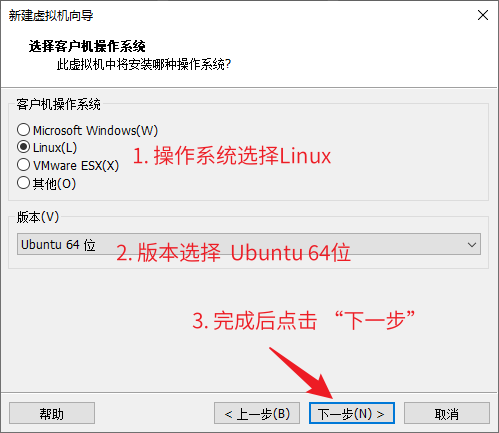
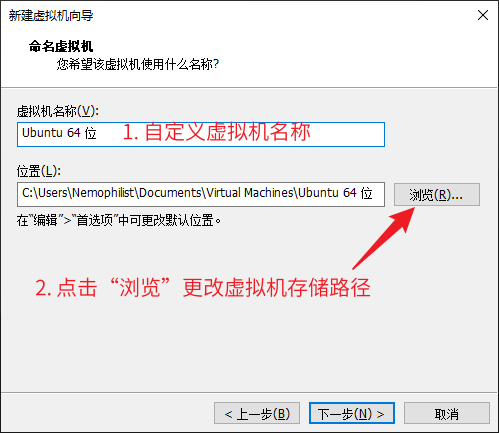
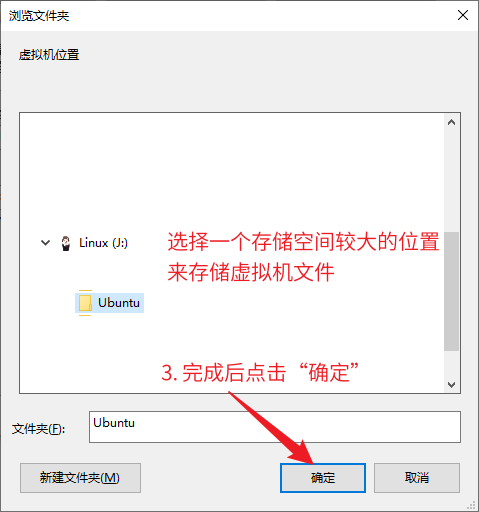
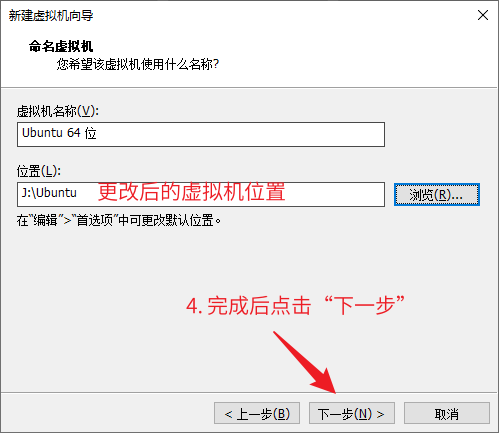
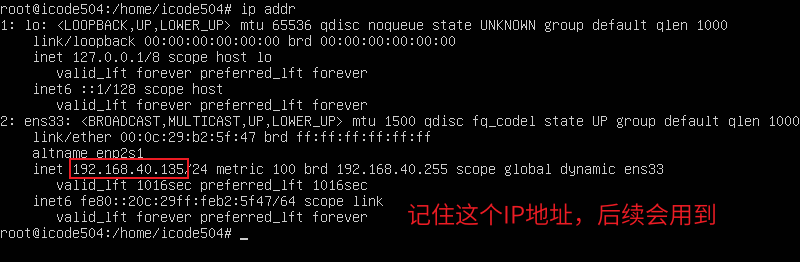
C#的AOP(最经典实现)
(适用于.NET/.NET Core/.NET Framework)
【目录】
0.前言
1.第一个AOP程序
2.Aspect横切面编程
3.一个横切面程序拦截多个主程序
4.多个横切面程序拦截一个主程序
5.AOP的泛型处理
(扩充)
6.AOP的异步处理
(扩充)
7.优势总结
8.展望
0.前言
AOP(Aspect Oriented Programming)是“面向横切面编程”,主要是用来对程序/模块进行解耦。怎么理解??
