C#版开源免费的Bouncy Castle密码库
前言
今天大姚给大家分享一款C#版开源、免费的Bouncy Castle密码库:BouncyCastle。
项目介绍
BouncyCastle是一款C#版开源、免费的Bouncy Castle密码库,开发人员可以通过该项目在他们的 C# 应用程序中使用 Bouncy Castle 提供的各种密码学功能,从而加强数据的安全性和保护隐私信息。
Bouncy Castle介绍
Bouncy Castle是一个流行的密码学库,提供了广泛的密码算法和协议的实现(包括对称加密、非对称加密、哈希函数、数字签名等)。它由澳大利亚注册的慈善组织“Bouncy Castle军团”开发,旨在提供可靠而安全的加密解决方案。
项目源代码


创建控制台应用
创建一个名为:
BouncyCastleExercise
的控制台。


安装BouncyCastle包
搜索名为:
BouncyCastle.Cryptography
包安装:

BouncyCastle使用示例
internal class Program
{
static void Main(string[] args)
{
#region AES加密解密示例
string aesPlaintext = "Hello, 追逐时光者!!!";
byte[] aesKey = new byte[16];
byte[] aesIV = new byte[16];
byte[] aesCiphertext = EncryptAES(aesPlaintext, aesKey, aesIV);
string decryptedAesPlaintext = DecryptAES(aesCiphertext, aesKey, aesIV);
Console.WriteLine("AES plaintext: " + aesPlaintext);
Console.WriteLine("AES ciphertext: " + Convert.ToBase64String(aesCiphertext));
Console.WriteLine("Decrypted AES plaintext: " + decryptedAesPlaintext);
#endregion
#region DES 加密解密示例
string desPlaintext = "Hello, DES!";
byte[] desKey = new byte[8];
byte[] desIV = new byte[8];
byte[] desCiphertext = EncryptDES(desPlaintext, desKey, desIV);
string decryptedDesPlaintext = DecryptDES(desCiphertext, desKey, desIV);
Console.WriteLine("DES plaintext: " + desPlaintext);
Console.WriteLine("DES ciphertext: " + Convert.ToBase64String(desCiphertext));
Console.WriteLine("Decrypted DES plaintext: " + decryptedDesPlaintext);
#endregion
#region RC4 加密解密示例
string rc4Plaintext = "Hello, RC4!";
byte[] rc4Key = new byte[16];
byte[] rc4Ciphertext = EncryptRC4(rc4Plaintext, rc4Key);
string decryptedRc4Plaintext = DecryptRC4(rc4Ciphertext, rc4Key);
Console.WriteLine("RC4 plaintext: " + rc4Plaintext);
Console.WriteLine("RC4 ciphertext: " + Convert.ToBase64String(rc4Ciphertext));
Console.WriteLine("Decrypted RC4 plaintext: " + decryptedRc4Plaintext);
#endregion
#region 哈希算法示例
// MD5 示例
string md5Plaintext = "Hello, MD5!";
string md5Hash = CalculateMD5Hash(md5Plaintext);
Console.WriteLine("MD5 hash of 'Hello, MD5!': " + md5Hash);
// SHA1 示例
string sha1Plaintext = "Hello, SHA1!";
string sha1Hash = CalculateSHA1Hash(sha1Plaintext);
Console.WriteLine("SHA1 hash of 'Hello, SHA1!': " + sha1Hash);
// SHA256 示例
string sha256Plaintext = "Hello, SHA256!";
string sha256Hash = CalculateSHA256Hash(sha256Plaintext);
Console.WriteLine("SHA256 hash of 'Hello, SHA256!': " + sha256Hash);
#endregion
}
#region AES加密解密示例
/// <summary>
/// AES 加密方法
/// </summary>
/// <param name="plaintext">plaintext</param>
/// <param name="key">key</param>
/// <param name="iv">iv</param>
/// <returns></returns>
public static byte[] EncryptAES(string plaintext, byte[] key, byte[] iv)
{
IBufferedCipher cipher = CipherUtilities.GetCipher("AES/CTR/PKCS7Padding");
cipher.Init(true, new ParametersWithIV(ParameterUtilities.CreateKeyParameter("AES", key), iv));
return cipher.DoFinal(System.Text.Encoding.UTF8.GetBytes(plaintext));
}
/// <summary>
/// AES 解密方法
/// </summary>
/// <param name="ciphertext">ciphertext</param>
/// <param name="key">key</param>
/// <param name="iv">iv</param>
/// <returns></returns>
public static string DecryptAES(byte[] ciphertext, byte[] key, byte[] iv)
{
IBufferedCipher cipher = CipherUtilities.GetCipher("AES/CTR/PKCS7Padding");
cipher.Init(false, new ParametersWithIV(ParameterUtilities.CreateKeyParameter("AES", key), iv));
byte[] plaintext = cipher.DoFinal(ciphertext);
return System.Text.Encoding.UTF8.GetString(plaintext);
}
#endregion
#region DES 加密解密示例
/// <summary>
/// DES 加密方法
/// </summary>
/// <param name="plaintext">plaintext</param>
/// <param name="key">key</param>
/// <param name="iv">iv</param>
/// <returns></returns>
public static byte[] EncryptDES(string plaintext, byte[] key, byte[] iv)
{
IBufferedCipher cipher = CipherUtilities.GetCipher("DES/CBC/PKCS7Padding");
cipher.Init(true, new ParametersWithIV(ParameterUtilities.CreateKeyParameter("DES", key), iv));
return cipher.DoFinal(System.Text.Encoding.UTF8.GetBytes(plaintext));
}
/// <summary>
/// DES 解密方法
/// </summary>
/// <param name="ciphertext">ciphertext</param>
/// <param name="key">key</param>
/// <param name="iv">iv</param>
/// <returns></returns>
public static string DecryptDES(byte[] ciphertext, byte[] key, byte[] iv)
{
IBufferedCipher cipher = CipherUtilities.GetCipher("DES/CBC/PKCS7Padding");
cipher.Init(false, new ParametersWithIV(ParameterUtilities.CreateKeyParameter("DES", key), iv));
byte[] plaintext = cipher.DoFinal(ciphertext);
return System.Text.Encoding.UTF8.GetString(plaintext);
}
#endregion
#region RC4 加密解密示例
/// <summary>
/// RC4 加密方法
/// </summary>
/// <param name="plaintext">plaintext</param>
/// <param name="key">key</param>
/// <returns></returns>
public static byte[] EncryptRC4(string plaintext, byte[] key)
{
IStreamCipher cipher = new RC4Engine();
cipher.Init(true, new KeyParameter(key));
byte[] data = System.Text.Encoding.UTF8.GetBytes(plaintext);
byte[] ciphertext = new byte[data.Length];
cipher.ProcessBytes(data, 0, data.Length, ciphertext, 0);
return ciphertext;
}
/// <summary>
/// RC4 解密方法
/// </summary>
/// <param name="ciphertext">ciphertext</param>
/// <param name="key">key</param>
/// <returns></returns>
public static string DecryptRC4(byte[] ciphertext, byte[] key)
{
IStreamCipher cipher = new RC4Engine();
cipher.Init(false, new KeyParameter(key));
byte[] plaintext = new byte[ciphertext.Length];
cipher.ProcessBytes(ciphertext, 0, ciphertext.Length, plaintext, 0);
return System.Text.Encoding.UTF8.GetString(plaintext);
}
#endregion
#region 哈希算法示例
/// <summary>
/// 计算 MD5 哈希
/// </summary>
/// <param name="input">input</param>
/// <returns></returns>
public static string CalculateMD5Hash(string input)
{
IDigest digest = new MD5Digest();
byte[] hash = new byte[digest.GetDigestSize()];
byte[] data = System.Text.Encoding.UTF8.GetBytes(input);
digest.BlockUpdate(data, 0, data.Length);
digest.DoFinal(hash, 0);
return Convert.ToBase64String(hash);
}
/// <summary>
/// 计算 SHA1 哈希
/// </summary>
/// <param name="input">input</param>
/// <returns></returns>
public static string CalculateSHA1Hash(string input)
{
IDigest digest = new Sha1Digest();
byte[] hash = new byte[digest.GetDigestSize()];
byte[] data = System.Text.Encoding.UTF8.GetBytes(input);
digest.BlockUpdate(data, 0, data.Length);
digest.DoFinal(hash, 0);
return Convert.ToBase64String(hash);
}
/// <summary>
/// 计算 SHA256 哈希
/// </summary>
/// <param name="input">input</param>
/// <returns></returns>
public static string CalculateSHA256Hash(string input)
{
IDigest digest = new Sha256Digest();
byte[] hash = new byte[digest.GetDigestSize()];
byte[] data = System.Text.Encoding.UTF8.GetBytes(input);
digest.BlockUpdate(data, 0, data.Length);
digest.DoFinal(hash, 0);
return Convert.ToBase64String(hash);
}
#endregion
}
输出结果:

项目源码地址
更多项目实用功能和特性欢迎前往项目开源地址查看
FreeRTOS教程3 中断管理
1、准备材料
STM32CubeMX软件(
Version 6.10.0
)
Keil µVision5 IDE(
MDK-Arm
)
2、学习目标
本文主要学习 FreeRTOS 中断管理的相关知识,
包括系统硬件中断、 FreeRTOS 可管理的中断、中断屏蔽和一些其他注意事项等知识
3、前提知识
3.1、STM32 的硬件中断
根据
STM32CubeMX教程4 EXTI 按键外部中断
实验 “3、中断系统概述表” 小节内容可知
- STM32F4 系列有 10 个系统中断和82个可屏蔽的外部中断
- 嵌套向量中断控制器(NVIC)采用 4 位二进制数表示中断优先级,这 4 位二进制数表示的中断优先级又分为了抢占优先级和次优先级
当启用FreeRTOS之后,NVIC中断分组策略采用 4 位抢占优先级且不可修改,
对于 STM32 的硬件优先级来说,优先级数字越小表示优先级越高,最高优先级为0
,如下所示为 STM32 的中断列表

3.2、FreeRTOS 可管理的中断
对于 STM32 处理器所有的硬件中断来说,其中有些可以被 FreeRTOS 软件管理,而有些特别重要的中断则不能够被 FreeRTOS 软件所管理
,这很好理解,比如系统的硬件 Reset 中断,如果 Reset 中断可以被FreeRTOS所管理,那么在系统死机时用户需要硬件复位,但 FreeRTOS 不能响应最终导致无法复位从而卡死
那么哪些硬件中断可以被 FreeRTOS 所管理呢?
这由
configLIBRARY_LOWEST_INTERRUPT_PRIORITY
(中断的最低优先级数值) 和
configLIBRARY_MAX_SYSCALL_INTERRUPT_PRIORITY
(FreeRTOS可管理的最高优先级) 两个参数决定,由于 NVIC 中断分组策略采用 4 位抢占优先级,因此中断最低优先级数值为 15 ,而 FreeRTOS 可管理的最高优先级默认设置为 5
当配置参数 configLIBRARY_LOWEST_INTERRUPT_PRIORITY = 15 , configLIBRARY_MAX_SYSCALL_INTERRUPT_PRIORITY = 5 时,则表示
在 STM32 的所有硬件中断中优先级为 0~4 的中断 FreeRTOS 不可管理,而对于中断优先级为 5~15 的中断 FreeRTOS 可以管理
,具体如下图所示

3.3、何为上下文?
在操作系统和嵌入式系统中,上下文(Context)是指程序执行过程中的当前状态,包括所有的寄存器值、程序计数器(PC)值以及其他与执行环境相关的状态信息。
上下文记录了程序执行的位置和状态,使得程序可以在中断、任务切换或函数调用等场景下进行正确的恢复和继续执行
在 FreeRTOS 中,上下文通常与任务(Task)或中断处理函数相关联。当任务切换发生时,当前任务的上下文会被保存,然后将控制权转移到下一个任务,该任务的上下文会被恢复以便继续执行。类似地,当中断发生时,处理器会保存当前执行任务的上下文,并在中断处理完毕后,恢复之前任务的上下文以继续执行。
3.4、在 ISR 中使用 FreeRTOS API 函数
3.4.1、中断安全版本 API
通常需要在中断服务例程 (ISR) 中使用 FreeRTOS API 函数提供的功能,
但许多 FreeRTOS API 函数执行的操作在 ISR 内无效
,比如能够让任务进入阻塞状态的 API 函数,如果从 ISR 调用这些 API 函数,因为它不是从任务调用,所以没有有效的调用任务使其进入阻塞状态
因此对于一些 API 函数,
FreeRTOS 提供了两种不同版本,一种版本供任务使用,另一种版本供 ISR 使用
,在 ISR 中使用的函数名称后面带有 “FromISR” 的后缀,关于这种设计的优缺点,感兴趣的读者可以自行阅读 “
Mastering_the_FreeRTOS_Real_Time_Kernel-A_Hands-On_Tutorial_Guide.pdf
” 6.2小节内容
3.4.2、
xHigherPriorityTaskWoken
参数
xHigherPriorityTaskWoken
参数是中断安全版本 API 中常见的一个参数,该参数用于通知应用程序编写者在退出 ISR 时是否应该进行上下文切换
,因为在执行某个中断期间,在进入中断时和退出中断后多个任务的状态可能发生了改变,也即可能存在中断某个任务,但返回另外一个任务的情况发生
如果通过 FreeRTOS API 函数解锁的任务的优先级高于运行状态任务的优先级,则根据 FreeRTOS 调度策略,应切换到更高优先级的任务,但究竟何时实际切换到更高优先级的任务则取决于调用 API 函数的上下文,有以下两种情况
- 如果 API 函数是从任务中调用的,那么在抢占式调度策略下,在 API 函数退出之前,API 函数内会自动切换到更高优先级的任务
- 如果 API 函数是从 ISR 中调用的,那么在中断中不会自动切换到更高优先级的任务,但是可以设置一个变量来通知应用程序编写者应该执行上下文切换,也就是 FreeRTOS 中断安全版本的 API 函数中经常见到的
xHigherPriorityTaskWoken
参数
如果应执行上下文切换,则中断安全 API 函数会将
pxHigherPriorityTaskWoken
设置为 pdTRUE ,而且只能将其设置为 pdTRUE ,所以
pxHigherPriorityTaskWoken
指向的变量必须在第一次使用之前初始化为 pdFALSE
如果不通过上述的方法在退出 ISR 前执行上下文切换,那么最坏的情况就是本来应该在退出 ISR 时切换到某个高优先级的任务进行执行,但现在只能将其转为就绪状态,直到下一个滴答定时器到来进行上下文切换其才会转为运行状态
3.4.3、portYIELD_FROM_ISR() 和 portEND_SWITCHING_ISR() 宏
在
FreeRTOS教程2 任务管理
文章 "3.8、任务调度方法" 小节中,介绍了主动让位于另一项同等优先级任务的 API 函数 taskYIELD() ,它是一个可以在任务中调用来请求上下文切换的宏,
portYIELD_FROM_ISR() 和 portEND_SWITCHING_ISR() 都是 taskYIELD() 的中断安全版本,他们两个的使用方式相同,并且执行相同的操作
3.4.4、简单总结
所以根据上面几个小节的叙述,如果我们希望在 ISR 中使用 FreeRTOS 提供的 API 函数,则应该使用这些 API 函数的中断安全版本,并且通过
xHigherPriorityTaskWoken
参数和 portYIELD_FROM_ISR() 宏在退出 ISR 之前进行可能的上下文切换,其可能的一种应用结构如下所示
/*一个可能的在中断中使用FreeRTOS API函数,然后进行上下文切换的例子*/
void An_Interrupt_Instance_Function(void)
{
//定义一个用于通知应用程序编程者是否应该进行上下文切换的变量,必须初始化为pdFALSE
BaseType_t highTaskWoken = pdFALSE;
//使用二值信号量API函数做演示
if(BinarySem_Handle != NULL)
{
//将中断安全版本API函数的pxHigherPriorityTaskWoken参数指向 highTaskWoken
xSemaphoreGiveFromISR(BinarySem_Handle, &highTaskWoken);
//根据highTaskWoken决定是否要进行上下文切换
portYIELD_FROM_ISR(highTaskWoken);
}
}
但是不是所有中断中都可以使用 FreeRTOS 提供的 API 函数,在 ISR 中使用 FreeRTOS API 函数总结如下所述
- 对于FreeRTOS可屏蔽的ISR中,如果要调用 FreeRTOS API 函数,则应该使用 FreeRTOS API 的中断安全版本函数(函数名末尾为FromISR或FROM_ISR),不可以使用任务级的API函数
- 对于FreeRTOS不可屏蔽的ISR中,不能够调用任何 FreeRTOS API函数
另外在 STM32CubeMX 软件 NVIC 配置界面中,如果在某个中断后面勾选了 “Uses FreeRTOS functions” 选项,根据上面的两点描述可知,只能在 FreeRTOS 可屏蔽的ISR中使用 FreeRTOS API 函数,所以该中断优先级可选范围会被强制到 15~5 之间,具体如下图所示

3.5、任务优先级和中断优先级
任务优先级为软件设置的一个属性,设置范围为1~(configMAX_PRIORITIES-1),数字越大优先级越高
,在抢占式调度方式中高优先级的任务可以抢占低优先级的任务
中断优先级为硬件响应优先级,中断分组策略4位全用于抢占优先级的中断优先级数字设置范围为0-15,数字越小优先级越高
对于大多数的系统,其既会存在多个不同优先级的任务,同时也会存在多个不同优先级的中断,它们之间的执行顺序应该如下图所示

3.6、延迟中断处理
通常认为最佳实践是使 ISR 尽可能短,下面列出了可能的几条原因
- 即使任务被分配了非常高的优先级,它们也只有在硬件没有中断服务时才会运行
- ISR 会扰乱(添加“抖动”)任务的开始时间和执行时间
- 应用程序编写者需要考虑任务和 ISR 同时访问变量、外设和内存缓冲区等资源的后果,并防范这些资源
- 某些 FreeRTOS 端口允许中断嵌套,但中断嵌套会增加复杂性并降低可预测性,中断越短,嵌套的可能性就越小
什么时延迟中断处理?
中断服务程序必须记录中断原因,并清除中断。
中断所需的任何其他处理通常可以在任务中执行,从而允许中断服务例程尽可能快地退出,这称为“延迟中断处理”,因为中断所需的处理从 ISR “延迟” 到任务。
举个例子,比如在 ADC 周期采集中,当一轮采集完成之后,ADC 采集完成中断回调函数只负责将采集完成的值写入缓存区,然后由其他任务对缓存区中的数据进行更复杂处理
将中断处理推迟到任务还允许应用程序编写者相对于应用程序中的其他任务确定处理的优先级,并能够使用所有 FreeRTOS API 函数
如果中断处理被推迟的任务的优先级高于任何其他任务的优先级,则处理将立即执行,就像处理已在 ISR 本身中执行一样。这种场景如下图所示,其中任务 1 是普通应用程序任务,任务 2 是中断处理被推迟的任务

