深入浅出Java多线程(十一):AQS
大家好,我是你们的老伙计秀才!今天带来的是[深入浅出Java多线程]系列的第十一篇内容:AQS(
AbstractQueuedSynchronizer
)。大家觉得有用请点赞,喜欢请关注!秀才在此谢过大家了!!!
在现代多核CPU环境中,多线程编程已成为提升系统性能和并发处理能力的关键手段。然而,当多个线程共享同一资源或访问临界区时,如何有效地控制线程间的执行顺序以保证数据一致性及避免竞态条件变得至关重要。Java平台为解决这些问题提供了多种同步机制,如synchronized关键字、volatile变量以及更加灵活且功能强大的并发工具类库——java.util.concurrent包。 在这一庞大的并发工具箱中,AbstractQueuedSynchronizer(简称AQS)扮演了核心角色。作为Java并发框架中的基石,AQS是一个高度抽象的底层同步器,它不仅被广泛应用于诸如ReentrantLock、Semaphore、CountDownLatch、CyclicBarrier等标准同步组件,还为开发者提供了一种便捷的方式来构建符合特定需求的自定义同步器。 AQS的设计理念是基于模板方法模式,通过封装复杂的同步状态管理和线程排队逻辑,使得子类只需关注并实现资源获取与释放的核心算法即可。它使用一个名为 例如,在ReentrantLock中,AQS负责记录当前持有锁的线程重入次数,而当线程尝试获取但无法立即获得锁时,会将该线程包装成Node节点并安全地插入到等待队列中。随后,线程会被优雅地阻塞,直至锁被释放或者其在等待队列中的位置变为可以获取资源的状态。这个过程涉及到一系列精心设计的方法调用,如tryAcquire(int)、acquireQueued(Node, int)和release(int)等。 在这个简单的示例中,我们创建了一个ReentrantLock实例并在两个线程中分别调用lock方法进入临界区。如果第一个线程已经占有锁,第二个线程将会进入等待队列,直到锁被释放。这背后的机制正是由AQS提供的强大同步支持所驱动的。通过对AQS的深入探讨,读者将能更好地理解这些高级同步工具的内部工作原理,从而更高效地进行并发编程实践。 在Java多线程编程中,AbstractQueuedSynchronizer(简称AQS)作为J.U.C包下的一款核心同步框架,扮演了构建高效并发锁和同步器的重要角色。AQS的设计理念与实现机制极大地简化了开发人员创建自定义同步组件的工作量,同时提供了强大的底层支持以满足多样化的并发控制需求。 队列管理: 同步功能: 应用实例: 下面是一个简单的代码示例,展示了如何使用基于AQS实现的ReentrantLock进行线程同步: 在这个例子中,当一个线程调用lock方法并成功获取到资源(即获得锁)时,另一个线程必须等待直至锁被释放。这一过程正是通过AQS所维护的线程等待队列和相应的同步算法得以实现的。此外,AQS也支持资源共享的两种模式,即独占模式(一次只有一个线程能获取资源)和共享模式(允许多个线程同时获取资源但数量有限制),并且灵活地支持可中断的资源请求操作,为复杂多样的并发场景提供了一站式的解决方案。 在Java多线程编程中,AbstractQueuedSynchronizer(AQS)的数据结构设计是其高效实现同步功能的关键。AQS的核心数据结构主要包括以下几个部分: volatile变量state Node双端队列 waitStatus标志位 线程调度逻辑 资源共享模式支持 尽管AQS提供了如 总结AQS的数据结构如下图: 在Java多线程同步框架AbstractQueuedSynchronizer(AQS)中,资源共享模式是其核心概念之一,用于定义并发环境中资源的访问方式。AQS支持两种主要的资源共享模式:独占模式(Exclusive)和共享模式(Share)。 独占模式 在这个示例中,两个线程尝试进入临界区,但由于使用的是ReentrantLock(基于AQS),因此在同一时刻仅允许一个线程执行临界区代码。 共享模式 此例中,Semaphore初始化为3个许可,这意味着最多三个线程可以同时执行 总之,无论是独占模式还是共享模式,AQS都提供了底层机制来确保线程安全地进行资源的获取与释放,并利用双端队列结构及状态变量维护线程的等待、唤醒逻辑,使得这些高级同步工具能够在各种复杂的并发场景中表现得既高效又稳定。 在Java多线程同步框架AbstractQueuedSynchronizer(AQS)中,有几个关键方法是实现资源获取与释放的核心逻辑。