我们可以把一般的编程理解为“纵向编程”(主程序),比如如下的一个示例代码:
public string GetInfo(inti)
{string s = "";if (i == 1)
s= "A";else if (i == 2)
s= "B";else if (i == 3)
s= "C";elses= "Z";returns;
}
试想一下,上述软件实际使用后,
- 如果条件变量i有更多的判断值,我们是不是要在GetInfo()方法内部修改代码+重新编译?
- 如果后续需要加个日志记录功能,我们是不是也要在GetInfo()方法内部加上日志函数+重新编译?
- 如果...
- 更多如果...
为了避免上述的这些麻烦并增加软件的灵活性,“横向编程”,也就是AOP被创造了出来,它就像是“横切一刀”,把相关功能塞进了主程序。
现行AOP的实现,主要是通过拦截方法(即拦截主程序),并修改其参数+返回值来完成。
网上有很多相关方案,比如:特性注释拦截、动态代码生成、派遣代理模式、等。但这些方案要么实现的很复杂、要么耦合度没完全切断、逻辑有变化时还是需要修改代码重新编译。均不够理想。
而今天要隆重登场的主角-DeveloperSharp平台中的AOP技术,则提供了一种简便、快捷、彻底解耦的AOP实现。使用它,在程序逻辑有变化时,你只需要修改配置文件就行,而不再需要对主程序进行一丁丁点的代码修改!!
1.第一个AOP程序
制作一个AOP程序需要四个步骤:
(1)制作主程序
(2)制作横切面程序
(3)制作配置文件,让横切面程序拦截主程序
(4)调用主程序
下面,我们一步一步来实现上述四个步骤。
【第一步】:制作主程序
我们在Visual Studio中新建一个名为“School.Logic”的类库工程,并在该工程中新建一个名为PersonManage的类,该类中有一个名为GetInfo1的方法,代码如下:
//从NuGet引用DeveloperSharp包 usingDeveloperSharp.Structure.Model;namespaceSchool.Logic
{//主程序必须继承自LogicLayer类 public classPersonManage : LogicLayer
{public string GetInfo1(string Name, intNum)
{return $"共有{Name}{Num}人";
}
}
}
以上,编写了一个非常简单的主程序。
【第二步】:制作横切面程序
我们再在Visual Studio中新建一个名为“School.Aspect”的类库工程,并在该工程中新建一个名为Interceptor1的类,代码如下:
//从NuGet引用DeveloperSharp包 usingDeveloperSharp.Structure.Model.Aspect;namespaceSchool.Aspect
{//横切面程序必须继承自AspectModel类 public classInterceptor1 : AspectModel
{//PreProcess方法先于主程序执行 public override void PreProcess(objectsender, AspectEventArgs e)
{//把主程序的两个参数值改掉 e.MethodInfo.ParameterValues[0] = "老师";
e.MethodInfo.ParameterValues[1] = 20;
}//PostProcess方法后于主程序执行 public override void PostProcess(objectsender, AspectEventArgs e)
{
}
}
}
以上,编写了一个横切面程序。它的主要功能是把主程序方法的两个参数值给改掉。
AspectModel基类中的PreProcess方法会在主程序方法执行之前被执行,而PostProcess方法会在主程序方法执行之后被执行。它两就是AOP横向拦截的核心要素。它两均需要被override重写覆盖掉。
【第三步】:制作配置文件,让横切面程序拦截主程序
若是在.Net Core环境下,我们创建一个名为DeveloperSharp.json的配置文件,设置让Interceptor1拦截PersonManage中的GetInfo1方法。文件内容如下:
{"DeveloperSharp":
{"AspectObject":
[
{"name":"School.Aspect.Interceptor1", //横切面拦截器类 "scope":"School.Logic.PersonManage", //被拦截的主程序类 "method":"GetInfo1" //被拦截的方法 }
]
}
}
若是在.Net Framework环境下,我们创建一个名为DeveloperSharp.xml的配置文件,设置让Interceptor1拦截PersonManage中的GetInfo1方法。文件内容如下:
<?xml version="1.0" encoding="utf-8"?> <DeveloperSharp> <AspectObject> <Aoname="School.Aspect.Interceptor1"scope="School.Logic.PersonManage"method="GetInfo1"/> </AspectObject> </DeveloperSharp>
注意:以上配置中所有的类名,都要用完全限定名。
【第四步】:调用主程序