那么什么情况下需要进行延迟中断处理操作呢?
没有具体绝对的规则,在以下列出的几点情况下,将处理推迟到任务可能比较有用:
- 中断所需的处理并不简单。比如上面的举例,如果 ADC 仅仅需要采集值,那么在采集完成中断回调函数中将采集值写入缓存区即可,但是如果还需要对采集值进行复杂处理,那么最好推迟到任务中完成
- 中断处理是不确定的 - 这意味着事先不知道处理需要多长时间。
3.7、进行中断屏蔽
FreeRTOS 中为什么要屏蔽中断?
想象这样一个场景,当一个中等优先级的任务 TASK1 正在通过串口输出字符串 “Hello world!” 并且刚好输出到 ”Hello“ 时,另外一个高级优先级的任务 TASK2 突然抢占 TASK1 ,然后通过串口输出字符串 “lc_guo” ,当两个任务均执行完毕之后,你可能会在串口接受框中看到 ”Hellolc_guo world!“ 字符串
上述场景最终的结果与我们期望任务输出的字符串不符,在操作系统中称 TASK1 输出字符串的操作不是原子的,可能被打断的,
因此在某些时候需要我们屏蔽掉中断以保证某些操作为原子的,可以连续执行完不被打断的,能够连续执行完且不被打断的程序段称其为临界段
那 FreeRTOS 中应该如何屏蔽中断?
在 FreeRTOS 中提供了三组宏函数方便用户在合适的位置屏蔽中断,在功能上屏蔽中断和定义临界代码段几乎是相同的,这几组函数通常成对使用
/**
* @brief 屏蔽FreeRTOS可管理的MCU中断
* @retval None
*/
void taskDISABLE_INTERRUPTS(void);
/**
* @brief 解除屏蔽FreeRTOS可管理的MCU中断
* @retval None
*/
void taskENABLE_INTERRUPTS(void);
/**
* @brief 开始临界代码段
* @retval None
*/
void taskENTER_CRITICAL(void);
/**
* @brief 退出临界代码段
* @retval None
*/
void taskEXIT_CRITICAL(void);
/**
* @brief 开始临界代码段的中断安全版本
* @retval 返回中断屏蔽状态uxSavedInterruptStatus,作为参数用于匹配的taskEXIT_CRITICAL_FROM_ISR()调用
*/
UBaseType_t taskENTER_CRITICAL_FROM_ISR(void);
/**
* @brief 退出临界代码段的中断安全版本
* @param uxSavedInterruptStatus:进入临界代码段时返回的中断屏蔽状态,taskENTER_CRITICAL_FROM_ISR()返回的值
* @retval None
*/
void taskEXIT_CRITICAL_FROM_ISR(UBaseType_t uxSavedInterruptStatus);
4、实验一:中断各种特性测试
4.1、实验目的
- 启动 RTC 周期唤醒中断,在周期唤醒中通过串口 USART1 不断输出当前 RTC 时间
- 创建任务 TASK_TEST ,在该任务中通过串口 USART1 输出提示信息即可
4.2、CubeMX相关配置
首先读者应按照 “
FreeRTOS教程1 基础知识
” 章节配置一个可以正常编译通过的 FreeRTOS 空工程,然后在此空工程的基础上增加本实验所提出的要求
本实验需要初始化 USART1 作为输出信息渠道,具体配置步骤请阅读 “
STM32CubeMX教程9 USART/UART 异步通信
” ,如下图所示

本实验需要配置 RTC 周期唤醒中断,具体配置步骤和参数介绍读者可阅读 ”
STM32CubeMX教程10 RTC 实时时钟 - 周期唤醒、闹钟A/B事件和备份寄存器
“ 实验,此处不再赘述,这里参数、中断、时钟如下图所示



配置 Clock Configuration 和 Project Manager 两个页面,接下来直接单击 GENERATE CODE 按钮生成工程代码即可
4.3、添加其他必要代码
按照 “
STM32CubeMX教程9 USART/UART 异步通信
” 实验 “6、串口printf重定向”小节增加串口 printf 重定向代码,具体不再赘述
然后在 rtc.c 文件下方重新实现 RTC 的周期唤醒回调函数,在该函数体内获取当前 RTC 时间并通过 USART1 将时间输出到串口助手,具体如下所述
/*周期唤醒回调函数*/
void HAL_RTCEx_WakeUpTimerEventCallback(RTC_HandleTypeDef *hrtc)
{
RTC_TimeTypeDef sTime;
RTC_DateTypeDef sDate;
if(HAL_RTC_GetTime(hrtc, &sTime, RTC_FORMAT_BIN) == HAL_OK)
{
HAL_RTC_GetDate(hrtc, &sDate, RTC_FORMAT_BIN);
char str[22];
sprintf(str,"RTC Time= %2d:%2d:%2d\r\n",sTime.Hours,sTime.Minutes,sTime.Seconds);
printf("%s", str);
}
}
最后在 freertos.c 中添加任务函数体内代码即可,这里无需实现具体功能,仅通过 USART1 串口输出信息告知用户该任务已执行即可,具体如下所述
/*测试任务函数*/
void TASK_TEST(void *argument)
{
/* USER CODE BEGIN TASK_TEST */
/* Infinite loop */
for(;;)
{
printf("TASK_TEST\r\n");
osDelay(pdMS_TO_TICKS(500));
}
/* USER CODE END TASK_TEST */
}
4.4、烧录验证
烧录程序,打开串口助手,由于周期唤醒中断每隔 1s 执行依次,TASK_TEST 任务大概每隔 500ms 执行有一次,因此通过串口助手输出信息可以发现,每输出两次 ”TASK_TEST“ 就会输出一次当前 RTC 时间,和预期一致,具体如下图所示

上述任务流程应该如下图所示

4.5、各种特性测试
4.5.1、中断如果处理时间较长呢?
修改 RTC 周期唤醒中断函数体,在函数体末尾增加 1s 延时函数 HAL_Delay(1000); 模拟中断处理时间较长的情况
,注意由于 RTC 周期唤醒中断优先级为 1 ,因此不能调用任何 FreeRTOS API 函数,包括延时函数,任务 TASK_TEST 不做任何改动,将修改后的程序重新编译烧录,观察串口助手的输出信息,具体如下图所示

可以发现,只有最开始测试任务 TASK_TEST 执行了两次,一旦 RTC 周期唤醒被执行那么之后测试任务便得不到执行,为什么会这样?RTC 周期唤醒每隔 1s 执行一次,执行一次之后延时 1s 占用处理器,不断循环,导致处理器没有任何机会去处理 TASK_TEST
上述任务流程应该如下图所示

4.5.2、任务如果处理时间较长呢?
修改测试任务 TASK_TEST 函数体,将其可以进入阻塞状态的延时函数 osDelay() 修改为 HAL_Delay() 函数,同时将延时时间从 500ms 增加至 2s ,用于模拟任务一直运行的情况
,RTC 周期唤醒中断函数与 “4.3、添加其他必要代码” 小节一致,具体如下所示
void TASK_TEST(void *argument)
{
/* USER CODE BEGIN TASK_TEST */
/* Infinite loop */
for(;;)
{
printf("TASK_TEST\r\n");
HAL_Delay(2000);
}
/* USER CODE END TASK_TEST */
}
将修改后的程序重新编译烧录,观察串口助手的输出信息,具体如下图所示,从图中可知 RTC 运行正常,本来应该连续运行 2s 的 TASK_TEST 并没有影响到每隔 1s 输出 RTC 时间的周期唤醒中断,说明中断抢占了 TASK_TEST 得到了执行,也就是说虽然我们希望 TASK_TEST 测试任务连续运行 2s ,但是其并没有真正连续运行 2s,其在大概 1s 的时候被中断了

4.5.3、进行中断屏蔽
上述 ”4.5.2、任务如果处理时间较长呢?“ 小节阐述了一个问题,有时候我们希望我们的 TASK_TEST 任务是原子式执行的,不希望被中断打断,所以我们需要在任务函数体内屏蔽中断,修改 TASK_TEST 任务函数体如下所示
void TASK_TEST(void *argument)
{
/* USER CODE BEGIN TASK_TEST */
/* Infinite loop */
for(;;)
{
//进入临界段
//taskDISABLE_INTERRUPTS();
taskENTER_CRITICAL();
printf("TASK_TEST\r\n");
HAL_Delay(2000);
//退出临界段
//taskENABLE_INTERRUPTS();
taskEXIT_CRITICAL();
}
/* USER CODE END TASK_TEST */
}
同时别忘记,
FreeRTOS能够屏蔽中断优先级为5~15,因此我们还需要在 STM32CubeMX 软件的 NVIC 中将 RTC 周期唤醒中断优先级设置到该范围内
,这里笔者将其设置为了 7 ,具体如下图所示

将修改后的程序重新编译烧录,观察串口助手的输出信息,具体如下图所示,可以发现 RTC 周期唤醒函数每隔 2s 才会得到一次输出,这说明 TASK_TEST 任务整个函数体得到了连续运行,成功屏蔽掉了 RTC 周期唤醒中断

