《最新出炉》系列初窥篇-Python+Playwright自动化测试-39-highlight() 方法之追踪定位
1.简介
在之前的文章中宏哥讲解和分享了,为了看清自动化测试的步骤,通过JavaScript添加高亮颜色,就可以清楚的看到执行步骤了。在学习和实践Playwright的过程中,偶然发现了使用Playwright中的highlight()方法也突出显示Web元素。与之前的方法有异曲同工之妙。而且很简单。highlight()方法可以突出显示Web元素,方便调试和可视化操作。
2.测试场景
我们在日常工作中进行自动化测试,有时会遇到一个定位表达式,会同时定位到多个元素的可能,并且,有的元素是不可见的,这样一来,不仅会导致我们的测试用例执行失败,而且在查找问题时困难,尤其是隐藏的元素。那么我们如何在调试定位的时候就让我们定位到的全部元素都比较直观的展示在我们眼前呢?selenium需要我们逐一去查看,而playwright就直接提供了一个高亮的方法来突出展示web页面上的元素。
3.高亮显示定位到的元素
在我们调试元素定位的时候,不知道页面上有多少个此类元素,不清楚页面上这个元素具体显示在什么位置,这时候就可以使用 locator.highlight()。语法如下:
locator.highlight()
4.highlight实战
4.1highlight高亮单个元素
我们以度娘首页为例:高亮百度的搜索框(搜索框的元素id为kw)。
4.1.1代码设计

4.1.2参考代码
# coding=utf-8
Llama3-8B到底能不能打?实测对比
前几天Meta开源发布了新的Llama大语言模型:Llama-3系列,本次一共发布了两个版本:Llama-3-8B和Llama-3-70B,根据Meta发布的测评报告,Llama-3-8B的性能吊打之前的Llama-2-70B,也就是说80亿参数的模型干掉了700亿参数的模型,这个还真挺让人震惊的。

Llama-3-8B真的有这么强吗?
鉴于8B的模型可以在24G显存下流畅运行,成本不高,我就在AutoDL上实际测试了一下。
测试方案
使用的是我之前在AutoDL上发布的一个大语言模型WebUI镜像:
yinghuoai-text-generation-webui
(这个WebUI可以对大语言模型进行推理和微调),显卡选择的是 4090D 24G显存版本,使用三个问题分别测试了 Llama-3-8B-Instruct(英文问答)、Llama-3-8B-Instruct(中文问答)、llama3-chinese-chat、Qwen1.5-7B-Chat。其中llama3-chinese-chat是网友基于Llama-3-8B-Instruct训练的中文对话模型,项目地址:
https://github.com/CrazyBoyM/llama3-Chinese-chat
三个问题分别是:
- 小明的妻子生了一对双胞胎。以下哪个推论是正确的?
- A.小明家里一共有三个孩子
- B.小明家里一共有两个孩子。
- C.小明家里既有男孩子也有女孩子
- D.无法确定小明家里孩子的具体情况
- 有若干只鸡兔同在一个笼子里,从上面数,有35个头,从下面数,有94只脚。问笼中各有多少只鸡和兔?
- 请使用C#帮我写一个猜数字的游戏。
这三个问题分别考察大语言模型的逻辑推理、数学计算和编码能力。当然这个考察方案不怎么严谨,但是也能发现一些问题。
因为Llama-3的中文训练语料很少,所有非英语的训练数据才占到5%,所以我这里对Llama-3-8B分别使用了中英文问答,避免因中文训练不足导致测试结果偏差。
测试结果
鸡兔同笼问题
Llama-3-8B-Instruct(中文问答)
首先模型没有搞清楚鸡和兔的脚的数量是不同的,其次模型解方程的能力也不怎么行,总是算不对。
另外还是不是飙几句英语,看来中文训练的确实不太行。

Llama-3-8B-Instruct(英文问答)
搞清楚了不同动物脚的数量问题,但是还是不会计算,有时候方程能列正确,但是测试多次还是不会解方程组。

llama3-chinese-chat
中文无障碍,数学公式也列对了,但是答案是错的,没有给出解答过程。实测结果稳定性也比较差,每次总会给出不一样的解答方式。

Qwen1.5-7B-Chat
中文无障碍,答案正确,解答过程也基本完整。

小明家孩子的情况
Llama-3-8B-Instruct(中文问答)
答案不正确,解释的也不全面,没有说明其它答案为什么不正确。

Llama-3-8B-Instruct(英文问答)
答案正确,但是分析的逻辑有缺陷,没有完全说明白,只谈到性别问题,数字逻辑好像有点绕不清。

llama3-chinese-chat
答案错误,逻辑是混乱的,前言不搭后语,没有逻辑性。

Qwen1.5-7B-Chat
答案是正确的,但是逻辑不太通顺,说着性别,就跳到数量上去了。

猜数字游戏编程
Llama-3-8B-Instruct(中文问答)
代码完整,没有明显问题,但是还是会冒英文。

Llama-3-8B-Instruct(英文问答)
代码完整,没有明显问题。

llama3-chinese-chat
代码正确,但是不够完整,还需要更多提示。

Qwen1.5-7B-Chat
代码完整,没有明显问题。

测试结论
根据上边的测试结果,有一些结论是比较明确的。
Llama-3-8B的中文能力确实不太行,最明显的是时不时会冒一些英文,更重要的是使用中文时输出的内容偏简单化,逻辑上不那么严谨。
网友训练的 llama3-chinese-chat 问题比较多,可能是训练数据不足,或者训练参数上不够优秀,回答问题过于简略,逻辑性不够,稳定性也不太行,经常输出各种不一样的答案。建议只是玩玩,可以学习下它的训练方法。
Llama-3-8B的逻辑分析和数学能力不太行?至少在回答上边的鸡兔同笼问题和小明家孩子的情况上表现不佳,这是什么原因呢?训练语料的问题?但是我使用Llama-3-70B时,它可以正确且圆满的回答这两个问题,这就是权重参数不够的问题了,8B参数的能力还是差点。
Llama-3-8B的英文能力总体感觉还可以,但实测也没有那么惊艳,总有一种缺少临门一脚的感觉,有点瑕疵。说它媲美或者超越百亿参数的模型,这个是存在一些疑虑的。
Qwen1.5-7B-Chat在这几个问题的表现上还不错,不过很可能是这几个问题都学的很熟练了,特别是鸡兔同笼问题,大语言模型刚刚火爆的时候在国内常常被拿来做比较使用。目前还没有完整的Llama-3和Qwen1.5的评测对比数据,Llama-3公开的基准测试很多使用了few-shot,也就是评估时先给出几个问答示例,然后再看模型在类似问题上的表现,关注的是学习能力。根据HuggingFace上公开的数据,仅可以对比模型在MMLU(英文综合能力)和HumanEval(编程)上的的表现,比较突出的是编程能力,如下面两张图所示:


企业或者个人要在业务中真正使用,感觉还得是百亿模型,准确性和稳定性都会更好,百亿之下目前还不太行,经常理解或者输出不到位,目前感觉70B参数的最好。
对于Llama-3-8B,如果你使用英文开展业务,又不想太高的成本,不妨试试,但是需要做更多增强确定性的工作,比如优化提示词、做些微调之类的,至于中文能力还得等国内的厂商们再努力一把,目前还不太行。
Llama-3的在线体验地址请移步这里:
性能直逼GPT4,Llama3的三种在线体验方式。
园子周边第3季-博客园T恤:设计初稿第3版预览
在
鼠标垫
之后,T恤是园子周边的重头戏,而设计是重头戏中的难题,不仅众口难调,而且要求更高,不像鼠标垫放在桌上,这可是要穿在身上。
虽然设计挑战高,但我们没有被吓倒,甚至痴心妄想设计出独到,让园子的T恤有不一样的味道,于是借鉴鼠标垫的一点骄傲,继续让星星成为主角。
在前2版的设计尝试之后(
第1版
,
第2版
),参考大家的反馈,我们进行了第3版设计尝试,今天发出来给大家预览。
另外,我们正在寻找高品质的T恤厂家,不管设计是否符合大家的品味,质量上我们一定要做到尽可能地好,如果您有认识的优秀厂家,欢迎加
企业微信
向我们推荐。
博客园T恤第3版设计款式1

