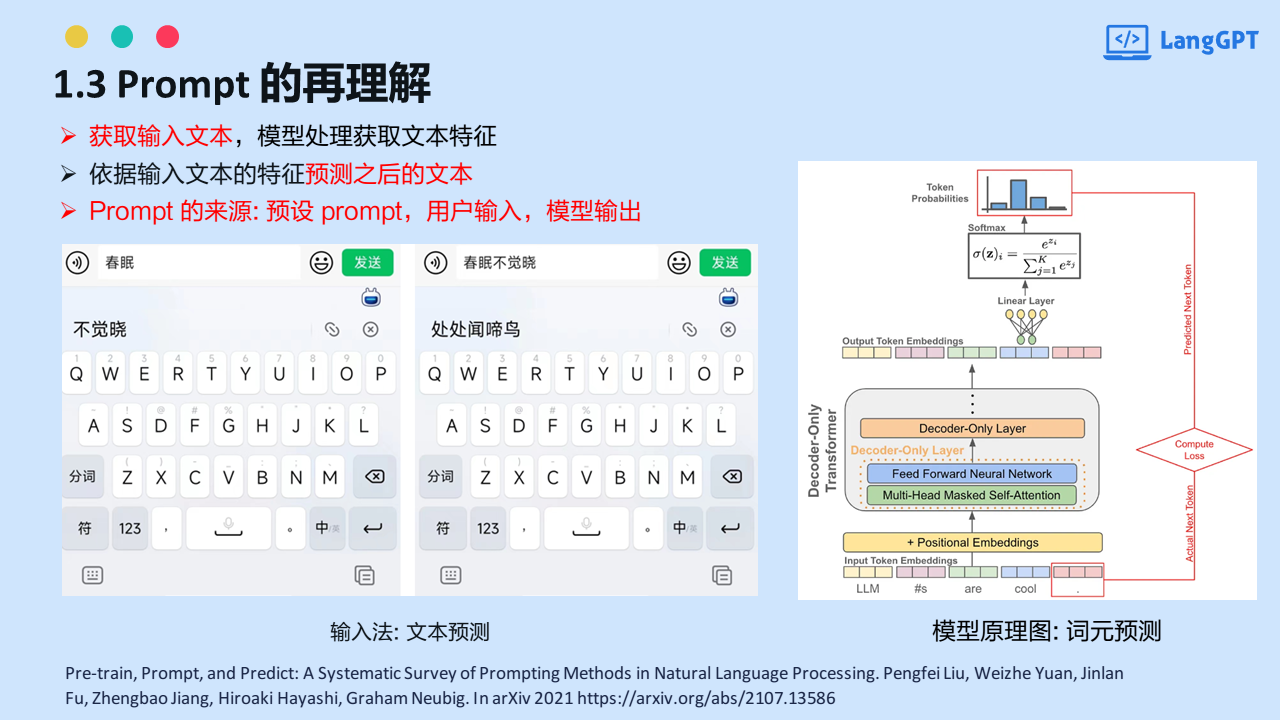
Pandas导出美化技巧,让你的Excel更出众
pandas
的
DataFrame
可以通过设置参数使得在
jupyter notebook
中显示的更加美观,
但是,将
DataFrame
的数据导出
excel
时,却只能以默认最朴素的方式将数据写入
excel
。
本文介绍一种简单易用,让导出的
excel
更加美观的方法。
1. 概要
首先,引入一个库
StyleFrame
,这个库封装
pandas
和
openpyxl
,让我们轻松的设置
DataFrame
的样式并导出到
excel
中。
安装很简单:
pip install styleframe
这个库主要包含3个模块:
styleframe
:相当于这个库的主入口,它封装了
DataFrame
对象。styler
:用来单元格的样式。utils
:常用样式元素的辅助类,比如数字和日期格式、颜色和边框类型等。
安装成功之后,下面通过示例看看如何使用。
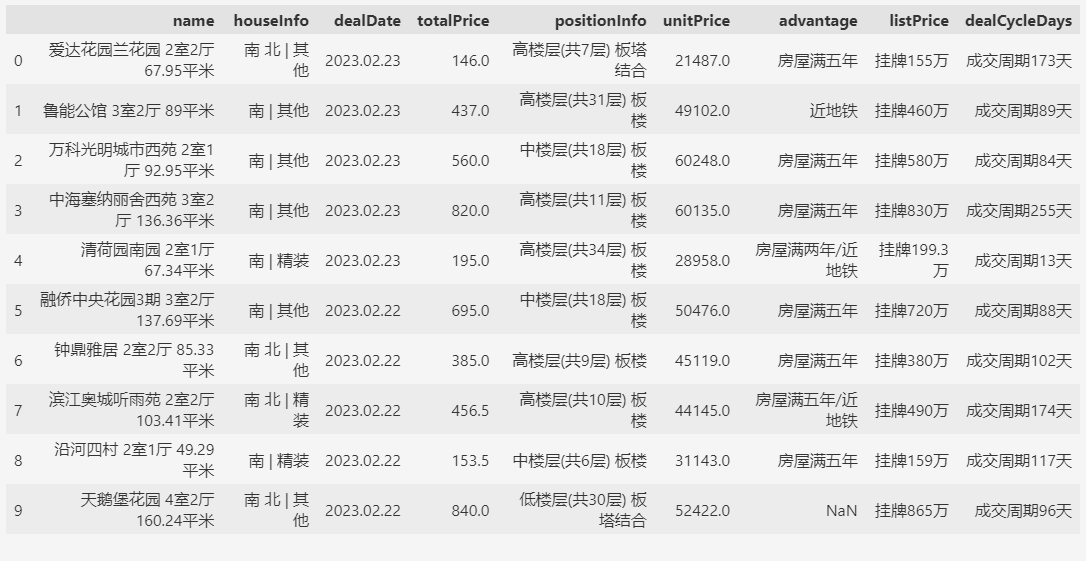
2. 准备数据
下面示例中使用的数据采集自链家网的真实成交数据。
数据下载地址:
https://databook.top/。
导入数据:
import pandas as pd
fp = "D:/data/南京二手房交易/南京建邺区.csv"
df = pd.read_csv(fp)