5、注释详解
注释1
:图片来源于
Mastering_the_FreeRTOS_Real_Time_Kernel-A_Hands-On_Tutorial_Guide.pdf
参考资料
Mastering_the_FreeRTOS_Real_Time_Kernel-A_Hands-On_Tutorial_Guide.pdf
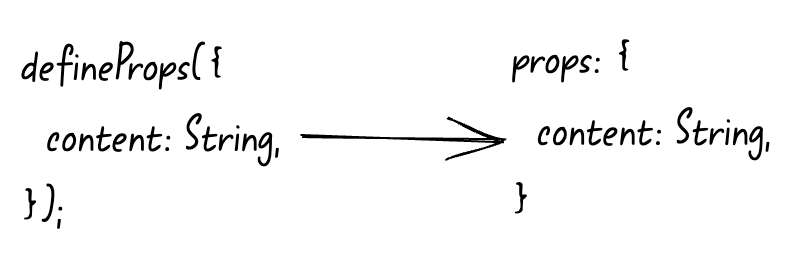
为什么defineProps宏函数不需要从vue中import导入?
前言
我们每天写
vue
代码时都在用
defineProps
,但是你有没有思考过下面这些问题。为什么
defineProps
不需要
import
导入?为什么不能在非
setup
顶层使用
defineProps
?
defineProps
是如何将声明的
props
自动暴露给模板?
举几个例子
我们来看几个例子,分别对应上面的几个问题。
先来看一个正常的例子,
common-child.vue
文件代码如下:
<template>
<div>content is {{ content }}</div>
</template>
<script setup lang="ts">
defineProps({
content: String,
});
</script>
我们看到在这个正常的例子中没有从任何地方
import
导入
defineProps
,直接就可以使用了,并且在
template
中渲染了
props
中的
content
。
我们再来看一个在非
setup
顶层使用
defineProps
的例子,
if-child.vue
文件代码如下:
<template>
<div>content is {{ content }}</div>
</template>
<script setup lang="ts">
import { ref } from "vue";
const count = ref(10);
if (count.value) {
defineProps({
content: String,
});
}
</script>
代码跑起来直接就报错了,提示
defineProps is not defined
通过debug搞清楚上面几个问题
在我的上一篇文章
vue文件是如何编译为js文件
中已经带你搞清楚了
vue
文件中的
<script>
模块是如何编译成浏览器可直接运行的
js
代码,其实底层就是依靠
vue/compiler-sfc
包的
compileScript
函数。
当然如果你还没看过我的上一篇文章也不影响这篇文章阅读,这里我会简单说一下。当我们
import
一个
vue
文件时会触发
@vitejs/plugin-vue
包的
transform
钩子函数,在这个函数中会调用一个
transformMain
函数。
transformMain
函数中会调用
genScriptCode
、
genTemplateCode
、
genStyleCode
,分别对应的作用是将
vue
文件中的
<script>
模块编译为浏览器可直接运行的
js
代码、将
<template>
模块编译为
render
函数、将
<style>
模块编译为导入
css
文件的
import
语句。
genScriptCode
函数底层调用的就是
vue/compiler-sfc
包的
compileScript
函数。
一样的套路,首先我们在vscode的打开一个
debug
终端。
然后在
node_modules
中找到
vue/compiler-sfc
包的
compileScript
函数打上断点,
compileScript
函数位置在
/node_modules/@vue/compiler-sfc/dist/compiler-sfc.cjs.js
。在
debug
终端上面执行
yarn dev
后在浏览器中打开对应的页面,比如:
http://localhost:5173/
。此时断点就会走到
compileScript
函数中,我们在
debug
中先来看看
compileScript
函数的第一个入参
sfc
。
sfc.filename
的值为当前编译的
vue
文件路径。由于每编译一个
vue
文件都要走到这个debug中,现在我们只想
debug
看看
common-child.vue
文件,所以为了方便我们在
compileScript
中加了下面这样一段代码,并且去掉了在
compileScript
函数中加的断点,这样就只有编译
common-child.vue
文件时会走进断点。
compileScript
函数
我们再来回忆一下
common-child.vue
文件中的
script
模块代码如下:
<script setup lang="ts">
defineProps({
content: String,
});
</script>
我们接着来看
compileScript
函数的入参
sfc
,在上一篇文章
vue文件是如何编译为js文件
中我们已经讲过了
sfc
是一个
descriptor
对象,
descriptor
对象是由
vue
文件编译来的。
descriptor
对象拥有
template
属性、
scriptSetup
属性、
style
属性,分别对应
vue
文件的
<template>
模块、
<script setup>
模块、
<style>
模块。在我们这个场景只关注
scriptSetup
属性,
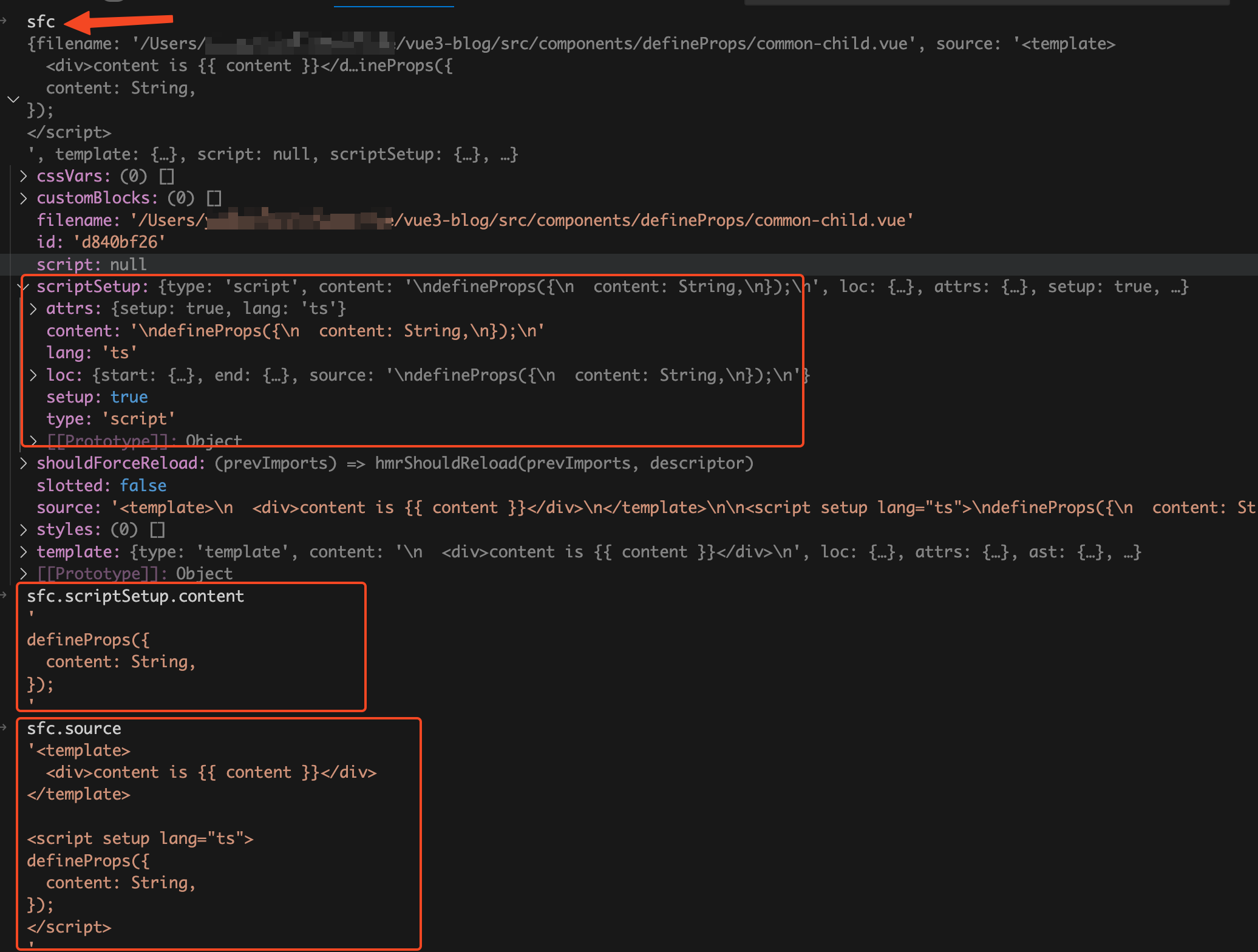
sfc.scriptSetup.content
的值就是
<script setup>
模块中
code
代码字符串,
sfc.source
的值就是
vue
文件中的源代码code字符串。详情查看下图:
compileScript
函数内包含了编译
script
模块的所有的逻辑,代码很复杂,光是源代码就接近1000行。这篇文章我们不会去通读
compileScript
函数的所有功能,只会讲处理
defineProps
相关的代码。下面这个是我简化后的代码:
function compileScript(sfc, options) {
const ctx = new ScriptCompileContext(sfc, options);
const startOffset = ctx.startOffset;
const endOffset = ctx.endOffset;
const scriptSetupAst = ctx.scriptSetupAst;
for (const node of scriptSetupAst.body) {
if (node.type === "ExpressionStatement") {
const expr = node.expression;
if (processDefineProps(ctx, expr)) {
ctx.s.remove(node.start + startOffset, node.end + startOffset);
}
}
if (node.type === "VariableDeclaration" && !node.declare || node.type.endsWith("Statement")) {
// ....
}
}
ctx.s.remove(0, startOffset);
ctx.s.remove(endOffset, source.length);
let runtimeOptions = ``;
const propsDecl = genRuntimeProps(ctx);
if (propsDecl) runtimeOptions += `\n props: ${propsDecl},`;
const def =
(defaultExport ? `\n ...${normalScriptDefaultVar},` : ``) +
(definedOptions ? `\n ...${definedOptions},` : "");
ctx.s.prependLeft(
startOffset,
`\n${genDefaultAs} /*#__PURE__*/${ctx.helper(
`defineComponent`
)}({${def}${runtimeOptions}\n ${
hasAwait ? `async ` : ``
}setup(${args}) {\n${exposeCall}`
);
ctx.s.appendRight(endOffset, `})`);
return {
//....
content: ctx.s.toString(),
};
}
在
compileScript
函数中首先调用
ScriptCompileContext
类生成一个
ctx
上下文对象,然后遍历
vue
文件的
<script setup>
模块生成的
AST抽象语法树
。如果节点类型为
ExpressionStatement
表达式语句,那么就执行
processDefineProps
函数,判断当前表达式语句是否是调用
defineProps
函数。如果是那么就删除掉
defineProps
调用代码,并且将调用
defineProps
函数时传入的参数对应的
node
节点信息存到
ctx
上下文中。然后从参数
node
节点信息中拿到调用
defineProps
宏函数时传入的
props
参数的开始位置和结束位置。再使用
slice
方法并且传入开始位置和结束位置,从
<script setup>
模块的代码字符串中截取到
props
定义的字符串。然后将截取到的
props
定义的字符串拼接到
vue
组件对象的字符串中,最后再将编译后的
setup
函数代码字符串拼接到
vue
组件对象的字符串中。
ScriptCompileContext
类
ScriptCompileContext
类中我们主要关注这几个属性:
startOffset
、
endOffset
、
scriptSetupAst
、
s
。先来看看他的
constructor
,下面是我简化后的代码。
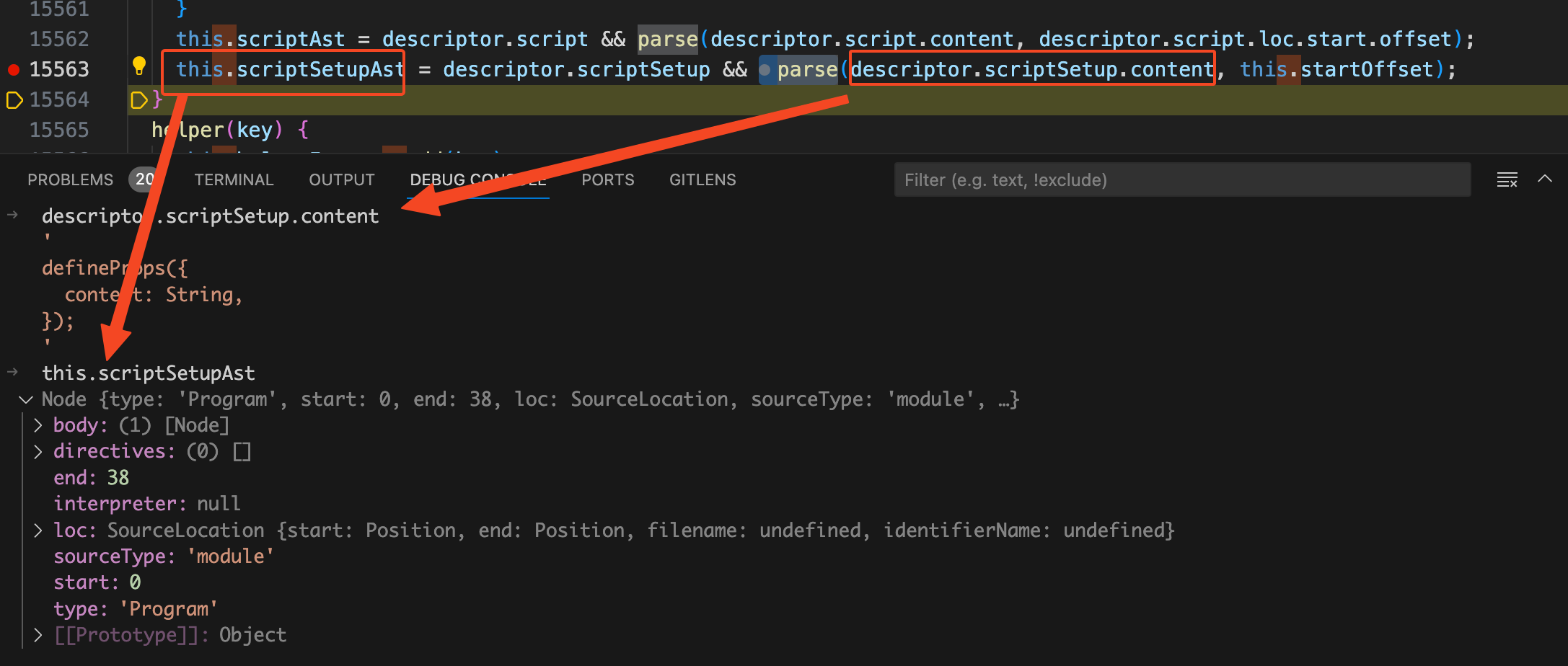
import MagicString from 'magic-string'
class ScriptCompileContext {
source = this.descriptor.source
s = new MagicString(this.source)
startOffset = this.descriptor.scriptSetup?.loc.start.offset
endOffset = this.descriptor.scriptSetup?.loc.end.offset
constructor(descriptor, options) {
this.s = new MagicString(this.source);
this.scriptSetupAst = descriptor.scriptSetup && parse(descriptor.scriptSetup.content, this.startOffset);
}
}
在前面我们已经讲过了
descriptor.scriptSetup
对象就是由
vue
文件中的
<script setup>
模块编译而来,
startOffset
和
endOffset
分别就是
descriptor.scriptSetup?.loc.start.offset
和
descriptor.scriptSetup?.loc.end.offset
,对应的是
<script setup>
模块在
vue
文件中的开始位置和结束位置。
descriptor.source
的值就是
vue
文件中的源代码code字符串,这里以
descriptor.source
为参数
new
了一个
MagicString
对象。
magic-string
是由
svelte
的作者写的一个库,用于处理字符串的
JavaScript
库。它可以让你在字符串中进行插入、删除、替换等操作,并且能够生成准确的
sourcemap
。
MagicString
对象中拥有
toString
、
remove
、
prependLeft
、
appendRight
等方法。
s.toString
用于生成返回的字符串,我们来举几个例子看看这几个方法你就明白了。
s.remove( start, end )
用于删除从开始到结束的字符串:
const s = new MagicString('hello word');
s.remove(0, 6);
s.toString(); // 'word'
s.prependLeft( index, content )
用于在指定
index
的前面插入字符串:
const s = new MagicString('hello word');
s.prependLeft(5, 'xx');