博客园T恤第3版设计款式2

博客园T恤第3版设计款式3

C#S7.NET实现西门子PLCDB块数据采集的完整步骤
前言
本文介绍了如何使用S7.NET库实现对西门子PLC DB块数据的读写,记录了使用计算机仿真,模拟PLC,自至完成测试的详细流程,并重点介绍了在这个过程中的易错点,供参考。
用到的软件:
1.Windows环境下链路层网络访问的行业标准工具(WinPcap_4_1_3.exe)下载链接:
https://www.winpcap.org/install/bin/WinPcap_4_1_3.exe
https://support.industry.siemens.com/cs/attachments/109772889/SIMATIC_PLCSIM_Advanced_V3.exe
提取码:c8ht
下载完后需要激活,可自行百度
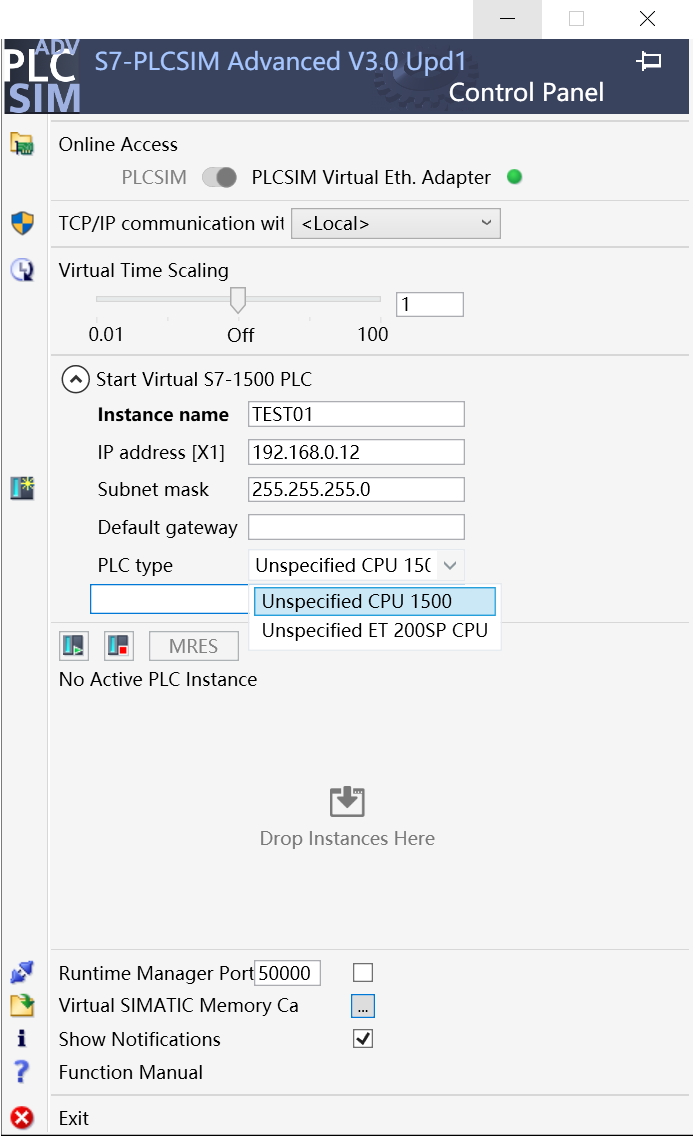