# 为了简化,只取10条数据来演示导出效果
df = df.head(10)
3. 行列设置
先看看默认导出
excel
的效果。
output = "d:\data\output.xlsx"
df.to_excel(output, index=None)
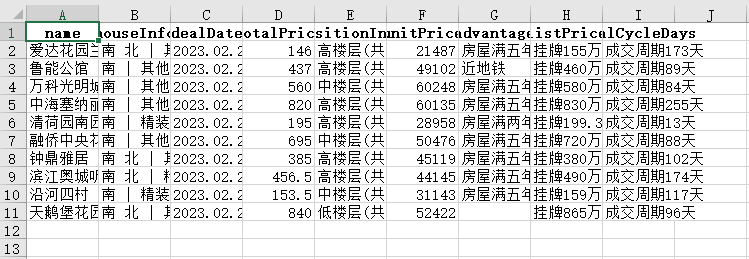
默认导出的样式就是这样,所有单元格都一样,不管单元格的内容是什么。
3.1. 设置自适应
第一步,我们设置内容自适应(
shrink_to_fit
),确保每个单元格中的内容能够完整显示。
from styleframe import StyleFrame, Styler, utils
style = Styler(shrink_to_fit=True)
sf = StyleFrame(df, styler_obj=style)
writer = sf.to_excel(output)
writer.close()
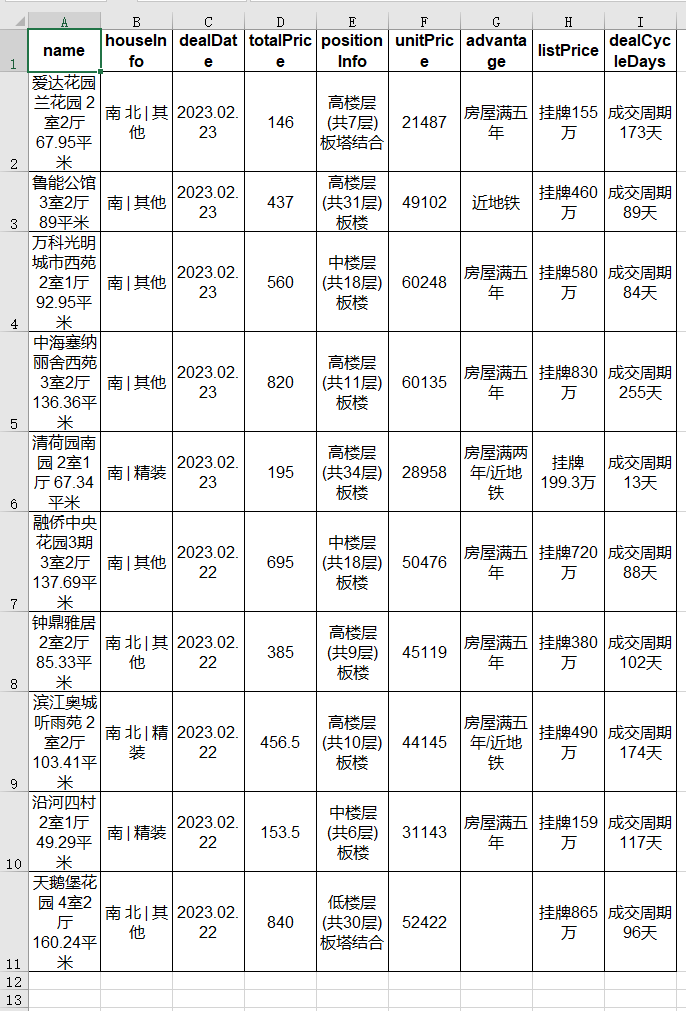
可以看出,
StyleFrame
的默认导出样式,给有数据的表格加了边框。
使用
shrink_to_fit=True
样式之后,每个单元格的内容可以完整显示了。
3.2. 设置列宽
从上面的效果,我们发现,所有列的宽度是一样的,无论列中的内容有多长。
我们可以设置某些文字内容比较多列更宽一些。
sf.set_column_width_dict(
{