最后,我们再在Visual Studio中创建一个控制台工程,让它来调用主程序中的GetInfo1方法,代码如下:
//需要引用School.Aspect、School.Logic、DeveloperSharp三项 static void Main(string[] args)
{var pm = newSchool.Logic.PersonManage();//要用这种形式调用主程序中的方法,AOP功能才会生效 var str = pm.InvokeMethod("GetInfo1", "学生", 200);
Console.WriteLine(str);
Console.ReadLine();
}
附注:有人会觉得上述InvokeMethod这种调用方法不够优雅,但事实上ASP.NET Web Api也是被类似InvokeMethod这种方式包裹调用才实现了各种Filter拦截器的拦截(本质也是AOP),只不过它的这个InvokeMethod动作是在.NET自身的CLR管道运行时中进行的。而且,那些Filter拦截器还只能用于ASP.NET Web Api环境,而不能像本方案这样用于一般程序。
现在,为了让前面第三步创建的配置文件生效,我们此时还需要在此主调项目中对它进行链接:
若是在.Net Core环境下,我们只需要把DeveloperSharp.json文件放到程序执行目录中(即bin目录下与dll、exe等文件的同一目录中,放错了位置会报错)(注意:有些.Net Core版本在Visual Studio“调试”时,不会在bin目录下生成全部的dll、exe,此时需要把此配置文件放在应用程序的“根目录”下)。
若是在.Net Framework环境下,我们需要在工程配置文件App.config/Web.config中添加appSettings节点,节点内容如下:
<appSettings> <addkey="ConfigFile"value="D:\Test\Assist\DeveloperSharp.xml" /> </appSettings>
此处需要设置为配置文件的“绝对路径”(使用“绝对路径”而不是“相对路径”,一是有利于安全性,二是有利于分布式部署)
一切准备完毕,运行,结果如下:
【控制台显示出】:
共有老师20人
可见AOP已经拦截成功。
若此时,我们在配置文件DeveloperSharp.json/DeveloperSharp.xml中稍做修改,比如:把“GetInfo1”这个方法名改为“ABC”这样一个不存在的方法名,再运行,结果如下:
【控制台显示出】:
共有学生200人
2.Aspect横切面编程
上面,第二步,制作的横切面程序,是通过修改主程序方法的参数值,而最终改变了主程序的返回值。
其实,我们也有办法直接修改主程序方法的返回值,比如把上面Interceptor1类的代码修改为如下:
//从NuGet引用DeveloperSharp包 usingDeveloperSharp.Structure.Model.Aspect;namespaceSchool.Aspect
{//横切面程序必须继承自AspectModel类 public classInterceptor1 : AspectModel
{//PreProcess方法先于主程序执行 public override void PreProcess(objectsender, AspectEventArgs e)
{
}//PostProcess方法后于主程序执行 public override void PostProcess(objectsender, AspectEventArgs e)
{//把主程序的返回值改掉 e.MethodInfo.ReturnValue = $"共有校长2人";
}
}
}
运行,结果如下:
【控制台显示出】:
共有校长2人
到目前为止,我们已经知道了如何通过“Aspect横切面程序”修改主程序方法的参数值、返回值。
如果我们想进一步获取主程序的“命名空间”、“类名”、“方法名”、“参数名”、“参数类型”、“返回值类型”,则可以通过如下代码获取:
e.MethodInfo.NamespaceName //命名空间 e.MethodInfo.ClassName //类名 e.MethodInfo.MethodName //方法名 e.MethodInfo.ParameterInfos[0].Name //参数名(第一个参数) e.MethodInfo.ParameterInfos[0].ParameterType //参数类型(第一个参数) e.MethodInfo.ReturnValue.GetType() //返回值类型
有时候,在某些特殊情况下,我们希望主程序方法不运行,此时则可以通过在PreProcess方法里把e.Continue设置为false来完成。
接前面的“第一个AOP程序”,比如:我们希望当人数大于10000时,主程序方法就不再运行,则可以通过把Interceptor1类的代码修改为如下样式来实现:
//从NuGet引用DeveloperSharp包 usingDeveloperSharp.Structure.Model.Aspect;namespaceSchool.Aspect
{//横切面程序必须继承自AspectModel类 public classInterceptor1 : AspectModel