这些方法由子类覆盖以满足特定的同步需求,并结合AQS提供的底层队列管理和状态更新机制,确保了线程间的同步操作正确且高效地执行。 tryAcquire(int arg) tryAcquireShared(int arg) acquire(int arg) acquireInterruptibly(int arg) isHeldExclusively() 综上所述,AQS通过提供一套模板方法供子类扩展,从而实现了灵活且高效的线程同步机制。在实际应用中,开发者可以根据具体场景重写相应的tryAcquire系列方法,利用AQS强大的底层队列和原子状态管理功能来实现复杂的并发控制逻辑。 总结AQS的流程如下图: 在Java多线程同步框架AbstractQueuedSynchronizer(AQS)中,资源释放逻辑是同步机制中的重要一环。当一个线程完成了对共享资源的独占或共享操作后,需要通过调用相应的release方法来释放资源,使得等待队列中的其他线程有机会获取并使用这些资源。 资源释放入口: 唤醒后续结点: 中断与资源管理: 此外,在资源释放的过程中,AQS确保了操作的原子性和一致性,防止多个线程同时释放资源造成混乱。正是由于这种精心设计的资源释放逻辑,基于AQS构建的同步组件才能够高效、安全地协调多线程对共享资源的访问。 举例来说,在使用ReentrantLock时,线程在完成临界区代码后应调用lock对象的unlock()方法释放锁: 在这个例子中,当执行到finally块的unlock()方法时,就触发了AQS内部的资源释放逻辑,从而有可能唤醒另一个之前因无法获取锁而进入等待状态的线程。 AbstractQueuedSynchronizer(AQS)作为Java并发编程中至关重要的框架,为构建高效、安全的锁和其他同步器提供了基础结构。它巧妙地结合了数据结构和原子操作,实现了线程间的资源共享管理,并支持独占模式和共享模式两种主要的同步方式。 在AQS的设计中,volatile变量 对于资源的获取流程,AQS采用自旋+CAS的方式插入新的等待节点至队尾,当无法立即获取资源时,线程会进入等待状态并通过LockSupport.park阻塞自身。而在资源释放时,AQS则通过unparkSuccessor方法唤醒等待队列中的下一个合适节点,使得资源能够被有效地传递给其他线程。 例如,在ReentrantLock中,AQS用于实现可重入的锁功能,当线程调用lock()方法尝试获取锁时,如果当前锁已被占用,则线程将加入等待队列;而当线程调用unlock()方法释放锁时,AQS会自动处理后续线程的唤醒工作。 总的来说,AQS通过模板方法设计模式,简化了自定义同步组件的开发难度,开发者仅需关注资源访问策略的实现,即可构建出如ReentrantLock、Semaphore、CountDownLatch等多种广泛应用的同步工具类。AQS以其强大的内核机制,极大地提升了Java多线程环境下的同步性能和灵活性,成为并发编程库不可或缺的基石。 本文使用
引言
state
的volatile变量来表示同步状态,并借助于FIFO双端队列结构来管理等待获取资源的线程。AQS内部维护的Node节点不仅包含了每个等待线程的信息,而且还通过waitStatus标志位巧妙地实现了独占式和共享式的两种资源共享模式。// 示例代码:ReentrantLock基于AQS的简单应用
import java.util.concurrent.locks.ReentrantLock;
public class AQSExample {
private final ReentrantLock lock = new ReentrantLock();
public void criticalSection() {
lock.lock(); // 调用lock()即尝试获取AQS的资源
try {
// 临界区代码
System.out.println("Thread " + Thread.currentThread().getName() + " is executing critical section.");
} finally {
lock.unlock(); // 释放资源
}
}
public static void main(String[] args) {
AQSExample example = new AQSExample();
Thread t1 = new Thread(example::criticalSection, "Thread-1");