"name": 25,
"positionInfo": 20,
"advantage": 15,
"dealCycleDays": 16,
}
)
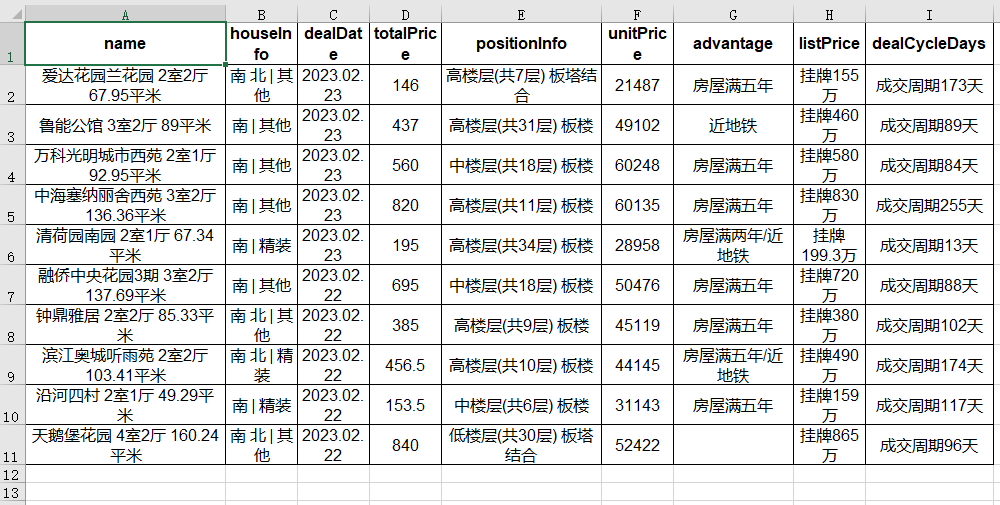
调整之后,内容看起来更清晰了。
3.3. 设置表头,内容
接下来,我们通过
字号
,
对齐方式
,
背景色
以及
是否加粗
来区分
表头
和
内容
部分。
header_style = Styler(
bg_color="yellow",
bold=True,
font_size=12,
horizontal_alignment=utils.horizontal_alignments.center,
vertical_alignment=utils.vertical_alignments.center,
)
content_style = Styler(
shrink_to_fit=True,
font_size=8,
horizontal_alignment=utils.horizontal_alignments.left,
)
sf.apply_column_style(sf.columns, content_style)
sf.apply_headers_style(header_style)
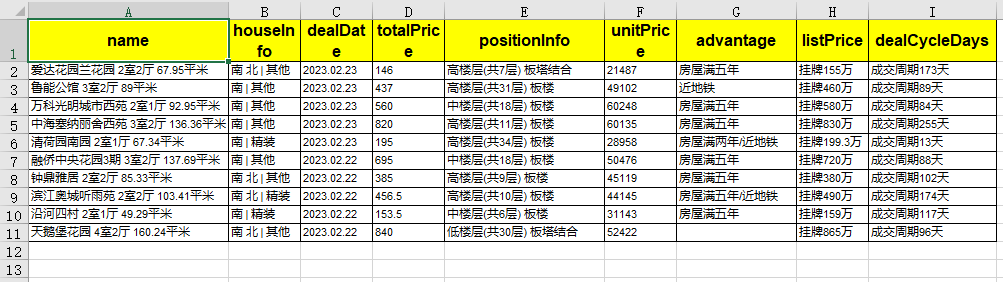
内容更加紧凑了,表头部分也更突出了。
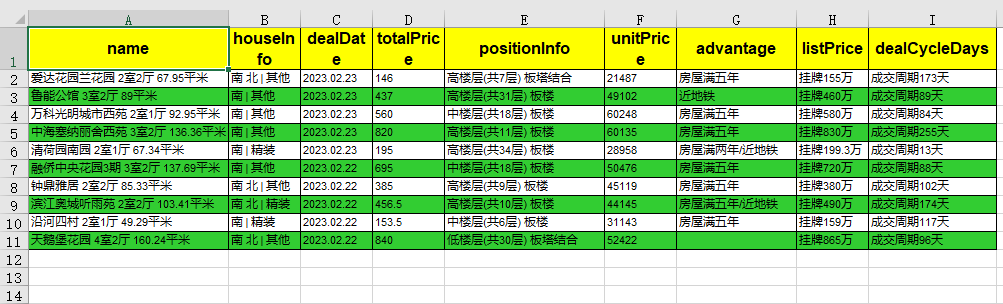