s.toString(); // 'helloxx word'
s.appendRight( index, content )
用于在指定
index
的后面插入字符串:
const s = new MagicString('hello word');
s.appendRight(5, 'xx');
s.toString(); // 'helloxx word'
我们接着看
constructor
中的
scriptSetupAst
属性是由一个
parse
函数的返回值赋值,
parse(descriptor.scriptSetup.content, this.startOffset)
,
parse
函数的代码如下:
import { parse as babelParse } from '@babel/parser'
function parse(input: string, offset: number): Program {
try {
return babelParse(input, {
plugins,
sourceType: 'module',
}).program
} catch (e: any) {
}
}
我们在前面已经讲过了
descriptor.scriptSetup.content
的值就是
vue
文件中的
<script setup>
模块的代码
code
字符串,
parse
函数中调用了
babel
提供的
parser
函数,将
vue
文件中的
<script setup>
模块的代码
code
字符串转换成
AST抽象语法树
。
现在我们再来看
compileScript
函数中的这几行代码你理解起来就没什么难度了,这里的
scriptSetupAst
变量就是由
vue
文件中的
<script setup>
模块的代码转换成的
AST抽象语法树
。
const ctx = new ScriptCompileContext(sfc, options);
const startOffset = ctx.startOffset;
const endOffset = ctx.endOffset;
const scriptSetupAst = ctx.scriptSetupAst;
流程图如下: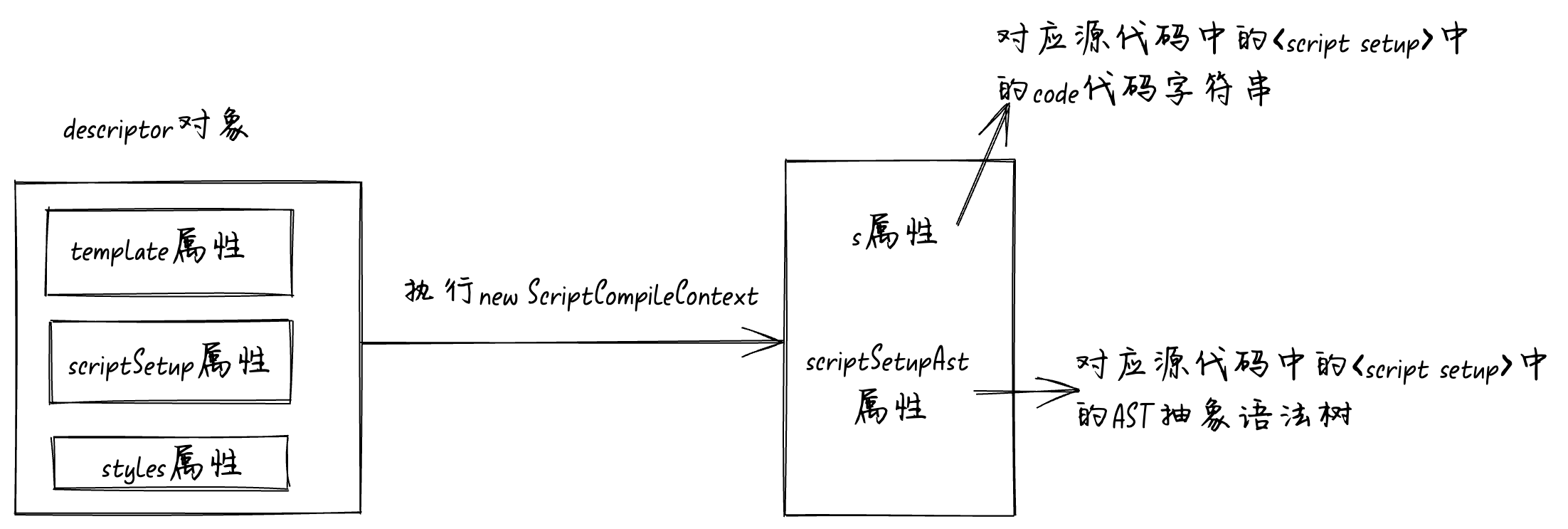
processDefineProps
函数
我们接着将断点走到
for
循环开始处,代码如下:
for (const node of scriptSetupAst.body) {
if (node.type === "ExpressionStatement") {
const expr = node.expression;
if (processDefineProps(ctx, expr)) {
ctx.s.remove(node.start + startOffset, node.end + startOffset);
}
}
}
遍历
AST抽象语法树
,如果当前节点类型为
ExpressionStatement
表达式语句,并且
processDefineProps
函数执行结果为
true
就调用
ctx.s.remove
方法。这会儿断点还在
for
循环开始处,在控制台执行
ctx.s.toString()
看看当前的
code
代码字符串。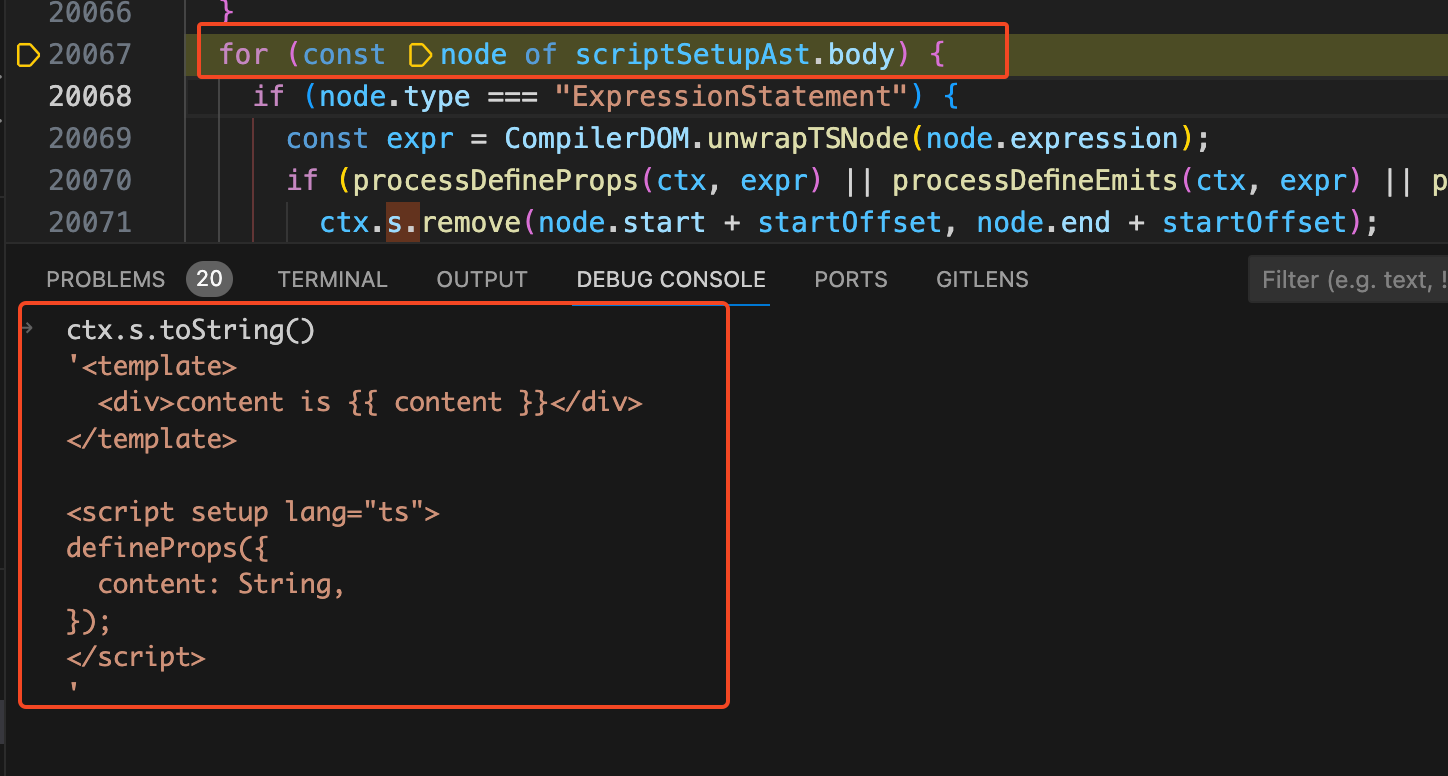
从图上可以看见此时
toString
的执行结果还是和之前的
common-child.vue
源代码是一样的,并且很明显我们的
defineProps
是一个表达式语句,所以会执行
processDefineProps
函数。我们将断点走到调用
processDefineProps
的地方,看到简化过的
processDefineProps
函数代码如下:
const DEFINE_PROPS = "defineProps";
function processDefineProps(ctx, node, declId) {
if (!isCallOf(node, DEFINE_PROPS)) {
return processWithDefaults(ctx, node, declId);
}
ctx.propsRuntimeDecl = node.arguments[0];
return true;
}
在
processDefineProps
函数中首先执行了
isCallOf
函数,第一个参数传的是当前的
AST语法树
中的
node
节点,第二个参数传的是
"defineProps"
字符串。从
isCallOf
的名字中我们就可以猜出他的作用是判断当前的
node
节点的类型是不是在调用
defineProps
函数,
isCallOf
的代码如下:
export function isCallOf(node, test) {
return !!(
node &&
test &&
node.type === "CallExpression" &&
node.callee.type === "Identifier" &&
(typeof test === "string"
? node.callee.name === test
: test(node.callee.name))
);
}
isCallOf
函数接收两个参数,第一个参数
node
是当前的
node
节点,第二个参数
test
是要判断的函数名称,在我们这里是写死的
"defineProps"
字符串。我们在
debug console
中将
node.type
、
node.callee.type
、
node.callee.name
的值打印出来看看。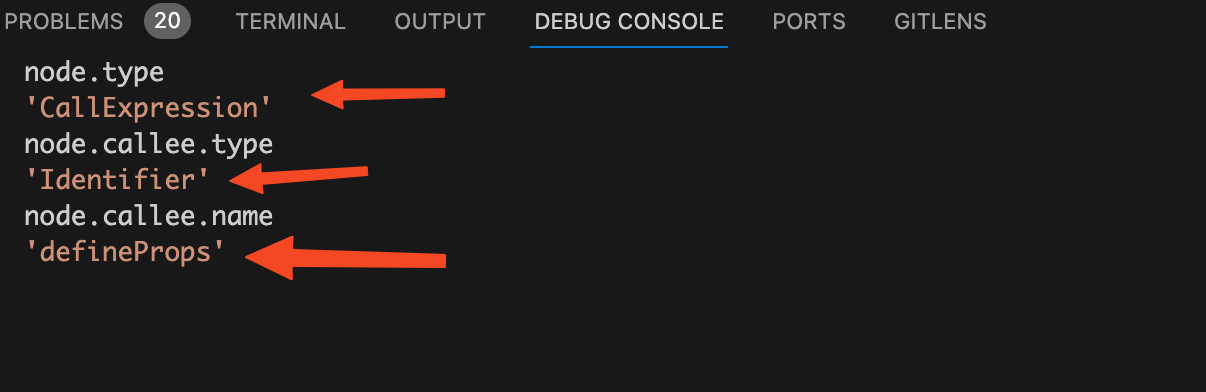
从图上看到
node.type
、
node.callee.type
、
node.callee.name
的值后,可以证明我们的猜测是正确的这里
isCallOf
的作用是判断当前的
node
节点的类型是不是在调用
defineProps
函数。我们这里的
node
节点确实是在调用
defineProps
函数,所以
isCallOf
的执行结果为
true
,在
processDefineProps
函数中是对
isCallOf
函数的执行结果取反。也就是
!isCallOf(node, DEFINE_PROPS)
的执行结果为
false
,所以不会走到
return processWithDefaults(ctx, node, declId);
。
我们接着来看
processDefineProps
函数:
function processDefineProps(ctx, node, declId) {
if (!isCallOf(node, DEFINE_PROPS)) {
return processWithDefaults(ctx, node, declId);
}
ctx.propsRuntimeDecl = node.arguments[0];
return true;
}
如果当前节点确实是在执行
defineProps
函数,那么就会执行
ctx.propsRuntimeDecl = node.arguments[0];
。将当前
node
节点的第一个参数赋值给
ctx
上下文对象的
propsRuntimeDecl
属性,这里的第一个参数其实就是调用
defineProps
函数时给传入的第一个参数。为什么写死成取
arguments[0]
呢?是因为
defineProps
函数只接收一个参数,传入的参数可以是一个对象或者数组。比如:
const props = defineProps({
foo: String
})
const props = defineProps(['foo', 'bar'])
记住这个在
ctx
上下文上面塞的
propsRuntimeDecl
属性,后面生成运行时的
props
就是根据
propsRuntimeDecl
属性生成的。
至此我们已经了解到了
processDefineProps
中主要做了两件事:判断当前执行的表达式语句是否是
defineProps
函数,如果是那么将解析出来的
props
属性的信息塞的
ctx
上下文的
propsRuntimeDecl
属性中。
我们这会儿来看
compileScript
函数中的
processDefineProps
代码你就能很容易理解了:
for (const node of scriptSetupAst.body) {
if (node.type === "ExpressionStatement") {
const expr = node.expression;
if (processDefineProps(ctx, expr)) {
ctx.s.remove(node.start + startOffset, node.end + startOffset);
}
}
}
遍历
AST语法树
,如果当前节点类型是
ExpressionStatement
表达式语句,再执行
processDefineProps
判断当前
node
节点是否是执行的
defineProps
函数。如果是
defineProps
函数就调用
ctx.s.remove
方法将调用
defineProps
函数的代码从源代码中删除掉。此时我们在
debug console
中执行
ctx.s.toString()
,看到我们的
code
代码字符串中已经没有了
defineProps
了: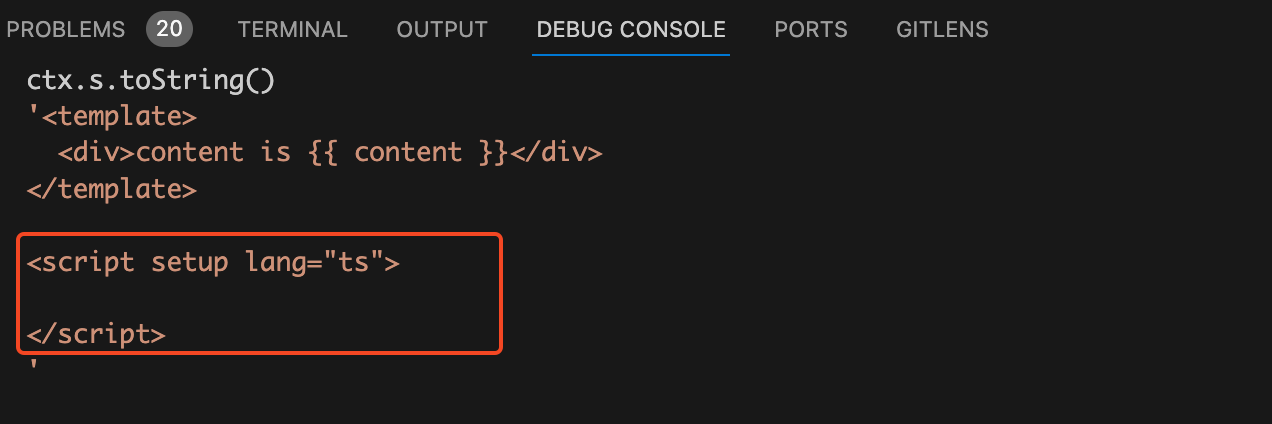
现在我们能够回答第一个问题了:
为什么
defineProps
不需要
import
导入?
因为在编译过程中如果当前
AST抽象语法树
的节点类型是
ExpressionStatement
表达式语句,并且调用的函数是
defineProps
,那么就调用
remove
方法将调用
defineProps
函数的代码给移除掉。既然
defineProps
语句已经被移除了,自然也就不需要
import
导入了
defineProps
了。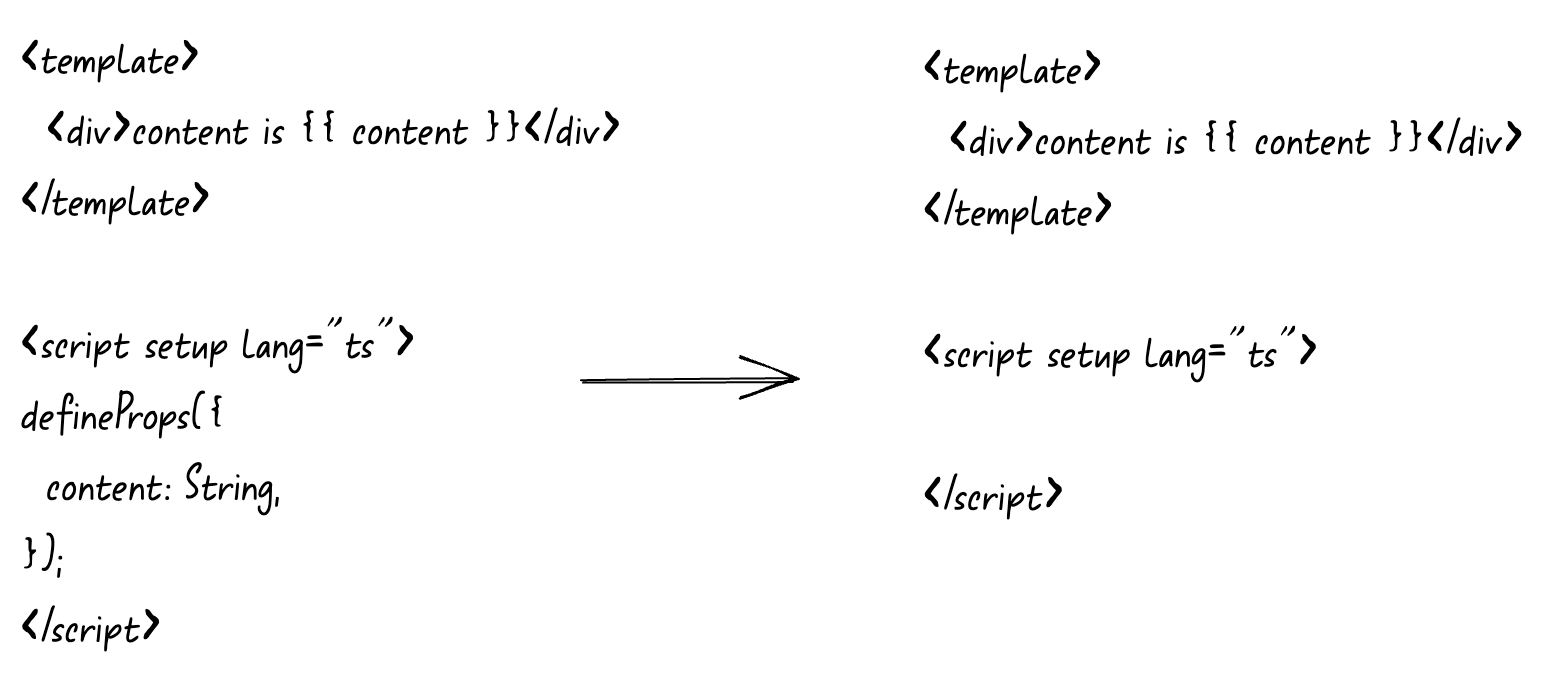
genRuntimeProps
函数
接着在
compileScript
函数中执行了两条
remove
代码:
ctx.s.remove(0, startOffset);
ctx.s.remove(endOffset, source.length);
这里的
startOffset
表示
script
标签中第一个代码开始的位置, 所以
ctx.s.remove(0, startOffset);
的意思是删除掉包含
<script setup>
开始标签前面的所有内容,也就是删除掉
template
模块的内容和
<script setup>
开始标签。这行代码执行完后我们再看看
ctx.s.toString()
的值: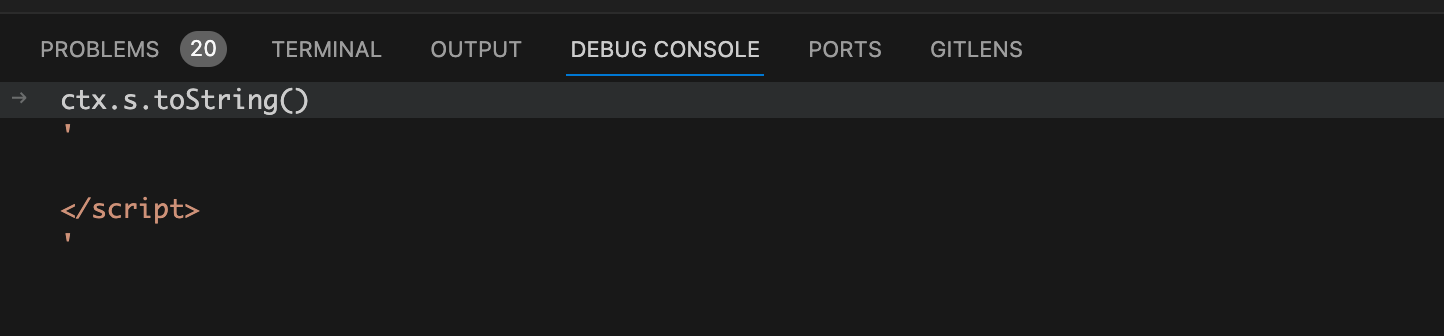
接着执行
ctx.s.remove(endOffset, source.length);
,这行代码的意思是将
</script >
包含结束标签后面的内容全部删掉,也就是删除
</script >
结束标签和
<style>
模块。这行代码执行完后我们再来看看
ctx.s.toString()
的值: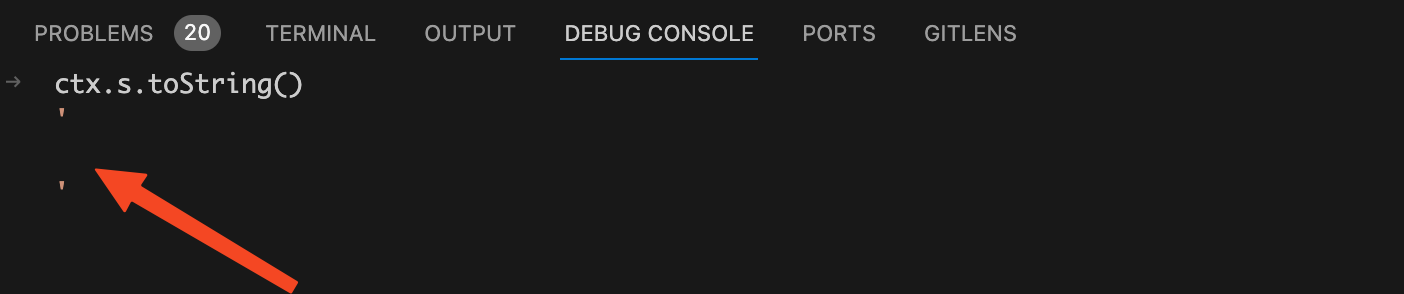
由于我们的
common-child.vue
的
script
模块中只有一个
defineProps
函数,所以当移除掉
template
模块、
style
模块、
script
开始标签和结束标签后就变成了一个空字符串。如果你的
script
模块中还有其他
js
业务代码,当代码执行到这里后就不会是空字符串,而是那些
js
业务代码。
我们接着将
compileScript
函数中的断点走到调用
genRuntimeProps
函数处,代码如下:
let runtimeOptions = ``;
const propsDecl = genRuntimeProps(ctx);
if (propsDecl) runtimeOptions += `\n props: ${propsDecl},`;
从
genRuntimeProps
名字你应该已经猜到了他的作用,根据
ctx
上下文生成运行时的
props
。我们将断点走到
genRuntimeProps
函数内部,在我们这个场景中
genRuntimeProps
主要执行的代码如下:
function genRuntimeProps(ctx) {
let propsDecls;
if (ctx.propsRuntimeDecl) {
propsDecls = ctx.getString(ctx.propsRuntimeDecl).trim();
}
return propsDecls;
}
