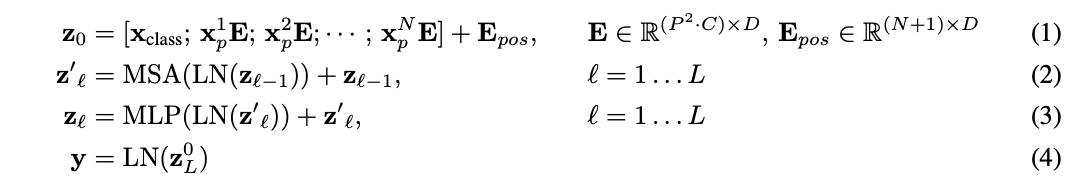大家好,我是呼噜噜,在上一篇文章
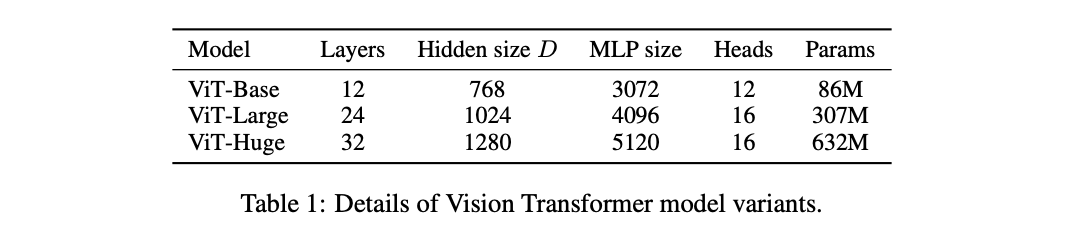
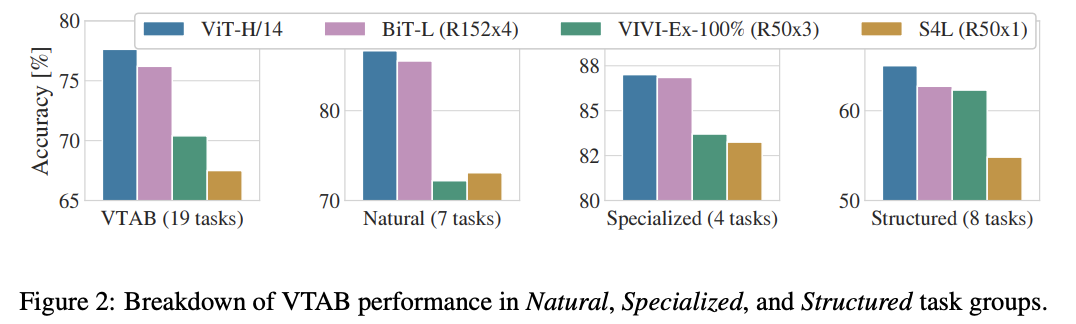
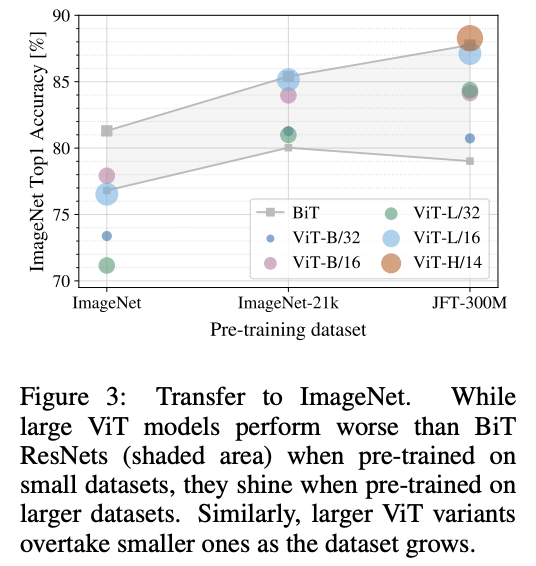
聊聊x86计算机启动发生的事?
我们了解了x86计算机启动过程,MBR、0x7c00是什么?其中当bios引导结束后,操作系统接过计算机的控制权后,发生了哪些事?本文将揭开迷雾的序章-
Bootsect.S
回顾计算机启动过程
我们先来回顾一下,上古时期计算机按下电源键的启动过程,这里以8086架构为例:

8086、80x86是什么意思?
有许多人不知道 经常遇到的8086、80x86是什么意思?我们简单科普一下:
- 8086是Intel公司推出的最早,也是最流行的面向个人电脑的CPU型号
- x86泛指一系列基于Intel 8086且向后兼容的中央处理器指令集架构,由于以“86”作为结尾,因此其架构被称为"x86"
- 80x86也就是在8086基础上的增强版,包括80286,80386,80486,其后面就是我们所熟悉的奔腾、酷睿、i5、i7等等
寄存器初始化CS:IP
相比于上一篇文章
聊聊x86计算机启动发生的事
,我们这里再讲细致点,当计算机一按下电源后,8086CPU就处于
实模式
的状态,此时会将CPU的寄存器初始化为
CS=0xFFFF;IP=0x0000
,也就是实际物理地址
0xFFFF0
(
CS左移4位+IP
)
CS : 代码段寄存器;IP : 指令指针寄存器。
CS:IP指向的内容 会被CPU当做计算机指令去执行
那么从地址
0xFFFF0
中取出来的指令是什么?我们知道当电路通电后,内存是一片空白的,内存断电后 数据是无法保存的,所以BIOS程序需要事先被刷入
只读存储器ROM
中。物理地址
0xFFFF0
就是指向这样一段BIOS ROM
CPU是如何和ROM相连的?
那么问题又来了,CPU是如何和ROM相连的?CPU 不仅和ROM相连,还和RAM(俗称内存),IO接口等设备相连,他们是通过
总线
相连。还好当时笔者将计算机组成原理好好复习了一遍,不然这部分真挺难理解的。

总线
是贯穿整个系统的是一组电子管道,是连接各个部件的信息传输线,是各个部件共享的传输介质,称作总线,它
携带信息字节并负责在各个计算机部件间传递
。
总线按系统总线传输信息内容的不同,又可以分为3 种:
数据总线、地址总线和控制总线
。我们这里用到的就是地址总线,把 0xFFFF0 作为 CPU 的地址总线信号传输出去,去这个地址总线对应的位置处找
由于计算机有多个设备,必然会存在多个设备
同时竞争总线控制权
的问题,这时候就需要
总线仲裁,
让某个设备优先获得总线控制权,获得了总线控制权的设备,才能开始传送数据。未获胜的设备只能等待获胜的设备处理完成后才能执行。
我们简单总结一下:当总线仲裁器仲裁通过后,CPU可以依靠地址总线寻址,找到对应设备ROM上地址
0xFFFF0
处的内容。
拓展可见:
什么是计算机中的高速公路-总线?
加载MBR到内存中
当BIOS自检完成,设置启动顺序后,利用 BIOS 的输入功能将启动磁盘的
启动扇区MBR
(也叫第一扇区,主引导记录)的内容原封不动地搬到内存的
0x7C00
地址处,并设置CPU寄存器
CS=0x07C0,IP=0x0000
。到这一步,计算机的控制权将交到操作系统手中!
为什么是0x7C00这个地址?如何得出?别再问了,本文不再解释了,具体看笔者的上一篇文章
聊聊x86计算机启动发生的事

对于Linux0.12来说,第一个程序
Bootsect.S
编译成二进制后,需要事先放到
主引导记录MBR
中,MBR大小就是一个扇区的大小512字节,如果这512字节的最后两个字节是
0x55AA
,表明这个设备可以用于启动。只有这样我们BIOS才能识别它,才能把bootsect.S加载到内存中。
如果不是0x55和0xAA,表明设备不能用于启动,控制权于是被转交给"启动顺序"中的下一个设备。如果到最后还是没找到符合条件的,直接报出一个无启动区的error。
下面我们看下操作系统编译后,存放在储存设备(硬盘)的模块分布:

先简单介绍一下,不必深究,后续文章会娓娓道来:
- bootsect.s的主要作用就是加载操作系统,把操作系统从硬盘中,加载到内存里去
- setup.s的主要作用:首先获得光标,内存,显卡,磁盘等硬件参数存放在内存空间中,方便后续程序使用;临时建立gdt、idt表,并且从实模式进入到了保护模式
- 在linux0.12源码,boot目录下还有一个head.s,在上图中被
归于system模块
,属于操作系统主体文件,主要是进行进入保护模式之后的初始化工作
- system模块:就是操作系统的主体,比如文件系统,IO,进程等模块。 Linux0.12 内核 system 模块大约占随后的 260 个扇区。
更多精彩文章在公众号「
小牛呼噜噜
」
bootsect.S具体干了什么?
bootsect的主要作用就是加载操作系统,把操作系统从硬盘中,加载到内存里去,我们下面结合bootsect.s的源码一起来看看bootsect.S具体干了什么?
呼噜噜这里整个过程先汇成了图,大家配合图去阅读下文,对照起来,更容易理解