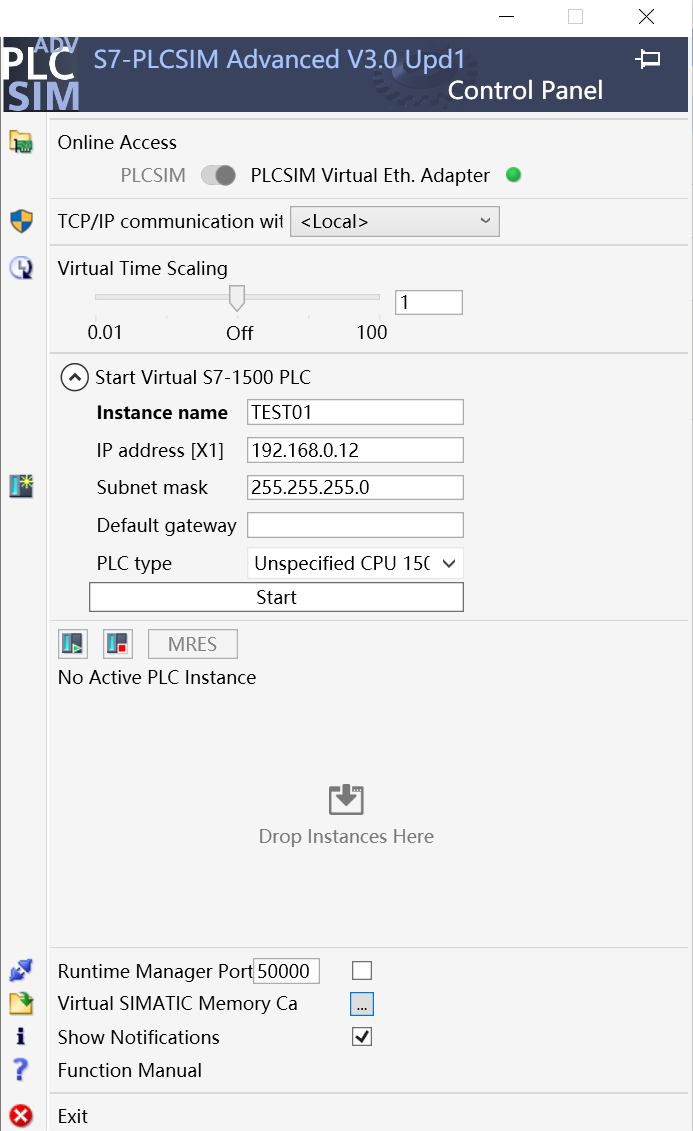
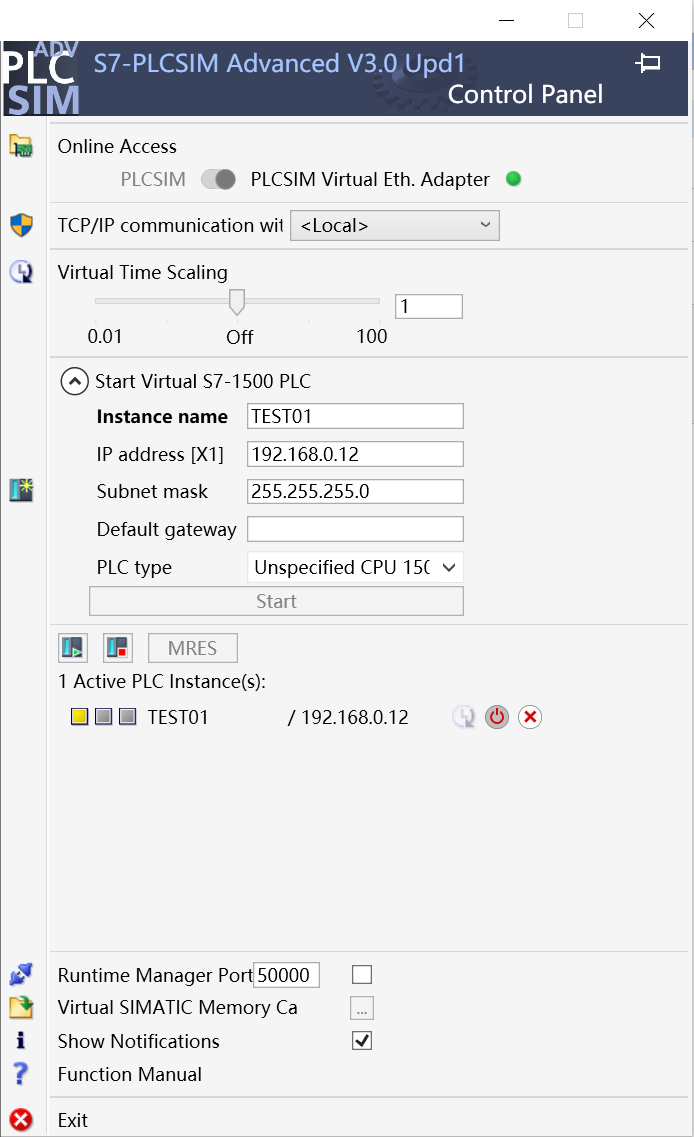
(5)模拟PLC正常启动,Active PLC中会显示PLC状态,此时为黄灯长亮(因为没有打开博图软件初始化PLC,初始化之后会变成绿灯长亮),至此PLCSIM Advanced配置完成;
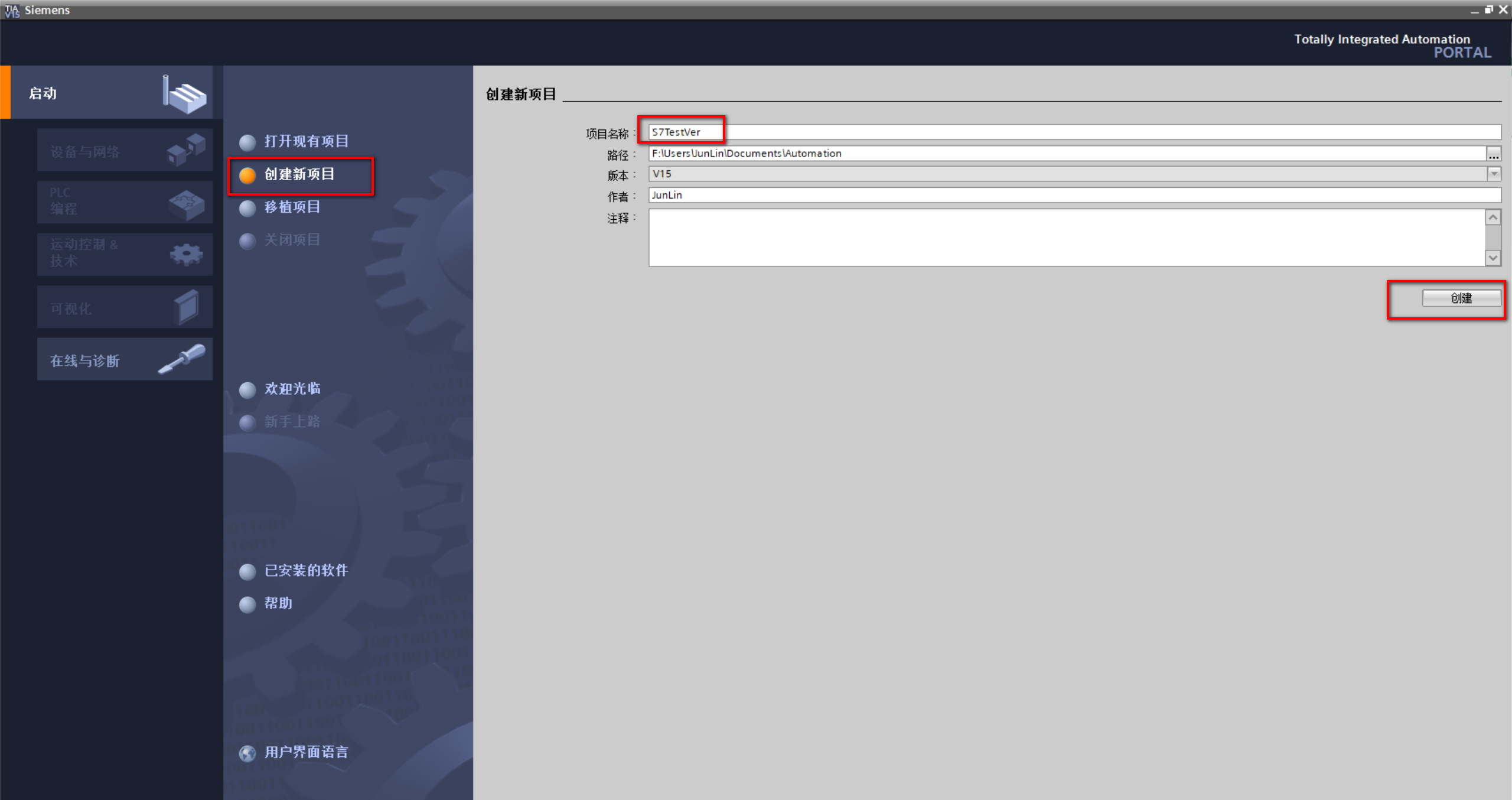
2.TIA Portal V15软件的配置流程:
(1)创建新项目
(2)添加新设备(S7-1500的CPU均可)
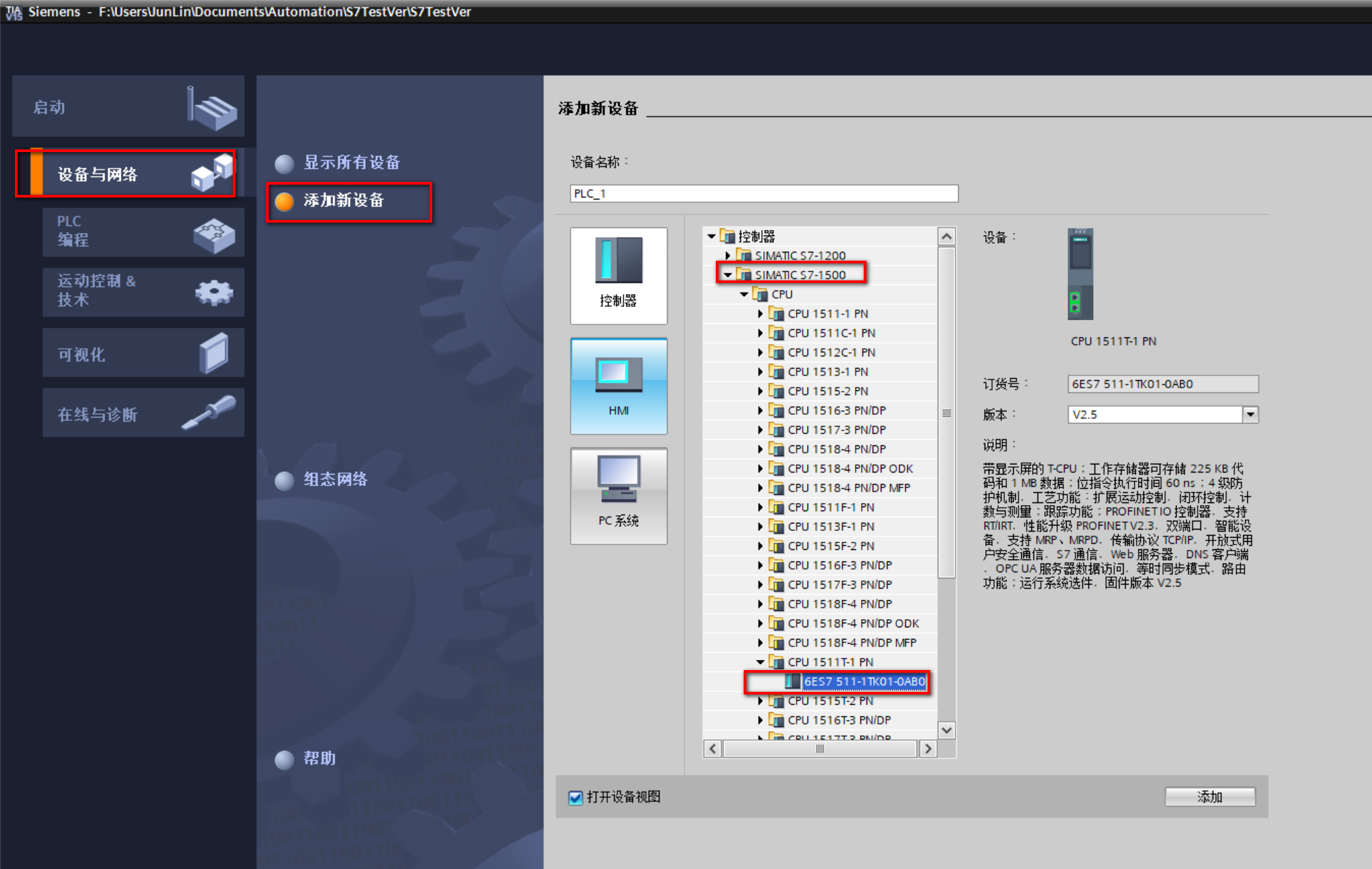
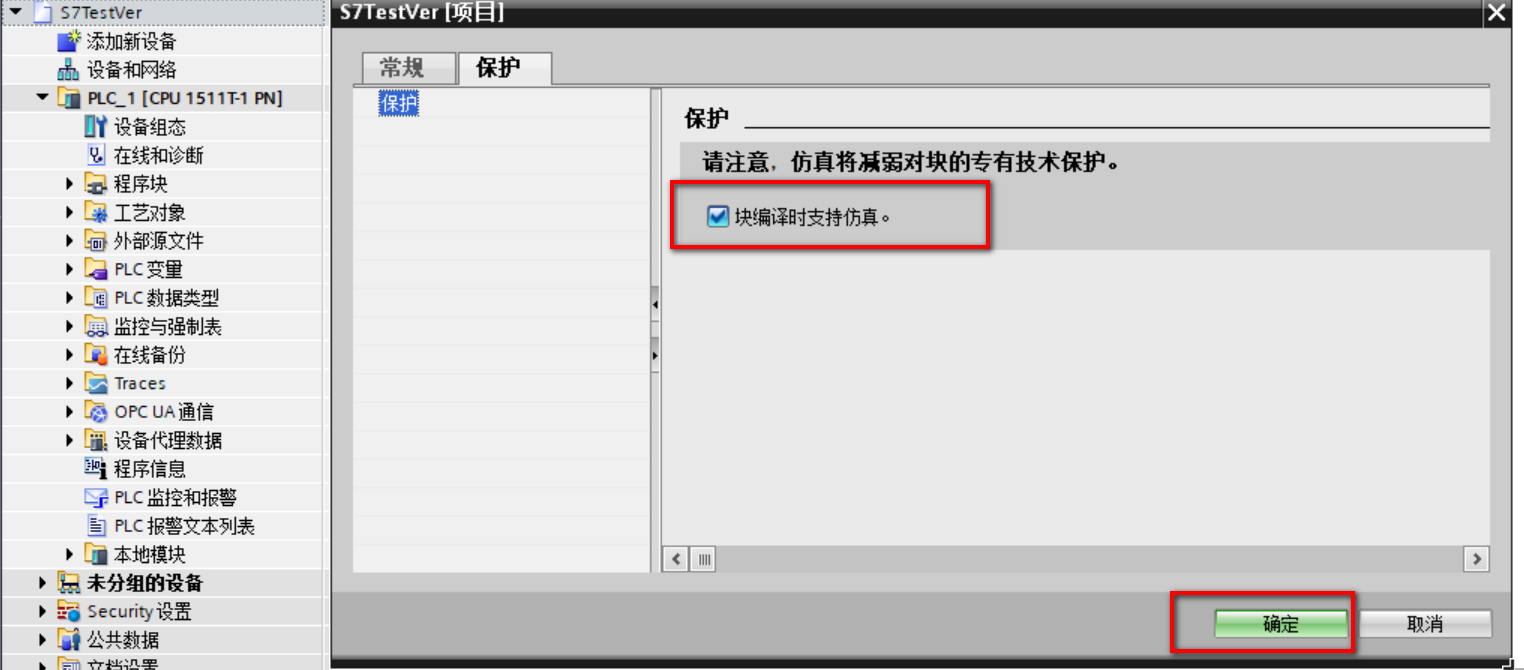
(3)右键项目名称(S7TestVer)进入属性窗口,在保护中勾选“块编译时支持仿真”;
