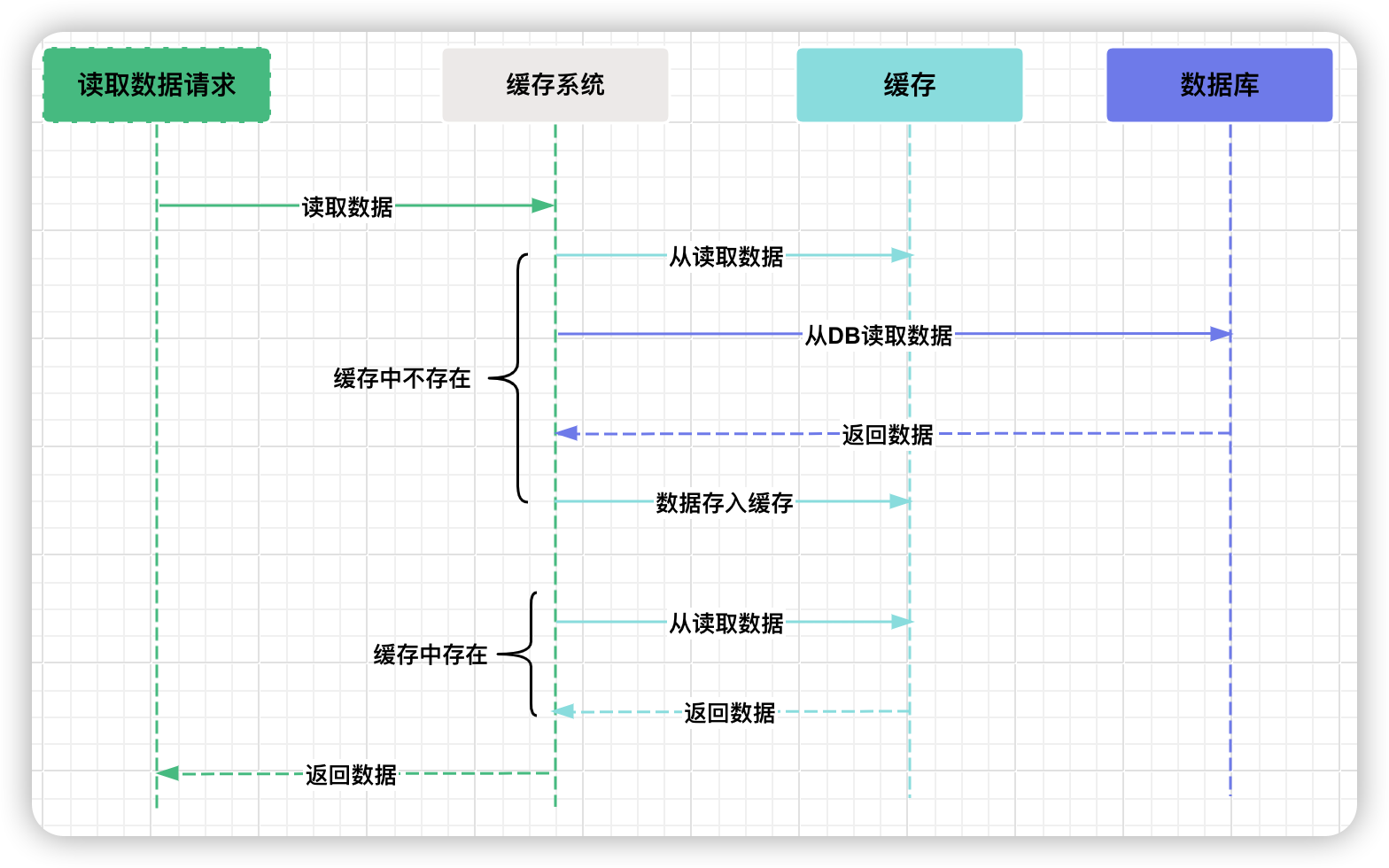
Python中两种网络编程方式:Socket和HTTP协议
本文分享自华为云社区《
Python网络编程实践从Socket到HTTP协议的探索与实现
》,作者:柠檬味拥抱。
在当今互联网时代,网络编程是程序员不可或缺的一项技能。Python作为一种高级编程语言,提供了丰富的网络编程库,使得开发者能够轻松地实现各种网络应用。本文将介绍Python中两种主要的网络编程方式:Socket编程和基于HTTP协议的网络编程,并通过实际案例来演示它们的应用。
1. Socket编程
Socket是实现网络通信的基础。通过Socket,程序可以在网络中传输数据,实现客户端与服务器之间的通信。Python提供了
socket
模块,使得Socket编程变得简单而直观。
下面是一个简单的Socket服务器和客户端的实现:
# 服务器端
import socket
# 创建socket对象
server_socket=socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 获取本地主机名
host=socket.gethostname()
port= 9999# 绑定端口
server_socket.bind((host, port))
# 设置最大连接数,超过后排队
server_socket.listen(5)whileTrue:
# 建立客户端连接
client_socket, addr=server_socket.accept()
print("连接地址: %s" %str(addr))
msg= '欢迎访问Socket服务器!' + "\r\n"client_socket.send(msg.encode('utf-8'))
client_socket.close()
# 客户端
import socket
# 创建socket对象
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 获取本地主机名
host = socket.gethostname()
port = 9999
# 连接服务,指定主机和端口
client_socket.connect((host, port))
# 接收服务端发送的数据
msg = client_socket.recv(1024)
print(msg.decode('utf-8'))
client_socket.close()运行以上代码,可以在本地搭建一个简单的Socket服务器,并通过客户端连接并接收消息。
2. HTTP协议的实践
HTTP(HyperText Transfer Protocol)是一种用于传输超媒体文档(例如HTML)的应用层协议。Python提供了多种库用于HTTP通信,其中最常用的是
requests
库。
以下是一个使用
requests
库发送HTTP GET请求的示例:
import requests
url= 'https://api.github.com'response= requests.get(url)
print("状态码:", response.status_code)
print("响应内容:", response.text)
通过
requests.get()
函数可以发送HTTP GET请求,并获取响应的状态码和内容。
3. 使用Socket进行简单的网络通信
Socket编程在Python中是一种基础的网络通信方式,它提供了一种在网络上发送和接收数据的方法,可用于构建各种类型的网络应用程序,包括即时通讯、文件传输等。
下面是一个简单的基于Socket的聊天程序,包括服务端和客户端:
# 服务器端
import socket
server_socket=socket.socket(socket.AF_INET, socket.SOCK_STREAM)
host=socket.gethostname()
port= 12345server_socket.bind((host, port))
server_socket.listen(1)
print("等待客户端连接...")
client_socket, client_address=server_socket.accept()