设置段基址 & 内存分段机制
要想bootsect启动,需要让BIOS将bootsect.s 从硬盘的MBR中搬到 内存位置
0x7c00
处,大小512个字节。当bootsect被BIOS加载到内存后,计算机的控制权就到操作系统bootsect的手上了。
entry start ! 告知链接程序,程序入口是从start 标号开始执行的
start:
mov ax,#BOOTSEG !BOOTSEG=0x7c0 , 将 ds 段寄存器置为 0x7C0
mov ds,ax !再将 ax 段寄存器里的值复制到 ds 段寄存器里
mov ax,#INITSEG !SETUPSEG=0x9000,将 es 段寄存器置为 0x9000
mov es,ax !再将 ax 段寄存器里的值复制到 es 段寄存器里
mov cx,#256
sub si,si
sub di,di
rep
movw
jmpi go,INITSEG
我们可以看到CPU实际执行第一句的代码
mov ax,#BOOTSEG !BOOTSEG=0x7c0
,这是汇编写的,其实这里的
0x7c0
对应的就是我们上文的地址
0x7C00
0x7c0
是段地址,
0x7C00
是其实际的物理地址,
0x7c0
左移四位就是
0x7c00
,这就是
内存寻址-分段机制
那么大家一定会有疑问内存为什么分段?

计算机内存究竟是什么?其实它就像数组一样,咦有人不懂数组是什么,那么我们可以再头脑风暴一下,内存其实就像
纸带
一样,我们来看下上古时期的计算机:

穿孔纸带,图片来源于网络
纸带上有一个个孔,这样大家可能还看不明白,我们再来看一张图:

这些孔排列组合其实就是二进制数,纸带其实就是储存数据的介质,那么
内存
就是足够长的“纸带”
在现代计算机中,内存它使用的是
DRAM
芯片,也叫
动态随机存取存储器
,即只需给出地址,就能直接访问指定地址的数据,这一点特别像数组,所以许多材料都是用数组来画内存图
那么CPU访问内存明明可以直接通过地址访问内存,为什么还要分段?其实这又是一个历史因素导致的,让我们回到"分段"首次出现的时候:"分段"是从Intel 8086芯片开始的,8086又是你......

由于8086那个时代CPU、内存都很昂贵, CPU 和寄存器等宽度都是 16 位的,其可寻址2的16次方字节,也就是64kb,然而8086有20根地址线,可寻址的最大内存空间是1MB。CPU和寄存器的寻址能力远远不能满足使用,于是机智的祖师爷们,采用了
分段技术
分段
,为解决这个问题,8086引入段寄存器,如
CS、DS、ES、SS
。通过
段基址+段内偏移地址
的方式生成20位的地址,扩大寻址能力,从而实现对1MB内存空间的寻址。由于这样程序中指令了只用到16位地址,缩短了指令长度,也变相地提高了程序执行速度。
- CS:代码段寄存器,存放代码段的段基址
- DS是数据段寄存器,存放数据段的段基址
- ES是扩展段寄存器,存放当前程序使用附加数据段的段基址,该段是串操作指令中目的串所在的段
- SS是堆栈段寄存器,存放堆栈段的段基址
- 80836还新增2个寄存器,FS标志段寄存器、GS全局段寄存器。
使用段地址还有一个好处是 程序可以
重定位
,那个时候的计算机可
没有虚拟地址
之说,
只有物理地址
,
访问任何存储单元都直接给出物理地址
。这就带来一个问题: 如果此时计算机多道程序并发运行,程序中的地址都是实际物理地址,这些程序编译出来的程序运行地址是相同的,计算机只能运行一个程序。
重定向
: 将程序中指令的地址改成另一个地址,但该地址处的内容还是原内存地址处的内容。这样程序指令虽然还是物理地址,但程序能够并发运行了。
1982年处理器
80286
,首次提出
保护模式
概念,为了保持兼容性,所以同样支持内存分段管理,将8086这种称为
实模式
,最大的区别是
物理内存地址不能直接被程序访问
,这块非常重要,篇幅也较长,笔者先挖坑,后续系列文章再单独出一篇。
咳咳,拓展的有点多了,赶紧让我们回到bootsect源码处