还记得这个
ctx.propsRuntimeDecl
是什么东西吗?我们在执行
processDefineProps
函数判断当前节点是否为执行
defineProps
函数的时候,就将调用
defineProps
函数的参数
node
节点赋值给
ctx.propsRuntimeDecl
。换句话说
ctx.propsRuntimeDecl
中拥有调用
defineProps
函数传入的
props
参数中的节点信息。我们将断点走进
ctx.getString
函数看看是如何取出
props
的:
getString(node, scriptSetup = true) {
const block = scriptSetup ? this.descriptor.scriptSetup : this.descriptor.script;
return block.content.slice(node.start, node.end);
}
我们前面已经讲过了
descriptor
对象是由
vue
文件编译而来,其中的
scriptSetup
属性就是对应的
<script setup>
模块。我们这里没有传入
scriptSetup
,所以
block
的值为
this.descriptor.scriptSetup
。同样我们前面也讲过
scriptSetup.content
的值是
<script setup>
模块
code
代码字符串。请看下图: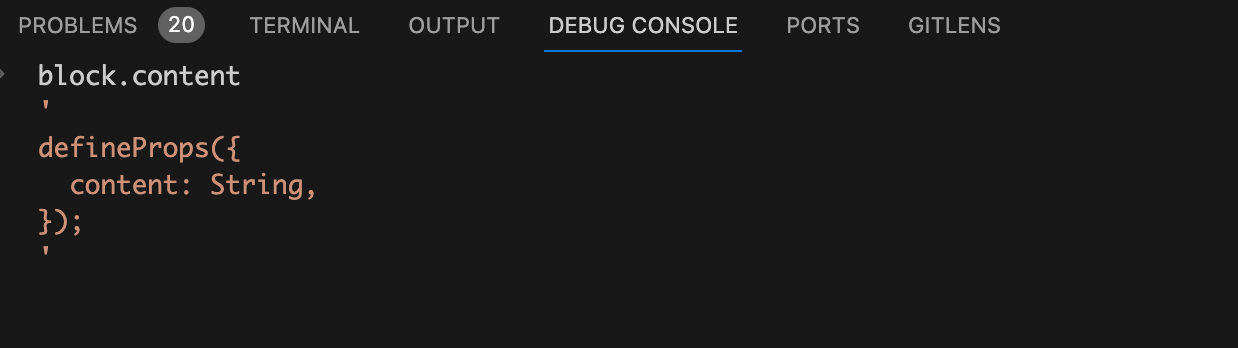
这里传入的
node
节点就是我们前面存在上下文中
ctx.propsRuntimeDecl
,也就是在调用
defineProps
函数时传入的参数节点,
node.start
就是参数节点开始的位置,
node.end
就是参数节点的结束位置。所以使用
content.slice
方法就可以截取出来调用
defineProps
函数时传入的
props
定义。请看下图: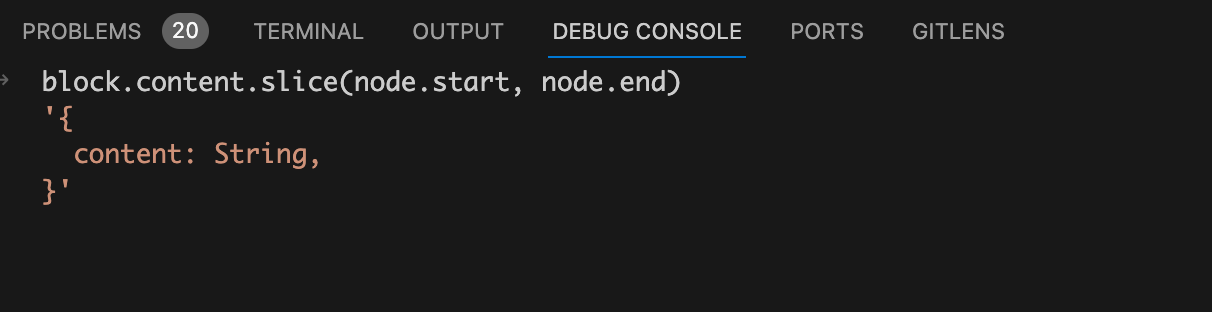
现在我们再回过头来看
compileScript
函数中的调用
genRuntimeProps
函数的代码你就能很容易理解了:
let runtimeOptions = ``;
const propsDecl = genRuntimeProps(ctx);
if (propsDecl) runtimeOptions += `\n props: ${propsDecl},`;
这里的
propsDecl
在我们这个场景中就是使用
slice
截取出来的
props
定义,再使用
\n props: ${propsDecl},
进行字符串拼接就得到了
runtimeOptions
的值。如图: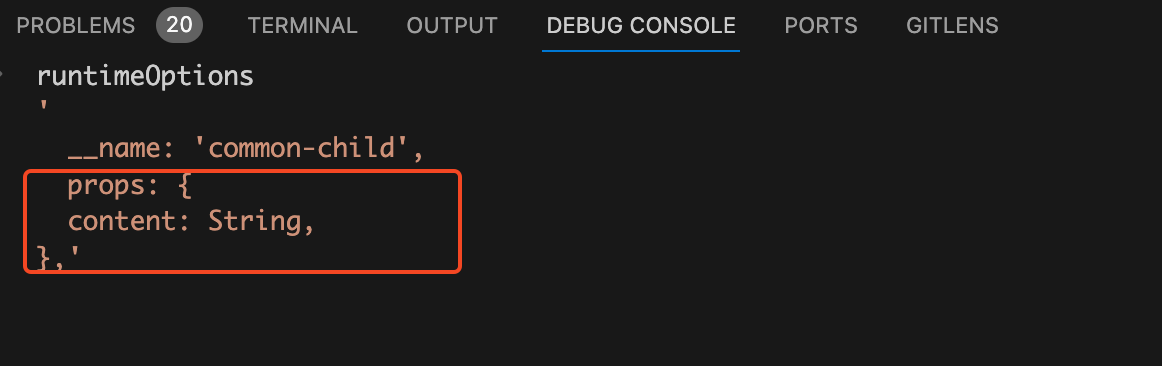
看到
runtimeOptions
的值是不是就觉得很熟悉了,又有
name
属性,又有
props
属性。其实就是
vue
组件对象的
code
字符串的一部分。
name
拼接逻辑是在省略的代码中,我们这篇文章只讲
props
相关的逻辑,所以
name
不在这篇文章的讨论范围内。
现在我们能够回答前面提的第三个问题了。
defineProps
是如何将声明的
props
自动暴露给模板?
编译时在移除掉
defineProps
相关代码时会将调用
defineProps
函数时传入的参数
node
节点信息存到
ctx
上下文中。遍历完
AST抽象语法树后
,然后从上下文中存的参数
node
节点信息中拿到调用
defineProps
宏函数时传入
props
的开始位置和结束位置。再使用
slice
方法并且传入开始位置和结束位置,从
<script setup>
模块的代码字符串中截取到
props
定义的字符串。然后将截取到的
props
定义的字符串拼接到
vue
组件对象的字符串中,这样
vue
组件对象中就有了一个
props
属性,这个
props
属性在
template
模版中可以直接使用。
拼接成完整的浏览器运行时
js
代码
我们再来看
compileScript
函数中的最后一坨代码;
const def =
(defaultExport ? `\n ...${normalScriptDefaultVar},` : ``) +
(definedOptions ? `\n ...${definedOptions},` : "");
ctx.s.prependLeft(
startOffset,
`\n${genDefaultAs} /*#__PURE__*/${ctx.helper(
`defineComponent`
)}({${def}${runtimeOptions}\n ${
hasAwait ? `async ` : ``
}setup(${args}) {\n${exposeCall}`
);
ctx.s.appendRight(endOffset, `})`);
return {
//....
content: ctx.s.toString(),
};
这里先调用了
ctx.s.prependLeft
方法给字符串开始的地方插入了一串字符串,这串拼接的字符串看着脑瓜子痛,我们直接在
debug console
上面看看要拼接的字符串是什么样的: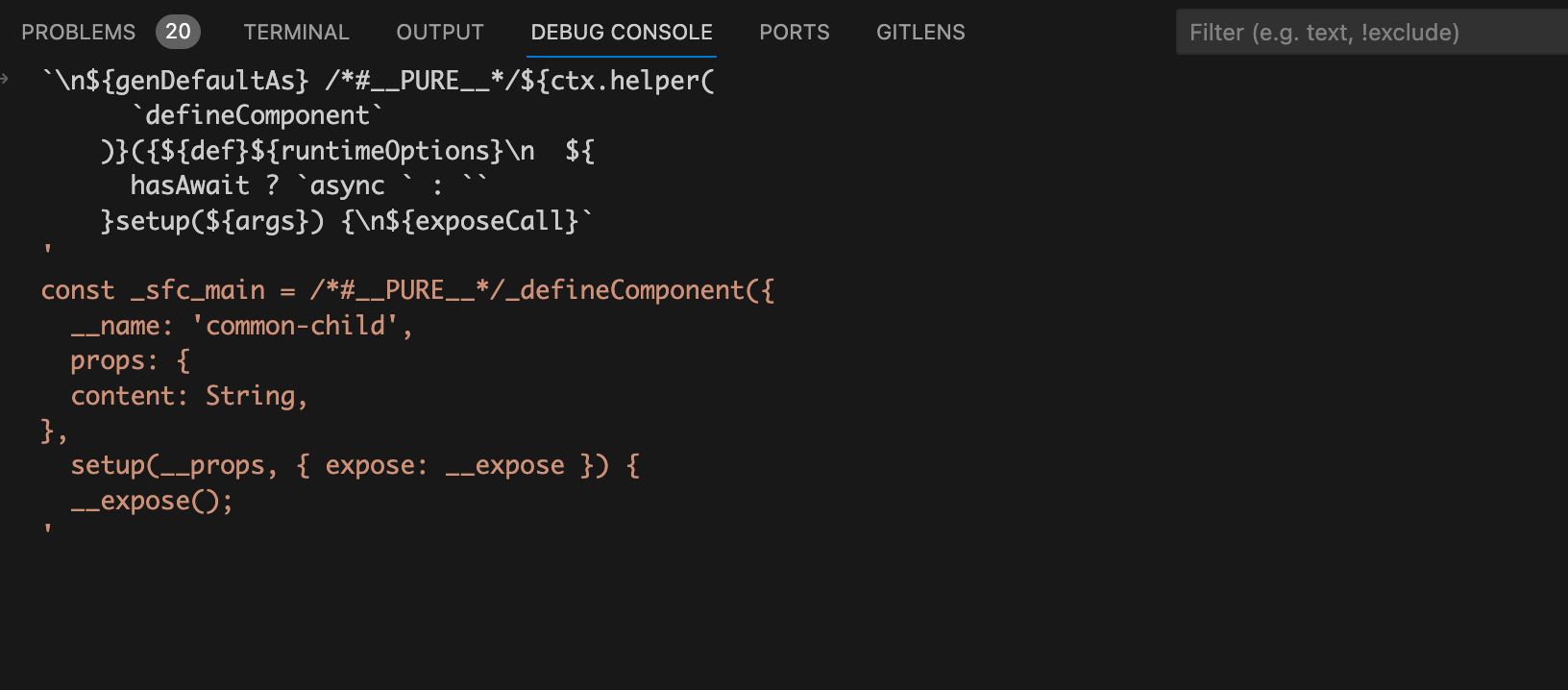
看到这串你应该很熟悉,除了前面我们拼接的
name
和
props
之外还有部分
setup
编译后的代码,其实这就是
vue
组件对象的
code
代码字符串的一部分。
当断点执行完
prependLeft
方法后,我们在
debug console
中再看看此时的
ctx.s.toString()
的值是什么样的: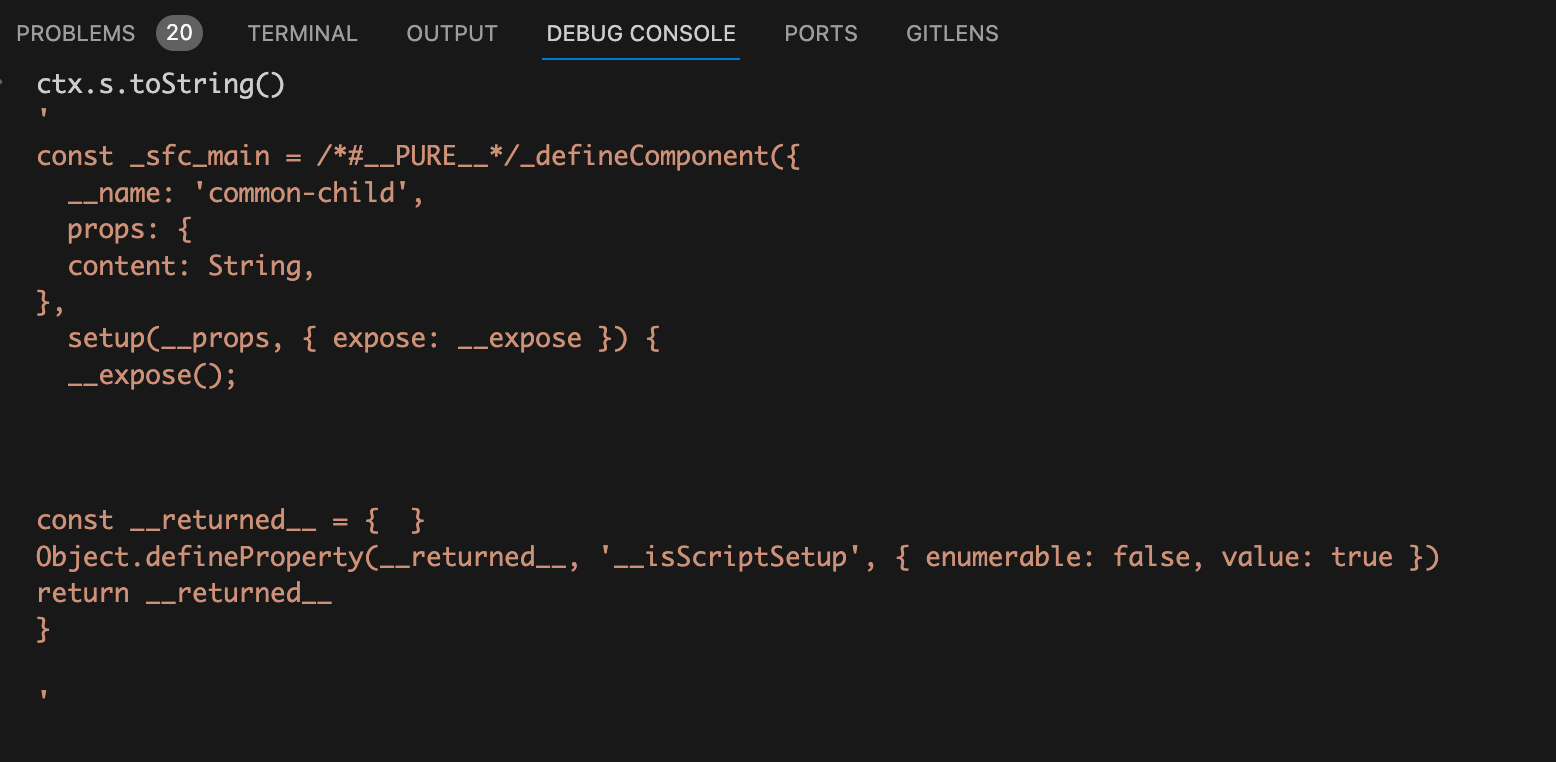
从图上可以看到
vue
组件对象上的
name
属性、
props
属性、
setup
函数基本已经拼接的差不多了,只差一个
})
结束符号,所以执行
ctx.s.appendRight(endOffset,
})
);
将结束符号插入进去。
我们最后再来看看
compileScript
函数的返回对象中的
content
属性,也就是
ctx.s.toString()
,
content
属性的值就是
vue
组件中的
<script setup>
模块编译成浏览器可执行的
js
代码字符串。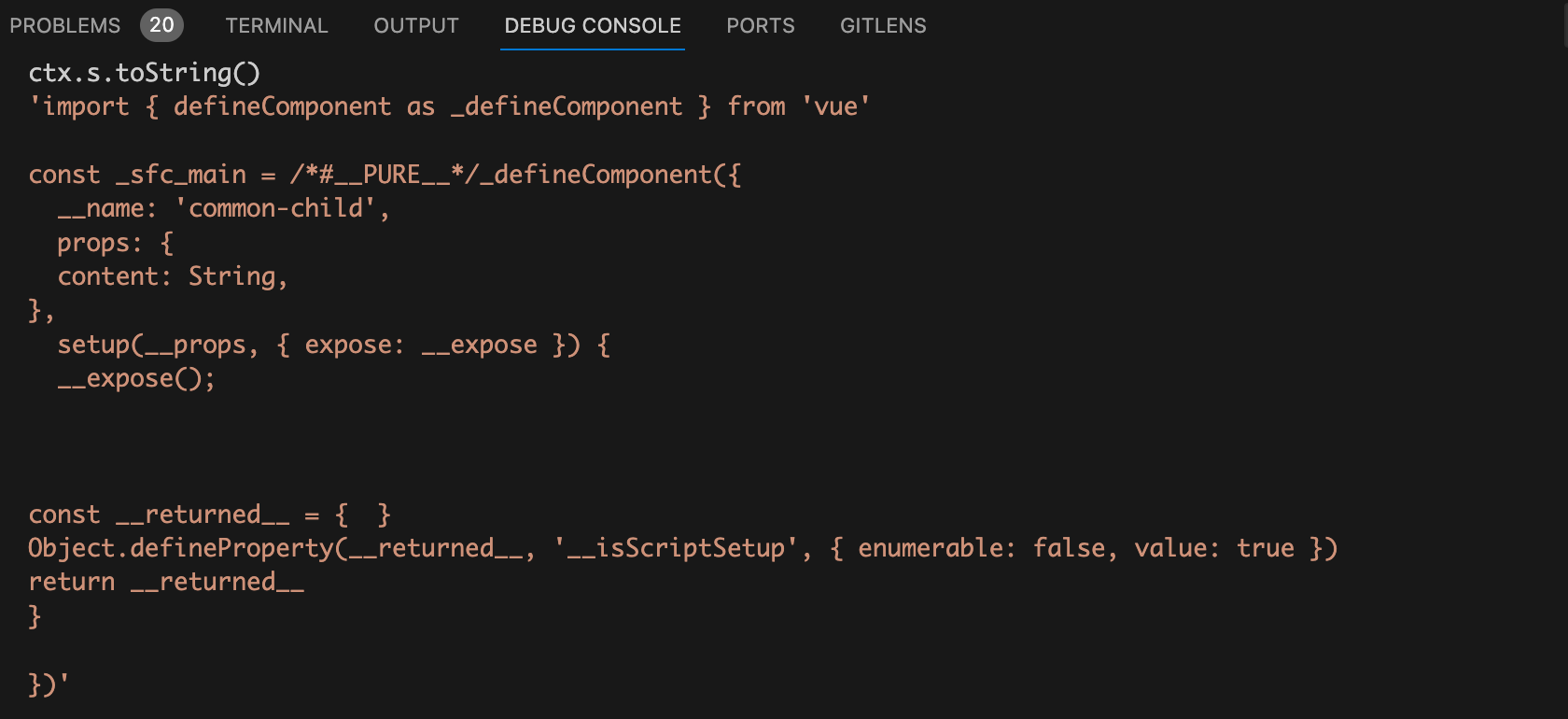
为什么不能在非
setup
顶层使用
defineProps
?
同样的套路我们来
debug
看看
if-child.vue
文件,先来回忆一下
if-child.vue
文件的代码。
<template>
<div>content is {{ content }}</div>
</template>
<script setup lang="ts">
import { ref } from "vue";
const count = ref(10);
if (count.value) {
defineProps({
content: String,
});
}
</script>
将断点走到
compileScript
函数的遍历
AST抽象语法树
的地方,我们看到
scriptSetupAst.body
数组中有三个
node
节点。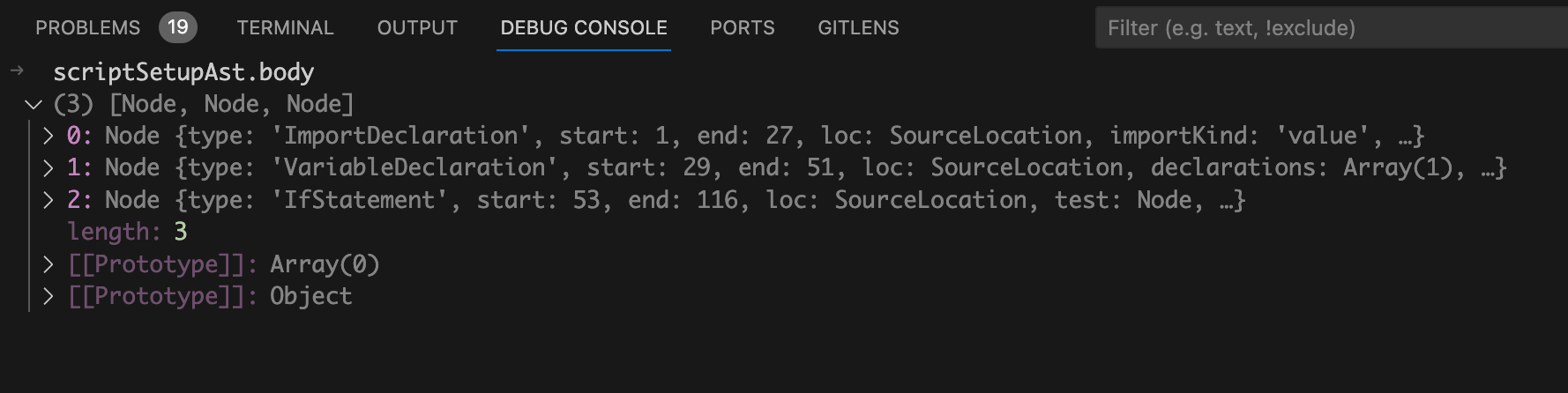
从图中我们可以看到这三个
node
节点类型分别是:
ImportDeclaration
、
VariableDeclaration
、
IfStatement
。很明显这三个节点对应的是我们源代码中的
import
语句、
const
定义变量、
if
模块。我们再来回忆一下
compileScript
函数中的遍历
AST抽象语法树
的代码:
function compileScript(sfc, options) {
// 省略..
for (const node of scriptSetupAst.body) {
if (node.type === "ExpressionStatement") {
const expr = node.expression;
if (processDefineProps(ctx, expr)) {
ctx.s.remove(node.start + startOffset, node.end + startOffset);
}
}
if (
(node.type === "VariableDeclaration" && !node.declare) ||
node.type.endsWith("Statement")
) {
// ....
}
}
// 省略..
}
从代码我们就可以看出来第三个
node
节点,也就是在
if
中使用
defineProps
的代码,这个节点类型为
IfStatement
,不等于
ExpressionStatement
,所以代码不会走到
processDefineProps
函数中,也不会执行
remove
方法删除掉调用
defineProps
函数的代码。当代码运行在浏览器时由于我们没有从任何地方
import
导入
defineProps
,当然就会报错
defineProps is not defined
。
总结
现在我们能够回答前面提的三个问题了。
为什么
defineProps
不需要
import
导入?因为在编译过程中如果当前
AST抽象语法树
的节点类型是
ExpressionStatement
表达式语句,并且调用的函数是
defineProps
,那么就调用
remove
方法将调用
defineProps
函数的代码给移除掉。既然
defineProps
语句已经被移除了,自然也就不需要
import
导入了
defineProps
了。为什么不能在非
setup
顶层使用
defineProps
?因为在非
setup
顶层使用
defineProps
的代码生成
AST抽象语法树
后节点类型就不是
ExpressionStatement
表达式语句类型,只有
ExpressionStatement
表达式语句类型才会走到
processDefineProps
函数中,并且调用
remove
方法将调用
defineProps
函数的代码给移除掉。当代码运行在浏览器时由于我们没有从任何地方
import
导入
defineProps
,当然就会报错
defineProps is not defined
。defineProps
是如何将声明的
props
自动暴露给模板?编译时在移除掉
defineProps
相关代码时会将调用
defineProps
函数时传入的参数
node
节点信息存到
ctx
上下文中。遍历完
AST抽象语法树后
,然后从上下文中存的参数
node
节点信息中拿到调用
defineProps
宏函数时传入
props
的开始位置和结束位置。再使用
slice
方法并且传入开始位置和结束位置,从
<script setup>
模块的代码字符串中截取到
props
定义的字符串。然后将截取到的
props
定义的字符串拼接到
vue
组件对象的字符串中,这样
vue
组件对象中就有了一个
props
属性,这个
props
属性在
template
模版中可以直接使用。
关注公众号:
前端欧阳
,解锁我更多
vue
干货文章,并且可以免费向我咨询
vue
相关问题。
Python爬虫实战系列1:博客园cnblogs热门新闻采集
实战案例:博客园热门新闻采集
一、分析页面
打开博客园网址https://www.cnblogs.com/,点击【新闻】再点击【本周】
本次采集,我们以页面新闻标题为案例来采集。这里可以看到标题“ 李彦宏:以后不会存在“程序员”这种职业了”。
1.1、分析请求
F12打开开发者模式,然后点击Network后点击任意一个请求,Ctrl+F开启搜索,输入标题
李彦宏:以后不会存在“程序员”这种职业了
,开始搜索
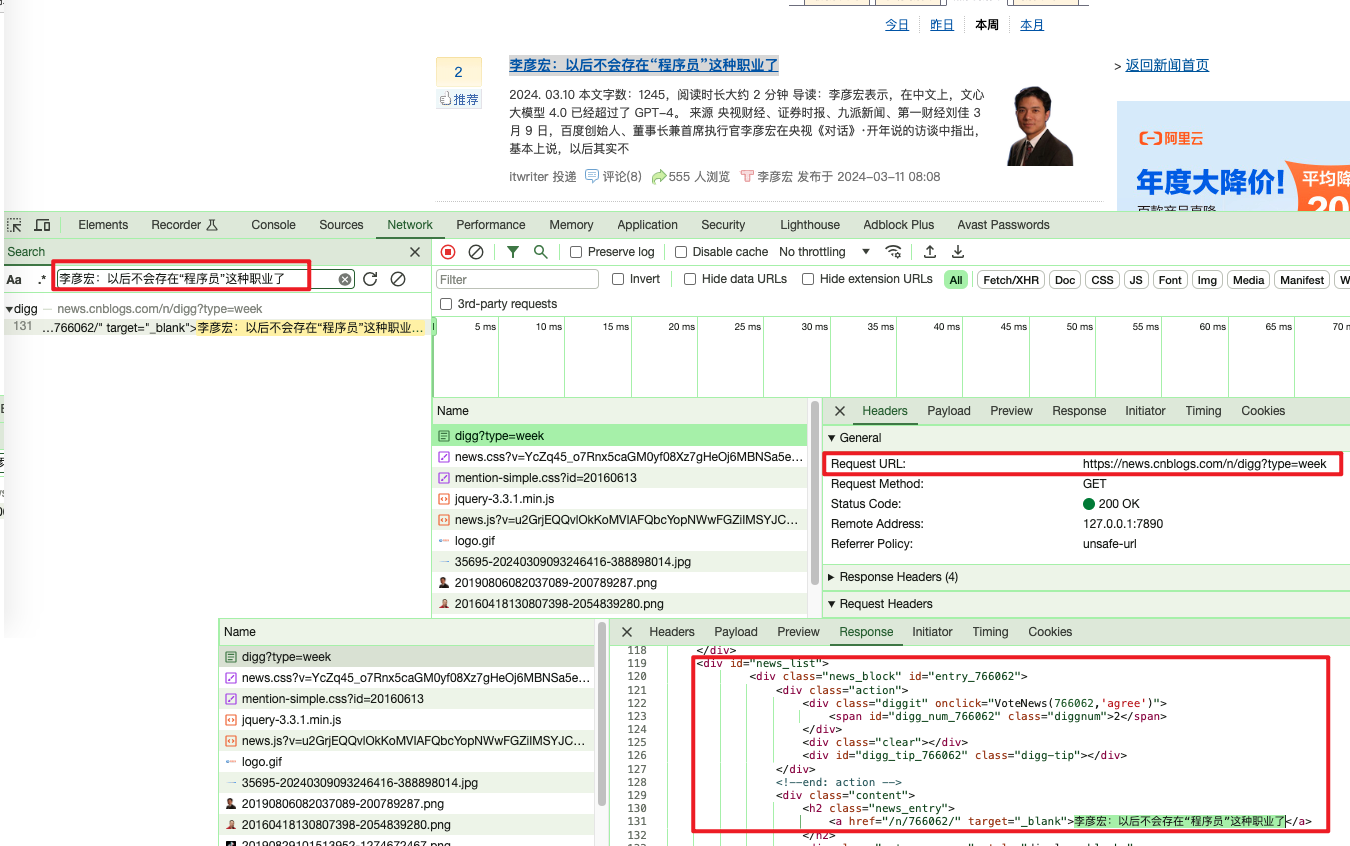
可以看到请求地址为
https://news.cnblogs.com/n/digg?type=week
但是返回的内容不是json格式,而是html源码,说明该页面是博客园后端拼接html源码返回给前端的,这里我们就不能简单的直接通过API接口来获取数据了,还需要对html源码进行解析。
1.2、分析页面
点击查看元素,然后点击新闻标题。
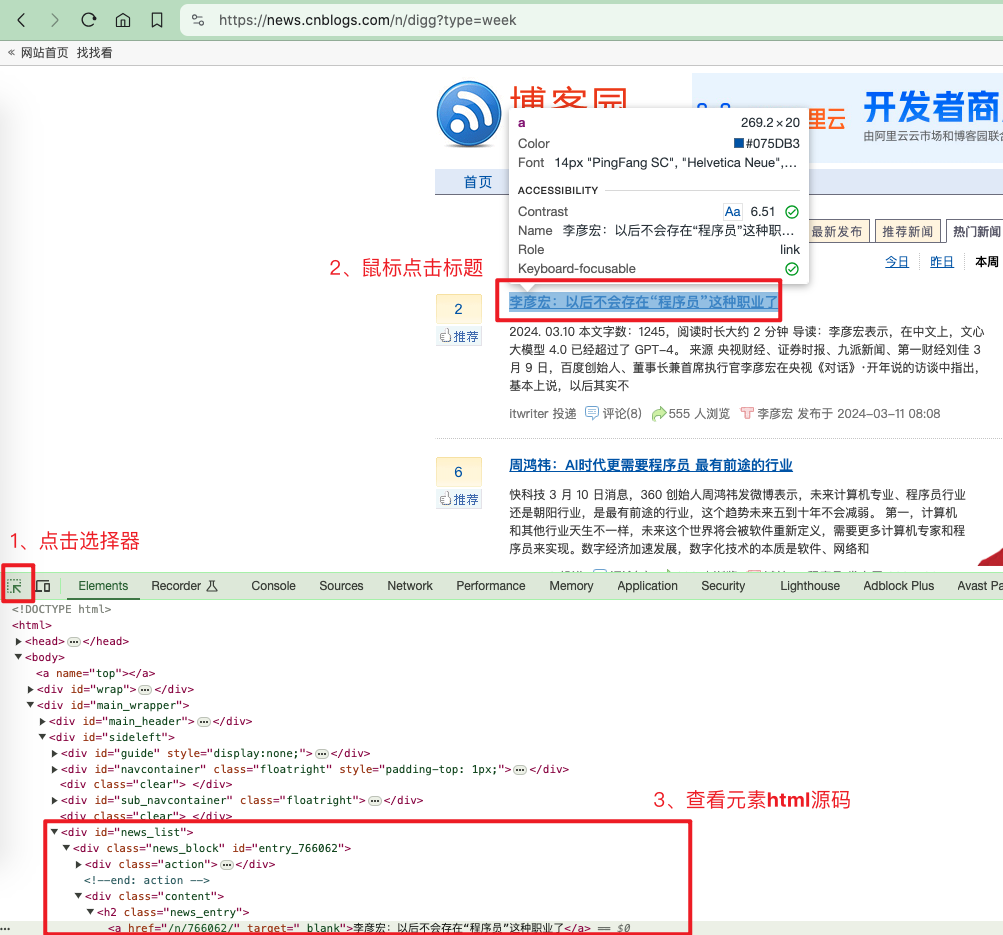
对应的html源码是
<a href="/n/766062/" target="_blank">李彦宏:以后不会存在“程序员”这种职业了</a>
通过源码我们可以看出,标题是被一个id=news_list的div包裹,然后news_div下还有news_block这个div包裹,然后是逐级向下,一直到a标签才是我们想要的数据。