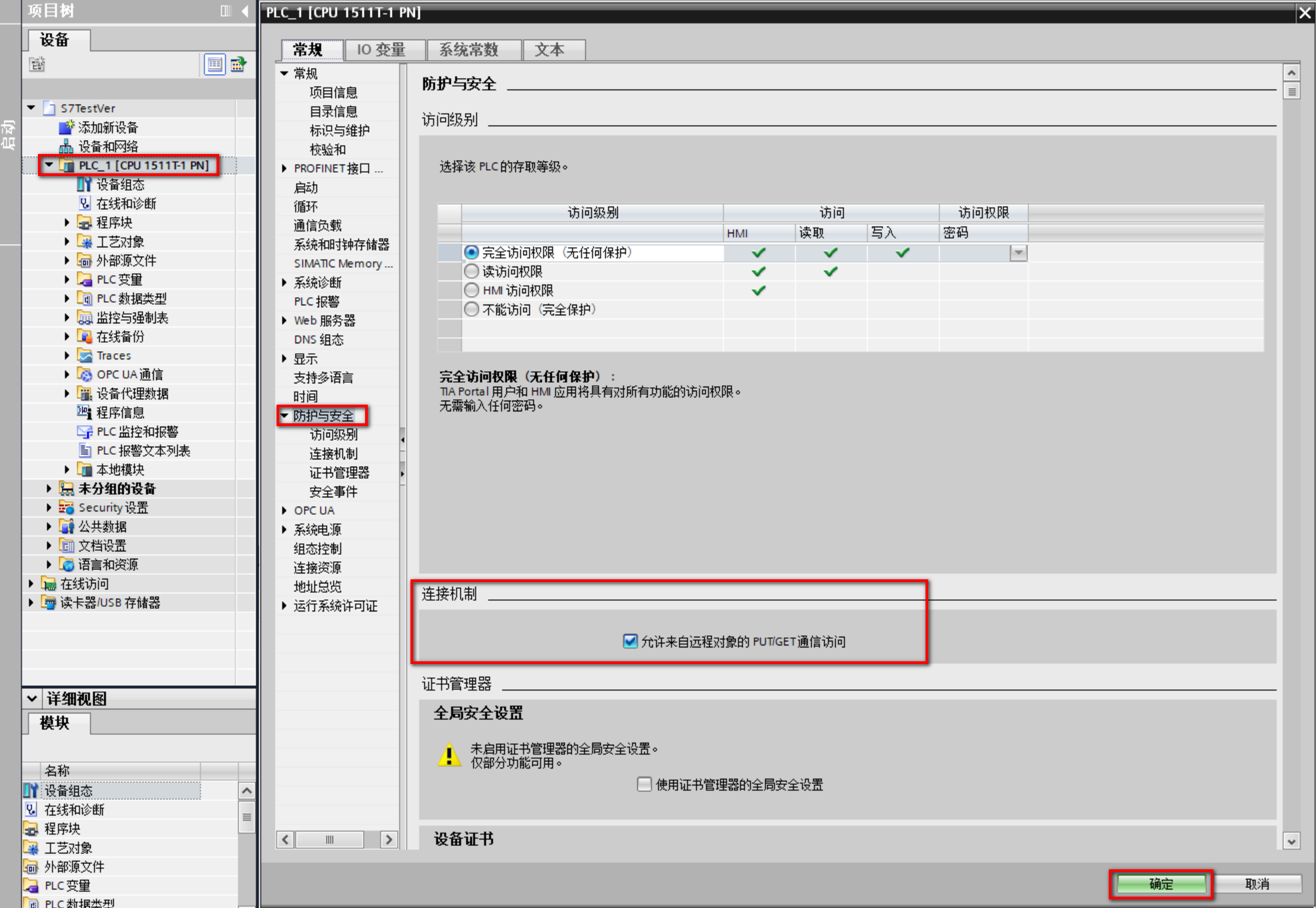
(4)右键设备名称(PLC_1)进入属性窗口,在 防护与安全 -- 连接机制 中勾选“允许来自远程对象的PUT/GET通信访问”,同时需要检查访问级别,选择该PLC的存取等级;
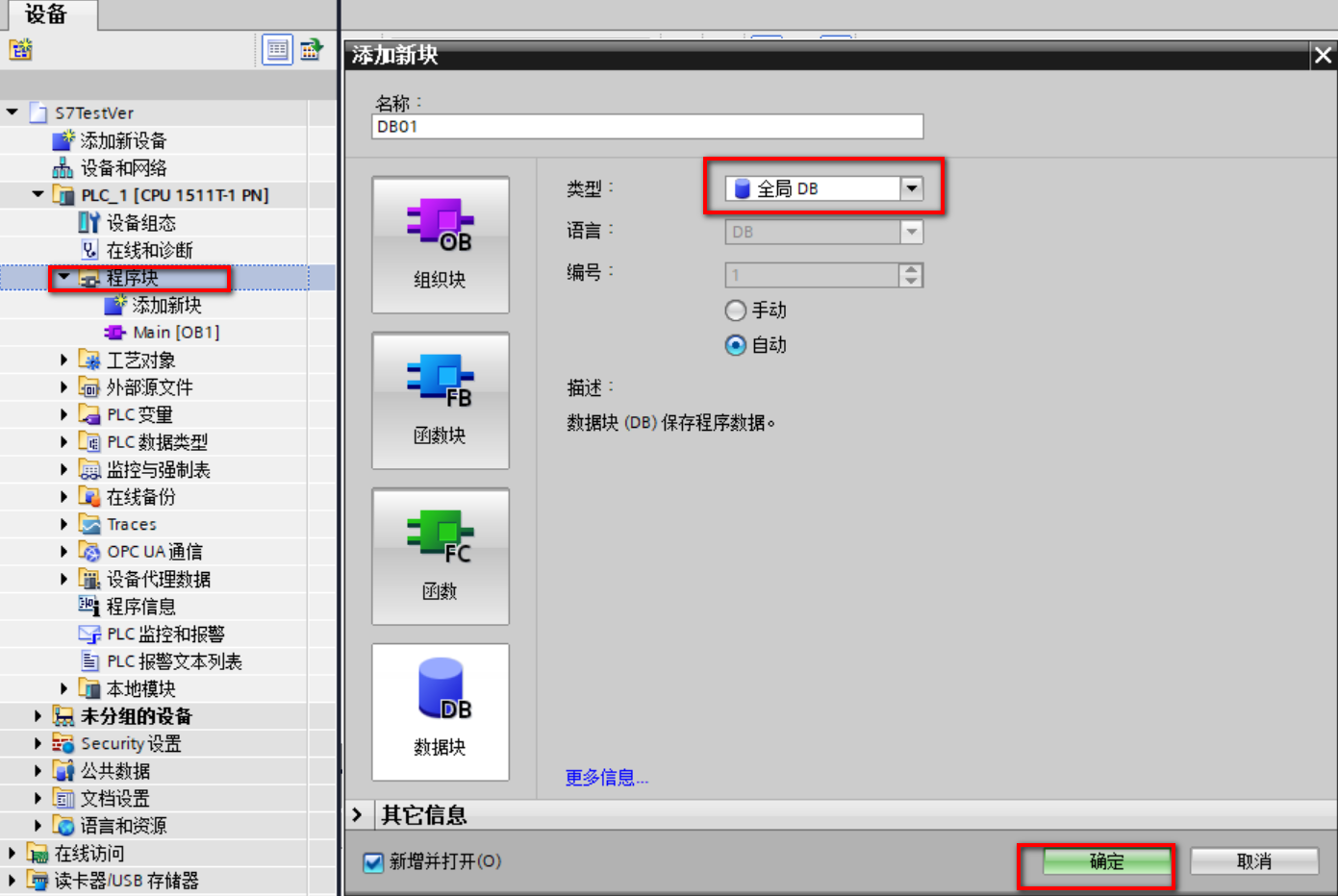
(5)右键程序块进入添加新块窗口,选择数据块(DB块)确认命名后点击确定;
(5)右键BD01块进入属性窗口,选择属性,取消勾选“优化的块访问”;
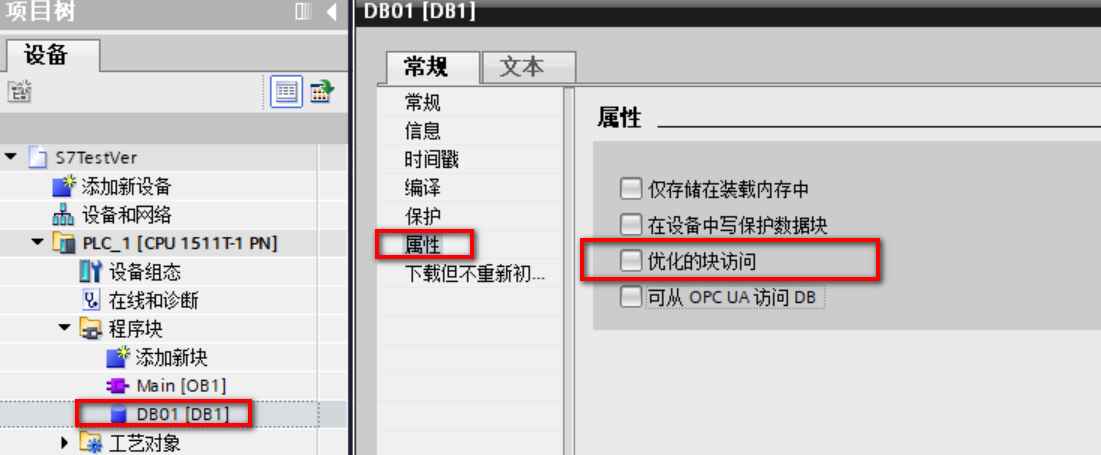
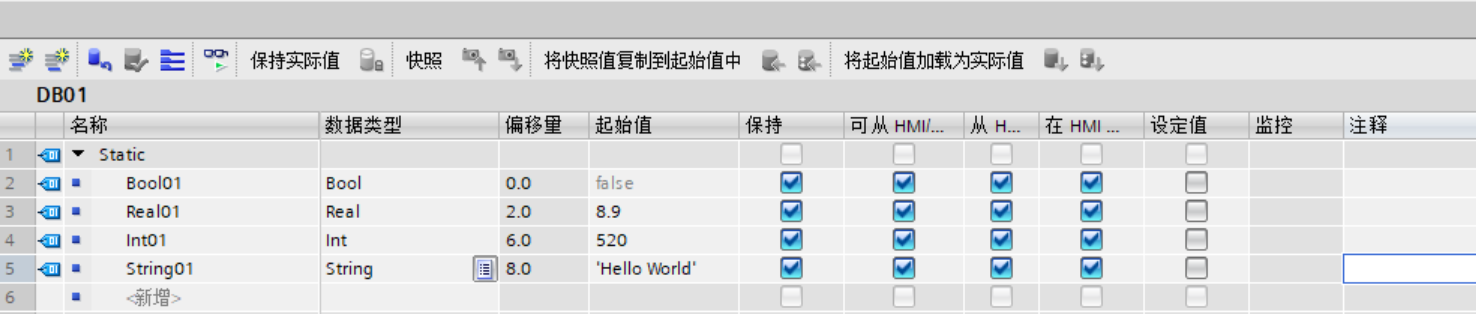
(6)双击DB01块,添加内容,用于后续测试;
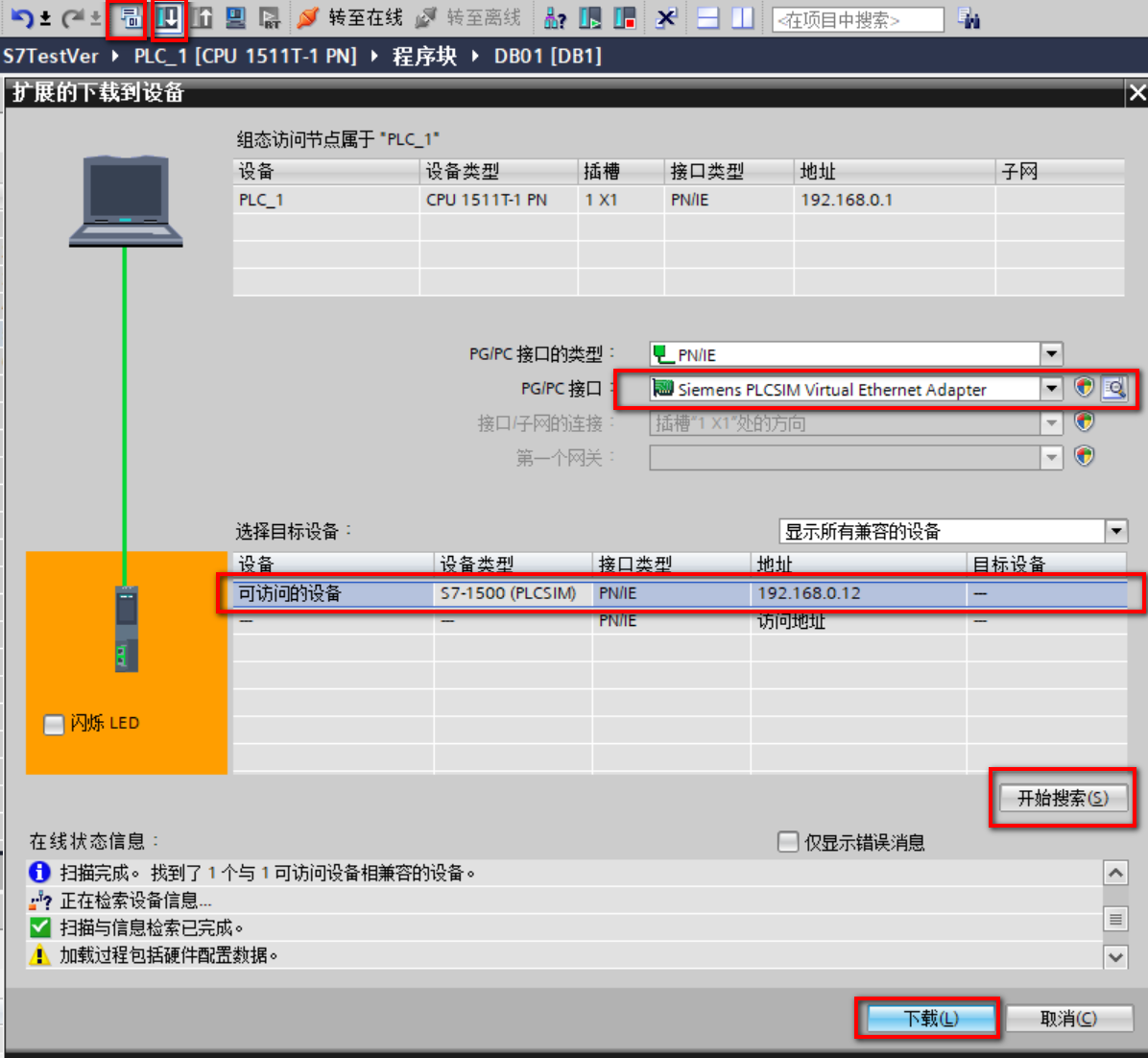
(7)编译并下载参数到模拟PLC,下载时会提示先搜索PLC,完成后下载参数即可;