{//PreProcess方法先于主程序执行 public override void PreProcess(objectsender, AspectEventArgs e)
{//当人数大于10000时,主程序方法就不再运行 if (Convert.ToInt32(e.MethodInfo.ParameterValues[1]) > 10000)
e.Continue= false;
}//PostProcess方法后于主程序执行 public override void PostProcess(objectsender, AspectEventArgs e)
{
}
}
}
现在的这个示例是一个Aspect横切面程序拦截一个主程序。在后续将要讲解的“多个Aspect横切面程序拦截一个主程序”的情况中,只要有一个e.Continue=false被设置,主程序方法就不会运行(在此事先提点)。
3.一个横切面程序拦截多个主程序
为了演示这部分的内容,我们首先在前面“第一个AOP程序”的基础上,把主程序进行扩充。采取的动作是:
(1)在PersonManage类中增加一个GetInfo2方法
(2)再新增一个主程序类SystemManage,该类中有一个名为GetMessage1的方法。代码如下:
PersonManage类:
//从NuGet引用DeveloperSharp包 usingDeveloperSharp.Structure.Model;namespaceSchool.Logic
{//主程序必须继承自LogicLayer类 public classPersonManage : LogicLayer
{public string GetInfo1(string Name, intNum)
{return $"共有{Name}{Num}人";
}public string GetInfo2(string Name, intNum)
{return $"学校共有{Name}{Num}人";
}
}
}
SystemManage类:
//从NuGet引用DeveloperSharp包 usingDeveloperSharp.Structure.Model;namespaceSchool.Logic
{//主程序必须继承自LogicLayer类 public classSystemManage : LogicLayer
{public string GetMessage1(string Name1, int Num1, string Name2, intNum2)
{return $"第一组共有{Name1}{Num1}人,第二组共有{Name2}{Num2}人";
}
}
}
如此一来,现在就有了3个主程序方法。
接下来,我们修改配置文件,让Interceptor1去拦截上述的3个主程序方法。
若是在.Net Core环境下,DeveloperSharp.json文件的内容修改为如下:
{"DeveloperSharp":
{"AspectObject":
[
{"name":"School.Aspect.Interceptor1","scope":"School.Logic.PersonManage","method":"*" //星号*代表该作用域下的全部方法 },
{"name":"School.Aspect.Interceptor1","scope":"School.Logic.SystemManage","method":"GetMessage1"}
]
}
}
若是在.Net Framework环境下,DeveloperSharp.xml文件的内容修改为如下:
<?xml version="1.0" encoding="utf-8"?> <DeveloperSharp> <AspectObject> <Aoname="School.Aspect.Interceptor1"scope="School.Logic.PersonManage"method="*"/> <Aoname="School.Aspect.Interceptor1"scope="School.Logic.SystemManage"method="GetMessage1"/> </AspectObject> </DeveloperSharp>
最后,我们把控制台启动程序修改为如下:
//需要引用School.Aspect、School.Logic、DeveloperSharp三项 static void Main(string[] args)
{var pm = newSchool.Logic.PersonManage();var sm = newSchool.Logic.SystemManage();//要用这种形式调用主程序中的方法,AOP功能才会生效 var str1 = pm.InvokeMethod("GetInfo1", "学生", 200);var str2 = pm.InvokeMethod("GetInfo2", "学生", 200);var str3 = sm.InvokeMethod("GetMessage1", "学生", 200, "院士", 10);
Console.WriteLine(str1);
Console.WriteLine(str2);
Console.WriteLine(str3);
Console.ReadLine();
}
运行结果如下:
【控制台显示出】:
共有老师20人
学校共有老师20人
第一组共有老师20人,第二组共有院士10人
可见AOP所有拦截均已成功!