1.3、分页信息处理
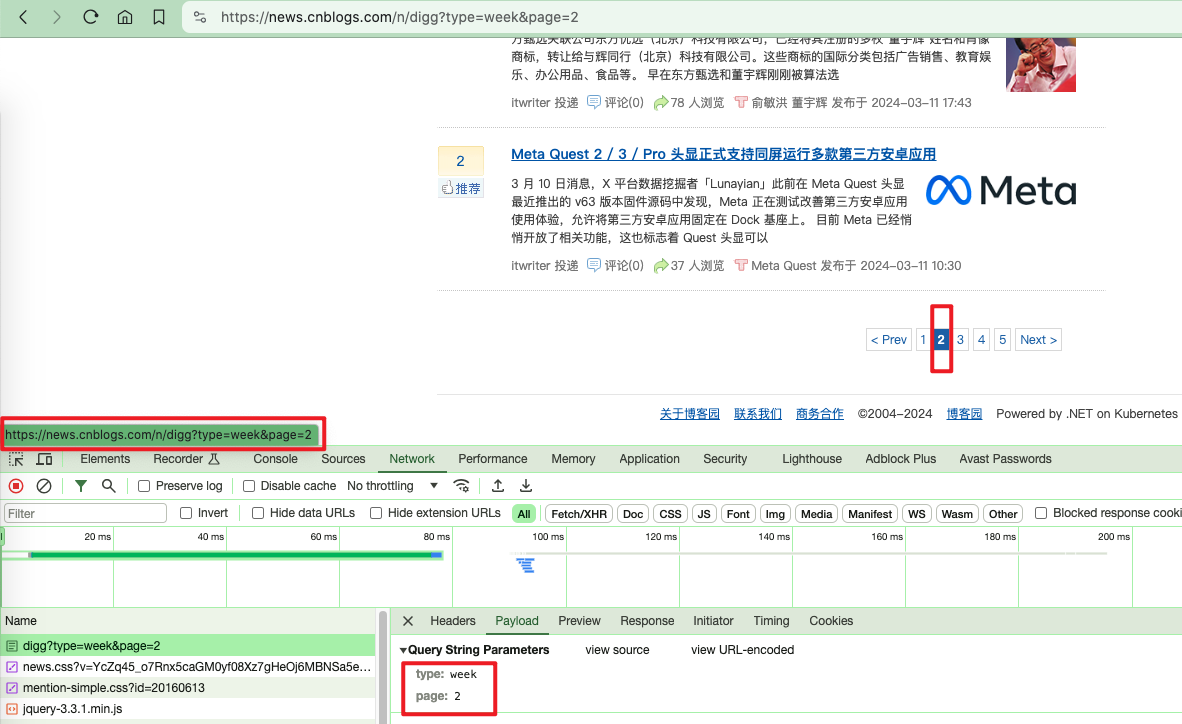
通过页面分析,可以看到分页很简单,直接在Query String QueryParamters里传入type: week、page: 2两个参数即可。
1.4、判断反爬及cookie
如何判断该请求需要哪些header和cookie参数?或者有没有反爬策略
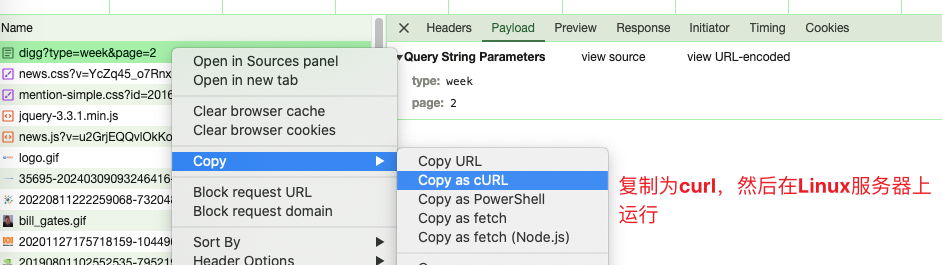
首先拷贝curl,在另一台机器上运行,curl代码如下
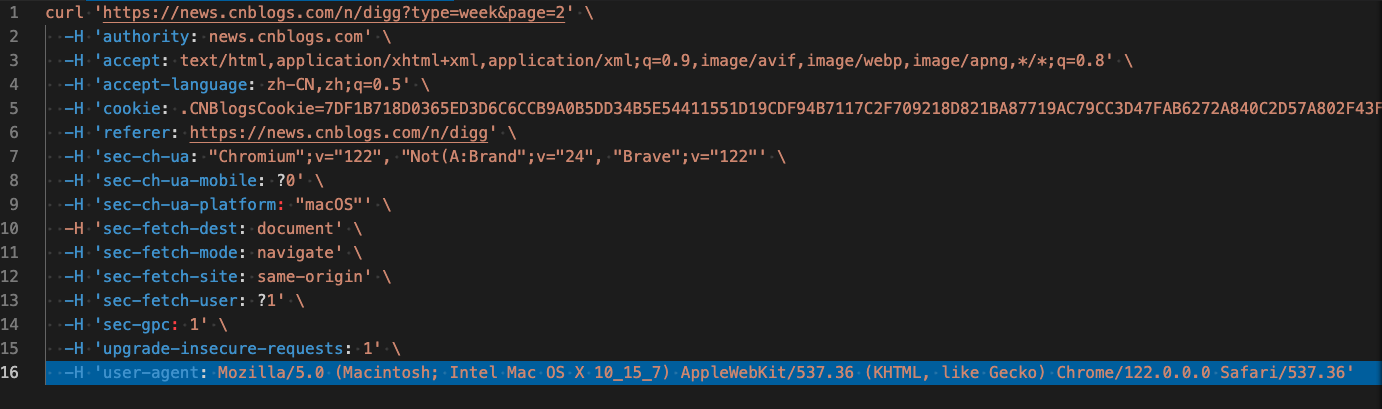
通过逐步删除代码中header参数来判断哪些是必要的参数,首先把cookie参数删除试试,发现可以获取到结果。由此判断,该网站没有设置cookie请求机制。
那就很简单了,直接发请求,解析html源码。
二、代码实现
新建Cnblogs类,并在init里设置默认header参数
class Cnblogs:
def __init__(self):
self.headers = {
'authority': 'news.cnblogs.com',
'referer': 'https://news.cnblogs.com/n/digg?type=yesterday',
'user-agent': USERAGENT
}
新建获取新闻get_news函数
def get_news(self):
result = []
for i in range(1, 4):
url = f'https://news.cnblogs.com/n/digg?type=today&page={i}'
content = requests.get(url)
html = etree.HTML(content.text)
news_list = html.xpath('//*[@id="news_list"]/div[@class="news_block"]')
for new in news_list:
title = new.xpath('div[@class="content"]/h2[@class="news_entry"]/a/text()')
push_date = new.xpath('div[@class="content"]/div[@class="entry_footer"]/span[@class="gray"]/text()')
result.append({
"news_title": str(title[0]),
"news_date": str(push_date[0]),
"source_en": spider_config['name_en'],
"source_cn": spider_config['name_cn'],
})
return result
代码主要使用了requests和lxml两个库来实现
测试运行
def main():
cnblogs = Cnblogs()
results = cnblogs.get_news()
print(results)
if __name__ == '__main__':
main()
完整代码
# -*- coding: utf-8 -*-
import os
import sys
import requests
from lxml import etree
opd = os.path.dirname
curr_path = opd(os.path.realpath(__file__))
proj_path = opd(opd(opd(curr_path)))
sys.path.insert(0, proj_path)
from app.utils.util_mysql import db
from app.utils.util_print import Print
from app.conf.conf_base import USERAGENT
spider_config = {
"name_en": "https://news.cnblogs.com",
"name_cn": "博客园"
}
class Cnblogs:
def __init__(self):
self.headers = {
'authority': 'news.cnblogs.com',
'referer': 'https://news.cnblogs.com/n/digg?type=yesterday',
'user-agent': USERAGENT
}
def get_news(self):
result = []
for i in range(1, 4):
url = f'https://news.cnblogs.com/n/digg?type=week&page={i}'
content = requests.get(url)
html = etree.HTML(content.text)
news_list = html.xpath('//*[@id="news_list"]/div[@class="news_block"]')
for new in news_list:
title = new.xpath('div[@class="content"]/h2[@class="news_entry"]/a/text()')
push_date = new.xpath('div[@class="content"]/div[@class="entry_footer"]/span[@class="gray"]/text()')
result.append({
"news_title": str(title[0]),
"news_date": str(push_date[0]),
"source_en": spider_config['name_en'],
"source_cn": spider_config['name_cn'],
})
return result
def main():
cnblogs = Cnblogs()
results = cnblogs.get_news()
print(results)
if __name__ == '__main__':
main()
总结
通过以上代码,我们实现了采集博客园的功能。
本文章代码只做学习交流使用,作者不负责任何由此引起的法律责任。
各位看官,如对你有帮助欢迎点赞,收藏,转发,关注公众号【Python魔法师】获取更多Python魔法~