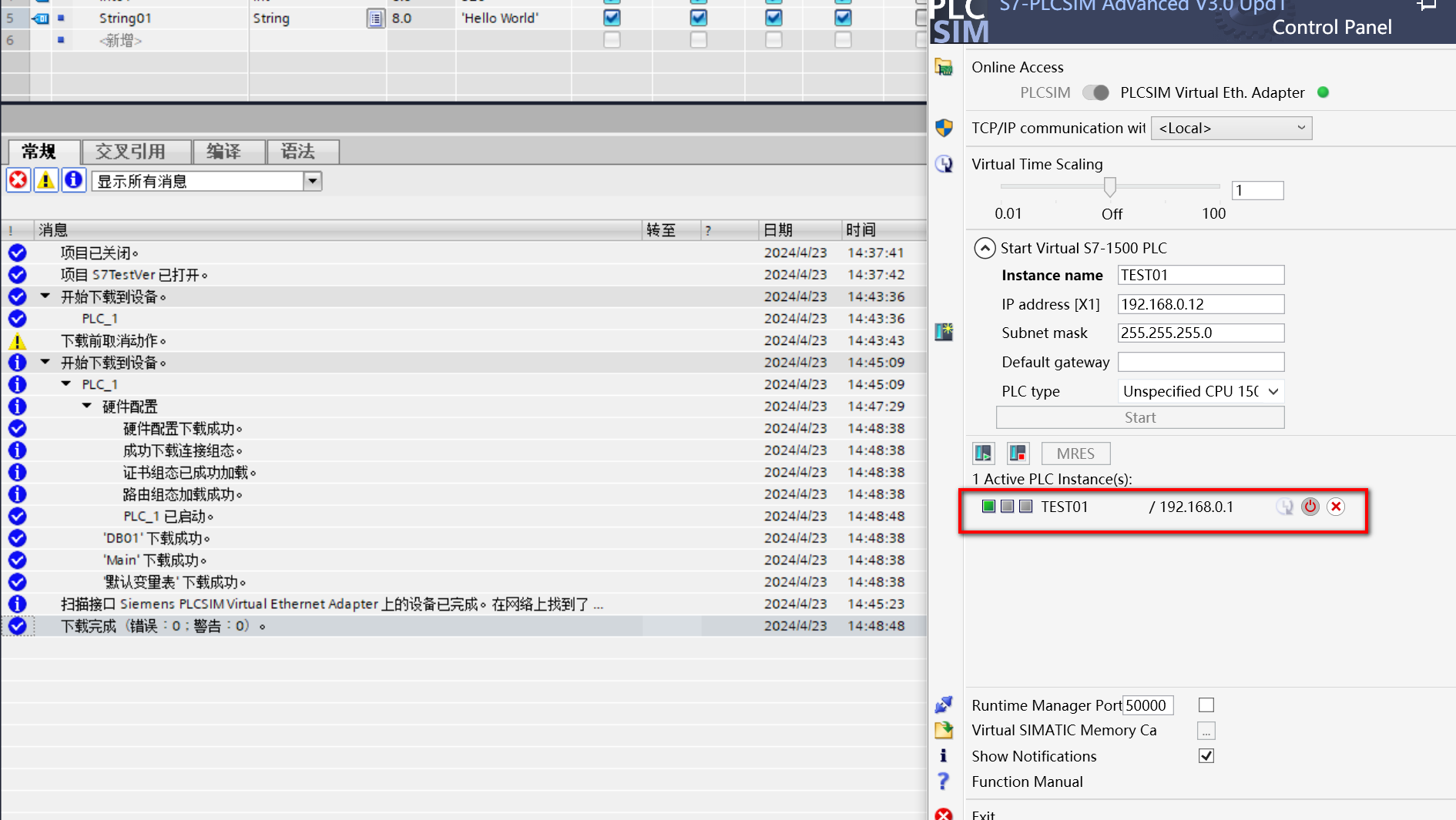
(8)下载完成后,可以看到Active PLC中显示的PLC状态为绿灯,至此PLC配置完成;
3.C#上位机的程序测试:
1 Plc S71500 = new Plc(CpuType.S71500,"192.168.0.1",0,1);2 publicForm1()3 {4 InitializeComponent();5 }6 7 private void btn_Comm_Click(objectsender, EventArgs e)8 {9 if(S71500.IsConnected)10 {11 btn_Comm.BackColor =Color.Gray;12 S71500.Close();13 btn_Comm.Text = "未建立链接";14 }15 else 16 {17 S71500.Open();18 btn_Comm.BackColor =Color.Green;19 btn_Comm.Text = "已连接";20 }21 }22 23 private void btn_Read_Click(objectsender, EventArgs e)24 {25 if ((bool)S71500.Read("DB1.DBX0.0"))26 {27 txb_Bool.Text = "1";28 }29 else 30 {31 txb_Bool.Text = "0";32 }33 }34 35 private void btn_Write_Click(objectsender, EventArgs e)36 {37 if (txb_Bool.Text == "1")38 {39 S71500.Write("DB1.DBX0.0", 1);40 }41 else 42 {43 S71500.Write("DB1.DBX0.0", 0);44 }45 }