Thread t2 = new Thread(example::criticalSection, "Thread-2");
t1.start();
t2.start();
}
}
AQS简介
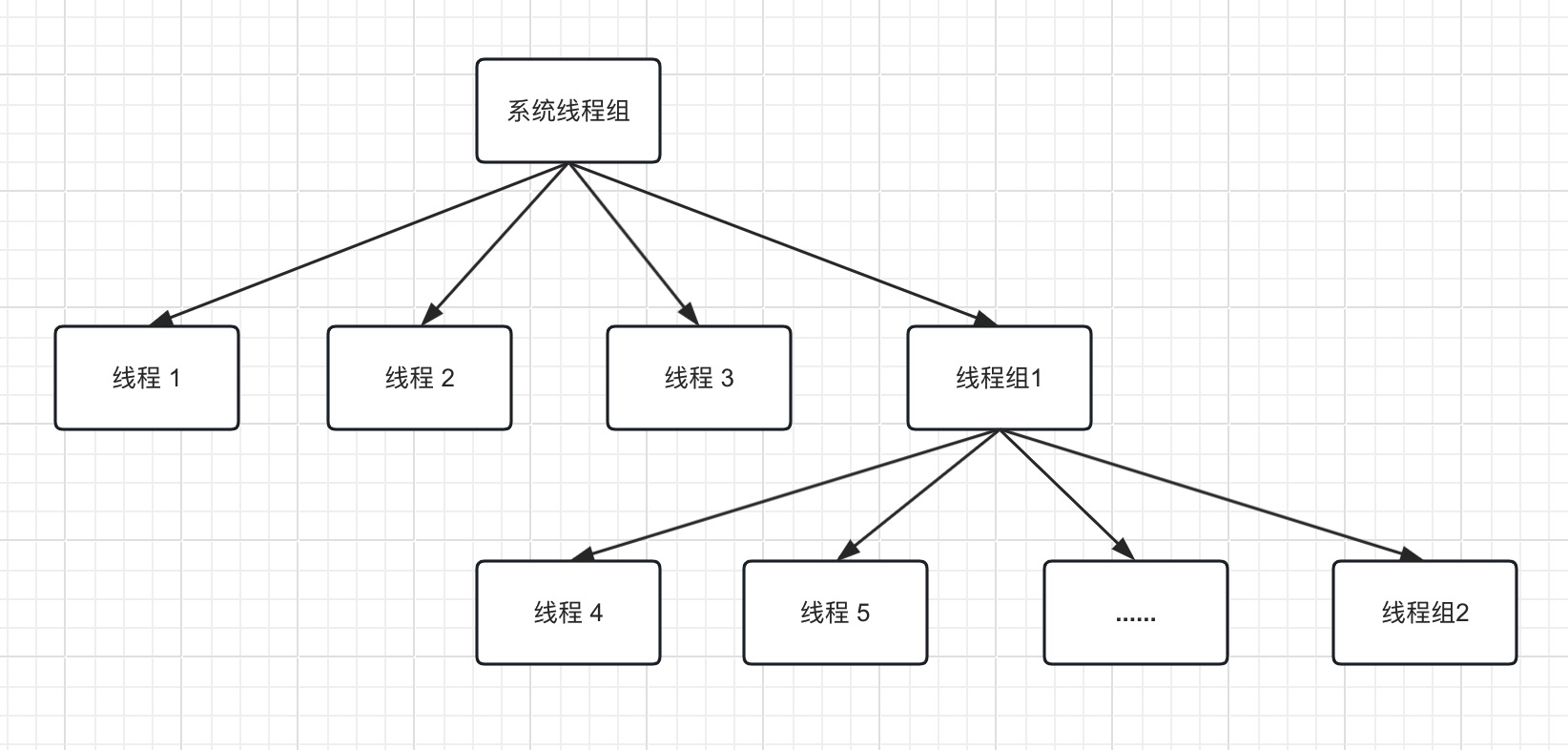
从数据结构层面看,AQS内部维护了一个基于先进先出(FIFO)原则的双端队列。该队列并非直接存储线程对象,而是使用Node节点表示等待资源的线程,并通过volatile变量state记录当前资源的状态。AQS利用两个指针head和tail精确地跟踪队列的首尾位置,确保线程在无法立即获取资源时能够安全且有序地进入等待状态。
AQS不仅实现了对资源的原子操作,例如通过
getState()
、
setState()
以及基于Unsafe的
compareAndSetState()
方法保证资源状态更新的原子性和可见性,还提供了线程排队和阻塞机制,包括线程等待队列的维护、入队与出队的逻辑,以及线程在资源未得到时如何正确地挂起和唤醒等核心功能。
AQS的强大之处在于它支撑了许多常见的并发工具类,诸如ReentrantLock、Semaphore、CountDownLatch、ReentrantReadWriteLock以及SynchronousQueue等,这些同步工具均是建立在AQS基础之上的,有效地解决了多线程环境下的互斥访问、信号量控制、倒计数等待、读写分离等多种同步问题。import java.util.concurrent.locks.ReentrantLock;
public class AQSExample {
private final ReentrantLock lock = new ReentrantLock();
public void criticalSection() {
lock.lock(); // 调用lock()方法尝试获取AQS管理的资源
try {
// 执行临界区代码
System.out.println("Thread " + Thread.currentThread().getName() + " is in the critical section.");
} finally {
lock.unlock(); // 在finally块中确保资源始终会被释放
}
}
public static void main(String[] args) {
AQSExample example = new AQSExample();
Thread t1 = new Thread(example::criticalSection, "Thread-1");
Thread t2 = new Thread(example::criticalSection, "Thread-2");
t1.start();
t2.start();
}
}
AQS的数据结构
:
AQS内部维护了一个名为
state
的volatile整型变量,用于表示共享资源的状态。该状态值可以用来反映资源的数量、锁的持有状态等信息,具体含义由基于AQS构建的具体同步组件定义。由于state是volatile修饰的,因此确保了对它的修改能被其他线程及时看到,实现了跨线程的内存可见性。protected volatile int state;
:
AQS使用一个FIFO(先进先出)的双端队列来存储等待获取资源的线程。这里的节点并非直接存储线程对象,而是封装为
Node
类的对象,每个Node代表一个等待线程,并通过
prev
和
next
指针形成链表结构。头尾指针
head
和
tail
分别指向队列的首尾结点,便于进行快速插入和移除操作。static final class Node {
volatile int waitStatus;
volatile Node prev;
volatile Node next;
volatile Thread thread;
// 其他成员方法及属性...
}
:
每个Node节点都有一个
waitStatus
字段,它是一个int类型的volatile变量,用以标识当前节点所对应的线程等待状态。例如,
CANCELLED
表示线程已经被取消,
SIGNAL
表示后继节点的线程需要被唤醒,
CONDITION
则表示线程在条件队列中等待某个条件满足,还有如
PROPAGATE
这样的状态值用于共享模式下的资源传播。
:
当线程尝试获取资源失败时,会创建一个Node节点并将当前线程包装进去,然后利用CAS算法将其安全地加入到等待队列的尾部。而在释放资源时,AQS会根据资源管理策略从队列中选择合适的节点并唤醒对应线程。
:
AQS内建了对独占模式和共享模式的支持,这两种模式的区别在于:独占模式下同一时刻只能有一个线程获取资源,典型的如ReentrantLock;而共享模式允许多个线程同时获取资源,如Semaphore和CountDownLatch。在Node节点的设计上,通过
SHARED
和
EXCLUSIVE
静态常量区分不同模式的节点。
tryAcquire(int)
、
tryRelease(int)
等方法供子类覆盖以完成特定的资源控制逻辑,但具体的线程入队与出队、状态更新以及阻塞与唤醒等底层细节都是由AQS本身精心设计并实现的。这种机制使得基于AQS构建的同步工具能够有效地处理并发场景中的竞争问题,保证了线程间的安全协同执行。遗憾的是,由于篇幅限制,在此处无法提供完整的代码示例来展示AQS如何将线程包装成Node节点并维护其在线程等待队列中的位置变化。
资源共享模式
:
在独占模式下,同一时间只能有一个线程获取并持有资源,典型的例子就是ReentrantLock。当一个线程成功获取锁之后,其他试图获取锁的线程将被阻塞,直到持有锁的线程释放资源。通过AQS中的
tryAcquire(int)
方法实现对资源的尝试获取,以及
tryRelease(int)
方法来释放资源。例如:import java.util.concurrent.locks.ReentrantLock;
public class ExclusiveModeExample {
private final ReentrantLock lock = new ReentrantLock();
public void criticalSection() {
lock.lock(); // 尝试以独占模式获取资源(即获取锁)
try {
// 在这里执行临界区代码
} finally {
lock.unlock(); // 释放资源(即释放锁)
}
}
public static void main(String[] args) {
ExclusiveModeExample example = new ExclusiveModeExample();
Thread t1 = new Thread(example::criticalSection, "Thread-1");
Thread t2 = new Thread(example::criticalSection, "Thread-2");
t1.start();
t2.start();
}
}
:
而在共享模式下,多个线程可以同时获取资源,但通常会限制可同时访问资源的线程数量。Semaphore和CountDownLatch就是采用共享模式的例子。例如,在Semaphore中,可以通过参数指定允许多少个线程同时访问某个资源:import java.util.concurrent.Semaphore;
public class SharedModeExample {
private final Semaphore semaphore = new Semaphore(3); // 只允许最多3个线程同时访问资源
public void accessResource() {
try {
semaphore.acquire(); // 获取许可,如果当前可用许可数小于1,则线程会被阻塞
// 在这里执行需要保护的共享资源操作
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
semaphore.release(); // 释放许可,使其他等待的线程有机会继续访问
}
}
public static void main(String[] args) {
SharedModeExample example = new SharedModeExample();
for (int i = 0; i < 5; i++) {
Thread t = new Thread(example::accessResource, "Thread-" + (i + 1));
t.start();
}
}
}
accessResource
方法中的共享资源操作。超过三个线程则需等待其他线程释放许可后才能继续执行。
AQS关键方法解析
和
tryRelease(int arg)
:
这两个方法分别对应资源的独占式获取和释放操作。在ReentrantLock等基于AQS构建的独占锁中,子类需要重写这两个方法来定义资源是否可以被当前线程获取或释放的条件。例如,在ReentrantLock中,tryAcquire会检查当前线程是否已经持有锁以及锁的状态是否允许重新获取;tryRelease则负责递减锁的计数并根据结果决定是否唤醒等待队列中的线程。
和
tryReleaseShared(int arg)
:
对于共享模式下的资源控制,AQS提供了这两个方法。在Semaphore、CountDownLatch等共享资源管理器中,tryAcquireShared将尝试获取指定数量的资源,并返回一个表示成功与否及剩余资源量的整数值;而tryReleaseShared则是释放资源,同样根据资源总量的变化判断是否有等待的线程可以被唤醒。
和
release(int arg)
:
这是AQS对外暴露的主要接口,用于资源的获取和释放。acquire首先调用tryAcquire试图直接获取资源,若失败则通过addWaiter方法将当前线程包装成Node节点加入到等待队列尾部,并进一步调用acquireQueued进入自旋循环直至成功获取资源或被中断。acquireQueued内部包含parkAndCheckInterrupt方法,使用LockSupport.park挂起当前线程,直到其他线程释放资源后通过unpark唤醒它。public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
和
acquireSharedInterruptibly(int arg)
:
这两个方法扩展了acquire和acquireShared的功能,使其支持可中断的资源请求。如果在等待过程中线程被中断,将会抛出InterruptedException,而非一直阻塞。
:
这个方法仅在使用条件变量时有用,用于确定当前线程是否独占资源。在ReentrantLock的Condition实现中,该方法用于检测当前线程是否持有锁,以便决定能否执行signal/signalAll等操作。
AQS
资源释放
资源释放的主要入口是
release(int arg)
方法,它接受一个参数arg,表示要释放的资源数量。此方法首先调用子类实现的
tryRelease(int arg)
方法尝试释放资源。如果该方法返回true,说明资源成功释放,此时AQS会进一步检查当前头节点的状态,并决定是否唤醒下一个等待的线程。public final boolean release(int arg) {
if (tryRelease(arg)) { // 尝试释放资源
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h); // 唤醒等待队列中的下一个线程
return true;
}
return false;
}
在资源成功释放后,
unparkSuccessor(Node node)
方法会被调用来唤醒等待队列中合适的下一个线程。这个方法首先检查头结点的waitStatus状态,如果大于等于0,则遍历队列以找到首个可用的未取消结点,并使用LockSupport.unpark唤醒对应的线程。private void unparkSuccessor(Node node) {
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);
}
对于支持可中断的同步器如ReentrantLock,其释放资源的过程还会考虑线程中断的情况。当一个线程在等待过程中被中断时,它的等待状态将被正确处理,并可能抛出InterruptedException异常,从而允许上层代码进行恰当的响应。public class ReentrantLockExample {
private final ReentrantLock lock = new ReentrantLock();
public void criticalSection() {
lock.lock();
try {
// 执行临界区代码
} finally {
lock.unlock(); // 释放锁,可能唤醒等待队列中的线程
}
}
}
总结
state
是资源状态的核心表示,通过
tryAcquire(int)
、
tryRelease(int)
等protected方法,子类可以灵活定义资源获取和释放的具体逻辑。同时,AQS利用FIFO双端队列和Node节点结构来维护等待获取资源的线程队列,确保了线程间的公平性和互斥性。
markdown.com.cn
排版