多线程系列(十八) -AQS原理浅析
一、摘要
在之前的文章中,我们介绍了 ReentrantLock、ReadWriteLock、CountDownLatch、CyclicBarrier、Semaphore、ThreadPoolExecutor 等并发工具类的使用方式,它们在请求共享资源的时候,都能实现线程同步的效果。
在使用方式上稍有不同,有的是独占式,多个线程竞争时只有一个线程能执行方法,比如 ReentrantLock 等;有的是共享式,多个线程可以同时执行方法,比如:ReadWriteLock、CountDownLatch、Semaphore 等,不同的实现争用共享资源的方式也不同。
如果仔细阅读源码,会发现它们都是基于
AbstractQueuedSynchronizer
这个抽象类实现的,我们简称
AQS
。
AQS 是一个提供了原子式管理同步状态、阻塞和唤醒线程功能的框架,是除了 Java 自带的
synchronized
关键字之外的锁实现机制。
可以这么说,
AQS
是
JUC
包下线程同步类的基石,也是很多面试官喜欢提问的话题,掌握
AQS
原理对我们深入理解线程同步技术有着非常重要的意义。
本文以
ReentrantLock
作为切入点,来解读
AQS
相关的知识点,最后配上简单的应用示例来帮助大家理解 AQS,如果有描述不对的地方,欢迎大家留言指出,不胜感激!
二、ReentrantLock
在之前的线程系列文章中,我们介绍了
ReentrantLock
的基本用法,它是一个可重入的互斥锁,它具有与使用
synchronized
关键字一样的效果,并且功能更加强大,编程更加灵活,支持公平锁和非公平锁两种模式。
使用方式也非常简单,只需要在相应的代码上调用
加锁
和
释放锁
方法即可,简单示例如下!
public class Counter {
// 默认非公平锁模式
private final Lock lock = new ReentrantLock();
public void add() {
// 加锁
lock.lock();
try {
// 具体业务逻辑...
} finally {
// 释放锁
lock.unlock();
}
}
}
如果阅读
lock()
和
unlock()
方法,会发现它的底层都是由
AQS
来实现的。
下面,我们一起来看看这两个方法的源码实现,本文源码内容摘取自 JDK 1.8 版本,可能不同的版本略有区别!
2.1、lock 方法源码
public class ReentrantLock implements Lock, java.io.Serializable {
// 同步锁实现类
private final Sync sync;
public ReentrantLock() {
// 默认构造方法为非公平锁实现类
sync = new NonfairSync();
}
public ReentrantLock(boolean fair) {
// true:公平锁实现类,false:非公平锁实现类
sync = fair ? new FairSync() : new NonfairSync();
}
public void lock() {
// 加锁操作
sync.lock();
}
// 非公平锁实现类
static final class NonfairSync extends Sync {
// 加锁操作
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
}
// 公平锁实现类
static final class FairSync extends Sync {
// 加锁操作
final void lock() {
acquire(1);
}
}
// 公平锁和非公平锁,都继承自 AQS
abstract static class Sync extends AbstractQueuedSynchronizer {
// lock 抽象方法
abstract void lock();
}
}
从源码上可以清晰的看到,当初始化
ReentrantLock
对象时,需要指定锁的模式。
默认构造方法是
非公平锁模式
,采用的是
NonfairSync
内部实现类;公平锁模式下,则采用的是
FairSync
内部实现类;这两个内部实现类都继承了
Sync
抽象类;同时,
Sync
也继承了
AbstractQueuedSynchronizer
,也就是我们上文提到的
AQS
。
如果把
lock()
方法的请求链路进行抽象,可以用如下图进行简要概括。
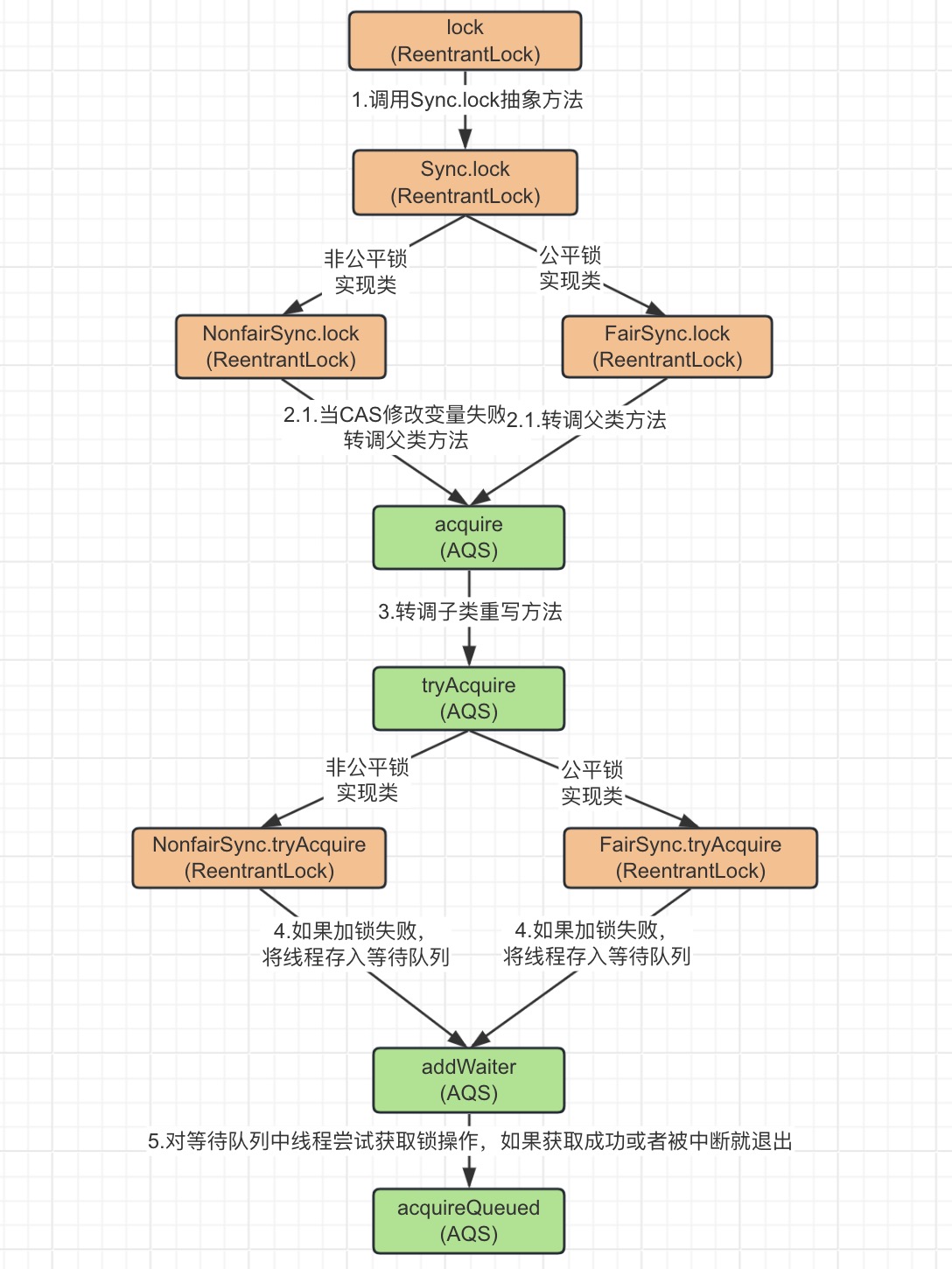
无论是非公平锁模式还是公平锁模式,可能最终都会调用
AQS
的
acquire()
方法,它表示
通过独占式的方式加锁
,我们继续往下看这个方法的源码,部分核心代码如下:
public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable {
// 通过独占式的方式加锁
public final void acquire(int arg) {
// 尝试加锁,会回调具体的实现类
if (!tryAcquire(arg) &&
// 如果尝试加锁失败,将当前线程加入等待队列
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
// 由子类完成加锁逻辑的实现,支持重写该方法
protected boolean tryAcquire(int arg) {
throw new UnsupportedOperationException();
}
}
从
AQS
的源码上可以看出,
acquire()
方法并不进行具体加锁逻辑的实现,而是通过具体的实现类重写
tryAcquire()
方法来完成加锁操作,如果加锁失败,会将当前线程加入等待队列。
如果是非公平锁模式,会回调
ReentrantLock
类的
NonfairSync.tryAcquire()
方法;如果是公平锁模式,会回调
ReentrantLock
类的
FairSync.tryAcquire()
方法,我们继续回看
ReentrantLock
类的源码。
非公平锁
NonfairSync
静态内部实现类,相关的源码如下!
// 非公平锁实现类
static final class NonfairSync extends Sync {
// 加锁操作
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
// 尝试非公平方式加锁,重写父类 tryAcquire 方法
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
// 采用CAS方式修改线程同步状态,如果成功返回true
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
// 支持当前线程,重复获得锁,将state值加1
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
公平锁
FairSync
静态内部实现类,相关的源码如下!
// 公平锁实现类
static final class FairSync extends Sync {
// 加锁操作
final void lock() {
acquire(1);
}
// 尝试公平方式加锁,重写父类 tryAcquire 方法
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
// 1)判断等待队列是否有线程处于等待状态,如果没有,尝试获取锁;如果有,就进入等待队列
// 2)采用CAS方式修改线程同步状态,如果成功返回true
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
// 支持当前线程,重复获得锁,将state值加1
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
从源码上可以清晰的看到,无论是是公平锁还是非公平锁模式,都是采用
compareAndSetState()
方法(简称
CAS
)进行加锁,如果成功就返回
true
;同时支持当前线程重复获得锁,也就是之前提到的锁可重入机制。
唯一的区别在于:公平锁实现类多了一个
hasQueuedPredecessors()
方法判断,它的用途是判断等待队列是否有线程处于等待状态,如果没有,尝试获取锁;如果有,就将当前线程存入等待队列,依此排队,从而保证线程通过公平方式获取锁的目的。
关于 CAS 实现原理,在之前的并发原子类文章中已经有所介绍,通过它加上
volatile
修饰符可以实现一个无锁的线程安全访问操作,本文不再重复解读,有兴趣的朋友可以翻阅之前的文章。
2.2、unlock 方法源码
public class ReentrantLock implements Lock, java.io.Serializable {
// 同步锁实现类
private final Sync sync;
public void unlock() {
// 释放锁操作
sync.release(1);
}
}
unlock()
方法的释放锁实现相对来说就简单多了,整个请求链路可以用如下图进行简要概括。
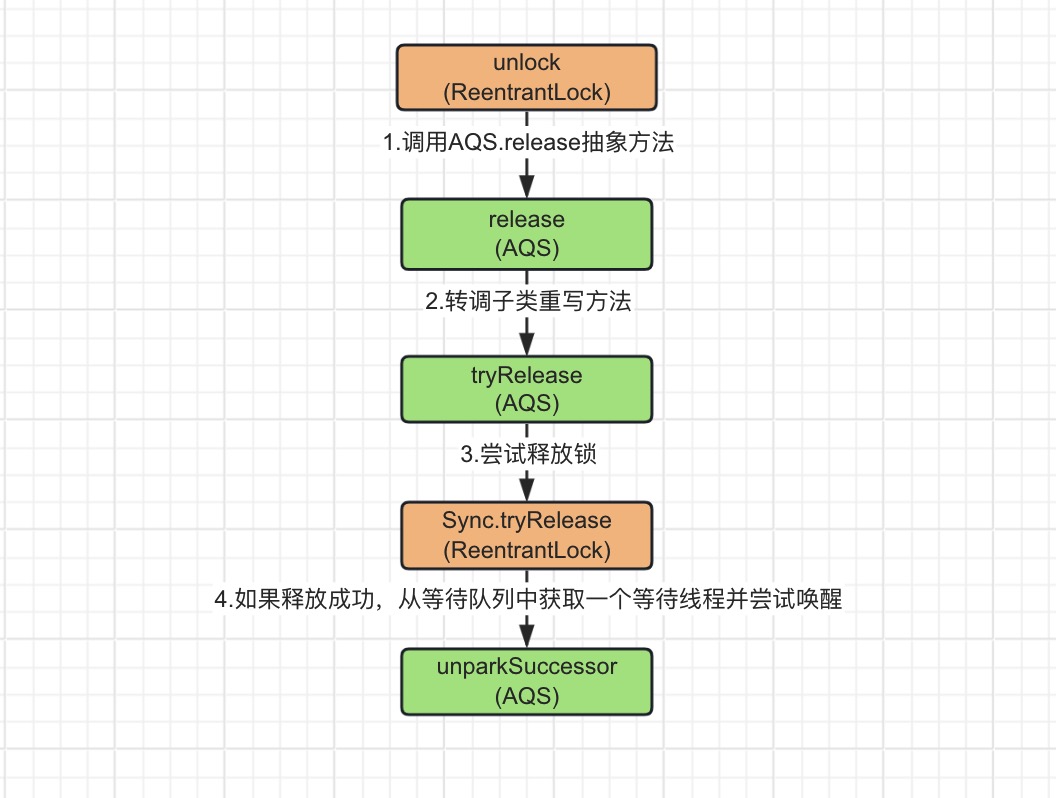
当调用
unlock()
方法时,会直接跳转到
AQS
的
release()
方法上,
AQS
相关的源码如下!
public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable {
// 释放锁操作
public final boolean release(int arg) {
// 尝试释放锁
if (tryRelease(arg)) {
// 从队列头部中获取一个等待线程,并进行唤醒操作
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
// 由子类完成释放锁逻辑的实现,支持重写该方法
protected boolean tryRelease(int arg) {
throw new UnsupportedOperationException();
}
}
与加锁操作类似,
AQS
的
release()
方法并不进行具体释放锁逻辑的实现,而是通过具体的实现类重写
tryRelease()
方法来完成释放锁操作,如果释放锁成功,会从队列头部中获取一个等待线程,并进行唤醒操作。
我们继续回看
ReentrantLock
类的
Sync.tryRelease()
释放锁方法,部分核心源码如下:
abstract static class Sync extends AbstractQueuedSynchronizer {
// 尝试释放锁
protected final boolean tryRelease(int releases) {
// 将state值进行减1操作
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
}
相比加锁过程,释放锁要简单的多,主要是将线程的同步状态值进行自减操作。
三、AQS 原理浅析
如果仔细的研究 AQS 的源码,尽管实现上很复杂,但是也有规律可循。
从上到下,整个框架可以分为五层,架构可以用如下图来描述!(图片来自
ReentrantLock 的实现看 AQS 的原理及应用 - 美团技术团队
)
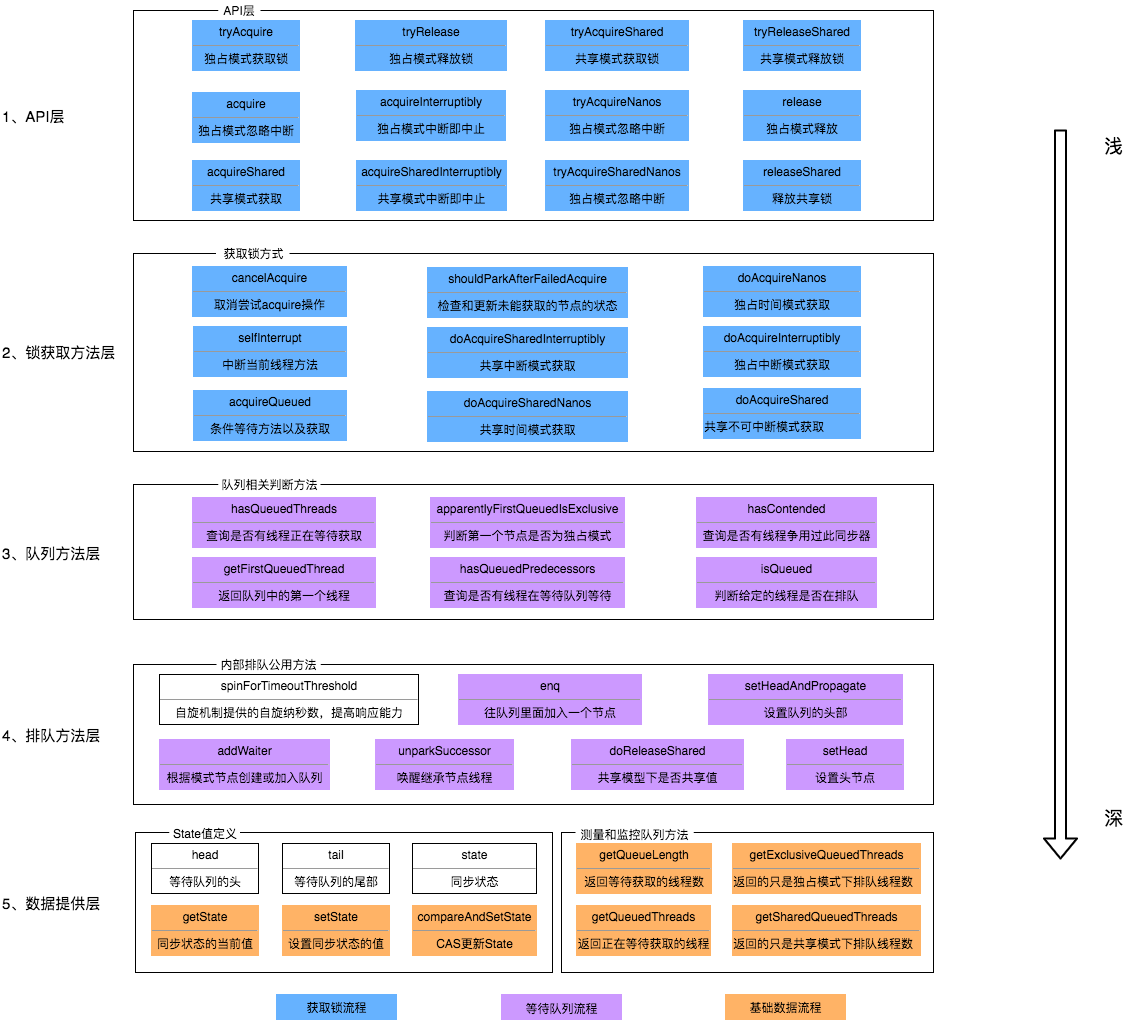
当有自定义线程同步器接入
AQS
时,只需要按需重写第一层的方法即可,不需要关心底层的实现。
以加锁为例,当调用
AQS
的 API 层获取锁方法时,会先尝试进行加锁操作(具体逻辑由实现类完成),如果加锁失败,会进入等待队列处理环节,这些处理逻辑同时也依赖最底层的基础数据提供层来完成。
3.1、原理概述
整个
AQS
实现线程同步的核心思想,可以用如下这段话来描述!
AQS 内部维护一个共享资源变量和线程等待队列,如果被请求的共享资源空闲,那么就将当前请求资源的线程设置为有效的工作线程,将共享资源设置为锁定状态;如果共享资源被占用,就需要一定的阻塞等待唤醒机制来保证锁分配。这个机制主要用的是 CLH 队列的变体实现的,将暂时获取不到锁的线程加入到等待队列中,待条件允许的时候将线程从队列中取出并进行唤醒。
CLH 队列是一个单向链表队列,对应的还有 CLH 锁实现,它是一个基于逻辑队列非线程饥饿的一种自旋公平锁实现,由 Craig、Landin 和 Hagersten 三位大佬发明,因此命名为 CLH 锁。关于这方面的技术知识讲解可以参阅这篇文章:
多图详解 CLH 锁的原理与实现
。
而
AQS
中的队列采用的是 CLH 变体的虚拟双向队列,通过将每一条请求共享资源的线程封装成一个 CLH 队列的一个节点来实现锁的分配。
具体实现原理,可以用如下图来简单概括:
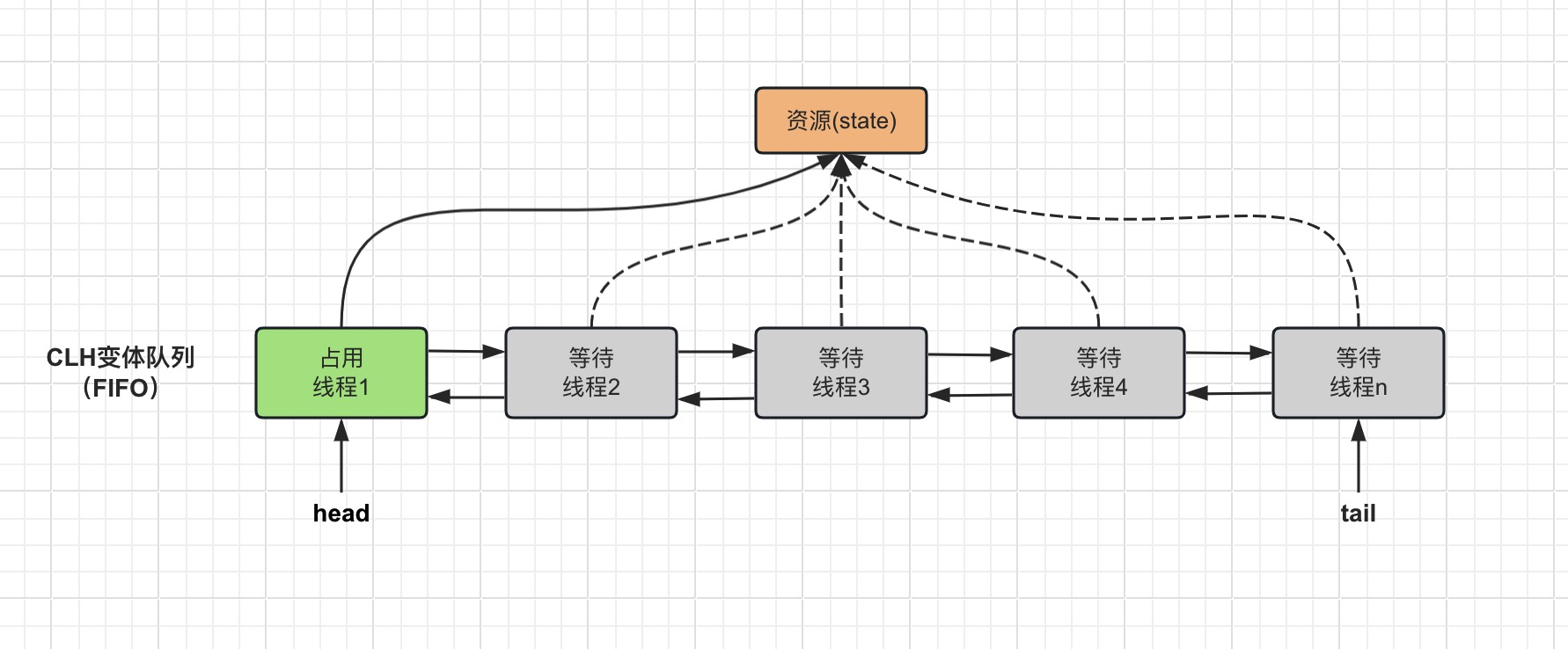
同时,
AQS
中维护了一个共享资源变量
state
,通过它来实现线程的同步状态控制,这个字段使用了
volatile
关键字修饰符来保证多线程下的可见性。
当多个线程尝试获取锁时,会通过
CAS
方式来修改
state
值,当
state=1
时表示当前对象锁已经被占有(相对独占模式来说),此时其他线程来加锁时会失败,加锁失败的线程会被放入上文说到的
FIFO
等待队列中,并且线程会被挂起,等待其他获取锁的线程释放锁才能够被唤醒。
总结下来,用大白话说就是,
AQS
是基于 CLH 队列,使用
volatile
修饰共享变量
state
,线程通过
CAS
方式去改变
state
状态值,如果成功则获取锁成功,失败则进入等待队列,等待被唤醒的线程同步器框架。
打开 ReentrantLock、ReadWriteLock、CountDownLatch、CyclicBarrier、Semaphore 等类的源码实现,你会发现它们的线程同步状态都是基于
AQS
实现的,可以看成是
AQS
的衍生物。
下面我们一起来看看相关的源码实现!
3.2、源码浅析
3.2.1、线程同步状态控制
AQS
源码中维护的共享资源变量
state
,表示同步状态的意思,它是实现线程同步控制的关键字段,核心源码如下:
/**
* The synchronization state.
*/
private volatile int state;
针对
state
字段值的获取和修改,
AQS
提供了三个方法,并且都采用
Final
修饰,意味着子类无法重写它们,相关方法如下:
| 方法 | 描述 |
|---|---|
| protected final int getState() | 获取
state
的值 |
| protected final void setState(int newState) | 设置
state
的值 |
| protected final boolean compareAndSetState(int expect, int update) | 使用 CAS 方式更新
state
|
如果仔细分析源码,
state
字段还有一个很大的用处,通过它可以实现
多线程的独占模式和共享模式
。
以
ReentrantLock
和
Semaphore
类为例,它们的加锁过程中
state
值的变化情况如下。
3.2.1.1、ReentrantLock 独占模式的获取锁,简易流程图如下:
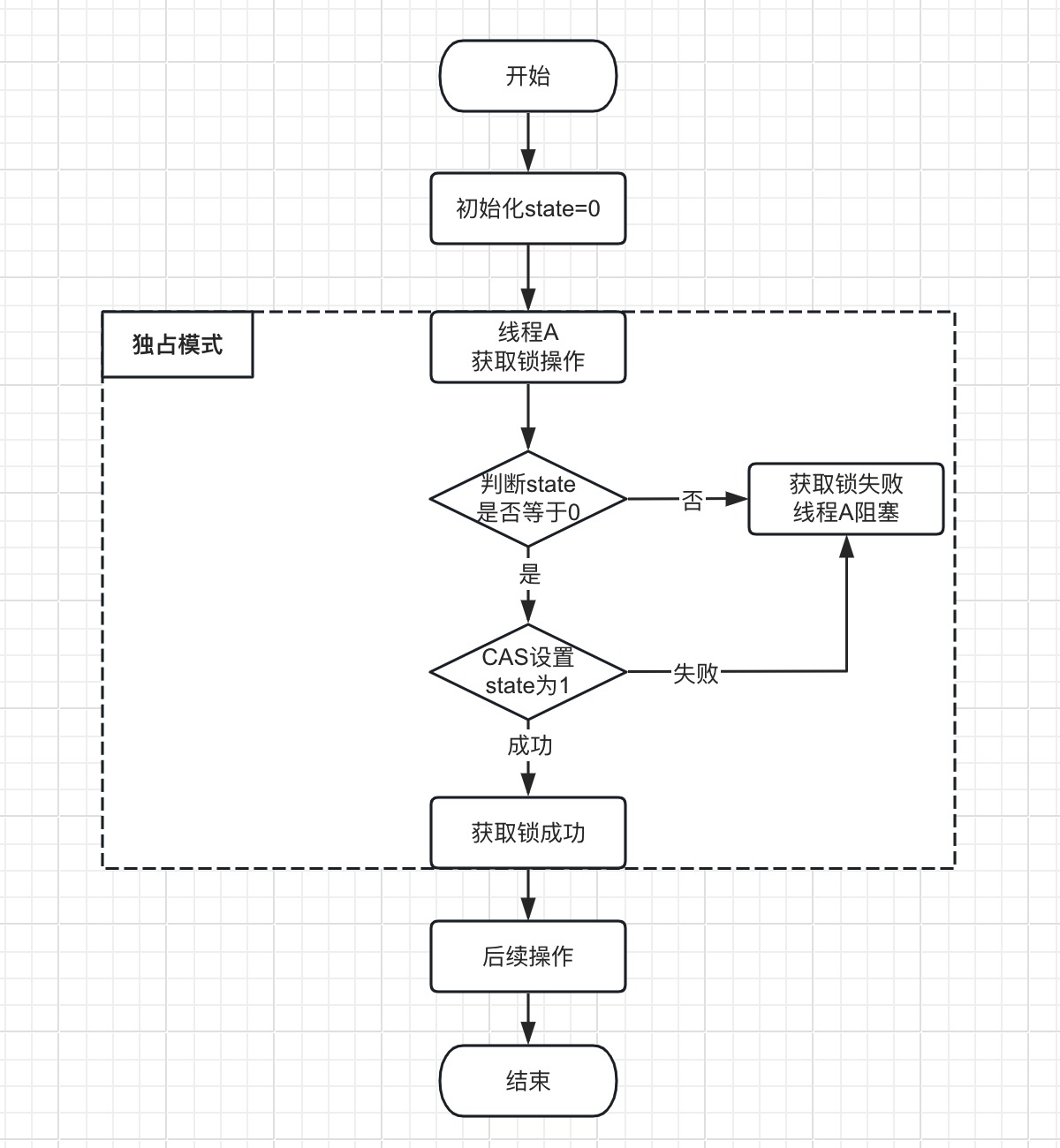
ReentrantLock
类部分核心源码,实现逻辑如下:
public class ReentrantLock implements Lock, java.io.Serializable {
// 非公平锁实现类
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
// 加锁操作
final void lock() {
// 将state从0设置为1,如果成功,直接获取当前共享资源
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
// 尝试加锁,会转调tryAcquire方法
acquire(1);
}
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
// 判断state是否等于0
if (c == 0) {
// 尝试state从0设置为1,如果成功,返回true
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
// 支持当前线程可重入,每调用一次,state的值加1