分类算法(Classification Algorithm)需求记录
[toc]
比如说,在WEB扫描器场景中。一个扫描器在扫描过程中,它可以自动识别接口类型并采用相应分类规则进行漏洞检测的算法,这种通常属于一种称为"智能扫描"(Intelligent Scanning)或"漏洞扫描引擎"的技术。
这些算法利用机器学习、深度学习和模式识别等技术,通过分析网络流量、响应内容、请求参数等信息,来自动识别接口类型,并据此去选择相应的漏洞检测规则。
这些算法通常包括以下步骤:
数据收集
:收集目标系统的网络流量、响应数据、请求参数等信息。特征提取
:从收集到的数据中提取特征,例如请求方法、URL结构、响应头信息等。接口分类
:基于提取到的特征,将接口进行分类,例如HTTP接口、RESTful接口、SOAP接口等。规则匹配
:针对每种接口类型,使用相应的漏洞检测规则集进行匹配,以判断接口是否存在漏洞。漏洞报告
:生成漏洞报告,指出发现的漏洞类型、严重程度以及建议的修复措施。
这种智能扫描技术能够提高漏洞扫描的效率和准确性,使得扫描器能够更快速地识别潜在的安全风险,并帮助安全团队及时进行漏洞修复。
问题 Question:
如何能自动识别一个接口是什么类型?然后能识别他属于什么分类,采用该分类里的规则去发包判断这个接口是否有漏洞?
智能扫描技术通常使用多种方法和算法来识别接口类型,以下是其中一些可能使用的技术和算法:
正则表达式匹配
:通过预先定义的正则表达式模式,对请求的URL或响应内容进行匹配,以识别特定类型的接口。特征提取和分析
:对请求和响应数据进行特征提取,例如HTTP请求方法、URL路径结构、请求头信息、响应状态码等。然后使用这些特征来判断接口类型。机器学习
:使用机器学习算法,例如支持向量机(SVM)、决策树、随机森林等,通过对大量数据进行训练,识别出接口类型。这些算法可以根据历史数据的模式来学习,然后对新的数据进行分类。深度学习
:利用深度神经网络等深度学习技术,对请求和响应数据进行分析和学习,从而识别接口类型。深度学习模型能够学习到更复杂的特征和模式,从而提高识别准确性。模式识别
:利用模式识别技术,例如基于模式匹配的方法,来识别接口的类型。这种方法通过识别特定的模式或结构来判断接口类型。
以上这些方法通常会
结合使用
,以提高接口类型识别的准确性和可靠性。算法的选择取决于数据的特点、需求和可用资源等因素。
机器学习分类算法介绍
机器学习分类(Classification)是监督学习的一种重要任务,其目的是根据输入数据的特征,将其归类到事先定义好的类别或标签中。
在Web扫描器中应用机器学习分类算法,可以自动识别请求、响应数据属于哪种类型的接口或漏洞。
机器学习分类一般包括以下几个步骤:
数据收集和标注
收集大量真实的请求/响应数据,并由人工或其他方式对其进行标注,即确定每个数据属于哪一类接口或漏洞类型。特征工程
从原始数据中提取对于分类任务有意义的特征,如URL路径、参数名、请求头、响应正文等。设计好的特征对最终的分类性能至关重要。模型选择和训练
选择合适的分类算法,如决策树、逻辑回归、支持向量机、神经网络等。使用标注好的数据对模型进行训练,使其能从特征中学习不同类别的模式。模型评估
在保留的测试数据上评估模型的分类性能,根据准确率、召回率、F1分数等指标衡量模型的好坏。模型调优和上线
通过调整算法参数、特征等方式优化模型性能。当性能达标后,可将模型部署到线上系统,对新的未知数据进行自动分类。
常见的分类算法有:
- 朴素贝叶斯
- 逻辑回归
- 决策树
- 随机森林
- 支持向量机
- 神经网络等。
- ...
近年来,深度学习技术在分类任务上取得了很好效果。
Reference
一文读懂机器学习分类算法(附图文详解)
https://zhuanlan.zhihu.com/p/82114104