mov ds,ax
这句话代码的意思就是:将 ax 段寄存器里的值复制到 ds 段寄存器里。ds在上文我们提到,8086特地为采用内存分段机制,引入的段寄存器。ds具体表示
数据段寄存器
,
存放数据段的段基址
换句话说,就是将段基址设为
0x07c0
,那么后续
数据段程序
中只需写
段内偏移地址
,就能访问实际物理地址了。比如后续程序中出现
mov ax,0x01
,
0x01
其实是
[ds:0x01]
,那么
ax的实际物理地址= 0x07c0 <<4 + 0x01
。将ds寄存器段基址设置好后,其实就是方便之后程序访问内存,访问的数据的内存地址都先默认加上
0x7c00
,然后再去内存中寻址。
如果实际编程时,代码段的起始地址一般放到 CS寄存器,虽然CPU没有强制规定代码段、数据段等分离。
mov ax,#INITSEG
,
mov es,ax
将 ax 段寄存器里的值
0x9000
复制到 es 段寄存器里,和ds赋值同理,不再赘述。需要注意的是
8086无法直接给段寄存器进行赋值,需要使用通用寄存器来当中介
(一般使用ax)
bootsect的"再次搬家"到0x90000
接着bootsect自己把自己从内存位置
0x7c00
处,搬到
0x90000
处,这次可没BIOS帮忙了,得自食其力