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
}
3.2.1.2、Semaphore 共享模式的获取锁,简易流程图如下:
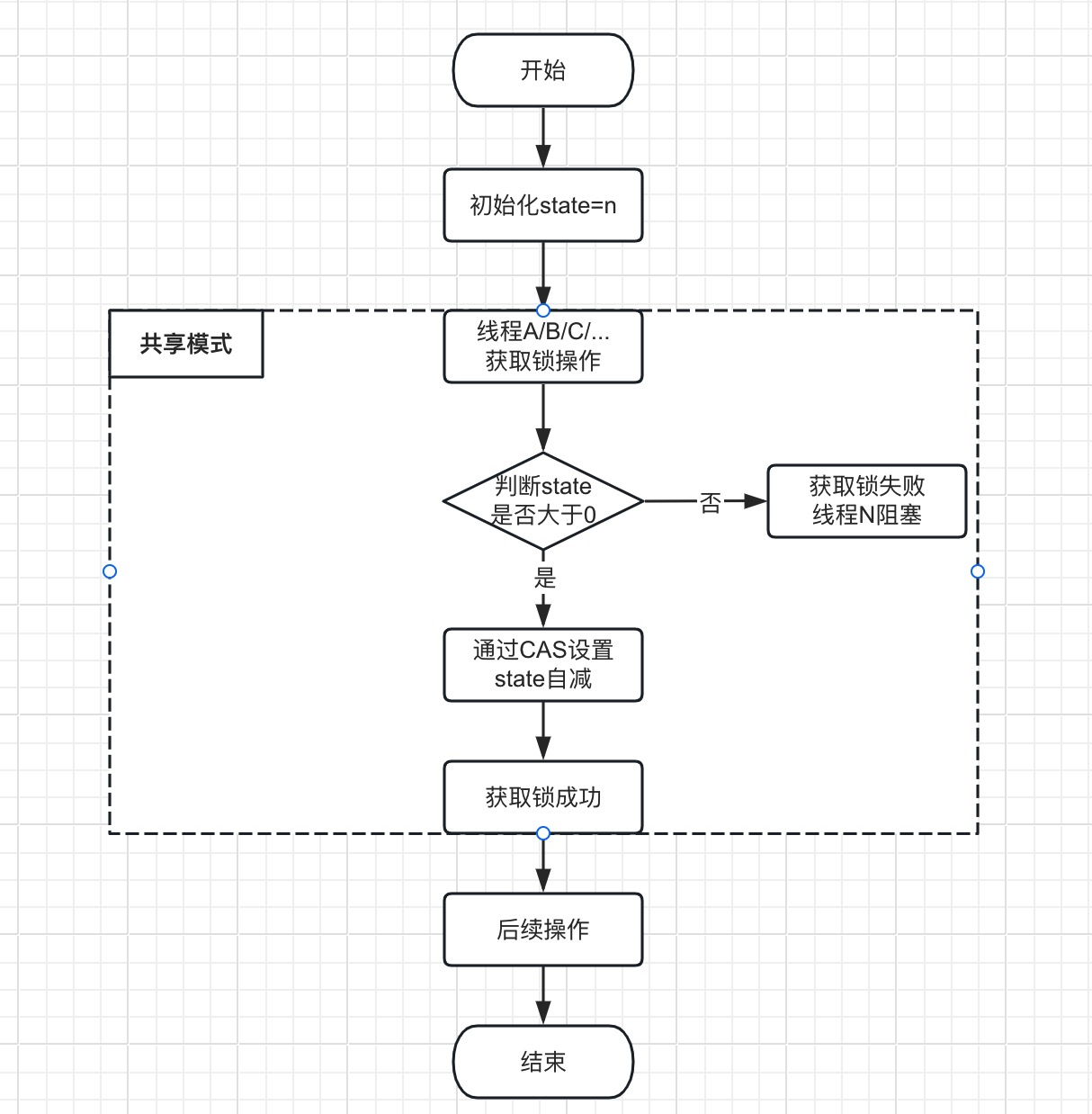
Semaphore
类部分核心源码,实现逻辑如下:
public class Semaphore implements java.io.Serializable {
// 初始化的时候,设置线程最大并发数,本质设置的是state的值
public Semaphore(int permits) {
sync = new NonfairSync(permits);
}
// 非公平锁内部实现类
static final class NonfairSync extends Sync {
NonfairSync(int permits) {
// 设置state的值
setState(permits);
}
// 通过共享方式,尝试获取锁
protected int tryAcquireShared(int acquires) {
return nonfairTryAcquireShared(acquires);
}
}
// 尝试获取共享资源,会调用Sync.nonfairTryAcquireShared方法
public boolean tryAcquire() {
// 如果state的值小于0,表示无可用共享资源
return sync.nonfairTryAcquireShared(1) >= 0;
}
// 抽象同步类
abstract static class Sync extends AbstractQueuedSynchronizer {
// 通过共享方式,尝试获取锁
final int nonfairTryAcquireShared(int acquires) {
for (;;) {
// 通过cas方式,设置state自减
int available = getState();
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
}
}
3.2.2、公平锁和非公平锁实现
在上文的
ReentrantLock
源码分析过程中,对于公平锁和非公平锁实现,其实已经有所解读。
在
AQS
中所有的加锁逻辑是有具有的实现类来完成,以
ReentrantLock
类为例,它的加锁逻辑由两个实现类来完成,分别是非公平锁静态内部实现类
NonfairSync
和公平锁静态内部实现类
FairSync
。
如上文的源码介绍,这两个类的的加锁逻辑基本一致,唯一的区别在于:公平锁实现类加锁时,增加了一个
hasQueuedPredecessors()
方法判断,这个方法会判断等待队列是否有线程处于等待状态,如果没有,尝试获取锁;如果有,就进入等待队列。
简单的说就是,非公平锁实现类的加锁方式,如果有线程尝试获取锁,直接尝试通过
CAS
方式进行抢锁,如果抢成功了,就直接获取锁,没有抢成功就进入等待队列;而公平锁实现类的加锁方式,会判断等待队列是否有线程处于等待状态,如果有则不去抢锁,乖乖排到后面,如果没有则尝试抢锁。
相对来说,非公平锁会有更好的性能,因为它的吞吐量比较大。其次,非公平锁让获取锁的时间变得更加不确定,可能会导致在阻塞队列中的线程长期处于饥饿状态。
Semaphore
类的公平锁和非公平锁实现也类似,拥有两个静态内部实现类,源码就不再解读了,有兴趣的朋友可以自行阅读。
3.2.3、主要模板方法
从
ReentrantLock
的源码实现中可以看出,
AQS
使用了
模板方法设计模式
,它不提供加锁和释放锁的具体逻辑实现,而是由实现类重写对应的方法来完成,这样的好处就是实现更加的灵活,不同的线程同步器可以自行继承
AQS
类,然后实现独属于自身的加锁和解锁功能。
常用的模板方法主要有以下几个:
| 方法 | 描述 |
|---|---|
| protected boolean isHeldExclusively() | 判断该线程是否正在独占资源。只有用到
Condition
才需要去实现它 |
| protected boolean tryAcquire(int arg) | 独占方式。尝试获取资源,
arg
为获取锁的次数,成功则返回
true
,失败则返回
false
|
| protected boolean tryRelease(int arg) | 独占方式。尝试释放资源,
arg
为释放锁的次数,成功则返回
true
,失败则返回
false
|
| protected int tryAcquireShared(int arg) | 共享方式。尝试获取资源,
arg
为获取锁的次数,负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源 |
| protected boolean tryReleaseShared(int arg) | 共享方式。尝试释放资源,
arg
为释放锁的次数,如果释放后允许唤醒后续等待结点返回
true
,否则返回
false
|
通常自定义线程同步器,要么是独占模式,要么是共享模式。
如果是独占模式,重写
tryAcquire()
和
tryRelease()
方法即可,比如 ReentrantLock 类。
如果是共享模式,重写
tryAcquireShared()
和
tryReleaseShared()
方法即可,比如 Semaphore 类。
3.2.4、线程加入等待队列实现
当线程调用
tryAcquire()
方法获取锁失败之后,就会调用
addWaiter()
方法,将当前线程加入到等待队列中去。
addWaiter()
方法,部分核心源码如下:
public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable {
// 将当前线程加入等待队列
private Node addWaiter(Node mode) {
// 以当前线程构造一个节点,尝试通过CAS方式插入到双向链表的队尾
Node node = new Node(Thread.currentThread(), mode);
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
// 如果插入没有成功,则通过enq入队
enq(node);
return node;
}
// 通过enq入队
private Node enq(final Node node) {
// CAS 自旋方式,直到成功加入队尾
for (;;) {
Node t = tail;
if (t == null) {
// 队列为空,创建一个空结点作为head结点,并将tail也指向它
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
}
我们再来看看
Node
类节点相关的属性,部分核心源码如下:
static final class Node {
// 当前节点在队列中的状态,状态值枚举含义如下:
// 0:节点初始化时的状态
// 1: 表示节点引用线程由于等待超时或被打断时的状态
// -1: 表示当队列中加入后继节点被挂起时,其前驱节点会被设置为SIGNAL状态,表示该节点需要被唤醒
// -2:当节点线程进入condition队列时的状态
// -3:仅在释放共享锁releaseShared时对头节点使用
volatile int waitStatus;
// 前驱节点
volatile Node prev;
// 后继节点
volatile Node next;
//该节点的线程实例
volatile Thread thread;
// 指向下一个处于Condition状态的节点(用于条件队列)
Node nextWaiter;
//...
}
可以很清晰的看到,每个关键属性变量都加了
volatile
修饰符,确保多线程环境下可见。
正如上文所介绍的,
Node
其实是一个双向链表数据结构,大致的数据结构图如下!(图片来自
ReentrantLock 的实现看 AQS 的原理及应用 - 美团技术团队
)
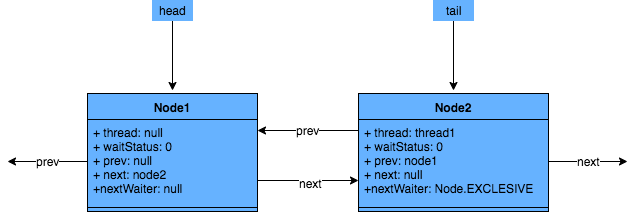
其中第一个节点,也叫头节点,为虚节点,并不存储任何线程信息,只是占位用;真正有数据的是从第二个节点开始,当有线程需要加入等待队列时,会向队尾进行插入。
线程加入等待队列之后,会再次调用
acquireQueued()
方法,尝试进行获取锁,如果成功或者中断就退出,部分核心源码如下:
final boolean acquireQueued(final Node node, int arg) {
// 标记是否成功拿到锁
boolean failed = true;
try {
// 标记等待过程中是否中断过
boolean interrupted = false;
// 开始自旋,要么获取锁,要么中断
for (;;) {
// 获取当前节点的前驱节点
final Node p = node.predecessor();
// 如果p是头结点,说明当前节点在等待队列的头部,尝试获取锁(头结点是虚节点)
if (p == head && tryAcquire(arg)) {
// 获取锁成功,头指针移动到当前node
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
// 如果p不是头节点或者是头节点但获取锁失败,判断当前节点是否要进入阻塞,如果满足要求,就通过park让线程进入阻塞状态,等待被唤醒
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
// 如果没有成功获取锁(比如超时或者被中断),那么取消节点在队列中的等待
cancelAcquire(node);
}
}
线程加入等待队列实现,总结下来,大致步骤如下:
- 1.调用
addWaiter()
方法,将当前线程封装成一个节点,尝试通过
CAS
方式插入到双向链表的队尾,如果没有成功,再通过自旋方式插入,直到成功为止 - 2.调用
acquireQueued()
方法,对在等待队列中排队的线程,尝试获取锁操作,如果失败,判断当前节点是否要进入阻塞,如果满足要求,就通过
LockSupport.park()
方法让线程进入阻塞状态,并检查是否被中断,如果没有,等待被唤醒
3.2.5、线程从等待队列中被唤醒实现
当线程调用
tryRelease()
方法释放锁成功之后,会从等待队列的头部开始,获取排队的线程,并进行唤醒操作。
释放锁方法,部分核心源码如下:
public final boolean release(int arg) {
// 尝试释放锁
if (tryRelease(arg)) {
// 获取头部节点
Node h = head;
if (h != null && h.waitStatus != 0)
// 尝试唤醒头部节点的下一个节点中的线程
unparkSuccessor(h);
return true;
}
return false;
}
其中
unparkSuccessor()
是执行唤醒线程的核心方法,部分核心源码如下:
private void unparkSuccessor(Node node) {
// 获取头结点 waitStatus
int ws = node.waitStatus;
// 置零当前线程所在的结点状态,允许失败
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
// 获取当前节点的下一个节点s
Node s = node.next;
// 如果下个节点是null或者被取消,就从队列尾部依此寻找节点
if (s == null || s.waitStatus > 0) {
s = null;
// 从尾部节点开始向前找,找到队列中排在最前的有效节点
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
// 将当前节点的下一个节点中的线程,进行唤醒操作
if (s != null)
LockSupport.unpark(s.thread);
}
线程从等待队列中被唤醒实现,总结下来,大致步骤如下:
- 1.当线程调用
tryRelease()
方法释放锁成功之后,会从等待队列获取排队的线程 - 2.如果队列的头节点的下一个节点有效,会尝试进行唤醒节点中的线程;如果为空或者被取消,就从队列尾部依此寻找节点,找到队列中排在最前的有效节点,并尝试进行唤醒操作
四、简单应用
了解完
AQS
基本原理之后,按照以上的知识点,我们可以自己实现一个不可重入的互斥锁线程同步类。
示例代码如下:
public class MutexLock {
// 自定义同步器
private static class Sync extends AbstractQueuedSynchronizer {
// 判断是否锁定状态
@Override
protected boolean isHeldExclusively() {
return getState() == 1;
}
// 尝试获取资源,立即返回。成功则返回true,否则false。
@Override
protected boolean tryAcquire(int acquires) {
//state为0才设置为1,不支持重入!
if (compareAndSetState(0, 1)) {
//设置为当前线程独占资源
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
// 尝试释放资源,立即返回。成功则为true,否则false。
@Override
protected boolean tryRelease(int releases) {
// 判断资源是否已被释放
if (getState() == 0)
throw new IllegalMonitorStateException();
setExclusiveOwnerThread(null);
//释放资源,放弃占有状态
setState(0);
return true;
}
}
// 真正同步类的实现都依赖继承于AQS的自定义同步器!
private final Sync sync = new Sync();
// 获取锁,会阻塞等待,直到成功才返回
public void lock() {
sync.acquire(1);
}
// 释放锁
public void unlock() {
sync.release(1);
}
}
测试类如下:
public class MutexLockTest {
private static int count =0;
private static MutexLock lock = new MutexLock();
public static void main(String[] args) throws Exception {
final int threadNum = 10;
CountDownLatch latch = new CountDownLatch(threadNum);
// 创建10个线程,同时对count进行1000相加操作
for (int i = 0; i < threadNum; i++) {
new Thread(new Runnable() {
@Override
public void run() {
// 加锁
lock.lock();
for (int j = 0; j < 1000; j++) {
count++;
}
// 释放锁
lock.unlock();
// 线程数减 1
latch.countDown();
}
}).start();
}
// 等待线程执行完毕
latch.await();
System.out.println("执行结果:" + count);
}
}
输出结果:
执行结果:10000
从日志输出结果可以清晰的看到,执行结果与预期值一致!
五、小结
本文从
ReentrantLock
源码分析到
AQS
原理解析,进行了一次知识内容的总结,从上文的分析中可以看出,
AQS
是
JUC
包下线程同步器实现的基石。
ReentrantLock、ReadWriteLock、CountDownLatch、CyclicBarrier、Semaphore、ThreadPoolExecutor 等并发工具类,线程同步的实现都基于
AQS
来完成,掌握
AQS
原理对线程同步的理解和使用至关重要。
AQS
原理是面试时热点话题,希望本篇能帮助到大家!
六、参考
1.
https://www.cnblogs.com/waterystone/p/4920797.html
2.
https://tech.meituan.com/2019/12/05/aqs-theory-and-apply.html