3.4. 设置行间隔颜色
最后,我们在优化下内容显示部分,用不同的背景色区分
奇数行
和
偶数行
。
row_style = Styler(
bg_color="#32CD32",
shrink_to_fit=True,
font_size=8,
horizontal_alignment=utils.horizontal_alignments.left,
)
# 计算要设置背景色的行索引
indexes = list(range(1, len(sf), 2))
sf.apply_style_by_indexes(indexes, styler_obj=row_style)
4. 样式设置
样式设置主要是
Styler
这个模块提供的功能。
通过
Styler
类提供的接口,我们可以设置灵活的控制导出的样式。
4.1. 字体
我们给第一行设置不同的字体(
font="STKaiti"
),看看导出的效果:
first_line_style = Styler(
shrink_to_fit=True,
font="STKaiti",
font_size=14,
horizontal_alignment=utils.horizontal_alignments.left,
)
sf.apply_style_by_indexes(indexes_to_style=[0], styler_obj=first_line_style)
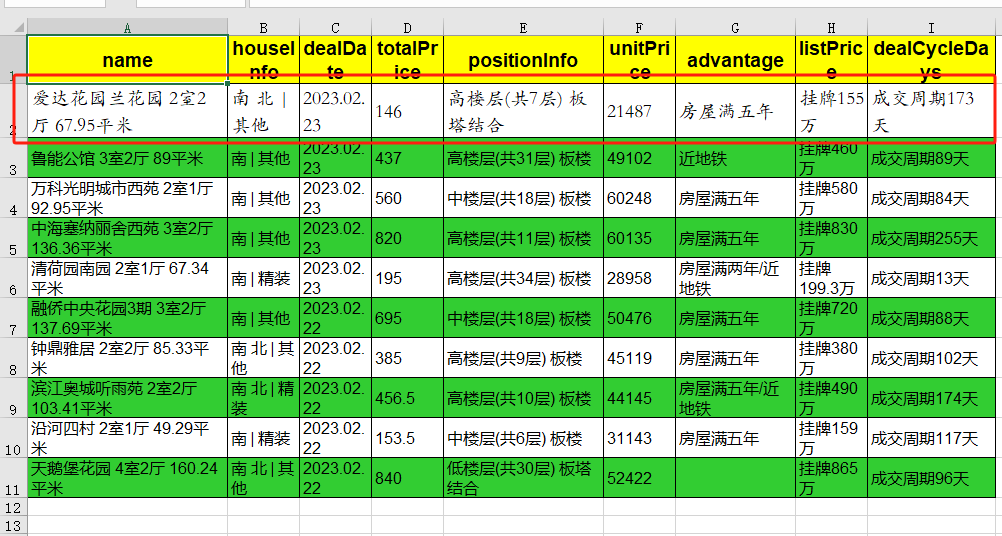
第一行的字体是
华文楷体
,和其他行不一样。
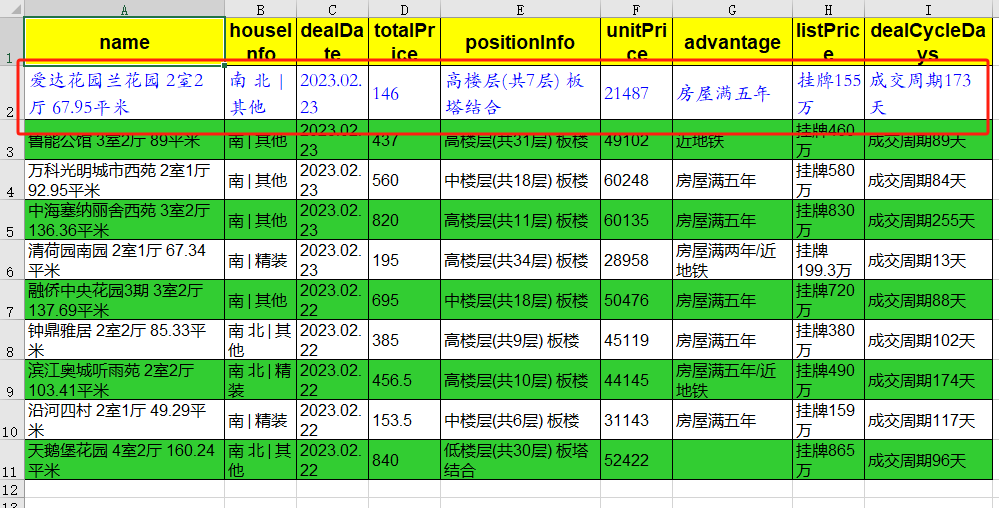
4.2. 颜色
再把第一行的字调成蓝色(
font_color="blue"
)。
first_line_style = Styler(
shrink_to_fit=True,
font="STKaiti",
font_size=14,
font_color="blue",
horizontal_alignment=utils.horizontal_alignments.left,
)
sf.apply_style_by_indexes(indexes_to_style=[0], styler_obj=first_line_style)
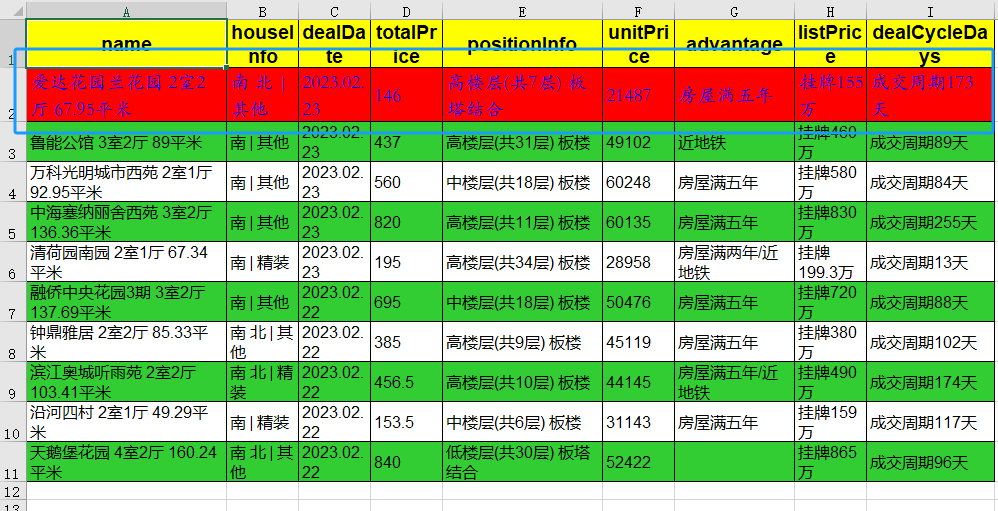
4.3. 背景色
再给第一行加一个红色背景(
bg_color="red"
)。
first_line_style = Styler(
shrink_to_fit=True,
font="STKaiti",
font_size=14,
font_color="blue",
bg_color="red",
horizontal_alignment=utils.horizontal_alignments.left,
)