print("连接地址:", client_address)whileTrue:
data= client_socket.recv(1024).decode('utf-8')ifnot data:breakprint("客户端消息:", data)
message= input("服务器消息:")
client_socket.send(message.encode('utf-8'))
client_socket.close()
# 客户端
import socket
client_socket=socket.socket(socket.AF_INET, socket.SOCK_STREAM)
host=socket.gethostname()
port= 12345client_socket.connect((host, port))whileTrue:
message= input("客户端消息:")
client_socket.send(message.encode('utf-8'))
data= client_socket.recv(1024).decode('utf-8')
print("服务器消息:", data)
client_socket.close()
运行以上代码,可以实现一个简单的基于Socket的聊天程序。客户端和服务器端可以互相发送消息,实现简单的即时通讯功能。
4. 使用HTTP协议进行网络通信
HTTP协议是一种应用层协议,广泛用于传输超文本文档(如HTML)的数据传输。在Python中,使用HTTP协议进行网络通信通常通过
requests
库来实现,这个库提供了简单易用的接口,方便发送HTTP请求和处理响应。
下面是一个使用
requests
库发送HTTP POST请求的示例:
import requests
url= 'https://httpbin.org/post'data= {'key1': 'value1', 'key2': 'value2'}
response= requests.post(url, data=data)
print("状态码:", response.status_code)
print("响应内容:", response.text)
运行以上代码,可以向指定的URL发送一个HTTP POST请求,并获取服务器返回的响应。
5. 使用Socket进行多线程网络通信
在实际应用中,往往需要处理多个客户端的连接请求。为了实现高并发处理,可以使用多线程来处理每个客户端的连接。Python的
threading
模块提供了多线程支持,可以很方便地实现多线程网络通信。
以下是一个使用多线程处理Socket连接的示例:
# 服务器端
import socket
import threading
def handle_client(client_socket):whileTrue:
data= client_socket.recv(1024).decode('utf-8')ifnot data:breakprint("客户端消息:", data)
message= input("服务器消息:")
client_socket.send(message.encode('utf-8'))
client_socket.close()
server_socket=socket.socket(socket.AF_INET, socket.SOCK_STREAM)
host=socket.gethostname()
port= 12345server_socket.bind((host, port))
server_socket.listen(5)
print("等待客户端连接...")whileTrue:
client_socket, client_address=server_socket.accept()
print("连接地址:", client_address)
client_thread= threading.Thread(target=handle_client, args=(client_socket,))
client_thread.start()
# 客户端
import socket
