessage= "电话号码格式不正确.")]
[Column(Name= "电话号码", Order = 5)]public stringPhoneNumber
{get =>_phoneNumber;set => this.SetProperty(ref_phoneNumber, value);
}/// <summary> ///电子邮箱/// </summary> [DisplayOrder(6)]
[DisplayHint("请填写电子邮箱")]
[DisplayName("电子邮箱")]
[EmailAddress(ErrorMessage= "电子邮箱格式不正确.")]
[Column(Name= "电子邮箱", Order = 6)]public stringEmail
{get =>_email;set => this.SetProperty(ref_email, value);
}/// <summary> ///地址信息/// </summary> [DisplayOrder(7)]
[DisplayHint("请填写地址")]
[DisplayName("地址")]
[StringLength(50, ErrorMessage = "地址的最大长度为50个字符.")]
[Column(Name= "地址", Order = 7)]public stringAddress
{get =>_address;set => this.SetProperty(ref_address, value);
}/// <summary> ///身份证号码/// </summary> [DisplayOrder(8)]
[DisplayName("身份证号码")]
[DisplayHint("请填写身份证号码")]
[RegularExpression(RegexHelper.IdCardNumber, ErrorMessage= "身份证号码格式不正确.")]
[Column(Name= "身份证号码", Order = 8)]public stringIdCardNumber
{get =>_idCardNumber;set => this.SetProperty(ref_idCardNumber, value);
}/// <summary> ///教育信息/// </summary> [DisplayOrder(9)]
[DisplayHint("请填写教育信息")]
[DisplayName("教育信息")]
[Browsable(false)]publicEducationInfo Education
{get =>_education;set => this.SetProperty(ref_education, value);
}/// <summary> ///婚姻状况/// </summary> [DisplayOrder(10)]
[DisplayHint("请选择婚姻状况")]
[DisplayName("婚姻状况")]
[Column(Name= "婚姻状况", Order = 10)]publicMaritalStatus MaritalStatus
{get =>_maritalStatus;set => this.SetProperty(ref_maritalStatus, value);
}
}public classEducationInfo
{public string Degree { get; set; } //学位 public string Major { get; set; } //专业 public string School { get; set; } //学校 public DateTime GraduationDate { get; set; } //毕业日期 }public enumMaritalStatus
{/// <summary> ///单身/// </summary> [Description("单身")]
Single,/// <summary> ///已婚/// </summary> [Description("已婚")]
Married,/// <summary> ///离异/// </summary> [Description("离异")]
Divorced,/// <summary> ///丧偶/// </summary> [Description("丧偶")]
运行效果
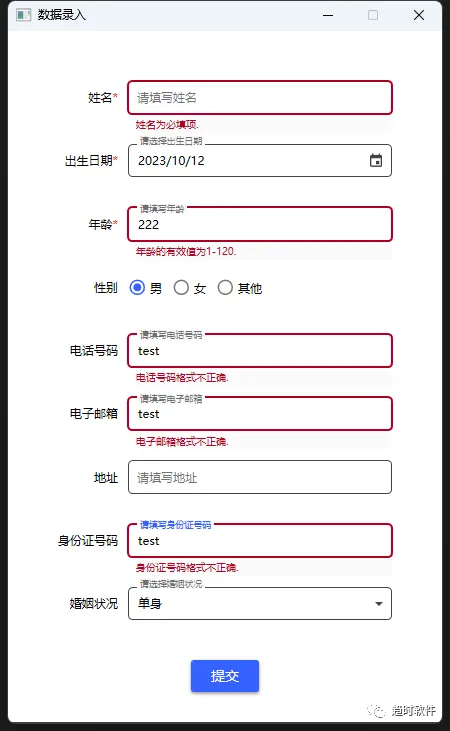
三、
答疑解惑
3.1 如何实现每个属性的自定义布局?
答:控件提供了默认外观,如果无法满足要求,也可以编辑控件模板,在相应的数据类型模板中修改布局代码,也可以只编辑某种类型的控件模板,下面展示修改String类型模板,其它类型基本相似。
<FormSource="{Binding Person}"> <Form.StringTemplate> <DataTemplate> <Grid> <Grid.RowDefinitions> <RowDefinitionSharedSizeGroup="RowHeight" /> </Grid.RowDefinitions> <Grid.ColumnDefinitions> <ColumnDefinitionWidth="Auto"SharedSizeGroup="Title" /> <ColumnDefinitionWidth="10" /> <ColumnDefinitionWidth="*" /> </Grid.ColumnDefinitions> <StackPanelHorizontalAlignment="Right"VerticalAlignment="Center"Orientation="Horizontal"> <TextBlockVerticalAlignment="Center"Text="{Binding Name}" /> <TextBlockVerticalAlignment="Center"Foreground="Red"Text="*"Visibility="{Binding IsRequired, Converter={StaticResource BooleanToVisibilityConverter}}" /> </StackPanel> <TextBoxGrid.Column="2"MinWidth="150"VerticalAlignment="Center"extensions:BindingExtensions.BindingProperty="{x:Static TextBox.TextProperty}"extensions:BindingExtensions.BindingSource="{Binding}" /> </Grid> </DataTemplate> </Form.StringTemplate> </Form>
3.2 如果控件模板中提供的基础数据类型没有我需要的属性类型,如何扩展新的属性类型?