4.多个横切面程序拦截一个主程序
为了演示这部分的内容,我们还是要先回到前面的“第一个AOP程序”,在它的基础上,我们新增一个名为Interceptor2的Aspect横切面类,代码如下:
//从NuGet引用DeveloperSharp包 usingDeveloperSharp.Structure.Model.Aspect;namespaceSchool.Aspect
{//横切面程序必须继承自AspectModel类 public classInterceptor2 : AspectModel
{//PreProcess方法先于主程序执行 public override void PreProcess(objectsender, AspectEventArgs e)
{//把主程序的两个参数值改掉 e.MethodInfo.ParameterValues[0] = "辅导员";
e.MethodInfo.ParameterValues[1] = 40;
}//PostProcess方法后于主程序执行 public override void PostProcess(objectsender, AspectEventArgs e)
{
}
}
}
如此一来,我们就有了2个Aspect横切面程序Interceptor1与Interceptor2。
接下来,我们修改配置文件,让Interceptor1、Interceptor2都去拦截主程序方法GetInfo1。
若是在.Net Core环境下,DeveloperSharp.json文件的内容修改为如下:
{"DeveloperSharp":
{"AspectObject":
[
{"name":"School.Aspect.Interceptor1","scope":"School.Logic.PersonManage","method":"GetInfo1"},
{"name":"School.Aspect.Interceptor2","scope":"School.Logic.PersonManage","method":"GetInfo1"}
]
}
}
若是在.Net Framework环境下,DeveloperSharp.xml文件的内容修改为如下:
<?xml version="1.0" encoding="utf-8"?> <DeveloperSharp> <AspectObject> <Aoname="School.Aspect.Interceptor1"scope="School.Logic.PersonManage"method="GetInfo1"/> <Aoname="School.Aspect.Interceptor2"scope="School.Logic.PersonManage"method="GetInfo1"/> </AspectObject> </DeveloperSharp>
上述修改完毕,运行控制台主调程序,结果如下:
【控制台显示出】:
共有辅导员40人
从上述运行结果,我们大致可以推断出:Interceptor1、Interceptor2这两个Aspect横切面拦截器是按配置顺序执行的。其中,Interceptor1先把GetInfo1方法的两个参数值改为了("老师",20),接着,Interceptor2又把GetInfo1方法的两个参数值改为了("辅导员",40),所以最终GetInfo1方法的参数值变为了("辅导员",40)。
5.AOP的泛型处理
如果我们的主程序是泛型方法,则需要用InvokeMethod<T>这种方式来进行调用。
比如,现有如下的主程序代码:
//从NuGet引用DeveloperSharp包 usingDeveloperSharp.Structure.Model;namespaceTest4Logic
{//主程序必须继承自LogicLayer类 public classCalculate : LogicLayer
{public int add(int i, intj)
{return i +j;
}public int add(int i, int j, intk)
{return i + j +k;
}public string add<T>(T i, T j, T k)
{return "T" + i.ToString() + j.ToString() +k.ToString();
}public string add<T, V>(T i, T j, V k)
{return "TTV" + i.ToString() + j.ToString() +k.ToString();
}public string add<T, V>(T i, V j, V k)
{return "TVV" + i.ToString() + j.ToString() +k.ToString();
}
}
}
对应的Aspect横切面类代码如下:
//从NuGet引用DeveloperSharp包 usingDeveloperSharp.Structure.Model.Aspect;namespaceTest4Aspect
{//横切面程序必须继承自AspectModel类 public classInterceptor : AspectModel
{//PreProcess方法先于主程序执行 public override void PreProcess(objectsender, AspectEventArgs e)
{//把主程序的第一个参数值改掉 e.MethodInfo.ParameterValues[0] = 8;
}//PostProcess方法后于主程序执行 public override void PostProcess(objectsender, AspectEventArgs e)
{
}
}
}
对应的配置文件如下:
若是在.Net Core环境下,DeveloperSharp.json文件的内容如下:
{"DeveloperSharp":
{"AspectObject":
[