start:
mov ax,#BOOTSEG
mov ds,ax
mov ax,#INITSEG
mov es,ax
mov cx,#256 ! 设置移动计数值=256 字(512 字节);
sub si,si ! si寄存器 清零
sub di,di ! di寄存器 清零
rep ! 重复执行并递减 cx 的值,直到 cx = 0 为止。
movw ! 即 movs 指令。从内存[si]处移动 cx 个字到[di]处。//一次移动两个字节,256B*2=512B
mov cx,#256
将cx 寄存器的值赋值为 256,单位是字(Word), 1 word=2Byte
sub si,si
是si寄存器 清零操作,
sub
是汇编语言中的一种运算指令,它用来执行减法运算,并将结果存储到被减数(前者)上去。比如
sub a,b
就是
a = a-b
。再结合前面的ds,es,那么此时si的段地址
ds:si = 0x07C0:0x0000
,同理di的段地址
es:di = 0x9000:0x0000
rep
就是重复执行后一条指令,
movw
就是复制的意思。
rep movw
就是重复多次搬运
我们可以知道这段的总体意思就是:循环256次,反复将段地址
0x07C0:0x0000
的内容一个字一个字的复制到
段地址0x9000:0x0000
处,直到寄存器cx为0。这样就实现了bootsect的"自我搬运",把
实际物理内存地址0x7c00处
512个字节的内容全部复制到
实际物理内存地址0x90000处
。
那为啥bootsect还要"多此一举" 将自己从
0x7c00
,搬到
0x90000
处?
- 操作系统system后续最终是要从物理内存起始位置处
地址0
开始存放,好处是让system代码中的地址对应上实际的物理地址。
- 一般要留
512KB
的内存空间放操作系统system,
会覆盖0x7c00地址的内容
,所以需要把bootsect代码搬到内存更高处。
加载setup.s到内存0x90200
当上面bootsect完成自我搬运后,紧接着执行
jmpi go,INITSEG
,jmpi有段间跳转的作用。这里 INITSEG 指出跳转到的
段地址0x9000
,标号 go 是段内偏移地址。
其实就是执行完
jmpi go,INITSEG
后,CPU已经移动到内存
0x90000+go
位置处的代码中 执行。为啥要加go?其实此时bootsect编译后的二进制内容,已经搬运到内存
0x90000
处,但是我们不能再从头执行
start: mov ax,#BOOTSEG
操作,而是从
go: mov ax,cs
处代码继续执行下去。
jmpi go,INITSEG ! 段间跳转。这里 INITSEG 指出跳转到的段地址,标号 go 是段内偏移地址。
go: mov ax,cs
mov dx,#0xfef4 ! arbitrary value >>512 - disk parm size
mov ds,ax
mov es,ax
push ax ! 临时保存段值(0x9000)
mov ss,ax ! put stack at 0x9ff00 - 12.
mov sp,dx
push #0 ! 置段寄存器 fs = 0。
pop fs ! fs:bx 指向存有软驱参数表地址处(指针的指针)
mov bx,#0x78 ! fs:bx is parameter table address
seg fs
lgs si,(bx) ! gs:si is source
mov di,dx ! es:di is destination
mov cx,#6 ! copy 12 bytes
cld
rep ! 复制 12 字节的软驱参数表到 0x9000:0xfef4 处。
seg gs
movw
mov di,dx
movb 4(di),*18 ! patch sector count
seg fs ! 让中断向量 0x1E 的值指向新表。
mov (bx),di
seg fs
mov 2(bx),es
pop ax
mov fs,ax
mov gs,ax
xor ah,ah ! reset FDC 让中断向量 0x1E 的值指向新表。
xor dl,dl
int 0x13
上述主要是将 寄存器DS、ES 和SS 重新设置为CPU移动后,代码所在的段处
0×9000
,设置SP栈寄存器
0xfef4
栈指针要远大于512字节偏移(即 0x90200 )处都可以,一般setup程序大概占用4个扇区,这样栈顶段地址
ss:sp
和现有的代码足够远 ,防止后续栈操作覆盖掉已有的代码。
还有BIOS 设置的中断 0x1e 的中断向量值等操作。这边和主干操作不太相干,简略过一下,主要就是把这些寄存器重新设置好值,方便后续使用。
更多精彩文章在公众号「
小牛呼噜噜
」
接下来紧接着将setup.s 加载到内存
0x90200
处
load_setup:
xor dx, dx ! 驱动器drive 0, 磁头head 0
mov cx,#0x0002 ! 扇区sector 2, 磁道号track 0,从第二个扇区开始读
mov bx,#0x0200 ! 偏移address = 512, in INITSEG ,表示读到0x90200
mov ax,#0x0200+SETUPLEN ! service 2, nr of sectors ,SETUPLEN是 4个扇区
int 0x13 ! read it
jnc ok_load_setup ! ok,就跳到ok_load_setup
push ax ! dump error code
call print_nl ! 屏幕光标回车
mov bp, sp
call print_hex ! 显示十六进制值
pop ax
xor dl, dl ! reset FDC
xor ah, ah
int 0x13
j load_setup ! j 即 jmp 指令,失败就再跳转到load_setup,重复执行
那怎么简单高效将磁盘里的内容加载到内存中呢?linus这里用的是bios的中断程序,因为此时bios还在内存中,可以为我们所用,
0x13
号中断 在BIOS中是可以访问软盘、IDE、ROM、远程磁盘服务的作用。
这里0x13 和C语言中的函数调用是很像的,不过需要注意的是它的参数只能通过
寄存器去传参
,而C语言函数调用不仅可以寄存器传参,还可以
栈传参
。所以0x13的参数就是其前面的dx,cx,bx,ax寄存器的值,另外磁盘只认磁头磁道扇区,如果给个地址,磁盘是不识别的,磁盘一副不太聪明的样子。