答:控件提供了一个名为“CustomTypeTemplates”的属性来处理这个问题,以下为示例代码。
<FormSource="{Binding Person}"> <Form.CustomTypeTemplates> <CustomTypeDataTemplateCollection> <CustomTypeDataTemplateCustomType="{x:Type model:EducationInfo}"> <Grid> <Grid.RowDefinitions> <RowDefinitionSharedSizeGroup="RowHeight" /> </Grid.RowDefinitions> <Grid.ColumnDefinitions> <ColumnDefinitionWidth="Auto"SharedSizeGroup="Title" /> <ColumnDefinitionWidth="10" /> <ColumnDefinitionWidth="*" /> </Grid.ColumnDefinitions> <StackPanelHorizontalAlignment="Right"VerticalAlignment="Center"Orientation="Horizontal"> <TextBlockVerticalAlignment="Center"Text="{Binding Name}" /> <TextBlockVerticalAlignment="Center"Foreground="Red"Text="*"Visibility="{Binding IsRequired, Converter={StaticResource BooleanToVisibilityConverter}}" /> </StackPanel> <TextBoxGrid.Column="2"MinWidth="150"VerticalAlignment="Center"extensions:BindingExtensions.BindingProperty="{x:Static TextBox.TextProperty}"extensions:BindingExtensions.BindingSource="{Binding}" /> </Grid> </CustomTypeDataTemplate> </CustomTypeDataTemplateCollection> </Form.CustomTypeTemplates> </Form>
3.3 如果我想自定义某个属性名的模板,如何实现?
答:控件提供了一个名为“CustomNameTemplates”的属性来处理这个问题,以下为示例代码。
<FormSource="{Binding Person}"> <Form.CustomNameTemplates> <CustomNameDataTemplateCollection> <CustomNameDataTemplateCustomName="Name"> <Grid> <Grid.RowDefinitions> <RowDefinitionSharedSizeGroup="RowHeight" /> </Grid.RowDefinitions> <Grid.ColumnDefinitions> <ColumnDefinitionWidth="Auto"SharedSizeGroup="Title" /> <ColumnDefinitionWidth="10" /> <ColumnDefinitionWidth="*" /> </Grid.ColumnDefinitions> <StackPanelHorizontalAlignment="Right"VerticalAlignment="Center"Orientation="Horizontal"> <TextBlockVerticalAlignment="Center"Text="{Binding Name}" /> <TextBlockVerticalAlignment="Center"Foreground="Red"Text="*"Visibility="{Binding IsRequired, Converter={StaticResource BooleanToVisibilityConverter}}" /> </StackPanel> <TextBoxGrid.Column="2"MinWidth="150"VerticalAlignment="Center"extensions:BindingExtensions.BindingProperty="{x:Static TextBox.TextProperty}"extensions:BindingExtensions.BindingSource="{Binding}" /> </Grid> </CustomNameDataTemplate> </CustomNameDataTemplateCollection> </Form.CustomNameTemplates> </Form>
3.4 如果我想隐藏某些属性应该怎么做?
答:对属性设置“Browsable”特性,以下为示例代码。
[Browsable(false)]publicEducationInfo Education
{get =>_education;set => this.SetProperty(ref_education, value);
}
3.5 如何绑定枚举类型?
答:枚举在Form控件中默认显示为下拉框(ComboBox),只需要在枚举中设置"Description“特性就可以正常显示中文选项,如果不设置该属性则直接显示枚举名称。
public enumMaritalStatus
{/// <summary> ///单身/// </summary> [Description("单身")]
Single,/// <summary> ///已婚/// </summary> [Description("已婚")]
Married,/// <summary> ///离异/// </summary> [Description("离异")]
Divorced,/// <summary> ///丧偶/// </summary> [Description("丧偶")]
Widowed
}
3.6 如何绑定复杂属性,诸如单选框(RadioButton)、多选框(CheckBox)、下拉框(ComboBox)等?
答:控件读取一个名为”OverwriteType“的特性,特性中有一个名为“HandleMethod”的属性,该属性指明了覆盖当前类型的方式,并需要指定映射参数。
[OverwriteType(HandleMethod.RadioButton, "1=男", "2=女", "3=其他")]public intGender
{get =>_gender;set => this.SetProperty(ref_gender, value);
}
public enumHandleMethod
{
ComboBox,
CheckBox,
RadioButton
}
以上为数据添加及修改部分的优化实现,下一节讲解如何在查询列表中优化。