client_socket=socket.socket(socket.AF_INET, socket.SOCK_STREAM)
host=socket.gethostname()
port= 12345client_socket.connect((host, port))whileTrue:
message= input("客户端消息:")
client_socket.send(message.encode('utf-8'))
data= client_socket.recv(1024).decode('utf-8')
print("服务器消息:", data)
client_socket.close()
通过在服务器端的主循环中创建新的线程来处理每个客户端的连接,可以实现同时处理多个客户端的请求,提高服务器的并发处理能力。
6. 使用HTTP协议进行网络通信
HTTP(HyperText Transfer Protocol)是一种用于传输超文本文档(如HTML)的应用层协议。在网络编程中,基于HTTP协议的通信方式更为常见,特别是在Web开发和API交互中。Python提供了多种库用于HTTP通信,其中最常用的是
requests
库。
以下是一个使用
requests
库发送HTTP GET请求的示例:
import requests
url= 'https://api.github.com'response= requests.get(url)
print("状态码:", response.status_code)
print("响应内容:", response.text)
通过
requests.get()
函数可以发送HTTP GET请求,并获取响应的状态码和内容。
requests
库还提供了丰富的参数和方法,用于处理各种HTTP请求和响应,如设置请求头、传递参数、处理Cookie等。
7. 使用Socket进行多线程网络通信
在实际应用中,往往需要处理多个客户端的连接请求。为了实现高并发处理,可以使用多线程来处理每个客户端的连接。Python的
threading
模块提供了多线程支持,可以很方便地实现多线程网络通信。
以下是一个使用多线程处理Socket连接的示例:
# 服务器端
import socket
import threading
def handle_client(client_socket):whileTrue:
data= client_socket.recv(1024).decode('utf-8')ifnot data:breakprint("客户端消息:", data)
message= input("服务器消息:")
client_socket.send(message.encode('utf-8'))
client_socket.close()
server_socket=socket.socket(socket.AF_INET, socket.SOCK_STREAM)
host=socket.gethostname()
port= 12345server_socket.bind((host, port))
server_socket.listen(5)
print("等待客户端连接...")whileTrue:
client_socket, client_address=server_socket.accept()
print("连接地址:", client_address)
client_thread= threading.Thread(target=handle_client, args=(client_socket,))
client_thread.start()
# 客户端
import socket
client_socket=socket.socket(socket.AF_INET, socket.SOCK_STREAM)
host=socket.gethostname()
port= 12345client_socket.connect((host, port))whileTrue:
message= input("客户端消息:")
client_socket.send(message.encode('utf-8'))
data= client_socket.recv(1024).decode('utf-8')