sf.apply_style_by_indexes(indexes_to_style=[0], styler_obj=first_line_style)
4.4. 边框
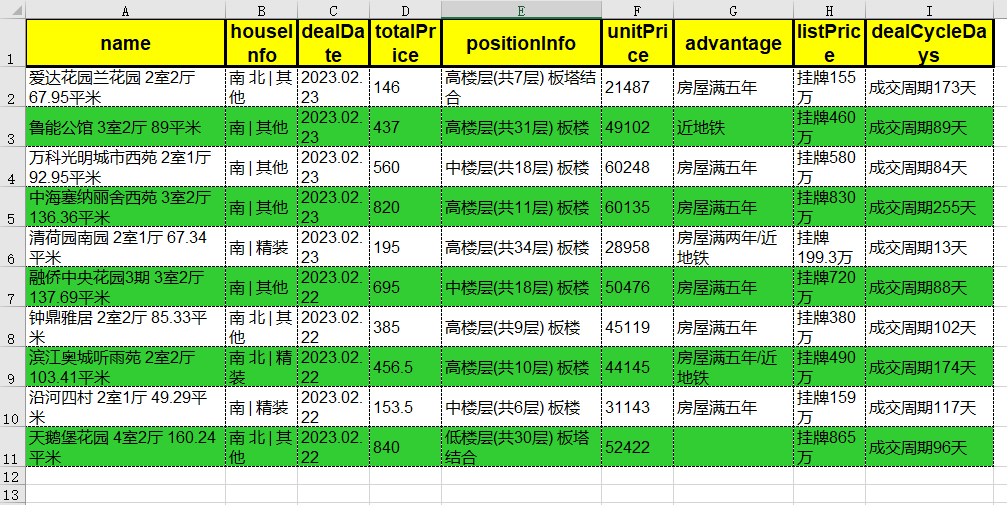
边框
是区隔,突出内容的一种手段,比如,我们可以在表头部分用
实线粗边框
(
border_type=utils.borders.thick
),内容部分用
虚线细边框
(
border_type=utils.borders.dashed
)。
header_style = Styler(
bg_color="yellow",
bold=True,
font_size=14,
border_type=utils.borders.thick,
)
content_style = Styler(
shrink_to_fit=True,
font_size=12,
border_type=utils.borders.dashed,
)
sf.apply_column_style(sf.columns, content_style)
sf.apply_headers_style(header_style)
4.5. 数字和日期
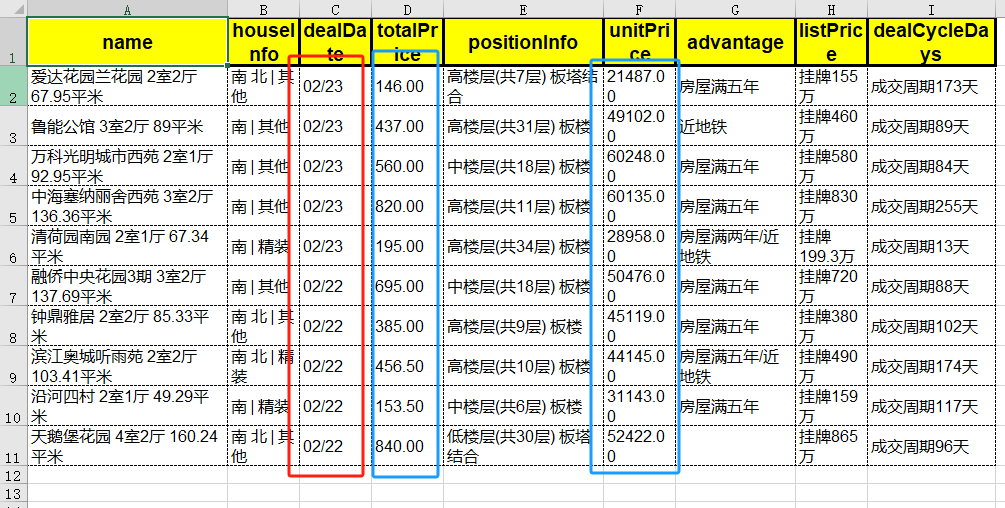
最后,看看如何定制数字(
number_format
)和日期(
date_format
)的显示方式。
我们把上面示例中的总价(
totalPrice
)保留两位小数,日期(
DealDate
)改为只显示月和日。
num_style = Styler(
shrink_to_fit=True,
font_size=12,
number_format=utils.number_formats.general_float,
border_type=utils.borders.dashed,
horizontal_alignment=utils.horizontal_alignments.left,
)
sf.apply_column_style(["totalPrice", "unitPrice"], num_style)
date_style = Styler(
shrink_to_fit=True,
font_size=12,
date_format="DD/MM",
border_type=utils.borders.dashed,
horizontal_alignment=utils.horizontal_alignments.left,
)
sf.apply_column_style("dealDate", date_style)
5. 总结
导出分析结果
是我们做数据分析的最后一步,也是最容易被忽视的一步。
我们常常把大部分的精力都会花在数据的整理和分析上,最后给客户提供一个简易的报告和数据。
殊不知,导出一个美观清晰的分析结果和数据,反而更能得到客户的肯定和信任,因为这才是客户能够切身感知到的部分,否则花在数据整理和分析的精力再多,也不能让客户有直接的感受。