{"name":"Test4Aspect.Interceptor", //横切面拦截器类 "scope":"Test4Logic.Calculate", //被拦截的主程序类 "method":"add" //被拦截的方法 }
]
}
}
若是在.Net Framework环境下,DeveloperSharp.xml文件的内容如下:
<?xml version="1.0" encoding="utf-8"?> <DeveloperSharp> <AspectObject> <Aoname="Test4Aspect.Interceptor"scope="Test4Logic.Calculate"method="add"/> </AspectObject> </DeveloperSharp>
控制台主调程序代码如下:
//需要引用Test4Aspect、Test4Logic、DeveloperSharp三项 static void Main(string[] args)
{var cal = newTest4Logic.Calculate();//要用这种形式调用主程序中的方法,AOP功能才会生效 var r1 = cal.InvokeMethod("add", 1, 2);var r2 = cal.InvokeMethod("add", 1, 2, 3);var r3 = cal.InvokeMethod<int>("add", 1, 2, 3);var r4 = cal.InvokeMethod<int, float>("add", 1, 2, (float)3);var r5 = cal.InvokeMethod<int, float>("add", 1, (float)2, (float)3);
Console.WriteLine(r1);
Console.WriteLine(r2);
Console.WriteLine(r3);
Console.WriteLine(r4);
Console.WriteLine(r5);
Console.ReadLine();
}
运行上述控制台主调程序,结果如下:
【控制台显示出】:
10
13
T823
TTV823
TVV823
主程序中每个泛型方法的对应调用一目了然。
6.AOP的异步处理
如果我们的主程序是异步方法,还是使用InvokeMethod来进行调用。下面给出一个代码样式示例(代码做了简化处理):
//主程序//主程序必须继承自LogicLayer类 public classUserService : LogicLayer
{public async Task<Worker> GetUser(string Id, int Age, stringName)
{//...相关代码... }public async Task<T> GetUser<T>(string Id, int Age, string Name) where T : User, new()
{//...相关代码... }
}---------------------------------------------------------------------- //主调程序 var us = newUserService();//要用这种形式调用主程序中的方法,AOP功能才会生效 var worker = await us.InvokeMethod("GetUser", "C007", 26, "alex");var user = await us.InvokeMethod<Manager>("GetUser", "A002", 46, "kevin");
Console.WriteLine(worker.Name);
Console.WriteLine(user?.Name);
即然主程序可以是异步的,那Aspect横截面拦截程序能不能也是异步的了?答案是肯定的。你可以把PreProcess与PostProcess中的至少一个改为异步方法,实现单个Aspect类的同步异步混用,其代码结构与原先的同步Aspect类一致,这点连.NET/微软自身都还没有实现...
下面给出一个示例代码:
//横切面程序必须继承自AspectModel类 public classUserInterceptor : AspectModel
{//PreProcess方法先于主程序执行 public override void PreProcess(objectsender, AspectEventArgs e)
{
}//PostProcess方法后于主程序执行 public override async void PostProcess(objectsender, AspectEventArgs e)
{await Task.Run(() =>{
Thread.Sleep(10000);
File.AppendAllText("D:/zzz.txt", "耗时操作");
});
}
}
7.优势总结
本文所讲述的,是全网唯一实现AOP彻底解耦的技术方案。使用它,当你需要给主程序增加Aspect横切面拦截器时,无论是增加一个还是多个,都不再需要修改&重新编译主程序。这实现了不同功能构件之间的0依赖拼装/拆卸开发方式,随之而来的也会对研发团队的管理模式产生重大影响,意义深远...
8.展望
AOP对于程序代码的解耦、业务模块的拆分与拼装组合,有着巨大的作用。正确的使用AOP,甚至能对传统的软件架构设计,产生颠覆性的影响,如超级战士出场一般,让所有人刮目相看,完全耳目一新!!
为了让读者能直观感知AOP的上述神奇魅力,下面给出一个业务案例:
有一批货品要录入数据库,货品包含长、宽、高、颜色、类型等属性。现在有业务需求如下,
(1)当货品长度大于10厘米时,它在数据库中标记为A类;当货品长度大于20厘米时,标记为B类。
(2)当货品颜色无法分辨时,统一在数据库中默认标记为白色。
(3)每个货品录入数据库后,还要在另一个财务数据库中录入该货品的价格信息,同时把该货品的操作员名字记入日志文件。
这样的一个业务案例,你以前会怎么设计这个程序?今天学了AOP后你又会怎么设计程序?你会创建几个Aspect横切面了...?
原文首发于下方公众号,请关注!
向大佬学习,探行业内幕,享时代机遇。