print("服务器消息:", data)
client_socket.close()
通过在服务器端的主循环中创建新的线程来处理每个客户端的连接,可以实现同时处理多个客户端的请求,提高服务器的并发处理能力。
8. 使用Socket进行多线程网络通信
在实际应用中,往往需要处理多个客户端的连接请求。为了实现高并发处理,可以使用多线程来处理每个客户端的连接。Python的
threading
模块提供了多线程支持,可以很方便地实现多线程网络通信。
以下是一个使用多线程处理Socket连接的示例:
# 服务器端
import socket
import threading
def handle_client(client_socket):whileTrue:
data= client_socket.recv(1024).decode('utf-8')ifnot data:breakprint("客户端消息:", data)
message= input("服务器消息:")
client_socket.send(message.encode('utf-8'))
client_socket.close()
server_socket=socket.socket(socket.AF_INET, socket.SOCK_STREAM)
host=socket.gethostname()
port= 12345server_socket.bind((host, port))
server_socket.listen(5)
print("等待客户端连接...")whileTrue:
client_socket, client_address=server_socket.accept()
print("连接地址:", client_address)
client_thread= threading.Thread(target=handle_client, args=(client_socket,))
client_thread.start()
# 客户端
import socket
client_socket=socket.socket(socket.AF_INET, socket.SOCK_STREAM)
host=socket.gethostname()
port= 12345client_socket.connect((host, port))whileTrue:
message= input("客户端消息:")
client_socket.send(message.encode('utf-8'))
data= client_socket.recv(1024).decode('utf-8')
print("服务器消息:", data)
client_socket.close()
通过在服务器端的主循环中创建新的线程来处理每个客户端的连接,可以实现同时处理多个客户端的请求,提高服务器的并发处理能力。
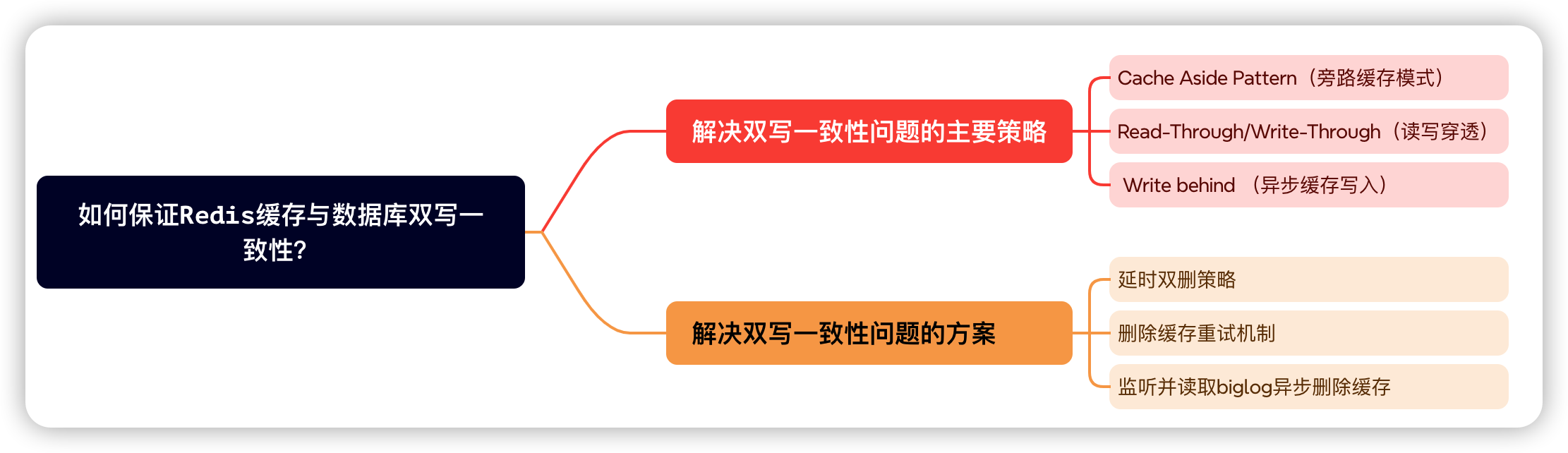
总结
本文深入介绍了Python中的网络编程,重点探讨了两种主要方式:Socket编程和基于HTTP协议的网络编程。首先,我们了解了Socket编程,它是一种底层的网络通信方式,可以实现自定义的通信协议,具有灵活性和高度控制性。我们通过示例演示了如何使用Socket编程在服务器端和客户端之间进行简单的通信,并介绍了如何使用多线程来处理多个客户端的连接请求,以提高服务器的并发处理能力。
其次,我们介绍了基于HTTP协议的网络编程,这是一种更高层次的抽象,适用于构建Web应用、访问API等场景。我们使用了
requests
库来发送HTTP请求,并获取服务器的响应,演示了如何发送GET和POST请求,并处理响应的状态码和内容。基于HTTP协议的网络编程更简单易用,适合于与现有的Web服务进行交互。
通过本文的学习,我们可以了解到Python提供了丰富的网络编程工具和库,使得开发者能够轻松实现各种网络应用。无论是底层的Socket编程还是基于HTTP协议的网络编程,都可以满足不同场景下的需求。掌握网络编程技术对于开发网络应用和系统非常重要,希望本文能够帮助读者更好地理解和应用Python中的网络编程技术,为其在项目开发中提供帮助和启发。