另外
xor
对两个操作数进行逻辑(按位)异或操作,并将结果存放在目标操作数,
xor dx,dx
也是一个置零操作,指定驱动和磁头
那么我们连起来,这段主要是让bios 0x13号中断处理程序 从磁盘的第2扇区开始读,接连读4个扇区的内容到内存
0x90200
处中。成功就跳转到
ok_load_setup
,没成功就回到
load_setup
,重复执行上述操作。
加载system到内存0x10000
当bootsect成功将setup.s搬到内存
0x90200
处后,CPU从
ok_load_setup
处继续执行指令。接下来就是需要将整个操作系统system(head.s+其他文件,大约260个扇区)的内容加载到内存
0x10000
处,下面我们就具体看下代码是如何实现的:
ok_load_setup:
! Get disk drive parameters, specifically nr of sectors/track
!提示这面段代码功能是:利用BIOSINT 0x13 中断,来来取磁盘的一些参数,比如是取每磁道扇区数,并保存在
位置 sectors 处
xor dl,dl
mov ah,#0x08 ! AH=8 is get drive parameters
int 0x13
xor ch,ch
seg cs !表示下一条语句的操作数在 cs 段寄存器所指的段中。它只影响其下一条语句
mov sectors,cx
mov ax,#INITSEG
mov es,ax !取磁盘参数中断改了es寄存器的值,这里重置es的值
! Print some inane message 提示下面这段功能是:打印一些消息
mov ah,#0x03 ! read cursor pos 读取当前光标的地址
xor bh,bh
int 0x10 ! bios 0x10中断,其作用:在屏幕上显示字符和字符串
mov cx,#9
mov bx,#0x0007 ! page 0, attribute 7 (normal)
mov bp,#msg1 ! msg1的内容是: .byte 13,10(换行+回车) .ascii "Loading"
mov ax,#0x1301 ! write string, move cursor
int 0x10
! ok, we've written the message, now
! we want to load the system (at 0x10000) 加载system到内存0x10000
mov ax,#SYSSEG
mov es,ax ! segment of 0x010000
call read_it ! 读磁盘上 system 模块
call kill_motor ! 关闭驱动器马达
call print_nl ! 光标回车换行
... 省略非主干代码...
! after that (everyting loaded), we jump to
! the setup-routine loaded directly after
! the bootblock:
jmpi 0,SETUPSEG !bootsect程序到这里就结束了,跳转到0x9020,同时setup获得控制权
这里
int 0x10
号中断,其作用是 在屏幕上显示字符和字符串,由于操作系统比较大,加载需要时间,这时在屏幕上显示提示信息"Loading"
这里将操作系统加载到内存中,是通过子程序
read_it
来实现的,read_it就不具体展开了,比较复杂。我们需要知道由于操作系统比较大,一个磁道是远远放不下的,另外磁盘是不认地址的,在搬运过程中,需要进行磁道、扇区和磁头的计算,特别是一个段的大小是64k,如果放不下,需要更换段地址。如果不更换段地址,会从该段地址0字节开始重新写,这样会覆盖之前的内容。
那为什么一个段的大小是64KB呢?
我们知道在8086CPU中,其内存地址是表示为
段基址+段内偏移地址,其中
偏移地址使用一个16位的二进制数表示,表示范围
0000~FFFF
,所以总共有2^16(2的16次方)=64K个不同的地址,一个内存最小单元是字节Byte,所以一个段大小为64KB

jmpi 0,SETUPSEG
,bootsect程序到这里就结束了,跳转到内存地址
0x90200
,同时setup获得控制权
为了帮助大家理解,呼噜噜这里又把本篇文章全部串起来,大家可以根据下面这张图重新回顾一下bootsect整个工作流程:

额外补充一下:
boot_flag: .word 0xAA55
最后2个字节是
0xAA55
,由于bootsect是采用AT&T汇编,
小端
显示的,实际上就是
0x55AA
与前文MBR那边前后呼应
这也说明了操作系统在开始加载到内存的程序中,得与内存地址一一对应, 不能多一个字节,也不能少一个字节!!!
尾语
本文主要讲解了bootsect.S的主要工作流程,Linux0.12虽然和如今的Linux6.x内核相比显得过于简陋,但麻雀虽小五脏俱全,它是我们打开操作系统大门的钥匙,后面让我们看看setup.s获得计算机的控制权后,会发生什么?
最近实在太忙了,后面随缘更新,留言可催更(bushi)~~

参考资料:
《Linux内核完全注释5.0》
《操作系统真象还原》
https://elixir.bootlin.com/linux/0.12/source/boot/bootsect.S
https://files.embeddedts.com//old/saved-downloads-manuals/EBIOS-UM.PDF
本篇文章到这里就结束啦,如果我的文章对你有所帮助的话,还请点个免费的
赞
,你的支持会激励我输出更高质量的文章,感谢!
作者:小牛呼噜噜 ,首发于公众号
小牛呼噜噜
,系列文章还有:
- 聊聊x86计算机启动发生的事?
- Linux0.12内核源码解读(2)-Bootsect.S
- Linux0.12内核源码解读(3)-Setup.S
- 图解CPU的实模式与保护模式
- Linux0.12内核源码解读(7)-陷阱门初始化
- 图解计算机中断
- 什么是系统调用机制?结合Linux0.12源码图解